我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:秋筠
一、背景与痛点:为什么需要 OpenSpec?
AICoding 领域,模型的逻辑推理能力在短小上下文中表现卓越,但在大型工程环境中,模型面临两大挑战:
- 上下文中毒:无关信息污染上下文,模型误将噪声当作重要信息
- 注意力漂移:长对话中逐渐偏离原始需求,产生幻觉或偏离预期
单纯依靠增加大语言模型的参数规模已无法解决复杂业务逻辑中的幻觉与失控问题。
OpenSpec 倡导的是一种「规格驱动开发」(Spec-Driven Development)范式。其核心理念是:在写任何一行代码之前,先由人类与 AI 共同协商并锁定一份机器可读、人可评审的规格文档。需求是什么、技术方案怎么设计、实现步骤有哪些------全部以 Markdown 文件持久化在项目里。AI 每次开工,不是从你的口头描述出发,而是从这份规格文档出发。
同样都是「先写规范再写代码」的开源 SDD 框架,OpenSpec(github.com/fission-ai/... 展现出了极高的工程性价比,无论是使用 Claude Code、Cursor 还是 Aider,都可以无缝接入 OpenSpec 的规格管理层。OpenSpec 对存量代码库的需求场景,相当友好,相比 Spec Kit 擅长的新项目场景,对于很多公司的开发更为适合。
| 维度 | Spec Kit | OpenSpec |
|---|---|---|
| 出品方 | GitHub | Fission AI |
| 设计思路 | 严格门控,步步审查 | 依赖图驱动,灵活迭代 |
| 擅长场景 | 新项目从零开始(Greenfield) | 已有代码库增量开发(Brownfield) |
| 规范体量 | 较重,单阶段可达 800+ 行 | 较轻,文档约 250 行 |
| 流程自由度 | 线性,不能跳步 | 非线性,随时可以回改 |
| 协作友好度 | 直接改主规范,多人易冲突 | 变更隔离,archive 时合并 |
| Token 消耗 | 较高 | 较低 |
| 变更追踪 | 无内建机制 | Delta Spec + 归档历史 |
二、安装与初始化
2.1 安装
bash
# 前置条件:Node.js 20.19.0+
npm install -g @fission-ai/openspec@latest2.2 初始化
bash
# 命令行方式进入到你的项目
cd your-project
# 初始化
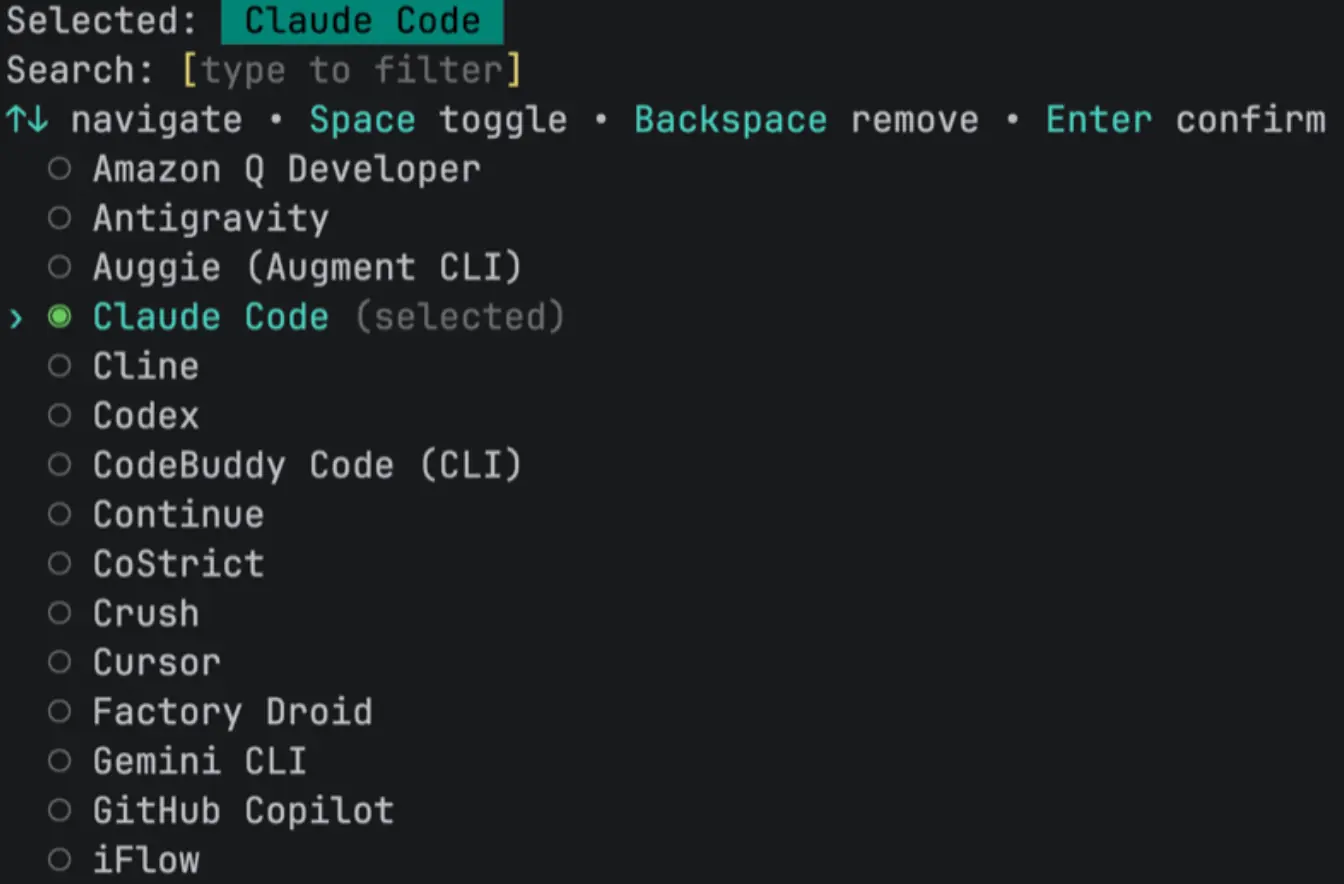
openspec init初始化时 CLI 会问你使用哪些 AI 工具(Claude Code、Cursor、Copilot 等),然后自动往对应目录写入 Skill 和斜杠命令文件。由于我使用的 Claude Code,便选择了对应的 Agent。
Space 选择,Enter 确认
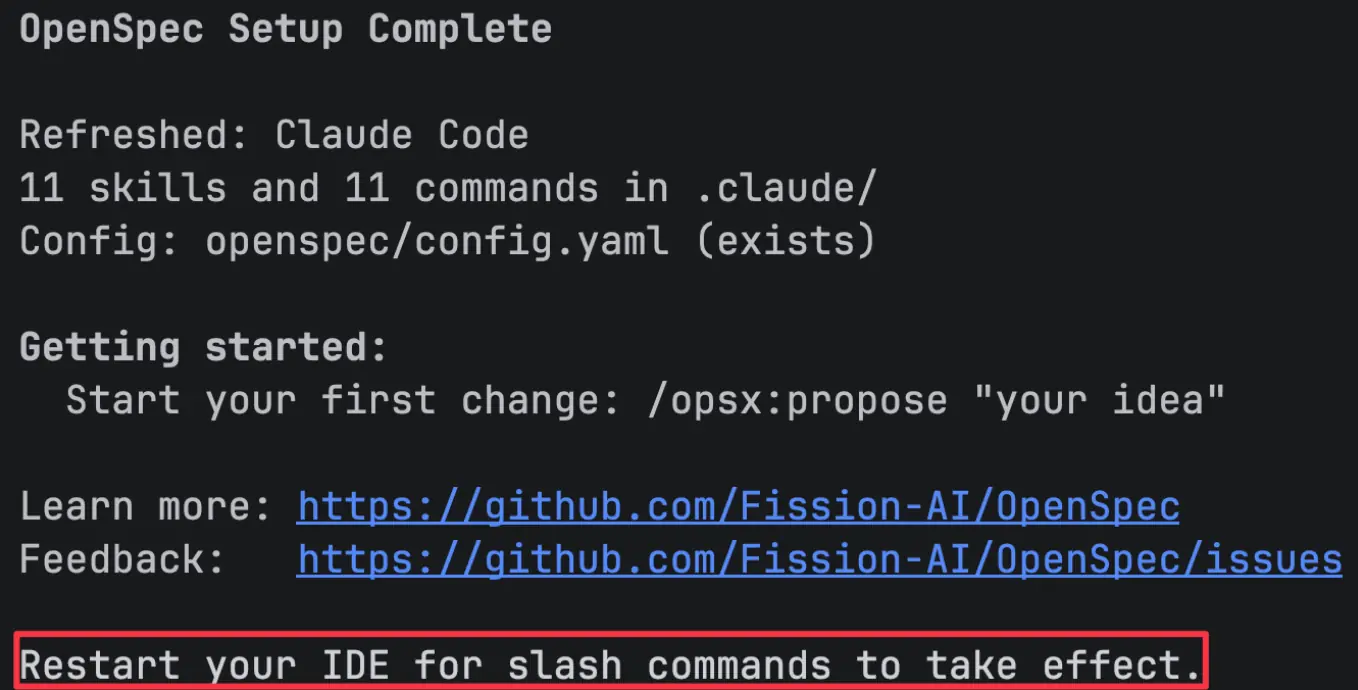
注意:初始化完成后,需要重启 ide 才能生效。
完成后项目里多出一个 openspec/ 目录:
latex
openspec/
├── specs/
├── changes/
└── config.yaml # 项目配置2.3 配置项目上下文(可选,建议配置)
这一步经常被跳过,但它对工件质量影响巨大。在 openspec/config.yaml 里告诉 AI 你的项目是什么样的:
yaml
schema: spec-driven
# Project context (项目上下文)
# 此信息将在创建各种 artifacts 时提供给 AI 参考
context: |
## 项目概述
XXX 系统(Engine)是数据平台的核心调度引擎,负责将不同类型的任务(Job)提交到对应类型的执行引擎组件上运行。
核心功能:
- 向上:接收平台各应用提交的任务(Job)
- 内部:负责任务的负载均衡 & 优先级调度
- 向下:将各种类型的任务真正提交(submit)到具体的执行引擎组件上
## 技术栈
## 模块结构
## 代码规范
## 测试规范
## Git提交规范
# Per-artifact rules (每个artifact的规则)
rules:
proposal:
- 提案应简洁明了,包含背景、目标、方案概述
- 方案设计需考虑向后兼容性
tasks:
- 每个任务应可独立完成和测试
- 任务粒度适中,避免过大或过细
- 需要标明任务涉及的模块和文件路径context 会注入到所有 工件的生成过程中------相当于一次配置,以后再也不用在对话开头反复交代技术栈了。rules 则是针对特定工件类型的额外要求。
可以让 AI 先生成,然后自己修改:
latex
请阅读 openspec/config.yaml 并帮我填写项目详情、技术栈和约定等强烈建议该规范文件在组内按照项目维度持续迭代,如果需要更新规范也尽量让 Claude 自己生成,AI 最能理解 AI 生成的规范。
三、项目结构与关键产物
openspec 结构如下:
latex
openspec/
├── specs/ # 系统当前行为的「源真相」(Source of Truth) ← 「系统现在是什么样的」
├── changes/ # 每个变更的独立工作目录 ← 「我们打算改什么」
├── archive/ # 已完成变更的归档目录 ← 「历史记录」
└── config.yaml # 项目配置目录说明:
| 目录 | 作用 | 内容示例 |
|---|---|---|
specs/ |
Main Specs,系统当前行为的权威描述 | user-auth.md、api-specs.md |
changes/ |
活跃变更的工作目录 | add-dark-mode/、fix-login/ |
archive/ |
已归档变更的历史记录 | 2026-02-27_add-dark-mode/ |
config.yaml |
项目级配置文件 | context、rules 等 |
Specs(主规格) 是系统当前行为的权威描述------「源真相」。它回答的是「系统现在是怎么运作的」。
Changes(变更) 是你正在进行的修改------每个功能、每个 Bug 修复独立一个文件夹,互不干扰。它回答的是「我们打算怎么改」。
每个变更(Change)都被组织在独立的文件夹中,包含 4 个工件,它们之间有明确的依赖关系:
latex
proposal.md → specs/ → design.md → tasks.md
为什么做? 做什么? 怎么做? 具体步骤- proposal.md:描述变更的初衷和范围。
- **specs/:具体的逻辑规格,通常包含 "Scenario(场景)" 描述,通过具体的输入输出消除模糊性。这里存放的是 Delta Specs(增量规格)**,仅描述本次变更涉及的行为变化。
- design.md:技术设计方案,包括本次变更涉及的数据库变更、接口调整等。
- tasks.md:原子化的任务清单,作为 AI 的执行路径图。
这个依赖关系是**「使能」而不是「门禁」**。意思是:有了 proposal 才能生成 specs,有了 specs 才能生成 design------但这是 AI 生成工件时需要的输入,而不是说你必须按这个顺序来。你完全可以先写 design 再补 specs,或者直接跳到 tasks,流程是灵活的。
Delta Specs 与 Main Specs 的关系:
openspec/specs/:Main Specs,描述系统当前的完整行为,是「源真相」openspec/changes/<name>/specs/:Delta Specs,描述本次变更带来的行为变化- 归档时,Delta Specs 会自动合并到 Main Specs,保持源真相的更新
四、核心命令与使用场景
OpenSpec 分为默认快速模式 和扩展全量模式,新安装默认启用快速模式。
整体工作流程图:

4.1 工作流模式选择
快速模式(Core Profile)
适合简单开发场景,仅提供 4 个核心命令,流程极简:/opsx:propose → /opsx:apply → /opsx:archive
核心命令:/opsx:propose(创建变更 + 规划制品)、/opsx:explore(梳理思路)、/opsx:apply(实现任务)、/opsx:archive(完成变更归档)。
新手可以通过 onboard 命令学习整个工作流程。 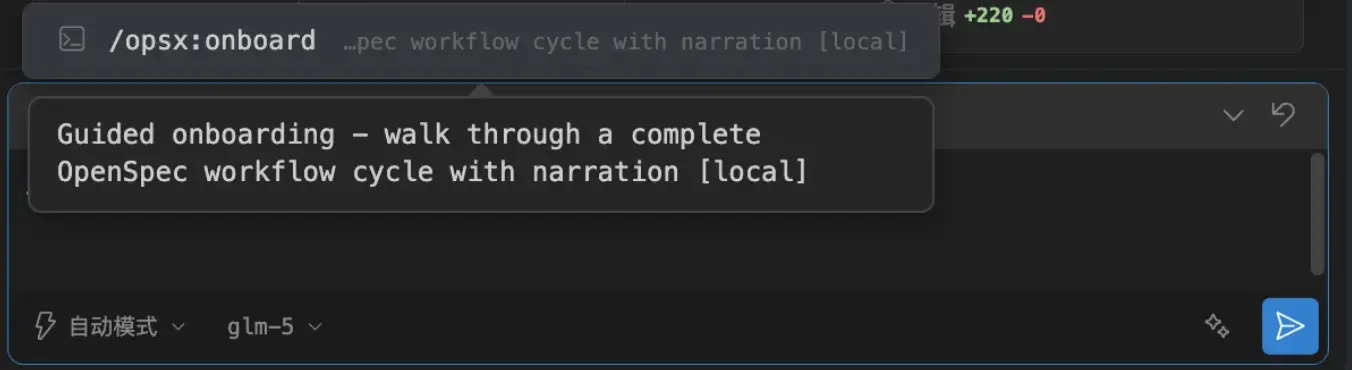
扩展模式(Expanded Profile)
适合复杂开发、团队协作场景,包含脚手架、校验、批量操作等专属命令。
开启方式 :依次执行 openspec config profile + openspec update
bash
# 选择 workflows only
openspec config profile
# 更新,之后需要重启
openspec update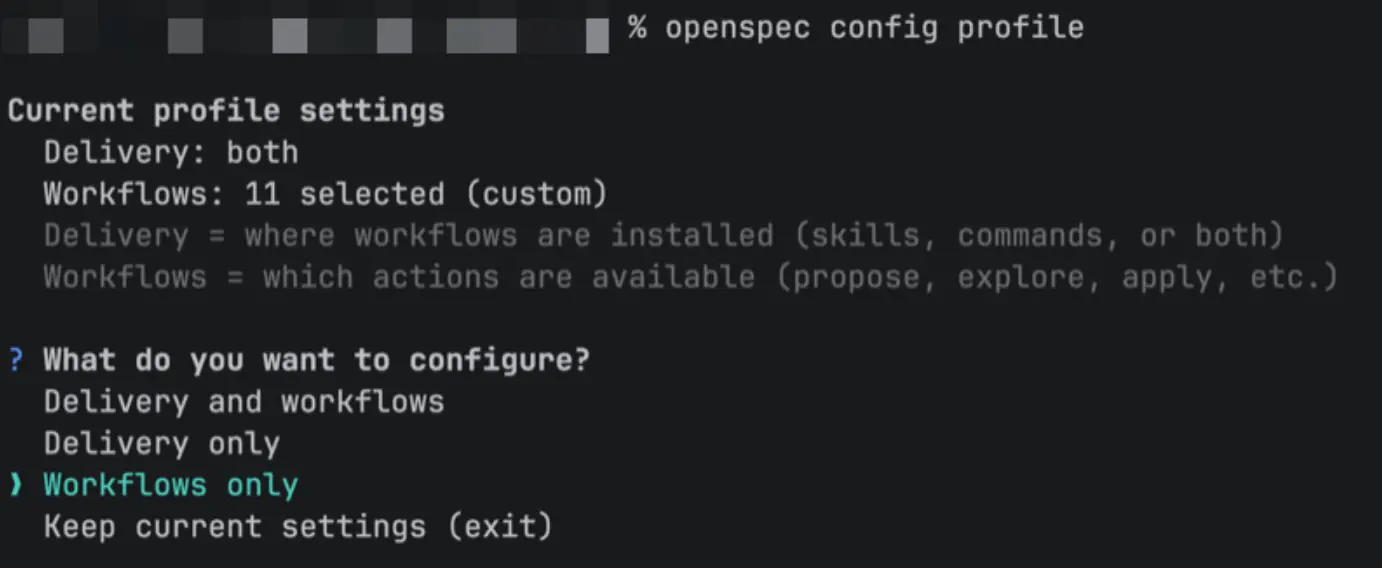
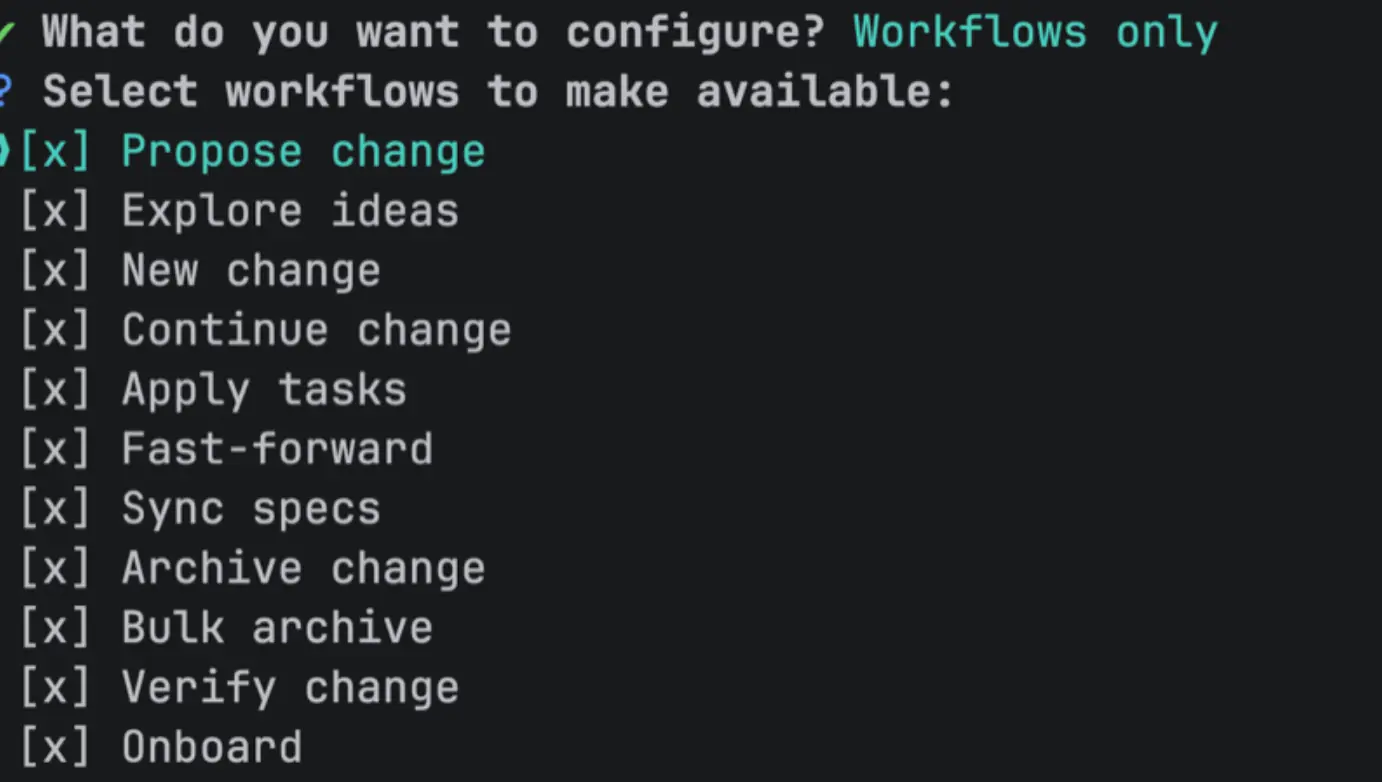
扩展模式额外支持:/opsx:new、/opsx:continue、/opsx:ff、/opsx:verify、/opsx:sync、/opsx:bulk-archive 等命令。
4.2 核心命令速查
| 命令 | 核心用途 | 适用场景 |
|---|---|---|
| /opsx:propose | 创建变更 + 规划制品 | 快速模式,简单开发 |
| /opsx:explore | 梳理思路、调研问题 | 需求模糊,技术探索 |
| /opsx:new | 启动变更脚手架 | 扩展模式,新建变更 |
| /opsx:continue | 逐步骤生成下一个制品 | 扩展模式,探索式开发 |
| /opsx:ff | 一次性生成所有规划制品 | 扩展模式,需求清晰 |
| /opsx:apply | 执行任务,实现功能 | 所有模式,开发实现 |
| /opsx:verify | 验证实现与规范的一致性 | 扩展模式,归档前校验 |
| /opsx:sync | 合并增量规范到主分支 | 扩展模式,规范同步 |
| /opsx:archive | 完成变更,归档记录 | 所有模式,变更收尾 |
| /opsx:bulk-archive | 批量归档多个变更 | 扩展模式,多任务并行 |
CLI 命令(终端执行):
| CLI 命令 | 用途 |
|---|---|
openspec init |
初始化项目 |
openspec list |
列出所有活跃变更 |
openspec status |
查看指定变更的进度 |
openspec config profile |
配置工作流模式 |
openspec update |
更新斜杠命令配置 |
4.3 使用场景
场景一:已有项目如何接入 OpenSpec
项目已经有大量代码,没有任何规格文档,想开始用 OpenSpec。
渐进式引入策略:
openspec init初始化/opsx:explore让 AI 分析现有代码,按模块梳理当前行为- 基于探索结果,逐步往
openspec/specs/里写规格(AI 可以帮你生成初稿) - 后续新功能按正常流程走------每次归档都会让主规格更完整一点
几个变更归档之后,你会发现 openspec/specs/ 已经积累了一份相当可用的系统行为文档,而这一切都是在正常开发过程中自然生长出来的,没有额外负担。
场景二:技术预研阶段的探索式调研
还在评估阶段,想让 AI 帮你搞清楚某个问题域,产出决策依据。
推荐路径:
latex
/opsx:explore → (多轮对话)→ (方向确定后再 /opsx:propose 或 /opsx:new)示例对话:
latex
你: /opsx:explore 我们计划引入消息队列来解耦订单和库存系统,
目前在 RabbitMQ 和 Kafka 之间纠结,帮我分析各自的优劣势和适用场景
AI: 让我分析一下你的业务场景和技术约束...
当前系统状态:
- 订单系统日均 50 万单,峰值 QPS 约 200
- 库存扣减要求强一致性
- 团队 Java 栈为主,运维经验有限
对比分析:
| 维度 | RabbitMQ | Kafka |
|------------|---------------------|----------------------|
| 吞吐量 | 万级/秒 | 十万级/秒 |
| 延迟 | 微秒级 | 毫秒级 |
| 消息可靠性 | 强,支持确认机制 | 需配置,默认可能丢 |
| 运维复杂度 | 低,开箱即用 | 高,依赖 ZooKeeper |
| 学习曲线 | 平缓 | 陡峭 |
建议: 当前规模下 RabbitMQ 更合适,
吞吐量足够、运维成本低、团队上手快。
若未来日均单量破百万再考虑迁移 Kafka。
你: 如果选 RabbitMQ,需要改动哪些模块?
AI: 正在分析订单和库存模块的耦合点...
...explore 全程不产生任何文件,对项目零副作用。你可以一直探索,直到心里有谱了再决定要不要正式立项。
场景三:需求方向明确但细节待厘清
你只有一个大方向------「搜索结果不够精准」、「导出功能太慢」------但不确定具体该怎么做。
推荐路径:
latex
/opsx:explore → /opsx:new → /opsx:continue → ... → /opsx:apply → /opsx:archive
# 1. 启动探索模式,梳理问题
你: /opsx:explore 用户反馈报表导出超过 1 万条数据时经常超时失败,
帮我分析一下瓶颈在哪,有哪些优化方向
AI: 正在分析导出模块的实现...
发现性能瓶颈:
1. 全量数据一次性加载到内存 (OOM 风险)
2. 未使用流式写入,先构造完整 Excel 再输出
3. 数据库查询缺少分页,单次查询返回 10 万+ 行
4. 导出任务同步执行,占用 HTTP 连接过久
优化优先级建议:
1. 改为异步任务 + 流式写入 (核心改动,彻底解决)
2. 数据库游标分批查询 (配合流式写入)
3. 前端轮询下载状态 (用户体验优化)
4. 大文件分片下载 (可选,应对超大数据量)
你: 先做前三个,分片下载暂不考虑。
# 2. 基于探索结果,新建变更
你: /opsx:new optimize-report-export
AI: 已创建 openspec/changes/optimize-report-export/
准备创建: proposal
# 3. 逐步骤生成规划制品,可随时调整
你: /opsx:continue optimize-report-export
AI: 正在创建 proposal.md...
✓ 范围: 异步任务 + 流式写入 + 前端轮询
下一个工件: specs
你: (审查 proposal,范围 OK)
你: /opsx:continue optimize-report-export
AI: 正在创建 specs/...
✓ specs/export-performance.md 已创建
核心要求:
- 导出任务必须异步执行,支持进度查询
- Excel 生成必须使用流式 API,内存占用 < 100MB
- 单次导出上限 50 万条,超过需拆分
下一个工件: design
你: (specs 写得挺具体,加个一条:导出失败要支持重试)
(手动编辑 specs/export-performance.md,加上重试要求)
你: /opsx:continue optimize-report-export
AI: 正在创建 design.md... (已纳入你补充的重试要求)
✓ design.md 已创建
下一个工件: tasks
你: /opsx:continue optimize-report-export
AI: ✓ tasks.md --- 6 个实现任务
所有规划制品已完成。
你: /opsx:apply optimize-report-export
...为什么用 continue 而不是 ff? 因为需求本身就不清晰,每一步生成的工件都可能需要你手动修正。continue 给你在每个工件节点上审查和调整的机会,避免 AI 在错误的方向上一路狂奔。
场景四:需求明确,快速落地实现
你已经想好了要做什么、做成什么样,只需要 AI 来执行。
**Core Profile 路径(最快)**:
latex
/opsx:propose → 审查 → /opsx:apply → /opsx:verify → /opsx:archive
你: /opsx:propose 为 API 接口添加请求限流功能,支持按 IP 和用户 ID 两种维度限流,
默认阈值 IP 100次/分钟、用户 50次/分钟,超限返回 429 状态码
AI: ✓ 已创建 openspec/changes/add-rate-limiter/
✓ proposal.md --- 范围与意图
✓ specs/rate-limiting.md --- 增量规格
✓ design.md --- 令牌桶算法 + Redis 存储
✓ tasks.md --- 5 个实现任务
准备就绪,请审查!
你: (扫了一遍 tasks.md,拆分合理,specs 覆盖了 IP 和用户两种限流维度)
你: /opsx:apply add-rate-limiter
AI: 正在执行任务...
✓ 已创建 RateLimiter 注解
✓ 已实现令牌桶限流算法
✓ 已添加 IP 维度限流拦截器
✓ 已添加用户维度限流拦截器
✓ 已配置默认阈值和 429 响应
全部 5 个任务已完成!
你: /opsx:verify add-rate-limiter
AI: ✅ 完整性: 5/5 任务完成,所有场景已覆盖
✅ 正确性: 符合规格意图
✅ 一致性: 限流逻辑实现统一
未发现问题。
你: /opsx:archive add-rate-limiter
AI: ✓ 已同步增量规格至 openspec/specs/rate-limiting.md
✓ 已归档至 openspec/archive/2026-03-15_add-rate-limiter/**Expanded Profile 路径(更可控)**:
如果你喜欢把「创建变更」和「生成工件」分开,可以用 new + ff:
latex
# 1. 新建变更脚手架
你: /opsx:new add-rate-limiter
AI: 已创建 openspec/changes/add-rate-limiter/
准备创建: proposal
# 2. 快速生成所有规划制品(提案、规范、设计、任务)
你: /opsx:ff
AI: 正在创建所有规划制品...
✓ proposal.md
✓ specs/
✓ design.md
✓ tasks.md
准备就绪,可开始实现!
# 3. 执行任务,实现功能
你: /opsx:apply
AI: 正在执行任务...
✓ 全部 5 个任务已完成!
# 4. 验证实现是否符合规范(可选但推荐)
你: /opsx:verify
AI: 未发现问题。
# 5. 归档变更,完成开发
你: /opsx:archive
AI: ✓ 已合并规格
✓ 已归档变更这两条路径效果一样,区别只在于 propose 是一步到位,而 new + ff 让你在创建骨架后还有一个「要不要继续」的决策点。
场景五:开发中断后恢复进度
昨天做了一半的功能,今天打开新对话要继续。或者临时切去修了个 Bug,现在想切回来。
推荐路径:
latex
(新对话)→ /opsx:apply <change-name>这是 OpenSpec 最实用的价值之一。 因为所有规格和任务清单都以文件形式存在项目里,AI 不需要你重新描述上下文------它直接读 tasks.md,看哪些任务已经打了勾、哪些还没完成,然后从断点继续:
latex
你: /opsx:apply add-multi-tenant-support
AI: 正在读取 tasks.md... 发现 12 个任务,已完成 7 个。
从任务 8 继续: 实现租户数据隔离中间件
✓ 已创建 TenantContext 中间件
✓ 已配置 SQL 拦截器自动注入租户条件
正在执行任务 9: 改造现有 DAO 层
...如果被打断期间你手动改了部分代码,AI 也能感知实际代码状态,智能跳过已完成的部分。
想在继续之前调整方案? 先看看当前进度:
latex
openspec status add-multi-tenant-support然后直接编辑 openspec/changes/add-multi-tenant-support/tasks.md------增删任务条目、调整顺序都行------再执行 /opsx:apply。
场景六:实现完成后发现问题或遗漏
apply 执行完了,但看了眼代码,感觉哪里不对------有个需求没实现、逻辑有问题,或者你想在原有基础上再加点东西。
这其实是两类情况,但处理方式都一样:直接改工件文件,然后重新执行 /opsx:apply。
OpenSpec 的任务清单不是一次性的------tasks.md 你随时可以编辑,apply 每次都会检查哪些任务未完成,从那里接着跑。
情况一:发现 AI 漏做了某个需求
打开 openspec/changes/<change-name>/tasks.md,把漏掉的需求补进去(取消勾选或新增任务条目),然后重新 apply:
latex
你: /opsx:apply add-rate-limiter
AI: 正在读取 tasks.md... 发现 6 个任务,已完成 5 个。
正在执行任务 6: 添加限流事件的监控埋点
✓ 已集成 Prometheus 指标采集
全部 6 个任务已完成!如果是比较大的需求遗漏,也可以先更新一下 specs/ 里的 Delta Specs,把漏掉的行为描述补上,再让 AI 重新生成 tasks:
latex
你: /opsx:continue add-rate-limiter
AI: tasks.md 已存在 --- 根据更新的 specs 重新生成...
✓ tasks.md 已更新 --- 8 个实现任务 (原 5 个)
准备就绪,可执行 /opsx:apply情况二:实现有问题,想指出来让 AI 修
先用 verify 让 AI 自己扫一遍,它会帮你列出实现和规格之间的出入:
latex
你: /opsx:verify add-rate-limiter
AI: 正在对照规格验证实现...
✅ 完整性: 5/5 任务完成
⚠️ 正确性: 警告 --- 用户维度的限流未考虑未登录场景
(规格要求未登录用户使用 IP 限流兜底,当前代码直接跳过)
✅ 一致性: 限流逻辑实现统一
发现 1 个问题。也可以直接描述你发现的问题,让 AI 在当前对话里修:
latex
你: 限流器的配置写死在代码里了,应该支持从配置中心动态调整阈值
AI: 找到问题了 --- RateLimiterConfig 的阈值来自硬编码常量。
正在修复...
✓ 已改为从 Nacos 读取配置,支持热更新修完之后,记得在 tasks.md 里补一条对应的任务并标为完成,保持工件和代码的同步------这样归档时 verify 才干净。
情况三:做着做着想追加新需求
如果新增的需求跟这个变更强相关,直接往 specs/ 和 tasks.md 里加,继续 apply。
如果是一个独立的新功能------比如「限流功能做好了,顺便想加个熔断器」------建议另开一个变更,别把两件事混在一起:
latex
你: /opsx:propose add-circuit-breaker 为下游服务调用添加熔断器,
支持配置失败阈值和恢复时间判断标准很简单:如果这个新需求拿掉了,原来的变更还是完整的,就单开一个变更。
场景七:多任务并行与切换
手头同时推进好几个功能,需要在它们之间自由切换。
推荐路径:
latex
/opsx:propose feature-a → /opsx:apply feature-a → (切走)
/opsx:propose feature-b → /opsx:apply feature-b → (切回)
/opsx:apply feature-a → ...
/opsx:bulk-archive因为每个变更独立存放在 openspec/changes/<name>/ 里,完全隔离,切换上下文只需要在 apply 时指定不同的变更名。用 openspec list 随时看看都有哪些活跃变更:
latex
$ openspec list
CHANGES
add-rate-limiter ████████░░ 5/7 任务
fix-export-timeout ██████████ 4/4 任务 ✓
add-audit-log ████░░░░░░ 2/6 任务全部完成后 /opsx:bulk-archive 一次性归档,它会自动检测不同变更的 Delta Specs 之间是否有冲突。
场景八:系统化 Bug 修复流程
线上出了 Bug,需要定位根因、设计修复方案、验证修复效果。
推荐路径:
latex
/opsx:explore → /opsx:propose → /opsx:apply → /opsx:verify → /opsx:archive
# 1. 先用 explore 定位问题
你: /opsx:explore 用户反馈「购物车商品偶尔会莫名消失」,
帮我分析一下可能的原因和涉及的代码模块
AI: 正在分析购物车模块...
发现可疑点:
1. 购物车数据同时存在 Redis 和 MySQL,双写一致性无保障
2. Redis 缓存过期时间设置为 30 分钟,但无被动刷新机制
3. 并发场景下删除商品操作可能误删其他用户的购物项 (CartService.java:89)
建议优先检查: CartService.removeItem() 的用户校验逻辑
你: 看一下 removeItem 的具体实现
AI: 分析代码发现:
- 第 92 行: 仅校验商品 ID 是否存在,未校验归属用户
- 第 105 行: 删除操作使用商品 ID 作为缓存 key 的一部分,未包含用户标识
- 这两个问题都可能导致「商品消失」现象
# 2. 确认问题后,创建修复变更
你: /opsx:propose fix-cart-item-removal 修复购物车商品删除的用户校验漏洞和缓存 key 设计问题
AI: ✓ 已创建 openspec/changes/fix-cart-item-removal/
✓ proposal.md --- 根因分析 + 修复范围
✓ specs/cart-removal.md --- 修复后的预期行为
✓ design.md --- 缓存 key 引入用户 ID + 删除前归属校验
✓ tasks.md --- 4 个修复任务
准备就绪,请审查!
你: (确认 tasks 覆盖了两个问题,追加一条:补充集成测试)
你: /opsx:apply fix-cart-item-removal
...Bug 修复场景的优势 :/opsx:explore 能帮你在动手前系统性地梳理问题,避免「修了一个 Bug 引出两个新 Bug」。修复方案被文档化后,也方便复盘和知识沉淀。
场景九:大型重构与架构迁移
需要对现有模块进行大规模重构,或者从旧架构迁移到新架构。
推荐路径:
latex
/opsx:explore → /opsx:new → /opsx:continue → ... → 分阶段 /opsx:apply → /opsx:archive
# 1. 先全面了解现状
你: /opsx:explore 当前项目使用 JWT 无状态认证,想改造为 OAuth2 + Redis 会话。
帮我梳理涉及的模块、迁移风险、推荐的迁移策略
AI: 正在分析认证授权体系...
当前状态:
- JWT 签发后无法主动失效,依赖短期有效期
- 权限变更需等待 Token 过期才能生效
- 前端 6 个模块依赖 Token 解析逻辑
迁移策略建议:
1. 双轨并行: 先支持 OAuth2,JWT 继续可用,逐步切换
2. 优先级: 登录流程 → 权限校验 → 前端适配
3. 风险点: 登出场景需同时清除 Redis 会话和前端 Token
预计工作量: 2-3 周
# 2. 创建变更,拆分阶段
你: /opsx:new migrate-to-oauth2-session
AI: 已创建 openspec/changes/migrate-to-oauth2-session/
准备创建: proposal
你: /opsx:continue migrate-to-oauth2-session
AI: 正在创建 proposal.md...
✓ 范围: 分三阶段迁移 (登录流程 → 权限校验 → 前端适配)
下一个工件: specs
你: (多轮 continue 生成完整工件后...)
# 3. 分阶段执行
你: /opsx:apply migrate-to-oauth2-session --phase 1
AI: 正在执行第一阶段: 登录流程改造
✓ 已创建 OAuth2AuthorizationServer 配置
✓ 已实现 RedisTokenStore
✓ 已添加会话管理端点
第一阶段完成,请在验证后继续第二阶段大型重构的注意点:
- 在
specs/中明确记录「迁移前行为」和「迁移后行为」,确保行为一致性 tasks.md按阶段拆分,每个阶段可独立验证和上线- 每个阶段完成后先 verify 再进入下一阶段
场景十:多人协作与代码审查
团队成员各自开发,需要同步进度、合并规格、进行代码审查。
协作模式一:同一变更的分工协作
latex
# 成员 A 负责前端
成员A: /opsx:apply add-file-upload --scope frontend
# 成员 B 负责后端
成员B: /opsx:apply add-file-upload --scope backend
# 完成后合并验证
成员A: /opsx:verify add-file-upload
成员B: /opsx:sync add-file-upload # 同步各自的规格变更
# 最终归档
成员A: /opsx:archive add-file-upload协作模式二:并行变更后批量合并
latex
# 不同成员开发不同功能
成员A: /opsx:propose add-message-template
成员B: /opsx:propose add-export-scheduler
# 各自完成后
成员A: /opsx:verify add-message-template
成员B: /opsx:verify add-export-scheduler
# 批量归档,自动检测冲突
成员A: /opsx:bulk-archive
AI: 正在归档 2 个变更...
⚠️ 检测到规格冲突:
- add-message-template 和 add-export-scheduler 都修改了任务调度服务接口
- 冲突文件: specs/task-scheduler.md
建议: 手动合并冲突后再归档团队协作最佳实践:
openspec/specs/纳入版本控制,作为团队的「共享知识库」- 使用
/opsx:sync定期同步规格,避免归档时才发现冲突
五、OpenSpec 实践:从需求到归档
以「列表查询支持多条件筛选」这个小功能进行实践:
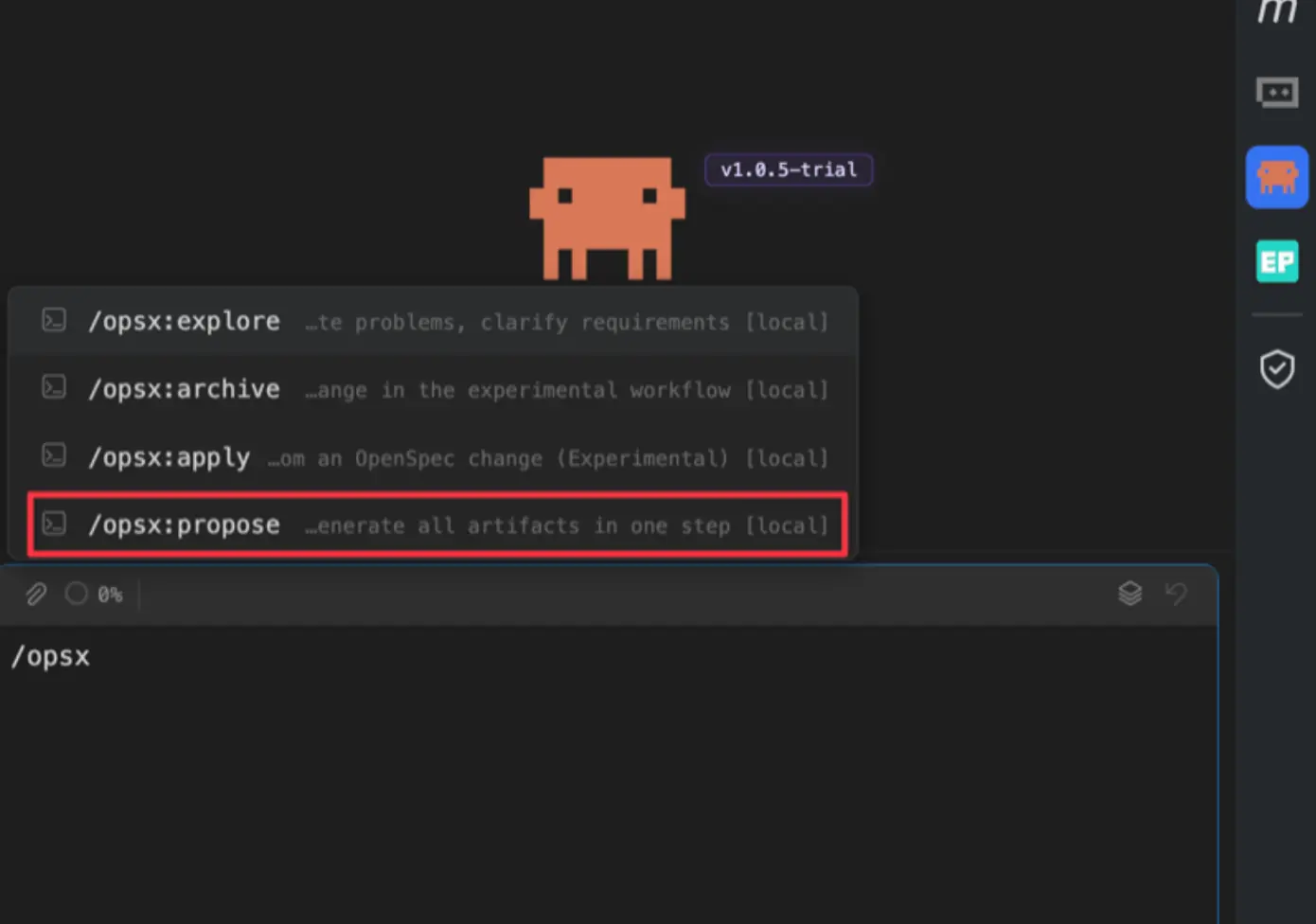
由于我的需求场景比较明确,所以我初始化 OpenSpec 后,直接「/opsx:propose 需求描述」生成所有的规格、设计、任务文档:
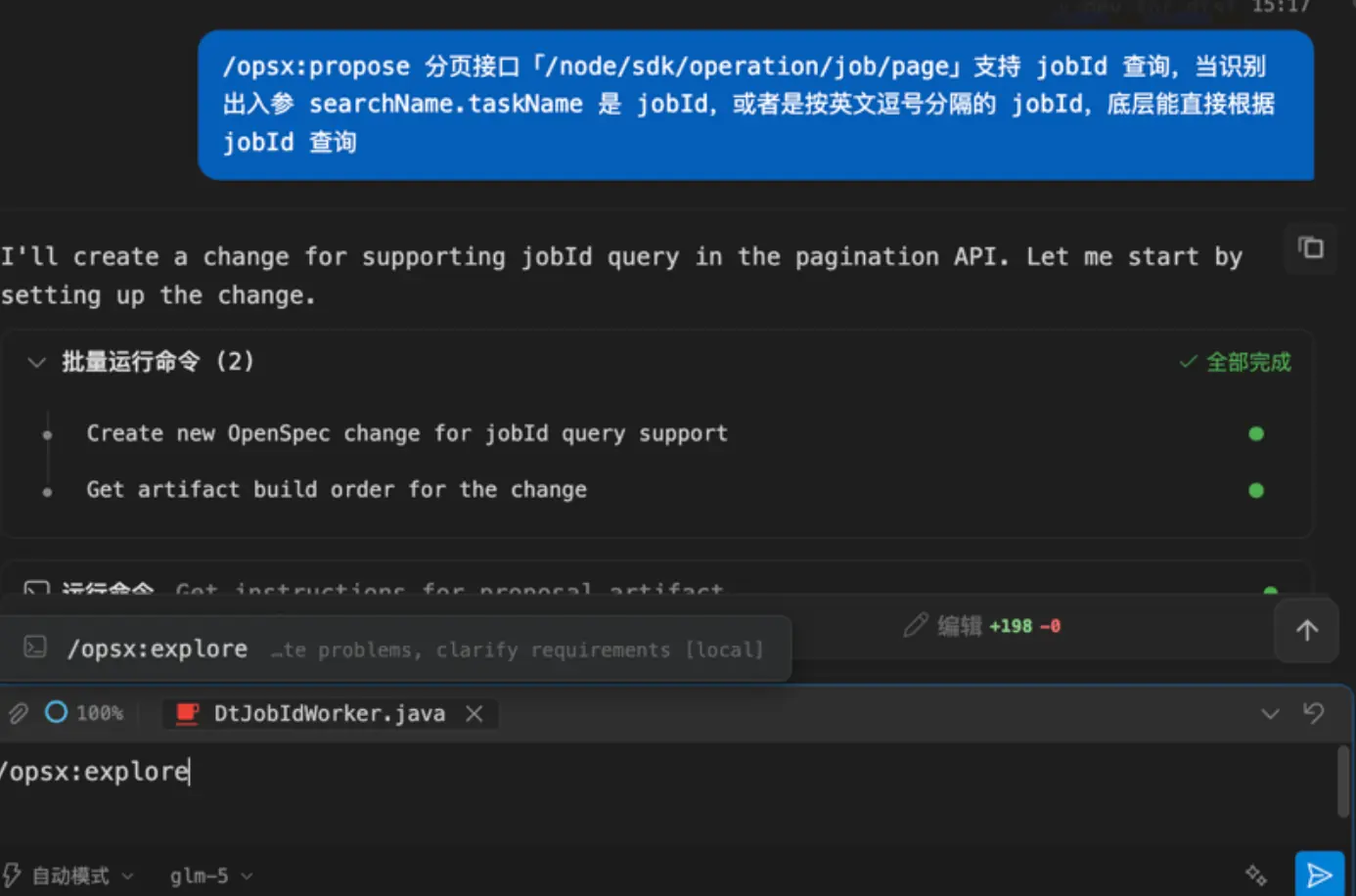
OpenSpec 产物如下,需求规格、设计方案、任务列表都被放在新生成的变更文件夹下:
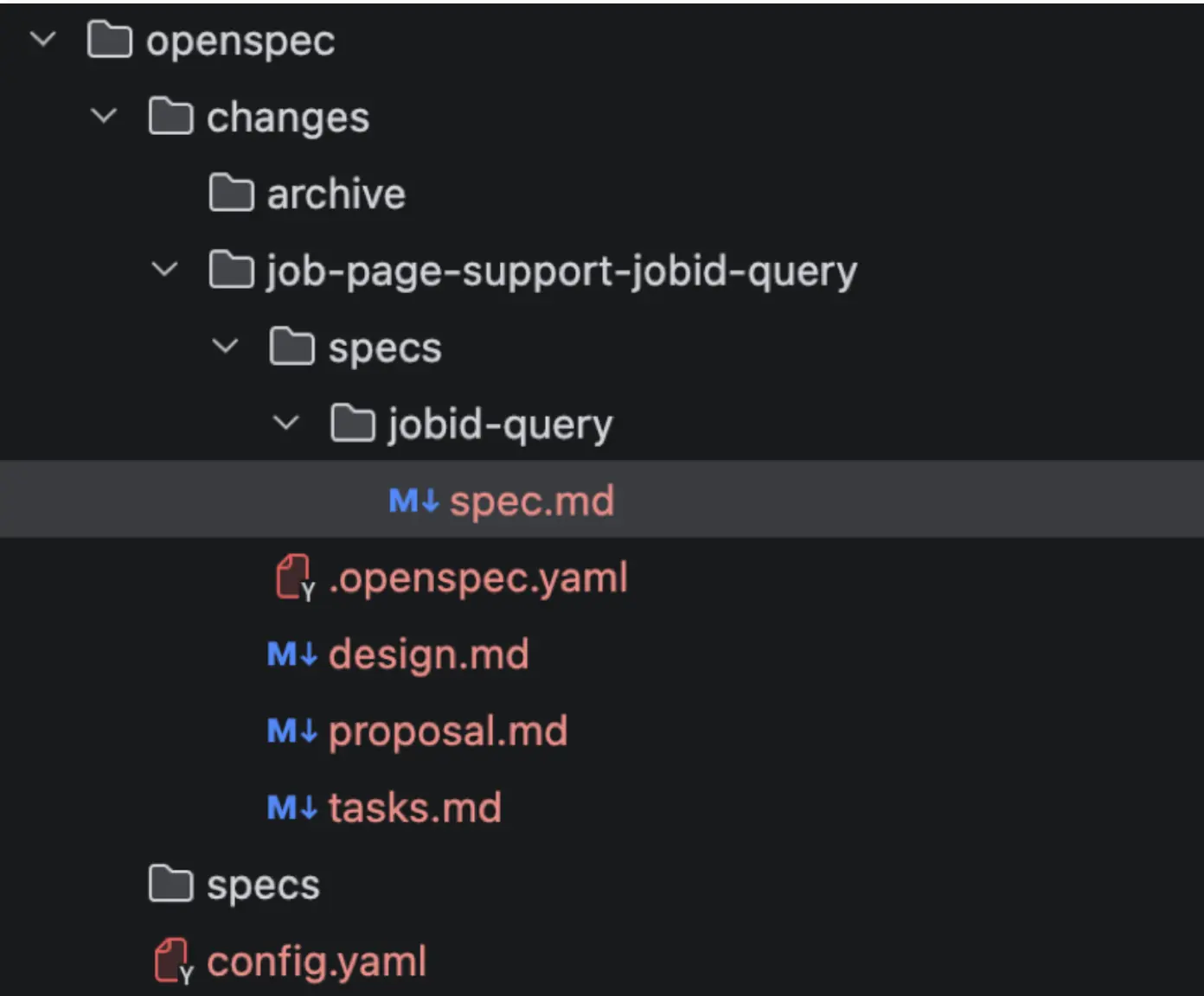
我审查了一下 design.md 文档,发现其中有些考虑不太恰当,于是我通过 「/opsx:explore」进行了探索:
备注:这一步应该不需要 「/opsx:explore」,直接跟 ClaudeCode 对话就行,但后续需加到设计规格文档中
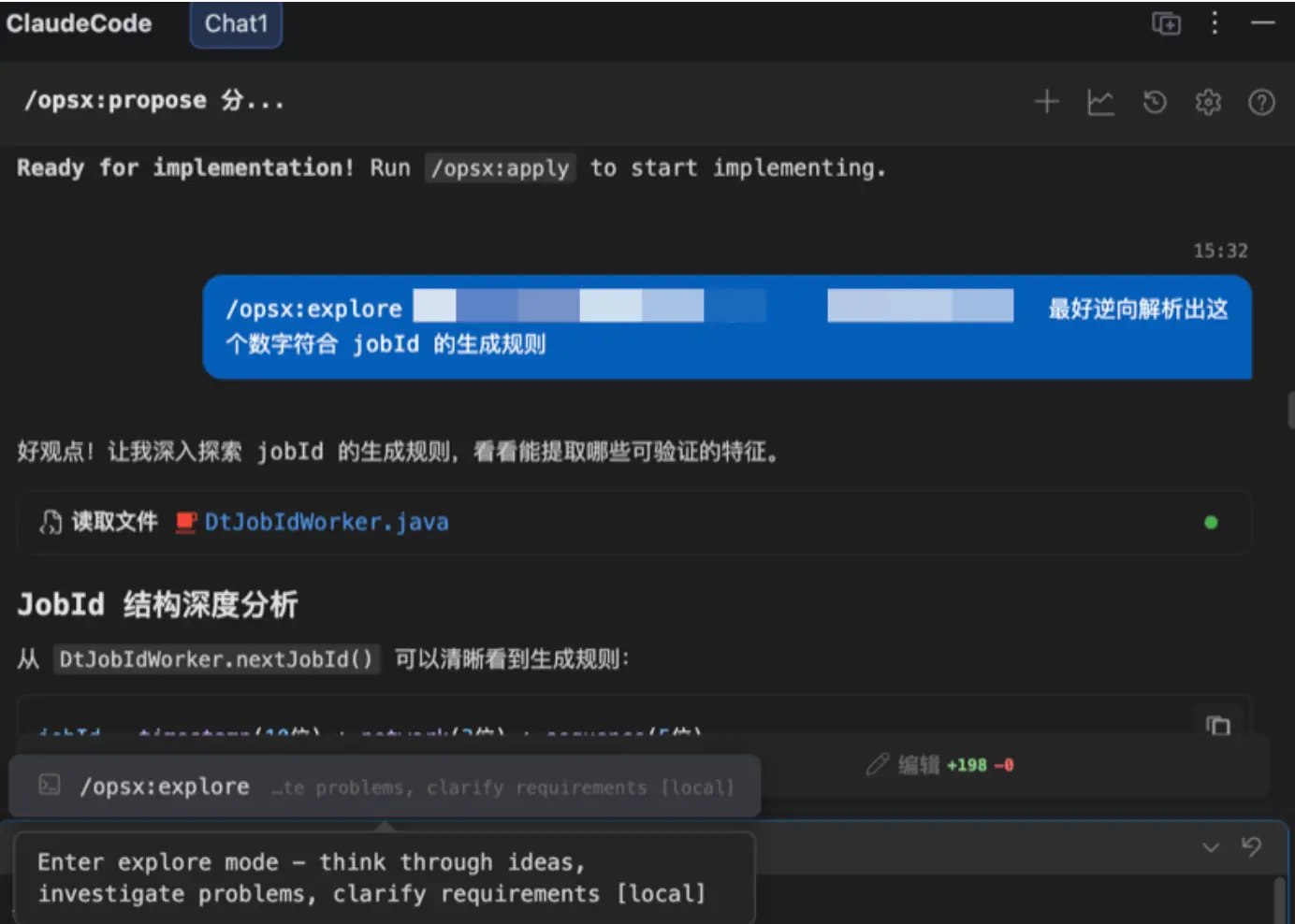 !
!
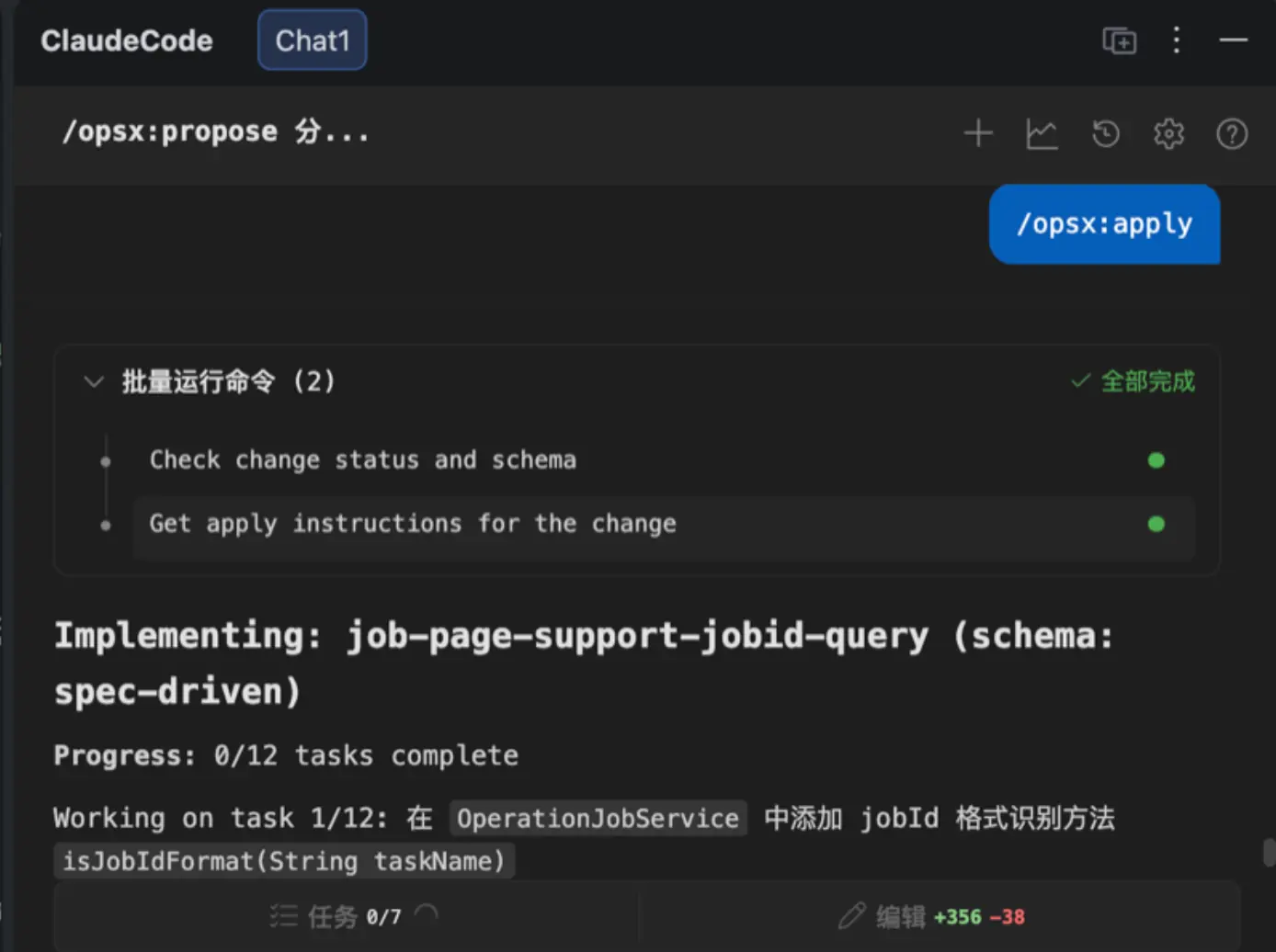
多轮的对话交互后,我审查了 proposal.md、spec.md、design.md,感觉场景和设计方案上已经符合我的要求,开始应用,生成代码:
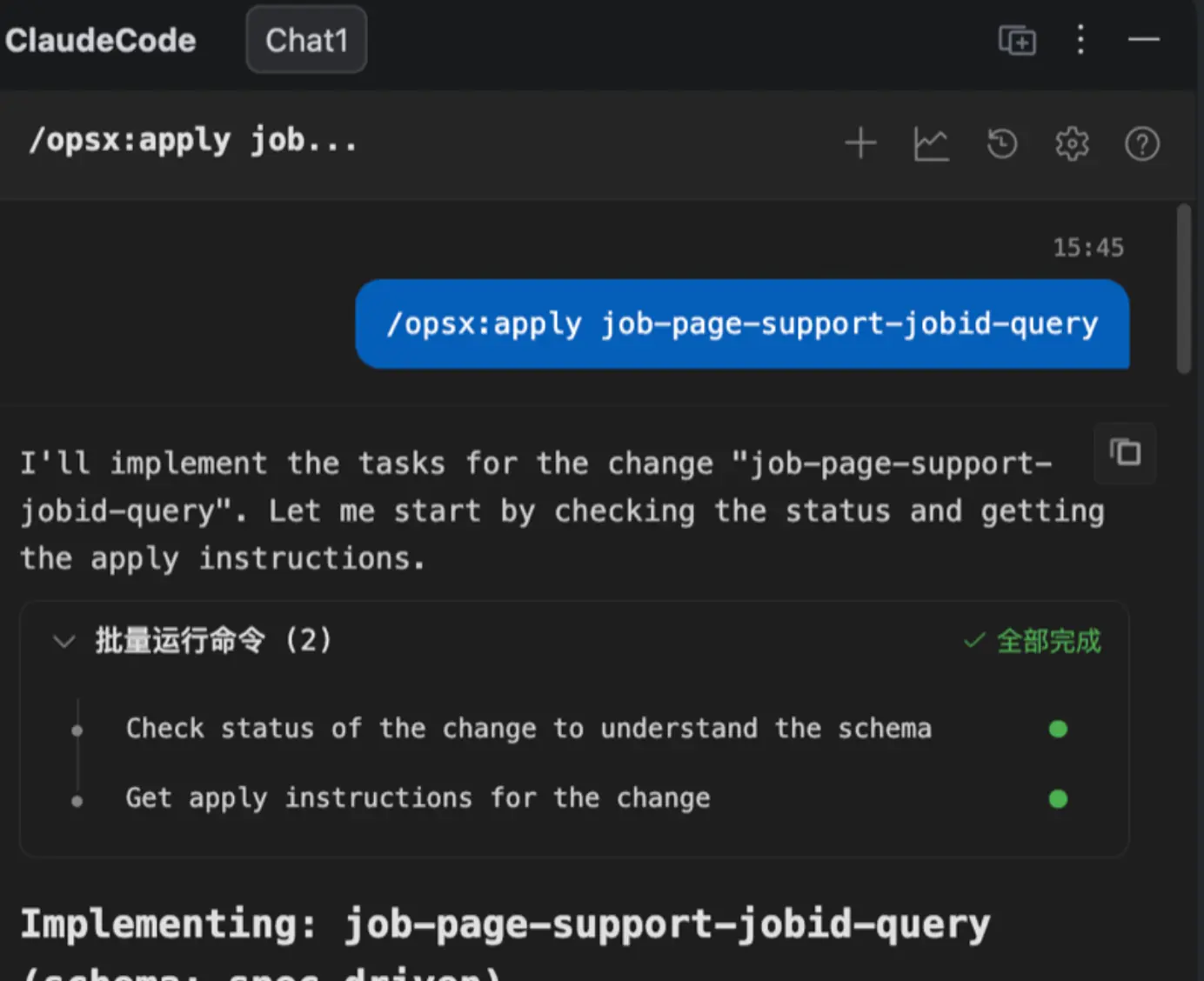
当我中途不小心关闭会话后,可以通过 /opsx:apply <change> 或 /opsx:continue <change> 再切回来:
当所有的任务都执行完成, tasks.md 中的事项前会被标记 x 表示完成:
最后通过「/opsx:archive」归档此次需求。
推荐的归档流程
latex
/opsx:apply → /opsx:verify → (修复问题)→ /opsx:archive别急着归档。verify 能帮你抓住实现和规格之间的不一致------比如 spec 写了「支持批量删除」但实际只实现了单个删除,或者 design 里说用 Redis 缓存但代码里直接查数据库。这些问题在归档前修复的成本远低于归档后。
归档时的注意事项
- 归档会提醒 但不会阻止任务未全部完成的情况------如果你确认部分任务不再需要,可以手动标为完成或直接归档
- 如果变更还没有 sync 过,
archive会在归档时自动同步 - 归档是不可逆的(虽然历史目录保留了所有内容),所以最好先 verify 一下
整个流程跑下来,OpenSpec 产出的效果还是令人满意的,一些前期没有考虑到的细节 AI 都补上了,生成的相关文档也有利于开发人员的知识对齐,可以尝试在团队内部推广。
回顾上述实践过程,有几点值得强调:
第一,前期沟通清楚至关重要。 OpenSpec 的核心价值在于「规格驱动」,而非「即兴编程」。在执行 /opsx:propose 或 /opsx:ff 之前,花时间把需求想透、把场景列全,远比匆忙开工后再反复返工高效。如果你对需求本身还有疑虑,善用 /opsx:explore 先行探索,让 AI 帮你梳理思路、发现盲点,而不是一上来就催着生成代码。
第二,AI Coding 不等于 Vibe Thinking。 所谓 Vibe Thinking,是指那种「我有个大概想法,让 AI 自己看着办」的心态------这在简单场景或许能蒙混过关,但在复杂工程中注定翻车。OpenSpec 的工作流设计恰恰是反 Vibe 的:它要求你在每个节点停下来审查、确认、修正。proposal 对不对?specs 够不够具体?design 有没有漏洞?tasks 拆分合不合理?这些问题需要人来做判断,AI 做不了这个主。
第三,AI 代替不了一切。 这句话听起来像陈词滥调,但在 OpenSpec 的实践中体现得淋漓尽致。AI 可以帮你生成初稿、补全细节、执行任务,但它不会主动问你「这个边界条件你想怎么处理」,也不会凭空想到「这个方案可能影响现有接口兼容性」。这些关键决策点需要人来把关。实践中,我对 proposal.md、specs/、design.md 都进行了或多或少的审查和修改,这才是 OpenSpec 发挥价值的真正原因------人和 AI 协作,而非 AI 单向输出。
第四,返工成本与前期投入的权衡。 虽然 OpenSpec 允许你在生成代码后发现问题、回退变更、重新调整规格,但这种返工的代价往往被低估。代码写了又删、测试写了又改、对话历史越来越长------这些都消耗着你的时间和注意力。相比之下,在规划阶段多花半小时把规格想清楚,能省下后面数小时的调试和返工。前期沟通清楚,降低返工率,这才是 OpenSpec 工作流的精髓。
六、最佳实践
6.1 项目上下文先行配置
在动手写第一个变更之前,先把 config.yaml 的 context 字段填好。技术栈、模块划分、代码规范、API 风格------这些信息写进去后,后续所有变更的工件生成都能自动继承,省去每次对话开头重复交代背景的麻烦。
这是 OpenSpec 使用的前置条件,投入十分钟,收益贯穿整个项目周期。
6.2 善用 explore 避免方向性错误
当你对需求、技术方案或现有代码有疑虑时,先用 /opsx:explore 探索。它不产生任何文件,对项目零副作用,却能帮你:
- 发现被忽略的边界条件
- 识别现有代码的潜在风险点
- 梳理模块间的依赖关系
- 验证技术方案的可行性
探索阶段发现的问题,修正成本几乎为零;在实现阶段发现同样的问题,修正成本可能是十倍甚至百倍。
6.3 变更迭代还是新建的判断
在已有变更上继续迭代,还是另起一个新变更?参考下表:
| 场景 | 建议操作 |
|---|---|
| 目标没变,仅实现路径需要调整 | 更新现有变更 |
| 先交付核心功能,后续逐步完善 | 更新现有变更 |
| 需求方向完全偏离原计划 | 新建变更 |
| 追加的功能可独立于原变更存在 | 新建变更 |
| 当前变更已具备独立上线条件 | 归档旧的,新建新的 |
6.4 变更职责保持单一
每个变更应该只解决一个问题、只承载一个职责。add-rate-limiter 只做限流,fix-cart-concurrency 只修并发问题,refactor-auth-module 只重构认证模块。
如果发现变更范围膨胀到「顺便再做点别的」,或者命名时想用 misc-xxx、feature-v2 这种模糊名称,说明职责边界已经模糊,应该拆分成多个独立变更。
职责单一的变更更易审查、更易回滚、更易复用。
6.5 规划阶段选用高推理模型
/opsx:propose、/opsx:ff、/opsx:continue 这些命令需要模型理解需求全貌、做出架构决策,推理能力直接影响工件质量。建议使用 Claude Opus、GPT-5.4 等高推理模型。
/opsx:apply 阶段主要是按任务执行,对推理要求相对较低,可以选用响应更快的模型。
6.6 执行前清空对话历史
执行 /opsx:apply 时,建议开启新对话窗口。让 AI 从干净的状态读取工件文件,避免探索阶段、讨论阶段的对话噪音干扰代码生成质量。
探索和执行是两个阶段,上下文应该隔离。
6.7 归档不仅是清理,更是知识沉淀
每次归档都会将 Delta Specs 合并到 Main Specs,这意味着 openspec/specs/ 会逐渐成为项目的「活文档」。善用这一点:
- 定期审查 Main Specs,删除过时内容,保持其作为「源真相」的权威性
- 新成员 onboarding 时,Main Specs 是理解系统行为的最佳入口
- 归档目录
openspec/archive/保留完整历史,便于追溯变更脉络
一个维护良好的 OpenSpec 目录本身就是一份高质量的技术文档,比单独维护的 Wiki 更实时、更准确。
6.8 多变更并行时定期检查状态
手头同时推进多个变更时,养成定期执行 openspec list 的习惯:
bash
$ openspec list
CHANGES
add-rate-limiter ████████░░ 5/7 任务
fix-export-timeout ██████████ 4/4 任务 ✓
add-audit-log ████░░░░░░ 2/6 任务这能帮你:
- 感知每个变更的进度,避免遗忘
- 发现是否有变更已经完成但未归档
- 规划优先级,决定先完成哪个
建议在每天结束工作前执行一次,保持对多任务状态的清晰把控。
七、常见问题与故障排查
7.1 变更管理问题
| 问题 | 解决方案 |
|---|---|
| apply 时任务跳过 | 检查 tasks.md 中的完成标记;确认代码已更新 |
| verify 报告不一致 | 对比 specs/ 与实际代码;更新任一方 |
| archive 后想回退 | 查看归档目录 openspec/archive/,手动恢复 |
| 命令执行顺序混淆 | 参考「核心命令与使用场景」章节的流程图 |
7.2 团队协作问题
| 问题 | 解决方案 |
|---|---|
| 多人修改同一变更 | 使用不同变更名;或拆分任务 |
| Delta Specs 冲突 | bulk-archive 会提示;手动合并冲突部分 |
| 规格版本不同步 | 定期 sync;在归档前统一同步 |
附录 术语表
| 术语 | 英文 | 定义 |
|---|---|---|
| 上下文中毒 | Context Poisoning | 大量无关信息污染模型上下文,导致生成质量下降 |
| 注意力漂移 | Attention Drift | 模型在长对话中逐渐偏离原始需求 |
| 源真相 | Source of Truth | 系统当前行为的权威描述 |
| Delta Specs | Delta Specifications | 变更带来的规格增量 |
| Main Specs | Main Specifications | 系统当前完整行为的规格描述 |
| 使能关系 | Enabling Relationship | 工件间的依赖关系,提供生成输入而非强制执行顺序 |
| 规格驱动开发 | Spec-Driven Development (SDD) | 先定义规格再编写代码的开发范式 |
| 工件 | Artifact | OpenSpec 生成的各类文档(proposal、specs、design、tasks) |
| 变更 | Change | 一个独立的功能开发或 bug 修复单元 |
| 归档 | Archive | 变更完成后的历史记录保存过程 |
| 快速模式 | Core Profile | 仅包含核心命令的简化工作流模式 |
| 扩展模式 | Expanded Profile | 包含完整命令集的高级工作流模式 |
最后
欢迎关注【袋鼠云数栈UED团队】~ 袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star