基于 Docker 部署 Hadoop 伪分布式(单机)镜像 + 持久化挂载 + 完整测试

一、最终目标
- 构建一个 Hadoop 3.3.0 伪分布式 Docker 镜像
- 配置 命名卷持久化(数据不丢)
- 配置 宿主机配置挂载(方便你后期改配置)
- 自带 SSH 免密、JDK、Hadoop 环境
- 可直接扩展 ZK / Hive / Sqoop / Flume
二、文件结构(直接照建)
创建目录
bash
mkdir ~/hadoop-pseudo/
bash
cd ~/hadoop-pseudo/
touch Dockerfile
touch entrypoint.sh把hadoop-3.3.0.tar.gz 放到~/hadoop-pseudo/
bash
cp ~/hadoop-docker/hadoop-3.3.0.tar.gz ~/hadoop-pseudo/目录结构如下
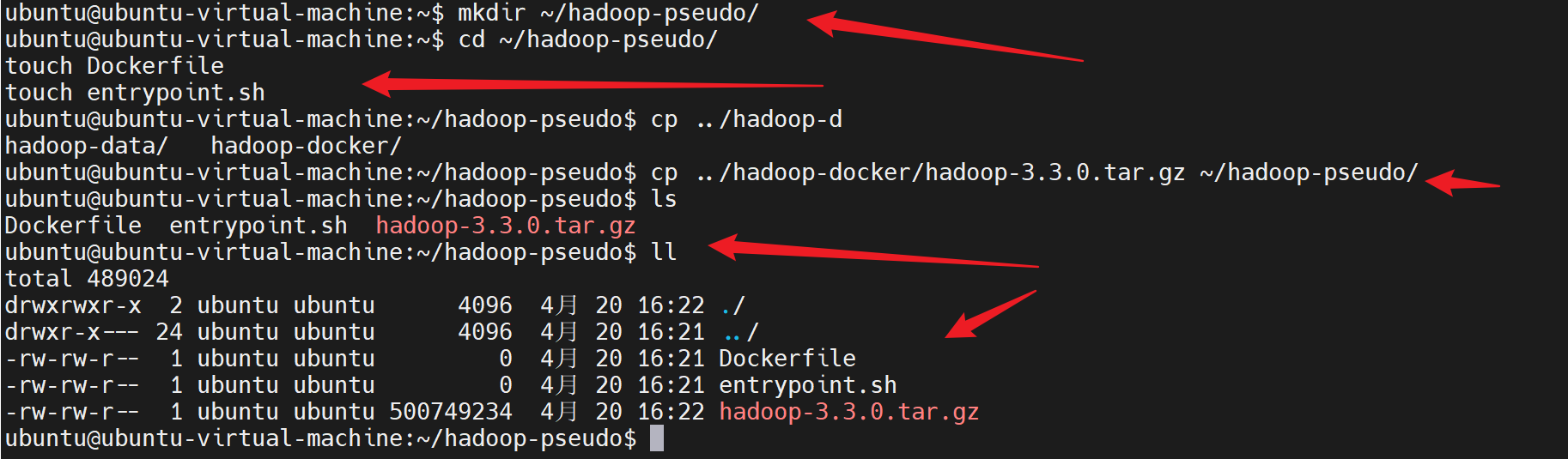
~/hadoop-pseudo/
├── Dockerfile
├── entrypoint.sh
└── hadoop-3.3.0.tar.gz(你自己放进来)三、Dockerfile(最终版,可直接构建)
编译Dockerfile
bash
sudo nano Dockerfile内容如下:
dockerfile
FROM ubuntu:22.04
ENV DEBIAN_FRONTEND=noninteractive
# 安装依赖
RUN apt update && apt install -y \
openssh-server openssh-client \
openjdk-8-jdk \
vim net-tools iputils-ping \
&& apt clean
# SSH 配置(免密必备)
RUN mkdir -p /var/run/sshd && \
echo "root:root" | chpasswd && \
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config && \
sed -i 's/PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
# SSH 免密
RUN ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
# 安装 Hadoop
ENV HADOOP_VERSION=3.3.0
COPY hadoop-$HADOOP_VERSION.tar.gz /tmp/
RUN tar -xzf /tmp/hadoop-$HADOOP_VERSION.tar.gz -C /usr/local/ && \
mv /usr/local/hadoop-$HADOOP_VERSION /usr/local/hadoop && \
rm /tmp/hadoop-$HADOOP_VERSION.tar.gz
# 环境变量
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 数据目录(用于挂载)
RUN mkdir -p /hadoop-data/namenode \
/hadoop-data/datanode \
/hadoop-data/tmp
# 入口脚本
COPY entrypoint.sh /
RUN chmod +x /entrypoint.sh
EXPOSE 22 9000 50070 8088 19888
CMD ["/entrypoint.sh"]四、entrypoint.sh(启动容器自动跑 SSH + 不退出)
bash
sudo nano entrypoint.sh
bash
#!/bin/bash
service ssh start
tail -f /dev/null五、构建镜像(直接运行)
bash
cd ~/hadoop-pseudo
docker build -t hadoop-pseudo:3.3.0 .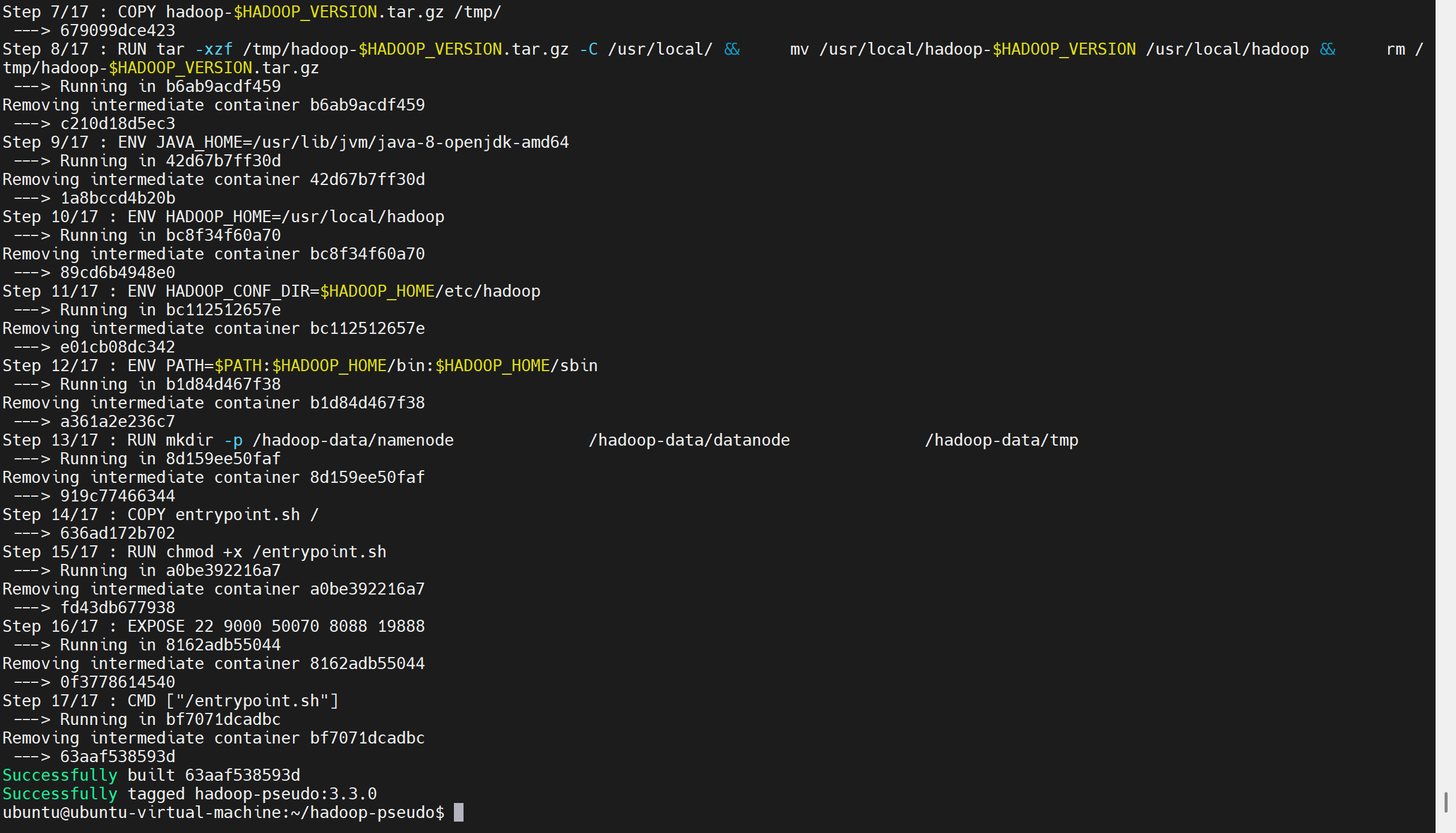
六、挂载卷(带持久化挂载 ✅ 关键)
挂载说明(完全按你博客逻辑)
- 命名卷:存 HDFS 数据(容器删了不丢)
- 宿主机挂载:存配置文件(你直接在宿主机改)
先查看当前docker的挂载卷有哪些
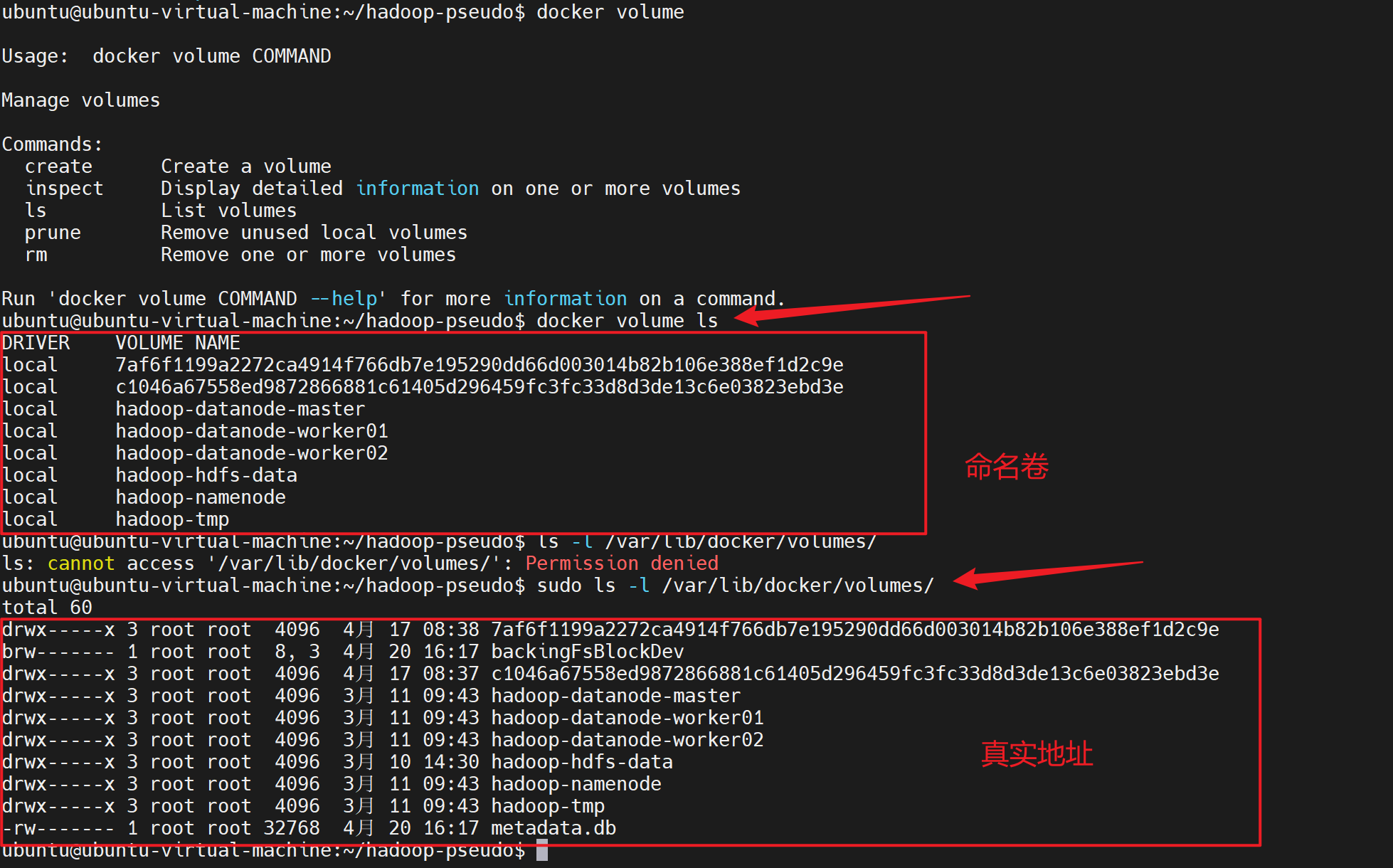
也可以通过命令查看命名卷的挂载地址
bash
docker volume inspect hadoop-namenode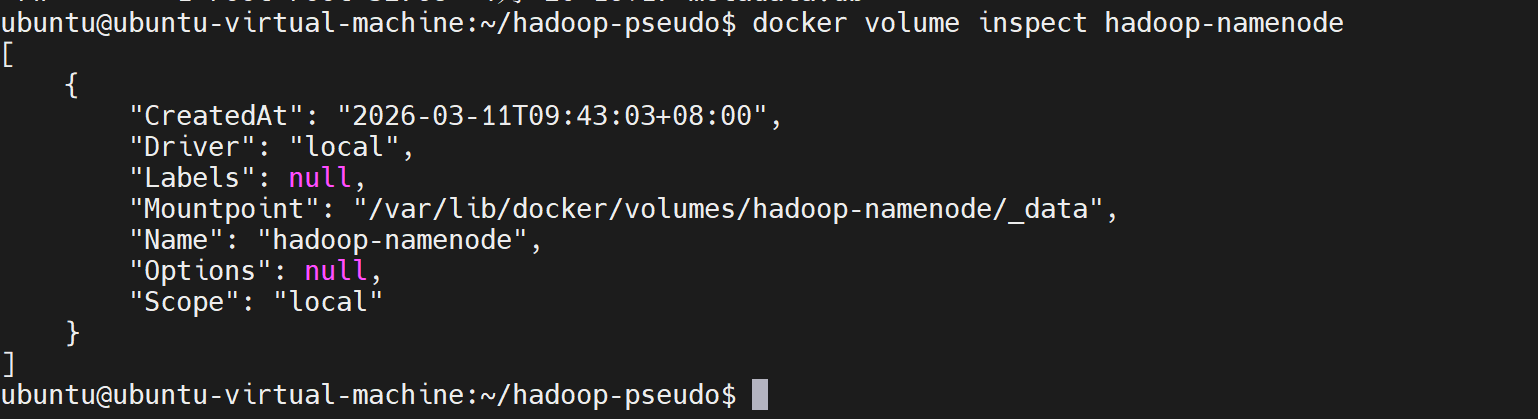
创建命名卷pseudo-hadoop-namenode,pseudo是伪分布的伪
bash
# 1. 创建宿主机配置目录(以后改 xml 直接在这里改)
mkdir -p ~/hadoop-conf
# 2. 创建命名卷(数据持久化)
docker volume create pseudo-hadoop-namenode
docker volume create pseudo-hadoop-datanode
docker volume create pseudo-hadoop-tmp
docker volume ls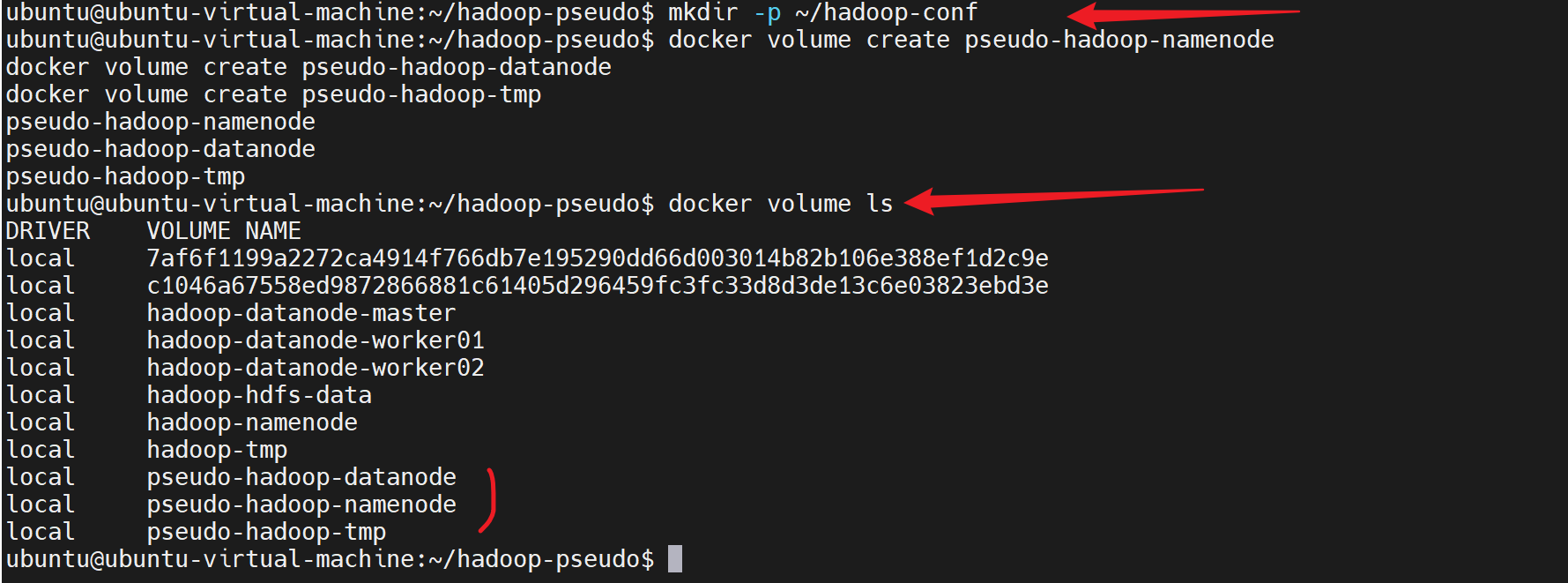
七、网络配置
查看所有网络
bash
ubuntu@ubuntu-virtual-machine:~/hadoop-pseudo$ docker network ls
NETWORK ID NAME DRIVER SCOPE
2ef9b450c96a bridge bridge local
766cf0c6e53c hadoop-net bridge local
2917ca404b43 hadoop-network bridge local
63a7cb1bc2c7 host host local
4857814735ec none null local查看特定网络
bash
docker network inspect hadoop-net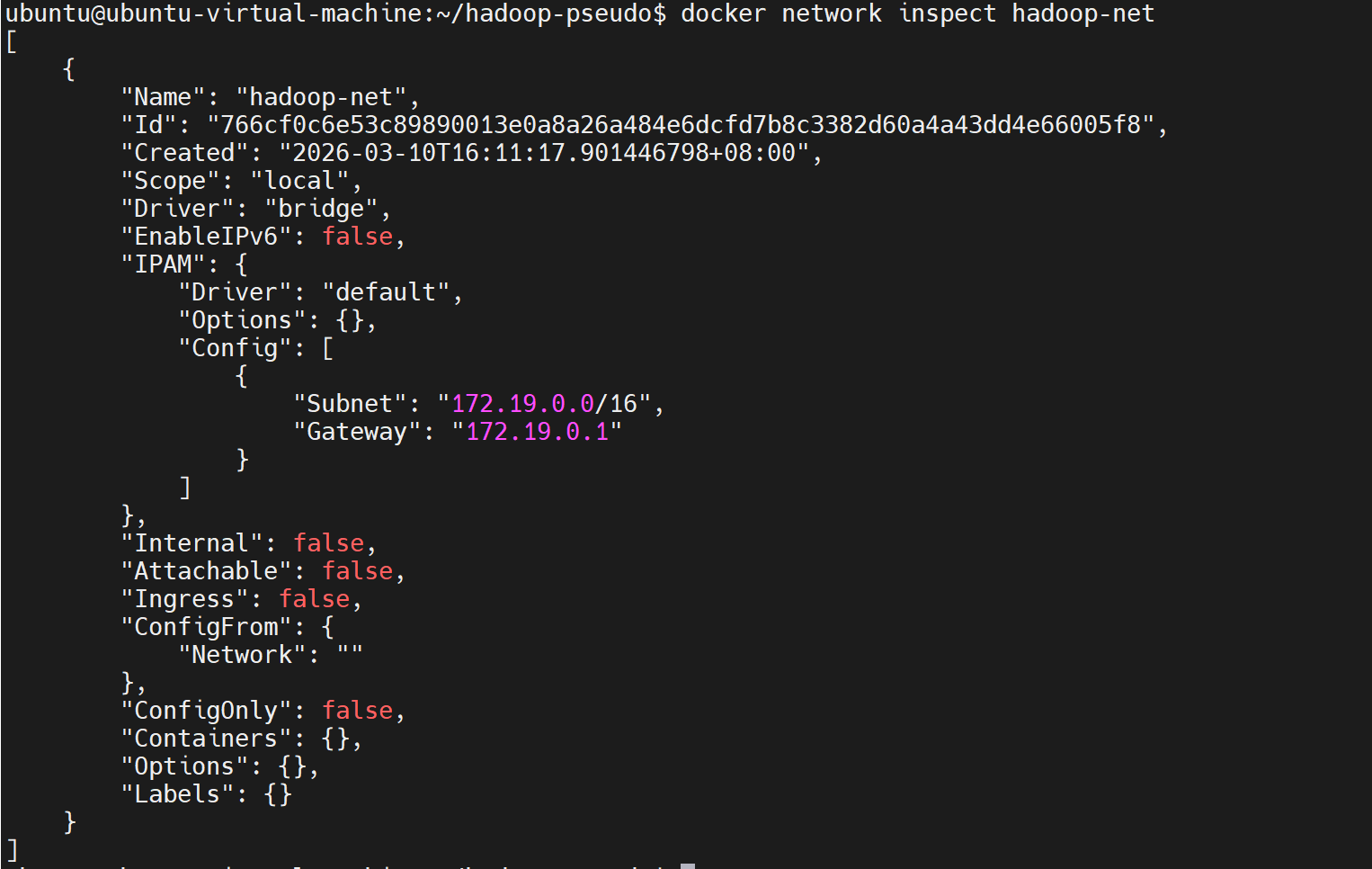
查看所有网络的详细配置
bash
docker network inspect $(docker network ls -q)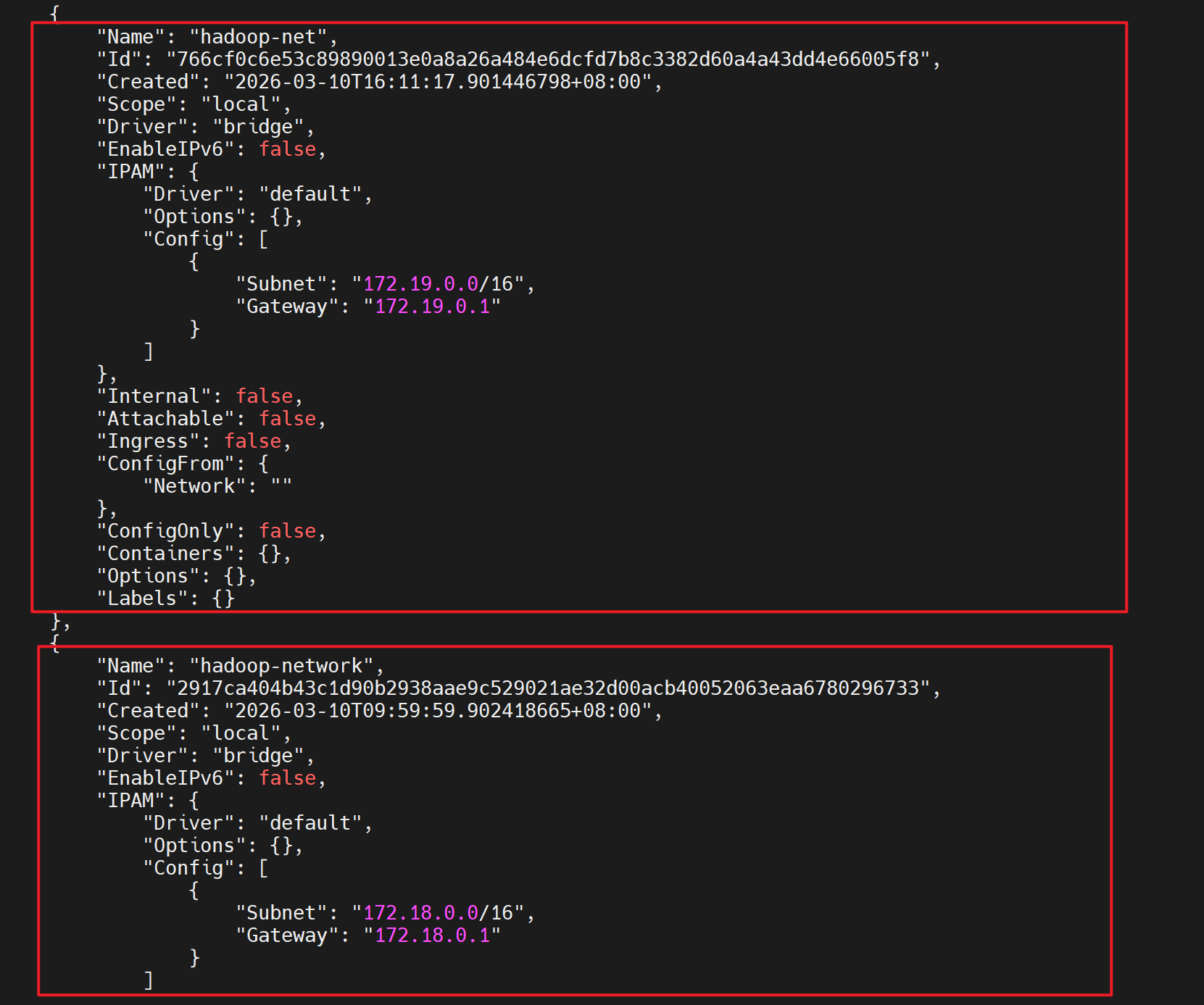
查看当前容器的网络信息
bash
docker ps --format "table {{.Names}}\t{{.Networks}}"
查看当前的网络
bash
docker network ls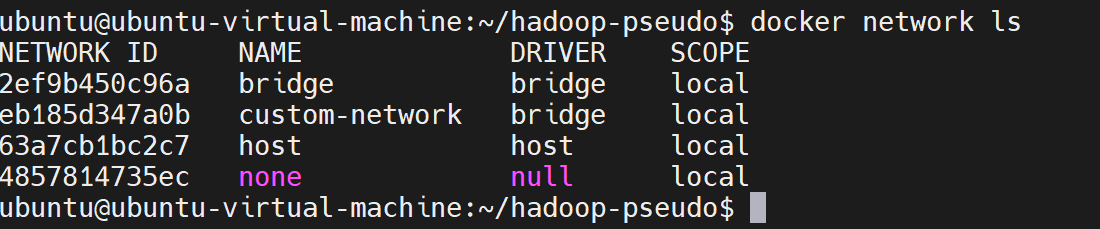
bash
docker network inspect custom-network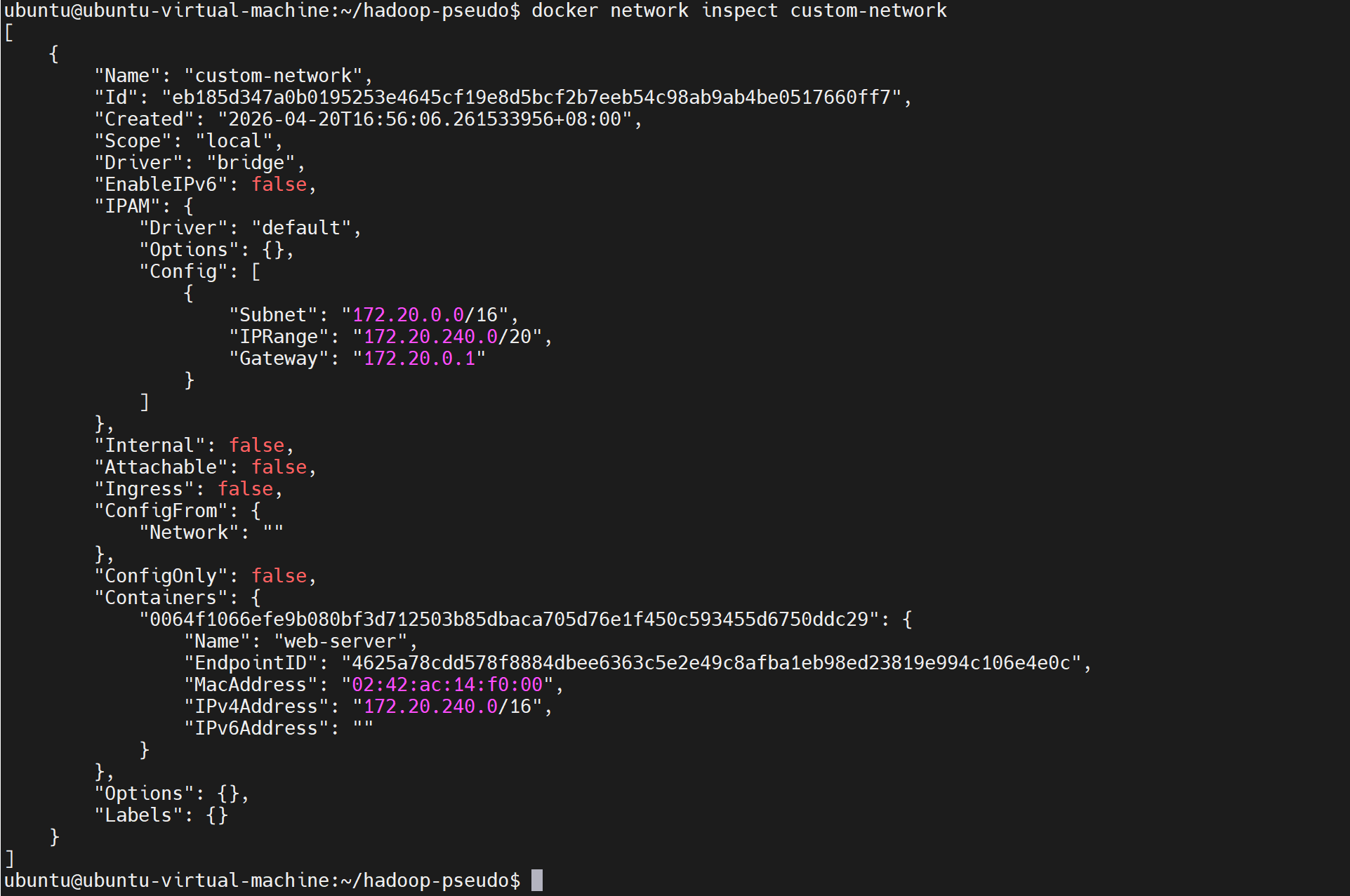
根据您提供的 docker network inspect custom-network 输出,该网络的配置为:
- Subnet :
172.20.0.0/16 - IPRange :
172.20.240.0/20 - Gateway :
172.20.0.1
这意味着:
- 可用 IP 范围:
172.20.0.2~172.20.255.254(但实际可用池受IPRange限制) - Docker 通常从
172.20.0.2开始分配,但因设置了IPRange: 172.20.240.0/20,Docker 会优先从该范围分配(即172.20.240.0~172.20.255.255)
✅ 安全起见,我们选择一个明确在
IPRange内且未被占用的地址,例如:172.20.240.10
不指定网络和ip的命令
bash
# 3. 启动伪分布式容器
docker run -d \
--name hadoop-pseudo \
--hostname hadoop-pseudo \
-p 50070:50070 \
-p 8088:8088 \
-p 9000:9000 \
-v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop \
-v pseudo-hadoop-namenode:/hadoop-data/namenode \
-v pseudo-hadoop-datanode:/hadoop-data/datanode \
-v pseudo-hadoop-tmp:/hadoop-data/tmp \
--privileged \
hadoop-pseudo:3.3.0✅ 修改后的启动命令(指定网络 + 固定 IP)
bash
docker run -d \
--name hadoop-pseudo \
--hostname hadoop-pseudo \
--network custom-network \
--ip 172.20.240.10 \
-p 50070:50070 \
-p 8088:8088 \
-p 9000:9000 \
-v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop \
-v pseudo-hadoop-namenode:/hadoop-data/namenode \
-v pseudo-hadoop-datanode:/hadoop-data/datanode \
-v pseudo-hadoop-tmp:/hadoop-data/tmp \
--privileged \
hadoop-pseudo:3.3.0
🔍 验证是否成功
启动后执行:
bash
# 检查容器的 IP 地址
docker inspect hadoop-pseudo --format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'
# 或者更具体地检查 custom-network 的 IP
docker inspect hadoop-pseudo | grep -A 10 "custom-network"
# 应输出:172.20.240.10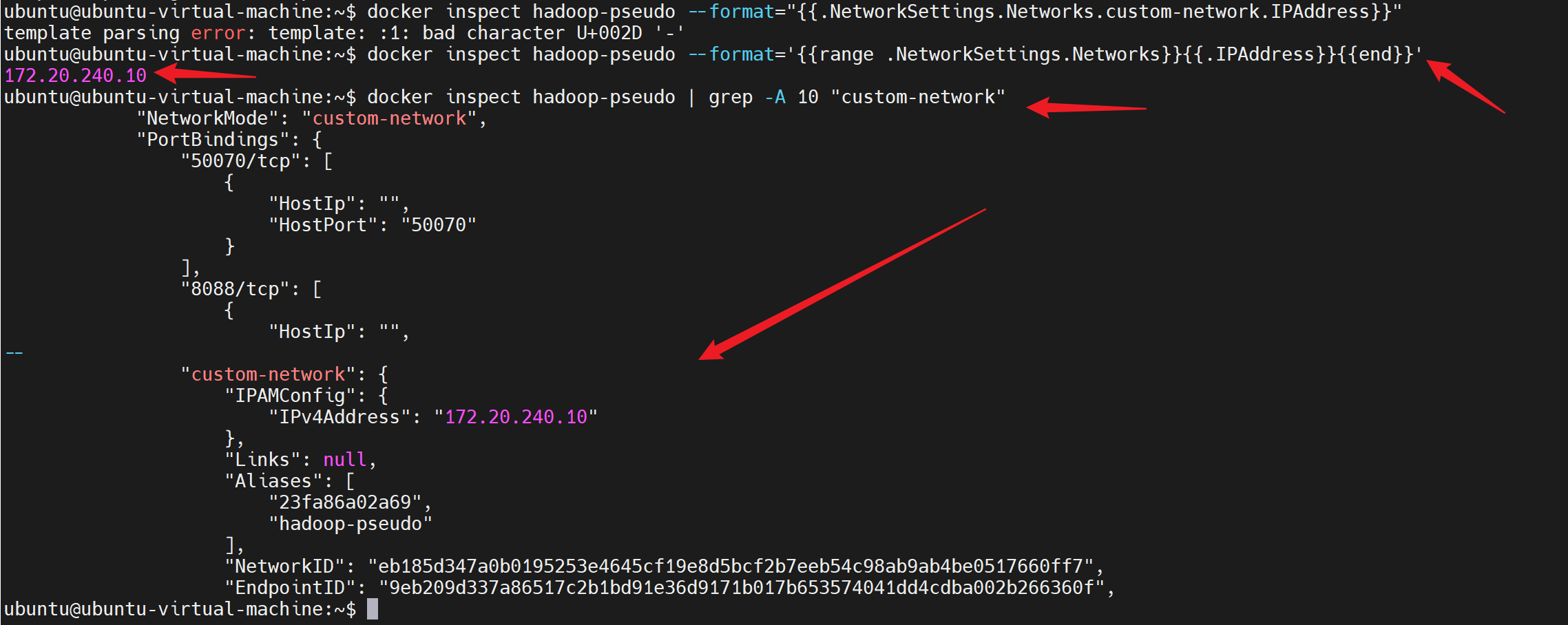
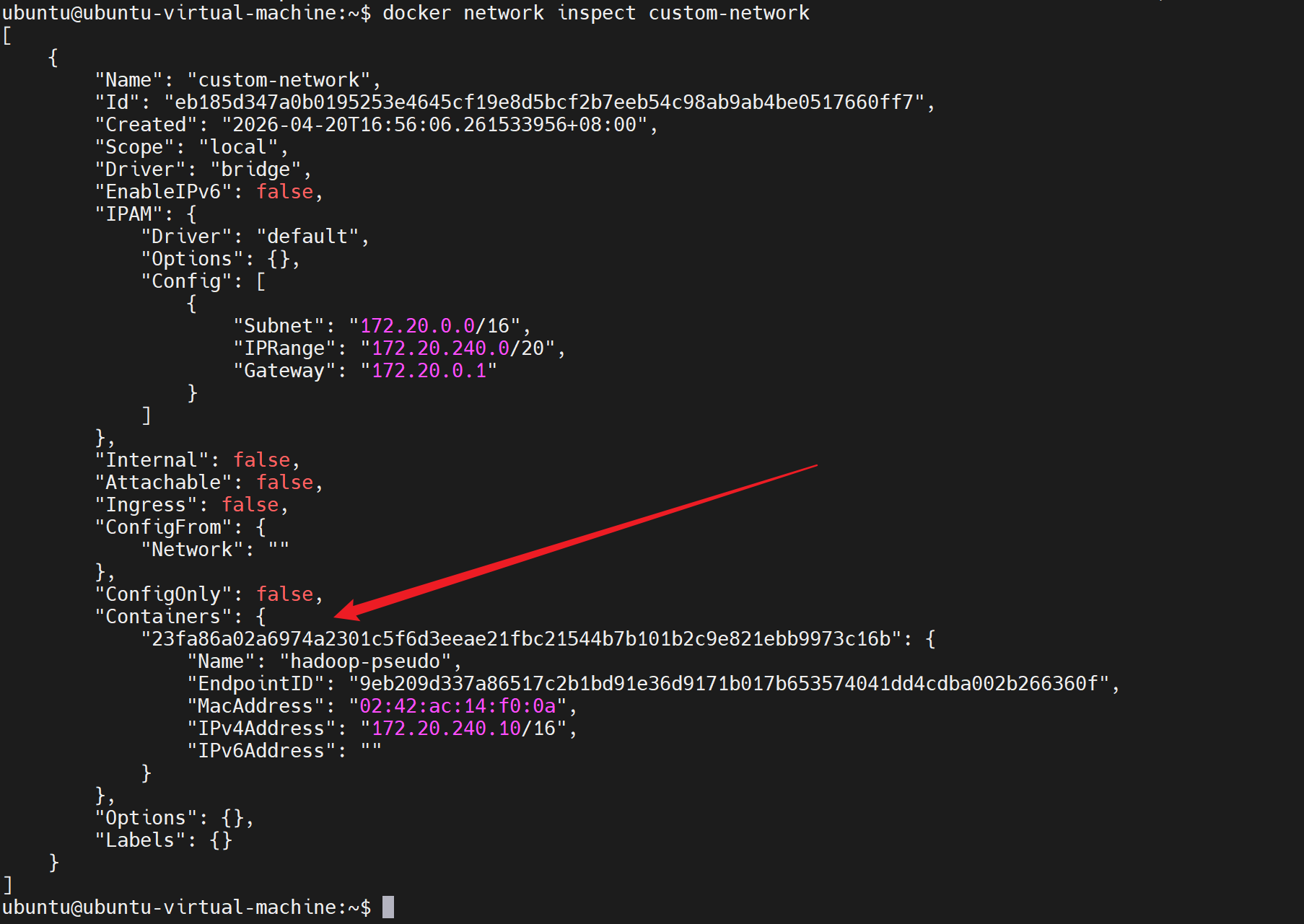
或查看完整网络信息:
bash
docker network inspect custom-network确认 "Containers" 中 hadoop-pseudo 的 IP 为 172.20.240.10。
⚠️ 注意事项
- IP 必须在
IPRange范围内 (172.20.240.0/20=172.20.240.0~172.20.255.255),否则启动失败。 - 如果该 IP 已被其他容器占用,Docker 会报错:
IP address X.X.X.X is already allocated。- 可改用
172.20.240.11、172.20.240.12等。
- 可改用
- 若想避免手动选 IP,也可只加
--network custom-network,让 Docker 自动分配(但仍会在IPRange内)。
八、进入容器
bash
docker exec -it hadoop-pseudo bash九、伪分布式核心配置(直接复制覆盖)
bash
# 查看docker容器内的$HADOOP_CONF_DIR
root@hadoop-pseudo:/# echo $HADOOP_CONF_DIR
/usr/local/hadoop/etc/hadoop
root@hadoop-pseudo:/# ls $HADOOP_CONF_DIR
root@hadoop-pseudo:/#
# hadoop的配置文件,会放在这个路径下,然后实际存储在linux的~/hadoop-conf目录下1)core-site.xml
bash
cat > $HADOOP_CONF_DIR/core-site.xml << 'EOF'
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-pseudo:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop-data/tmp</value>
</property>
</configuration>
EOF
2)hdfs-site.xml
bash
cat > $HADOOP_CONF_DIR/hdfs-site.xml << 'EOF'
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop-data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop-data/datanode</value>
</property>
</configuration>
EOF3)mapred-site.xml
bash
#cat > $HADOOP_CONF_DIR/mapred-site.xml << 'EOF'
cat << EOF > $HADOOP_CONF_DIR/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/yarn/lib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*</value>
</property>
<!-- 添加 MapReduce 环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
EOF4)yarn-site.xml
bash
cat > $HADOOP_CONF_DIR/yarn-site.xml << 'EOF'
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
EOF5)workers
bash
echo "hadoop-pseudo" > $HADOOP_CONF_DIR/workers
同时切换到linux的~/hadoop-conf目录,会发现配置文件保存在宿主机上

6)hadoop-env.sh
bash
cat > $HADOOP_CONF_DIR/hadoop-env.sh << 'EOF'
# 设置 Java 环境
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Hadoop 安装目录(通常已经设置,但保险起见显式设置)
export HADOOP_HOME=/usr/local/hadoop
# Hadoop 配置目录
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
# HDFS 用户配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
# YARN 用户配置
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# MapReduce 用户配置
export MAPRED_MAPTASK_USER=root
export MAPRED_REDUCETASK_USER=root
EOF
十、查看挂载数据
bash
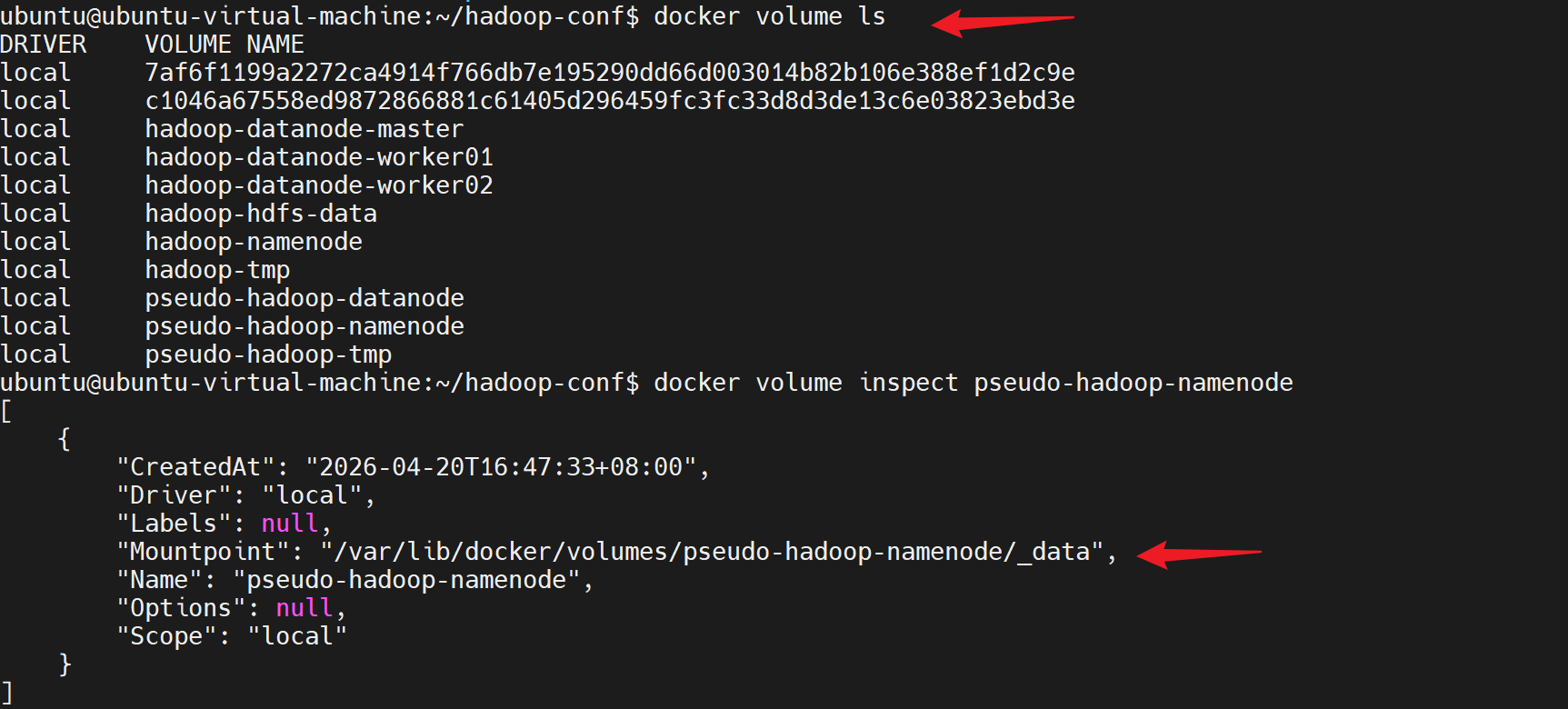
ubuntu@ubuntu-virtual-machine:~/hadoop-conf$ docker volume ls
DRIVER VOLUME NAME
local 7af6f1199a2272ca4914f766db7e195290dd66d003014b82b106e388ef1d2c9e
local c1046a67558ed9872866881c61405d296459fc3fc33d8d3de13c6e03823ebd3e
local hadoop-datanode-master
local hadoop-datanode-worker01
local hadoop-datanode-worker02
local hadoop-hdfs-data
local hadoop-namenode
local hadoop-tmp
local pseudo-hadoop-datanode
local pseudo-hadoop-namenode
local pseudo-hadoop-tmp
ubuntu@ubuntu-virtual-machine:~/hadoop-conf$ docker volume inspect pseudo-hadoop-namenode
[
{
"CreatedAt": "2026-04-20T16:47:33+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/pseudo-hadoop-namenode/_data",
"Name": "pseudo-hadoop-namenode",
"Options": null,
"Scope": "local"
}
]
查看/var/lib/docker/volumes/下的数据
bash
ubuntu@ubuntu-virtual-machine:~/hadoop-conf$ sudo ls -l /var/lib/docker/volumes/
total 76
drwx-----x 3 root root 4096 4月 17 08:38 7af6f1199a2272ca4914f766db7e195290dd66d003014b82b106e388ef1d2c9e
brw------- 1 root root 8, 3 4月 21 08:40 backingFsBlockDev
drwx-----x 3 root root 4096 4月 17 08:37 c1046a67558ed9872866881c61405d296459fc3fc33d8d3de13c6e03823ebd3e
drwx-----x 3 root root 4096 3月 11 09:43 hadoop-datanode-master
drwx-----x 3 root root 4096 3月 11 09:43 hadoop-datanode-worker01
drwx-----x 3 root root 4096 3月 11 09:43 hadoop-datanode-worker02
drwx-----x 3 root root 4096 3月 10 14:30 hadoop-hdfs-data
drwx-----x 3 root root 4096 3月 11 09:43 hadoop-namenode
drwx-----x 3 root root 4096 3月 11 09:43 hadoop-tmp
-rw------- 1 root root 65536 4月 21 08:40 metadata.db
drwx-----x 3 root root 4096 4月 20 16:47 pseudo-hadoop-datanode
drwx-----x 3 root root 4096 4月 20 16:47 pseudo-hadoop-namenode
drwx-----x 3 root root 4096 4月 20 16:47 pseudo-hadoop-tmp查看pseudo-hadoop-namenode 命名卷下的数据
bash
sudo ls -l /var/lib/docker/volumes/pseudo-hadoop-namenode
sudo ls -l /var/lib/docker/volumes/pseudo-hadoop-namenode/_data
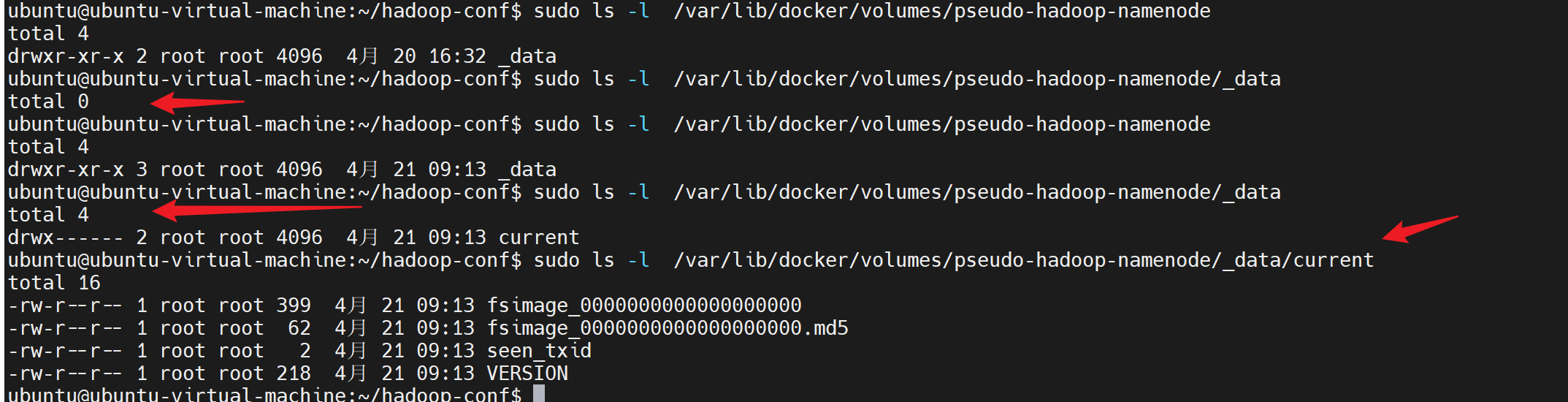
未格式化前 还没有数据
十一、格式化 + 启动 Hadoop
bash
hdfs namenode -format -force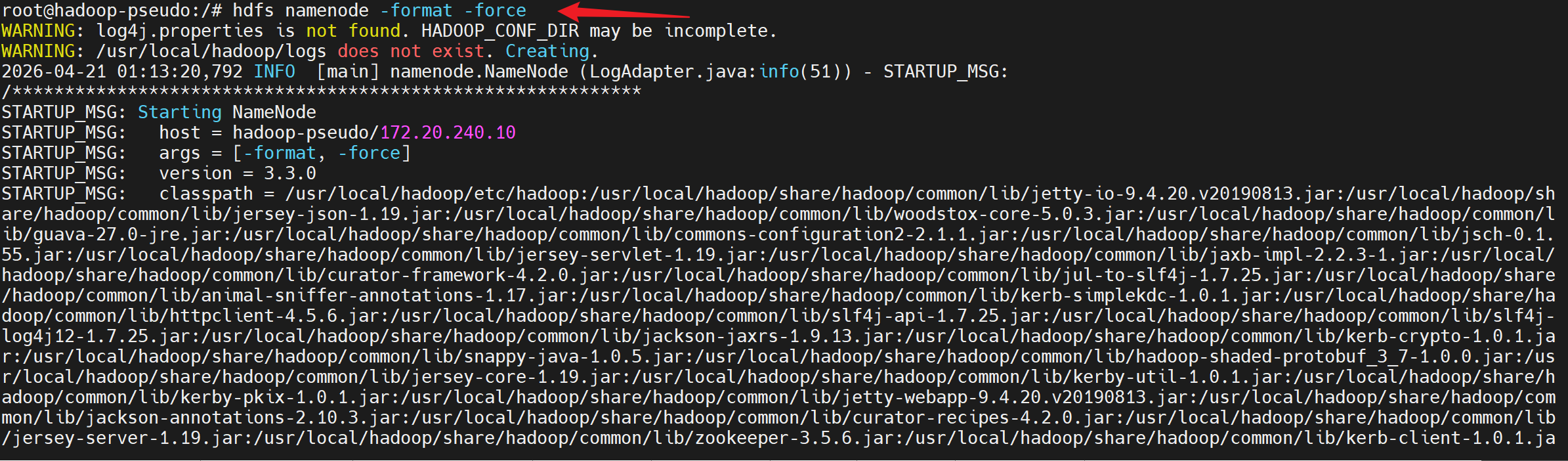
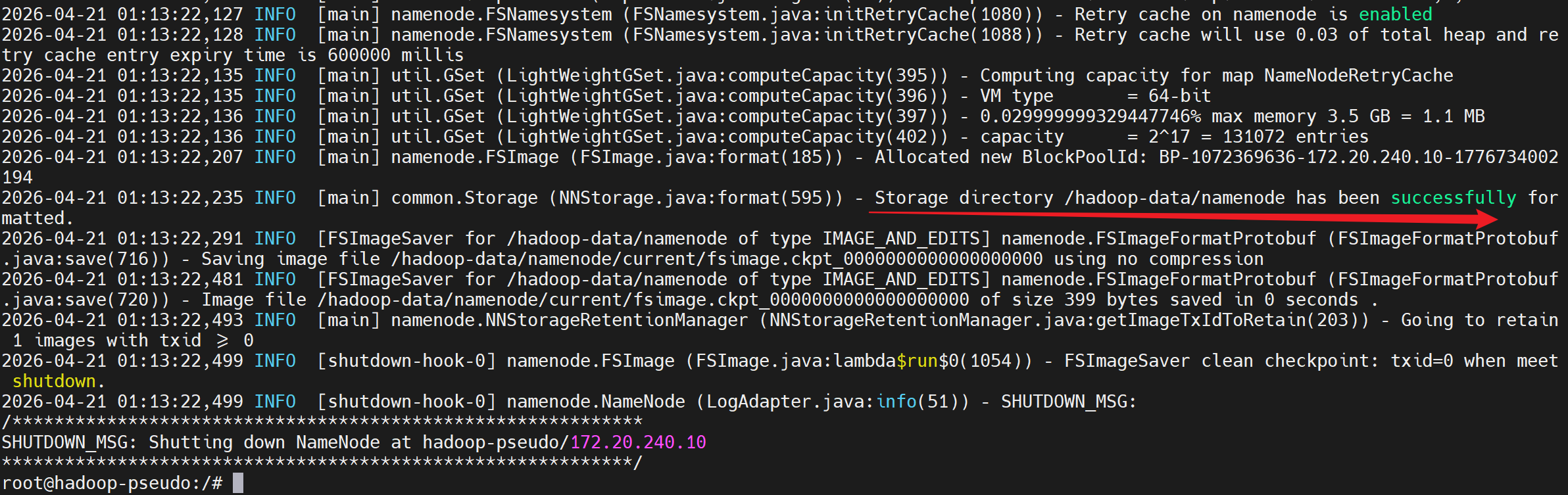
这时在linux的命名卷下,也可以看到格式化后的数据
启动hadoop
bash
start-dfs.sh
jps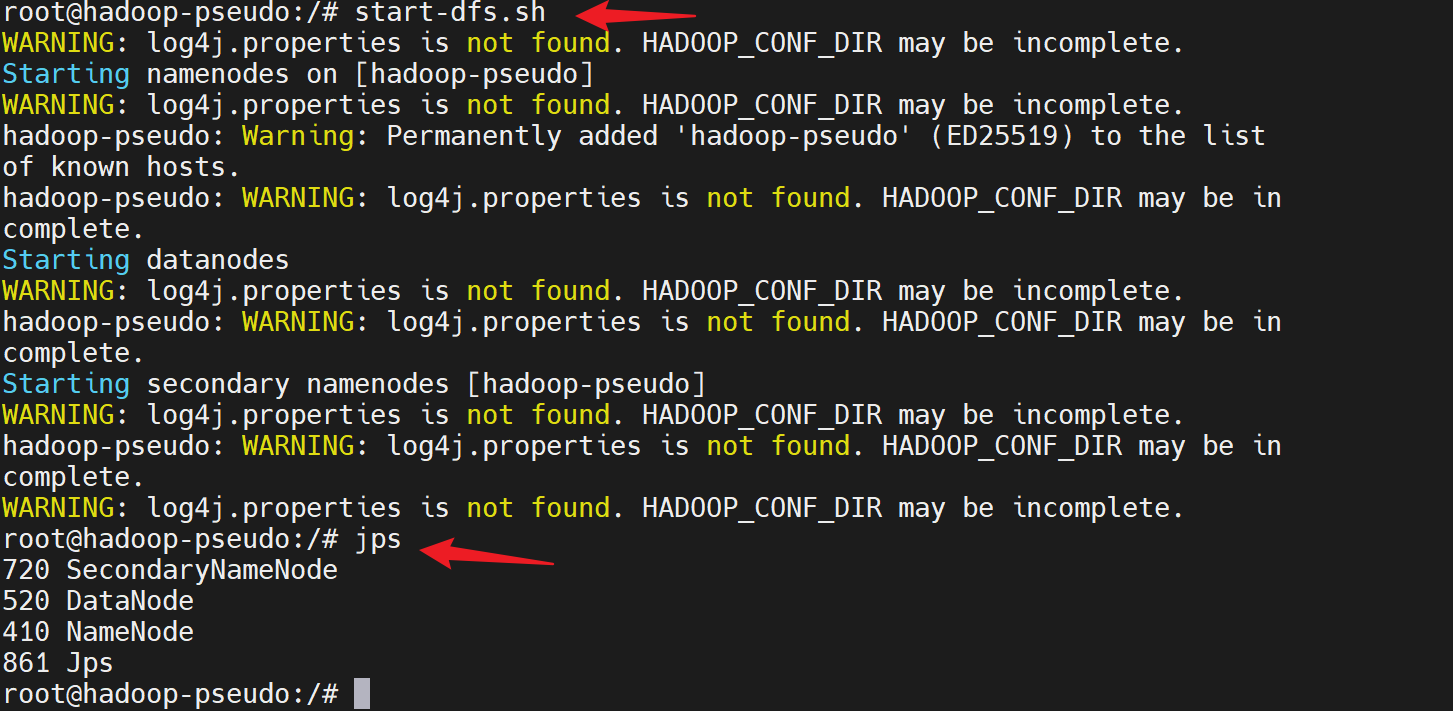
启动yarn
bash
start-yarn.sh
jps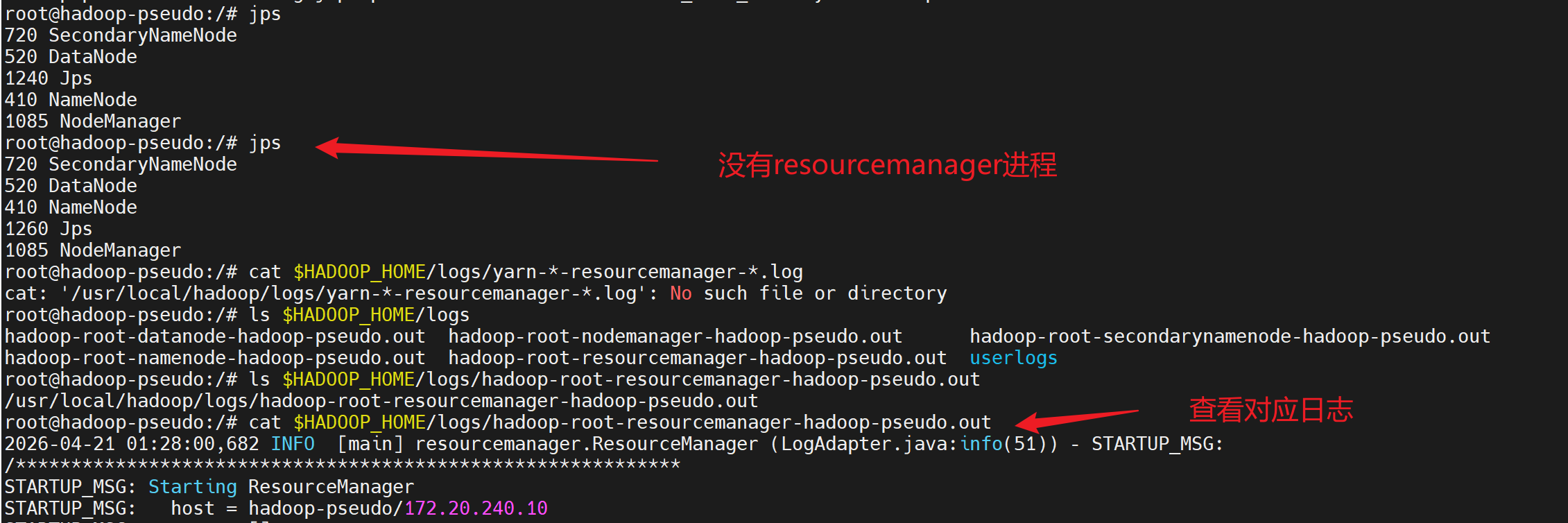
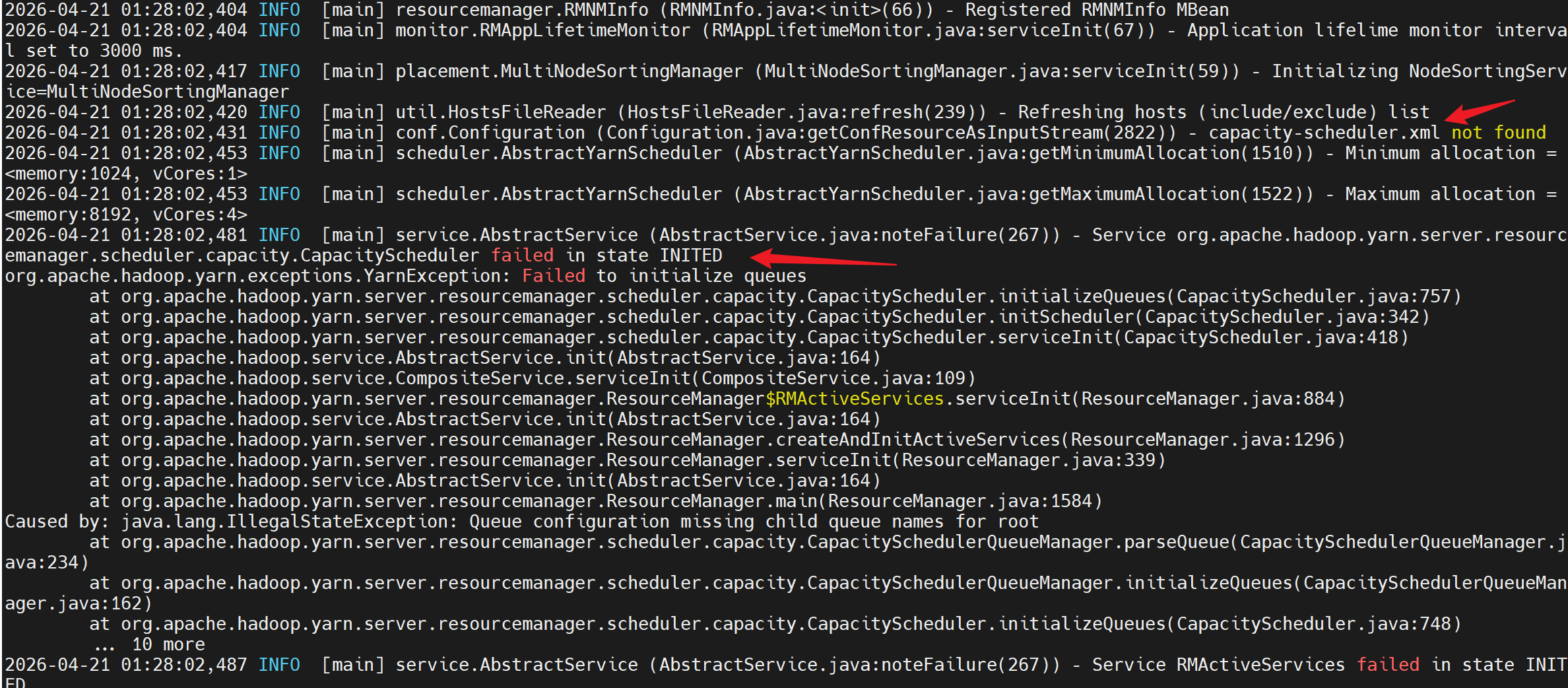
这个是因为在当初构建镜像时,
当使用 -v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop 挂载卷时,会完全替换容器内的 /usr/local/hadoop/etc/hadoop 目录内容。这意味着:
容器内 Hadoop 安装自带的默认配置文件被挂载的空目录覆盖了
只有 ~/hadoop-conf 目录中存在的配置文件才会出现在容器内
这个时候,可以从一个linux已经解压后的hadoop中,把默认文件复制过来,查看hadoop在默认的配置文件
bash
ls /opt/app/hadoop/etc/hadoop/
复制默认配置文件到~/hadoop-conf/目录下
我理解了,您希望从现有的 Hadoop 安装中复制默认配置文件到 ~/hadoop-conf 目录。让我帮您完成这个操作:
复制所有非编辑的默认配置文件
在linux的终端执行
bash
# 首先检查当前 ~/hadoop-conf 目录的内容
ls -la ~/hadoop-conf/
# 创建一个临时列表来跟踪哪些文件是自定义编辑过的
CUSTOM_FILES=("hadoop-env.sh" "core-site.xml" "hdfs-site.xml" "mapred-site.xml" "yarn-site.xml" "workers")
# 从源目录复制所有非自定义的配置文件
SOURCE_DIR="/opt/app/hadoop/etc/hadoop/"
echo "Copying default Hadoop configuration files..."
for file in $(ls $SOURCE_DIR); do
IS_CUSTOM=false
for custom_file in "${CUSTOM_FILES[@]}"; do
if [ "$file" = "$custom_file" ]; then
IS_CUSTOM=true
break
fi
done
if [ "$IS_CUSTOM" = false ] && [ -f "$SOURCE_DIR$file" ]; then
if [ ! -f "~/hadoop-conf/$file" ]; then
echo "Copying $file to ~/hadoop-conf/"
cp "$SOURCE_DIR$file" ~/hadoop-conf/
else
echo "Skipping $file (already exists in ~/hadoop-conf/)"
fi
fi
done
echo "Copy completed!"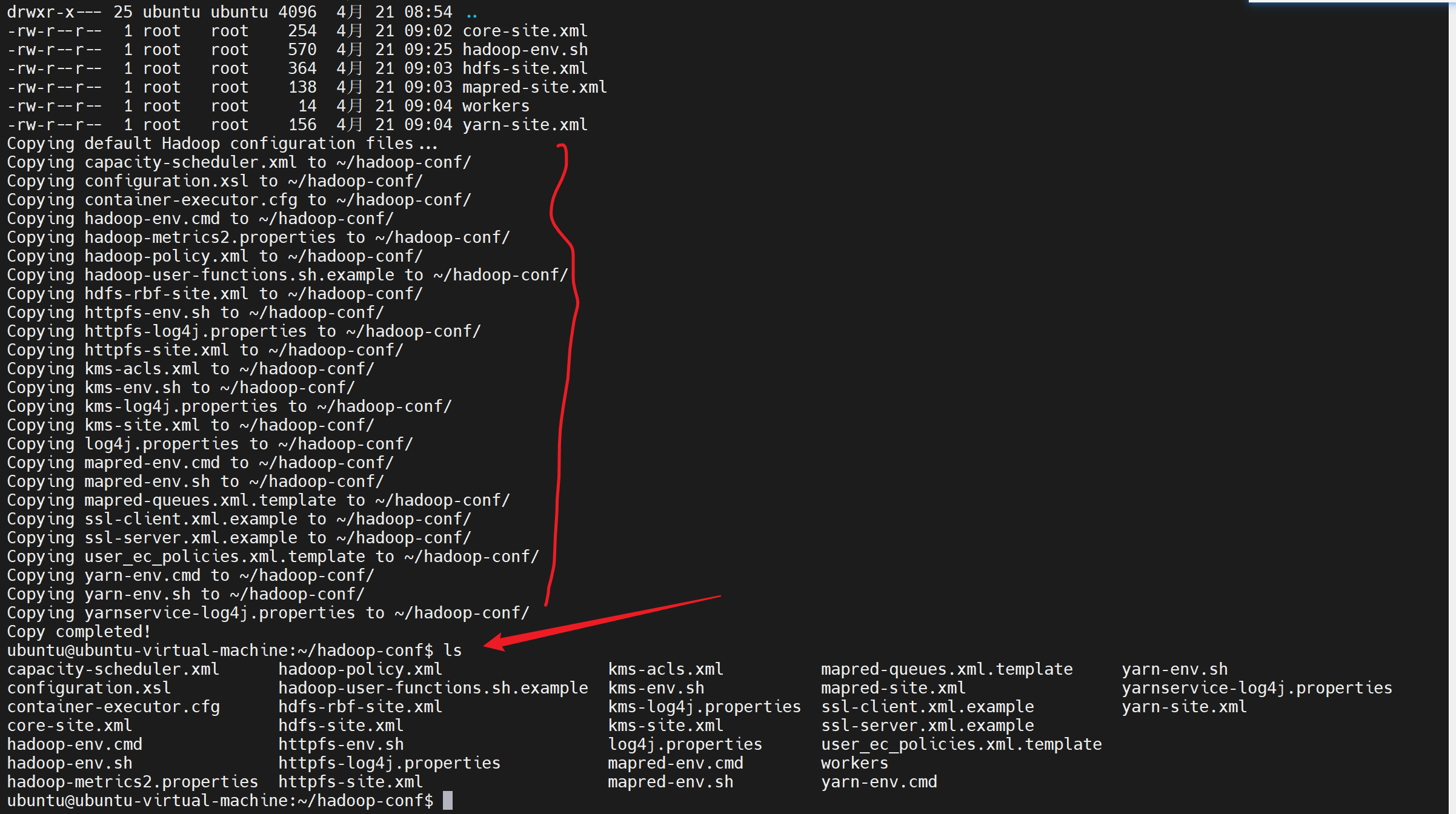
验证复制结果
bash
# 检查 ~/hadoop-conf 目录现在的全部内容
echo "Contents of ~/hadoop-conf after copying defaults:"
ls -la ~/hadoop-conf/现在 ~/hadoop-conf 目录应该包含了所有 Hadoop 的默认配置文件,除了您手动编辑的那几个文件。这样,当您重新启动容器时,挂载的卷将包含所有必需的配置文件。
修改后,启动yarn.sh
出现以下进程 = 成功:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
十二、测试案例(可直接跑)
1)创建目录
bash
hdfs dfs -mkdir -p /user/root/input2)上传文件
bash
echo "hello hadoop docker pseudo distributed" > test.txt
hdfs dfs -put test.txt /user/root/input3)运行 WordCount
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/input /user/root/output4)查看结果
bash
hdfs dfs -cat /user/root/output/part-r-00000
十三、Web UI(宿主机浏览器打开)
- HDFS: http://localhost:50070
- YARN: http://localhost:8088
以上的地址打不开
根据您的描述,Hadoop 3.3.0 版本的 Web UI 端口发生了变化。在 Hadoop 3.0+ 版本中,NameNode 的 Web UI 端口从 50070 改为 9870。
让我帮您确认并解决这个问题:
1. 检查 Hadoop 3.3.0 的默认端口
bash
# 查看当前 NameNode HTTP 地址配置
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml | grep -A 2 -B 2 "namenode.http"2. 正确的访问地址
对于 Hadoop 3.3.0,NameNode Web UI 的端口是:
- 新端口 :
http://localhost:9870(而不是 50070)
3. 更新您的 Docker 端口映射
如果要从本地访问,您需要将端口 9870 映射出来。请更新您的 Docker 运行命令:
bash
# 停止当前容器
docker stop hadoop-pseudo
# 使用正确的端口映射重新运行
docker run -d \
--name hadoop-pseudo \
--hostname hadoop-pseudo \
--network custom-network \
--ip 172.20.240.10 \
-p 9870:9870 \
-p 8088:8088 \
-p 8042:8042 \
-p 9000:9000 \
-v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop \
-v pseudo-hadoop-namenode:/hadoop-data/namenode \
-v pseudo-hadoop-datanode:/hadoop-data/datanode \
-v pseudo-hadoop-tmp:/hadoop-data/tmp \
--privileged \
hadoop-pseudo:3.3.0
bash
# 查看当前容器状态
docker ps -a | grep hadoop-pseudo
# 如果容器已停止,直接启动它
docker start hadoop-pseudo
# 然后添加端口映射需要重新配置容器,所以我们可以提交当前容器状态到新镜像
docker commit hadoop-pseudo hadoop-pseudo-updated:3.3.0
# 停止原容器
docker stop hadoop-pseudo
# 删除原容器
docker rm hadoop-pseudo
# 使用新镜像运行容器,并添加正确的端口映射
docker run -d --name hadoop-pseudo --hostname hadoop-pseudo --network custom-network --ip 172.20.240.10 -p 9870:9870 -p 8088:8088 -p 8042:8042 -p 9000:9000 -v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop -v pseudo-hadoop-namenode:/hadoop-data/namenode -v pseudo-hadoop-datanode:/hadoop-data/datanode -v pseudo-hadoop-tmp:/hadoop-data/tmp --privileged hadoop-pseudo-updated:3.3.0进入容器
bash
docker exec -it hadoop-pseudo bash5. 其他重要端口变更
Hadoop 3.x 版本的主要 Web UI 端口变更:
- NameNode HTTP: 50070 → 9870
- NameNode HTTPS: 50470 → 9871
- DataNode HTTP: 50075 → 9864
- DataNode HTTPS: 50475 → 9865
6. 访问其他管理界面
- NameNode Web UI: http://localhost:9870
- ResourceManager: http://localhost:8088
- DataNode: http://localhost:9864
请使用 http://localhost:9870 来访问 NameNode 的 Web 界面。如果您已经在 hdfs-site.xml 中配置了端口,请确保端口映射正确。
十四、最重要:后期可无缝扩展 ZK/Hive/Sqoop/Flume
这个镜像满足所有后期扩展条件:
- JDK 8
- Hadoop 完整环境
- SSH 免密
- 配置可外部挂载
- 数据持久化
- 端口全开
- 单一节点(伪分布式)= 最适合做学习实验栈
你后面要装:
- Zookeeper
- Hive
- Sqoop
- Flume
- HBase
全部可以直接在这个容器里装,不用重做环境!