在项目开发、文档数字化、票据识别落地场景中,OCR是高频刚需模块。目前开发者选型热度最高的三款方案:SDK15、PaddleOCR-VL-1.5、GLM-OCR,各有技术特性差异,不同场景适配度差距极大。本文基于实测数据,从基础识别、复杂场景适配、工程落地角度做全方位对比,为开发选型提供精准参考。
一、基础识别能力实测:核心指标差异化明显
技术层面评判OCR性能,主要参考角标识别、生僻字兼容、特殊字符识别三大核心指标。实测结果显示,PaddleOCR-VL-1.5集成度更高,无需额外配置开关,可自动识别文档角标、脚注标注,开箱即用,二次开发成本更低。SDK15识别精度严谨,但角标识别需手动开启对应接口功能,配置流程繁琐,高密角标场景偶发漏检问题。GLM-OCR细节识别能力偏弱,密集角标场景漏检率较高,专业文档适配性不足。
生僻字兼容方面,SDK15优势显著,搭载27712字超大字符集,可完美适配古籍文献、行业专业术语、小众非标文档识别,适配政企、文博等专业项目。PaddleOCR字符集可覆盖绝大多数通用办公场景,满足常规开发需求。GLM-OCR适配标准印刷字体,生僻字兼容能力一般。特殊字符识别上,GLM-OCR稳定性更优,乱码、错识概率更低,另外两款工具存在小幅识别偏差。
二、复杂业务场景适配:落地能力拉开差距
针对多语种、手写识别、超大文件解析、票据套打四大落地高频场景,三款工具的适配差异十分突出。多语种识别领域,PaddleOCR支持109种语言自动识别,覆盖面极广,仅小众语种存在轻微乱码,适合跨境业务开发场景。SDK15仅支持13种语种手动选择,胜在识别稳定,适合固定语种的标准化项目。GLM-OCR小语种识别误差大,不适用跨境开发需求。
手写场景实测,PaddleOCR对潦草手写字体、手写工单、自由笔迹的鲁棒性更强,适配教育、办公手写电子化项目。SDK15整体识别率达标,但易混数字、字母识别容错率低。GLM-OCR手写识别表现一般,仅适配标准印刷文本场景。
大文件解析是SDK15的核心亮点,可稳定处理10MB以上高清扫描件、工程图纸、高清票据,适配高精度、大体积文件识别项目。PaddleOCR与GLM-OCR均存在文件大小限制,超大图片易解析失败、超限报错,难以支撑专业高清场景落地。同时三款工具在票据套打场景均存在轻微缺陷,无完美适配方案。
三、工程选型总结:按需落地,拒绝冗余
综合实测数据来看,三款OCR方案无绝对优劣,核心看业务场景匹配度。SDK15偏向专业级落地,适合古籍数字化、高清大图处理、政企高精度识别项目,适配专业开发团队。PaddleOCR综合性能均衡、开源易用、二次开发成本低,是跨境、教育、普通办公项目的高性价比选型,适配中小开发团队与个人开发者。GLM-OCR轻量化、特殊字符稳定,适合轻量化常规文档识别的快速开发场景。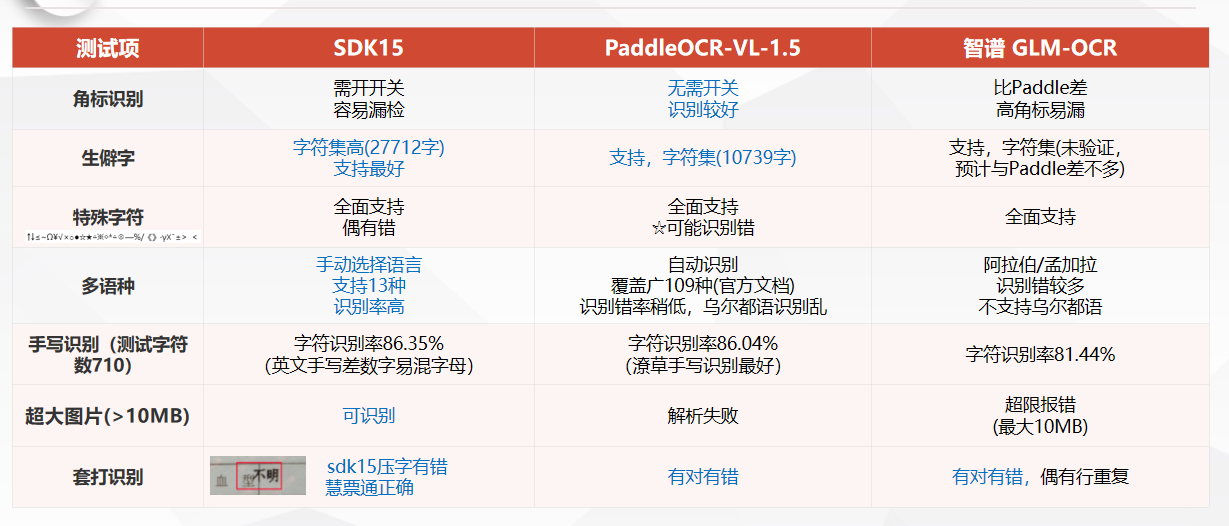
在AI OCR技术快速迭代的背景下,开发选型无需盲目追求全能,结合业务场景匹配技术特性,才能实现项目高效落地、性能与成本最优。