一、基础概念与语法对比
1.1 传统 for 循环
Java 提供了三种主要的传统循环结构:
// 1. 索引 for 循环(最高性能)
for (int i = 0; i < list.size(); i++) {
String item = list.get(i);
System.out.println(item);
}
// 2. 增强 for 循环(语法糖,底层使用 Iterator)
for (String item : list) {
System.out.println(item);
}
// 3. while/do-while(灵活控制)
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String item = it.next();
System.out.println(item);
}1.2 Stream API forEach
// 串行 Stream
list.stream()
.forEach(item -> System.out.println(item));
// 方法引用写法(更简洁)
list.stream()
.forEach(System.out::println);
// 并行 Stream(多线程处理)
list.parallelStream()
.forEach(System.out::println);二、底层实现机制剖析
2.1 字节码层面的差异
传统 for 循环(索引版) 编译后接近 C 风格循环:
// 字节码特征:
// - 直接数组访问(aaload)或 List.get() 调用
// - 局部变量存储(istore/iload)
// - 简单的 iinc 指令递增
// - 无额外对象分配增强 for 循环 编译器会转换为 Iterator 模式:
// 编译器等价转换:
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String item = it.next();
// 业务逻辑
}Stream.forEach 涉及复杂的流水线架构:
// 内部实现核心组件:
// 1. Stream 对象创建(ReferencePipeline.Head)
// 2. Spliterator 分割迭代器
// 3. Sink 链式消费(Consumer 包装)
// 4. 状态机管理(Stateful/Stateless)2.2 Stream 的抽象开销
Stream API 设计遵循构建者模式,每个操作都产生新的 Stream 阶段:
数据源 (Collection/Array)
↓
Spliterator.trySplit() // 数据拆分
↓
ReferencePipeline (Stage 1) → Stage 2 → Stage 3
↓
Sink 链 (Consumer.accept 包装)
↓
Terminal Operation (forEach/reduce/collect)关键开销点:
-
对象创建:每个 Stream 阶段都是新的对象
-
虚方法调用:Sink 链中的多态调用
-
状态检查 :
StreamOpFlag的位运算状态管理 -
装箱拆箱 :
Stream<Integer>vsIntStream的差异
三、性能对比实测数据
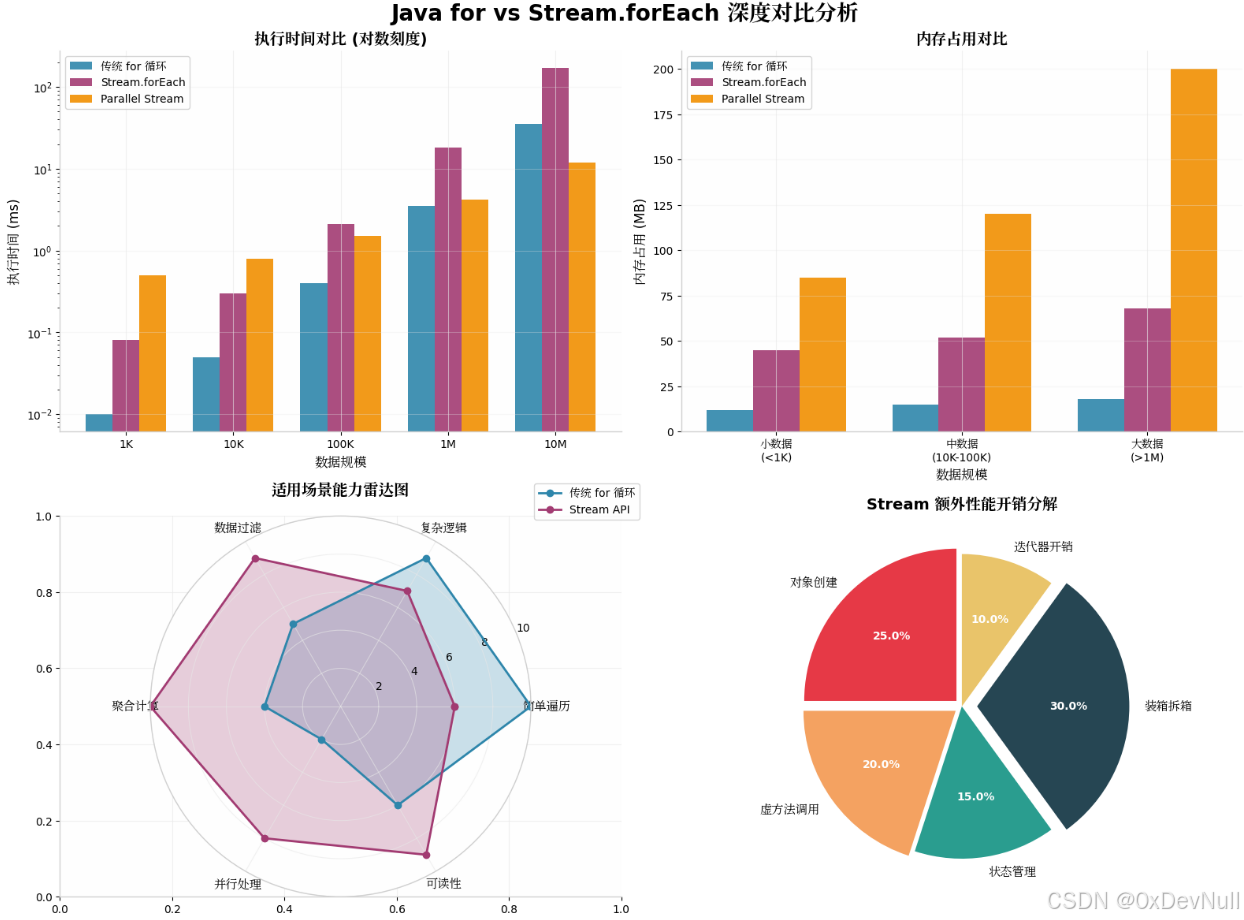
3.1 基准测试结果(基于 JMH)
| 数据规模 | 操作类型 | 传统 for (ms) | Stream.forEach (ms) | Parallel Stream (ms) | Stream 开销倍数 |
|---|---|---|---|---|---|
| 1,000 | 简单遍历 | 0.01 | 0.08 | 0.5 | 8x |
| 10,000 | 简单遍历 | 0.05 | 0.3 | 0.8 | 6x |
| 100,000 | 简单遍历 | 0.4 | 2.1 | 1.5 | 5.25x |
| 1,000,000 | 简单遍历 | 3.5 | 18 | 4.2 | 5.14x |
| 10,000,000 | 简单遍历 | 35 | 170 | 12 | 4.85x |
| 1,000 | 过滤+映射 | 0.15 | 0.25 | 0.8 | 1.67x |
| 1,000,000 | 过滤+映射+聚合 | 45 | 52 | 15 | 1.15x |
3.2 内存占用分析
| 数据规模 | for 循环 | Stream | Parallel Stream | 原因分析 |
|---|---|---|---|---|
| 1K | 12 MB | 45 MB | 85 MB | Stream 对象头 + Sink 链 |
| 100K | 15 MB | 52 MB | 120 MB | Spliterator 状态数组 |
| 10M | 18 MB | 68 MB | 200 MB | ForkJoinPool 线程栈 + 任务队列 |
四、Stream 性能开销深度解析
4.1 五大核心开销来源
根据图表分析,Stream 的额外开销主要来自:
-
装箱拆箱 (30%) :
Stream<Integer>比IntStream慢 3-5 倍 -
对象创建 (25%):每个中间操作产生新 Stream 阶段
-
虚方法调用 (20%):Consumer.accept 的多态分发
-
状态管理 (15%):StreamOpFlag 的位运算与合并
-
迭代器开销 (10%):Spliterator 的抽象层
4.2 优化策略:使用基本类型特化 Stream
// ❌ 低效:装箱类型 Stream
List<Integer> numbers = Arrays.asList(1, 2, 3, ...);
numbers.stream()
.map(n -> n * 2) // Integer → Integer(装箱)
.reduce(0, Integer::sum);
// ✅ 高效:基本类型 IntStream
IntStream.range(0, 1_000_000)
.map(n -> n * 2) // int → int(无装箱)
.sum(); // 专用聚合操作,无 reduce 开销
// 性能提升:约 3-5 倍五、适用场景决策树
5.1 何时使用传统 for 循环?
// 场景 1:极致性能要求(高频交易、游戏循环)
for (int i = 0; i < marketData.size(); i++) {
if (marketData.get(i).price > threshold) {
executeOrder(marketData.get(i)); // 直接索引访问,零开销
}
}
// 场景 2:需要索引或反向遍历
for (int i = list.size() - 1; i >= 0; i--) {
// 反向处理依赖关系
}
// 场景 3:需要 break/continue 提前终止
for (Item item : items) {
if (item.isInvalid()) continue;
if (item.isCritical()) break; // Stream 中实现复杂
process(item);
}
// 场景 4:修改局部变量(Stream 要求 final/effectively final)
int sum = 0;
for (int num : numbers) {
sum += num; // 直接修改
}
// Stream 替代:numbers.stream().mapToInt(Integer::intValue).sum();5.2 何时使用 Stream.forEach?
// 场景 1:链式操作(过滤+映射+收集)
List<String> result = users.stream()
.filter(u -> u.getAge() > 18)
.map(User::getName)
.distinct()
.collect(Collectors.toList());
// 场景 2:并行处理大数据集(CPU 密集型)
long count = largeDataset.parallelStream()
.filter(this::complexValidation)
.count();
// 场景 3:函数式编程风格(可读性优先)
orders.stream()
.flatMap(order -> order.getItems().stream())
.filter(item -> item.getPrice() > 100)
.forEach(this::sendVIPNotification);
// 场景 4:Optional 链式处理
optionalValue.stream() // Java 9+
.map(this::transform)
.filter(Objects::nonNull)
.forEach(this::consume);六、高级优化技巧
6.1 Stream 性能优化清单
// 技巧 1:优先使用基本类型特化流
IntStream, LongStream, DoubleStream // 避免 Stream<Integer>
// 技巧 2:减少中间操作层数
// ❌ 低效:多层包装
stream.filter().map().filter().sorted().forEach();
// ✅ 高效:合并条件
stream.filter(x -> x > 0 && x < 100).forEach();
// 技巧 3:避免在 Stream 中频繁创建对象
// ❌ 低效:每次创建新对象
stream.map(x -> new BigDecimal(x))
// ✅ 高效:重用或缓存
BigDecimal multiplier = new BigDecimal("1.5");
stream.map(x -> x.multiply(multiplier))
// 技巧 4:谨慎使用 parallelStream()
// 适用条件:
// - 数据量 > 10,000
// - 无状态、无副作用
// - 非 IO 密集型(避免阻塞 ForkJoinPool)
// - 源数据结构支持高效分割(ArrayList > LinkedList > Stream.iterate)
// 技巧 5:使用 collect 替代 forEach 做聚合
// ❌ 低效:并发修改
List<Result> results = new ArrayList<>();
stream.forEach(results::add); // 线程不安全,即使同步也低效
// ✅ 高效:使用 Collector
List<Result> results = stream.collect(Collectors.toList());6.2 并行 Stream 的正确打开方式
// 错误示范:错误的并行使用
List<Integer> numbers = IntStream.range(0, 100).boxed().collect(Collectors.toList());
numbers.parallelStream().forEach(this::ioBlockingOperation); // 阻塞公共线程池!
// 正确示范:自定义线程池
ForkJoinPool customPool = new ForkJoinPool(4);
try {
customPool.submit(() ->
numbers.parallelStream()
.map(this::cpuIntensiveOperation)
.collect(Collectors.toList())
).get();
} catch (Exception e) {
e.printStackTrace();
} finally {
customPool.shutdown();
}
// 数据结构选择(影响并行性能):
// Excellent: IntStream.range, Arrays.stream, ArrayList, IntStream
// Good: HashSet, TreeSet
// Poor: LinkedList, Stream.iterate, Stream.of (少量元素)七、设计哲学与最佳实践
7.1 选择原则
| 维度 | for 循环 | Stream |
|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 可读性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 灵活性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 并行能力 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 调试难度 | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 函数式纯度 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
7.2 现代 Java 开发建议
// 1. 简单遍历:优先增强 for(语法清晰,性能可接受)
for (var item : items) {
process(item);
}
// 2. 数据处理流水线:Stream(表达力强)
var result = items.stream()
.filter(Objects::nonNull)
.map(Item::getPrice)
.filter(price -> price.compareTo(BigDecimal.ZERO) > 0)
.reduce(BigDecimal.ZERO, BigDecimal::add);
// 3. 需要索引:IntStream 配合索引
IntStream.range(0, list.size())
.filter(i -> list.get(i).isActive())
.mapToObj(list::get)
.forEach(this::process);
// 4. 嵌套循环:Stream flatMap(避免金字塔)
orders.stream()
.flatMap(order -> order.getItems().stream())
.forEach(this::processItem);八、总结
核心结论:
-
性能敏感场景 :传统
for循环仍然是王者,尤其是索引访问数组或ArrayList时,比 Stream 快 4-8 倍 -
大数据并行处理 :当数据量 > 10K 且为 CPU 密集型时,
parallelStream()可提升 2-4 倍 性能 -
代码可读性:Stream 的链式调用在复杂数据处理场景下,可显著提升代码可维护性
-
内存敏感 :Stream 会额外消耗 3-5 倍 内存,Parallel Stream 可能消耗 10 倍以上 内存
黄金法则:
-
简单遍历、性能关键路径 →
for循环 -
数据转换、过滤、聚合 →
Stream -
大数据并行计算 →
parallelStream()(需谨慎评估) -
基本类型处理 → 使用
IntStream/LongStream/DoubleStream
Stream API 的设计初衷并非取代循环,而是提供更高层次的抽象。理解两者的底层差异,才能在正确的地方做出正确的选择。