一、面试题目
请详细解释什么是大模型的 上下文窗口(Context Window)限制?从工程实践角度看,目前业界应对这个限制的主流解决方法有哪些?它们各自的适用场景是什么?
二、知识储备
1. 核心背景:什么是上下文窗口限制?
大模型就像一个"正在考试的学生",上下文窗口 就是他面前那张 "草稿纸的大小"。
① 物理定义: 模型在单次推理过程中能够同时处理的最大 Token 数量。
② 痛点:
- 遗忘问题: 一旦对话或文档超过这个长度,模型就必须"丢掉"最前面的信息(草稿纸写满了)。
- 计算爆炸: 由于 Self-Attention 的复杂度是
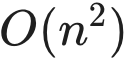 ,窗口越大,计算量和显存占用呈指数级增长。
,窗口越大,计算量和显存占用呈指数级增长。
2. 主流解决方法:如何"无限"延长草稿纸?
目前业界主要通过以下四种路径来突破限制:
① 检索增强生成 (RAG):
- 逻辑: 不把所有资料塞给模型,而是只在需要时去"查书"。
- 作用: 理论上能处理无限大的外部知识库,只提取最相关的片段放入窗口。
② 滑动窗口与摘要 (Sliding Window & Summarization):
- 逻辑: 像处理流水线一样,把前面的旧对话总结成一小段"摘要",带着摘要继续聊。
- 作用: 适合长对话,保留核心记忆,舍弃细节。
③ 架构优化 (Long-Context Models):
- 逻辑: 从底层改进。如 Flash Attention (减少显存开销)、RoPE(旋转位置编码)。
- 作用: 让模型原生支持百万级(1M+)Token,如 Gemini 1.5 Pro。
④ KV Cache 管理 (PagedAttention):
- 逻辑: 像操作系统管理内存分页一样管理显存,极大提升长文本下的推理效率。
三、代码实现
1. Python 实现:利用 LangChain 模拟滑动窗口摘要
在 Python 中,我们常在应用层手动"修剪"上下文。
python
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import ChatOpenAI
# 1. [Harness 思想]:定义最大 Token 限制,超出则触发自动摘要
llm = ChatOpenAI(model="gpt-4")
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=1000)
# 2. 模拟对话:当对话过长,Harness 逻辑会自动总结旧信息
memory.save_context({"input": "你好,我想聊聊 Node.js"}, {"output": "没问题"})
# 自动通过摘要压缩上下文,释放窗口空间
context = memory.load_memory_variables({})2. Node.js 实现:模拟 RAG 模式下的上下文注入
Node.js 适合处理高并发的检索流。
javascript
async function ragContextEngine(userQuery, bigDoc) {
// 1. 发现文档太大,直接丢给模型会触发 Context Window 限制
if (bigDoc.length > 100000) {
// 2. [RAG 逻辑]:切片并检索
const relevantChunks = await vectorStore.search(userQuery);
// 3. [Harness 控制]:只拼接最相关的 3 个片段,确保不爆窗口
const prompt = `背景信息: ${relevantChunks.join("\n")}\n问题: ${userQuery}`;
return await llm.call(prompt);
}
return await llm.call(bigDoc + userQuery);
}四、破局之道
在回答完方案后,通过这段话展现你对 "成本与性能平衡" 的架构思考:
你可以告诉面试官:回答上下文窗口限制,核心要理解 "数据价值密度"。
在工程落地时,我不会盲目追求"长窗口模型",因为那意味着更高的成本和更慢的响应。我会优先采用 RAG(检索) 解决知识广度问题,采用 Summary(摘要) 解决逻辑深度问题,并辅以 PagedAttention 优化性能。一个优秀的架构师,应该在有限的窗口内,通过精准的上下文工程(Context Engineering),让模型看到最有价值的信息。