提示词强化 3:JSON 与「流式」------前后端原理、BFF、以及两个示例页
很多人第一次接触 OpenAI 兼容 Chat Completions + stream: true 时,容易把两件事混在一起:
- **SSE(网络层)**里每一行
data: ...往往是一个 JSON 对象 ------但这是 协议包络(描述本次 delta、finish_reason 等),不是你要的业务数据。 - 业务层 若要求模型输出 一整段 JSON 字符串 ,流式传的是 这段字符串被切成的小块 ;在流未结束之前,任意时刻 拼出来的文本通常 还不是 合法 JSON,因此不能指望「每个 SSE 帧 = 一个可
JSON.parse的业务对象」。
本文按顺序说明:前后端各自在做什么 、本仓库里的 BFF 怎么接 、以及 index-json-story-stream.html (故事)与 index-json-phrase-stream.html(亲子例句)在实现上的同与不同。
本地看效果
clone代码之后,项目根目录新建.env.local,填上各种key。然后node server.js,浏览器看任一html文件即可
一、怎么「用 JSON 做流式」------先把链路画对
更精确的说法是:流式传递的是「正在生长的文本」;若这段文本的目标是 JSON,则 JSON 是最终形态,而不是每个网络包自带一个完整业务 JSON。
1. 上游大模型(Moonshot 等)在流什么?
浏览器(或 BFF)发起:
http
POST .../v1/chat/completions
Content-Type: application/json
{ "model": "...", "messages": [...], "stream": true }上游若支持流式,响应常见为 text/event-stream(SSE) :长连接,服务端持续写出多行,形如:
text
data: {"id":"...","choices":[{"delta":{"content":"你"}}],...}
data: {"id":"...","choices":[{"delta":{"content":"好"}}],...}
...
data: [DONE]要点:
- 每一行
data:后面跟的,是 OpenAI 兼容的「事件」JSON (整行可JSON.parse)。 - 你真正关心的故事/例句内容,在
choices[0].delta.content里,往往是 几个字符到一小段文本 ;这些片段 顺序拼接 后,才是模型正在「打字」出来的 一整段字符串 (本仓库页面里通常命名为content或 buffer)。
所以:「流式」首先流的是 delta 文本;业务 JSON 是这些文本拼接后的语义。
2. 前端在做什么?(应用层)
典型三步:
fetch拿到response.body,用ReadableStreamDefaultReader按块读取。TextDecoder(..., { stream: true })解码字节流,按\n拆行;半行 留在carry里下一拍再拼(避免 UTF-8 多字节字符或data:行被截断)。- 对完整行:若以
data:开头且负载不是[DONE],则JSON.parse包络 ,取出delta.content,执行content += delta。
到此为止,你得到的是 一根越来越长的字符串 。若这根字符串应当是 单个 JSON 对象,下一步才是:
tryParseModelJson(content):从整段里抠出{ ... }(容错 ```json 围栏),再JSON.parse;失败则返回null,不抛错。- 流结束后再 兜底 parse 一次 ,避免最后几字节在
carry里漏处理。
JSON.parse 要求语法完整 :中间态如 {"stor、未闭合的引号、缺 ] 等都会失败------因此「每来一个 delta 就 parse 整段业务 JSON」在实现上是 反复尝试直到某一刻刚好合法,而不是「每个包必成功」。
3. BFF / 后端在做什么?(可选但推荐)
若浏览器 直连 Moonshot,则必须在请求头里带 Authorization: Bearer <API_KEY> ,Key 会暴露在前端代码、网络面板、扩展、误提交的构建产物中,生产环境不可取。
BFF(Backend for Frontend) 在这里指:浏览器只访问你自己的同源或可信域上的一个小服务;由该服务:
- 从 环境变量 / 密钥管理 读取
MOONSHOT_API_KEY,代发https://api.moonshot.cn/v1/...; - 对
stream: true的 chat completions,把上游 SSE 原样透传 给浏览器(低延迟、不整包缓冲),浏览器端的readSseDeltas逻辑与直连完全一致。
本仓库的 server.js 即扮演这一角色:见下一节。
二、本仓库里的 BFF:server.js 行为摘要
1. Moonshot 代理路径
- 浏览器请求:
POST {BFF根}/moonshot/v1/chat/completions - 服务端转发到:
{MOONSHOT_API_ORIGIN}/v1/chat/completions(默认https://api.moonshot.cn),并带上Authorization: Bearer ${MOONSHOT_API_KEY}(或兼容读取VITE_API_KEY/API_KEY,以文件头注释为准)。 - 当请求体 JSON 里
"stream": true且上游返回text/event-stream时:使用Readable.fromWeb(upstream.body).pipe(res)做 SSE 透传 ;否则仍可按整包arrayBuffer回传。
这样:前端不需要、也不应该保存 Moonshot Key ;只需填 BFF 根地址 (例如 http://127.0.0.1:3000)。
2. 火山 TTS(仅例句页会用到)
亲子例句页在句末小喇叭里会调 TTS。浏览器请求:
POST {BFF根}/tts/api/v1/tts
由服务端合并 AppId / Cluster / Token 等敏感配置,按火山文档格式转发到 openspeech;真实 token 不出现在页面。
故事页 不涉及 TTS,因此只需 Moonshot 这一条 BFF 路径即可。
3. 运行注意
- 用
node server.js启动 BFF,在.env.local配置 Moonshot(及例句页需要的火山 TTS)变量。 - 静态 HTML 建议通过 同源或允许 CORS 的 HTTP 打开(不要依赖
file://随意跨域),以便fetchBFF 与流式读取稳定。
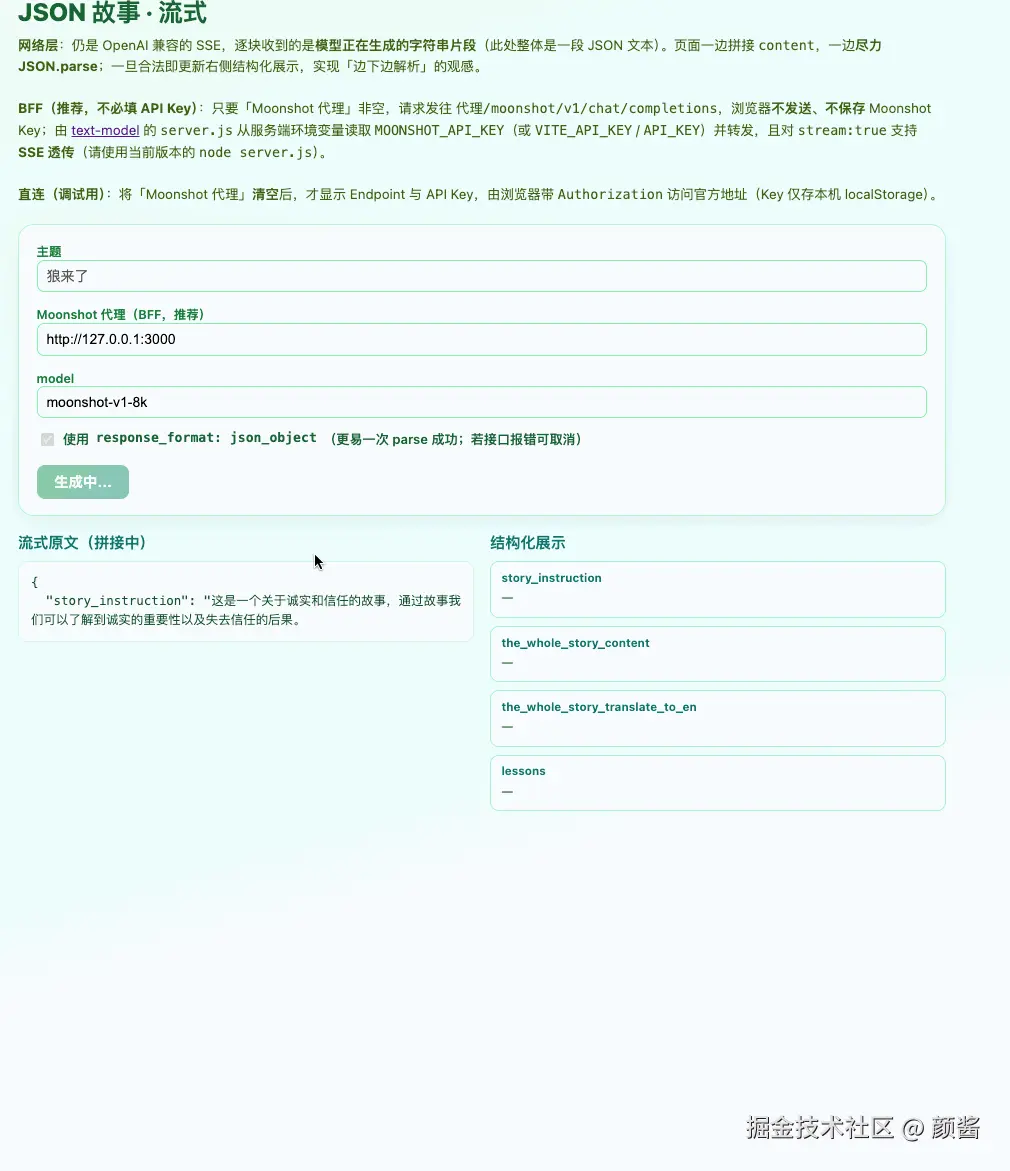
三、故事页:index-json-story-stream.html
目标 JSON 形态
System prompt 要求模型只输出(概念上)如下结构:
story_instruction、the_whole_story_content、the_whole_story_translate_to_en、lessons[]
并可配合 response_format: { type: 'json_object' } ,让模型更倾向输出 纯 JSON ,提高流式过程中「第一次 parse 成功」的稳定性。
实现要点
| 步骤 | 作用 |
|---|---|
readSseDeltas |
只负责 SSE 包络 → delta.content → 拼 content |
tryParseModelJson(content) |
从 content 抠 {...} 并 整段 JSON.parse,失败返回 null |
| 每个 delta 后 | content += delta → 再 tryParseModelJson → 成功则 mergeParsed 写入 contentParsed,右侧卡片更新 |
| 流结束后 | 再 tryParseModelJson 一次兜底;仍失败则提示用户(可对比关闭 JSON Object 模式) |
与 BFF 的配合
proxyBase(页内文案「Moonshot 代理」)非空 :请求 URL 为${proxyBase}/moonshot/v1/chat/completions,不发送Authorization;localStorage 会 移除 直连用的 api key 项。- 清空代理 :走直连 endpoint,浏览器带
Bearer ${apiKey}(仅适合本地学习)。
体验特点 :结构化 UI 往往在 JSON 尾部括号、引号补全 前后才第一次稳定更新;这是「整对象流式打印」的常态,不是 bug。
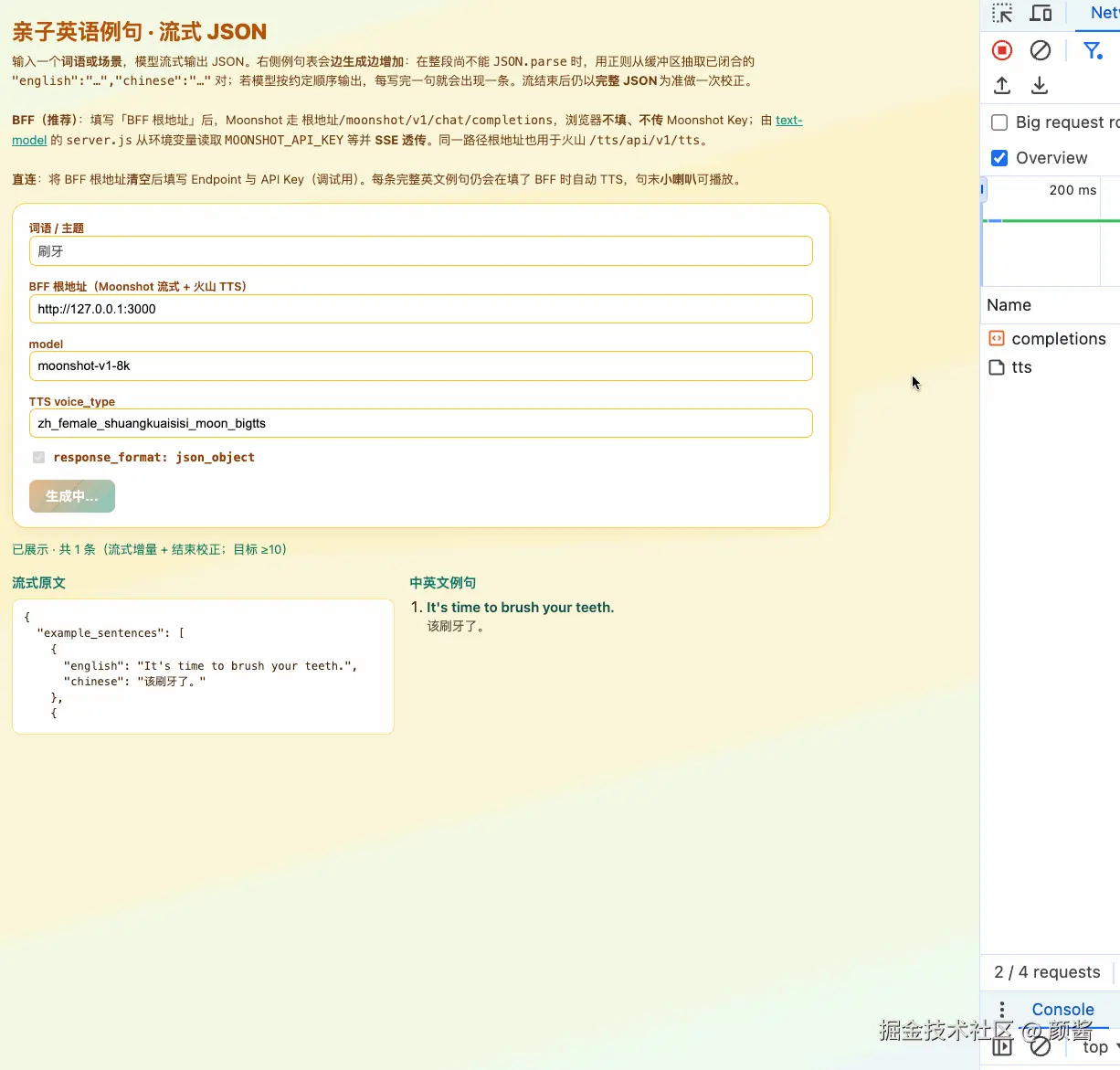
四、亲子例句页:index-json-phrase-stream.html
目标 JSON 形态
example_sentences 数组,每项 english + chinese,至少 10 句;同样可用 json_object 模式。
与故事页相同的骨架
- 同一套
readSseDeltas+tryParseModelJson+ 结束兜底。 - BFF :
bffBase非空 时,POST ${bffBase}/moonshot/v1/chat/completions,不传 Moonshot Key;清空 则显示直连 endpoint + key。 - 额外:
POST ${bffBase}/tts/api/v1/tts做句末朗读(voice_type、encoding等在页内配置,不在页内配火山 token)。
多出来的「半段 JSON 也要列表」:applyParsedFromBuffer
故事页只在 整段能 JSON.parse 时更新列表。例句页希望 更早 看到句子,因此在 tryParseModelJson 仍失败 时增加一步:
-
extractPairsFromPartialBuffer(buf)用正则匹配已经 成对闭合 的
"english": "..." , "chinese": "..."(含转义字符处理decodeJsonStrSegment)。这依赖模型 按 english → chinese 顺序 输出(与 system 约定一致);不是 通用 JSON 流式解析器,而是 针对本结构的启发式增量展示。
-
applyParsedFromBuffer1)若整段已能 parse →
mergeParsed得到规范数组;2)否则若有正则抠到的对已出现 → 用
example_sentences: partial更新 UI。
流结束后仍以 tryParseModelJson 最终结果 为准,保证与模型完整输出一致。
TTS 与 UI
每句英文在合适的时机进入 队列 ,限制并发(如 2 路)调用 BFF TTS,把返回的音频 base64 转成 Blob URL ,供句末小喇叭播放;密钥与火山侧细节均在 server.js。
五、若你要「字段级」严格可控的流式
仅靠「一个 JSON 被慢慢生成」,无法保证 键顺序与字段边界;例句页的正则增量是 特例优化。更通用的工程选项包括:
| 方向 | 说明 |
|---|---|
| NDJSON | 每行一个小 JSON,收到一行 parse 一行 |
| 多轮 / 分步 | 先流式大纲,再单独请求结构化块 |
| tool / schema | 由接口约束结构化输出 |
| BFF 内增量解析 | 上游仍 SSE,BFF 用 partial-json 等库,向前端推「已就绪字段」事件 |
六、小结
- 网络层 :流的是 SSE 行内的包络 JSON ;业务内容在
delta.content的拼接结果里。 - 应用层 :在内存里维护
content,能整段 parse 时再变成对象 ;故事页以整段 parse 为主;例句页 额外 用正则从半段里抽已完成的english/chinese对。 - BFF :浏览器只打自家
/moonshot/...(及例句的/tts/...),Moonshot / 火山密钥在服务端 ;stream: true时server.jsSSE 透传,前端解析逻辑与直连一致。 - 安全 :生产环境请 默认走 BFF;直连 + 页内 Key 仅作本地对照。
参考
- 示例页:故事流式 JSON · 亲子例句流式 JSON + TTS
- BFF 实现:server.js
- 课程专栏:跟月影学前端智能体开发