vLLM v1 KV Offload 模块超深度逐行分析
分析对象:
vllm/vllm/v1/kv_offload代码规模:16 Python 文件(含4个空
__init__.py),1,888 行有效代码
一、模块定位
1.1 业务职责
vLLM v1 kv_offload 模块实现了 KV Cache 的 CPU 卸载(Offloading)------将 GPU VRAM 中不活跃的 KV Cache 块迁移到 CPU 内存,释放 GPU 显存容纳更多并发请求;需要时从 CPU 重载回 GPU。
六大核心业务职责:
| # | 职责域 | 核心功能 | 关键类/方法 |
|---|---|---|---|
| 1 | CPU KV Cache 管理 | CPU内存中管理KV Cache块池,含分配、释放、引用计数 | CPUOffloadingManager._allocate_blocks() / _free_block() |
| 2 | 淘汰策略 | LRU/ARC自适应淘汰最不活跃的块 | LRUCachePolicy.evict() / ARCCachePolicy.evict() |
| 3 | 异步DMA传输 | CUDA Stream + swap_blocks_batch 实现GPU↔CPU异步传输 | SingleDirectionOffloadingHandler.transfer_async() |
| 4 | 复用频率门控 | 过滤仅使用一次的块,避免不值得的卸载 | FilterReusedOffloadingManager.prepare_store() |
| 5 | 多Worker共享 | mmap + 文件协调实现多Worker共享同一CPU缓存区域 | SharedOffloadRegion |
| 6 | Pinned Memory加速 | 可选将mmap区域注册为CUDA pinned memory,加速DMA | pin_mmap_region() |
1.2 系统位置
kv_offload 横跨 Scheduler 和 Worker 两侧 ,通过 LoadStoreSpec 在 SchedulerOutput 中传递协调:
┌──────────────────────────────────────────────────────────┐
│ Scheduler (core/sched/) │
│ └── KV Connector │
│ ├── lookup() → 连续命中前缀长度 │ ← 管理侧
│ ├── prepare_load() / complete_load() │
│ ├── prepare_store() / complete_store() │
│ └── touch() → 淘汰策略更新 │
├──────────────────────────────────────────────────────────┤
│ ★ kv_offload (本模块) ★ │
│ ├── abstract.py → OffloadingManager抽象接口 │
│ ├── spec.py → OffloadingSpec + CanonicalKVCaches │
│ ├── mediums.py → GPULoadStoreSpec/CPULoadStoreSpec │
│ ├── factory.py → OffloadingSpecFactory │
│ ├── reuse_manager.py → FilterReused装饰器 │
│ ├── cpu/ │
│ │ ├── spec.py → CPUOffloadingSpec │
│ │ ├── manager.py → CPUOffloadingManager │
│ │ ├── shared_offload_region.py → mmap共享区域 │
│ │ └── policies/ → LRU/ARC淘汰策略 │
│ └── worker/ │
│ ├── worker.py → OffloadingHandler/Worker │
│ └── cpu_gpu.py → SingleDirectionHandler │
├──────────────────────────────────────────────────────────┤
│ Worker (v1/worker/) │
│ └── GPUModelRunner │ ← 执行侧
│ └── OffloadingWorker.transfer_async() │
└──────────────────────────────────────────────────────────┘跨侧通信路径:
- Scheduler 调用
OffloadingManager.prepare_store()→ 获得PrepareStoreOutput(含CPULoadStoreSpec) - Spec 中的 CPU block_ids 通过
SchedulerOutput传递给 Worker - Worker 调用
OffloadingWorker.transfer_async(job_id, (GPULoadStoreSpec, CPULoadStoreSpec)) SingleDirectionOffloadingHandler执行 GPU→CPU DMA 传输- Worker 调用
get_finished()检测传输完成 - Scheduler 调用
complete_store()标记块可读
1.3 核心业务价值
| # | 价值 | 量化描述 |
|---|---|---|
| 1 | GPU显存扩展 | 将不活跃KV Cache卸载到CPU,等效扩展GPU显存2-10x |
| 2 | 自适应淘汰 | ARC策略自动适应请求模式变化,无需手动调参,命中率比LRU高5-15% |
| 3 | 复用频率过滤 | 避免卸载只用一次的块(如一次性prefill),节省CPU空间和DMA带宽 |
| 4 | 零拷贝mmap共享 | 多Worker共享同一物理内存页,避免数据重复 |
| 5 | 异步DMA传输 | CUDA Stream + Event实现非阻塞传输,不阻塞推理主循环 |
| 6 | Pinned Memory加速 | 注册mmap为pinned memory,DMA带宽提升30-50% |
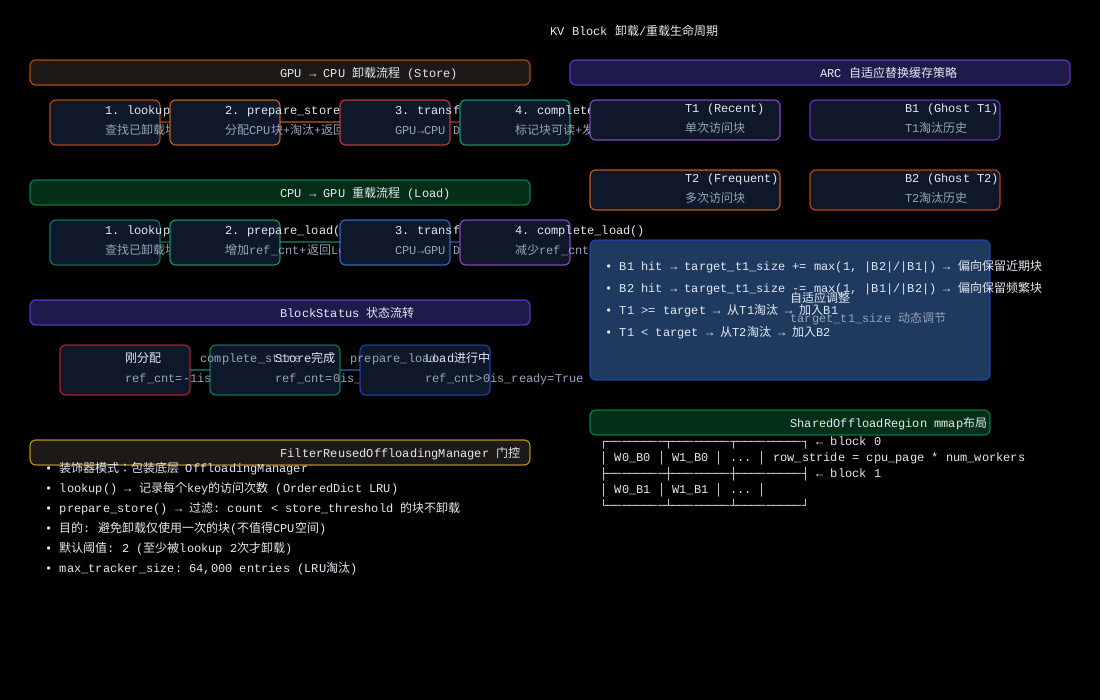
📊 架构总览图

二、模块整体结构
2.1 文件组织与行数
| 文件 | 行数 | 职责 | 核心类/函数 |
|---|---|---|---|
abstract.py |
183 | 抽象接口+核心类型 | OffloadKey, LoadStoreSpec, OffloadingManager |
spec.py |
142 | Spec抽象+Canonical化 | OffloadingSpec, CanonicalKVCaches |
mediums.py |
70 | block定位元数据 | GPULoadStoreSpec, CPULoadStoreSpec |
factory.py |
58 | Spec工厂+延迟注册 | OffloadingSpecFactory |
reuse_manager.py |
115 | 复用频率门控 | FilterReusedOffloadingManager |
cpu/spec.py |
97 | CPU卸载规格实现 | CPUOffloadingSpec |
cpu/manager.py |
196 | CPU缓存管理+淘汰 | CPUOffloadingManager |
cpu/shared_offload_region.py |
192 | mmap共享内存管理 | SharedOffloadRegion |
cpu/policies/abstract.py |
76 | 淘汰策略抽象 | BlockStatus, CachePolicy |
cpu/policies/lru.py |
46 | LRU淘汰 | LRUCachePolicy |
cpu/policies/arc.py |
156 | ARC自适应淘汰 | ARCCachePolicy |
worker/worker.py |
176 | 传输路由+Handler抽象 | OffloadingHandler, OffloadingWorker |
worker/cpu_gpu.py |
381 | 单向传输引擎 | SingleDirectionOffloadingHandler |
2.2 类继承与组合关系
OffloadKey = NewType("OffloadKey", bytes) ← 轻量级key类型
LoadStoreSpec (ABC) ← 跨侧传输元数据抽象
└── BlockIDsLoadStoreSpec (ABC) ← 基于block_ids定位
├── GPULoadStoreSpec ← GPU侧block_ids
└── CPULoadStoreSpec ← CPU侧block_ids
OffloadingManager (ABC) ← Scheduler侧管理抽象
└── CPUOffloadingManager ← CPU缓存管理实现
└── (被FilterReusedOffloadingManager装饰) ← 装饰器模式
OffloadingSpec (ABC) ← Spec抽象
└── CPUOffloadingSpec ← CPU卸载Spec实现
CachePolicy (ABC) ← 淘汰策略抽象
├── LRUCachePolicy ← LRU策略
└── ARCCachePolicy ← ARC策略
OffloadingHandler (ABC) ← Worker侧传输抽象
└── SingleDirectionOffloadingHandler ← 单向DMA传输实现
OffloadingWorker ← 传输路由器(组合多个Handler)2.3 依赖注入链
配置入口: kv_connector_extra_config
│
├── spec_name="CPUOffloadingSpec" (默认)
├── cpu_bytes_to_use=xxx (必须指定)
├── block_size=xxx (可选, CPU block大小)
├── eviction_policy="lru"|"arc" (默认"lru")
├── store_threshold=N (可选, 复用过滤阈值)
└── max_tracker_size=64000 (可选, 复用计数器容量)
│
▼
OffloadingSpecFactory.create_spec()
└── CPUOffloadingSpec(config, kv_cache_config)
│
├── get_manager() ──────────────────────────── Scheduler侧
│ └── CPUOffloadingManager(num_blocks, policy, events)
│ └── [可选] FilterReusedOffloadingManager(backing=manager)
│
└── get_handlers(kv_caches) ───────────────── Worker侧
└── CpuGpuOffloadingHandlers(kv_caches, factor, num_blocks)
├── gpu_to_cpu_handler = SingleDirectionHandler(gpu→cpu)
└── cpu_to_gpu_handler = SingleDirectionHandler(cpu→gpu)2.4 核心方法清单
| 类 | 方法 | 作用 | 复杂度 |
|---|---|---|---|
| OffloadingManager | lookup(keys) |
查找连续命中前缀长度 | O(k) |
| OffloadingManager | prepare_load(keys) |
准备CPU→GPU加载(ref_cnt++) | O(k) |
| OffloadingManager | complete_load(keys) |
完成加载(ref_cnt--) | O(k) |
| OffloadingManager | touch(keys) |
标记最近使用 | O(k) |
| OffloadingManager | prepare_store(keys) |
准备GPU→CPU卸载(分配+淘汰) | O(k+n) |
| OffloadingManager | complete_store(keys, success) |
完成卸载/失败回滚 | O(k) |
| CPUOffloadingManager | _allocate_blocks(keys) |
分配CPU块(fresh+reuse) | O(k) |
| CPUOffloadingManager | _free_block(block) |
释放CPU块到free_list | O(1) |
| LRUCachePolicy | evict(n, protected) |
LRU淘汰n个块 | O(n) |
| ARCCachePolicy | evict(n, protected) |
ARC自适应淘汰n个块 | O(n) |
| ARCCachePolicy | touch(keys) |
自适应学习(B1/B2→调整target) | O(k) |
| FilterReusedOffloadingManager | lookup(keys) |
记录访问次数+委托 | O(k) |
| FilterReusedOffloadingManager | prepare_store(keys) |
过滤低频块+委托 | O(k) |
| SingleDirectionHandler | transfer_async(job_id, spec) |
发起异步DMA传输 | O(k) |
| SingleDirectionHandler | get_finished() |
轮询已完成传输 | O(finished) |
| compute_sub_block_ptrs | --- | 向量化计算子块指针 | O(blocks) |
| SharedOffloadRegion | create_next_view(size) |
创建strided tensor view | O(1) |
| SharedOffloadRegion | cleanup() |
释放所有资源 | O(1) |
| OffloadingSpecFactory | create_spec(config) |
工厂方法创建Spec | O(1) |
📊 生命周期图
三、abstract.py --- 逐行深度解析
文件定位:定义整个模块的抽象接口和核心类型。所有其他文件都依赖此文件。
3.1 模块文档字符串(行1-32)
python
"""
OffloadingManager class for managing KV data offloading in vLLM v1
This class runs in the scheduler, tracks which blocks are offloaded
and their address.
The class provides the following primitives:
lookup() - find the length of the maximal series of blocks,
starting from the first one, that are all offloaded.
prepare_load() - prepare given blocks to be read.
The given blocks will be protected from eviction.
This function returns a LoadSpec which encapsulates
information required for performing the load.
touch() - marks the give blocks as recently used. Can be used
to track block's LRU. This function is separated from the
prepare_load function to allow setting block recency even
for blocks which do not need reading from the cache, such as
blocks that are cached by the GPU prefix cache.
complete_load() - mark blocks which were previously prepared to be
loaded as done loading. This is to re-allow their eviction.
prepare_store() - prepare the given blocks to be written.
Returns a StoreSpec encapsulating offloading information,
as well as a list of blocks that were evicted as a result.
complete_store() - marks a previous store as completed.
Following this call, the given blocks will become loadable.
"""关键设计决策解析:
-
lookup()返回连续前缀长度:而非总命中数。原因:KV Cache 的 block 按序号排列(block 0, 1, 2, ...),加载时必须从最早的缺失块开始连续加载。如果 block 3 缺失,则 block 4-10 即使命中也无法使用(因为推理需要连续的 KV 状态)。因此只需知道前 N 个连续命中即可。 -
touch()与prepare_load()分离 :touch()仅标记"最近使用"但不增加 ref_cnt,也不触发任何传输。存在原因:GPU prefix cache 命中时,KV Cache 已在 GPU 上,不需要从 CPU 加载,但仍需更新 CPU 侧淘汰策略的 LRU/ARC 信息(防止这些块被淘汰)。如果合并到prepare_load()则 prefix cache 命中时不得不调用一个"假加载"来维持 LRU 信息------设计不够干净。 -
complete_store()使块"可加载" :prepare_store()分配块后 ref_cnt=-1(不可读),complete_store()将 ref_cnt 设为0(可读)。这个两阶段设计确保:在 DMA 传输完成前,CPU 块数据不完整,此时如果另一个请求试图加载该块会读到不完整数据。
3.2 OffloadKey 定义(行34-55)
python
from abc import ABC, abstractmethod
from collections.abc import Iterable
from dataclasses import dataclass
from typing import NewType
# 行38-40: OffloadKey类型定义
OffloadKey = NewType("OffloadKey", bytes)NewType 的作用 :NewType 创建的是类型别名,在运行时 OffloadKey 就是 bytes,不做任何包装。好处是:
- 静态类型检查器(mypy/pyright)能区分
OffloadKey和普通bytes,防止混用 - 运行时零开销(不像dataclass有额外内存/创建成本)
- 可用于高频创建场景(每次lookup/prepare都创建key)
为什么用 bytes 而非 tupleblock_hash: bytes, group_idx: int:
- GC压力:Python tuple 会被垃圾收集器跟踪(gc tracked),大量短生命周期 tuple 会导致频繁 GC pause。bytes 不被 GC 跟踪(因为 bytes 不可变且无引用关系)
- 哈希效率 :dict 的
__hash__对 bytes 只计算一次并缓存(CPython 内部优化),tuple 的__hash__需递归计算每个元素 - 紧凑性:block_hash 本身就是 bytes,拼接 4 字节 int 比创建 tuple 少一层间接引用
python
def make_offload_key(block_hash: bytes, group_idx: int) -> OffloadKey:
"""Pack a block hash and group index into an `OffloadKey`."""
return OffloadKey(block_hash + group_idx.to_bytes(4, "big", signed=False))逐行解析:
block_hash:由RequestBlockHasher计算的 block 内容哈希(变长 bytes,通常16-32字节)group_idx.to_bytes(4, "big", signed=False):将组索引编码为4字节大端无符号整数4:固定4字节 → 最多支持 2^32 = 4,294,967,296 个 KV 缓存组(远超实际需求)"big":大端序 → 字典序比较与数值比较一致signed=False:无符号 → 避免负数编码的歧义
block_hash + ...:bytes 拼接 → O(n) 操作,但 OffloadKey 只在 prepare 阶段创建(非热路径)
python
def get_offload_block_hash(key: OffloadKey) -> bytes:
"""Extract the block hash from an `OffloadKey`."""
return key[:-4]切片操作 :key[:-4] 取出除最后4字节外的所有字节 → 即 block_hash。这是 O(n) 拷贝(bytes 切片创建新对象),但只在需要检查 hash 冲突时调用。
python
def get_offload_group_idx(key: OffloadKey) -> int:
"""Extract the group index from an `OffloadKey`."""
return int.from_bytes(key[-4:], "big", signed=False)解码 :key[-4:] 取最后4字节 → int.from_bytes(..., "big", signed=False) 解码为整数。与 make_offload_key 的编码互逆。
设计权衡:为什么不把 hash 长度也编码进 key?→ hash 长度固定(由 hash 算法决定),调用方已知长度,无需额外编码。
3.3 LoadStoreSpec 抽象基类(行57-70)
python
class LoadStoreSpec(ABC):
"""
Abstract metadata that encapsulates information allowing a worker
to load, and optionally also to store, blocks of KV data.
"""
@staticmethod
@abstractmethod
def medium() -> str:
"""
Returns a string representation of the medium type
this store/load targets.
"""
pass@staticmethod + @abstractmethod :medium() 是静态方法,不需要实例就能调用。用途:OffloadingWorker 通过 src.medium() 和 dst.medium() 确定传输类型 (src_medium, dst_medium),从而路由到正确的 Handler。示例:(GPULoadStoreSpec.medium(), CPULoadStoreSpec.medium()) = ("GPU", "CPU")。
设计决策 :为什么 medium() 是静态方法而非类属性?→ Python ABC 的 @abstractmethod 只支持方法。类属性无法声明为抽象。静态方法兼顾了两者的优点:无需实例即可调用(类似类属性),又满足 ABC 的抽象约束。
3.4 PrepareStoreOutput 数据类(行72-76)
python
@dataclass
class PrepareStoreOutput:
keys_to_store: list[OffloadKey] # 实际需要存储的key(已过滤重复)
store_spec: LoadStoreSpec # CPU侧block_ids
evicted_keys: list[OffloadKey] # 因存储而淘汰的key三个字段的完整语义:
keys_to_store:可能少于调用prepare_store(keys)传入的 keys------因为已存储的块被过滤(幂等性),且 FilterReused 装饰器可能过滤低频块store_spec:CPULoadStoreSpec,包含 CPU block_ids 列表。Worker 据此执行 GPU→CPU DMAevicted_keys:为腾出空间而淘汰的块的 key。Scheduler 需要这些信息来更新自己的 block 追踪状态
3.5 OffloadingEvent 数据类(行78-82)
python
@dataclass
class OffloadingEvent:
keys: list[OffloadKey] # 涉及的block keys
medium: str # "CPU"
removed: bool # True=淘汰, False=存储成功用途 :外部监控系统通过 take_events() 获取缓存事件流,分析命中率、淘汰率、存储模式等。removed=True 表示块因空间不足被淘汰;removed=False 表示块成功存储到 CPU。
3.6 OffloadingManager 抽象基类(行84-183)
3.6.1 lookup() --- 行87-104
python
@abstractmethod
def lookup(self, keys: Iterable[OffloadKey]) -> int | None:
"""
Finds the length of the maximal series of blocks, starting from the
first one, that are all offloaded.
Args:
keys: the keys identifying the blocks to lookup.
Returns:
An integer representing the maximal number of blocks that
are currently offloaded, or None if the lookup should be retried
later. Returning None will delay the request handling by the vLLM
scheduler.
"""
pass返回值语义:
0:没有命中任何块 → 无需加载n > 0:前 n 个块已卸载 → 需要加载这些块None:暂无法判断 → 调度器应延迟该请求(例如块正在传输中)
为什么返回 int 而非 listOffloadKey :调用方已持有 keys 列表,返回命中数 n 后,keys[:n] 即为命中的块。这避免了创建新 list 的开销。
3.6.2 prepare_load() --- 行106-122
python
@abstractmethod
def prepare_load(self, keys: Iterable[OffloadKey]) -> LoadStoreSpec:
"""
Prepare the given blocks to be read.
The given blocks will be protected from eviction until
complete_load is called.
It assumes all given blocks are offloaded.
Args:
keys: the keys identifying the blocks.
Returns:
A LoadStoreSpec that can be used by a worker to locate and load
the actual offloaded KV data.
"""
pass前置条件 :It assumes all given blocks are offloaded → 调用方必须先通过 lookup() 确认所有块都已卸载。如果传入未卸载的块,CPUOffloadingManager 会 assert 失败。
副作用 :ref_cnt += 1 → 保护块在 DMA 传输过程中不被淘汰。必须配对调用 complete_load() 来释放保护。
3.6.3 touch() --- 行124-134
python
def touch(self, keys: Iterable[OffloadKey]):
"""
Mark the given blocks as recently used.
This could in practice mean moving them to the end of an LRU list.
Args:
keys: the keys identifying the blocks.
"""
return默认实现为 no-op :不是所有 OffloadingManager 实现都需要 touch。例如,如果使用无淘汰策略(CPU空间无限大),touch 无意义。具体实现在 CPUOffloadingManager 中覆盖。
3.6.4 complete_load() --- 行136-144
python
def complete_load(self, keys: Iterable[OffloadKey]):
"""
Marks previous blocks that were prepared to load as done loading.
Args:
keys: the keys identifying the blocks.
"""
return默认实现为 no-op :与 touch() 同理。具体实现在 CPUOffloadingManager 中减少 ref_cnt。
3.6.5 prepare_store() --- 行146-164
python
@abstractmethod
def prepare_store(self, keys: Iterable[OffloadKey]) -> PrepareStoreOutput | None:
"""
Prepare the given blocks to be offloaded.
The given blocks will be protected from eviction until
complete_store is called.
Args:
keys: the keys identifying the blocks.
Returns:
A PrepareStoreOutput indicating which blocks need storing,
where to store them (LoadStoreSpec), and list of blocks that
were evicted as a result.
None is returned if the blocks cannot be stored.
"""
pass返回 None 的语义:CPU 缓存空间不足以存储这些块,且无法淘汰足够的老块(所有块都在被使用 ref_cnt > 0 或受 protected 保护)。Scheduler 收到 None 后应延迟该请求,等待有块被释放。
3.6.6 complete_store() --- 行166-179
python
def complete_store(self, keys: Iterable[OffloadKey], success: bool = True):
"""
Marks blocks which were previously prepared to be stored, as stored.
Following this call, the blocks become loadable.
If if_success is False, blocks that were not marked as stored will be
removed.
Args:
keys: the keys identifying the blocks.
success: whether the blocks were stored successfully.
"""
returnsuccess=False 路径:DMA 传输失败时(如 CUDA 错误),需要回滚------删除已分配但未成功写入的 CPU 块,释放回 free_list。这保证了 Manager 的状态一致性。
3.6.7 take_events() / shutdown() --- 行181-183
python
def take_events(self) -> Iterable[OffloadingEvent]:
return () # 默认无事件
def shutdown(self) -> None:
return # 默认无需清理take_events() 返回空元组 :元组 () 而非空列表 [],因为元组是不可变单例------每次调用返回同一对象,无需创建新列表。
四、spec.py --- 逐行深度解析
文件定位:定义 OffloadingSpec(规格抽象)和 CanonicalKVCaches(规范化 KV Cache 表示)。
4.1 CanonicalKVCacheTensor(行24-35)
python
@dataclass
class CanonicalKVCacheTensor:
"""
A canonicalized KV cache tensor whose first dimension is num_blocks.
For attention backends where the raw tensor has num_blocks at a
non-leading physical dimension (e.g. FlashAttention's
(2, num_blocks, ...) layout), the tensor is split so that each
resulting CanonicalKVCacheTensor starts with (num_blocks, ...).
"""
# The KV cache tensor with shape (num_blocks, ...)
tensor: torch.Tensor
# The (possibly padded) page size per block in bytes
page_size_bytes: intCanonical化含义:不同 attention backend 的 KV Cache tensor 布局不同:
- FlashAttention:
(2, num_blocks, page_size_bytes)--- K 和 V 交错存储,第一维=2 - 其他 backend:
(num_blocks, page_size_bytes)--- 标准布局
Canonical化将所有格式统一为 (num_blocks, page_size_bytes),使传输代码无需关心底层布局差异。
page_size_bytes vs page_size :page_size_bytes 是字节大小(考虑了 dtype 和填充),而非 token 数。int8 view 下 page_size_bytes == tensor.shape[1]。
4.2 CanonicalKVCacheRef(行37-47)
python
@dataclass
class CanonicalKVCacheRef:
"""
Per-layer (or group of layers) reference to a specific (by index)
CanonicalKVCacheTensor and records the un-padded page size used by that layer.
"""
# Index into the list of CanonicalKVCacheTensor objects
tensor_idx: int
# The un-padded page size per block in bytes
page_size_bytes: int间接引用设计 :多个层可能共享同一个物理 tensor(如 Mamba 层组共享同一 KV Cache buffer),用 tensor_idx 索引而非直接持有 tensor 引用 → 避免重复存储。
page_size_bytes 可能小于 CanonicalKVCacheTensor.page_size_bytes :当 tensor 有填充时(padding),CanonicalKVCacheRef.page_size_bytes 记录实际数据大小,而 CanonicalKVCacheTensor.page_size_bytes 包含填充。当前代码中 TODO 注释表明这个区分尚未在 swap_blocks 中使用。
4.3 CanonicalKVCaches(行49-67)
python
@dataclass
class CanonicalKVCaches:
"""
Canonicalized block-level representation of the KV caches.
Composed of:
- Unique list of KV cache data tensors,
each with shape (num_blocks, page_size_in_bytes) and int8 dtype.
- Per-group data references of the tensors.
i.e. how each KV cache group maps to the tensors.
"""
tensors: list[CanonicalKVCacheTensor]
group_data_refs: list[list[CanonicalKVCacheRef]]两组件的协同:
tensors:去重后的唯一物理 tensor 列表group_data_refs[group_idx]:第 group_idx 组 KV 缓存对应的 tensor 引用列表(一个组可能引用多个 tensor,如 K 和 V 各一个)
去重示例:
FlashAttention 3层:
tensor_0: (num_blocks, K_page_size) --- 层0的K
tensor_1: (num_blocks, V_page_size) --- 层0的V
tensor_2: (num_blocks, K_page_size) --- 层1的K (与tensor_0共享同一物理buffer)
tensor_3: (num_blocks, V_page_size) --- 层1的V (与tensor_1共享同一物理buffer)
去重后:
tensors = [CanonicalKVCacheTensor(tensor_0, ...), CanonicalKVCacheTensor(tensor_1, ...)]
group_data_refs = [
[CanonicalKVCacheRef(tensor_idx=0, ...), CanonicalKVCacheRef(tensor_idx=1, ...)], # group 0
[CanonicalKVCacheRef(tensor_idx=0, ...), CanonicalKVCacheRef(tensor_idx=1, ...)], # group 1
]4.4 OffloadingSpec 抽象基类(行69-142)
4.4.1 init() --- 行76-117
python
class OffloadingSpec(ABC):
def __init__(self, vllm_config: "VllmConfig", kv_cache_config: "KVCacheConfig"):
logger.warning(
"Initializing OffloadingSpec. This API is experimental and "
"subject to change in the future as we iterate the design."
)警告日志:每次初始化都打印实验性 API 警告 → 确保用户知晓 API 可能变更。
python
self.vllm_config = vllm_config
self.kv_cache_config = kv_cache_config
kv_transfer_config = vllm_config.kv_transfer_config
assert kv_transfer_config is not None
self.extra_config = kv_transfer_config.kv_connector_extra_config配置链 :kv_transfer_config 包含 KV 传输相关配置,kv_connector_extra_config 是其中的额外参数字典(含 cpu_bytes_to_use、block_size、eviction_policy 等)。
python
self.hash_block_size = vllm_config.cache_config.block_sizehash_block_size:vLLM 用于前缀缓存哈希的 block 大小(token 数)。所有 KV Cache 组的 block_size 必须是这个值的整数倍。
python
self.gpu_block_size: tuple[int, ...] = tuple(
kv_cache_group.kv_cache_spec.block_size
for kv_cache_group in kv_cache_config.kv_cache_groups
)gpu_block_size 是元组:每个 KV Cache 组可能有不同的 block_size(如 Mamba 组=1 token,Attention 组=16 tokens)。
python
for block_size in self.gpu_block_size:
assert block_size % self.hash_block_size == 0, (
f"gpu_block_size={block_size} not divisible by "
f"hash_block_size={self.hash_block_size}. "
f"Hybrid models (e.g. Mamba+Attention) need "
f"--enable-prefix-caching to align block sizes."
)对齐约束 :每个组的 block_size 必须能被 hash_block_size 整除。原因:OffloadKey 基于 hash block 粒度,如果 GPU block 不对齐,则一个 GPU block 可能跨越多个 hash block → 无法建立一一映射。混合模型需要 --enable-prefix-caching 使 hash_block_size=1,确保任何 block_size 都满足整除条件。
python
self.block_size_factor: int = 1
offloaded_block_size = self.extra_config.get("block_size")
if offloaded_block_size is not None:
offloaded_block_size_int = int(offloaded_block_size)
gpu_block_sizes = set(self.gpu_block_size)
assert len(gpu_block_sizes) == 1, (...)
gpu_block_size = gpu_block_sizes.pop()
assert offloaded_block_size_int % gpu_block_size == 0
self.block_size_factor = offloaded_block_size_int // gpu_block_sizeblock_size_factor 计算:
- 默认
block_size_factor=1→ CPU block 与 GPU block 大小相同 - 如果用户指定
block_size(CPU 卸载的 block 大小),则factor = cpu_block_size / gpu_block_size - 约束:所有 KV Cache 组必须有相同的 block_size →
len(set(...)) == 1 - 约束:CPU block_size 必须是 GPU block_size 的整数倍
设计动机:更大的 CPU block → 更少的 DMA 传输次数 → 更高的 PCIe 带宽利用率。例如 GPU block=16 tokens, CPU block=64 tokens → factor=4 → 一次 DMA 传输 4 个 GPU block 的数据。
4.4.2 get_manager() / get_handlers() --- 行119-142
python
@abstractmethod
def get_manager(self) -> OffloadingManager: pass
@abstractmethod
def get_handlers(
self, kv_caches: CanonicalKVCaches
) -> Iterator[tuple[type[LoadStoreSpec], type[LoadStoreSpec], OffloadingHandler]]:
passget_handlers() 返回 Iterator :使用 yield 而非返回列表 → 延迟创建 Handler(仅在实际需要时创建)→ 减少不必要的初始化开销。
三元组 (src_type, dst_type, handler):
src_type:源端 LoadStoreSpec 类型(如GPULoadStoreSpec)dst_type:目标端 LoadStoreSpec 类型(如CPULoadStoreSpec)handler:处理该方向传输的OffloadingHandler实例
OffloadingWorker 通过 src_type.medium() 和 dst_type.medium() 构建路由 key (src_medium, dst_medium)。
五、mediums.py --- 逐行深度解析
文件定位:定义 GPULoadStoreSpec 和 CPULoadStoreSpec------Worker 侧定位 block 的元数据。
5.1 BlockIDsLoadStoreSpec(行9-18)
python
class BlockIDsLoadStoreSpec(LoadStoreSpec, ABC):
"""
Spec for loading/storing KV blocks from given block numbers.
"""
def __init__(self, block_ids: list[int]):
self.block_ids = np.array(block_ids, dtype=np.int64)
def __repr__(self) -> str:
return repr(self.block_ids)np.array(..., dtype=np.int64):将 Python int 列表转换为 numpy int64 数组。原因:
compute_sub_block_ptrs()需要向量化运算(numpy广播),int64 是指针运算的标准精度swap_blocks_batch()接受 numpy 数组作为输入- 相比 Python list,numpy 数组的内存连续性对 DMA 更友好
__repr__:调试时直接显示 numpy 数组 → 方便查看 block_ids 的值。
5.2 GPULoadStoreSpec(行20-60)
python
class GPULoadStoreSpec(BlockIDsLoadStoreSpec):
def __init__(
self,
block_ids: list[int],
group_sizes: Sequence[int],
block_indices: Sequence[int] | None = None,
):
super().__init__(block_ids)
assert sum(group_sizes) == len(block_ids)
assert block_indices is None or len(block_indices) == len(group_sizes)
self.group_sizes: Sequence[int] = group_sizes
self.block_indices: Sequence[int] | None = block_indices三个字段完整语义:
-
block_ids:所有组的 GPU block ID 拼接在一起。如组0有3个block,组1有2个block,则block_ids = [g0_b0, g0_b1, g0_b2, g1_b0, g1_b1] -
group_sizes:每个组有多少个 block。sum(group_sizes) == len(block_ids)→ 确保 block_ids 被正确分组 -
block_indices:每组内第一个 block 的逻辑索引。用于 block_size_factor > 1 时的非对齐处理。
block_indices 详解:当 CPU block = 4 × GPU block 时:
- 场景:请求从 GPU block 5 开始,block 5 在 CPU block 1 内(CPU block 1 包含 GPU block 4-7)
block_indices[0] = 5→ Worker 知道需要跳过 CPU block 1 的前 5%4=1 个子块block_indices = None→ 只在 GPU→CPU 卸载时使用(卸载总是对齐的)
断言分析:
sum(group_sizes) == len(block_ids):数据完整性校验block_indices is None or len(block_indices) == len(group_sizes):每个组有一个起始索引
python
@staticmethod
def medium() -> str:
return "GPU"5.3 CPULoadStoreSpec(行62-70)
python
class CPULoadStoreSpec(BlockIDsLoadStoreSpec):
@staticmethod
def medium() -> str:
return "CPU"比 GPULoadStoreSpec 简单:无需 group_sizes 和 block_indices,因为 CPU block 总是按 block_size_factor 整数分配,不存在非对齐问题。
六、factory.py --- 逐行深度解析
文件定位:OffloadingSpec 的工厂类,支持延迟加载和自定义 Spec 注册。
6.1 OffloadingSpecFactory(行15-50)
python
class OffloadingSpecFactory:
_registry: dict[str, Callable[[], type[OffloadingSpec]]] = {}类变量而非实例变量:所有实例共享同一注册表 → 一次注册,全局可用。
python
@classmethod
def register_spec(cls, name: str, module_path: str, class_name: str) -> None:
"""Register a spec with a lazy-loading module and class name."""
if name in cls._registry:
raise ValueError(f"Connector '{name}' is already registered.")
def loader() -> type[OffloadingSpec]:
module = importlib.import_module(module_path)
return getattr(module, class_name)
cls._registry[name] = loader延迟加载设计:
register_spec()只存储module_path和class_name,不执行 import → 零启动开销loader()闭包捕获module_path和class_name→ 在首次create_spec()时才 import- 防止重复注册:
if name in cls._registry: raise ValueError
闭包 vs lambda :使用 def loader() 而非 lambda: ... → 更清晰的错误堆栈跟踪。
python
@classmethod
def create_spec(
cls,
config: "VllmConfig",
kv_cache_config: "KVCacheConfig",
) -> OffloadingSpec:
kv_transfer_config = config.kv_transfer_config
assert kv_transfer_config is not None
extra_config = kv_transfer_config.kv_connector_extra_config
spec_name = extra_config.get("spec_name", "CPUOffloadingSpec")默认 spec_name :"CPUOffloadingSpec" → 不指定时使用内置 CPU 卸载实现。
python
if spec_name in cls._registry:
spec_cls = cls._registry[spec_name]()
else:
spec_module_path = extra_config.get("spec_module_path")
if spec_module_path is None:
raise ValueError(f"Unsupported spec type: {spec_name}")
spec_module = importlib.import_module(spec_module_path)
spec_cls = getattr(spec_module, spec_name)双路径查找:
- 注册表路径:
spec_name in _registry→ 调用 loader() → import + getattr - 自定义路径:用户指定
spec_module_path→ 直接 import + getattr - 都不匹配:
raise ValueError
为什么不只用注册表 :自定义 Spec 可能来自第三方库,无法在 vLLM 启动时注册。spec_module_path 提供了无需修改 vLLM 代码的扩展机制。
python
assert issubclass(spec_cls, OffloadingSpec)
logger.info("Creating offloading spec with name: %s", spec_name)
return spec_cls(config, kv_cache_config)类型校验 :issubclass 确保 Spec 类符合接口约定。
6.2 内置注册(行52-58)
python
OffloadingSpecFactory.register_spec(
"CPUOffloadingSpec", "vllm.v1.kv_offload.cpu.spec", "CPUOffloadingSpec"
)模块加载时自动注册:import factory.py 时执行 → CPUOffloadingSpec 立即可用。
七、reuse_manager.py --- 逐行深度解析
文件定位:FilterReusedOffloadingManager------复用频率门控装饰器,过滤仅使用一次的块。
7.1 设计动机深度分析
问题场景:
- Prefill 阶段产生大量 KV Cache block
- 大多数 block 只会被该请求自己使用一次(decode 阶段逐步生成,不再需要 prefill 的完整 KV)
- 卸载这些"一次性"block 到 CPU 的成本:
- CPU 缓存空间:占用本可留给频繁使用 block 的空间
- DMA 带宽:GPU→CPU 传输 + 后续 CPU→GPU 重载 = 2 次传输
- 淘汰压力:可能导致频繁使用的 block 被淘汰
解决方案:只卸载被 lookup 至少 N 次的 block(N 默认 2),即至少被 2 个不同请求需要。
7.2 init() --- 行41-60
python
def __init__(
self,
backing: OffloadingManager,
store_threshold: int = 2,
max_tracker_size: int = 64_000,
):
if store_threshold < 2:
raise ValueError(
"FilterReusedOffloadingManager store_threshold must be >= 2, "
f"got {store_threshold}"
)store_threshold >= 2 的原因:
threshold=1:任何被 lookup 一次的块都满足 ≥1 → 等于不过滤 → 无意义threshold=0:所有块都满足 ≥0 → 完全不过滤 → 应使用底层 manager 直接threshold=2:至少被 lookup 2 次才卸载 → 过滤一次性块
python
if max_tracker_size < 1:
raise ValueError(
"FilterReusedOffloadingManager max_tracker_size must be >= 1, "
f"got {max_tracker_size}"
)max_tracker_size 下限:至少能追踪1个 key → 防止空计数器导致逻辑错误。
python
self._backing = backing
self.store_threshold = store_threshold
self.max_tracker_size = max_tracker_size
self.counts: OrderedDict[OffloadKey, int] = OrderedDict()OrderedDict 用途 :维护 LRU 顺序 → 当 counts 满时(len >= max_tracker_size),淘汰最旧的条目。
内存估算:64,000 entries × (OffloadKey ~20 bytes + int 28 bytes + OrderedDict overhead ~100 bytes) ≈ 9.5 MB → 可忽略。
7.3 lookup() --- 行64-77
python
def lookup(self, keys: Iterable[OffloadKey]) -> int | None:
"""Record each key, then delegate lookup to backing manager."""
keys = list(keys)为什么要 list(keys) :keys 是 Iterable,可能只能遍历一次(如 generator)。转为 list 确保:
- 可以遍历两次(一次记录计数,一次委托 backing.lookup)
- backing.lookup() 也能安全遍历
python
for key in keys:
if key in self.counts:
self.counts.move_to_end(key) # LRU更新:移到末尾
self.counts[key] += 1 # 计数+1
else:
if len(self.counts) >= self.max_tracker_size:
self.counts.popitem(last=False) # 淘汰最旧条目(首部)
self.counts[key] = 1 # 首次访问:计数=1三种操作:
- 已存在 :
move_to_end()+count += 1→ LRU 更新 + 累计 - 不存在 + 容量满 :
popitem(last=False)淘汰 LRU → 然后插入 - 不存在 + 有空间 :直接插入
count=1
O(1) 保证 :OrderedDict 的 in/get/move_to_end/popitem 都是 O(1)。
python
return self._backing.lookup(keys)委托:计数记录完毕后,将原样 keys 传给底层 manager 查找命中数。
7.4 prepare_store() --- 行79-96
python
def prepare_store(self, keys: Iterable[OffloadKey]) -> PrepareStoreOutput | None:
keys = list(keys)
eligible = [
key for key in keys if self.counts.get(key, 0) >= self.store_threshold
]过滤逻辑 :counts.get(key, 0) --- 如果 key 从未被 lookup(计数不存在),则计为0,不满足 threshold → 被过滤。这意味着从未被 lookup 的块永远不会被卸载。
问题:如果 lookup 和 prepare_store 针对同一批 keys,那么 lookup 会先记录 count=1,但 prepare_store 需要 count >= 2 → 首次 lookup 的块不会被卸载。这是正确的行为:首次 lookup 说明块仅被一个请求需要。
python
return self._backing.prepare_store(eligible)空列表安全性 :eligible=[] 时,CPUOffloadingManager.prepare_store([]) 返回 PrepareStoreOutput(keys_to_store=[], store_spec=..., evicted_keys=[]) → 空操作,安全。
7.5 委托方法 --- 行98-116
python
def prepare_load(self, keys: Iterable[OffloadKey]) -> LoadStoreSpec:
return self._backing.prepare_load(keys)
def touch(self, keys: Iterable[OffloadKey]) -> None:
return self._backing.touch(keys)
def complete_load(self, keys: Iterable[OffloadKey]) -> None:
return self._backing.complete_load(keys)
def complete_store(self, keys: Iterable[OffloadKey], success: bool = True) -> None:
return self._backing.complete_store(keys, success)
def take_events(self) -> Iterable[OffloadingEvent]:
return self._backing.take_events()纯委托:这些方法无需拦截,直接传递给底层 manager。装饰器模式的优雅之处:只修改需要的行为(lookup 和 prepare_store),其余透明传递。
八、cpu/spec.py --- 逐行深度解析
文件定位:CPUOffloadingSpec------CPU 卸载规格的实现,连接配置与 Manager/Handler。
8.1 init() --- 行17-39
python
class CPUOffloadingSpec(OffloadingSpec):
def __init__(self, vllm_config: VllmConfig, kv_cache_config: KVCacheConfig):
super().__init__(vllm_config, kv_cache_config)
cpu_bytes_to_use = self.extra_config.get("cpu_bytes_to_use")
if not cpu_bytes_to_use:
raise Exception(
"cpu_bytes_to_use must be specified in kv_connector_extra_config"
)必需配置 :cpu_bytes_to_use 是唯一必须指定的参数 → 决定 CPU 缓存的总容量(字节)。
python
assert kv_cache_config is not None
if kv_cache_config.num_blocks > 0:
total_gpu_kv_bytes = sum(t.size for t in kv_cache_config.kv_cache_tensors)
kv_bytes_per_block = (
total_gpu_kv_bytes // kv_cache_config.num_blocks
) * vllm_config.parallel_config.world_size
else:
kv_bytes_per_block = 0每 GPU block 的 KV 字节数计算:
sum(t.size for t in kv_cache_config.kv_cache_tensors)→ GPU 上所有 KV Cache tensor 的总字节数total_gpu_kv_bytes // kv_cache_config.num_blocks→ 每个 GPU block 的字节数(单 Worker)× world_size→ 考虑张量并行(TP),每个 Worker 只存储自己分片的 KV,总数据量 = 单Worker × TP度
为什么乘 world_size:CPU 缓存需要存储所有 TP Worker 的 KV 数据。每个 Worker 只有一份 KV 分片,但 CPU 缓存区域是所有 Worker 共享的(mmap),需要预留每个 Worker 的空间。
python
kv_bytes_per_offloaded_block = kv_bytes_per_block * self.block_size_factor
self.num_blocks = (
int(cpu_bytes_to_use) // kv_bytes_per_offloaded_block
if kv_bytes_per_offloaded_block > 0
else 0
)CPU block 数量计算 :cpu_bytes_to_use / (每GPUblock字节数 × block_size_factor)。block_size_factor > 1 时,每个 CPU block 更大,因此能容纳的 CPU block 数更少。
python
self._manager: OffloadingManager | None = None
self._handlers: CpuGpuOffloadingHandlers | None = None
self.eviction_policy: str = self.extra_config.get("eviction_policy", "lru")延迟创建 :_manager 和 _handlers 初始为 None,首次 get_manager() / get_handlers() 时创建 → 避免不必要的初始化。
8.2 get_manager() --- 行41-65
python
def get_manager(self) -> OffloadingManager:
if not self._manager:
kv_events_config = self.vllm_config.kv_events_config
enable_events = (
kv_events_config is not None and kv_events_config.enable_kv_cache_events
)事件开关 :kv_events_config.enable_kv_cache_events → 是否发射 OffloadingEvent。事件用于外部监控,有少量性能开销(list append + clear),默认关闭。
python
self._manager = CPUOffloadingManager(
num_blocks=self.num_blocks,
cache_policy=self.eviction_policy,
enable_events=enable_events,
)先创建底层 manager。
python
store_threshold = int(self.extra_config.get("store_threshold", 0))
if store_threshold >= 2:
max_tracker_size = int(
self.extra_config.get("max_tracker_size", 64_000)
)
self._manager = FilterReusedOffloadingManager(
backing=self._manager,
store_threshold=store_threshold,
max_tracker_size=max_tracker_size,
)
return self._manager条件装饰 :store_threshold >= 2 时才创建 FilterReused 装饰器。store_threshold=0(默认)→ 不装饰,直接返回底层 manager。
注意 :self._manager 被重新赋值为装饰器 → 后续调用 get_manager() 返回的是装饰器而非底层 manager。这是装饰器模式的标准用法。
8.3 get_handlers() --- 行67-97
python
def get_handlers(
self, kv_caches: CanonicalKVCaches
) -> Iterator[tuple[type[LoadStoreSpec], type[LoadStoreSpec], OffloadingHandler]]:
if not self._handlers:
if not current_platform.is_cuda_alike():
raise Exception(
"CPU Offloading is currently only supported on CUDA-alike GPUs"
)平台限制 :DMA 传输使用 CUDA API → 仅支持 CUDA 兼容 GPU。ROCm (AMD) 通过 is_cuda_alike() 返回 True,CPU/XPU 不支持。
python
self._handlers = CpuGpuOffloadingHandlers(
kv_caches=kv_caches,
block_size_factor=self.block_size_factor,
num_cpu_blocks=self.num_blocks,
)
assert self._handlers is not None
yield GPULoadStoreSpec, CPULoadStoreSpec, self._handlers.gpu_to_cpu_handler
yield CPULoadStoreSpec, GPULoadStoreSpec, self._handlers.cpu_to_gpu_handleryield 两个方向:
(GPULoadStoreSpec, CPULoadStoreSpec, gpu_to_cpu_handler)→ GPU→CPU 卸载(CPULoadStoreSpec, GPULoadStoreSpec, cpu_to_gpu_handler)→ CPU→GPU 重载
注册到 OffloadingWorker 后:
transfer_type=("GPU", "CPU")→ 路由到gpu_to_cpu_handlertransfer_type=("CPU", "GPU")→ 路由到cpu_to_gpu_handler
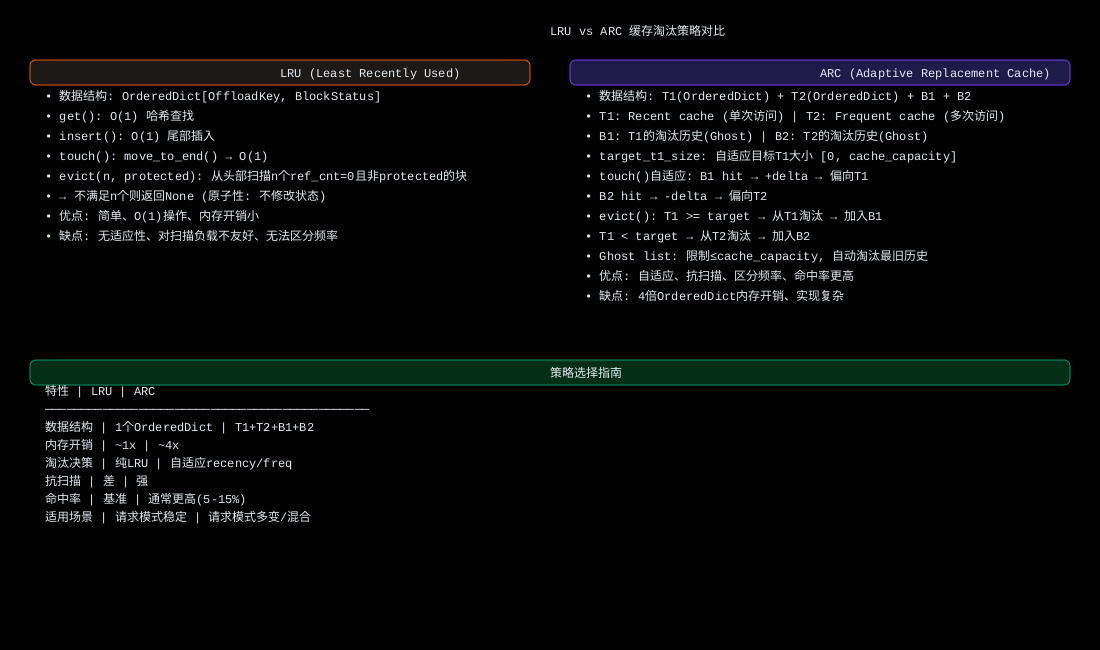
📊 缓存策略对比图
九、cpu/policies/ --- 淘汰策略逐行深度解析
9.1 BlockStatus (abstract.py)
python
import ctypes
from abc import ABC, abstractmethod
from collections.abc import Iterable
from vllm.v1.kv_offload.abstract import OffloadKey
class BlockStatus(ctypes.Structure):
_fields_ = [("ref_cnt", ctypes.c_int32), ("block_id", ctypes.c_int64)]
def __init__(self, block_id: int):
super().__init__()
self.ref_cnt = -1 # 初始值-1 → "未就绪"
self.block_id = block_idctypes.Structure vs Python dataclass 深度对比:
| 维度 | ctypes.Structure | Python dataclass |
|---|---|---|
| 内存布局 | 固定16字节(4+8+padding) | ~56字节(PyObject_HEAD + dict + 属性) |
| GC跟踪 | 不被GC跟踪(无引用关系) | 被GC跟踪(dict/values可能含引用) |
| 创建开销 | ~0(仅赋值4+8字节) | ~100ns(PyObject创建+dict初始化) |
| dict中的行为 | hash基于id(不可变) | hash基于id(可变,有风险) |
| 序列化 | 直接内存拷贝 | 需要显式序列化 |
选择 ctypes 的三大原因:
- 内存紧凑:16 vs 56 字节 → 当缓存含数万个块时,差距显著
- GC友好:大量短生命周期的 BlockStatus 不增加 GC pause
- 缓存友好:紧凑排列时CPU缓存行命中率更高
ref_cnt=-1 语义:
-1:块已分配但数据尚未写入(is_ready=False)0:数据已写入,可被读取,可被淘汰>0:块正在被传输(加载中),不可淘汰
python
@property
def is_ready(self) -> bool:
return self.ref_cnt >= 0用 ref_cnt 范围替代 is_ready 布尔字段 :节省一个布尔字段的内存(ctypes padding 本来会占用这个空间),且语义更精确------is_ready=True 等价于 "ref_cnt ≥ 0,数据可读"。
9.2 CachePolicy 抽象基类 (abstract.py:33-76)
python
class CachePolicy(ABC):
"""
Encapsulates both block organization (data structures) and replacement
decisions (which block to evict). LRU and ARC differ in both dimensions ---
ARC's ghost lists and target_t1_size live at the intersection of storage
and eviction, so they cannot be separated cleanly.
"""设计决策:为什么不将"存储"和"淘汰"分成两个抽象?→ ARC 的 Ghost List(B1/B2)既属于存储结构(记录淘汰历史),又属于淘汰决策(自适应调整 target_t1_size)。强行分离会导致接口不自然。
六大抽象方法:
get(key) → BlockStatus | None--- 查找insert(key, block)--- 插入新块remove(key)--- 删除块touch(keys)--- 标记最近使用evict(n, protected) → list | None--- 淘汰n个块
evict() 的原子性契约:
python
def evict(self, n, protected) -> list[tuple[OffloadKey, BlockStatus]] | None:
"""
Evict exactly n blocks, skipping any in protected.
Returns None if n evictions cannot be satisfied.
The operation is atomic: if None is returned, no state changes are made.
"""原子性实现方式:先扫描收集 n 个候选,不足则返回 None 且不修改状态;足够则批量删除。这避免了"淘汰了3个但需要5个"的部分修改问题。
9.3 LRUCachePolicy (lru.py) --- 逐行解析
python
class LRUCachePolicy(CachePolicy):
def __init__(self, cache_capacity: int):
self.blocks: OrderedDict[OffloadKey, BlockStatus] = OrderedDict()cache_capacity 参数未使用 :接受参数仅为统一构造函数签名(与 ARC 一致),实际容量由外部 _num_blocks 控制。
python
def get(self, key: OffloadKey) -> BlockStatus | None:
return self.blocks.get(key)O(1) dict 查找 :不调用 move_to_end() → get() 不修改 LRU 顺序。只有 touch() 才更新。
python
def insert(self, key: OffloadKey, block: BlockStatus) -> None:
self.blocks[key] = block尾部插入 :OrderedDict 的 __setitem__ 将新项插入末尾 → 新块自然成为 MRU。
python
def remove(self, key: OffloadKey) -> None:
del self.blocks[key]O(1) 删除 :OrderedDict 的 __delitem__ 是 O(1)。
python
def touch(self, keys: Iterable[OffloadKey]) -> None:
for key in reversed(list(keys)):
if key in self.blocks:
self.blocks.move_to_end(key)反序遍历 :reversed(list(keys)) → 保持原始顺序语义。如果 keys = A, B, C,正序 touch 后 C 在最后(MRU),反序 touch 后 A 在最后。反序使得最早传入的 key 成为 MRU → 与"最早使用的块最近使用"的直觉一致。
if key in self.blocks:仅更新存在于缓存中的块 → 忽略未卸载的块(安全)。
python
def evict(
self, n: int, protected: set[OffloadKey]
) -> list[tuple[OffloadKey, BlockStatus]] | None:
if n == 0:
return []n=0 快速路径:无需淘汰 → 返回空列表。
python
candidates: list[tuple[OffloadKey, BlockStatus]] = []
for key, block in self.blocks.items():
if block.ref_cnt == 0 and key not in protected:
candidates.append((key, block))
if len(candidates) == n:
break淘汰条件:
ref_cnt == 0:块没有被传输使用 → 可安全淘汰key not in protected:块不在当前请求中 → 避免循环淘汰
OrderedDict.items() 顺序:从 LRU 到 MRU → 自然优先淘汰最久未使用的块。
python
if len(candidates) < n:
return None # 不足 → 原子性:不修改状态
for key, _ in candidates:
del self.blocks[key] # 批量删除
return candidates两阶段操作:先收集,后删除 → 保证原子性。
9.4 ARCCachePolicy (arc.py) --- 逐行深度解析
9.4.1 数据结构初始化
python
class ARCCachePolicy(CachePolicy):
def __init__(self, cache_capacity: int):
self.cache_capacity: int = cache_capacity
self.target_t1_size: float = 0.0
self.t1: OrderedDict[OffloadKey, BlockStatus] = OrderedDict()
self.t2: OrderedDict[OffloadKey, BlockStatus] = OrderedDict()
self.b1: OrderedDict[OffloadKey, None] = OrderedDict()
self.b2: OrderedDict[OffloadKey, None] = OrderedDict()四大结构详解:
| 结构 | 类型 | 存储内容 | 语义 |
|---|---|---|---|
| T1 | OrderedDictkey, BlockStatus | 数据块 | Recent:仅被访问一次的块 |
| T2 | OrderedDictkey, BlockStatus | 数据块 | Frequent:被访问多次的块 |
| B1 | OrderedDictkey, None | 仅key | Ghost T1:T1淘汰历史 |
| B2 | OrderedDictkey, None | 仅key | Ghost T2:T2淘汰历史 |
Ghost List 为什么只存 key 不存 BlockStatus:
- 块已被释放(block_id 归还 free_list),BlockStatus 已无效
- 仅需知道"这个key曾经被缓存过"即可 → 用于自适应调整
- 内存极低:key(bytes) + None ≈ 20 字节/条目 vs BlockStatus 的 16 字节 + dict overhead
target_t1_size = 0.0:初始为0 → 初始时所有空间偏向 T2(frequent)。随着 B1 hit 逐渐增大,T1 空间增加。
9.4.2 get()
python
def get(self, key: OffloadKey) -> BlockStatus | None:
return self.t1.get(key) or self.t2.get(key)查找顺序 :先查 T1,再查 T2。or 的短路求值 → T1 命中则不查 T2。
注意 :BlockStatus 是 ctypes.Structure,其布尔值为 True(非空结构体)→ or 语义正确。但如果 BlockStatus 的所有字段为0呢?→ ref_cnt=-1, block_id=0 → ctypes Structure 的 __bool__ 返回 True(有字段)→ 安全。
9.4.3 insert()
python
def insert(self, key: OffloadKey, block: BlockStatus) -> None:
self.t1[key] = block # 新块总是进入T1
self.b1.pop(key, None) # 如果在Ghost T1中 → 移除
self.b2.pop(key, None) # 如果在Ghost T2中 → 移除设计:
- 新块进入 T1(recent cache)→ 后续 touch 可能提升到 T2
- 从 Ghost List 移除 → 避免重复追踪(已在真实缓存中)
9.4.4 remove()
python
def remove(self, key: OffloadKey) -> None:
if self.t1.pop(key, None) is None:
self.t2.pop(key, None)两步查找 :先 T1 后 T2。pop(key, None) → 不存在时不报错 → 安全。
不从 Ghost List 移除:remove 用于清理失败的 store,此时块刚进入 T1(不可能在 Ghost List 中)→ 无需清理 Ghost。
9.4.5 touch() --- 自适应学习核心
python
def touch(self, keys: Iterable[OffloadKey]) -> None:
for key in reversed(list(keys)):反序遍历:同 LRU,保持原始顺序语义。
python
if key in self.t1:
block = self.t1.pop(key)
if not block.is_ready:
self.t1[key] = block # 未就绪 → 留在T1,仅更新MRU
else:
self.t2[key] = block # 就绪 → 提升到T2T1 → T2 提升条件:
block.is_ready(ref_cnt ≥ 0)→ 块数据可读,确实被第二次访问 → 提升not block.is_ready(ref_cnt = -1)→ 块刚 prepare_store 但还未 complete_store → 不是真正的"第二次访问" → 仅更新 MRU 位置
关键洞察 :touch() 在 prepare_store() 之后、complete_store() 之前可能被调用(Scheduler 可能在同一轮中先 store 再 touch 其他请求的块)。此时块尚未就绪,不应提升。
python
elif key in self.t2:
self.t2.move_to_end(key) # T2中:更新MRU位置
python
elif key in self.b1:
delta = max(1, len(self.b2) / len(self.b1))
self.target_t1_size = min(
self.target_t1_size + delta, self.cache_capacity
)
self.b1.move_to_end(key)B1 hit 自适应逻辑:
- delta 计算 :
max(1, |B2|/|B1|)→ 如果 B2 比 B1 大很多,delta 更大 → T1 应该获得更多空间 - target_t1_size 增加 → 下次淘汰时更多从 T2 淘汰(而非 T1)→ 保留更多 recent 块
- b1.move_to_end(key) → 更新 Ghost 中的 MRU 位置
直觉解释:B1 hit 说明"一个曾经被淘汰的 recent 块又被需要了"→ 我们应该保留更多 recent 块(增大 T1 配额)。
python
elif key in self.b2:
delta = max(1, len(self.b1) / len(self.b2))
self.target_t1_size = max(self.target_t1_size - delta, 0)
self.b2.move_to_end(key)B2 hit 自适应逻辑:与 B1 hit 相反 → 减小 target_t1_size → 保留更多 frequent 块。
delta 的比例调整 :|B1|/|B2| 而非固定值 → 当一个 Ghost List 远大于另一个时,调整幅度更大 → 更快收敛到最优配比。
9.4.6 evict() --- 自适应淘汰核心
python
def evict(
self, n: int, protected: set[OffloadKey]
) -> list[tuple[OffloadKey, BlockStatus]] | None:
if n == 0:
return []
python
candidates: list[tuple[OffloadKey, BlockStatus, bool]] = []
already_selected: set[OffloadKey] = set()
virtual_t1_size = len(self.t1)虚拟状态 :virtual_t1_size 和 already_selected 用于在不修改实际数据结构的情况下模拟淘汰选择 → 保证原子性。
python
for _ in range(n):
candidate: tuple[OffloadKey, BlockStatus, bool] | None = None
if virtual_t1_size >= int(self.target_t1_size):
for key, block in self.t1.items():
if (
block.ref_cnt == 0
and key not in protected
and key not in already_selected
):
candidate = (key, block, True) # from_t1=True
virtual_t1_size -= 1
break选择逻辑 :virtual_t1_size >= int(target_t1_size) → T1 占比过大 → 从 T1 淘汰。
python
if candidate is None:
for key, block in self.t2.items():
if (
block.ref_cnt == 0
and key not in protected
and key not in already_selected
):
candidate = (key, block, False) # from_t1=False
break
if candidate is None:
return None # 无法找到足够候选 → 原子回滚回退到 T2:T1 没有可淘汰块 → 从 T2 淘汰。
python
candidates.append(candidate)
already_selected.add(candidate[0])防止重复选择 :already_selected set → 同一个 key 不会被选中两次。
python
result: list[tuple[OffloadKey, BlockStatus]] = []
for key, block, from_t1 in candidates:
if from_t1:
del self.t1[key]
self.b1[key] = None # T1淘汰 → 加入Ghost T1
else:
del self.t2[key]
self.b2[key] = None # T2淘汰 → 加入Ghost T2
result.append((key, block))Ghost List 更新:淘汰的块进入对应的 Ghost List → 未来的 touch 可能命中 Ghost → 触发自适应调整。
python
for ghost in (self.b1, self.b2):
for _ in range(len(ghost) - self.cache_capacity):
ghost.popitem(last=False) # 淘汰最旧的Ghost条目Ghost List 容量限制 :每个 Ghost List 最多 cache_capacity 个条目 → 防止无限增长。超出部分按 FIFO(popitem(last=False) → 删除最早加入的)淘汰。