atcoder abc 454
A - Closed interval
问题陈述
你得到整数 LLL 和 RRR 。
找出在 LLL 和 RRR 之间有多少个整数。
解题思路
大水题,用减法或者枚举都可以求解答案,直接输出即可。
代码
cpp
#include <bits/stdc++.h>
using namespace std;
int main()
{
int l, r;
cin >> l >> r;
cout << r - l + 1 << '\n';
return 0;
}B - Mapping
问题陈述
编号为 111 到 NNN 的人有 NNN 。
编号为 111 到 MMM 的衣服有 MMM 种。人 iii 穿的衣服 FiF_iFi 。
用 Yes 或 No 回答以下两个问题。
问题 111 :所有的 NNN 人都穿着不同类型的衣服吗?
问题 222 :对于每一种 MMM 类型的衣服,是否至少有一个人穿着该类型的衣服?
解题思路
开辟一个数组,记录每一种衣服是否出现过。接下来维护出现过的衣服种类数量即可,具体实现看代码。
代码
cpp
#include <bits/stdc++.h>
using namespace std;
int n, m, vis[105]; // vis数组标记某类衣服是否出现过,大小为105以容纳最多100种衣服
int main()
{
cin >> n >> m;
int f1, f2, cnt = 0; // f1表示问题1的答案,f2表示问题2的答案,cnt记录不同衣服种类的数量
f1 = f2 = 1; // 先假设两个问题的答案都是Yes(1表示Yes,0表示No)
for (int i = 1; i <= n; i++)
{
int x; // 第i个人穿的衣服类型编号
cin >> x;
if (!vis[x]) // 如果这种衣服之前没出现过
vis[x] = 1, cnt++; // 标记为已出现,不同种类数+1
else
f1 = 0; // 出现重复衣服 → 问题1答案为No(不是所有人都穿不同类型)
}
if (cnt != m) // 如果收集到的衣服种类数不等于总种类数M
f2 = 0; // 问题2答案为No(存在某种衣服没人穿)
// 输出问题1的答案
if (f1)
cout << "Yes\n";
else
cout << "No\n";
// 输出问题2的答案
if (f2)
cout << "Yes\n";
else
cout << "No\n";
return 0;
}C - Straw Millionaire
问题描述
有 NNN 种物品,编号为物品 111 到物品 NNN。初始时,高桥只有物品 111。
他有 MMM 个朋友。对于第 iii 个朋友(1≤i≤M1 \le i \le M1≤i≤M),如果高桥把物品 AiA_iAi 送给这个朋友,他就会获得物品 BiB_iBi。
求高桥能获得的物品种类数(包括初始就有的物品 111)。
解题思路
首先转换问题模型,一个朋友可以把物品 AiA_iAi 换成 BiB_iBi 就相当于在 AiA_iAi 和 BiB_iBi 之间连了一条单向边,从 1 号点出发,看看可以抵达哪些点就可以了。
代码
cpp
#include <bits/stdc++.h>
using namespace std;
const int maxn = 3e5 + 5;
int n, m, vis[maxn], ans; // vis标记某个物品是否已获得,ans记录能获得的物品种类数
vector<int> e[maxn]; // 邻接表存储交换关系:e[u] 表示送出物品u后能获得的所有物品
// 深度优先搜索:从物品x出发,收集所有能间接获得的物品
void dfs(int x)
{
if (vis[x]) // 如果这个物品已经获得过了,不再重复处理
return;
vis[x] = 1; // 标记物品x为已获得
ans++; // 物品种类数加1
// 遍历所有从x出发能直接换到的物品
for (int i = 0; i < e[x].size(); i++)
dfs(e[x][i]); // 递归获得这些物品后,还能继续换其他物品
}
int main()
{
cin >> n >> m;
// 读入M条交换规则
for (int i = 1; i <= m; i++)
{
int u, v;
cin >> u >> v;
e[u].push_back(v); // 送出物品u,可获得物品v(有向边 u -> v)
}
dfs(1); // 从初始拥有的物品1开始搜索
cout << ans; // 输出最终能获得的物品种类数(包括物品1本身)
return 0;
}D - (xx)
问题描述
给你一个由 (, x, ) 组成的字符串 AAA。
你可以对 AAA 进行任意多次以下两种操作,顺序不限:
- 选择 AAA 中的一个子串
(xx),并将其替换为xx。 - 选择 AAA 中的一个子串
xx,并将其替换为(xx)。
再给你一个由 (, x, ) 组成的字符串 BBB。请判断能否通过若干次操作将 AAA 变成 BBB。
共有 TTT 组测试数据,请对每组数据进行判断。
解题思路
可以把题目理解为,只要有 xx 就可以在他们的两边加/删括号,我们尽可能删除 A 和 B 里面所有的括号,如果删除之后两个字符串一样,就说明可以转换。
具体实现看代码。
代码
cpp
#include <bits/stdc++.h>
using namespace std;
const int maxn = 2e6 + 5;
string A, B;
int vis_A[maxn], vis_B[maxn]; // 标记可删除的括号(即被 xx 包裹的括号)
bool solve()
{
cin >> A >> B;
// 处理字符串 A:找到所有 "xx" 并尝试向两边扩展匹配 '(' 和 ')'
for (int i = 0; i < A.size() - 1; i++)
{
// 找到连续的 "xx"
if (A[i] == A[i + 1] && A[i] == 'x')
{
int l = i - 1, r = i + 2; // 左右各扩展一位,形成 "(xx)"
// 尝试不断向外扩展,只要外层是 '(' 和 ')' 就标记这对括号为可删除
while (l >= 0 && r < A.size() && A[l] == '(' && A[r] == ')')
vis_A[l--] = 1, vis_A[r++] = 1; // 标记这对括号
}
}
// 对字符串 B 做完全相同处理
for (int i = 0; i < B.size() - 1; i++)
{
if (B[i] == B[i + 1] && B[i] == 'x')
{
int l = i - 1, r = i + 2;
while (l >= 0 && r < B.size() && B[l] == '(' && B[r] == ')')
vis_B[l--] = 1, vis_B[r++] = 1;
}
}
// 跳过所有被标记为可删除的括号,比较剩下的字符是否相同
int i = 0, j = 0;
while (i < A.size() && j < B.size())
{
// 跳过 A 中要删除的括号
while (i < A.size() && vis_A[i])
i++;
// 跳过 B 中要删除的括号
while (j < B.size() && vis_B[j])
j++;
if (i >= A.size() || j >= B.size())
break;
// 如果剩余字符不同,则不可转换
if (A[i] != B[j])
{
// 清空标记数组(防止下一组测试干扰)
for (int k = 0; k < A.size(); k++) vis_A[k] = 0;
for (int k = 0; k < B.size(); k++) vis_B[k] = 0;
return false;
}
i++, j++;
}
// 跳过末尾可能剩余的标记括号
while (i < A.size() && vis_A[i]) i++;
while (j < B.size() && vis_B[j]) j++;
// 清空标记数组
for (int k = 0; k < A.size(); k++) vis_A[k] = 0;
for (int k = 0; k < B.size(); k++) vis_B[k] = 0;
// 两个字符串都被完全匹配(剩余部分相同且无未匹配字符)
return (i == A.size() && j == B.size());
}
int main()
{
int t;
cin >> t;
while (t--)
{
if (solve())
cout << "Yes\n";
else
cout << "No\n";
}
return 0;
}E - LRUD Moving
问题描述
给定正整数 N,A,BN, A, BN,A,B。保证 (A) 和 (B) 都在 (1) 到 (N) 之间(包含)。
有一个 N×NN \times NN×N 的网格。从上数第 iii 行、从左数第 jjj 列的格子记为 (i,j)(i, j)(i,j)。初始时,一个棋子放在格子 (1,1)(1, 1)(1,1) 上。
通过重复 N2−2N^2 - 2N2−2 次移动,每次将棋子移动到相邻的格子(上、下、左、右),你希望让棋子最终到达格子 (N,N)(N, N)(N,N),并且在此过程中要经过除 (A,B)(A, B)(A,B) 以外的所有格子。你不能重复访问同一个格子(中途也不能访问 (1,1)(1, 1)(1,1) 和 (N,N)(N, N)(N,N) 之外的格子多次)。
判断是否存在这样的移动序列。如果存在,请输出其中一种。
一共有 TTT 组测试数据,你需要对每组数据进行求解。
解题思路
首先我们可以把所有的格子进行分类(应该所有人都会吧),(i+j)(i + j)(i+j) 为奇数的话我们就把他染成黑色格子,否则就是白色格子,在移动的过程当中按照 白 -> 黑 -> 白 -> 黑 ... 这样的顺序进行移动。
如果 NNN 为奇数,那么 N2−2N^2 - 2N2−2 也为奇数,又因为 (1,1)(1, 1)(1,1) 和 (N,N)(N, N)(N,N) 同色,所以不存在合法的方案。接下来我们再来看一下 aaa 和 bbb,对结果的影响,如果 a+ba + ba+b 为偶数,那么此时整个棋盘上的格子 (i,j)(i, j)(i,j) 为偶数的数量小于奇数的数量,但是实际上应该是偶数比奇数多一个(因为起点和终点都是偶数),所以 (a+b)(a + b)(a+b) 必须为奇数。
剩下的就是构造的问题了,我们要想出一个方法找路径。
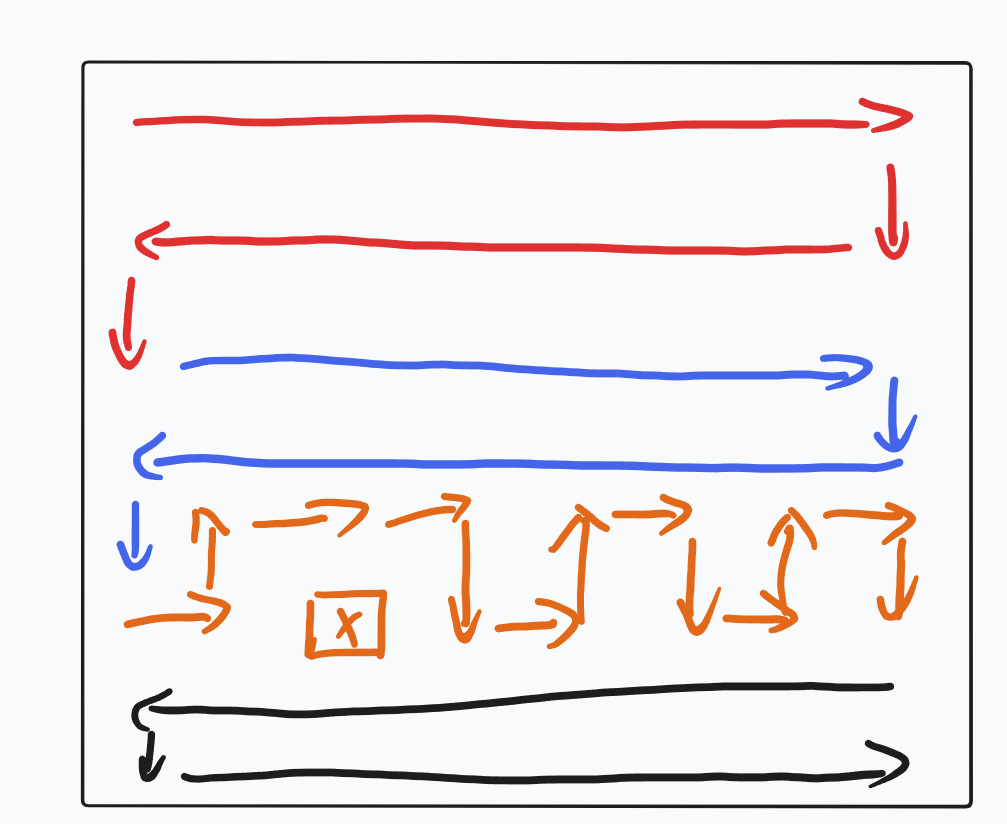
因为此时 nnn 为偶数,所以我们直接两行两行的处理,先从左到右,再从右到左,直到遇到有障碍物的两行,变成上下移动去绕开障碍物,后面我们就变成从右往左,再从左往右就好了,最终保证可以到达 (n,n)(n, n)(n,n)。
代码
cpp
#include <algorithm>
#include <cassert>
#include <iostream>
#include <vector>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
int T;
cin >> T;
while (T--)
{
int n, a, b;
cin >> n >> a >> b;
a--; // 转换为0-based索引,方便奇偶判断
b--;
// 不可行条件:
// 1. n为奇数时,起点(0,0)和终点(n-1,n-1)同色,去掉一个格子后奇偶性不匹配
// 2. (a+b)偶,即障碍物与起点同色,也会破坏哈密顿路径的二分图平衡
if (n % 2 == 1 || (a + b) % 2 == 0)
{
cout << "No\n";
continue;
}
vector<string> s1, s2; // s1存储前半部分路径,s2存储后半部分(待反转)
// 第一阶段:处理行方向的大循环(上下移动)
// 共n/2 - 1个完整的"蛇形"行对
for (int i = 0; i < n / 2 - 1; ++i)
{
// 标准行扫描模式:向右走n-1步,向下1步,向左n-1步,向下1步
string s;
s += string(n - 1, 'R'); // 向右到底
s += 'D'; // 向下
s += string(n - 1, 'L'); // 向左到底
s += 'D'; // 再向下
// 根据障碍物a(行坐标)决定将这段路径放入s1还是s2
if (a >= 2)
{
s1.push_back(s); // 障碍物还在后面,正常加入
a -= 2; // 已经处理了两行,减少a的相对位置
}
else
{
// 障碍物即将出现在接下来的两行中,需要反转这段路径
reverse(s.begin(), s.end());
s2.push_back(s); // 放入后半部分,之后会整体反转
}
}
// 第二阶段:处理列方向的小循环(左右微调),用于避开障碍物(b)
for (int i = 0; i < n / 2 - 1; ++i)
{
// 小菱形绕行模式:下、右、上、右
string s = "DRUR";
if (b >= 2)
{
s1.push_back(s); // 正常加入
b -= 2; // 已处理两列
}
else
{
reverse(s.begin(), s.end());
s2.push_back(s);
}
}
// 此时a和b应只剩下(0,1)或(1,0)的情况(即障碍物在最后需要微调的位置)
assert((a == 0 && b == 1) || (a == 1 && b == 0));
// 最后两步处理:根据障碍物相对位置决定最后绕行方向
if (a == 0 && b == 1)
{
s1.push_back("DR"); // 先下后右
}
else
{
s1.push_back("RD"); // 先右后下
}
// 构建最终答案
string ans;
for (auto &x : s1)
ans += x; // 前半部分正序
reverse(s2.begin(), s2.end()); // 反转后半部分的顺序
for (auto &x : s2)
ans += x; // 后半部分加入(相当于整体路径的后半段)
cout << "Yes\n" << ans << '\n';
}
return 0;
}F - Make it Palindrome 2
问题描述
给定一个正整数 NNN 、一个正整数 MMM 和一个长度为 NNN 的整数序列 A=(A1,A2,...,AN)A=(A_1,A_2,\dots,A_N)A=(A1,A2,...,AN) 。
保证 AAA 的每个元素都在 000 和 M−1M-1M−1 之间。
您可以对整数序列 AAA 执行以下操作,次数不限,可能为零:
---选择一对满足 1≤l≤r≤N1\le l\le r\le N1≤l≤r≤N 的整数 (l,r)(l,r)(l,r) ,每个 i=l,l+1,...,ri=l,l+1,\ldots,ri=l,l+1,...,r 用 (Ai+1) mod M(A_{i+1}) \bmod M(Ai+1)modM 替换 AiA_iAi 。
求生成 AAA 一个回文所需的最小运算次数。
这里,如果 Ai=AN+1−iA_i=A_{N+1-i}Ai=AN+1−i ,i=1,2,...,Ni=1,2,\ldots,Ni=1,2,...,N ,则 AAA 是回文。
给你 TTT 测试用例;每个都解出来。
解题思路
在 A 的基础上我们定义一个新的数组 B,令 Bi=Ai−An−i+1,i∈1,n/2B_i = A_i - A_{n - i + 1},i \in 1, n / 2Bi=Ai−An−i+1,i∈1,n/2,通过贪心我们也可以得出,修改的区间不可能跨越中间,所以我们只用考虑前一半就可以了。
现在问题变成了,每一次我们都可以选择一个区间,让里面的元素全部加一或者减一,直到全部变成 0 位置,这个操作我们自然而然可以选择差分来完成。
所以我们就有了 Ci=Bi−Bi−1,i∈1,n/2,Cn/2+1=0−Bn/2C_i = B_i - B_{i-1}, i \in 1, n / 2, C_{n / 2 + 1} = 0 - Bn / 2Ci=Bi−Bi−1,i∈1,n/2,Cn/2+1=0−Bn/2。
现在问题就变成了,我们可以让 C 里面的元素一个加一,一个减一,最终所有元素之和为 0,而且加一减一不会应该元素和模 m 的值,所以一开始的时候所有的 C 加起来一定是 m 的倍数。
假设我们让前 k 个最小的元素减一,剩下的加一,知道全部模 m 等于 0 为止。
这里我们令所有的 C 加起来为 S,前 k 个元素和为 X,那么就有了下面的公式:
X=(n/2+1−k)⋅m−S+X(n/2+1−k)⋅m−S=0k=n/2+1−S/mX = (n / 2 + 1 - k)·m - S + X \\ (n / 2 + 1 - k)·m - S = 0 \\ k = n / 2 + 1 - S / mX=(n/2+1−k)⋅m−S+X(n/2+1−k)⋅m−S=0k=n/2+1−S/m
然后计算前 k 个最小的元素之和是多少,然后输出即可。
代码
cpp
#include <bits/stdc++.h>
#define int long long // 防止中间计算溢出
using namespace std;
const int maxn = 2e5 + 5;
int A[maxn], B[maxn], C[maxn], n, m;
void solve()
{
cin >> n >> m;
// 读入原始数组 A
for (int i = 1; i <= n; i++)
cin >> A[i];
// 步骤1:计算每一对对称位置变成相同所需的最小"向前增加量"
// 操作是区间每个元素 +1 (mod m),所以 B[i] 表示 A[i] 要变成 A[n-i+1] 需要整体加多少 (mod m)
// 这里计算 (A[i] - A[n-i+1] + m) % m 是因为我们只关心"加多少次"而不是"减多少次"
// 因为操作只能增加 (mod m)
for (int i = 1; i <= n / 2; i++)
B[i] = (A[i] - A[n - i + 1] + m) % m;
// 步骤2:差分,为了把"区间加"操作转化成"单点加"的约束
// C[i] = B[i] - B[i-1] (mod m)
// 这样,对原数组的区间加操作,在差分数组上表现为修改两个端点
int S = 0;
for (int i = 1; i <= n / 2; i++)
C[i] = (B[i] - B[i - 1] + m) % m, S += C[i];
// 步骤3:闭合成环
// 因为差分数组的总和必须为 0 (mod m),这里补上最后一个差值,让总和是 m 的倍数
C[n / 2 + 1] = (m - B[n / 2]) % m, S += C[n / 2 + 1];
// 步骤4:排序,贪心选择
// 我们可以让某些 C[i] 增加 m,这样整体操作次数不变(因为模 m 意义下相同),但可以减少"实际加法次数"
// 因为操作是整体区间 +1,相当于我们可以"跳过"某些整圈的加法
// S / m 表示有多少个整圈的 m 可以被"吸收"
sort(C + 1, C + n / 2 + 2);
// k 是我们必须保留的最小操作次数(即最后答案中会累加的最小几个 C[i])
int k = n / 2 + 1 - S / m;
int ans = 0;
for (int i = 1; i <= k; i++)
ans += C[i];
cout << ans << '\n';
}
signed main()
{
int T;
cin >> T;
while (T--)
{
solve();
}
return 0;
}G - Mode in the Subtree
问题描述
给定一棵有根树,包含 (N) 个顶点,编号为 (1) 到 (N)。顶点 (1) 是根,顶点 (i) 的父节点是 pi(满足pi<i)p_i (满足 p_i < i)pi(满足pi<i)。
每个顶点都有颜色:顶点 (i) 的颜色为 ci(1≤ci≤N)c_i(1 \le c_i \le N)ci(1≤ci≤N)。
对于每个 v=1,2,...,Nv = 1, 2, \dots, Nv=1,2,...,N,解决以下问题:
设 fif_ifi 表示以顶点 vvv 为根的子树中,颜色为 iii 的顶点个数。
求:
- 序列 (f1,f2,...,fN)(f_1, f_2, \dots, f_N)(f1,f2,...,fN) 中的最大值 mmm,以及
- 满足 fi=mf_i = mfi=m 的正整数 i(i≤N)i(i \le N)i(i≤N)的个数 kkk。
解题思路
树上启发式合并,板子题不想多说了,维护每个颜色出现次数,出现次数为 ...\dots... 的颜色有多少种,当前最大出现次数。
代码
cpp
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn = 2.5e6 + 5; // 最大节点数
int N, M, F;
unsigned int state; // 随机数生成器的状态
int Q[maxn], D[maxn]; // 存储输入的前 M 个父节点和颜色
vector<int> g[maxn]; // 邻接表,存树的孩子
int C[maxn]; // 每个节点的颜色(0-based)
int sub[maxn]; // 子树大小
int euler[maxn], down[maxn], up[maxn], idx; // DFS序相关
int stk[maxn * 2], top; // 非递归DFS用的栈
int cnt[maxn], freq[maxn], mx; // cnt[col]=颜色出现次数, freq[x]=出现次数为x的颜色数, mx=当前最大出现次数
ll ans; // 最终答案(取模)
// 预处理子树大小,并将重儿子放在 g[c][0] 位置(用于启发式合并)
void dfs_size(int c)
{
sub[c] = 1;
for (int i = 0; i < (int)g[c].size(); i++)
{
int d = g[c][i];
dfs_size(d);
sub[c] += sub[d];
// 重儿子:子树最大的儿子,交换到第一个位置
if (sub[d] > sub[g[c][0]])
swap(g[c][i], g[c][0]);
}
}
// 非递归计算欧拉序,同时得到每个子树的区间 [down[c], up[c])
void dfs_order()
{
idx = 0; top = 0;
stk[top++] = ~0; // 哨兵:负数表示子树结束标记
stk[top++] = 0; // 从根节点0开始
while (top)
{
int c = stk[--top];
if (c >= 0) // 进入节点
{
euler[idx] = c;
down[c] = idx++;
// 孩子倒序入栈,保证处理顺序
for (int i = (int)g[c].size() - 1; i >= 0; i--)
{
stk[top++] = ~g[c][i]; // 结束标记
stk[top++] = g[c][i]; // 孩子节点
}
}
else // 离开节点
{
up[~c] = idx; // 子树区间右端点(开区间)
}
}
}
// 添加节点 c 的颜色到当前统计中
void add(int c)
{
int col = C[c];
freq[cnt[col]]--; // 原出现次数的颜色数减1
cnt[col]++; // 该颜色出现次数+1
freq[cnt[col]]++; // 新出现次数的颜色数加1
if (cnt[col] > mx) // 更新最大值
mx = cnt[col];
}
// 对节点 c 的子树进行查询,并累加到 ans
void query(int c)
{
ll a = mx ^ (c + 1); // 题目要求的变换1
ll b = freq[mx] ^ (c + 1); // 题目要求的变换2
ans = (ans + a * b) % 998244353;
}
// 清空节点 c 的子树信息(用于轻儿子)
void reset(int c)
{
for (int i = down[c]; i < up[c]; i++)
{
int col = C[euler[i]];
cnt[col] = 0;
}
for (int i = 0; i <= mx; i++)
freq[i] = 0;
mx = 0;
}
// DSU on tree(树上启发式合并)
void dsu(int c)
{
// 先处理所有轻儿子(不保留信息)
for (int i = 1; i < (int)g[c].size(); i++)
{
dsu(g[c][i]);
reset(g[c][i]); // 清空轻儿子的统计
}
// 处理重儿子(保留信息)
if (!g[c].empty())
{
dsu(g[c][0]); // 重儿子递归
// 把重儿子子树中除了重儿子本身以外的节点加进来
for (int i = up[g[c][0]]; i < up[c]; i++)
add(euler[i]);
}
add(c); // 加上当前节点
query(c); // 计算当前子树的答案
}
int main()
{
scanf("%d%u%d%d", &N, &state, &M, &F);
// 读取前 M 个父节点信息
for (int i = 2; i <= M; i++) scanf("%d", &Q[i]);
// 读取前 M 个颜色信息
for (int i = 1; i <= M; i++) scanf("%d", &D[i]);
// 构建树(节点编号从0开始)
for (int i = 2; i <= N; i++)
{
int p;
if (i <= M)
p = Q[i] - 1; // 直接使用输入
else
{
p = state % (i - 1); // 随机生成父节点
state = (state * 1103515245u + 12345u) % 2147483648u;
}
g[p].push_back(i - 1); // 添加边 p -> i-1
}
// 给节点赋值颜色(0-based)
for (int i = 1; i <= N; i++)
{
if (i <= M)
C[i - 1] = D[i] - 1;
else
{
C[i - 1] = state % F;
state = (state * 1103515245u + 12345u) % 2147483648u;
}
}
dfs_size(0); // 计算子树大小,找重儿子
dfs_order(); // 计算欧拉序
dsu(0); // 开始 DSU on tree
printf("%lld\n", ans);
return 0;
}