通过Canal将MySQL数据同步到ES
软件配置:
-
Mysql 8.2 (阿里云服务器中docker镜像内)
-
ES 7.17 (本地WSL docker)
-
Canal 1.1.6 (本地wsl)
-
Canal-adapter 1.1.6 (本地wsl)
-
jdk 11 (本地wsl)
原理
Canal 本质是在"假装自己是 MySQL 的从库",读取 binlog,再把数据变更解析出来。MySQL 有一个核心机制:
1. binlog(数据库变更日志)
MySQL 每次执行:
-
INSERT
-
UPDATE
-
DELETE
都会写入 binlog。
binlog 可以理解为:所有数据变更的“操作日志2. binlog 有三种格式
| 类型 | 说明 | Canal用哪种 |
|---|---|---|
| STATEMENT | 记录 SQL | ❌ 不稳定 |
| ROW | 记录行变化 | ✅ 必须用 |
| MIXED | 混合 | ❌ 不推荐 |
👉 Canal 依赖 ROW 格式
因为它记录的是:
before / after 的数据变化而不是 SQL。
三、MySQL 主从复制机制(关键底层)
MySQL 原生有一套机制:
主库(Master)
- 写 binlog
从库(Slave)
-
连接 Master
-
拉 binlog
- 执行 SQL
四、Canal 的"关键伪装"
⭐ Canal 做了一件非常巧妙的事情:
👉 它伪装成 MySQL 从库
Step 1:建立连接
Canal 对 MySQL 说:
我是一个 Slave
我要同步数据MySQL 会启动一个:
binlog dump threadStep 2:MySQL 推送 binlog
MySQL 开始把 binlog:
持续发送给 Canal就像"直播推流"。
Step 3:Canal 接收 binlog
Canal 收到的是这种原始数据:
TableMapEvent
WriteRowsEvent
UpdateRowsEvent
DeleteRowsEvent👉 注意:这是 底层事件,不是 SQL
Step 4:Canal 解析 binlog
Canal 做的事情:
binlog event → 结构化数据例如:
{
"table": "user",
"action": "update",
"before": {"name": "Tom"},
"after": {"name": "Tom2"}
}五、Canal Adapter 做什么
Canal 只负责:
"读 binlog + 解析数据"
但不会写 ES。
Adapter 的工作:
Step 1:接收 Canal 数据
拿到结构化变更:
update user set name='Tom2'Step 2:转换成 ES 文档
例如:
{
"_id": 1,
"name": "Tom2",
"age": 20
}Step 3:写入 ES
通过 Bulk API:
POST /_bulk批量写入 Elasticsearch。
六、整个链路本质
一句话总结:
MySQL binlog(变化日志)
↓
Canal(模拟从库读取 binlog)
↓
解析 binlog event
↓
Adapter(转换数据结构)
↓
Elasticsearch(存储+检索)下面为操作步骤:
- 检查并且调整数据库的配置如下
sql
-- 1. 查看 binlog 是否开启
SHOW VARIABLES LIKE 'log_bin';
-- 应该显示 ON
-- 2. 查看 binlog 格式
SHOW VARIABLES LIKE 'binlog_format';
-- 应该显示 ROW
-- 3. 查看 server_id
SHOW VARIABLES LIKE 'server_id';
-- 应该显示 1
-- 4. 查看 binlog 是否生效
SHOW MASTER STATUS;
-- 应该显示当前的 binlog 文件和位置
-- 5. 查看所有 binlog 相关配置
SHOW VARIABLES LIKE '%binlog%';-
从GIT 上找到canal下载包地址,我这里用的是1.1.6
https://github.com/alibaba/canal/releasesAssets 里的文件列表说明
文件名 说明 是否需要下载 canal.adapter-1.1.6.tar.gzCanal Adapter 的核心程序包(你正在用的) ✅ 如果你要用 Adapter,必须下载这个 canal.admin-1.1.6.tar.gzCanal Admin(Web 管理控制台) ❌ 除非你要用网页管理 Canal,否则不需要 canal.deployer-1.1.6.tar.gzCanal Deployer(Canal Server 服务端) ✅但 Canal 整体架构需要它,用来连接MYsql canal.example-1.1.6.tar.gz官方示例项目(含配置、SQL、测试数据) ❌ 一般开发者才需要 Source code (zip)源码压缩包(ZIP 格式) ❌ 一般开发者才需要 Source code (tar.gz)源码压缩包(tar.gz 格式) ❌ 一般开发者才需要
- 修改配置
ES\canal.deployer-1.1.6\conf\example\instance.properties
bash
canal.instance.master.address = 47.156.113.82:31218
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.name=example
canal.instance.connectionCharset = UTF-8
canal.instance.gtidon = false
canal.instance.tsdb.enable = true
canal.instance.get.ddl.isolation = false
canal.instance.parser.ddl.isolation = false
canal.instance.parser.parallel = false
canal.instance.filter.regex = .*\\..* 所有的库和表
canal.instance.network.soTimeout = 600
canal.instance.detecting.enable = true
canal.instance.detecting.interval.time = 1
canal.instance.binlog.format = ROW
canal.instance.binlog.image = FULL说明: 这是 Canal Server 用来:
-
连接 MySQL
-
拉取 binlog
-
解析 binlog
-
控制同步行为
其中instance 名称(非常重要)比如adapter配置中
bash
instance: example
destination: example不一致 → Adapter 拿不到数据 / NPE / 无日志
其他的不用修改,然后直接启动canal 服务就可以了
看到这里就启动成功了,
你要配置canal.adapter-1.1.6.tar.gz这里面的文件了,首先解压到和.canal.deployer同级目录下(无所谓其实)
同样在conf中书写配置application.yml,注意1.1.6版本的配置写法如下
php
server:
port: 8081 # Canal Adapter 服务端口(HTTP接口/监控用)
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss # JSON 序列化日期格式
time-zone: GMT+8 # 时区(中国时间)
default-property-inclusion: non_null # 不序列化 null 字段
# 数据源配置(Spring 层使用)
spring.datasource:
defaultDS:
url: jdbc:mysql://47.116.153.12:31218/go?useUnicode=true&characterEncoding=UTF-8&useSSL=false
username: canal # MySQL 用户名(供 canal 使用)
password: canal # MySQL 密码
driver-class-name: com.mysql.jdbc.Driver # MySQL 驱动(旧版驱动)
# Canal 适配器核心配置
canal.conf:
canal.client.adapter:
dateFormat: yyyy-MM-dd HH:mm:ss # canal 传输数据的时间格式
mode: tcp # canal 通信模式:tcp / kafka / rocketMQ / rabbitMQ
flatMessage: true # 是否使用扁平结构数据(推荐 true,方便 ES 写入)
syncBatchSize: 1000 # 每批同步最大条数
retries: 0 # 失败重试次数
timeout: # 超时时间(这里为空,默认值生效)
accessKey: # MQ/云环境访问 key(可选)
secretKey: # MQ/云环境 secret(可选)
consumerProperties:
# canal tcp 方式消费配置
canal.tcp.server.host: 127.0.0.1:11111 # canal server 地址
canal.tcp.batch.size: 500 # 每次拉取 binlog 数量
canal.tcp.username: # canal 用户名(如果开启认证)
canal.tcp.password: # canal 密码
# =========================
# 数据源配置(canal 监听的 MySQL)
# =========================
srcDataSources:
defaultDS:
url: jdbc:mysql://47.116.153.12:31218/go?useUnicode=true&characterEncoding=UTF-8&useSSL=false
username: canal # MySQL 账号
password: canal # MySQL 密码
driver-class-name: com.mysql.jdbc.Driver
# =========================
# 适配器配置(重点:同步目标)
# =========================
canalAdapters:
- instance: example # canal instance 名称(必须和 canal-server 配置一致)
groups:
- groupId: g1 # 逻辑分组(可以多个同步任务)
outerAdapters:
- name: es7 # 输出到 Elasticsearch 7
key: esKey # adapter 标识 key(可随便定义)
hosts: http://127.0.0.1:9200 # ES 地址
properties:
mode: rest # 写 ES 模式:rest(推荐)/ transport(已废弃趋势)
# security.auth: user:pass # ES 开启认证时使用
cluster.name: docker-cluster # ES 集群名称(docker 默认)配置解释都在参数中了,下面开始配置映射也就是表结构,同样在conf 文件中 es7
比如我这里配置了一个药材表herbs.yml
php
dataSourceKey: defaultDS
outerAdapterKey: esKey
destination: example
groupId: g1
esMapping:
_index: herbs
_type: _doc
_id: herb_id
upsert: true
sql: "SELECT h.herb_id, h.common_name, h.scientific_name, h.other_names, h.properties, h.tastes, h.efficacy, h.image_url, h.origin, h.type, h.medicinal_smell_id, h.character_id, h.toxicity_id, h.book_id, h.pinyin, h.is_show, h.created_at, h.updated_at FROM herbs h"
commitBatch: 1000
dateFormat: yyyy-MM-dd HH:mm:ss这个时候正常情况下启动

php
rm logs/adapter/adapter.log && ./bin/stop.sh && ./bin/startup.sh 去日志里面查看
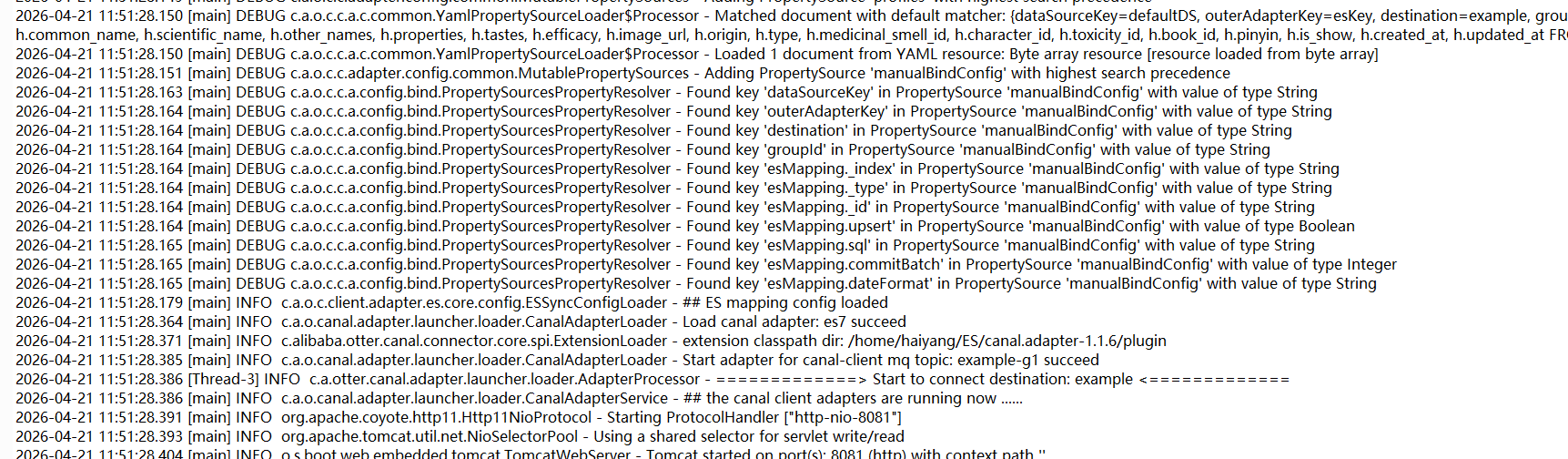
出现succeed就是成功了
因为binlog是增量日志,有可能你需要做一次全量同步这个时候只需要访问
sql
curl -X POST http://127.0.0.1:8081/etl/es7/herbs.yml 你就会看到下面的结果,如果原表数据量大,你可以选择分页,这个要去修改你的映射文件就行  这个时候es已经有了mysql中的数据了
这个时候es已经有了mysql中的数据了
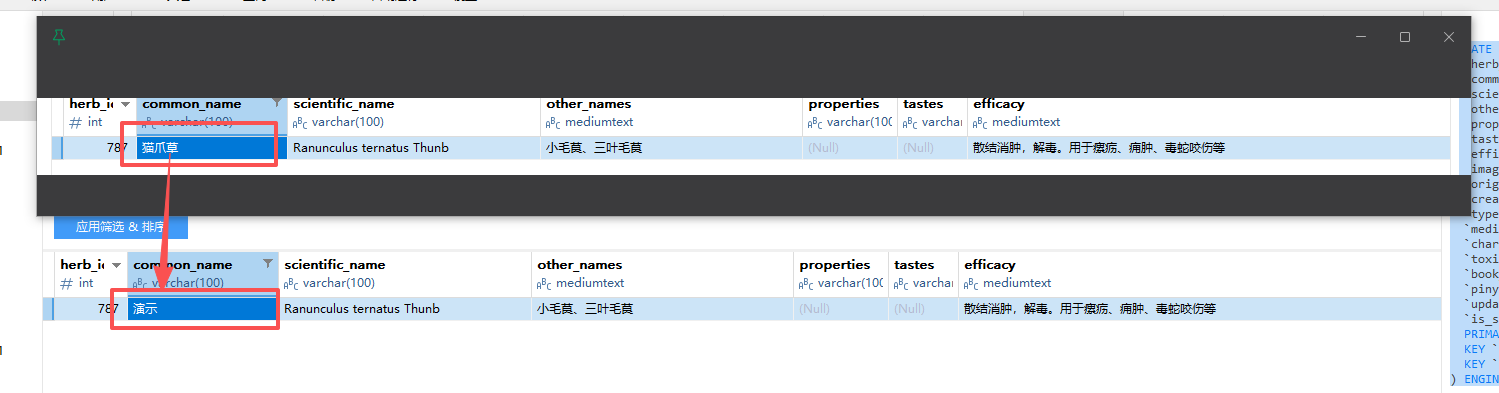
接下来:修改binlog测试一下
我用sql 调整了一行信息,这里面的信息会立刻显示出来

再来检查ES中的
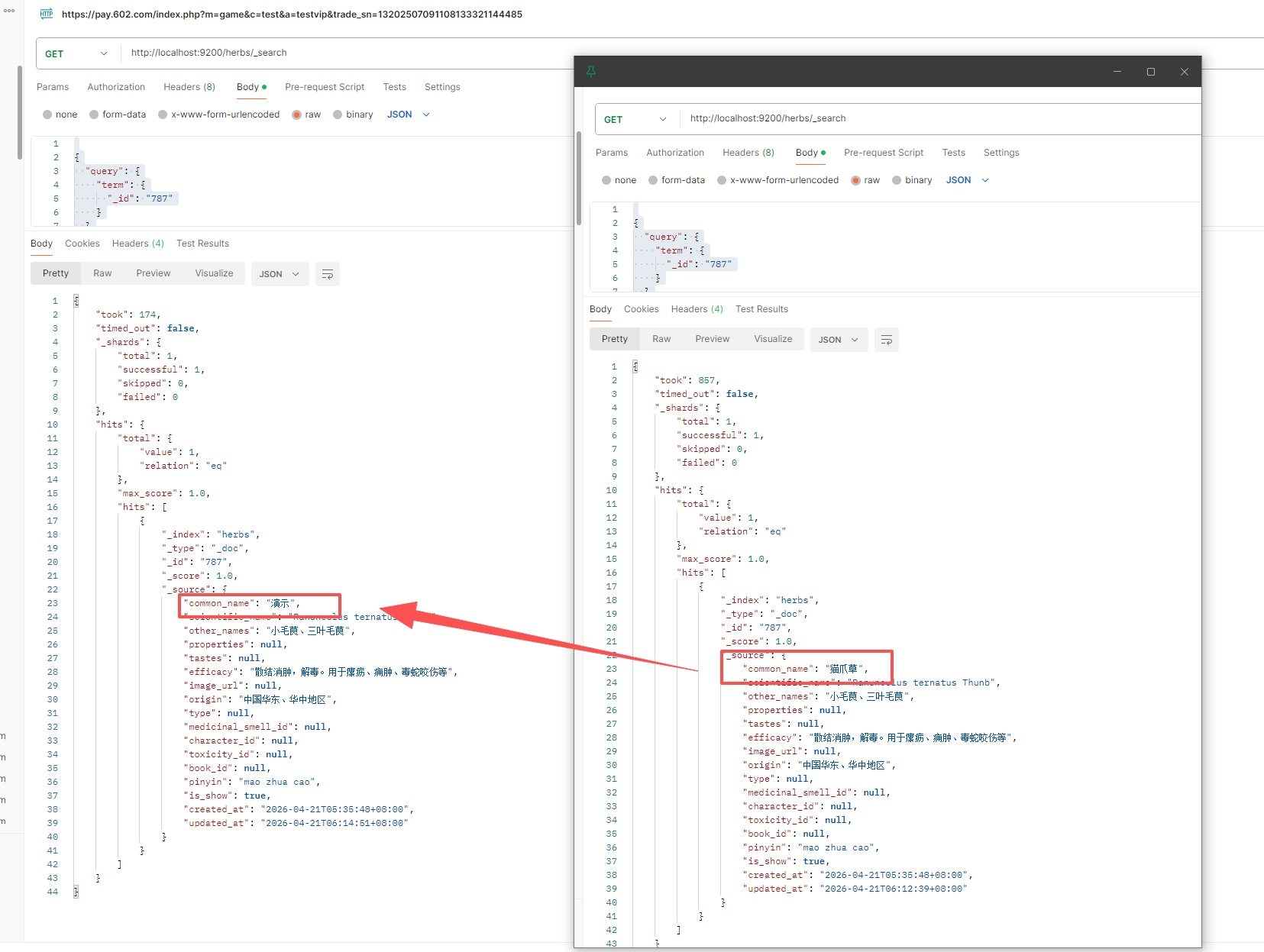
注意
mysql8.2 adapter需要换库里面的包,我这里用的是
mysql-connector-j-8.3.0.jar报空指针错误一般是参数配置文件,删除不需要的参数就行,
另外如果版本不对,参数配置的全对也可能会出现空指针的错误