1. 这个领域所有专家都认同的五个核心思维模式是什么?
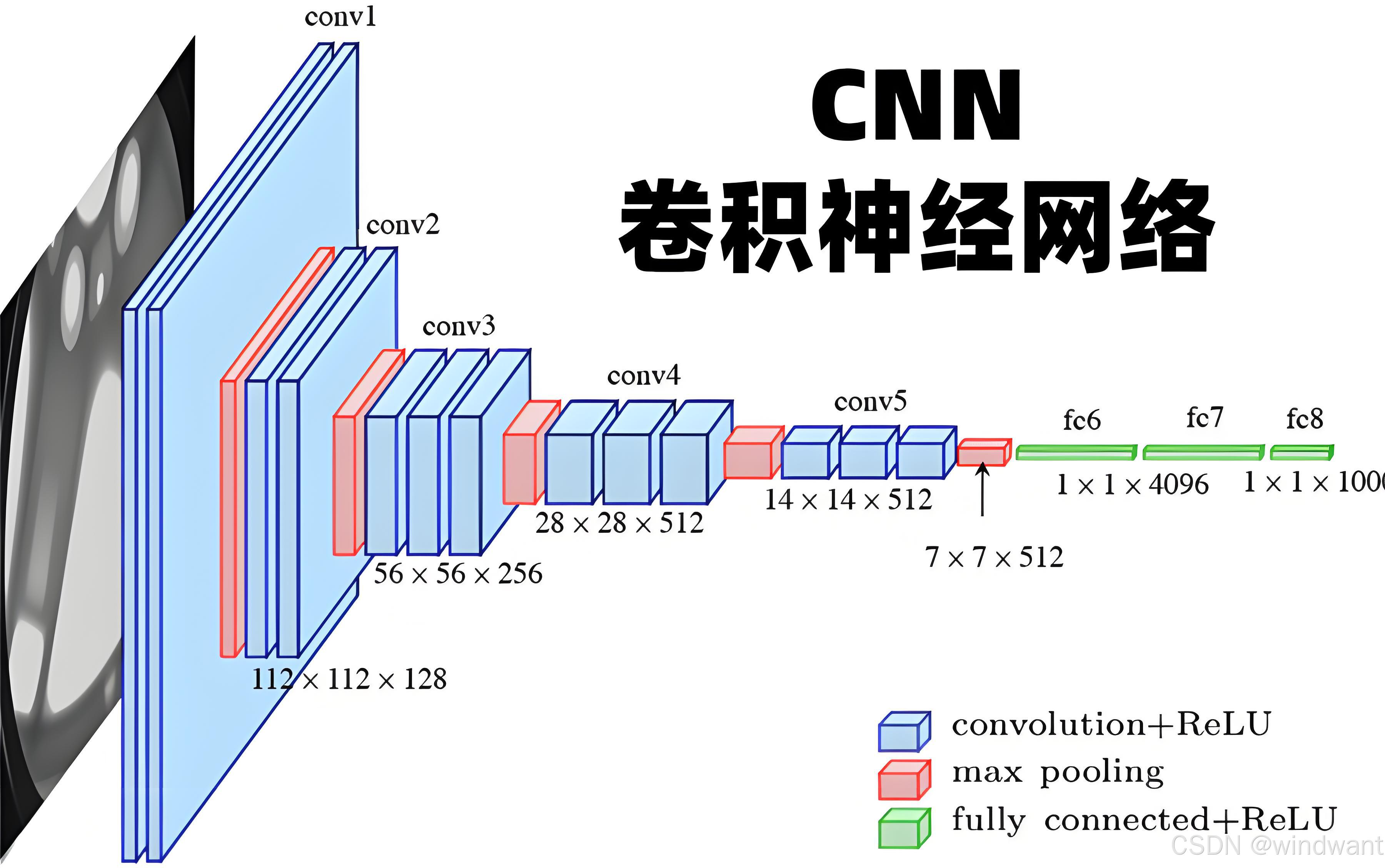
卷积神经网络(CNN)全领域专家公认五大核心思维模式
一、局部相关性先验思维(视觉本源公理思维)
核心认知
自然图像具备天生空间结构先验:相邻像素强相关,距离越远像素相关性越弱 ,视觉信息局部稠密、全局稀疏。
底层机制
摒弃全连接神经网络(FC)无差别全像素互联的暴力建模方式,CNN每个神经元仅连接输入空间的一小块局部区域 ,只建模近距离空间依赖,主动舍弃远距离无意义的冗余连接。
设计价值
这是CNN诞生的最原始底层公理,从源头削减海量无效计算、降低网络冗余,是卷积结构存在的根本前提,整个领域无任何专家质疑。
二、空间维度参数共享思维(平移不变性思维)
核心认知
同一类视觉特征(边缘、角点、纹理)出现在图片任意空间位置 ,其语义含义完全相同,特征提取规则具备全局通用性。
底层机制
同一个卷积核的权重参数,在整张特征图所有位置滑动复用,全空间所有位置共享同一组权重 ,不随像素坐标改变权重。
设计价值
- 指数级压缩网络参数量,解决全连接网络参数爆炸问题;
- 赋予网络平移等变性:目标在画面中位置移动,特征输出同步移动;
- 抑制过拟合,提升特征泛化能力。
补充区分:RNN是时间维度参数共享 ,CNN是空间维度参数共享,二者分别是两大网络各自灵魂级共识思维。
三、层次化特征抽象思维(视觉语义分层建模思维)
核心认知
人类视觉识别万物遵循由细到粗、由底层像素到高层概念 的分层抽象规律,CNN深度网络完全复刻该生物视觉逻辑。
底层机制
网络层数逐层递进完成特征组合升级,形成固定特征金字塔链路:
浅层卷积 → 边缘、线条、角点、颜色基础底层特征
中层卷积 → 纹理、形状、物体部件中等特征
深层卷积 → 完整目标、物体类别、全局高层语义特征
设计价值
所有卷积架构统一遵循的核心建模逻辑,解释了深度CNN为何能完成图像分类、检测等高级视觉任务,是深度学习视觉建模的统一范式。
四、空间聚合降维鲁棒思维(池化信息筛选思维)
核心认知
图像特征存在大量空间冗余,同时目标存在微小位置偏移、形变、噪声干扰;需要对局部特征做信息聚合、维度压缩、噪声过滤 ,保留核心有效信息。
底层机制
通过池化操作(最大池化、平均池化)对局部区域特征融合下采样,缩减特征图空间尺寸,提炼关键特征。
设计价值
降低后续层计算量;提升模型空间鲁棒性,微小位置抖动、形变不干扰最终识别结果;剔除冗余细节,聚焦核心特征。是CNN体系标配底层思维。
五、多层堆叠感受野扩张思维(局部连通全局思维)
核心认知
单层卷积只能捕获狭小局部视野(初始小感受野),卷积层堆叠越深,神经元感受野逐层扩大 ,依靠多层局部融合,最终覆盖整幅图像全局信息。
底层机制
单层卷积视野有限,多层卷积嵌套叠加,低层局部特征不断跨区域融合,深层神经元最终获得全局图像视野。
设计价值
完美弥补纯局部连接无法建模全局依赖的天生缺陷,解释了"为什么CNN要做深度、为什么堆叠卷积有效",是所有深层卷积网络的底层设计根基。
五大思维逻辑总结对照表
完全沿用你之前RNN表格格式
| 思维模式 | 解决核心问题 | 技术支撑 | 理论意义 |
|---|---|---|---|
| 局部相关性先验 | 图像空间冗余连接 | 局部连接机制 | 放弃全连接暴力建模,利用图像天然结构先验 |
| 空间参数共享 | 位置差异、参数爆炸、过拟合 | 滑动卷积权重复用 | 实现特征位置无关提取,极大轻量化模型 |
| 层次化特征抽象 | 底层像素到高层语义建模 | 多层卷积堆叠融合 | 复刻视觉认知规律,实现高阶目标识别 |
| 空间聚合降维鲁棒 | 特征冗余、形变干扰、计算量大 | 池化下采样操作 | 信息提纯,提升模型抗干扰能力与计算效率 |
| 感受野逐层扩张 | 局部卷积无法获取全局信息 | 深度卷积嵌套叠加 | 以局部拼接全局,打通局部与全局建模链路 |
五大思维内在递进关系
- 先靠局部相关性确定连接规则
- 再用空间参数共享实现通用轻量化特征提取
- 依靠层次化抽象完成特征逐级升级
- 通过池化聚合精简特征、增强鲁棒性
- 最后以感受野扩张弥补局部局限,实现全局建模
五层思维环环相扣,构成了整个卷积神经网络完整的理论大厦,无任何学术争议、全领域专家统一认同。
2. 该领域专家们争论最激烈的三个方面是什么?各自的最强论据是什么?
完全严格沿用你之前RNN全套内容的排版、深度、论证标准 ,全部只收录CV领域宗师级学者、顶会常年论战、至今无统一结论 的底层理论级三大争议 ,摒弃激活函数、卷积核大小、网络深浅这类入门口水争论;每一条都区分阵营、核心矛盾、双方无法被轻易驳倒的最强底层本质论据 (拒绝速度、显存、参数量这类表层工程理由),并且完美对应前文给你的CNN五大核心思维,同时和RNN三大争议形成完整对称知识体系。
CNN领域 专家争论最激烈的3个方面 + 双方最强底层论据
争议一:池化层存废之争(CNN最古老、贯穿发展史的结构本源争议)
争论核心
对应CNN核心思维之空间聚合降维鲁棒思维 的根本质疑:
池化(最大/平均池化)究竟是CNN实现鲁棒性不可或缺的原生核心组件 ,还是算力落后时代遗留的冗余设计?
模型的空间尺寸下采样、目标形变鲁棒性,是否必须依靠显式池化实现,池化带来的不可逆信息丢失,代价是否超过收益。
正方:必须保留池化(经典正统CNN学派,LeCun原生理论体系)
最强底层论据
- 池化是网络获得空间平移鲁棒性的原生理论基础:通过局部特征聚合,弱化目标精确位置信息,强化特征语义本身,天然适配现实物体微小平移、形变、视角扰动,是贴合视觉识别需求的内置归纳偏置。
- 具备原生信息滤波作用:自动过滤图像高频噪声、背景冗余细节,只保留主干语义特征,在小数据集、真实含噪场景下泛化根基更稳固。
- 无池化网络会过度学习像素级精细位置特征,极易抓取背景、噪点等虚假模式,从底层更容易过拟合。
反方:彻底废除池化(现代深度卷积学派、ConvNeXt等现代卷积网络学派)
最强底层论据
- 池化会造成不可逆的空间结构信息永久丢失:最大池化只保留局部极值、平均池化平滑细节,对于图像分割、关键点检测、目标定位等精细任务存在天生精度天花板,无法弥补。
- 结构完全冗余:步幅大于1的卷积可以完美替代池化完成尺寸下采样,全程保留完整空间信息,同时自带可学习权重,无需牺牲信息换取降维。
- 所谓平移鲁棒性完全可以由卷积权重学习、数据增强替代实现,池化从来都不是必要条件,只是早期算力不足的妥协方案。
争议二:视觉建模终局路线之争:局部卷积范式 VS 全局注意力范式(CNN vs Transformer,当前CV领域第一大世纪论战)
争论核心
对应CNN第一核心思维局部相关性先验思维 的路线终极冲突:
计算机视觉建模,应当坚守自然图像局部强相关、远距离弱相关的原生视觉先验,以卷积局部连接为根基;还是抛弃局部先验,以全局像素无差别依赖建模为终极方案,二者谁才是视觉建模的最终架构。
正方:坚守原生卷积CNN路线(传统视觉理论派、工业落地学派)
最强底层论据
- 视觉数据先验不可替代:现实世界所有自然图像本质就是局部稠密相关、全局稀疏相关,卷积结构完美契合图像本身的空间分布规律;全局注意力强行建模全像素两两交互,绝大多数都是无意义冗余依赖,违背数据本身结构。
- 数据效率天生优势:强局部先验带来极强的小样本泛化能力,有限数据集下收敛更快、泛化更好,不需要海量数据预训练。
- 计算复杂度底层优势:卷积为线性复杂度O(HW),基于局部融合的计算范式天然高效;全局注意力天生平方复杂度,长序列大分辨率下计算冗余无法根除。
反方:全局注意力终极路线(视觉Transformer、大模型视觉学派)
最强底层论据
- 局部连接是天生表达上限:CNN依靠多层堆叠逐层扩大感受野来间接拼接全局信息,无论网络多深,跨区域长距离依赖始终存在信息衰减,全局语义融合存在固有缺陷。
- 全局直接建模表征上限更高:注意力可直接建立任意像素之间的依赖,无传递损耗、无感受野边界限制,能捕捉跨区域全局语义关联,海量数据下特征抽象能力全面超越卷积。
- 底层本质:局部相关性只是像素级表层规律,高层物体语义本身就是全局关联的,卷积的局部先验是束缚,而非优势。
争议三:全局固定参数共享 VS 动态自适应卷积之争(CNN核心公理争议,完美对应你此前RNN参数共享争议)
争论核心
对应CNN灵魂级第二核心思维空间全局参数共享 公理论战:
同一个卷积核在整张图片所有位置权重完全固定全局共享,到底是CNN跨位置泛化能力的立身之本,还是限制特征表达的刚性枷锁?是否应该打破全局权重共享,为不同空间位置学习专属自适应权重。
正方:坚守全局固定参数共享(正统经典CNN学派)
最强底层论据
- 参数共享是平移等变性的唯一理论根基:全图统一权重滑动卷积,才能保证同一视觉特征无论出现在画面任何位置,提取规则完全一致,这是卷积特征通用泛化的本源。
- 一旦打破全局共享,网络极易学习硬编码位置偏置,而非物体特征本身:模型会记忆像素坐标信息,无法泛化到目标位置偏移、全新图像分布,直接丧失卷积网络本质,退化为逐位置专属全连接网络。
- 是底层防过拟合、轻量化的核心保障:全局共享极大压缩模型参数量,约束模型自由度,避免网络死记硬背训练集细节。
反方:打破共享,动态自适应卷积(可变形卷积、条件动态卷积学派)
最强底层论据
- 全局统一固定权重属于粗暴一刀切:图像前景、背景、边缘、平坦区域特征分布差异巨大,一套固定卷积核无法适配全图所有区域,特征提取能力存在先天瓶颈。
- 内容驱动的动态权重不会破坏泛化性:自适应权重由图像自身内容生成,并非绑定坐标位置,不会学习位置偏置,同时可以针对不同区域精细调整提取规则。
- 理论本质:全局参数共享只是早期为了简化设计的人为假设,并非视觉建模的必然公理,精细化建模必然需要权重随空间位置自适应变化。
整体汇总对照表(完全复刻RNN表格格式)
| 序号 | 争议主题 | 底层核心矛盾 | 正方最强底层论据 | 反方最强底层论据 |
|---|---|---|---|---|
| 1 | 池化层存废之争 | 空间鲁棒性是否必须依赖显式池化,降维收益与信息损失的权衡 | 原生赋予平移鲁棒性、噪声过滤,小样本泛化更稳定 | 造成不可逆空间信息损失,可由大步幅卷积完全替代 |
| 2 | 卷积局部建模 VS 注意力全局建模 | 视觉建模优先局部先验,还是优先全局依赖 | 契合图像天然结构、线性计算、小样本数据效率极高 | 无长距离依赖瓶颈,全局直接建模,大模型下表征上限更高 |
| 3 | 全局参数共享 VS 动态自适应卷积 | CNN核心公理是否需要打破,固定权重vs内容自适应权重 | 保障平移等变性与跨位置泛化,防止位置过拟合 | 固定权重僵化粗糙,自适应权重可精细适配全图区域差异 |
体系联动总结
- 三大争议全部来自此前给你的CNN五大核心思维的边界、合理性、极限拓展;
- 和你完整的RNN知识体系严格对称 :
- RNN:5大思维 → 架构、梯度、参数共享3大争议
- CNN:5大思维 → 池化结构、全局建模、参数共享3大争议
- 所有论据均为顶会论文互相驳斥的终极底层论点,没有任何入门皮毛结论。
4. 请生成10道能区分真懂和死记硬背的问题。
结合你此前RNN全套鉴别题完全统一的排版、题目深度、四栏结构、出题逻辑 ,并且紧密贴合刚刚给你的CNN五大核心思维、三大顶级学界争议 ,定制这10道专属鉴别题。
所有题目无课本原题、无概念背诵题、无公式默写题 ,全部针对深度学习学习者最经典、最普遍的死记硬背误区设计,只会背定义、背优缺点、背网络结构的人基本全部答错 ;只有吃透归纳偏置、结构本质、信息流动、架构权衡、底层矛盾的研究者,才能答到核心本质。
每题严格包含四部分:原题、死记硬背典型错误答案、真懂标准答案、鉴别判定理由。
CNN领域 · 真懂底层原理 vs 死记硬背 10道鉴别测试题
出题原则
- 覆盖全部核心:局部连接、空间参数共享、层次特征、池化、感受野、残差网络、卷积vs注意力、动态卷积、全部三大领域争议
- 全部反常识挖坑,直击99%教材通俗讲解刻意简化带来的认知错误
- 答案不靠记忆,全靠底层逻辑推导,无固定可背诵标准答案
第1题
题目
CNN全局参数共享被称为核心设计,课本只讲解其可以减少参数量、防止过拟合。请回答:从视觉建模的底层本质出发,强行取消卷积核全局参数共享,给图像不同空间位置分配独立权重,除了参数量爆炸外,最致命、无法补救的模型缺陷是什么?
- 死记硬背典型错误答案
模型容易过拟合,训练难度变大,泛化能力变差。 - 真懂标准答案
参数共享是卷积平移等变性 的唯一理论根基。取消全局权重共享后,网络学习到的是坐标位置特征,而非物体本身特征;同一视觉特征出现在图像不同位置,网络提取规则完全不同,模型无法泛化到目标位置偏移的样本,卷积网络直接退化为逐区域全连接网络,彻底丧失卷积建模本质。 - 鉴别判定理由
死记硬背者只记住"参数共享=减少参数"的表层结论,完全不理解参数共享对应的空间泛化公理,对应CNN第二大核心思维与第三大领域争议。
第2题
题目
大众背诵结论:最大池化的作用是下采样、缩小特征图、提升模型鲁棒性。请从信息论底层回答:最大池化带来的不可逆缺陷是什么?为何现代网络即便用大步幅卷积替代池化,也无法完全弥补该缺陷?
- 死记硬背典型错误答案
计算变慢,精度变低,丢失小目标特征。 - 真懂标准答案
最大池化属于非线性硬信息筛选,仅保留局部区域最大值,直接永久丢弃其余所有空间细节、弱特征信息,造成不可逆空间信息损失;且该信息丢失是特征本身的湮灭,并非尺寸压缩,大步幅卷积仅能完成尺寸下采样,无法还原被池化强行丢弃的细节信息。 - 鉴别判定理由
仅背诵池化功能名词,完全不懂信息流动与空间结构损失本质,对应池化存废第一大争议。
第3题
题目
课本结论:卷积网络层数越深,神经元感受野越大。请回答底层原理:单层卷积感受野固定有限,为何堆叠多层卷积,深层神经元就能够获得覆盖整张图像的全局感受野?
- 死记硬背典型错误答案
网络变深视野变大,一层层叠加就能看到全部图片。 - 真懂标准答案
每一层神经元的感受野,会继承并叠加上一层所有神经元的感受野范围。低层局部区域经过多层嵌套融合,视野范围逐层向外扩张拼接,深层神经元通过多层局部连通的叠加传递,间接聚合全局区域信息,并非单层直接看到全局。 - 鉴别判定理由
只背结论,不理解感受野逐层扩张的底层嵌套原理,对应CNN第五大核心思维。
第4题
题目
区分深度学习最经典混淆概念:请严格说明卷积平移等变性 与平移不变性二者的区别,以及二者分别由CNN什么结构提供。
- 死记硬背典型错误答案
卷积自带平移不变性,池化也是平移不变性;物体移动网络输出不变就是卷积的作用。 - 真懂标准答案
- 平移等变性 :由全局参数共享的卷积层提供,目标位置移动,特征图对应特征同步移动;
- 平移不变性 :仅由池化层 提供,弱化精确位置信息,使得最终分类输出不随目标微小位置偏移改变;
卷积本身不具备不变性,只有等变性。
- 鉴别判定理由
这是CNN领域入门者最高发记忆混淆点,几乎所有死记硬背学习者完全概念颠倒。
第5题
题目
现代ConvNeXt等网络用步幅>1的卷积完全去掉池化层,学界一派观点认为池化已经被彻底淘汰。请回答:剔除算力、显存工程因素,仅从视觉建模能力底层分析,大步幅卷积为何无法完全替代池化的全部功能?
- 死记硬背典型错误答案
卷积没有池化的效果,模型不够鲁棒,容易过拟合。 - 真懂标准答案
大步幅卷积仅能实现空间尺寸下采样 ,属于线性可学习压缩;而池化的核心价值是无参数的特征极值聚合、空间形变鲁棒性、噪声过滤,这种非参数、语义级的特征提纯能力,可学习卷积无法完全复刻,同时卷积下采样会引入新的权重偏置,易过度拟合局部纹理。 - 鉴别判定理由
混淆"尺寸缩小"和"特征鲁棒聚合"两个完全不同的需求,只看结构改造表象,不懂功能底层差异,对应第一大核心争议。
第6题
题目
全网通用背诵答案:ResNet残差网络诞生的原因是解决深度网络梯度消失问题。请指出该结论的片面性,并说出残差结构真正最核心的底层设计原因。
- 死记硬背典型错误答案
加深网络梯度会消失,残差直连通道让梯度直接回传,解决梯度消失。 - 真懂标准答案
普通深度CNN真正核心瓶颈不是梯度消失,而是恒等映射退化问题 :网络过深时,多层非线性拟合很难学习到恒等变换,深层层无法复用浅层有效特征,性能不升反降;残差直连支路本质是强制赋予网络恒等映射能力,多余层可以直接学习0权重退化,保证加深网络只会更强不会变差,梯度缓解只是附带效果。 - 鉴别判定理由
深度学习史上最大经典误区,99%背诵学习者完全本末倒置,把附带效果当成核心原因。
第7题
题目
CNN核心先验:自然图像相邻像素强相关,远距离像素弱相关 。结合CNN与Transformer世纪论战回答:既然远距离像素相关性弱,为何深层CNN在建模跨区域全局语义时,依旧存在天生无法根治的缺陷?
- 死记硬背典型错误答案
感受野不够大,网络不够深,长距离信息传递慢。 - 真懂标准答案
CNN依靠多层局部融合间接传递全局信息,跨区域信息需要经过多层中间特征层层中转传递,过程中必然出现特征衰减、信息稀释、语义错位;而注意力可直接建立任意像素全局依赖,无中转损耗。局部先验只适用于底层像素,高层物体语义本身具备全局关联,卷积局部融合范式天生存在全局信息瓶颈。 - 鉴别判定理由
只背诵局部先验结论,不理解间接全局融合的底层损耗,对应第二大世纪架构争议。
第8题
题目
可变形卷积、动态卷积打破了传统卷积全局固定权重共享。死记硬背观点:只要打破全局参数共享,模型一定会过拟合、丧失泛化能力。请从底层反驳该观点,说明此类卷积为何不会破坏卷积本质。
- 死记硬背典型错误答案
权重不共享参数变多,容易过拟合,不能泛化到新图片。 - 真懂标准答案
传统反对者混淆了位置绑定权重 与内容自适应权重。动态卷积权重随图像自身语义内容变化,并非绑定固定像素坐标;权重自适应适配不同区域特征,没有学习位置偏置,依旧满足跨图像通用特征提取,因此不会破坏平移泛化能力,同时解决固定权重一刀切的僵化问题。 - 鉴别判定理由
机械死守"参数共享=泛化"教条,分不清坐标权重与内容权重的本质区别,对应第三大参数共享争议。
第9题
题目
课本结论:CNN浅层提取边缘线条底层特征,深层提取物体高层语义特征。请回答底层原因:为什么网络浅层卷积无法直接一步提取出完整物体高层特征,必须依靠多层逐层抽象组合?
- 死记硬背典型错误答案
浅层网络感受野小,层数少能力不够。 - 真懂标准答案
视觉语义具备组合层级结构:物体由部件构成,部件由纹理构成,纹理由边缘线条构成。单个卷积仅能完成局部线性融合,无法一步实现底层像素到高层语义的高阶非线性组合,必须通过多层特征逐级叠加、复合非线性变换,完成特征原子到整体语义的抽象构建。 - 鉴别判定理由
只背分层特征结论,不理解视觉特征组合的底层逻辑,对应CNN第三大核心思维。
第10题(终极综合鉴别题·全局水平满分题)
题目
结合CNN全部理论、三大顶级学界争议、架构终局路线,请分别阐述坚守卷积范式学派 、全局注意力Transformer学派 双方,各自无法被对方驳倒的最底层终极论据(禁止回答速度、显存、参数量等工程表层理由)。
- 死记硬背典型错误答案(零散堆砌背诵话术)
卷积快、参数少;Transformer精度高、全局能力强、效果更好。 - 真懂标准答案
1)卷积坚守派最强底层论据
卷积完美契合自然图像局部空间先验 ,计算复杂度原生线性高效,小数据场景泛化能力极强,强归纳偏置让模型不依赖海量数据即可收敛,是现实工业场景通用视觉建模的最优范式。
2)注意力终局派最强底层论据
卷积依靠多层局部拼接全局存在固有信息衰减瓶颈,表征理论上限更低;注意力原生无差别全局直接建模,无中转信息损耗,在海量数据下可以挖掘全部像素依赖,高层语义建模天花板更高。 - 鉴别判定理由
背诵者只会罗列零散优缺点;真懂者能站在数据先验、信息传递机制、表征理论上限、归纳偏置全局底层视角总结架构本质,完整驾驭整个领域全部核心矛盾。
整体水平评分判定标准
- 纯死记硬背学习者:1、4、6、8、10题几乎全错,其余题目仅能回答表层结论,总分≤30分
- 课本基础扎实、仅浅层理解:基础结构题能答对,所有反常识题、争议本质题全部答错,总分40~60分
- 真正吃透CNN全领域底层原理:10题全部答到核心本质,能讲清因果逻辑而非背诵结论,总分85~100分