摘要
本文进一步深入介绍了梯度下降法的多变量情形。文章以二元函数为例演示了多变量梯度下降的迭代过程,讨论了学习率对收敛的影响。通过银行信贷案例,完整推导了从假设函数、损失函数到梯度计算与参数更新的全过程。文章对梯度下降法进行了分类,对比了全梯度下降、随机梯度下降、小批量梯度下降、随机平均梯度下降及Adam等方法的原理与优缺点。此外,对比了梯度下降与正规方程法的适用场景,并介绍了回归模型的三种评估指标:MAE、MSE与RMSE。
Abstract
This article further introduces the multivariate case of gradient descent. It demonstrates the iterative process using a binary function example and discusses the impact of learning rate on convergence. Through a bank credit case study, it presents a complete derivation from hypothesis function and loss function to gradient calculation and parameter updates. The article classifies gradient descent methods, comparing the principles and trade-offs of FGD, SGD, Mini-batch, SAG, and Adam. It also compares gradient descent with the normal equation method and introduces three regression evaluation metrics: MAE, MSE, and RMSE.
一.梯度下降法
上次我们简单地回顾了梯度下降法,并以单变量梯度下降的一个简单的例子进行了了解,接着我们再了解多变量梯度下降。
就以多变量变量梯度下降举个例子:
假设函数为,求当
和
为何值时,函数值最小。初始化起点为(1,3),学习率α为0.1,其中J(θ)函数关于
的导数为2
,关于
的导数为2
,所以J(θ)的梯度为(2
,2
)。则梯度下降的迭代计算过程如下:
第一步:
第二步:
......
第N步:,
已经极其接近最优值,J(θ)也接近最小值。
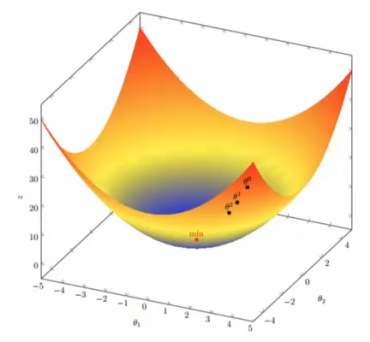
所以梯度下降的优化过程就是先给定初始位置、步长(学习率),接着计算该点的当前梯度的负方向,就可以向该负方向移动步长,如此重复直到收敛。
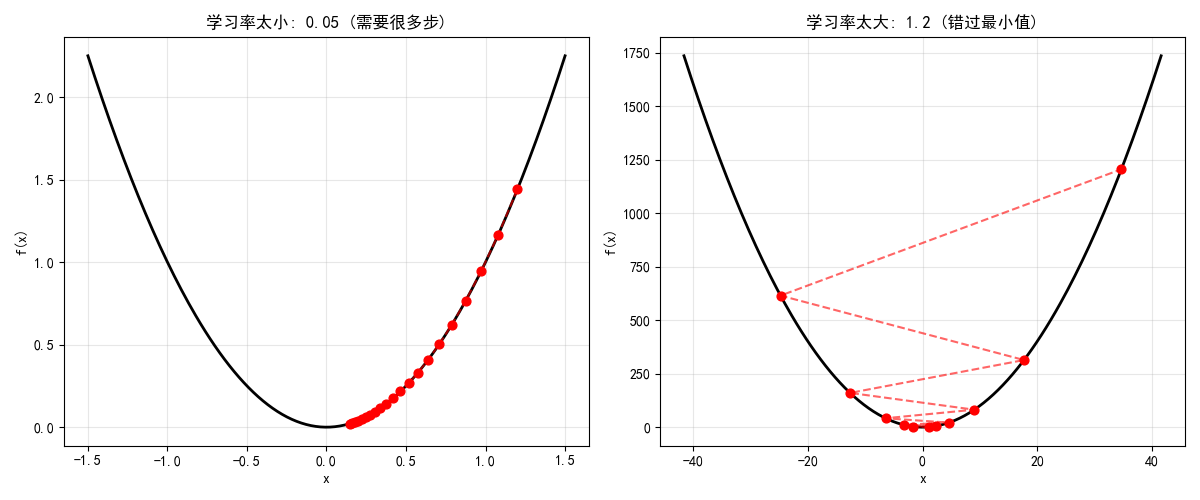
其中学习率步长的选择也是重要的,其是决定了在梯度下降迭代过程中,每一步沿梯度负增长方向前进的长度。如果学习率太小,下降速度就慢,学习率太大,容易造成错过最低点,产生下降过程中的震荡,甚至梯度爆炸。
为了进一步了解梯度下降法,下面就通过银行信贷的案例进行学习。银行信贷只考虑每月薪资、存款余额以及房产面积,目前已知8位贷款人的数据:
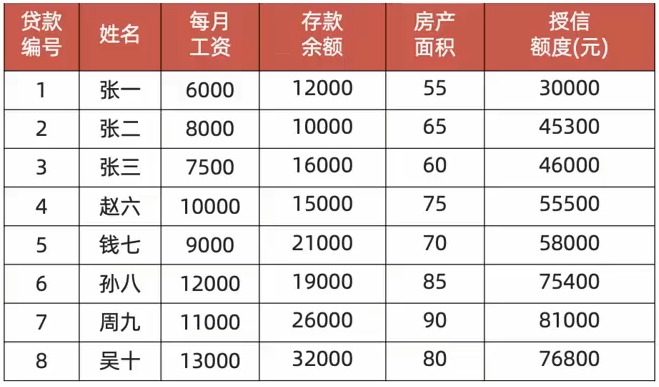
目标是为了计算数据样本产生的梯度,求解回归路线。
根据已知的数据可以假设函数(其中 =b,
=1)与损失函数(式中为了简化运算所有添加了1/2)如下:
所以接下来要做的就是先计算8个样本产生的平均梯度,带入梯度下降公式更新权重。
为了后面方便运算,这里就先将J(θ)的对于向量θ进行求导:
其中为第i个样本的向量表示(
),再将梯度向量表示改写成标量表示:
表示第i个样本的第j个特征值。为了计算每个分量的梯度,带入标量梯度下降公式计算。
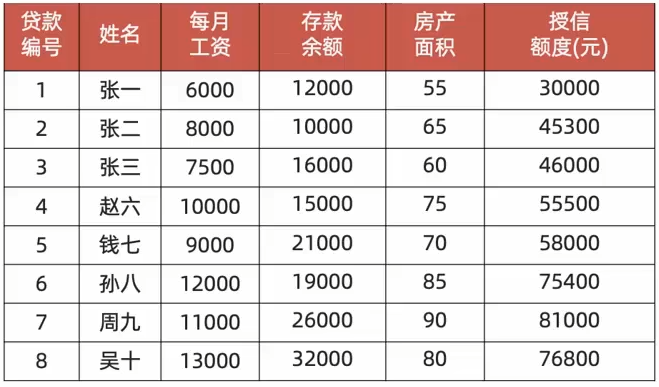
现在将之前的贷款数据带入(先假设,学习率α=0.001,
=1),则计算如下:
第1个样本,在偏置分量上产生的梯度:
第2个样本,在偏置分量上产生的梯度
第3个样本,在偏置分量上产生的梯度:
接着第4到第8个的样本计算的结果分别是:-30424、-27929、-44314、-43909、-31719。所以开始的的平均梯度为-29989,从而更新
的梯度为
。
基于上述公式,对剩下三列进行梯度更新计算:
计算在每月工资上产生的梯度,的梯度为:
计算在存款余额上产生的梯度,的梯度为:
计算在房产面积上产生的梯度,的梯度为:
再利用梯度下降公式更新:
经过第1轮迭代:初始值θ1,1,1,1迭代成θ30.989, 305768.94, 602022.125, 2284.29,如此多次迭代后,就可以计算出最终的向量θ。
二.梯度下降法分类
1.全梯度下降法(FGD)
每次迭代时,使用全部样本的梯度值,也就是有m个样本,求梯度时用了所有m个样本。
2.随机梯度下降法(SGD)
每次迭代时,随机选择并使用一个样本梯度值。
3.小批量梯度下降法(mini-batch)
每次迭代,随机选择并使用小批量的样本梯度值,也就是从m个样本中,选择x个样本进行迭代。若其batch_size=1,则就变成了SGD,若batch_size=n,则就变成了FGD。
4.随机平均梯度下降算法(SAG)
每次迭代时,随机选择一个样本的梯度值和以往样本的梯度值的均值。具体方式如下:
①随机选择一个样本,假设选择D样本,计算其梯度值并存储到列表D,然后使用列表中梯度的均值,更新模型参数。
②随机再选择一个样本,假设选择G样本,计算其梯度值并存储到列表D,G,然后使用列表中梯度的均值,更新模型参数。
③随机选择一个样本,假设又选择D样本,重新计算该梯度值并更新列表中D样本的梯度值,然后使用列表中梯度的均值,更新模型参数。
④以此类推,直到算法收敛。
5.带冲量/高阶优化的梯度下降
本质上是为传统梯度下降引入了"惯性"和"自适应步长"两种增强机制:基于冲量的方法(如Momentum、NAG)通过累积历史梯度来获得持续加速能力,有效抑制震荡并穿越局部极小;自适应学习率方法(如AdaGrad、RMSprop)则为每个参数单独维护步长,使稀疏特征更新更快、稠密特征更新更稳;而融合型算法(如Adam)同时结合了一阶动量(方向惯性)和二阶动量(尺度自适应)并加入偏差修正,成为目前深度学习中收敛最快、最鲁棒的默认选择,解决了传统梯度下降在平坦区、峡谷区和鞍点处效率低下的核心痛点。
对于上述五种分类,总的来说批量梯度下降(BGD)优点为梯度精确、收敛稳定,缺点是大数据集下计算极慢且易陷局部最优;随机梯度下降(SGD)计算快、能跳出局部最优,但梯度震荡剧烈、收敛不稳定;小批量梯度下降(Mini-batch)平衡了效率与稳定性,是深度学习的常用基线,但仍需手动调学习率;随机平均梯度(SAG)通过记忆历史梯度实现线性收敛,却面临巨大内存开销且不适合非凸问题;带冲量/高阶优化的方法(如Adam)引入惯性累积与自适应步长,收敛极快且鲁棒性强,已成为默认首选,但超参数增多且泛化有时不如精心调参的SGD。
三.梯度下降法与正规方程法对比
梯度下降法是一种迭代优化算法,通过不断沿负梯度方向更新参数来逼近最优解,其计算复杂度为 O(k⋅m⋅n)(k为迭代次数,m为样本数,n为特征数),在大数据集(百万级样本或万级特征)下仍能高效运行,但需要手动调整学习率和迭代次数,且结果受初始值影响;正规方程法则通过直接求解解析解一步完成参数计算,无需迭代和调参,但其核心瓶颈在于矩阵求逆的计算复杂度高达 O(n3),当特征数 n 较大(如超过 104)时计算极慢甚至内存溢出,且要求
可逆。
因此,选择取决于特征规模和数据类型:当特征数较小(通常 n<104)且样本量适中时,正规方程法简单直接、无需调参,更适合线性回归等凸优化问题;当特征数庞大(如图像、文本数据)、样本量极多或模型为非线性(如神经网络、逻辑回归)时,梯度下降法(尤其是小批量或Adam变体)是唯一可行的选择,尽管需要调参,但其灵活性和可扩展性使其成为大规模机器学习的主流方法。
四.回归模型的评估方法
1.平均绝对误差(MAE)
MAE计算预测值与真实值之间绝对差值的平均值,公式为。它对所有误差一视同仁,使用绝对值而非平方,因此对异常值不敏感,鲁棒性较强。MAE的评价结果与原始数据同量纲,解释直观,但其导数不连续,在优化求解时不如MSE方便。
2.均方误差(MSE)
MSE计算预测值与真实值之间差值平方的平均值,公式为。由于误差被平方,它对较大误差的惩罚远大于小误差(异常值会被显著放大),这使得MSE对异常值极其敏感,但同时也引导模型更加关注减少大幅偏差。MSE处处可导,是许多回归算法(如线性回归)中损失函数的首选。
3.均方根误差(RMSE)
RMSE是MSE的平方根,公式为。它继承了MSE对大误差敏感的特性,但最关键的优势是将误差尺度恢复到了原始数据单位,解决了MSE量纲为平方量级导致不直观的问题(例如房价预测中,MSE是"元²",而RMSE是"元")。因此RMSE是三者中最常用的评估指标------既保留了MSE对大幅偏差的惩罚特性,又具有与MAE同等的直观可解释性。
总结
本文系统讲解了多变量梯度下降的数学原理与实现过程。从二元函数示例到银行信贷案例,揭示了梯度下降的核心机制。通过对五种梯度下降变体的分类对比,阐明了不同方法在计算效率与收敛稳定性上的权衡:FGD精确但计算昂贵,SGD快速但震荡剧烈,Mini-batch兼顾效率与稳定,Adam通过动量与自适应步长成为深度学习首选。文章还对比了梯度下降与正规方程法的适用条件,并介绍了MAE(对异常值鲁棒)、MSE(对大误差敏感)、RMSE(量纲直观)三种评估指标的特点。理解这些优化方法与评估手段,是掌握线性回归模型训练与评价的关键。