传统循环神经网络(RNN)是处理序列数据 (文本、语音、时间序列)的经典模型,但它存在致命缺陷:无法有效捕捉长期依赖关系,训练时极易出现梯度消失、梯度爆炸问题,距离较远的上下文信息会完全丢失。
LSTM(Long Short-Term Memory,长短期记忆网络)是 RNN 最经典、最广泛使用的改进版本。它在原生 RNN 的基础上,设计了全新的细胞状态 + 三门控机制,完美解决了传统 RNN 长期遗忘的痛点,可以自主学习、保留长期重要信息、丢弃无关冗余信息,是目前 NLP、时序预测领域最核心的基础模型之一。
一、LSTM 通俗理解
LSTM的工作逻辑和人脑记忆完全一致:模型拥有有限的记忆能力,自主判断信息重要性,只保留相关有效信息用于预测,主动忘记无关冗余数据。
简单总结:记住重要的,忘记无关紧要的。
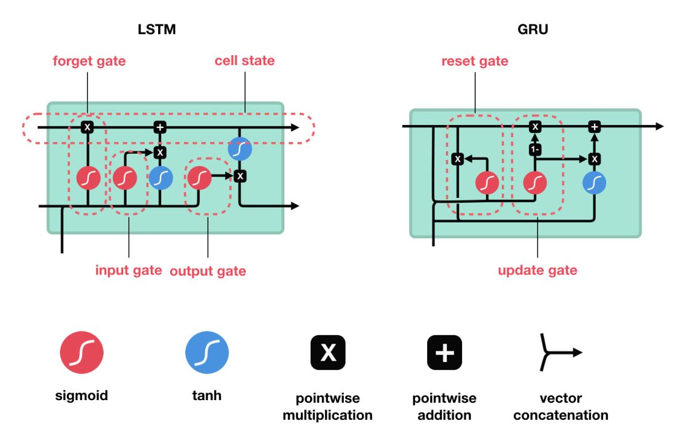
二、原生 RNN vs LSTM 结构对比
原生 RNN 的隐状态计算非常简单:
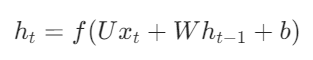
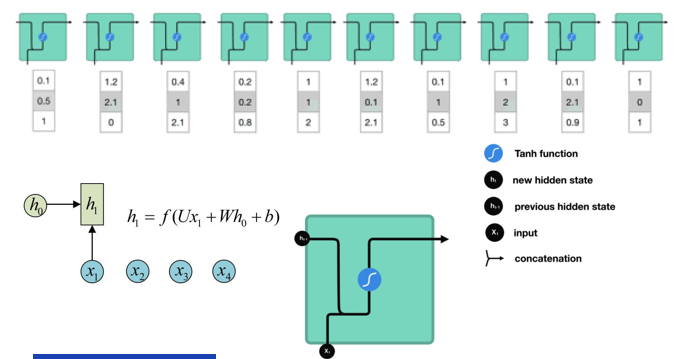
每一时刻直接叠加当前输入 + 上一时刻隐状态,信息无筛选、无保护,远距离传递时梯度会不断衰减,最终完全消失。
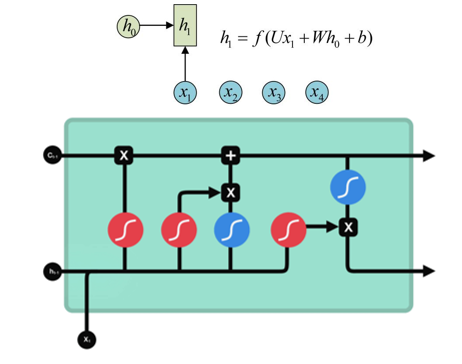
而 LSTM 彻底重构了循环单元:新增细胞状态 Cell State(长期记忆传送带),同时设计了三套独立门控结构,分别控制「遗忘旧信息、存入新信息、对外输出信息」,从根源解决长期遗忘问题。
三、LSTM 三大核心门控结构详解
LSTM 核心由遗忘门、输入门、输出门三部分组成,搭配贯穿时间步的细胞状态 Cell State,分步完成记忆的更新与输出。下面完全对应 PPT 图示,逐门拆解原理、步骤、功能。
3.1 遗忘门 Forget Gate(第一步:过滤旧记忆)
核心功能
决定从上一时刻的细胞状态(历史记忆)中,丢弃哪些不重要的历史关键词信息,是 LSTM 解决长期遗忘的第一步。
工作步骤
- 将上一时刻隐藏状态
和**当前时刻输入
- 经过线性变换后送入
sigmoid激活函数; - 输出取值范围在
0~1之间的权重向量:- 数值越接近 0 → 该部分历史信息完全丢弃
- 数值越接近 1 → 该部分历史信息完全保留
直观理解
就像我们看完评论后,自动忘掉助词、虚词这类无效旧信息,只保留有价值的历史观点。公式逻辑:遗忘门输出权重和旧细胞状态逐元素相乘,直接过滤掉不需要的历史记忆。
3.2 输入门 Input Gate(第二步:存入新记忆)
核心功能
筛选当前时刻输入的新信息,决定哪些新内容需要更新、存入细胞状态(长期记忆)。
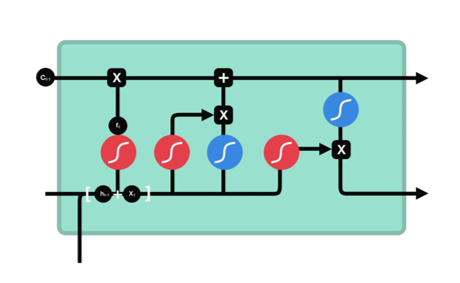
工作步骤(两步并行)
- sigmoid 控制门部分 :输入**
- tanh 候选值部分 :输入ht−1和xt,经过 tanh 激活函数,生成 -1,1 区间的全新候选记忆向量
- 两者逐元素相乘:用 sigmoid 权重过滤 tanh 候选值,只把重要的新信息筛选出来。
最后将经过遗忘门过滤后的旧细胞状态+输入门筛选后的新记忆相加,得到当前时刻最新细胞状态,完成长期记忆的更新。
3.3 输出门 Output Gate(第三步:对外输出记忆)
核心功能
决定最新细胞状态里的内容,哪些部分可以作为当前隐藏状态输出,传递给下一个时间步、或是模型下游任务。
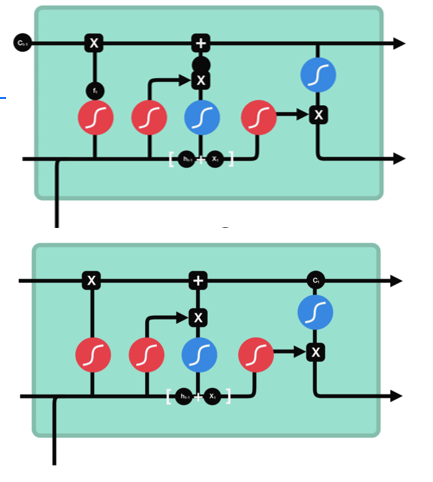
工作步骤
- 输入
- 将最新细胞状态**
- 将 tanh 输出与 sigmoid 权重逐元素相乘,得到当前时刻隐藏状态
- 把新细胞状态**
四、LSTM 整体工作流程总结
- 遗忘门:清理上一步无用的历史长期记忆
- 输入门:筛选当前输入的新信息,存入长期记忆
- 更新细胞状态:旧记忆过滤后 + 新记忆筛选后 = 最新长期记忆
- 输出门:从长期记忆里提取有效信息,生成当前输出隐状态