 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
-
- [1 引言](#1 引言)
-
- [1.1 相关工作概览](#1.1 相关工作概览)
- [2 问题建模](#2 问题建模)
-
- [2.1 异常传播链](#2.1 异常传播链)
- [2.2 技术挑战](#2.2 技术挑战)
- [2.3 RCRank 的补充视角](#2.3 RCRank 的补充视角)
- [3 PinSQL 系统设计](#3 PinSQL 系统设计)
-
- [3.1 数据采集与异常检测](#3.1 数据采集与异常检测)
- [3.2 个体 Active Session 估算](#3.2 个体 Active Session 估算)
- [3.3 H-SQL 识别:多层评分融合](#3.3 H-SQL 识别:多层评分融合)
- [3.4 R-SQL 识别:聚类 + 累积阈值 + 历史验证](#3.4 R-SQL 识别:聚类 + 累积阈值 + 历史验证)
- [3.5 修复模块](#3.5 修复模块)
- [4 RCRank 系统设计](#4 RCRank 系统设计)
-
- [4.1 数据收集与根因标注](#4.1 数据收集与根因标注)
- [4.2 多模态编码](#4.2 多模态编码)
- [4.3 自监督预训练](#4.3 自监督预训练)
- [4.4 根因自适应的跨模态融合](#4.4 根因自适应的跨模态融合)
- [4.5 影响度感知的训练目标](#4.5 影响度感知的训练目标)
- [5 实验结果](#5 实验结果)
-
- [5.1 PinSQL](#5.1 PinSQL)
- [5.2 RCRank](#5.2 RCRank)
- [6 ClickHouse 场景下的延伸讨论](#6 ClickHouse 场景下的延伸讨论)
-
- [6.1 ClickHouse 的大查询特点](#6.1 ClickHouse 的大查询特点)
- [6.2 system.query_log 作为诊断数据源](#6.2 system.query_log 作为诊断数据源)
- [6.3 PinSQL 方法的适配](#6.3 PinSQL 方法的适配)
-
- [个体 Active Session 估算的必要性降低](#个体 Active Session 估算的必要性降低)
- 资源争抢传播图
- [SQL 模板聚类的调整](#SQL 模板聚类的调整)
- [6.4 Workload 视角下的根因分析](#6.4 Workload 视角下的根因分析)
-
- [Workload 基线建模](#Workload 基线建模)
- [Workload 变化作为根因](#Workload 变化作为根因)
- [Workload 隔离与资源管控](#Workload 隔离与资源管控)
- 混合负载干扰
- [7 方法对比与局限性](#7 方法对比与局限性)
-
- [7.1 方法对比](#7.1 方法对比)
- [7.2 局限性](#7.2 局限性)
- [8 总结与展望](#8 总结与展望)
- 参考文献
1 引言
云数据库的性能异常诊断是一个长期未被很好解决的工程问题。工业界的标准做法是打开监控面板,按 total_response_time 或 #execution 对 SQL 模板排序,然后人工逐条排查。这个方法在模板数较少时勉强能用,一旦模板数到了数千甚至数万,人工排查就不可行了。
更根本的困难在于:排名靠前的 SQL 模板往往不是真正的根因。它们是被根因 SQL 牵连的受害者------因为锁等待、资源争抢等原因被拖慢,从而在排序指标上表现突出。真正的根因可能是一条流量不大但锁了关键资源的 UPDATE,或者一条因统计信息过期而选错执行计划的查询。
本文围绕 ICDE 2022 的 PinSQL 1 和 PVLDB 2024 的 RCRank 2 两项工作,分析大查询根因定位问题的建模思路和系统设计。在此基础上,讨论这些方法在 ClickHouse 等列式分析型数据库以及 workload 管理场景下的适用性与局限。
1.1 相关工作概览
大查询根因分析的研究可以从两个维度分类:单模态 vs 多模态观测,根因识别(RCI)vs 根因排名(RCR)。
在单模态方法中,iSQUAD 3 聚焦间歇性慢查询,通过 KPI 聚类和异常类型分类定位根因类别,但需要人工分析聚类外的根因。DBSherlock 4 采用谓词挖掘的因果分析方法,从数据库配置和指标中提取异常的充分条件,可解释性强但根因类型受限于预定义的谓词空间。ExplainIt 8 提供了一个声明式根因分析引擎,基于时序数据的因果推断,但不处理 SQL 级别的诊断。
在多模态方法中,OpenGauss 5 的 SQL 级诊断组件融合了执行计划和 KPI,但只做根因识别不做排名。D-Bot 6 利用 LLM 的多轮对话能力做端到端诊断,但推理延迟高(5.17 分钟/查询)且 LLM 对数值不敏感,难以准确估计根因影响度。
PinSQL 和 RCRank 在这一图景中各有定位:PinSQL 解决的是「实例级异常 → 定位哪条 SQL」的问题,RCRank 解决的是「已知慢查询 → 诊断为什么慢并排名」的问题。两者在实际诊断流程中构成天然的串联关系------先用 PinSQL 从实例异常中定位 R-SQL,再用 RCRank 诊断每条 R-SQL 的具体根因并按影响度排序,最后对影响最大的根因执行修复。
2 问题建模
2.1 异常传播链
PinSQL 对性能异常建立了一个传播模型,定义了两类异常 SQL:
- R-SQL(Root Cause SQL):异常的源头。典型场景包括业务突增导致的 QPS 变化、写法不当的 SQL(缺失索引、大范围扫描)、DDL 操作引发的 MDL 锁。
- H-SQL(High-impact SQL):被 R-SQL 影响而表现异常的 SQL。例如 R-SQL 持有行锁导致同表的 SELECT 阻塞。
传播路径为:
R-SQL → 资源争抢/锁阻塞 → H-SQL 响应时间恶化 → Active Session 飙升 → 告警触发诊断的目标是沿这条链路反向追踪,从 active session 异常出发,穿过大量 H-SQL 的噪声,定位到少数几条 R-SQL。
2.2 技术挑战
PinSQL 归纳了三个技术挑战,后续各节将分别说明 PinSQL 如何解决:
Challenge I(对应 §3.2):低开销获取个体 Active Session。 要判断一个 SQL 模板对实例 active session 的贡献,需要知道它在每个时间点上有多少查询正在执行。MySQL 中开启 Performance Schema 的 events_statements_history 等 consumer 可以提供这个信息,但论文实测该配置下 QPS 下降 8%~30%,对生产环境不可接受。
Challenge II(对应 §3.3):准确建模 SQL 模板对 active session 的影响。 简单的 Pearson 相关系数只衡量趋势相似性,忽略了绝对规模。一个只执行了 3 次但趋势完美匹配的模板,和一个执行了 30,000 次且趋势大致匹配的模板,对 active session 的实际贡献完全不同。
Challenge III(对应 §3.4):从 H-SQL 中区分 R-SQL。 现有的 Top-SQL 方案(按响应时间、执行次数、扫描行数等指标排序)本质上都是在定位 H-SQL------它们在排序指标上表现突出,但未必是异常的源头。
2.3 RCRank 的补充视角
RCRank 处理的是一个不同但互补的问题:已知某条 SQL 是慢查询,诊断它慢的根因类型,并按影响度排序。
根因类型包括统计信息过期(Statistics)、索引缺失(Index)、连接顺序不优(Join-Order)、分布键不合理(Distribution-key)、SQL 写法冗余(Query)等。
在 TPC 系列基准上还包括冗余索引、重复执行子查询、复杂表连接、全表更新、大数据插入等更细粒度的类别。
在时序侧更多是API查询、多次点击的重复查询,跨越超多时间线、时间区间的查询。
影响度定义为修复某根因后的性能提升比例:
impact(X_i, RC_j) = (runtime(X_i) - runtime(revise(X_i, RC_j))) / runtime(X_i)这个定义有明确的业务含义:impact = 55.3% 表示修复该根因后查询速度提升 55.3%。RCRank 输出一个按 impact 降序排列的根因列表。
3 PinSQL 系统设计
PinSQL 在阿里云 DAS(Database Autonomy Service)中已上线运行。系统包含四个顺序执行的模块。
3.1 数据采集与异常检测
数据采集分为两路:Performance Metrics(实例级指标,每秒采样)和 Query Logs(每条 SQL 的响应时间、扫描行数、时间戳)。数据异步写入 LogStore,通过 Kafka + Flink 按 SQL_ID 哈希聚合为模板级时序,以 1 秒和 1 分钟两种粒度存储。采集链路在数据库实例之外运行,不消耗用户实例的计算资源。
异常检测分为两层:Basic Perception Layer 检测单指标的 spike/level shift,Phenomenon Perception Layer 组合多指标模式判定异常类型。检测框架参考了 iSQUAD 3 的异常类型体系,支持用户自定义规则。
3.2 个体 Active Session 估算
为解决 Challenge I,PinSQL 从 query log 反推个体 active session,避免开启高开销的数据库内置监控。
每条查询 q 在 [time(q), time(q) + t_res(q)] 时间段内是活跃的。对于每秒 [t, t+1) 的时间窗口,将其拆分为 K 个等宽 bucket。基于每条查询的活跃区间与各 bucket 的重叠关系,统计该 bucket 内每个 SQL 模板的活跃查询数期望值。然后选取与 SHOW STATUS 采集到的实例级 active session 最接近的 bucket 作为校准基准。
实测效果(论文 Table III):K=10 时,估算值与真实 active session 的 Pearson 相关系数达到 0.96。不分 bucket 的方案相关系数为 0.92,直接用响应时间聚合的方案仅为 0.54。
这个估算在 SHOW STATUS 一秒内只能获取一个采样点的约束下工作,因此存在随机误差。但根因分析依赖的是模板间的相对排序而非绝对值,这种误差对最终结果的影响有限。相比 Performance Schema 方案,该方法不依赖特定数据库版本且完全在实例外运行。
3.3 H-SQL 识别:多层评分融合
为解决 Challenge II,PinSQL 用三个评分维度衡量 SQL 模板对 active session 的影响:
- Trend-level:模板 active session 与实例 active session 的加权 Pearson 相关系数。加权采用基于 Sigmoid 的时间衰减函数,异常时段附近的采样点权重更大,远离异常时段的权重趋于零。平滑因子 k_s 控制衰减速度。
- Scale-level:异常期间模板的累积 active session,经 min-max 归一化到 -1, 1。衡量绝对规模贡献。
- Scale-trend-level:模板 active session 占比(session_Qt / session_t)与实例 active session 的相关性。捕捉「异常期间占比突增」的模板。
简单来讲就是
- SQL 活跃会话曲线和实例整体活跃会话曲线走势像不像?
- 体量够不够大?
- 是不是异常时才突然变大?
时序的思路和TP的判断思路还是完全不一样,更多的是突发模版导致的。
最终评分为三者的加权和,权重由 scale 值最大的模板 Q_max 的相关系数自动校准。
3.4 R-SQL 识别:聚类 + 累积阈值 + 历史验证
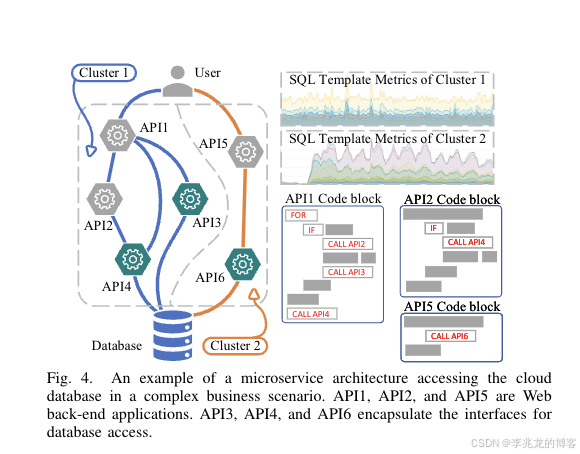
为解决 Challenge III,PinSQL 通过三步操作从 H-SQL 中区分出 R-SQL。
聚类 :微服务架构下同一业务的 SQL 模板有相似的 #execution 趋势。PinSQL 用 Pearson 相关系数构建模板间的邻接矩阵(阈值 τ=0.8),辅以性能指标节点,取连通分量作为业务簇。
累积阈值过滤:不取固定 top-k 簇,而是按 impact© 降序遍历,累加簇内所有模板的 session 贡献,直到与实例 active session 的相关性超过 τ_c=0.95。这保证了在多条业务链路同时出问题时不会遗漏。
历史趋势验证 :对候选模板回看 1/3/7 天历史,用 Tukey 规则检验其 #execution 是否在异常期间才突增,淘汰历史上持续高流量的稳态模板。
3.5 修复模块
PinSQL 提供 SQL 限流(Throttling)、查询优化(自动索引/SQL 重写)和实例弹性扩容(AutoScale)三种动作,默认先限流再优化。论文给出的生产案例(Fig. 8)中,用户曾对 Top SQL 做限流但异常反复出现------因为被限流的是 H-SQL 而非 R-SQL。PinSQL 定位到真实 R-SQL 后执行限流+优化,异常未再复发。
4 RCRank 系统设计
RCRank 来自 Hologres 生产系统,在 TPC 基准上验证。
4.1 数据收集与根因标注
慢查询收集基于执行时间阈值 δ(实验中设为 1 秒)。每条慢查询包含四个模态的信息:SQL 文本、执行计划(DAG)、执行日志(duration、read_rows 等)、系统 KPI 时序(CPU、内存、IO)。
根因标注采用两种方法:Rule-based 方法用于统计信息过期和连接顺序等可自动验证的根因(执行 ANALYZE 或切换优化策略后重跑比较);LLM-based 方法用于索引推荐、分布键和 SQL 重写(将查询信息组成 prompt 由 LLM 推荐修复方案,执行后计算 impact)。该标注流程同时产出了一个可复用的根因影响度数据集。
需要指出,LLM-based 标注存在固有风险:LLM 推荐的修复方案本身可能不正确,导致 impact 计算偏差。论文中由于隐私限制在 Hologres 上无法使用 GPT,改用 vicuna-13B 后标注质量有所下降,但未给出具体量化。
4.2 多模态编码
四个模态使用不同的编码器:SQL 文本用 BERT(bert-base-uncased,使用预训练权重,未做 SQL 领域继续预训练);执行计划用 QueryFormer 7(树结构 Transformer,保留 DAG 拓扑信息);执行日志用三层 MLP(日志是简单数值向量);KPI 时序用 2D-CNN(将多个 KPI 指标按时间步 × 指标种类排列为二维矩阵,用卷积核提取局部时空模式)。
4.3 自监督预训练
RCRank 的预训练利用模态间的天然对应关系:SQL 中的表名出现在执行计划节点中,日志的数值对应执行计划的操作。做法是在某个模态中 mask 关键信息(例如将 SQL 中的表名替换为 <mask>),用一个 Transformer 聚合模块联合其他模态来重建被 mask 的内容。训练目标是最小化各模态的重建误差。KPI 模态使用 auto-encoder 重建损失。
预训练只需要查询数据本身,不需要根因标注,因此可以利用远多于标注集的查询量。
4.4 根因自适应的跨模态融合
融合模块分两部分:
- Common Cross-Modal Transformer(C-CMT):以 SQL embedding 为 query、其他模态为 key/value 做 cross-attention,提取所有根因共享的通用特征。
- Adaptive Cross-Modal Transformer(A-CMT) :为每个根因类型 RC_j 设置独立的 Gating Unit,通过
G_j(E_S) = sigmoid(FC(E_S)) ⊙ E_S控制各模态在该根因诊断中的权重。
Gating Unit 的设计动机:不同根因关注不同的信息源。索引缺失需要看执行计划中的 Scan 节点和日志的 read_rows;统计信息过期需要看 KPI 中的 CPU 波动;SQL 写法问题需要分析 SQL 文本中的冗余操作。消融实验中,去掉 Gating Unit 后所有指标下降最为严重,验证了这种差异化关注的必要性。
4.5 影响度感知的训练目标
除 MSE 预测损失外,RCRank 引入两个正则项:
- Valid Regularization:推动模型对有效根因(impact ≥ ε)和无效根因(impact < ε)产生足够区分度,margin 为 η。
- Order Regularization:约束估计的 impact 排序间距不小于真实间距,防止估计值整体偏移时打乱排序。
两个正则项分别解决识别和排序的精度问题。实验表明缺少任一项都会导致 MC-ACC 和 Tau 指标显著下降。
5 实验结果
5.1 PinSQL
数据集 ADAC 包含 168 个真实异常案例,来自阿里云 36 个实例,94 亿次查询聚合为 77,450 个模板。
对比方法说明:Top-RT = 按总响应时间排序;Top-EN = 按执行次数排序;Top-ER = 按总扫描行数排序;Top-All = 综合多指标取各变体最佳结果。这些是各云厂商 Performance Insights 类产品的标准做法。
| 方法 | R-SQL H@1 | R-SQL H@5 | R-SQL MRR | H-SQL H@1 |
|---|---|---|---|---|
| Top-RT | 31.0 | 56.0 | 0.40 | 64.3 |
| Top-ER | 13.7 | 47.6 | 0.28 | 44.0 |
| Top-EN | 6.5 | 6.5 | 0.08 | 3.0 |
| Top-All | 33.3 | 56.0 | 0.42 | 66.1 |
| PinSQL | 80.4 | 83.9 | 0.82 | 97.6 |
PinSQL 在 R-SQL H@1 上比最优 baseline(Top-All)提升 47 个百分点。Top-All 在 H-SQL H@1 上达到 66.1%,说明 Top-SQL 方法确实能找到受影响的 SQL,但找不到根因。
消融实验中,去掉个体 Active Session 估算(改用聚合响应时间替代)导致 H@1 下降 31.5%,去掉加权综合评分导致下降 3.6%,去掉累积阈值(改用固定 Top-1 簇)也有明显下降。个体 Active Session 估算是贡献最大的单一组件。
整体诊断耗时平均 14.94 秒(Active Session 估算 8.01 秒 + H-SQL 排名 0.47 秒 + 聚类过滤 1.01 秒 + 历史验证 5.45 秒)。对于平均 540 秒的异常持续时间,这个延迟可以接受,但如果需要秒级自动限流决策则仍有优化空间。
5.2 RCRank
评估指标说明:V-ACC = 有效根因识别准确率;Top1-ACC = 影响最大根因的识别准确率;MSE = 影响度估计的均方误差;MC-ACC = 多根因排序准确率;Tau = Kendall 排序相关系数;Top1-IR = 按 Top-1 根因修复后的实际性能提升比例。
| 数据集 | V-ACC | Top1-ACC | MSE | Top1-IR |
|---|---|---|---|---|
| Hologres1 | 0.7628 | 0.5384 | 0.1226±0.1752 | 0.1988 |
| Hologres2 | 0.7420 | 0.4335 | 0.0896±0.1645 | 0.2764 |
| TPC-DS | 0.8466 | 0.6321 | 0.1732±0.1440 | 0.1477 |
对比方法中,OpenGauss 的 V-ACC 在 Hologres1 上为 0.7354、Top1-ACC 为 0.5032;D-Bot(vicuna-13B)的 V-ACC 为 0.3769(无法估计 impact 因此不报 Top1-IR)。RCRank 在所有指标上均为最优。
从实际效果看,按 Top-1 根因修复后,各数据集慢查询运行时间平均减少 24%~30%(Hologres1: 29.36%, Hologres2: 30.54%, TPC-DS: 26.39%)。这是全文中业务意义最直接的数字。
注意 PinSQL 和 RCRank 的处理延迟不宜直接对比:PinSQL 的 14.94 秒是完成一次实例级诊断(从告警到输出 R-SQL 列表),RCRank 的 0.018 秒是单条慢查询的模型推理时间,两者解决的问题粒度不同。
6 ClickHouse 场景下的延伸讨论
PinSQL 和 RCRank 的实验均基于 OLTP 或 HTAP 系统(MySQL、Hologres、PostgreSQL)。以下讨论这些方法在 ClickHouse 等列式 OLAP 引擎上的适用性。
6.1 ClickHouse 的大查询特点
查询粒度与资源消耗模式
ClickHouse 的典型分析查询可能扫描数十亿行,运行时间从秒级到分钟级不等。不同于 OLTP 中「大量短查询 + 少量问题查询」的模式,ClickHouse 中几乎所有查询都是重量级的。根因分析的挑战不是「在海量短查询中找到异常的那条」,而是「在一批本身就很重的查询中找到资源消耗不合理的那条」。
资源争抢的传播机制
ClickHouse 没有 OLTP 意义上的行级/页级事务锁,其并发控制粒度在 data part 级别。PinSQL 的异常传播链模型(R-SQL 通过锁阻塞影响 H-SQL)在 ClickHouse 中不直接适用。ClickHouse 中的资源争抢体现在以下几个维度:
- 内存争抢:大查询的 GROUP BY / ORDER BY / JOIN 操作消耗大量内存,可能触发其他查询的 memory limit exceeded 错误
- IO 带宽争抢:大范围扫描占满磁盘带宽,其他查询的数据读取被延迟
- CPU 争抢:ClickHouse 的向量化执行引擎高度并行,单条查询默认使用全部 CPU 核心(
max_threads默认等于核心数,可通过 settings 限制) - Merge / Mutation 干扰:后台 merge 和异步 mutation(ALTER TABLE UPDATE/DELETE,以 part 重写方式执行)与前台查询争抢 IO 和 CPU
分布式查询的复杂性
ClickHouse 集群中的分布式查询涉及 coordinator 节点和多个 worker 节点。一条慢查询的根因可能不在 SQL 本身,而在于某个 shard 的数据倾斜、网络延迟、或者该 shard 上正在执行的 merge 操作。
6.2 system.query_log 作为诊断数据源
ClickHouse 内置的 system.query_log 表提供了比 MySQL slow log 丰富得多的诊断信息:
sql
SELECT
query_id,
query,
type, -- QueryStart / QueryFinish / ExceptionBeforeStart / ExceptionWhileProcessing
event_time,
query_duration_ms,
read_rows,
read_bytes,
memory_usage,
ProfileEvents, -- 数百个细粒度计数器
Settings
FROM system.query_log
WHERE type = 'QueryFinish'
AND query_duration_ms > 10000
ORDER BY event_time DESCProfileEvents 字段包含了 SelectedParts、SelectedRanges、SelectedGranules、SelectedMarks、OSCPUWaitMicroseconds 等数百个计数器。这些信息对于判断查询的资源消耗模式非常有价值。
需要注意 system.query_log 默认是异步 flush 的(flush_interval_milliseconds 默认 7500ms),在短时间窗口内的诊断可能面临日志不完整的问题。对于 PinSQL 这种需要秒级时序的方法,这个延迟需要通过配置调低 flush 间隔或使用 SYSTEM FLUSH LOGS 来缓解。
对应到 RCRank 的多模态框架:
| RCRank 模态 | ClickHouse 对应 | 差异 |
|---|---|---|
| SQL 文本 | query 字段 | ClickHouse SQL 语法有特殊函数(arrayJoin、materialize 等),需要适配 tokenizer |
| 执行计划 | EXPLAIN PLAN(逻辑计划,树/DAG 结构)/ EXPLAIN PIPELINE(物理执行 pipeline) |
逻辑计划仍为树结构,但物理执行采用 processor graph 模型而非 Volcano iterator |
| 执行日志 | ProfileEvents + query_duration_ms + memory_usage | 信息密度远高于 MySQL 的简单日志,计数器数量达数百个 |
| KPI 时序 | system.metrics / system.asynchronous_metrics | 采集粒度和指标集不同 |
6.3 PinSQL 方法的适配
个体 Active Session 估算的必要性降低
ClickHouse 的 system.processes 表可以直接查询当前正在执行的查询列表。由于 ClickHouse 的并发查询数通常远小于 OLTP 系统(几十到几百,而非数千),查询 system.processes 的开销可以接受(但需注意高频查询时该操作会获取全局锁遍历查询列表,每秒查询数次以上仍可能有影响)。因此 PinSQL 中为规避 Performance Schema 开销而设计的 Active Session 估算技术,在 ClickHouse 场景下必要性降低。
资源争抢传播图
PinSQL 的锁传播链需要替换为基于资源维度的传播模型。一种可能的建模方式是:
以一个具体场景为例。查询 A 是一个大型 GROUP BY,消耗 80% 可用内存;查询 B 随后执行,因内存不足触发 memory limit exceeded 错误而失败;查询 C 本可以使用 hash join 但因剩余内存不足被降级为 partial merge join,响应时间大幅增加。在这个场景中,A 是 R-SQL,B 和 C 是 H-SQL。
从 system.query_log 中可以提取因果关系的信号:
- 时间重叠(必要条件):A 的执行时间段与 B/C 的执行时间段有交集
- 资源竞争证据:A 的
memory_usage与 B 的exception字段(memory limit exceeded)在时间上关联;A 的ProfileEvents['ReadBufferFromFileDescriptorReadBytes']与 C 的OSIOWaitMicroseconds升高在时间上关联 - 反事实验证:A 执行结束后的相同时段内,相似模板的 B'/C' 执行正常
将这种分析形式化:定义资源争抢图 G = (V, E),其中 V 是时间窗口内的所有查询,边 E 基于资源维度的时间重叠和反事实对比构建。R-SQL 是图中入度低但出度高的节点。
SQL 模板聚类的调整
ClickHouse 的业务查询往往来自 BI 工具或报表系统,模板多样性比 OLTP 场景低得多。聚类策略可以从 #execution 趋势扩展为结合查询来源(system.query_log 中的 client_hostname、http_user_agent 等字段)进行分组。
6.4 Workload 视角下的根因分析
上述适配讨论仍局限于单查询或单模板粒度,但 ClickHouse 的使用场景中,workload 层面的因素往往影响更大。
Workload 基线建模
数据库的工作负载通常表现出周期性------工作日与周末不同,月初与月末不同,大促期间与日常不同。建立 workload 的正常基线后,根因分析可以从绝对阈值告警升级为相对于基线的偏差检测。PinSQL 的历史趋势验证(回看 1/3/7 天历史)包含了这个思想的雏形,但没有系统化地建模 workload 的周期性。具体的 workload 基线建模方法可以参考 Ma et al. 9 的 workload forecasting 工作。
Workload 变化作为根因
在 PinSQL 的根因分类中,「业务场景变化」(如双 11 流量突增)被列为第一类根因,但论文的处理方式是将这类场景交给 AutoScale。实际上 workload shift 的诊断需要回答更细粒度的问题:流量增长是均匀的还是集中在某几个模板上?新增流量的 SQL 模板是已有的还是新出现的?workload 的读写比例是否变化?这些答案直接决定应对策略------均匀增长适合扩容,个别模板突增需要限流或优化,新模板出现需要检查索引覆盖。
Workload 隔离与资源管控
ClickHouse 从 24.x 版本开始实验性地引入 workload 级别的资源管控能力(CREATE WORKLOAD / CREATE RESOURCE),在此之前主要通过 max_concurrent_queries、max_memory_usage、quota 和 settings profile 等机制实现隔离。在有 workload 隔离的环境下,根因分析需要扩展为两层:第一层判断异常是发生在某个 workload 内部,还是 workload 间的资源争抢;第二层在定位到具体 workload 后,再做细粒度的 SQL 级诊断。
混合负载干扰
现代云数据库越来越多地支持 HTAP 能力。在同一实例上同时运行 OLTP 短查询和 OLAP 长查询时,一条分析查询可能在无感知的情况下拖慢数百条事务查询。这种跨负载类型的干扰比同类负载内的干扰更难诊断,因为 OLTP 和 OLAP 查询的指标分布、正常基线、资源消耗模式完全不同,需要分别建模后再做交叉分析。
7 方法对比与局限性
7.1 方法对比
| 维度 | PinSQL | RCRank |
|---|---|---|
| 输入 | 实例级异常告警 | 单条慢查询 |
| 输出 | R-SQL 排名列表 | 根因类型 + 影响度排名 |
| 流水线位置 | 上游(先执行) | 下游(对 PinSQL 输出做进一步诊断) |
| 技术路线 | 统计方法(相关系数 + 聚类) | 深度学习(Transformer + 自监督预训练) |
| 是否需要训练 | 否 | 是(预训练 + 有监督微调) |
| 处理延迟 | ~15 秒(实例级诊断) | ~0.018 秒(单查询推理) |
| 可解释性 | 高(每步有明确的统计含义) | 中(Gating Unit 提供一定可解释性) |
| 验证环境 | MySQL(OLTP) | Hologres + TPC(HTAP + benchmark) |
串联使用时需要注意:PinSQL 的误报(将 H-SQL 误判为 R-SQL)会导致 RCRank 在错误的查询上做诊断,但由于 RCRank 诊断的是查询本身的根因类型,即使输入的不是真正的 R-SQL,其诊断结果(如「此查询缺少索引」)仍可能对该查询本身有优化价值。
7.2 局限性
PinSQL 的传播链模型假设 R-SQL 通过锁/资源争抢影响 H-SQL,对于非 SQL 原因的异常(配置变更、硬件故障、网络抖动)不适用。个体 Active Session 估算依赖 query log 的完整性和及时性。#execution 趋势聚类假设同一业务的 SQL 模板有相似趋势,在高度解耦的微服务架构下可能不成立。
RCRank 的根因类型是预定义的固定集合,新出现的根因类型需要重新标注和训练。标注流程中 LLM 的 hallucination 风险可能引入系统性偏差。此外,RCRank 的模型需要定期更新以适应 workload 演化。
两项工作的共同局限在于:都聚焦于单实例内的诊断,对分布式数据库中跨节点的根因传播缺少建模;对 workload 的整体建模不够系统,异常的严重程度应结合 SLO 评估而非仅看指标绝对值。此外,PinSQL 的 168 个案例全部来自阿里云 MySQL,RCRank 的 Hologres 数据集为内部系统不可公开访问,两项工作的结论在其他数据库系统上的外部有效性尚需验证。
8 总结与展望
PinSQL 和 RCRank 分别在大查询根因分析的两个关键环节上给出了系统性的解决方案。PinSQL 通过异常传播链建模和低开销 Active Session 估算,在阿里云生产环境中 R-SQL 定位的 H@1 达到 80.4%。RCRank 通过多模态融合和影响度感知排名,将慢查询端到端加速了 24%~30%。
将这些方法迁移到 ClickHouse 等 OLAP 系统时,需要处理的核心差异是异常传播机制(资源争抢 vs 锁阻塞)和 workload 特征(少量大查询 vs 大量小查询)。ClickHouse 的 system.query_log 和 ProfileEvents 为多模态诊断提供了比 MySQL 更丰富的数据基础,但需要针对列式存储和分布式执行的特点重新设计根因类型和传播模型。
以下方向值得进一步研究:
- PinSQL + RCRank 的端到端集成------从实例异常到具体修复建议的完整闭环,以及误报在流水线中的传播和缓解。
- LLM 在诊断流程中的合理定位------用训练模型做定位和排名,用 LLM 做修复方案生成,用规则引擎做修复执行和验证。随着 LLM 推理速度的提升,D-Bot 类方案的延迟劣势可能逐步缩小。
- Workload 级别的根因分析------包括基线建模、负载分类、资源隔离策略和跨负载干扰检测,构建从 workload 异常到 SQL 级诊断的分层分析框架。
- 自适应根因类型发现------RCRank 的根因集合是固定的,面对 ClickHouse 等不断演化的系统,能否自动发现新的根因类型而非依赖人工扩展。
- 跨实例/跨服务的根因传播------微服务架构中数据库异常可能源自上游服务的行为变化,将诊断范围扩展到服务链路级别。
参考文献
1 Xiaoze Liu, Zheng Yin, Chao Zhao, et al. "PinSQL: Pinpoint Root Cause SQLs to Resolve Performance Issues in Cloud Databases." In ICDE, 2022, pp. 2549-2561.
2 Biao Ouyang, Yingying Zhang, Hanyin Cheng, et al. "RCRank: Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems." Proc. VLDB Endow., 18(4): 1169-1182, 2024.
3 M. Ma, Z. Yin, S. Zhang, et al. "Diagnosing Root Causes of Intermittent Slow Queries in Large-Scale Cloud Databases." Proc. VLDB Endow., 13(8): 1176-1189, 2020.
4 D. Y. Yoon, N. Niu, and B. Mozafari. "DBSherlock: A Performance Diagnostic Tool for Transactional Databases." In SIGMOD, 2016, pp. 1599-1614.
5 G. Li, X. Zhou, J. Sun, et al. "openGauss: An Autonomous Database System." Proc. VLDB Endow., 14(12): 3028-3041, 2021.
6 X. Zhou, G. Li, Z. Sun, et al. "D-Bot: Database Diagnosis System using Large Language Models." Proc. VLDB Endow., 17(10): 2514-2527, 2024.
7 Y. Zhao, G. Cong, J. Shi, and C. Miao. "QueryFormer: A Tree Transformer Model for Query Plan Representation." Proc. VLDB Endow., 15(8): 1658-1670, 2022.
8 V. Jeyakumar, O. Madani, A. Parandeh, et al. "ExplainIt! - A Declarative Root-Cause Analysis Engine for Time Series Data." In SIGMOD, 2019, pp. 333-348.
9 L. Ma, D. V. Aken, A. Hefny, G. Mezerhane, A. Pavlo, and G. J. Gordon. "Query-based Workload Forecasting for Self-Driving Database Management Systems." In SIGMOD, 2018, pp. 631-645.
10 W. Cao, Y. Gao, B. Lin, et al. "Tcprt: Instrument and Diagnostic Analysis System for Service Quality of Cloud Databases at Massive Scale in Real-time." In SIGMOD , 2018, pp. 615-627.
wo