Flink运行时架构
1.系统架构
-
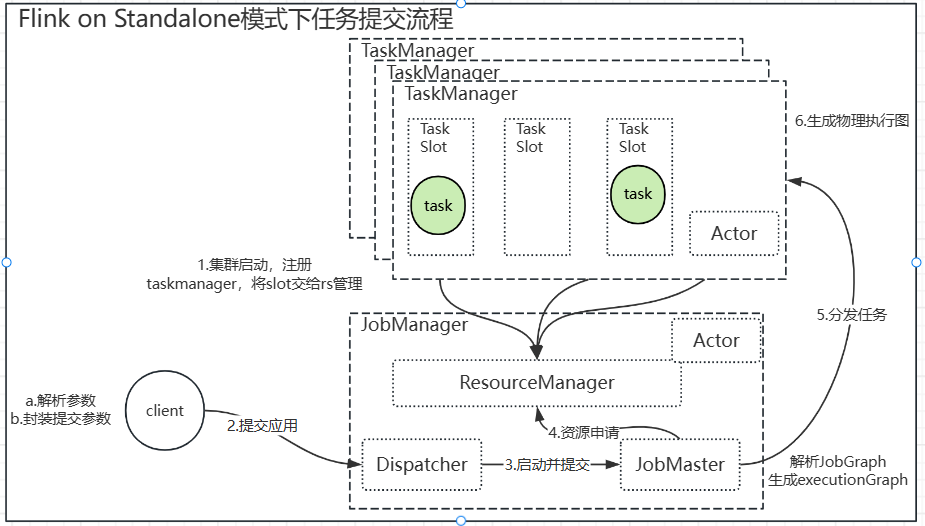
Client 应用提交客户端,用于解析参数、封装提交参数并将应用运行所需信息提交给JobManager
-
JobManager Flink集群中任务管理和调度的核心,控制应用执行的主进程。
-
JobMaster
JobMaster是JobManager中核心的组件,负责处理单独的作业,JobMaster和具体的Job是一一对应的,多个Job可以运行在同一个Flink集群中,每个Job都有自己的JobMaster。
在作业提交时,JobMaster会收到要执行的应用,JobMaster会将JobGraph转换成物理层面的数据流图(执行图),包含了所有可以并发执行的任务,JobMaster会向资源管理器发出请求,申请执行任务必要的资源,一旦获取到资源,就会把执行图分发给TaskManager运行。
运行过程中,JobMaster会负责所有需要中央协调的操作,包括检查点的协调等。
-
Dispatcher
负责提交应用,为一个应用创建JobMaster,该组件不是必须,主要看作业的提交方式。
-
ResourceManager
主要负责资源的分配和管理,在Flink集群中资源指的是TaskManager的任务槽(task slot),任务槽是Flink中的集群调配单元,包含用来执行计算的CPU和内存资源,任务都需要分配到一个slot上执行。
注意:该Resourcemanager需要与Yarn的资源管理器划分开(RM),Flink集群内置了ResourceManager。
-
Actor 通信系统,用于跨服务进程通信。
-
-
TaskManager
Flink的工作进程,数据流的具体计算就是TaskManager来执行的,Flink集群必须有一个TaskManager,每个TaskManager包含一定数量的任务槽(task slot)。Slot是资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量。
集群启动后,TaskManager会向资源管理器注册Slots;收到资源管理器的指令后,TaskManager会将slots分配给JobMaster调用。在作业运行过程中,TaskManager可以缓冲数据,不同TaskManager之间可以交换数据。
2.核心概念
2.1并行度
在分布式的场景下,数据量特别大时,可以将划分多个计算任务进行数据计算处理。不同的任务在不同的机器上面执行,实现并发计算。
在flink执行过程中,每一个算子可以包含1个或多个子任务(subtask),子任务在不同的线程、不同的机器中独立完成执行。
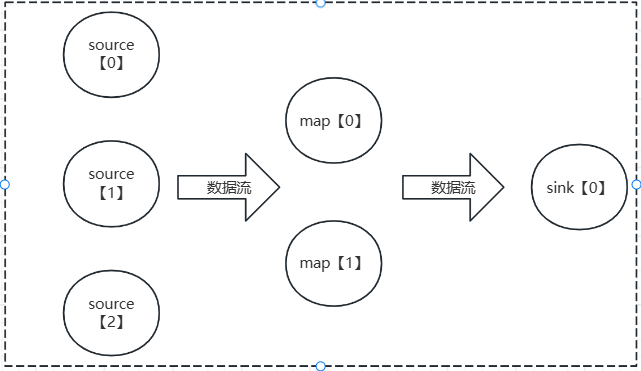
一个特定算子中子任务的数量就是并行度,包含子任务的数据流就是并行数据流,需要多个分区来分配并行任务。
一个流程序的并行度,可以认为是其所有算子中最大的并行度。一个流程序中,不同算子可能具有不同的并行度。
如图所示:source的并行度是3,map的并行度是2,sink的并行度是1。
并行度设置方式
并行度可以在编码、客户端提交作业或者flink配置文件中指定
- 通过流执行对象设置全局并行度
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(2);- 通过Ds对象设置算子并行度
java
// 设置source算子并行度
env.socketTextStream("", 9999).setParallelism(2);- 提交任务时,通过参数指定全局并行度
shell
bin/flink run -p 2 xxxx- 通过flink-conf.yaml文件指定全局默认并行度
2.2算子链
Flink中的每一个操作算子称为Task任务,算子的每个具体实例则称为subTask,SubTask是Flink中最小的处理单元,多个SubTask可能在不同的机器上执行。一个TaskManager进程包含一个或多个执行进程,用于执行SubTask,Taskmanager中的Slots对应一个执行线程。一个执行线程可以执行多个SubTask。
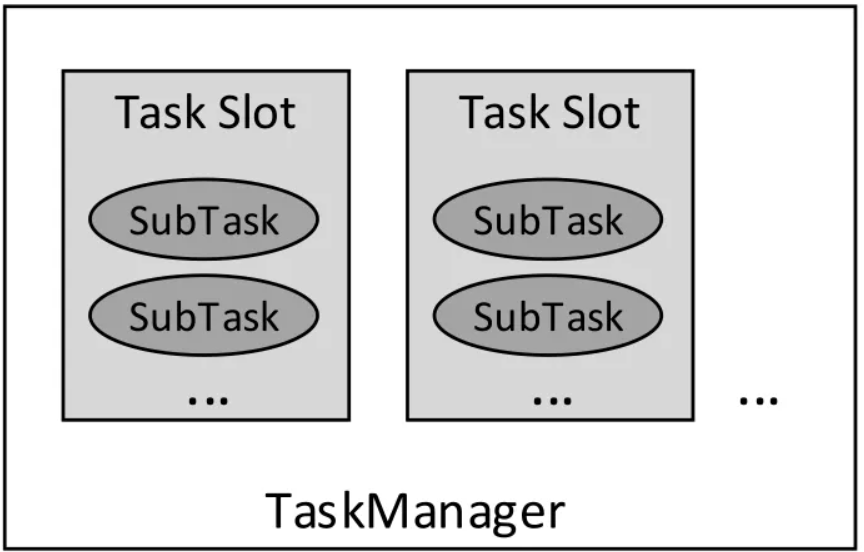
由于每个SubTask只能在一个线程中执行,为了减少线程间切换和数据缓冲的开销,在降低延迟的同时提高整体吞吐量,Flink可以将多个SubTask链接成一个Task在一个线程中执行,将多个subTask链接在一起的方式称为任务链。
默认情况下算子链是开启的,可以通过流执行对象进行关闭
java
//禁用算子链
env.disableOperatorChaining();
//
DataStreamSource<String> ds = env.socketTextStream("", 9999);
ds.disableChaining(); //当前算子禁用算子链
ds.startNewChain(); //从当前算子开始创建新链算子之间的关系
一个数据流在算子之间传输的形式,可以是一对一的直通模式,也可以是打乱的重分区模式。
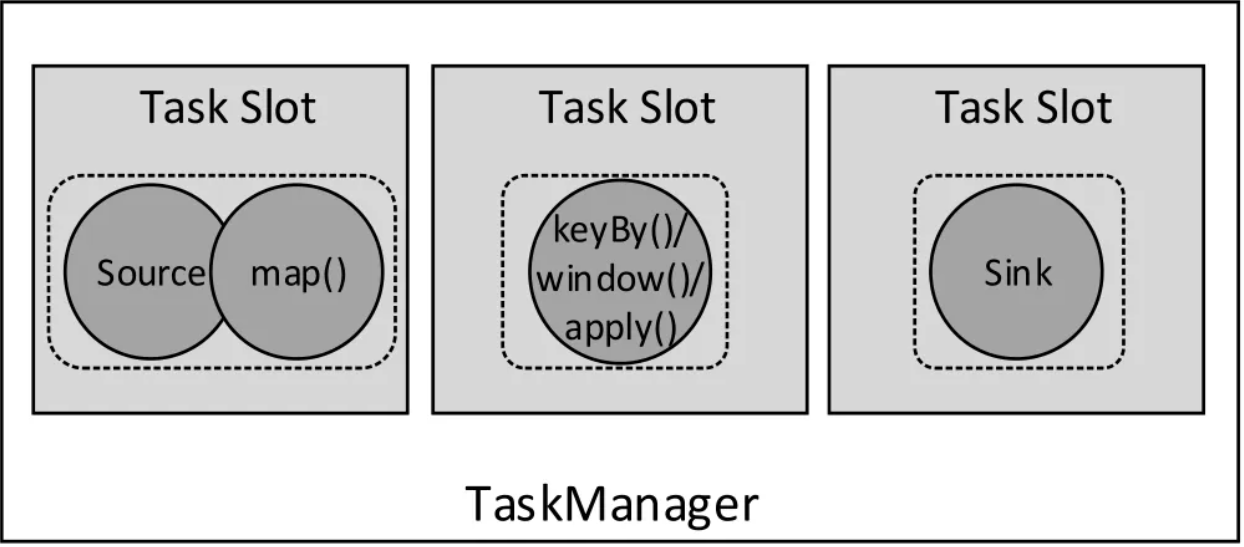
- 一对一
数据流维护着分区以及元素的顺序,比如source算子读取数据后,可以直接将数据发送给map,之间不需要重新分区,也不需要调整数据的顺序。这种关系类似于Spark的窄依赖。
- 重分区
从名称上来看就是数据流的分区发生了变化。比如map算子后面的keyBy/Window算子之间。每个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游子任务。这种传输方式会引起数据的分区发生变化,类似于Spark的Shuffle。
2.3任务槽
Flink中每个TaskManagr是一个JVM进程,可以启动多个独立的线程,来并行执行多个子任务(SubTask)。
TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那么一个TaskManager能够处理多少个任务,为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源进行划分,这就是任务槽(Slot)。
每个任务槽(task slot)表示TaskManager拥有计算资源的一个固定大小的子集。这些资源可以独立执行子任务。
假设TaskManger的slot数量为3,那么一个Taskmanager就可以并行运行3个subTask。
- taskmanager的slot数量,可以在配置文件中进行指定
yaml
taskmanager.numberOfTaskSlots: 8- 如果是flink on yarn的模式提交job,那么可以在提交job时通过参数-ys进行指定solts数量
注意:slot目前仅仅用来隔离内存,不会涉及到CPU的隔离 ,在具体应用时尽可能将Slot设置成机器的CPU核心数,避免不同的任务在CPU之间的竞争。
任务对任务槽的共享
同一个作业中,不同任务节点的并行子任务可以放在同一个Slot上运行。
默认情况下Flink是允许Slot共享的,如果想将某个算子使用独立的Slot执行可以在编码时进行设置Slot资源组。
java
SingleOutputStreamOperator<String> ds = env.addSource(new DiySource()).name("Diysource");
ds.slotSharingGroup("group_1"); //设置slot组只有属于同一个slot共享组的子任务,才会开启slot共享,不同组之间的任务是完全隔离的,必须分配到不同的slot上。如果所有算子的子任务都使用独立的slot组,那么slot所需的最大数量等于所有算子的子任务数之和。
3.作业提交流程
作业提交流程这里引用一张比较直观的图:
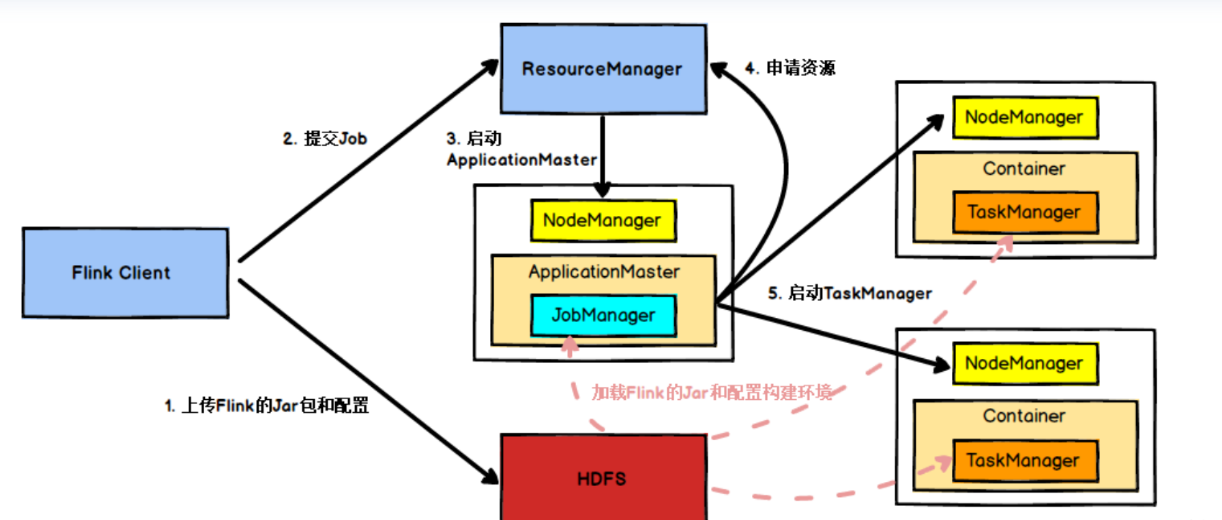
- Flink client将作业的Jar和配置文件上传到Hdfs分布式文件系统
- Flink将作业提交的请求发生到RM,其中请求信息包含作业Jar和配置的存储路径以及运行的信息
- RM收到客户端作业提交后,会选择一台NodeManager启动container容器,在容器内部启动ApplicationMaster来运行JobManager
- JobManger启动后从HDFS加载作业的Jar信息和配置,分析出执行图(ExecutionGraph)后向RM申请资源,用于运行Task任务
- RM收到资源请求后,通知TaskManager启动Contariner运行TaskManger,TaskManager运行后,JobManager将具体执行的Task分发给TaskManager
- JObManger监控TaskManager运行情况,并负责中央协调操作。
- 当程序运行完成后,TaskManager会将执行信息反馈给JobManager,统一由JobManager负责通知RM销毁资源