2.概述
算法原理
OpenCV(Open Source Computer Vision Library)是一个开源的机器视觉和机器学习软件库。1999年由英特尔公司发起,旨在为计算机视觉与人工智能领域提供通用函数库。
1.1 OpenCV的基本数据类型
OpenCV中的数据类型可分为三大类:
- 基本数据类型:直接由C++数据类型组装而来,包括向量、矩阵、点、矩形、尺寸等
- 助手对象:表示更抽象的概念,如垃圾收集指针类、范围对象等
- 大型数组类型 :典型代表是
cv::Mat类,用于表示任意维度的数组
1.2 核心数据类型
| 类名 | 用途 | 示例 |
|---|---|---|
cv::Vec |
固定长度的向量 | cv::Vec3f 表示3通道浮点向量 |
cv::Point |
点类容器 | cv::Point2i, cv::Point3f |
cv::Scalar |
四维双精度向量 | 用于表示颜色(B,G,R,Alpha) |
cv::Size |
尺寸类 | cv::Size2f |
cv::Rect |
矩形类 | (x, y, width, height) |
cv::RotatedRect |
有向矩形 | (center, size, angle) |
cv::Mat |
N维稠密数组 | 图像表示的核心类 |
1.2.1 数据类型概述
OpenCV设计了许多种数据类型,让计算机视觉和机器学习任务变得更加简单、直观。本节介绍OpenCV中的三类主要数据类型,以及操作这些数据的基本函数。
OpenCV中的数据类型可分为三大类:
-
基本数据类型:该类型直接由C++的数据类型(int或float等)组装而来,包括简单的向量和矩阵,以及简单的几何表示,如点、矩形和尺寸等。
-
助手对象:这些对象表示更抽象的概念,如垃圾收集指针类等,用于表示切片的范围对象,以及对某些算法终止条件的抽象等。
-
大型数组类型:该类型包含数组和其他常见的基本数据类型。大型数组类型的典型代表是cv::Mat类,用于表示包括任意基本元素的任意维度的数组。cv::Mat类的一个专门用途就是表示图像。
1.2.2 cv::Vec类
1.2.2.1基本概念
cv::Vec类可用来表示固定长度的向量(又称为固定向量类),是一个模板类,常使用\[\]来访问Vec向量成员,主要用来存储数值向量。除cv::Vec类外,还有固定维度的向量类cv::Matx。
cv::Matx类可用来处理固定大小的小维度矩阵运算。在计算机视觉中,有许多2×2、3×3和少量4×4的矩阵,以及用于各类变换的矩阵,都可以使用cv::Matx类来表示。值得注意的是,无论cv::Vec类,还是cv::Matx类,在编译时都需要知道变量的长度,这使得计算变得十分高效。
1.2.2.2 用法
- cv::Vec可以定义任意类型的向量:
cpp
cv::Vec<double, 3> myVector; //定义一个存放3个double型变量的向量
cv::Vec3d v3d(x0, x1, x2);- cv::Mat类的基本运算
cpp
// 矩阵基本运算
m0 + m1, m0 - m1 // 矩阵加减法
s * m0, m0 * s // 矩阵与数相乘
m0.mul(m1) // 矩阵对应元素相乘
m0 * m1 // 矩阵相乘
m0.inv() // 矩阵求逆
m0.t() // 矩阵转置
m0 > m1, m0 == m1 // 逐元素比较- cv::Vec类也可以使用以下预定义的类型:
cpp
- typedef cv::Vec<uchar, 2> Vec2b;
typedef cv::Vec<uchar, 3> Vec3b;
typedef cv::Vec<uchar, 4> Vec4b;
typedef cv::Vec<short, 2> Vec2s;
typedef cv::Vec<short, 3> Vec3s;
typedef cv::Vec<short, 4> Vec4s;
typedef cv::Vec<int, 2> Vec2i;
typedef cv::Vec<int, 3> Vec3i;
typedef cv::Vec<int, 4> Vec4i;
typedef cv::Vec<float, 2> Vec2f;
typedef cv::Vec<float, 3> Vec3f;
typedef cv::Vec<float, 4> Vec4f;
typedef cv::Vec<float, 6> Vec6f;
typedef cv::Vec<double, 2> Vec2d;
typedef cv::Vec<double, 3> Vec3d;
typedef cv::Vec<double, 4> Vec4d;
typedef cv::Vec<double, 6> Vec6d;- 支持的运算如下:
cpp
v1 = v2 + v3
v1 = v2 - v3
v1 = v2 * scale
v1 = scale * v2
v1 = -v2
v1 += v2
v1 -= v2, v1 != v2
norm(v1) (euclidean norm)1.2.2.3 示例代码
cpp
#include "stdafx.h"
#include "opencv.hpp"
using namespace std;
int main()
{
//定义与初始化
cv::Vec<int,3> myVec;
for (int i = 0; i < 3; i++)
myVec[i] = i;
cv::Vec3i v3i(0, 1, 2);
cv::Vec2d v2d(1.2, 2.4);
cv::Vec2d v2d_1(v2d);
//访问下标
cout << " myVec[0] = " << myVec[0] << endl;
cout << " myVec[1] = " << myVec[1] << endl;
cout << " myVec[2] = " << myVec[2] << endl << endl;
cout << " v3i[0] = " << v3i[0] << endl;
cout << " v3i[1] = " << v3i[1] << endl;
cout << " v3i[2] = " << v3i[2] << endl << endl;
cout << " v2d[0] = " << v2d[0] << endl;
cout << " v2d[1] = " << v2d[1] << endl << endl;
cout << " v2d_1(0) = " << v2d_1(0) << endl; //[]与()都能访问
cout << " v2d_1(1) = " << v2d_1(1) << endl << endl;
//计算
cv::Vec3f v1(1, 0, 0);
cv::Vec3f v2(1, 1, 0);
cv::Vec3f v3;
cout << " v1 = " << v1 << endl;
cout << " v2 = " << v2 << endl;
cout << " v1·v2 = " << v1.dot(v2) << endl; //点积
cout << " v1×v2 = " << v1.cross(v2) << endl; //叉积
cout << " v1 + v2 = " << v1 + v2 << endl; //加
cout << " v1 - v2 = " << v1 - v2 << endl; //减
cout << " v1 * 2 = " << v1*2 << endl; //乘标量
cout << " (v1 == v2) = " << (v1 == v2) << endl;
cout << " (v1 != v2) = " << (v1 != v2) << endl;
cout << " (v1+=v2) = " << (v1 += v2) << endl << endl;
system("PAUSE");
return 0;
}cv:Vec类的初始化与基本运算
2.基本图像操作
2.1 颜色空间转换
RGB空间 :基于笛卡儿坐标系的三原色模型,OpenCV默认通道顺序为BGR
HSI空间 (色调、饱和度、亮度):
H={θ,B⩽G360−θ,B>GH=\begin{cases} \theta, & B \leqslant G \\ 360-\theta, & B > G \end{cases}H={θ,360−θ,B⩽GB>G
S=1−3(R+G+B)min(R,G,B)S=1-\frac{3}{(R+G+B)}\\min(R,G,B)S=1−(R+G+B)3min(R,G,B)
I=13(R+G+B)I=\frac{1}{3}(R+G+B)I=31(R+G+B)
灰度空间 :
Y=0.299×R+0.587×G+0.114×BY=0.299\times R+0.587\times G+0.114\times BY=0.299×R+0.587×G+0.114×B
2.2 仿射变换
仿射变换的一般形式:
xy1=vw1t11t120t21t220t31t321\begin{bmatrix} x \\ y \\ 1 \end{bmatrix} = \begin{bmatrix} v \\ w \\ 1 \end{bmatrix} \begin{bmatrix} t_{11} & t_{12} & 0 \\ t_{21} & t_{22} & 0 \\ t_{31} & t_{32} & 1 \end{bmatrix} xy1 = vw1 t11t21t31t12t22t32001
| 变换类型 | 变换矩阵 |
|---|---|
| 恒等变换 | 100010\begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \end{bmatrix}100100 |
| 尺度变换 | Cx000Cy0\begin{bmatrix} C_x & 0 & 0 \\ 0 & C_y & 0 \end{bmatrix}Cx00Cy00 |
| 旋转变换 | cosθ−sinθsinθcosθ\begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix}cosθsinθ−sinθcosθ |
| 平移变换 | 10tx01ty\begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \end{bmatrix}1001txty |
2.3 直方图均衡化
变换函数:
sk=T(rk)=∑j=0knjn,k=0,1,2,⋯ ,L−1s_k = T(r_k) = \sum_{j=0}^{k}\frac{n_j}{n}, \quad k=0,1,2,\cdots,L-1sk=T(rk)=j=0∑knnj,k=0,1,2,⋯,L−1
2.4 示例代码
示例代码2-1 读取、显示和存储图像
cpp
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main() {
// 读取图像
Mat img = imread("lena.jpg");
if (img.empty()) {
cout << "无法读取图像" << endl;
return -1;
}
// 获取图像属性
int width = img.cols;
int height = img.rows;
cout << "图像宽度: " << width << ", 高度: " << height << endl;
// 高斯滤波
Mat blurImg;
GaussianBlur(img, blurImg, Size(5, 5), 0);
// 显示图像
imshow("原始图像", img);
imshow("高斯滤波", blurImg);
waitKey(0);
// 存储图像
imwrite("output.jpg", blurImg);
destroyAllWindows();
return 0;
}示例代码2-2 颜色空间转换
cpp
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
using namespace cv;
int main() {
Mat img_rgb = imread("lena.jpg");
Mat img_hsv, img_gray;
// RGB转HSV
cvtColor(img_rgb, img_hsv, COLOR_BGR2HSV);
// RGB转灰度
cvtColor(img_rgb, img_gray, COLOR_BGR2GRAY);
cout << "RGB image通道数: " << img_rgb.channels() << endl;
cout << "HSV image通道数: " << img_hsv.channels() << endl;
cout << "gray image通道数: " << img_gray.channels() << endl;
return 0;
}3.机器学习基础知识
3.1 机器学习的定义
- Arthur Samuel (1959):"在不直接针对问题进行明确编程的情况下,赋予计算机学习能力的研究领域"
- Tom M. Mitchell:"如果一个计算机程序针对某类任务T能用性能标准P来衡量,且能根据训练经验E来自我完善,那么我们称这个计算机程序在从经验E中学习该任务"
3.2 机器学习分类
| 学习类型 | 特点 | 典型任务 |
|---|---|---|
| 监督学习 | 使用标注数据进行训练 | 回归、分类 |
| 无监督学习 | 使用无标签数据进行训练 | 聚类、异常检测 |
| 强化学习 | 通过自我评估改进 | 游戏AI |
3.3 机器学习的一般流程
bash
数据集制作 → 特征提取 → 模型训练 → 测试预测3.4 OpenCV机器学习模块算法一览
| 算法 | OpenCV类 | 说明 |
|---|---|---|
| K-means | cv::kmeans |
聚类算法 |
| KNN | cv::ml::KNearest |
K近邻分类器 |
| 决策树 | cv::ml::DTrees |
CART算法 |
| 随机森林 | cv::ml::RTrees |
决策树集成 |
| Boosting | cv::ml::Boost |
AdaBoost等 |
| SVM | cv::ml::SVM |
支持向量机 |
| 神经网络 | cv::ml::ANN_MLP |
多层感知器 |
| 深度学习 | cv::dnn::Net |
DNN模块 |
4.K-means和KNN算法
4.1 K-means原理
K-means是最基础的聚类算法,通过最小化簇内平方和来分配样本标签:
∑y=1c∑i:y(i)=y∥x(i)−μy∥2\sum_{y=1}^{c}\sum_{i:y^{(i)}=y}\|x^{(i)}-\mu_y\|^2y=1∑ci:y(i)=y∑∥x(i)−μy∥2
其中 μy\mu_yμy 为类别 yyy 的中心:
μy=1ny∑i:y(i)=yx(i)\mu_y = \frac{1}{n_y}\sum_{i:y^{(i)}=y}x^{(i)}μy=ny1i:y(i)=y∑x(i)
算法流程:
- 给类别中心 μ1,⋯ ,μc\mu_1, \cdots, \mu_cμ1,⋯,μc 分配初值
- 更新样本标签:y(i)←argminy∥x(i)−μy∥2y^{(i)} \gets \arg\min_{y}\|x^{(i)}-\mu_y\|^2y(i)←argminy∥x(i)−μy∥2
- 更新类别中心:μy←1ny∑i:yx(i)\mu_y \leftarrow \frac{1}{n_y}\sum_{i:y}x^{(i)}μy←ny1∑i:yx(i)
- 重复步骤2和3,直到收敛
4.2 KNN原理
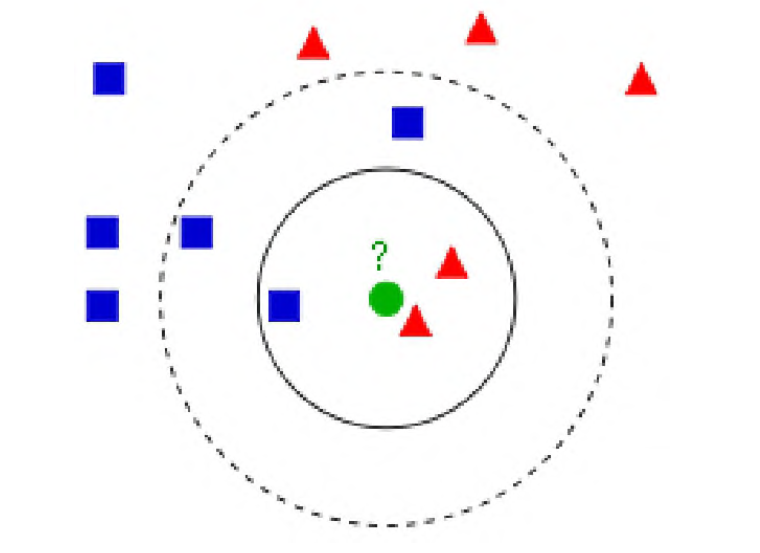
KNN(K近邻)是最简单的分类算法,核心思想是"投票":
对于待分类样本,计算与训练集中所有样本的距离,取距离最近的K个样本,哪个类别最多,就判定待测样本属于该类别。
距离度量:
- 欧氏距离:dEu=∑k=1n(x1k−x2k)2d_{Eu} = \sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2}dEu=∑k=1n(x1k−x2k)2
- 曼哈顿距离:dMan=∑k=1n∣x1k−x2k∣d_{Man} = \sum_{k=1}^{n}|x_{1k}-x_{2k}|dMan=∑k=1n∣x1k−x2k∣
- 闵可夫斯基距离:dMin=∑k=1n(x1k−x2k)ppd_{Min} = \sqrtp{\sum_{k=1}^{n}(x_{1k}-x_{2k})^p}dMin=p∑k=1n(x1k−x2k)p
回归预测 :
y^=∑i=1KyiK\hat{y} = \frac{\sum_{i=1}^{K}y_i}{K}y^=K∑i=1Kyi
4.3 OpenCV实现
cv::kmeans函数:
cpp
double cv::kmeans(
InputArray data, // 输入样本矩阵 N×dims
int K, // 聚类类别数
OutputArray bestLabels, // 输出每个样本的标签
TermCriteria criteria, // 迭代终止条件
int attempts, // 算法执行次数
int flags, // 初始化方法
OutputArray centers = noArray() // 输出聚类中心
);cv::ml::KNearest类:
cpp
// 创建KNN模型
Ptr<KNearest> knn = KNearest::create();
knn->setDefaultK(5); // 设置K值
knn->setIsClassifier(true); // 分类模式
// 训练
knn->train(trainData, ROW_SAMPLE, trainLabels);
// 预测
Mat response;
knn->findNearest(testData, K, response);4.4 示例代码
示例代码1 K-means二维坐标点集聚类
cpp
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace std;
int main() {
const int clusterCount = 4;
const int sampleCount = 500;
RNG rng(12345);
Mat points(sampleCount, 2, CV_32F);
Mat labels;
Mat centers;
// 生成随机样本
for (int i = 0; i < sampleCount; i++) {
points.at<float>(i, 0) = rng.uniform(0.0f, 500.0f);
points.at<float>(i, 1) = rng.uniform(0.0f, 500.0f);
}
// K-means聚类
double compactness = kmeans(
points,
clusterCount,
labels,
TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 1.0),
3,
KMEANS_PP_CENTERS,
centers
);
cout << "紧凑性: " << compactness << endl;
cout << "聚类中心:\n" << centers << endl;
return 0;
}示例代码2 KNN手写数字分类
cpp
#include <opencv2/ml.hpp>
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
using namespace cv;
using namespace cv::ml;
using namespace std;
int main() {
// 生成训练数据和标签
Mat trainData, trainLabels;
Mat testData, testLabels;
// ... 数据准备代码 ...
// 创建KNN模型
Ptr<KNearest> knn = KNearest::create();
knn->setDefaultK(3);
knn->setIsClassifier(true);
// 训练
knn->train(trainData, ROW_SAMPLE, trainLabels);
// 测试
Mat response;
knn->findNearest(testData, knn->getDefaultK(), response);
// 计算精度
float correct = 0;
for (int i = 0; i < response.rows; i++) {
if (response.at<float>(i) == testLabels.at<float>(i))
correct++;
}
cout << "精度: " << correct / response.rows << endl;
return 0;
}4.5 应用提示
- 数据规范化:特征尺度不同时需要进行归一化
- K值选择:通过交叉验证选择最佳K值,K过小容易过拟合,K过大边界模糊
- 距离度量:根据数据特点选择合适的距离函数
- 内存占用:KNN需要存储所有训练样本,适合小规模数据集
5.决策树
5.1 决策树的基本思想
决策树通过if-then结构分割数据,从根节点到叶子节点的路径对应分类规则。
5.2 最佳切分属性的选择
基于不纯度减少 或纯度增益选择最佳切分属性。
信息熵 (ID3算法):
H(D)=−∑j=1Jpjlog2(pj)H(D) = -\sum_{j=1}^{J}p_j\log_2(p_j)H(D)=−j=1∑Jpjlog2(pj)
信息增益 :
G(D,A)=H(D)−H(D∣A)=H(D)−∑i=1n∣Di∣∣D∣H(Di)G(D,A) = H(D) - H(D|A) = H(D) - \sum_{i=1}^{n}\frac{|D_i|}{|D|}H(D_i)G(D,A)=H(D)−H(D∣A)=H(D)−i=1∑n∣D∣∣Di∣H(Di)
信息增益率 (C4.5算法):
GR(D,A)=G(D,A)HA(D)GR(D,A) = \frac{G(D,A)}{H_A(D)}GR(D,A)=HA(D)G(D,A)
基尼系数 (CART算法):
Gini(D)=1−∑j=1Jpj2=1−∑j=1J(∣Dj∣∣D∣)2\operatorname{Gini}(D) = 1 - \sum_{j=1}^{J}p_j^2 = 1 - \sum_{j=1}^{J}\left(\frac{|D_j|}{|D|}\right)^2Gini(D)=1−j=1∑Jpj2=1−j=1∑J(∣D∣∣Dj∣)2
5.3 CART算法
OpenCV实现的是CART算法,可用于分类和回归。
分类问题 :使用基尼系数选择最优切分
回归问题 :使用均方误差(MSE)
MSE=1m∑i=1m(ytest(i)−y^test(i))2MSE = \frac{1}{m}\sum_{i=1}^{m}(y_{test}^{(i)}-\hat{y}_{test}^{(i)})^2MSE=m1i=1∑m(ytest(i)−y^test(i))2
5.4 OpenCV实现
cv::ml::DTrees类:
cpp
// 创建决策树
Ptr<DTrees> dtree = DTrees::create();
// 关键参数设置
dtree->setMaxDepth(10); // 最大树深度
dtree->setMinSampleCount(10); // 节点最小样本数
dtree->setUseSurrogates(false); // 是否使用代理切分
dtree->setCVFolds(5); // 交叉验证折数
dtree->setUse1SERule(true); // 是否使用1SE剪枝
// 训练和预测
dtree->train(trainData, ROW_SAMPLE, trainLabels);
dtree->predict(testData, response);5.5 示例代码
示例代码1蘑菇可食性分类
cpp
#include <opencv2/ml.hpp>
#include <opencv2/core.hpp>
using namespace cv;
using namespace cv::ml;
using namespace std;
int main() {
// 从CSV加载数据
Ptr<TrainData> trainData = TrainData::loadFromCSV(
"mushroom.csv", // 文件名
0, // 跳过行数
-1, // 标签列索引
-1 // 标签结束索引
);
// 设置训练/测试比例
trainData->setTrainTestSplitRatio(0.8);
// 创建决策树
Ptr<DTrees> dtree = DTrees::create();
dtree->setMaxDepth(8);
dtree->setMinSampleCount(2);
// 训练
dtree->train(trainData->getTrainingSamples(),
ROW_SAMPLE,
trainData->getTrainingResponses());
// 测试
Mat testSamples = trainData->getTestSamples();
Mat predicted;
dtree->predict(testSamples, predicted);
// 计算误差
Mat testLabels = trainData->getTestResponses();
float error = calcError(dtree, testSamples, testLabels);
cout << "测试误差: " << error << endl;
return 0;
}示例代码2 预测波士顿房价(回归)
cpp
#include <opencv2/ml.hpp>
#include <opencv2/core.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
// 加载训练数据和测试数据
Ptr<TrainData> trainData = TrainData::loadFromCSV(
"housing-train.csv", 0, -1);
Ptr<TrainData> testData = TrainData::loadFromCSV(
"housing-test.csv", 0, -1);
// 创建决策树(用于回归)
Ptr<DTrees> dtree = DTrees::create();
dtree->setMaxDepth(10);
// 训练
dtree->train(trainData->getTrainingSamples(),
ROW_SAMPLE,
trainData->getTrainingResponses());
// 保存模型
dtree->save("housing_dtree_model.xml");
// 加载模型
Ptr<DTrees> loadedDtree = StatModel::load<DTrees>(
"housing_dtree_model.xml");
// 预测
Mat testSamples = testData->getTestSamples();
Mat predicted;
loadedDtree->predict(testSamples, predicted);
// 计算MSE和RMSE
Mat testLabels = testData->getTestResponses();
Mat diff = testLabels - predicted;
double mse = mean(diff.mul(diff))[0];
double rmse = sqrt(mse);
cout << "测试集MSE: " << mse << endl;
cout << "测试集RMSE: " << rmse << endl;
return 0;
}6.随机森林
6.1 Bagging算法
随机森林基于Bagging(Bootstrap Aggregating)集成学习方法:
训练阶段:
- 使用Bootstrapping从原始训练集随机抽取N个样本(有放回)
- 重复k轮,得到k个训练子集
- 用k个训练子集训练k个基础模型
测试阶段:
- 分类:多数投票
- 回归:取平均值
6.2 随机森林的两重随机性
- 样本随机:通过Bootstrapping保证各树训练数据独立
- 特征随机:每个节点从随机特征子集中选择最优切分
当N足够大时,约36.8%的样本不会被抽中(袋外数据OOB),可用于验证。
6.3 随机森林 vs 决策树
| 特性 | 决策树 | 随机森林 |
|---|---|---|
| 训练集误差 | 低 | 较高 |
| 测试集误差 | 较高(易过拟合) | 较低 |
| 泛化能力 | 一般 | 强 |
6.4 OpenCV实现
cv::ml::RTrees类:
cpp
// 创建随机森林
Ptr<RTrees> rtrees = RTrees::create();
// 参数设置
rtrees->setMaxDepth(10); // 最大树深度
rtrees->setMinSampleCount(2); // 节点最小样本数
rtrees->setActiveVarCount(0); // 特征子集大小(0=sqrt(n))
rtrees->setCalculateVarImportance(true); // 计算特征重要性
// 设置终止条件(树的数量或OOB误差)
rtrees->setTermCriteria(TermCriteria(
TermCriteria::MAX_ITERS + TermCriteria::EPS,
100, 0.1));
// 获取特征重要性
Mat varImportance;
if (rtrees->getCalculateVarImportance()) {
varImportance = rtrees->getVarImportance();
}6.5 示例代码
示例代码1 蘑菇可食性分类
cpp
#include <opencv2/ml.hpp>
#include <opencv2/core.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
// 加载数据
Ptr<TrainData> data = TrainData::loadFromCSV(
"mushroom.csv", 0, -1);
data->setTrainTestSplitRatio(0.8);
// 创建随机森林
Ptr<RTrees> rtrees = RTrees::create();
rtrees->setMaxDepth(10);
rtrees->setMinSampleCount(2);
rtrees->setActiveVarCount(0); // 使用默认sqrt(n)
rtrees->setCalculateVarImportance(true);
rtrees->setTermCriteria(TermCriteria(
TermCriteria::MAX_ITERS, 100, 0));
// 训练
Mat trainSamples = data->getTrainingSamples();
Mat trainLabels = data->getTrainingResponses();
rtrees->train(trainSamples, ROW_SAMPLE, trainLabels);
// 获取特征重要性
Mat varImportance = rtrees->getVarImportance();
cout << "特征重要性:\n" << varImportance << endl;
// 测试
Mat testSamples = data->getTestSamples();
Mat predicted;
rtrees->predict(testSamples, predicted);
float accuracy = 1.0f - calcError(rtrees, testSamples,
data->getTestResponses());
cout << "测试精度: " << accuracy << endl;
return 0;
}示例代码2 预测波士顿房价
cpp
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
Ptr<TrainData> trainData = TrainData::loadFromCSV(
"housing-train.csv", 0, -1);
Ptr<TrainData> testData = TrainData::loadFromCSV(
"housing-test.csv", 0, -1);
// 创建随机森林
Ptr<RTrees> rtrees = RTrees::create();
rtrees->setMaxDepth(10);
rtrees->setActiveVarCount(0);
// 训练
rtrees->train(trainData->getTrainingSamples(),
ROW_SAMPLE,
trainData->getTrainingResponses());
// 预测
Mat predicted;
rtrees->predict(testData->getTestSamples(), predicted);
// 计算误差
Mat diff = testData->getTestResponses() - predicted;
double rmse = sqrt(mean(diff.mul(diff))[0]);
cout << "随机森林测试集RMSE: " << rmse << endl;
return 0;
}7.Boosting算法
7.1 Boosting基本思想
Boosting(提升)算法的核心是串行学习:每次迭代调整样本权重,让后续分类器更关注之前分错的样本,最终线性组合弱分类器形成强分类器。
7.2 AdaBoost算法
样本权重更新 :
wi(j+1)=1Zjwi(j)exp(−θjφj(xi)yi)w_i^{(j+1)} = \frac{1}{Z_j}w_i^{(j)}\exp(-\theta_j\varphi_j(x_i)y_i)wi(j+1)=Zj1wi(j)exp(−θjφj(xi)yi)
弱分类器权重 :
θj=12ln1−R(φj)R(φj)\theta_j = \frac{1}{2}\ln\frac{1-R(\varphi_j)}{R(\varphi_j)}θj=21lnR(φj)1−R(φj)
最终分类器 :
f(x)=sign(∑j=1kθjφj(x))f(x) = \text{sign}\left(\sum_{j=1}^{k}\theta_j\varphi_j(x)\right)f(x)=sign(j=1∑kθjφj(x))
其中 R(φj)R(\varphi_j)R(φj) 是第 jjj 个分类器的加权分类错误率。
7.3 OpenCV中的Boosting算法
| 算法 | OpenCV枚举值 | 说明 |
|---|---|---|
| Discrete AdaBoost | cv::ml::Boost::DISCRETE |
离散AdaBoost |
| Real AdaBoost | cv::ml::Boost::REAL |
置信度评估 |
| LogitBoost | cv::ml::Boost::LOGIT |
回归任务 |
| Gentle AdaBoost | cv::ml::Boost::GENTLE |
赋予异常数据较小权重 |
7.3.1 OpenCV实现
cpp
// 创建Boosting模型
Ptr<Boost> boost = Boost::create();
// 参数设置
boost->setBoostType(Boost::REAL); // Real AdaBoost
boost->setWeakCount(100); // 弱分类器数量
boost->setMaxDepth(1); // 决策树桩
boost->setWeightTrimRate(0.95); // 权重修剪率
boost->setUseSurrogates(false);
// 训练
boost->train(trainData, ROW_SAMPLE, trainLabels);7.3.2 示例代码
示例代码1 蘑菇可食性分类
cpp
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
Ptr<TrainData> data = TrainData::loadFromCSV(
"mushroom.csv", 0, -1);
data->setTrainTestSplitRatio(0.8);
// 创建Boosting模型
Ptr<Boost> boost = Boost::create();
boost->setBoostType(Boost::REAL);
boost->setWeakCount(100);
boost->setMaxDepth(1); // 决策树桩
boost->setWeightTrimRate(0.95);
// 训练
Mat trainSamples = data->getTrainingSamples();
Mat trainLabels = data->getTrainingResponses();
boost->train(trainSamples, ROW_SAMPLE, trainLabels);
// 测试
Mat testSamples = data->getTestSamples();
Mat predicted;
boost->predict(testSamples, predicted);
float accuracy = 1.0f - calcError(boost, testSamples,
data->getTestResponses());
cout << "AdaBoost测试精度: " << accuracy << endl;
return 0;
}示例代码2 英文字母分类(多分类展开技巧)
cpp
// 展开技巧:将多分类问题转换为多个二分类问题
// 26个类别 -> 26个二分类器
// 每个样本{x, y} 扩展为 {x, y} -> {x, y_class}, label -> 1/0
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
const int numClasses = 26;
Ptr<TrainData> origData = TrainData::loadFromCSV(
"letter-recognition.csv", 0, 0, 0);
// 展开数据集
// ... 数据展开代码 ...
// 创建AdaBoost分类器
Ptr<Boost> boost = Boost::create();
boost->setBoostType(Boost::REAL);
boost->setWeakCount(50);
// 训练26个二分类器
vector<Ptr<Boost>> classifiers(numClasses);
for (int c = 0; c < numClasses; c++) {
classifiers[c] = Boost::create();
classifiers[c]->train(expandedTrainData, ROW_SAMPLE,
expandedTrainLabels);
}
// 预测:选择置信度最高的类别
// ... 预测代码 ...
return 0;
}8.支持向量机
8.1 统计学习理论基础
经验风险最小化(ERM) :
Remp(α)=1m∑i=1mQ(zi,α)R_{emp}(\alpha) = \frac{1}{m}\sum_{i=1}^{m}Q(z_i,\alpha)Remp(α)=m1i=1∑mQ(zi,α)
结构风险最小化(SRM) :
R(α)⩽Remp(α)+h(ln(2m/h)+1)−ln(η/4)mR(\alpha) \leqslant R_{emp}(\alpha) + \sqrt{\frac{h(\ln(2m/h)+1)-\ln(\eta/4)}{m}}R(α)⩽Remp(α)+mh(ln(2m/h)+1)−ln(η/4)
VC维衡量学习机器的容量,间隔越大,VC维越小。
8.2 线性SVM
硬间隔SVM (线性可分):
minw,b12∥w∥2\min_{w,b} \frac{1}{2}\|w\|^2w,bmin21∥w∥2
s.t.y(i)(wTx(i)+b)⩾1\text{s.t.} \quad y^{(i)}(w^Tx^{(i)}+b) \geqslant 1s.t.y(i)(wTx(i)+b)⩾1
软间隔SVM (允许少量错误):
minw,b,ξ12∥w∥2+C∑i=1mξi\min_{w,b,\xi} \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{m}\xi_iw,b,ξmin21∥w∥2+Ci=1∑mξi
s.t.y(i)(wTx(i)+b)⩾1−ξi,ξi⩾0\text{s.t.} \quad y^{(i)}(w^Tx^{(i)}+b) \geqslant 1-\xi_i, \quad \xi_i \geqslant 0s.t.y(i)(wTx(i)+b)⩾1−ξi,ξi⩾0
8.3 对偶问题与支持向量
通过对偶问题求解,最终分类函数为:
f(x)=sign∑i=1mαiy(i)⟨x(i),x⟩+bf(x) = \text{sign}\left\\sum_{i=1}\^{m}\\alpha_i y\^{(i)}\\langle x\^{(i)}, x \\rangle + b\\rightf(x)=signi=1∑mαiy(i)⟨x(i),x⟩+b
只有 αi>0\alpha_i > 0αi>0 的样本(支持向量)决定分类超平面。
8.4 核方法
通过核函数将数据映射到高维空间实现非线性分类:
K(x,z)=⟨ϕ(x),ϕ(z)⟩K(x, z) = \langle \phi(x), \phi(z) \rangleK(x,z)=⟨ϕ(x),ϕ(z)⟩
常用核函数:
| 核函数 | 公式 | 参数 |
|---|---|---|
| 线性核 | K(x,z)=xTzK(x,z) = x^TzK(x,z)=xTz | 无 |
| 多项式核 | K(x,z)=(γxTz+c)dK(x,z) = (\gamma x^Tz + c)^dK(x,z)=(γxTz+c)d | γ,c,d\gamma, c, dγ,c,d |
| RBF核 | K(x,z)=exp(−γ∣x−z∣2)K(x,z) = \exp(-\gamma|x-z|^2)K(x,z)=exp(−γ∣x−z∣2) | γ\gammaγ |
| Sigmoid核 | K(x,z)=tanh(γxTz+c)K(x,z) = \tanh(\gamma x^Tz + c)K(x,z)=tanh(γxTz+c) | γ,c\gamma, cγ,c |
8.5 SVR回归
minw,b12∥w∥2+C∑i=1m(ξi+ξi∗)\min_{w,b} \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{m}(\xi_i + \xi_i^*)w,bmin21∥w∥2+Ci=1∑m(ξi+ξi∗)
s.t.y(i)−(wTx(i)+b)⩽ε+ξi\text{s.t.} \quad y^{(i)} - (w^Tx^{(i)}+b) \leqslant \varepsilon + \xi_is.t.y(i)−(wTx(i)+b)⩽ε+ξi
8.6 OpenCV实现
cv::ml::SVM类:
cpp
// 创建SVM
Ptr<SVM> svm = SVM::create();
// SVM类型
svm->setType(SVM::C_SVC); // C-SVM分类
// SVM::NU_SVC // v-SVM分类
// SVM::ONE_CLASS // 单类分类
// SVM::EPS_SVR // ε-SVR回归
// SVM::NU_SVR // v-SVR回归
// 核函数
svm->setKernel(SVM::RBF); // RBF核
// SVM::LINEAR // 线性核
// SVM::POLY // 多项式核
// SVM::SIGMOID // Sigmoid核
// 参数
svm->setC(10); // 惩罚参数C
svm->setGamma(0.5); // RBF/Poly/Sigmoid参数
svm->setDegree(3); // 多项式核度数
svm->setP(0.1); // ε-SVR参数
svm->setNu(0.5); // v-SVM参数
// 训练
svm->train(trainData, ROW_SAMPLE, trainLabels);
// 自动参数优化
svm->trainAuto(trainData, 10); // 10折交叉验证
// 预测
Mat response;
svm->predict(testData, response);
// 获取支持向量
Mat supportVectors = svm->getSupportVectors();8.7 示例代码
示例代码1 HOG特征+SVM手写数字分类
cpp
#include <opencv2/ml.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/objdetect.hpp>
using namespace cv;
using namespace cv::ml;
// 偏斜校正函数
Mat deskew(const Mat& img) {
Moments m = moments(img);
if (m.m00 == 0) return img;
double skew = m.mu11 / m.mu02;
Mat warpMat = (Mat_<float>(2, 3) <<
1, skew, -0.5 * skew * img.rows,
0, 1, 0);
Mat result;
warpAffine(img, result, warpMat, img.size());
return result;
}
// HOG特征计算
vector<float> computeHOG(const Mat& img) {
HOGDescriptor hog(Size(20, 20), Size(8, 8), Size(4, 4),
Size(4, 4), 9);
vector<float> descriptors;
hog.compute(img, descriptors);
return descriptors;
}
int main() {
// 读取并预处理图像
Mat bigImg = imread("digits.png", 0);
Mat labels;
vector<Mat> trainDigits, testDigits;
// ... 数据准备代码 ...
// 计算HOG特征
Mat trainData, trainLabels;
for (size_t i = 0; i < trainDigits.size(); i++) {
Mat deskewed = deskew(trainDigits[i]);
vector<float> hog = computeHOG(deskewed);
trainData.push_back(Mat(hog).t());
trainLabels.push_back(label);
}
// 创建并训练SVM
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::RBF);
svm->setC(10);
svm->setGamma(0.05);
// 使用auto训练优化参数
// svm->trainAuto(trainData, 10);
svm->train(trainData, ROW_SAMPLE, trainLabels);
// 测试
Mat testData;
for (size_t i = 0; i < testDigits.size(); i++) {
Mat deskewed = deskew(testDigits[i]);
vector<float> hog = computeHOG(deskewed);
testData.push_back(Mat(hog).t());
}
Mat response;
svm->predict(testData, response);
float accuracy = countNonZero(response == testLabels) /
(float)testLabels.rows;
cout << "测试精度: " << accuracy << endl;
return 0;
}9.神经网络
9.1 神经元模型(感知器)
输入:x∈Rnx \in \mathbb{R}^nx∈Rn
输出:hθ(x)=g(z)=g(θTx+b)h_\theta(x) = g(z) = g(\theta^Tx + b)hθ(x)=g(z)=g(θTx+b)
9.2 激活函数
| 激活函数 | 公式 |
|---|---|
| Sigmoid | 11+e−z\frac{1}{1+e^{-z}}1+e−z1 |
| Tanh | ez−e−zez+e−z\frac{e^z - e^{-z}}{e^z + e^{-z}}ez+e−zez−e−z |
| ReLU | max(0,z)\max(0, z)max(0,z) |
9.3 多层感知器结构
- 输入层:接收特征向量
- 隐藏层:提取特征
- 输出层:输出预测结果
9.4 前向传播
a(l)=g(z(l))=g(W(l−1)a(l−1)+b(l))a^{(l)} = g(z^{(l)}) = g(W^{(l-1)}a^{(l-1)} + b^{(l)})a(l)=g(z(l))=g(W(l−1)a(l−1)+b(l))
9.5 代价函数
J(θ)=L(θ)+λR(θ)J(\theta) = \mathcal{L}(\theta) + \lambda R(\theta)J(θ)=L(θ)+λR(θ)
交叉熵损失:
L(θ)=−1N∑i=1N∑k=1Kyk(i)log(y\^k(i))+(1−yk(i))log(1−y\^k(i))\mathcal{L}(\theta) = -\frac{1}{N}\sum_{i=1}^{N}\sum_{k=1}^{K}y_k\^{(i)}\\log(\\hat{y}_k\^{(i)}) + (1-y_k\^{(i)})\\log(1-\\hat{y}_k\^{(i)})L(θ)=−N1i=1∑Nk=1∑Kyk(i)log(y\^k(i))+(1−yk(i))log(1−y\^k(i))
L2正则项:
λR(θ)=λ2N∑l=1L−1∑i=1sl∑j=1sl+1(θji(l))2\lambda R(\theta) = \frac{\lambda}{2N}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\theta_{ji}^{(l)})^2λR(θ)=2Nλl=1∑L−1i=1∑slj=1∑sl+1(θji(l))2
9.6 梯度下降法
参数更新:
θ:=θ−α∂J(θ)∂θ\theta := \theta - \alpha \frac{\partial J(\theta)}{\partial \theta}θ:=θ−α∂θ∂J(θ)
9.7 反向传播算法(BP)
1. 前向传播计算各层输出
2. 计算输出层误差:δ(L)=(a(L)−y)⊙g′(z(L))\delta^{(L)} = (a^{(L)} - y) \odot g'(z^{(L)})δ(L)=(a(L)−y)⊙g′(z(L))
3. 反向递推:δ(l)=(W(l))Tδ(l+1)⊙g′(z(l))\delta^{(l)} = (W^{(l)})^T\delta^{(l+1)} \odot g'(z^{(l)})δ(l)=(W(l))Tδ(l+1)⊙g′(z(l))
4. 计算梯度并更新权重
9.8 OpenCV实现
cv::ml::ANN_MLP类:
cpp
// 创建MLP
Ptr<ANN_MLP> mlp = ANN_MLP::create();
// 设置网络结构 [输入层, 隐藏层1, ..., 输出层]
Mat layerSizes = (Mat_<int>(1, 4) << 784, 100, 50, 10);
mlp->setLayerSizes(layerSizes);
// 设置激活函数
mlp->setActivationFunction(ANN_MLP::SIGMOID_SYM, 0.6, 1);
// ANN_MLP::IDENTITY
// ANN_MLP::RELU
// ANN_MLP::LEAKYRELU
// 设置训练方法
mlp->setTrainMethod(ANN_MLP::RPROP); // 默认
// ANN_MLP::BACKPROP
// ANN_MLP::ANNEAL
// RPROP参数
mlp->setRpropDW0(0.1); // 初始步长
mlp->setRpropDWMin(1e-7); // 最小步长
mlp->setRpropDWMax(50.0); // 最大步长
// BP参数
mlp->setBackpropWeightScale(0.1); // 权重梯度
mlp->setBackpropMomentumScale(0.1); // 冲量
// 终止条件
mlp->setTermCriteria(TermCriteria(
TermCriteria::MAX_ITER + TermCriteria::EPS,
1000, 0.01));
// 训练
mlp->train(trainData, ROW_SAMPLE, trainLabels);
// 预测
Mat response;
mlp->predict(testData, response);9.9 示例代码
示例代码1 MLP手写数字分类
cpp
#include <opencv2/ml.hpp>
#include <opencv2/core.hpp>
using namespace cv;
using namespace cv::ml;
int main() {
// MNIST数据读取
// ... mnistReader代码 ...
// 准备训练数据(784维输入,10维输出)
Mat trainData, trainLabels;
Mat testData, testLabels;
// ... 数据准备 ...
// 创建MLP
Ptr<ANN_MLP> mlp = ANN_MLP::create();
// 设置网络结构 [输入, 隐藏层, 输出]
Mat layerSizes = (Mat_<int>(1, 3) << 784, 300, 10);
mlp->setLayerSizes(layerSizes);
// 设置激活函数
mlp->setActivationFunction(ANN_MLP::SIGMOID_SYM, 0.6, 1);
// 设置训练方法
mlp->setTrainMethod(ANN_MLP::RPROP);
mlp->setRpropDW0(0.1);
mlp->setRpropDWMin(1e-7);
mlp->setRpropDWMax(50.0);
// 设置终止条件
mlp->setTermCriteria(TermCriteria(
TermCriteria::MAX_ITER + TermCriteria::EPS,
1000, 0.01));
// 训练
mlp->train(trainData, ROW_SAMPLE, trainLabels);
// 测试
Mat response;
mlp->predict(testData, response);
// 计算精度
int correct = 0;
for (int i = 0; i < response.rows; i++) {
Point maxLoc;
minMaxLoc(response.row(i), 0, 0, 0, &maxLoc);
int predicted = maxLoc.x;
int actual = testLabels.at<int>(i);
if (predicted == actual) correct++;
}
cout << "MLP测试精度: " << (float)correct / response.rows << endl;
return 0;
}9.10 应用提示
| 网络结构示例 | 说明 |
|---|---|
| 784, 10, 10 | 单隐藏层,10个神经元 |
| 784, 100, 10 | 单隐藏层,100个神经元 |
| 784, 300, 10 | 单隐藏层,300个神经元 |
| 784, 100, 50, 10 | 双隐藏层 |
训练时间与精度随网络复杂度增加而增加。
10.深度神经网络
10.1 卷积神经网络(CNN)
CNN是深度学习的基石,比全连接网络更适合图像处理。
CNN基本结构:
bash
输入 → Conv → ReLU → Pooling → ... → Conv → ReLU →
Pooling → FC → ReLU → FC → Softmax → 输出10.2 卷积层
二维卷积 :
s(i,j)=(I∗K)(i,j)=∑m∑nI(m,n)K(i−m,j−n)s(i,j) = (I*K)(i,j) = \sum_m \sum_n I(m,n)K(i-m,j-n)s(i,j)=(I∗K)(i,j)=m∑n∑I(m,n)K(i−m,j−n)
填充(Padding) :在输入周围填充像素维持尺寸
步幅(Stride):滤波器移动的间隔
输出尺寸公式 :
OW=W+2P−FWS+1OW = \frac{W + 2P - FW}{S} + 1OW=SW+2P−FW+1
OH=H+2P−FHS+1OH = \frac{H + 2P - FH}{S} + 1OH=SH+2P−FH+1
10.3 池化层
- 最大池化:取区域最大值
- 平均池化 :取区域平均值
作用:减少特征图尺寸,降低计算量,增加平移不变性。
10.4 Softmax层
用于多分类:
Softmax(zi)=ezi∑jezj\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}Softmax(zi)=∑jezjezi
10.5 OpenCV DNN模块
cv::dnn::Net类:
cpp
#include <opencv2/dnn.hpp>
using namespace cv;
using namespace cv::dnn;
// 加载模型
Net net = readNetFromCaffe(prototxt, caffeModel); // Caffe
// Net net = readNetFromTensorflow(model); // TensorFlow
// Net net = readNetFromTorch(model); // Torch
// Net net = readNetFromONNX(model); // ONNX
// 设置后端和目标
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
// DNN_TARGET_OPENCL // GPU
// DNN_TARGET_OPENCL_FP16 // FPGA
// 读取图像并预处理
Mat img = imread("test.jpg");
Mat blob = blobFromImage(img, 1.0/255, Size(224, 224),
Scalar(0,0,0), false, false);
// 前向传播
net.setInput(blob);
Mat prob = net.forward();
// 获取预测结果
Point classIdPoint;
double confidence;
minMaxLoc(prob.reshape(1, 1), 0, &confidence, 0, &classIdPoint);
int classId = classIdPoint.x;10.6 应用示例类型
10.6.1 图像分类(GoogLeNet)
cpp
// 加载GoogLeNet模型
Net net = readNetFromCaffe("deploy.prototxt",
"caffenet_train_iter_10000.caffemodel");
Mat img = imread("test.jpg");
Mat blob = blobFromImage(img, 1.0f/255, Size(227, 227));
net.setInput(blob);
Mat prob = net.forward();
// 读取类别标签
vector<String> classNames = {...};
int classId;
minMaxLoc(prob, nullptr, nullptr, nullptr, &classIdPoint);
classId = classIdPoint.x;
cout << "预测类别: " << classNames[classId] << endl;10.6.2 目标检测(YOLOv4)
cpp
// 加载YOLOv4模型
Net net = readNetFromDarknet("yolov4.cfg", "yolov4.weights");
Mat img = imread("test.jpg");
Mat blob = blobFromImage(img, 1/255.0, Size(416, 416));
net.setInput(blob);
vector<Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
// 解析检测结果
for (auto& output : outputs) {
for (int i = 0; i < output.rows; i++) {
Mat detection = output.row(i);
float* data = (float*)detection.data;
float confidence = data[4];
// ... 解析边界框 ...
}
}10.6.3 实例分割(Mask R-CNN)
cpp
// 加载Mask R-CNN模型
Net net = readNetFromTensorflow("mask_rcnn_inception_v2_coco.pb",
"mask_rcnn_inception_v2_coco.pbtxt");
Mat img = imread("test.jpg");
Mat blob = blobFromImage(img, 1.0f, Size(800, 800));
net.setInput(blob);
vector<String> outNames = {"detection_out_final", "mask_detect_out"};
vector<Mat> outputs;
net.forward(outputs, outNames);
// 解析分割结果
Mat dets = outputs[0]; // 检测结果
Mat masks = outputs[1]; // 分割掩码10.7 应用提示
1. 模型格式 :支持Caffe、TensorFlow、Torch、PyTorch、Darknet和ONNX
2. GPU加速 :从OpenCV 4.1.0开始支持CUDA加速
3. 自定义层 :支持通过registerCustomLayer添加自定义层
4. 预处理:注意图像尺寸归一化和通道顺序(BGR→RGB)
11 附录:常用函数速查表
11.1 数据类型转换
| 操作 | 函数 |
|---|---|
| RGB转灰度 | cvtColor(img, gray, COLOR_BGR2GRAY) |
| RGB转HSV | cvtColor(img, hsv, COLOR_BGR2HSV) |
| 图像归一化 | normalize(img, img, 0, 255, NORM_MINMAX) |
11.2 数据集划分
cpp
Ptr<TrainData> data = TrainData::loadFromCSV(...);
data->setTrainTestSplitRatio(0.8); // 80%训练, 20%测试
Mat trainSamples = data->getTrainingSamples();
Mat trainLabels = data->getTrainingResponses();
Mat testSamples = data->getTestSamples();
Mat testLabels = data->getTestResponses();11.3 模型持久化
cpp
// 保存
model->save("model.xml");
// 加载
Ptr<ModelType> model = Algorithm::load<ModelType>("model.xml");