目录
[一,MiniMind Config部分](#一,MiniMind Config部分)
1,MiniMindConfig的父类PretrainedConfig
[3.4,混合专家 (MoE) 参数](#3.4,混合专家 (MoE) 参数)
[二,MiniMind Model部分](#二,MiniMind Model部分)
[1,class RMSNorm(torch.nn.Module):](#1,class RMSNorm(torch.nn.Module):)
[2,class Attention(nn.Module):](#2,class Attention(nn.Module):)
[3,class FeedForward(nn.Module):](#3,class FeedForward(nn.Module):)
[4,class MoEGate(nn.Module):](#4,class MoEGate(nn.Module):)
[5,class MOEFeedForward(nn.Module):](#5,class MOEFeedForward(nn.Module):)
[6,class MiniMindBlock(nn.Module):](#6,class MiniMindBlock(nn.Module):)
[7,class MiniMindModel(nn.Module):](#7,class MiniMindModel(nn.Module):)
[8,class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):](#8,class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):)
8.3,GenerationMixin的重要参数GenerationConfig:
本篇学习的是MiniMind工程下的model/model_minimind.py文件代码,也是在MiniMind学习过程中分解的第一个文件。
model_minimind.py是整个MiniMind模型的大脑和枢纽,它定义了模型的核心架构,而训练脚本(如 train_pretrain.py)通过导入它来实例化模型,推理工具(如 eval_model.py)和部署转换(如 convert_model.py)也围绕它展开。
其中涉及的概念和设计模式是AI学习过程中无法绕过的核心知识点。
代码用注释把这个文件分成了两部分,MiniMind Config和MiniMind Model:
在这两个部分中,定义了很多类和函数,通过对Transformers库中对应类的继承,实现了一个完整模型的各类功能,各个类和函数的关系和功能大概如下:
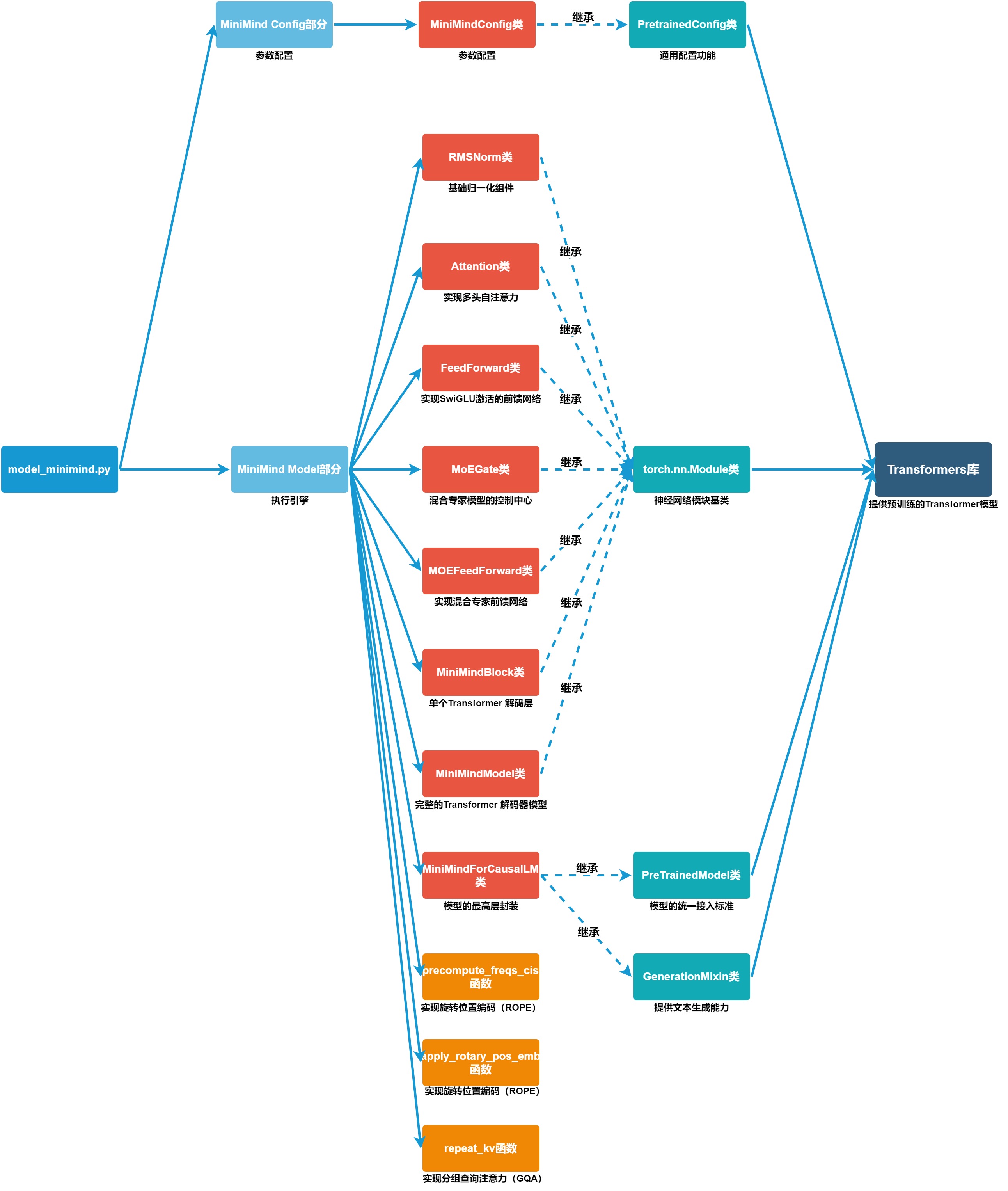
下面详细分解一下。
一,MiniMind Config部分
功能上:
**1,定义所有超参数:**包括模型结构相关的参数(如 hidden_size、num_hidden_layers、vocab_size 等),以及训练或推理时的控制参数(如 dropout、rope_scaling 等)。
**2,负责配置的持久化:**继承自 PretrainedConfig,因此可以方便地使用 save_pretrained() 将配置保存为 config.json 文件,或通过 from_pretrained() 从文件中加载配置。
**3,为模型实例化提供参数:**当创建 MiniMindModel 时,通常会将一个 MiniMindConfig 实例传入其构造函数,模型根据这个配置来构建内部的网络层。
4,对PretrainedConfig的继承使模型可以无缝集成到 transformers 的自动加载机制中(例如 AutoConfig.from_pretrained)。
代码上:
MiniMind Config部分只定义了一个类:MiniMindConfig,父类是PretrainedConfig
class MiniMindConfig(PretrainedConfig):
1,MiniMindConfig的父类PretrainedConfig
PretrainedConfig类是Hugging Face的transformers 库中定义的一个类。
如果本地没有安装transformers 库,可以执行(执行前先切换到自己的conda环境):
pip install transformers
验证是否安装可以执行:
pip show transformers
输出:
(minimind) PS D:\pyworkspace\minimind> pip show transformers
Name: transformers
Version: 4.57.1
Summary: State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow
Home-page: https://github.com/huggingface/transformers
Author: The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)
Author-email: transformers@huggingface.co
License: Apache 2.0 License
Location: d:\miniconda3\envs\minimind\lib\site-packages
Requires: filelock, huggingface-hub, numpy, packaging, pyyaml, regex, requests, safetensors, tokenizers, tqdm
Required-by: peft, sentence-transformers, trl
PretrainedConfig类位于Transformers 库的configuration_utils.py文件。
整个文件里就定义了这么一个类,包含了大量的参数和方法。
1.1,通用参数
建立对象后可用,一般在__init__ 方法中定义,比如:
name_or_path,当通过 from_pretrained 等方法创建配置时,此参数会存储传入的模型名称或路径。
output_hidden_states,是否让模型返回所有隐藏层(Hidden States)的输出。
1.2,通用类属性
属于类本身,直接在类定义体中定义,类似java的静态属性,比如:
model_type,模型的唯一标识符(例如 "bert", "gpt2"),AutoConfig 依靠它来定位正确的模型配置类。
is_composition,一个布尔标志,表示此配置是否由多个子配置(Sub-configs)组合而成。
1.3,序列化与反序列化方法
比如:
to_dict(),将配置对象转换为一个 Python 字典(Dictionary)。
to_json_string(),将配置对象转换为 JSON 格式的字符串。
1.4,其他重要方法
比如:
from_pretrained(),类方法,从本地路径或 Hugging Face Hub 加载一个预训练的配置。
save_pretrained(),实例方法,将当前的配置对象保存到本地指定目录。
update(),实例方法,用一个字典中的键值对来更新当前配置对象的属性。
egister_for_auto_class(),实例方法,将当前配置类注册到指定的 AutoClass(如 AutoConfig)中,使其能够被自动发现。
其他一些该类的说明参考以下页面:
https://hugging-face.cn/docs/transformers/main_classes/configuration
注:
PretrainedConfig 类是 Hugging Face 生态中不可或缺的一部分。它不仅提供了参数与模型权重分离的良好实践,还通过 save_pretrained 和 from_pretrained 等标准方法,为模型配置提供了统一的持久化接口,使得模型、配置的复用、共享和版本管理变得极其方便。
2,MiniMind的MiniMindConfig类
MiniMindConfig 类是 MiniMind 模型的核心"图纸",只有一些参数和初始化方法,没有业务逻辑,定义并控制着模型从整体架构到内部机制的方方面面。
其核心参数包括:
2.1,模型核心结构参数
定义了模型的基础骨架,决定了模型的规模和参数量,是配置时必须首先考虑的部分。
比如:
vocab_size。词汇表大小。指模型能处理的"词语"或"字符"种类总数,相当于模型语言的"字母表"规模
hidden_size。隐藏层维度。模型内部处理和传递信息的"向量"长度,是衡量模型容量的核心指标
num_hidden_layers。Transformer层数。模型堆叠的深度,层数越多,模型对信息抽象和理解的能力理论上越强
num_attention_heads。注意力头数量。模型在处理信息时的"并行观察者"数量,多头机制能让模型从不同角度理解词与词之间的关系
intermediate_size。前馈网络维度。hidden_size 的"放大版",为模型提供更强的非线性变换能力。若不指定,MiniMind 会基于 hidden_size 自动计算一个高效值(通常是其约 2.67 倍)
2.2,注意力机制与位置编码参数
参数专注于模型的"观察"能力,控制着模型如何捕捉文本中的长距离依赖关系。
比如:
max_position_embeddings。最大序列长度。模型能一次性处理的最大文本长度。增加它会平方级地提升计算和内存开销。
rope_theta。RoPE位置编码基值。是旋转位置编码(Rotary Position Embedding)的超参数,影响模型对不同位置信息的分辨能力。
num_key_value_heads 。KV头数量。用于分组查询注意力,默认值为2,小于 num_attention_heads。这个设计能显著减少缓存大小和计算量,提升推理速度。
flash_attn。是否使用Flash Attention。一个高效的注意力实现开关,开启后能有效加速训练并节省显存,通常建议保持开启。
3.3,正则化与激活函数参数
主要负责训练过程的稳定性和模型的泛化能力。
dropout。Dropout概率。一种正则化技术,在训练时随机"丢弃"部分神经元以防止过拟合。MiniMind 默认不使用,可能得益于其较小的规模。
rms_norm_eps。RMSNorm 分母稳定项。在层归一化时添加的一个极小值,防止分母为零,保证数值计算的稳定性。
hidden_act。隐藏层激活函数。决定前馈网络(FFN)如何引入非线性,'silu'(即 Swish)是当前大模型常用的选择,效果通常优于 ReLU。
3.4,混合专家 (MoE) 参数
用于开启和配置高级的 MoE(Mixture of Experts)架构。启用后,模型内部的 FFN 层会被多个"专家网络"替代。计算时只为每个输入激活最合适的少数专家,从而在不大幅增加计算量的前提下,大幅提升模型容量。只有当 use_moe 设置为 True 时,下方参数才生效。
比如:
use_moe。MoE开关。控制是否启用混合专家模型架构。
n_routed_experts。路由专家总数。模型层中所有可被选择的"专家"的总数量。
num_experts_per_tok。每个token选择的专家数。每个输入 token 会从所有专家中选出几个最合适的来激活。
n_shared_experts。共享专家数量。总是被激活的"公共"专家数量,用于捕捉所有输入都可能需要的通用模式。
aux_loss_alpha。辅助损失权重。为了确保专家们"工作量"均衡而添加的辅助损失项的权重系数。
scoring_func。专家评分函数。计算每个专家得分以进行选择的函数,默认为 'softmax'。
seq_aux bool。序列级辅助损失。是否在整个序列级别上计算均衡性辅助损失,而非按单个 token。
norm_topk_prob。归一化Top-k概率。是否对选出的专家权重进行归一化,确保输出分布合理。
参考网页:
https://blog.csdn.net/gitblog_01167/article/details/151856952
https://blog.csdn.net/2401_82540083/article/details/147859612
二,MiniMind Model部分
MiniMind Model部分是模型的"执行引擎"或"网络骨架"。
作用上:
1,构建实际的神经网络层:根据 MiniMindConfig 提供的参数,创建 nn.Embedding、TransformerBlock 列表、最终的 nn.Linear 输出层等。
2,实现前向传播逻辑:定义数据从输入 token ids 到输出 logits 的完整计算流程,包括 embedding、位置编码(RoPE)、多层 Transformer 计算、最终的层归一化和输出投影。
3,处理训练/推理时的细节:比如处理 attention_mask、past_key_values(KV cache)、返回 hidden states 或 attentions 等选项。
MiniMind是基于 Transformer Decoder 架构的因果语言模型,数据流顺序上:
输入 token ids → Embedding → 位置编码(RoPE) → MiniMindBlock × N → RMSNorm → LM Head → logits
其中每个 MiniMindBlock 内部包含:
1,自注意力层(Attention)
2,前馈网络(FeedForward 或 MOEFeedForward)
代码上:
MiniMind Model部分定义了很多的类和方法。
类包括:
1,class RMSNorm(torch.nn.Module):
RMSNorm=Root Mean Square Layer Normalization,基础归一化组件,属于模型的"基础设施"。
在每一层 Transformer 内部(Attention 和 FFN 之后)以及最终输出之前都会使用 RMSNorm。它替代了传统的 LayerNorm,是 MiniMind 性能优化的一个细节。
内部函数:
forward(self, x: torch.Tensor)。
用来计算 RMS。
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
2,class Attention(nn.Module):
Attention类是核心计算层之一,负责捕获序列中不同位置之间的依赖关系。在 Transformer中占据约1/3的参数和计算量。Attention的质量直接决定模型理解上下文的能力。
作用:
实现多头自注意力(Multi-Head Self-Attention),包括:
2.1,RoPE 旋转位置编码
2.2,GQA(Grouped Query Attention):通过 num_key_value_heads 参数实现,可减少 KV cache 大小。
2.3,Flash Attention(可选):当 flash_attn=True 时,使用 F.scaled_dot_product_attention 加速。
2.4,因果掩码(Causal Mask):确保每个 token 只能看到之前的 token。
内部函数:
forward(self, x, pos_cis, past_key_value=None, attention_mask=None, use_cache=False)。
计算注意力输出。
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
3,class FeedForward(nn.Module):
FeedForward类是核心计算层之一,提供非线性变换和特征维度扩展。在 Transformer 中占据约 2/3 的参数。对注意力输出做进一步处理,是模型容量扩展的主要来源。
作用:
实现 SwiGLU 激活的前馈网络(FeedForward)。
标准的 FFN 通常包含两个线性层和一个激活函数,而 SwiGLU 使用三个线性层(一个门控机制)以获得更好的性能。
内部函数:
forward(self, x)
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
4,class MoEGate(nn.Module):
MoEGate类实现混合专家模型(MoE)的门控机制,是MoE架构的控制中心。仅在启用混合专家时使用(config.use_moe=True)。不直接产生输出,而是为MOEFeedForward提供路由决策。
作用:
对于每个输入token,计算所有专家的得分,然后选择得分最高的num_experts_per_tok个专家,并返回这些专家的权重和索引。
内部函数:
forward(self, hidden_states)
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
5,class MOEFeedForward(nn.Module):
MOEFeedForward类实现混合专家前馈网络。是MoE 架构的 FFN 替代品。内部包含多个专家(每个专家是一个 FeedForward 实例),以及一个 MoEGate。
MOEFeedForward 会直接替换普通 FeedForward 出现在 MiniMindBlock 中。
作用:
当模型规模变大时,MoE 可以在不显著增加计算量的情况下大幅增加参数量。
内部函数:
forward(self, x)
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
6,class MiniMindBlock(nn.Module):
MiniMindBlock是是单个Transformer 解码层,模型的基本重复单元,整个模型由 config.num_hidden_layers 个 MiniMindBlock 堆叠而成。每一层都在逐步提炼和转换特征表示。
作用:
将注意力层和前馈层组合在一起,并添加残差连接和层归一化(RMSNorm)。
数据流:
输入 → RMSNorm → Attention → 残差 + 输入 → RMSNorm → FeedForward/MoE → 残差 → 输出
内部函数:
forward(self, x, pos_cis, past_key_value=None, attention_mask=None, use_cache=False)
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
7,class MiniMindModel(nn.Module):
MiniMindModel是完整的 Transformer 解码器模型(不含最终的 LM Head),是 MiniMindForCausalLM 的组成部分,不直接用于文本生成。
作用:
隐藏层计算,后续通过 LM Head 将隐藏状态映射为词表概率。
内部函数:
forward(self, input_ids, attention_mask=None, past_key_values=None, use_cache=False, **kwargs)
父类:
torch.nn.Module是PyTorch 所有神经网络模块的基类。
8,class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
MiniMindForCausalLM代表了一个完整的、可直接进行文本生成的语言模型,是模型的最高层封装,用户可以直接使用此类。比如:
model = MiniMindForCausalLM.from_pretrained("path/to/minimind")
output = model.generate(input_ids, max_new_tokens=100)
内部函数:
forward(self, input_ids, attention_mask=None, labels=None, past_key_values=None, use_cache=False, **kwargs)
prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, **kwargs)。继承自 GenerationMixin 的辅助方法,用于生成时调整输入格式。
_reorder_cache(self, past_key_values, beam_idx)。用于 beam search 时重新排序 KV cache。
父类:
8.1,父类:PreTrainedModel
定义于transformers的modeling_utils.py
class PreTrainedModel(nn.Module, EmbeddingAccessMixin, ModuleUtilsMixin, PushToHubMixin, PeftAdapterMixin):
PreTrainedModel是Transformers 库中所有模型的"根基",提提供了统一的接入标准,并集成了大量底层功能。
功能:
1,序列化与持久化:通过 save_pretrained() 和 from_pretrained() 这两个最核心的方法,实现了模型的一键保存与加载。
2,文本生成能力:通过混入(Mixin)GenerationMixin,让所有继承它的模型都自动获得generate()方法,从而实现文本生成功能。
3,与HF Hub无缝集成:push_to_hub() 方法可以将训练好的模型直接上传至Hugging Face Hub,方便分享和部署。
4,结构灵活调整:提供 resize_token_embeddings() 方法,允许在加载预训练模型后,动态地增加或减少词汇表大小。
5,分布式与高性能计算支持:from_pretrained() 支持 device_map 参数,可将大型模型的不同层分配到不同GPU上,是实现大模型分布式推理的关键。同时,from_pretrained() 也支持 quantization_config 参数,在加载模型时直接应用量化技术(如 bitsandbytes),显著降低模型显存占用。
重要属性(需在子类中指定):
1,config_class。将模型与对应的配置类(如MiniMindConfig)绑定
2,base_model_prefix。指明基础模型的属性名,例如在MiniMindForCausalLM中,其基础模型属性名为model
3,main_input_name。指定模型的主要输入名称(如input_ids或pixel_values),方便AutoClass自动推断
重要方法:
1,from_pretrained()。类方法,从HF Hub或本地路径加载预训练模型的权重和配置
2,save_pretrained()。实例方法,将当前模型的状态字典(state_dict)和配置保存到指定目录
3,push_to_hub()。实例方法,将模型、配置和词表文件上传至Hugging Face Hub
4,generate()。实例方法,继承自GenerationMixin,用于执行文本生成,支持多种解码策略
5,resize_token_embeddings()。实例方法,调整词嵌入矩阵的大小,用于扩展或缩小词汇表
父类介绍:
1,EmbeddingAccessMixin。操作模型的"嵌入层",把词语映射成向量。
2,ModuleUtilsMixin。辅助工具,包括注意力掩码管理,注意力头剪枝,数据类型与设备管理。
3,PushToHubMixin。一键将模型推送到Hugging Face Hub,实现分享和部署。
4,PeftAdapterMixin。引入PEFT,PEFT方法(如LoRA、IA³等)是当下"微调"大模型的主流技术,它能通过仅训练少量额外参数来达到接近全参数微调的效果。
8.2,父类:GenerationMixin
GenerationMixin类定义在transformer的utils.py文件中
class GenerationMixin(ContinuousMixin):
GenerationMixin很重要的一个作用就是提供了 generate() 方法。
GenerationMixin是Hugging Face (HF) Transformers 库中为因果语言模型(Causal LM,如 GPT、MiniMind 这类自回归模型)提供文本生成能力的核心混入类(Mixin class)。
GenerationMixin掌控着生成的宏观流程(循环、停止判断等),但将模型相关的具体细节(如何准备输入、如何管理缓存)委托给模型本身,此委托行为是基于契约完成的。
关键契约:
1,prepare_inputs_for_generation()。在生成的每一步,GenerationMixin 都会调用这个方法,让模型自己准备它所需的输入(如 input_ids, attention_mask 等)。这是自定义模型必须实现的方法。
2,_reorder_cache():在束搜索等过程中,GenerationMixin 会调用这个方法,让模型自己对KV缓存进行重新排序,以对齐不同的候选序列。如果自定义模型不使用束搜索,可以不实现。
8.3,GenerationMixin的重要参数GenerationConfig:
GenerationConfig 类可以控制generate() 的行为,你可以通过它设置输出长度、采样策略等几乎所有生成参数。
GenerationConfig可以设置参数来决定GenerationMixin的解码策略:
1,贪婪搜索 (Greedy Search):始终选择概率最高的下一个词。
2,束搜索(Beam Search):保留多个候选序列(束),在每一步都考虑所有束的可能性,最终选择整体概率最高的序列。
3,Top-K 采样:仅从概率最高的 K 个词中随机采样,排除"长尾"的低概率词。
4,Top-p (核采样, Nucleus Sampling):从总概率超过 p 的最小词集合中随机采样,动态调整候选词数量。
5,温度采样 (Temperature Sampling):通过温度参数调整概率分布的平滑程度。
**6,**对比搜索 (Contrastive Search)
**7,**辅助解码 (Assisted Decoding)
GenerationConfig 的核心参数:
1,控制输出长度:
max_new_tokens,指定要生成的最大新标记数
min_new_tokens,指定要生成的最小新标记数
max_length,指定输入+新标记的总长度
min_length,指定输入+新标记的最小长度
2,选择生成策略
do_sample,是否使用采样(随机性)策略
num_beams,束搜索的束数量
penalty_alpha,对比搜索的平衡参数
3,控制采样行为
temperature,控制概率分布的平滑程度,值越高分布越均匀
top_k,Top-K 采样,仅从概率最高的K个词中选择
top_p,Top-p (核) 采样,从累计概率达到 p 的最小集合中选择
4,避免重复
repetition_penalty,对重复出现的词施加惩罚,降低其概率
no_repeat_ngram_size,禁止生成指定大小的 n-gram 重复
5,控制缓存
use_cache,是否使用KV缓存以加速自回归解码
6,定义停止条件
eos_token_id。指定表示序列结束的 token ID
stop_strings。当生成到指定字符串时停止
7,控制输出内容
num_return_sequences,指定要生成的序列数量
output_scores,是否返回每个生成步骤的分数
9,三个函数
以下三个函数定义在MiniMind Model部分中,共同实现了旋转位置编码(RoPE)和分组查询注意力(GQA)所需的 KV 头重复逻辑。
三个函数分别是:
1,def precompute_freqs_cis(dim: int, end: int = int(32 * 1024)
作用:预先计算 RoPE 所需的旋转角度复数形式(freqs_cis),避免在每次前向传播时重复计算,从而提高效率。
2,def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1)
作用:将旋转位置编码应用到Q和K张量上,即根据位置索引对 Q/K 的每个特征对进行旋转变换。在Attention类的forward中被调用。
3,def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
作用:将 KV 张量的头维度重复n_rep次,用于实现分组查询注意力(GQA)或多查询注意力(MQA)。
参考文档:
https://xuebin.blog.csdn.net/article/details/153338106
over