

一、进程优先级
在计算机系统中,系统资源通常是有限的比如CPU资源。为了平衡系统性能同时确保每一个进程都能被系统调度与执行,操作系统系统可以通过调整优先级,确保关键任务(如系统进程、实时任务)优先执行,而普通任务(如后台计算)在空闲时运行。
1.1 查看优先级
在linux系统中我们可以通过两个关键属性PRI与NI来查看相应进程的优先级:

如果我们想要查看某一特定进程的优先级可以使用以下命令:
bash
ps -al | head -1 ; ps -al | grep 进程对应的可执行文件 | grep -v grep
- PRI:代表这个进程可被执行的优先级,其值越小越早被执行
- NI:代表这个进程的nice值
这里的PRI就是进程的有限级其值越小表示进程的优先级越大CPU越早执行,这里的NI也叫做nice值表示的是进程优先级PRI的"修正数据",当我们要对相应进程的优先级进行调整的时候首先改变的是nice值。
1.2 调整优先级
在Linux系统中想更改一个进程的优先级通常有许多种方式,这里我们介绍一种比较简单的方式:利用top命令来更改特定进程的优先级,通常分为以下步骤:
- 执行top命令
- 输入r(rnice),并输入对应进程的pid
- 输入更改后的nice值,点击回车修改完成
我们执行以上步骤修改一个进程的nice值为10后再通过命令行查看这一进程的详细属性会看到这样的情况:
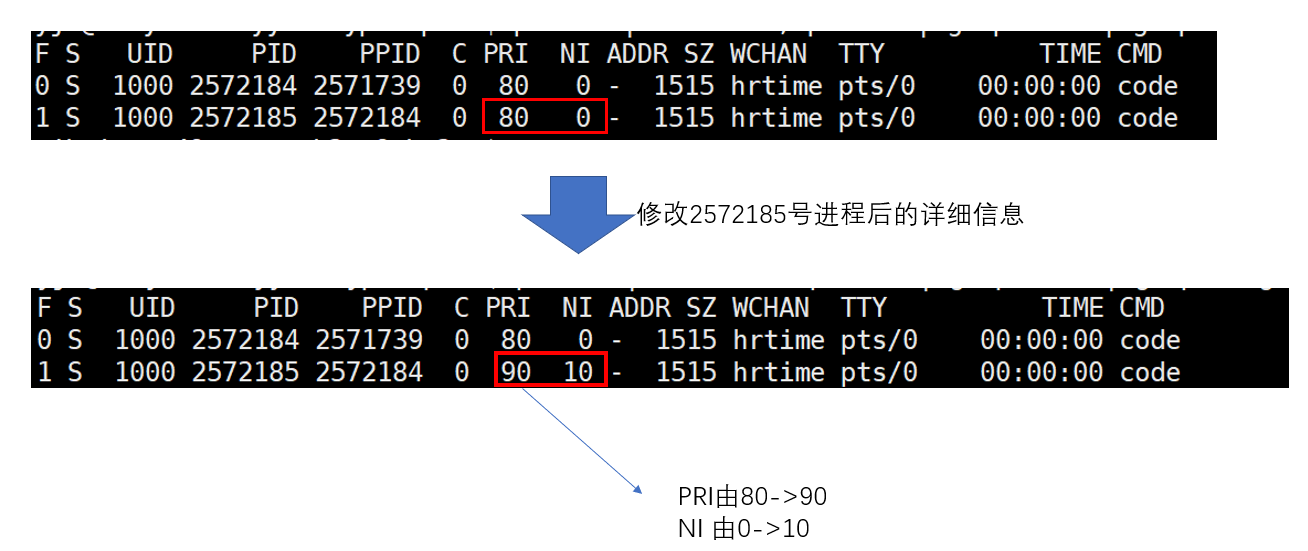
这是一个现象,接下来我们试着再将2572185号进程的nice值更改为-10看看优先级会发生怎么样的变化:

这说明进程的PRI的计算结果并不是已上一次调整后的旧的PRI为基准,而是已默认值80来进行调整,事实上进程PRI的计算依据下面的一套公式:
PRI(新)=PRI(标准值80)+NI
需要注意的是,进程的NI是有明确的上下限的一般为-20到19一共40个级别对应到PRI就是60到99。**至于为什么是40个级别?以及为什么调整进程优先级不会第一时间更改PRI而是调整nice值?**这个问题我们通过后续进程调度章节会一一讲解:
二、进程切换
在了解进程切换之前我们需要理解下面几个概念:竞争、独立、并行、并发
- 竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为 了高效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
所以进程的切换问题也可以理解为进程的并发问题,下面我们来详细理解一下进程切换的过程:
之前我们知道进程主要分为两大部分:**进程PCB+上下文数据,**前者主要存储进程的元数据也就是进程的属性,后者主要存储进程要执行的代码以及需要处理的数据。除了这一点我们也需要理解计算机系统中CPU的组成部分:
| 组件 | 主要功能 | 关键说明 |
|---|---|---|
| 运算器 | 执行算术运算(加、减、乘、除) 执行逻辑运算(与、或、非、异或) 执行移位和比较操作 | 核心是算术逻辑单元(ALU) 现代CPU包含专用浮点单元(FPU) 直接处理寄存器或内存中的数据 |
| 控制器 | 从内存取指令 译码指令 产生控制信号 协调各部件工作 | CPU的"指挥中心" 包含程序计数器(PC)、指令寄存器(IR) 控制指令执行流程和时序 |
| 寄存器组 | 临时存储指令、数据和地址 提供高速数据访问 存储CPU状态信息 | 速度极快(L1缓存级别) 包括通用寄存器和专用寄存器 数量有限但访问最快 |
| 内部总线 | 传输数据(数据总线) 传输地址(地址总线) 传输控制信号(控制总线) | CPU内部各部件通信通道 连接所有内部组件 |
| 缓存 | 存储频繁使用的数据和指令 减少CPU访问内存的等待时间 平衡CPU与内存速度差异 | 分L1、L2、L3多级结构 L1最快最小,L3最慢最大 基于局部性原理工作 |
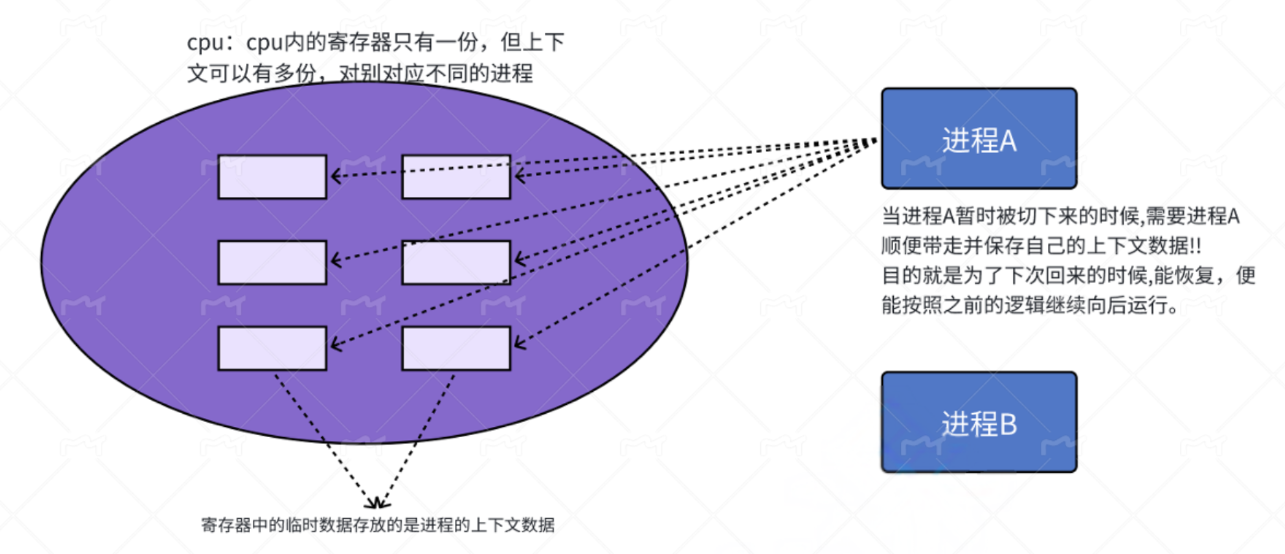
当进程被CPU进行执行时这时进程的上下文数据就会加载到CPU的各个寄存器中进行运算和处理,但是CPU不是将一个进程处理完全才切换另一个进程而是每个进程都会有自己的时间片这个时间片决定了该进程能被CPU处理多长时间,时间片耗尽无论进程上下文是否被处理完全CPU都会进行进程切换。这样做的目的是实现公平调度,防止单个进程垄断CPU,导致后续进程发生饥饿现象。
那么此时进行进程切换时,由于进程可能并未执行完全此时CPU的寄存器组中保存的是该进程执行过程中的临时数据。这些临时数据十分重要,它包含了进程代码运行的位置以及处理时产生的临时数据,这些数据如果不进行保护那么当下一次进程再次被切换到CPU上执行时CPU就无法拿到上次代码运行的位置以及上次处理的结果,就会导致CPU又从头开始执行浪费系统资源。所以进程切换的第一步就是先保护即将被切换走的进程的临时数据也就是当前各个寄存器组中的数据。这些数据会被保存到进程PCB之中由其中的tss结构体来保存:

然后新进程的上下文数据会被填充到CPU的寄存器组中覆盖前一个进程的历史数据,此时CPU便完成了一次进程切换。
三、进程调度
在之前的进程状态一节我们大致地理解了一下运行状态与运行队列,但是在实际的Linux系统中运行队列并不是单纯地我们传统意义上的队列结构比如链表或数组,而是一个非常复杂的数据结构。
| 对比维度 | **传统队列(FIFO)** | 实际运行队列 | 原因 |
|---|---|---|---|
| 数据结构 | 单向链表/数组 | 多个优先级数组+红黑树+位图 | 需要快速查找最高优先级进程 |
| 调度策略 | 先进先出 | 多策略组合(完全公平、实时、限期) | 不同进程类型需求不同 |
| 时间复杂度 | 入队O(1),出队O(1) | 入队O(log n),出队O(1) | 优先队列需要排序 |
| 公平性 | 绝对顺序公平 | 时间片加权公平 | 防止I/O型进程饥饿 |
在Linux系统中一个CPU只有一个运行队列在内核中叫做runqueue,这个runqueue的总体结构我们可以画图表示如下:
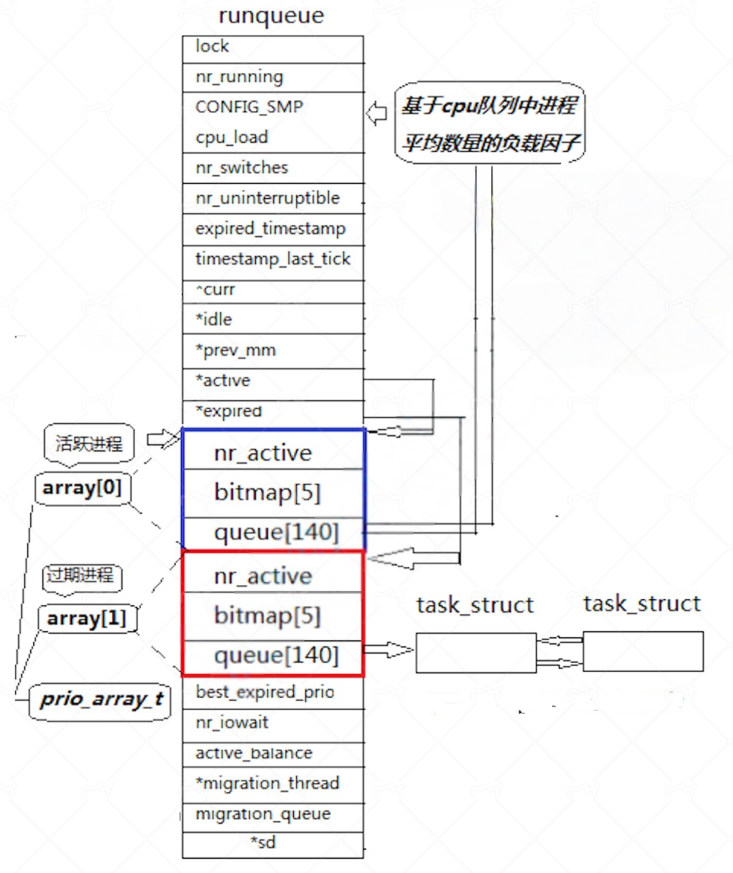
在这个数据结构中nr_active,bitmap5,queue140三个成员组成了一个复合数据结构struct prio_array,其中queue140是一个指针数组,其中的140也就是下标0,139表示140个优先级。每一个成员都是元素为task_struct*的双向链表。
cpp
// O(1)调度器中的优先级数组
struct prio_array {
unsigned int nr_active; // 活动进程数
struct list_head queue[MAX_PRIO]; // 140个链表头
unsigned int bitmap[BITMAP_SIZE]; // 位图
};需要注意的是这140个优先级中前100个优先级叫做实时优先级,我们不做考虑。后40个才是用户可以动态调整的优先级,所以前面对应的NI的范围为-20到19对应40个PRI优先级。
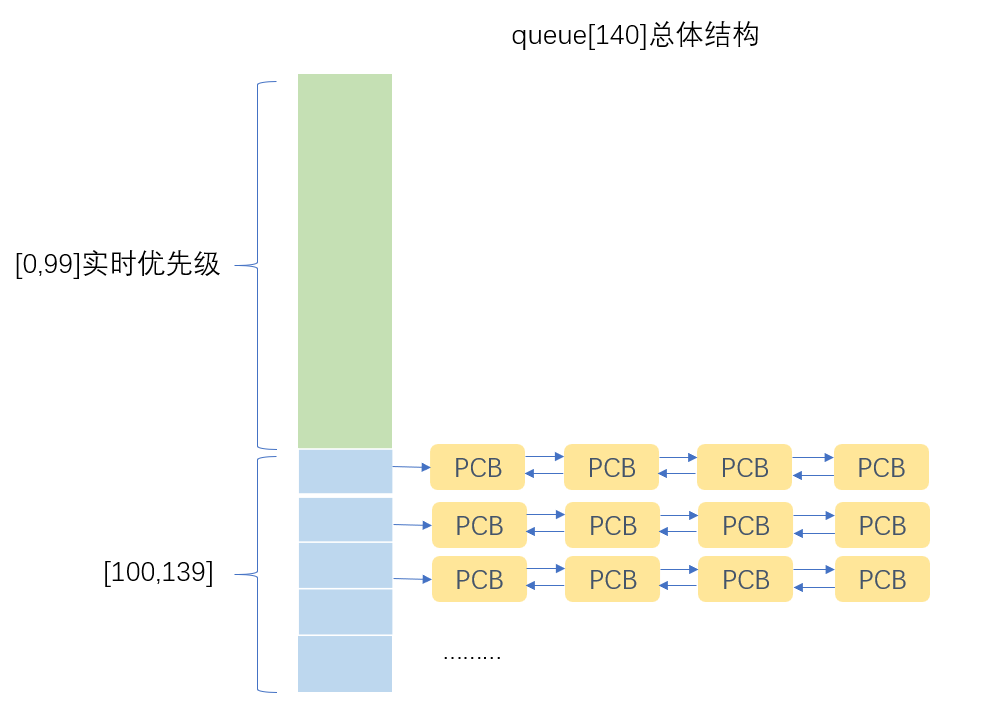
当进程调度的时候,调度器会安优先级从高到低扫描整个queue结构并从中找到第一个链表不为空的PCB队列然后Pop出一个PCB交给CPU执行。
但是这里就有了一个问题,每次进行进程调度的时候调度器都会从头到尾扫描整个queue结构。为了提高调度效率在prio_array中还同时有一个位图结构bitmap,它一共拥有160个比特位,分别表示queue140中每个优先级对应的PCB队列是否为空,如果为空就置为0不为空就置为1。除此之外nr_active则记录了整个queue结构中总的PCB的数量。
因此,当进行进程调度的时候调度器会首先按照优先级从高到低扫描bitmap然后确定第一个链表不为空的PCB队列的下标,然后在queue中对应的下标位置从链表中Pop出一个PCB交给CPU执行完成进程调度操作。
进程调度完成后,调度器会根据进程优先级将其PCB插入queue双向链表的对应位置。但这里存在一个问题:若该进程本身优先级较高,重新插入queue后仍会排在靠前位置。由于调度器始终按优先级从高到低进行调度,高优先级进程执行完毕才会轮到低优先级进程。这样会导致高优先级进程在完成执行前始终存在于队列中,持续占用CPU资源,而低优先级进程则长期得不到调度机会,从而产生进程饥饿现象。
为了解决这个问题,实际上Linux内核中会同时存在两个struct prio_array结构,他们的组成结构一致但是会被区分为"活跃队列"与"过期队列"。前者表示调度器正在该prio_array的queue中执行进程调度操作后者则代表调度器不会直接从该队列选择进程,当一个进程被调度结束调度器会按照优先级将该进程链入到过期队列中的queue结构的相应位置处。
前面我们提到过为什么我们在更改进程优先级的时候不会直接修改PRI而是存在一个nice值也是这个原因,如果没有nice值直接修改进程PRI可能会导致进程如果没有nice值直接修改进程PRI可能会导致进程优先级的计算失去"平滑调整"的能力,进而破坏调度器的公平性与稳定性。具体来说,直接修改PRI会绕过nice值所承载的"静态优先级+动态补偿"机制,使得低优先级进程在调度时被过度压制,而高优先级进程即使执行时间极长也无法被"降级"以让出CPU资源,最终导致调度器在长时间运行后出现严重的"优先级倾斜"------所有进程最终可能都堆积在最高优先级队列中,使调度退化成"先来先服务"甚至"随机调度",完全丧失基于优先级的调度意义。此外,由于PRI在Linux内核中是动态变化的,直接修改PRI会导致调度器内部的优先级映射关系混乱,比如在prio_array的bitmap标记、nr_active计数以及队列插入位置等环节出现逻辑错误,进而引发进程饥饿或CPU资源分配极度不均等严重问题。因此,通过nice值间接调整PRI,既能保留用户对进程优先级的"软干预"能力,又能确保内核调度器在动态维护优先级时保持结构清晰、逻辑一致,从而实现高效、公平的多任务调度
但是前面讲的"活跃队列"与"过期队列"并不是一成不变的,当"活跃队列"中的所有进程被调度完全后此时就代表所有调度完的进程都进入了"过期队列"。此时"过期队列"就会变为"活跃队列"开始被调度器进行二次调度,调度完成的进程就会被链入到先前的"活跃队列"(此时变为了过期队列)。这个操作主要是由两个指针来完成的就是前面runqueue结构中的active与expired指针。他们两个的类型都是struct prio_array*,前者指向活跃队列后者指向过期队列。调度器进来时默认会在active指向的活跃队列进行调度操作,当所有进程调度完全只需要将两指针的内容进行交换即可。