目录
- 引子
- 第 1 章:入口 --- 按下回车之后
- 第 2 章:全局状态 --- 一个请求的"上下文护照"
- 第 3 章:Query Engine --- 会话的"大脑"
- 第 4 章:核心循环 --- while(true) 状态机
- 第 5 章:流式调用与工具穿插 --- 性能魔法
- 第 6 章:权限系统 --- 8 层安全检查链
- 第 7 章:附加消息 --- 模型看不到的上下文
- 第 8 章:多 Agent --- 递归的边界
- 第 9 章:三层可观测性 --- 用户看不到的记录
- 第 10 章:全局设计哲学 --- 一张表看懂 Claude Code
- 第 11 章:带走什么 --- 可复用的工程 Pattern
- 附录:还没看完的部分
引子
你在 Claude Code 里输入了一句话:
"帮我重构这个模块,拆成三个文件,跑一下测试"
屏幕上开始跳动:读取文件、运行测试、编辑代码......最后告诉你:
Done in 45s | $0.12
整个过程丝滑得像一个熟练的程序员在替你干活。但你可能和我一样好奇:在这 45 秒里,Claude Code 内部到底经历了什么?
大多数关于 Claude Code 的文章都在讲"怎么用"------怎么装、怎么配、怎么调 prompt。但很少有人回答"它是怎么跑起来的"。
所以我扒了它的源码。
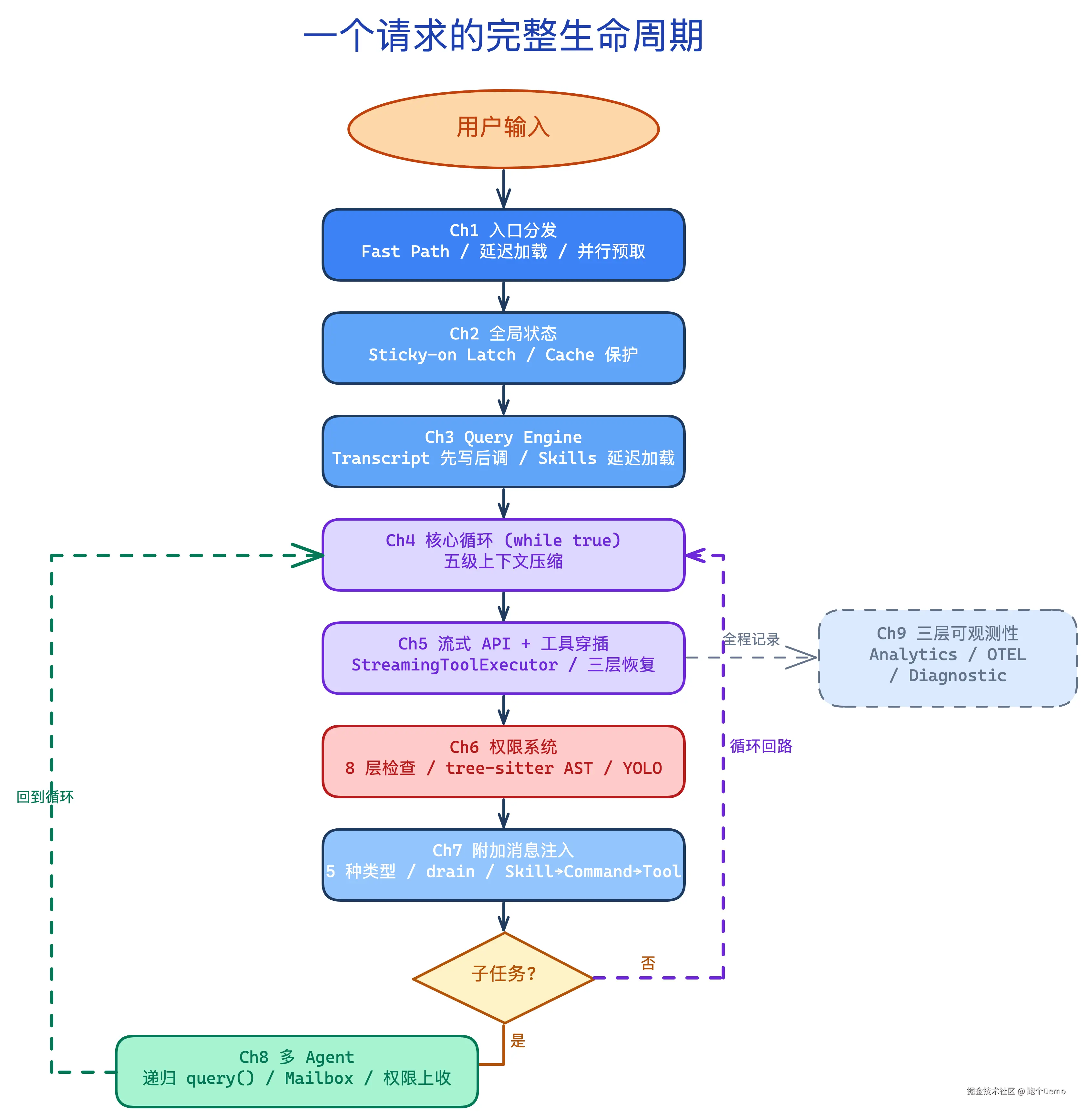
社区逆向工程版本,约 53KB 的七层架构拆解,一周时间不间断分析。从入口分发到多 Agent 递归,从流式 API 调用到 8 层权限检查链,我按一个请求的完整生命周期把它拆成 10 个环节。
每个环节都藏着一个设计选择。串起来,就是 Claude Code 的工程哲学。
全文流程图
第 1 章:入口 --- 按下回车之后
用户在终端敲下 claude,按下回车。代码从 cli.tsx 开始跑,第一个设计就很典型:
javascript
// cli.tsx --- Fast Path:零导入,12ms 退出
if (args[0] === '--version') {
console.log(`${MACRO.VERSION} (Claude Code)`);
return;
}
// 正常路径:全部延迟加载
const { main: cliMain } = await import('../main.js');--version 走 Fast Path,零导入直接退出。其他命令全部通过动态 import() 加载------交互模式、一次性模式、子命令走不同路径,只加载需要的代码。
模块加载的同时,MDM 设置读取、Keychain 认证等操作并行执行,不串行等待。三个入口文件各司其职:
| 文件 | 职责 | 体量 |
|---|---|---|
cli.tsx |
入口分发:Fast Path or 正常路径 | 轻量 |
main.tsx |
完整 CLI:解析参数、初始化环境 | 4690 行 |
REPL.tsx |
交互循环:用户输入、输出渲染 | 876KB,最大文件 |
设计哲学
把复杂度消化在启动层,主循环才能保持单纯。
如果不这么做,主循环就要处理"这个模块加载了吗?""认证过了吗?"这些分支------每多一个 if,循环就少一分可读性。Claude Code 选择在启动时把所有边界条件算清楚,进入主循环后只做一件事:处理请求。
第 2 章:全局状态 --- 一个请求的"上下文护照"
命令进来了,Claude Code 需要知道"现在是什么状态"------哪个项目、什么模型、花了多少钱、哪些功能被激活了。
这些信息全部收在 bootstrap/state.ts 里。
State:80+ 个字段的"护照"
State 类型定义了 80 多个字段,覆盖了 Claude Code 运行的方方面面:
- 会话追踪:sessionId、projectRoot、originalCwd
- 成本/Token:totalCostUSD、modelUsage、totalAPIDuration
- Skills 追踪:invokedSkills、discoveredSkillNames
- Sticky-on Latches:afkModeHeaderLatched、fastModeHeaderLatched...
你可以把它理解为一个请求的"护照"------走到哪一步,都带着这些信息。
Sticky-on Latch:保护 50-70K token 的缓存
这章最值得深入的是 Sticky-on Latch 机制。
先说背景。Anthropic 的 Prompt Cache 有一个特性:请求参数必须完全一致,才能命中缓存。
Cache Key 包含 7 个维度:
| 维度 | 变化后果 |
|---|---|
| System Prompt | 改了 → bust |
| Tools + Schema | 增/删/改 → bust |
| Beta Headers | 增/删 → bust |
| Model | 换模型 → bust |
| cache_control | scope/TTL 变化 → bust |
| Fast Mode | 切换 → bust |
| Effort | 变化 → bust |
其中 Beta Headers 包括 afk-mode-2026-01-31。也就是说,用户用 Shift+Tab 切换 Auto Mode,就改变了 betas 列表 → Cache Key 不同 → 50-70K token 的缓存直接 miss。
那 Anthropic 怎么解决的?Sticky-on Latch。
先解释"Latch"这个名字。它来自数字电路------锁存器 是一种只能单向翻转的电子元件:一旦被触发就锁定在激活状态,只有显式 Reset 信号才能复位。Claude Code 借用这个概念:一旦某个 Beta Header 被激活过,就锁住不变,直到用户执行 /clear 或 /compact 才重置。
sql
// state.ts:226-237
afkModeHeaderLatched: boolean | null, // null → true → 保持 true
fastModeHeaderLatched: boolean | null,
cacheEditingHeaderLatched: boolean | null,
thinkingClearLatched: boolean | null,源码实现(claude.ts:1412-1456):激活时调用 setAfkModeHeaderLatched(true) 等方法一次性写入;读取时(claude.ts:1655-1668)根据 latch 值构建 betasParams 数组;重置时(state.ts:clearBetaHeaderLatches())由 /clear 或 /compact 触发,四个字段统一归 null。
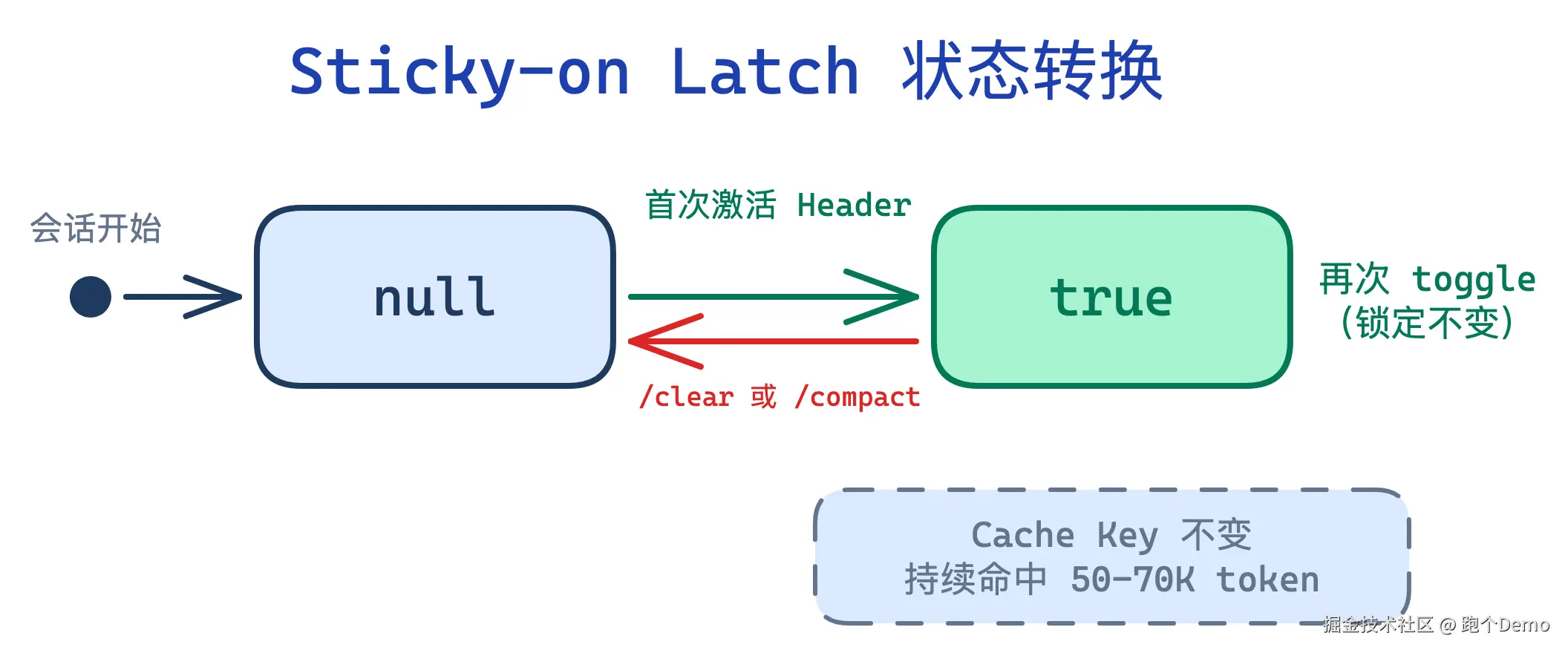 这本质上是一个工程权衡:用户切换模式时,你希望 Header 跟着变(直觉上合理),但你更不希望 bust 掉 50-70K token 的缓存。所以 Latch 选择了后者------牺牲一点"模式切换的即时响应",换取缓存命中率。
这本质上是一个工程权衡:用户切换模式时,你希望 Header 跟着变(直觉上合理),但你更不希望 bust 掉 50-70K token 的缓存。所以 Latch 选择了后者------牺牲一点"模式切换的即时响应",换取缓存命中率。
缓存分段机制
Cache 不是整体命中或整体 miss 的。源码中(utils/api.ts:splitSysPromptPrefix()),System Prompt 按 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记拆分成四个语义段,各自有独立的缓存策略:
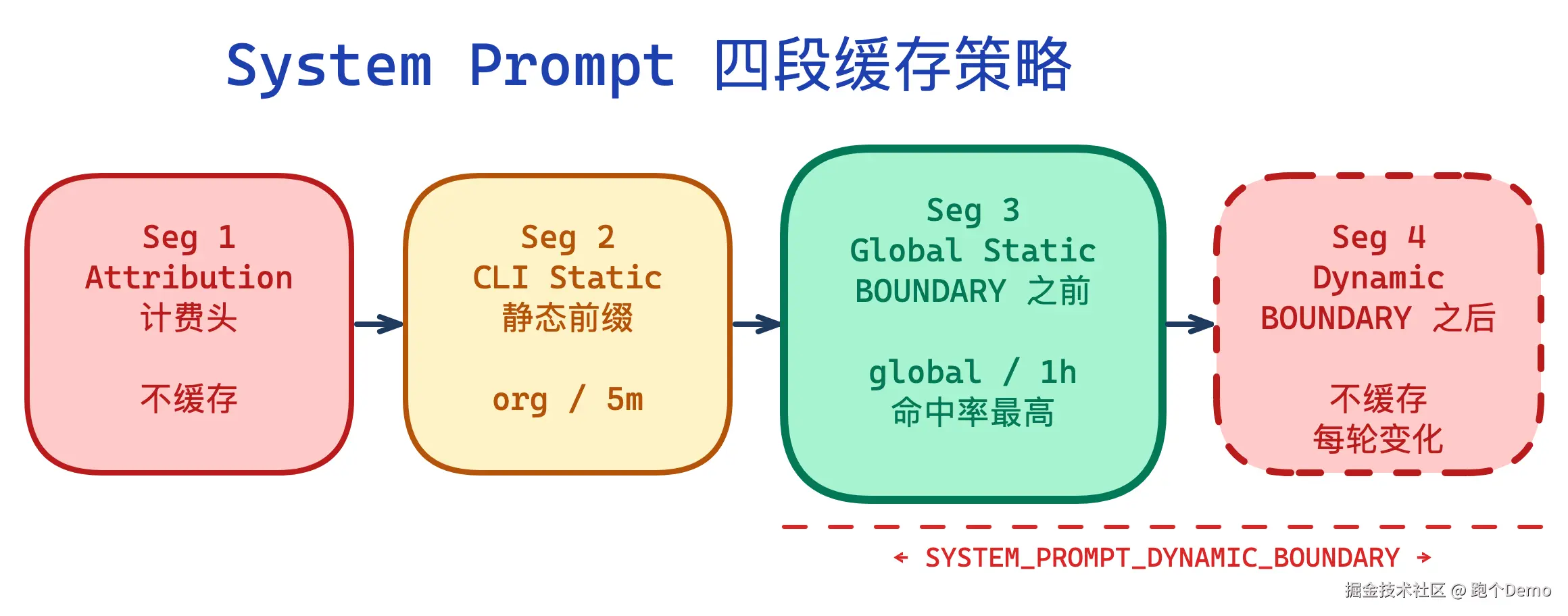
| 段 | 内容 | cacheScope | TTL | 说明 |
|---|---|---|---|---|
| Seg 1 | 计费归属头 | null(不缓存) | --- | 每次请求都不同 |
| Seg 2 | CLI 静态前缀 | org |
5m/1h | 同组织共享 |
| Seg 3 | 全局静态内容(DYNAMIC_BOUNDARY 之前) | global |
1h(符合条件的用户) | 命中率最高的段,包含核心系统指令 |
| Seg 4 | 动态内容(DYNAMIC_BOUNDARY 之后) | null(不缓存) | --- | 每轮变化的部分 |
Seg 2-3 命中时直接复用,总命中约 50-70K token。
此外,源码中有缓存中断检测 (promptCacheBreakDetection.ts):监控 prevCacheReadTokens 和当前值,如果下降超过 5%(最少 2K token),就记录 tengu_prompt_cache_break 事件并归因------帮助开发团队快速定位什么操作导致了缓存失效。
API 指标上,cache_read_input_tokens > 0 表示命中,cache_creation_input_tokens > 0 表示正在写入。
设计哲学
在交互自由度和缓存命中率之间做工程权衡。
Latch 机制不是"技术上做不到",而是"我们选择这样做"。它选择保护缓存,选择把交互自由度让渡给用户体验。
第 3 章:Query Engine --- 会话的"大脑"
状态就绪,命令要交给谁?QueryEngine.ts。
submitMessage():7 步流程
QueryEngine.submitMessage() 是请求进入核心循环前的最后一道关口。它做了 7 件事:
arduino
class QueryEngine {
async *submitMessage(prompt, options): AsyncGenerator<SDKMessage> {
// 1. 构建 system prompt
// 2. 处理用户输入(slash commands、attachments、hooks)
// 3. 写入 transcript(在 API 调用之前!)
// 4. Skills 和 Plugins 加载(cache-only,不阻塞网络)
// 5. yield 系统初始化消息
// 6. 进入核心循环 for await (message of query(...))
// 7. yield 最终 result
}
}文件 45.5 KB,是整个系统的会话管理中枢。

Transcript 先写后调
第 3 步有个值得注意的设计:transcript 在 API 调用之前写入磁盘。
花 4-30ms 写磁盘,这意味着什么?意味着如果进程在 API 调用中途被杀掉(比如用户 Ctrl+C,或者崩溃),下次启动时可以恢复上下文,不用从头开始。
这是典型的容错设计:在还没做任何"大事"之前,先把状态持久化。失败可以恢复,进程被杀可以续上。
Skills 延迟加载闭包
第 4 步的 Skills 加载也有讲究:启动时只解析 frontmatter(YAML 元数据),正文被闭包捕获,调用时才编译。
这意味着如果你有 50 个 Skill,启动时只读 50 个 frontmatter(几 KB),而不是编译 50 个完整文件。真正用到的那个,才会在调用时编译。
AsyncGenerator:边做边返回
submitMessage() 是一个 AsyncGenerator(异步生成器),用 async * 定义,用 for await...of 消费。
它和 Promise 的区别:Promise 只能 resolve 一次,而 AsyncGenerator 可以 yield 多次。这意味着 Claude Code 可以:
- 收到一条消息就 yield 一条(流式 UI)
- 中间被
.return()中断(用户 Ctrl+C) - 消费方处理慢时自动暂停(背压控制)
设计哲学
在做任何"大事"之前,先把状态写到磁盘。
如果不先写 transcript,一个 Ctrl+C 就能丢掉整个对话上下文。如果不延迟加载 Skills,50 个 Skill 的编译时间会堵在启动路径上。Claude Code 的每个"预防措施"都对应一个真实的故障场景。
第 4 章:核心循环 --- while(true) 状态机
Query Engine 把请求打包后,送入了整个系统的心脏:query.ts,约 1730 行。
while(true) 而不是递归
Query Loop 的结构很简单:
arduino
while (true) {
// 1. 上下文准备(五级压缩)
// 2. 检查阻塞限制
// 3. API 调用(流式)
// 4. 工具执行
// 5. 附加消息注入
// 6. 状态打包继续
}你可能会想:为什么不用递归?模型返回 tool_use → 执行工具 → 再调模型 → 再返回......这不是天然的递归吗?
原因有三个:
- 避免栈溢出。如果模型连续返回 50 轮 tool_use,递归调用就 50 层。用 while(true),栈永远是平的。
- State 对象一次打包。所有可变状态收在一个 State 对象里,一轮结束一次赋值。而不是分散在 50 个栈帧里各自维护状态。
- transition 字段记录"继续原因" 。每次循环结束时,
state.transition = { reason: 'next_turn' }。这样测试时可以断言恢复路径,调试时可以知道为什么进入了下一轮。
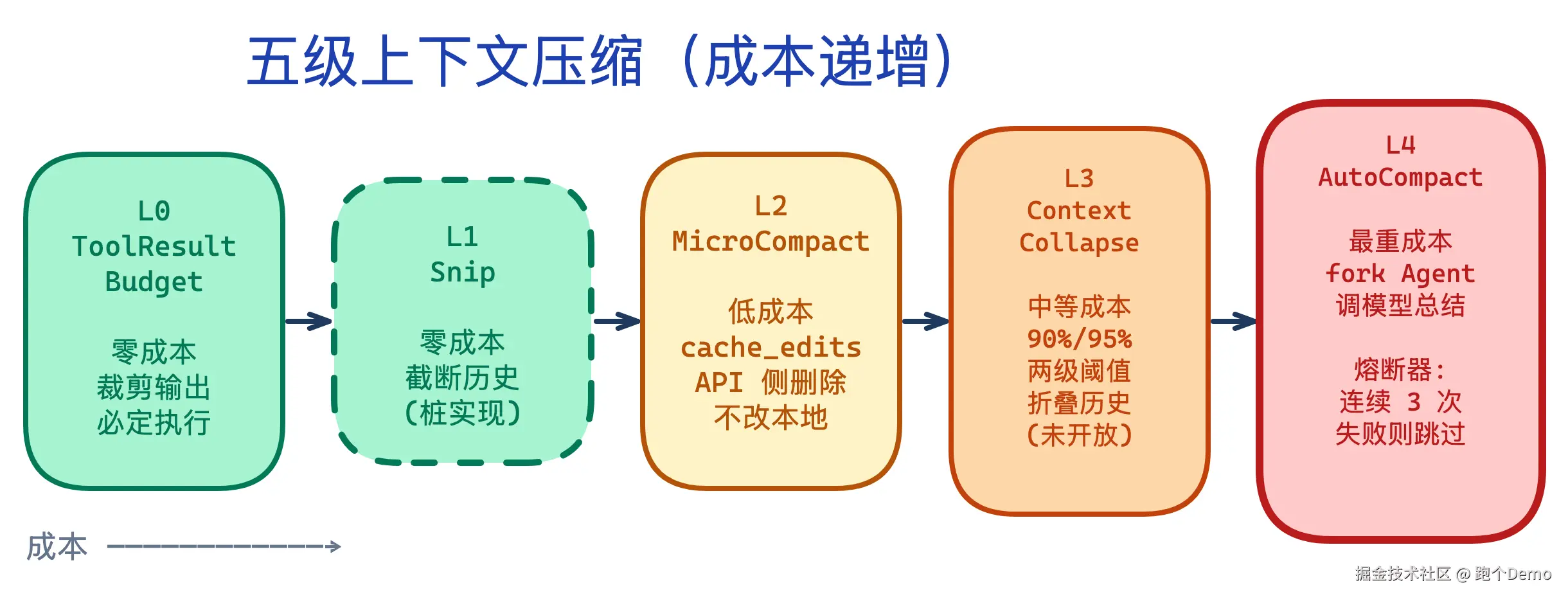
五级上下文压缩
在调 API 之前,Claude Code 要先检查上下文窗口是否快满了。如果满了,它不会直接报错,而是按五级逐步压缩:
| 级别 | 方法 | 触发条件 | 成本 |
|---|---|---|---|
| L0 | ToolResultBudget | 工具返回结果超预算 | 零成本(裁剪工具输出) |
| L1 | Snip | 历史消息超阈值 | 零成本(直接截断) |
| L2 | MicroCompact | 特定工具结果可删除 | 低成本(删除已知安全的消息) |
| L3 | ContextCollapse | 折叠多轮对话 | 中等(合并对话轮次) |
| L4 | AutoCompact | 上下文窗口将耗尽 | 最重(调模型总结) |
下面逐级拆解源码实现。
L0: ToolResultBudget --- 工具输出裁剪
源码 :toolResultStorage.ts:924-936,每轮循环必定执行 (query.ts:379)
当工具返回的结果超过预算时,不是丢弃,而是持久化到磁盘:

| 阈值 | 值 | 来源 |
|---|---|---|
| 单工具上限 | 50,000 chars | toolLimits.ts:13 |
| 单消息上限 | 200,000 chars | toolLimits.ts:49 |
关键设计:超预算的内容不丢失,而是存到磁盘再替换成路径引用。模型后续需要时可以通过 FileRead 再读回来。
L1: Snip --- 历史消息截断
源码 :compact/snipCompact.ts,由 feature flag HISTORY_SNIP 控制
当前版本是一个桩实现 (return { messages, changed: false, tokensFreed: 0 }),框架已搭好但未启用。启用后的行为是:直接移除旧的 assistant 消息块,整块删除而非截断。
L2: MicroCompact --- 缓存级微压缩
源码 :compact/microCompact.ts:253-293
这是五级中最精巧的一层。它不修改本地消息,而是在 API 层面通过 cache_edits 指令删除旧的工具结果。
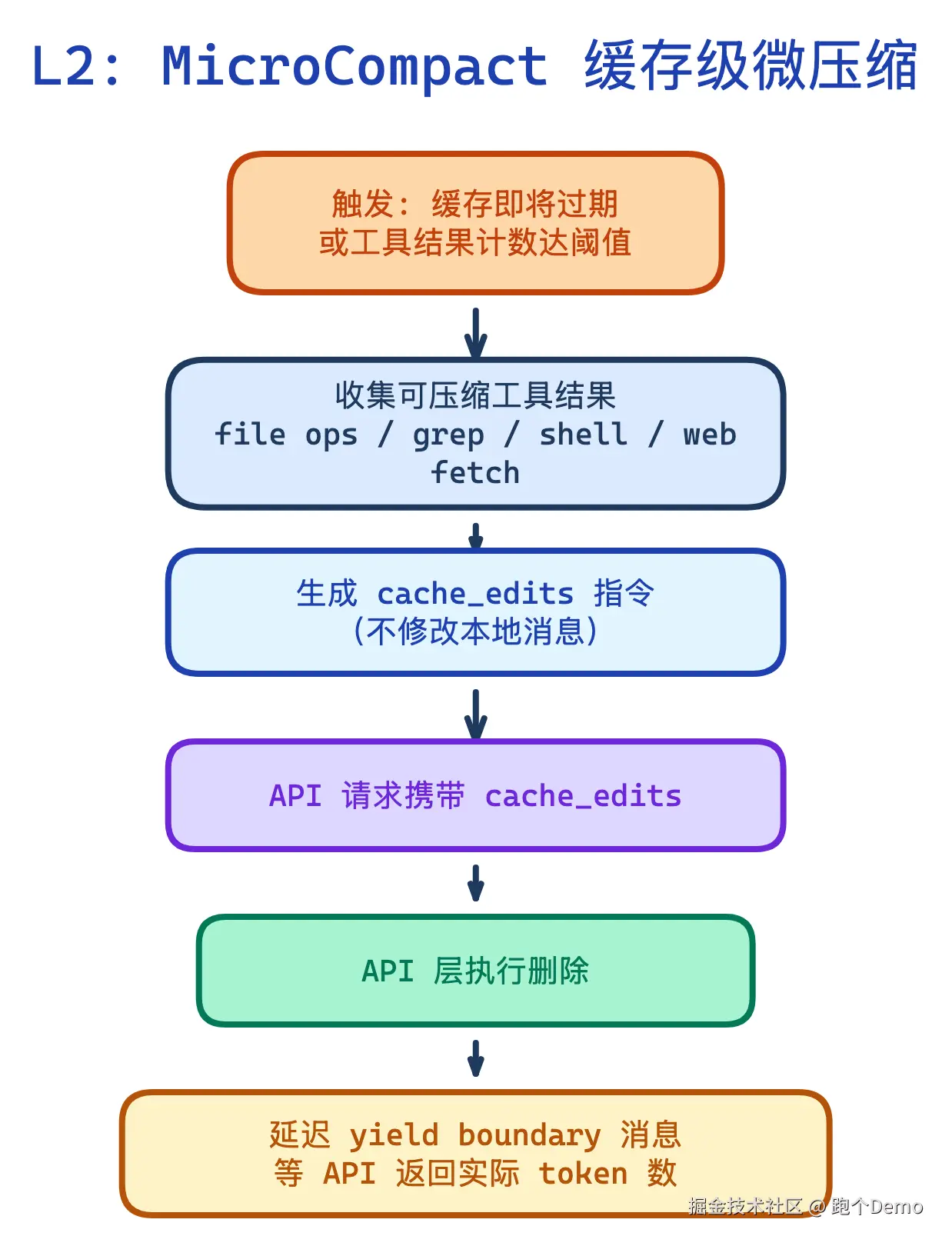
为什么不直接修改本地消息? 因为 cache_edits 是在 API 侧执行的,客户端消息保持完整。这意味着如果 API 调用失败,本地状态不会被破坏------又是容错优先。
L3: ContextCollapse --- 上下文折叠
源码 :contextCollapse/index.ts:32-52
采用两级阈值的渐进式折叠:
| 阈值 | 行为 |
|---|---|
| 上下文窗口 90% | 提交已暂存的折叠段(commit) |
| 上下文窗口 95% | 紧急生成新的折叠段(emergency collapse) |
折叠段是持久化存储 的(独立于消息数组),折叠后的摘要替换原始消息。当遇到 413(prompt-too-long)错误时,优先尝试 recoverFromOverflow() 释放折叠段,比 AutoCompact 便宜得多。
注:当前外部版本
isContextCollapseEnabled()返回false,此功能尚未对外开放。
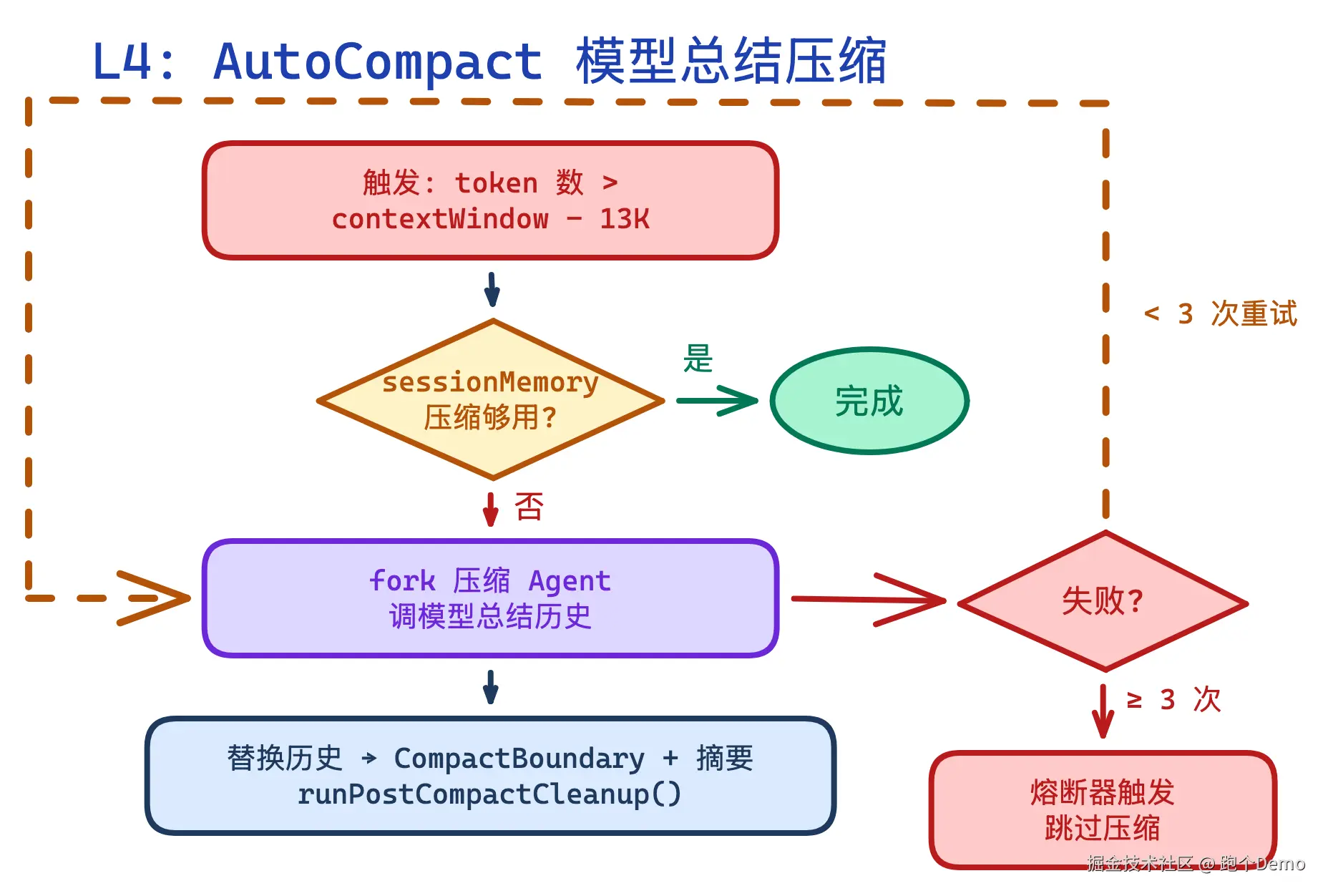
L4: AutoCompact --- 模型总结压缩
源码 :compact/autoCompact.ts:241-351
最后的手段:调用模型来总结对话历史。
| 关键常量 | 值 | 作用 |
|---|---|---|
| AUTOCOMPACT_BUFFER_TOKENS | 13,000 | 触发阈值 = 窗口大小 - 13K |
| WARNING_THRESHOLD_BUFFER_TOKENS | 20,000 | UI 警告阈值 |
| MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES | 3 | 熔断器上限 |
熔断器(circuit breaker)是这层最重要的防御:如果连续 3 次压缩失败,就不再尝试,避免"上下文快满了 → 调模型压缩 → 压缩失败 → 上下文更满 → 再调模型"的死循环。
五级编排总览
query.ts:379-467 中五级策略的执行是严格顺序的,每一级的输出是下一级的输入:
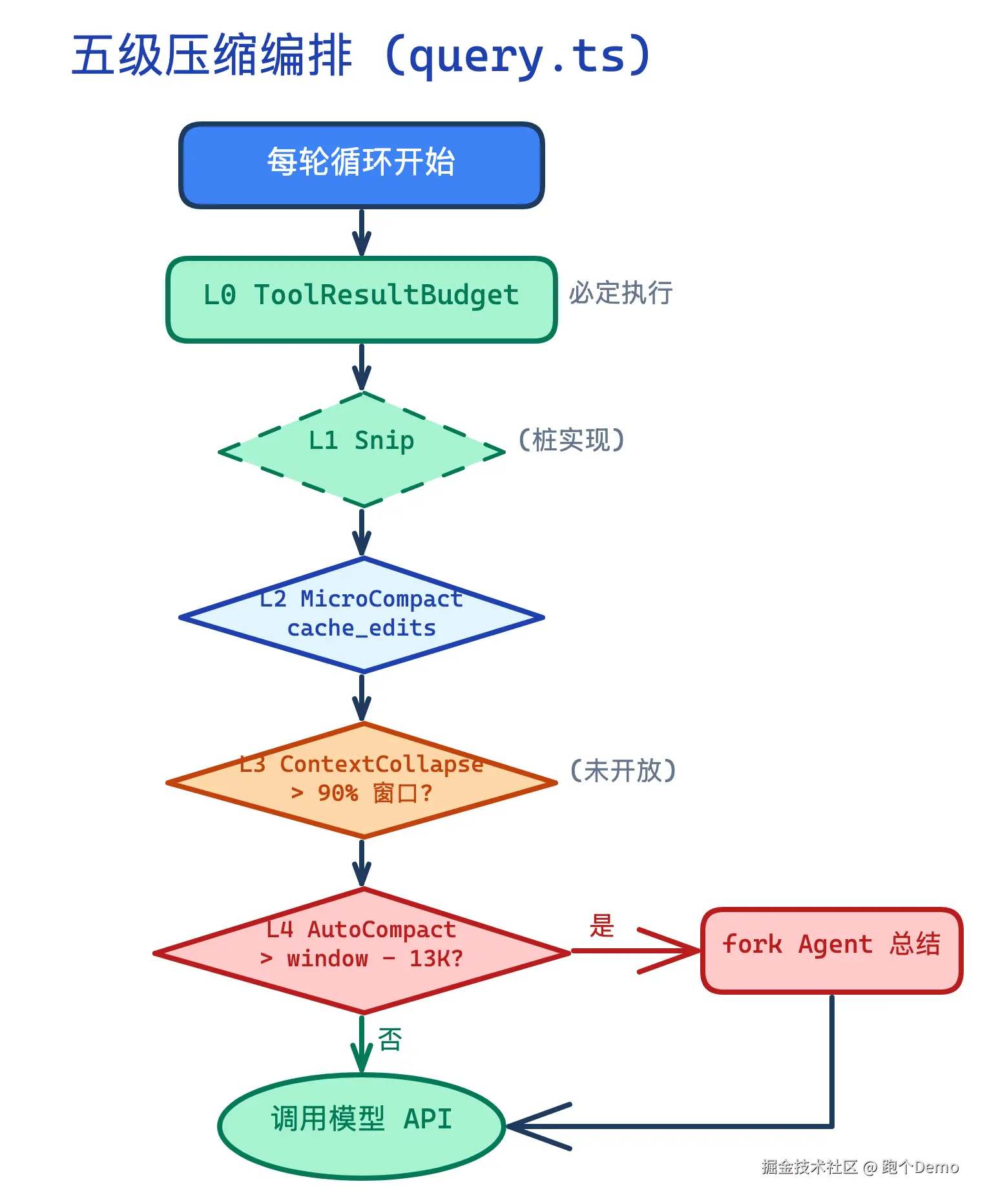
每一级只在前一级不够用时才触发。这种渐进式升级确保了大多数请求只经过 L0(零成本),只有长对话才会触及 L4(最重成本)。
设计哲学
Query Loop 不是函数调用,是状态机;压缩不是一刀切,是五级渐进。
while(true) + State 对象 + transition 字段,这就是一个标准的状态机实现。五级压缩则体现了另一个原则:用最低成本解决问题,只在便宜的方法不够时才升级。Claude Code 没有在每轮都调模型来压缩,而是让 90% 的请求以零成本通过,只有极端情况才动用最贵的手段。
第 5 章:流式调用与工具穿插 --- 性能魔法
进入循环后第一件事:调模型。但 Claude Code 没有"等"。
StreamingToolExecutor:API 还在返回,工具已经开始跑了
大多数人以为的流程是:
调 API → 等完整返回 → 提取 tool_use → 执行工具 → 拿到结果 → 调下一轮实际流程是:
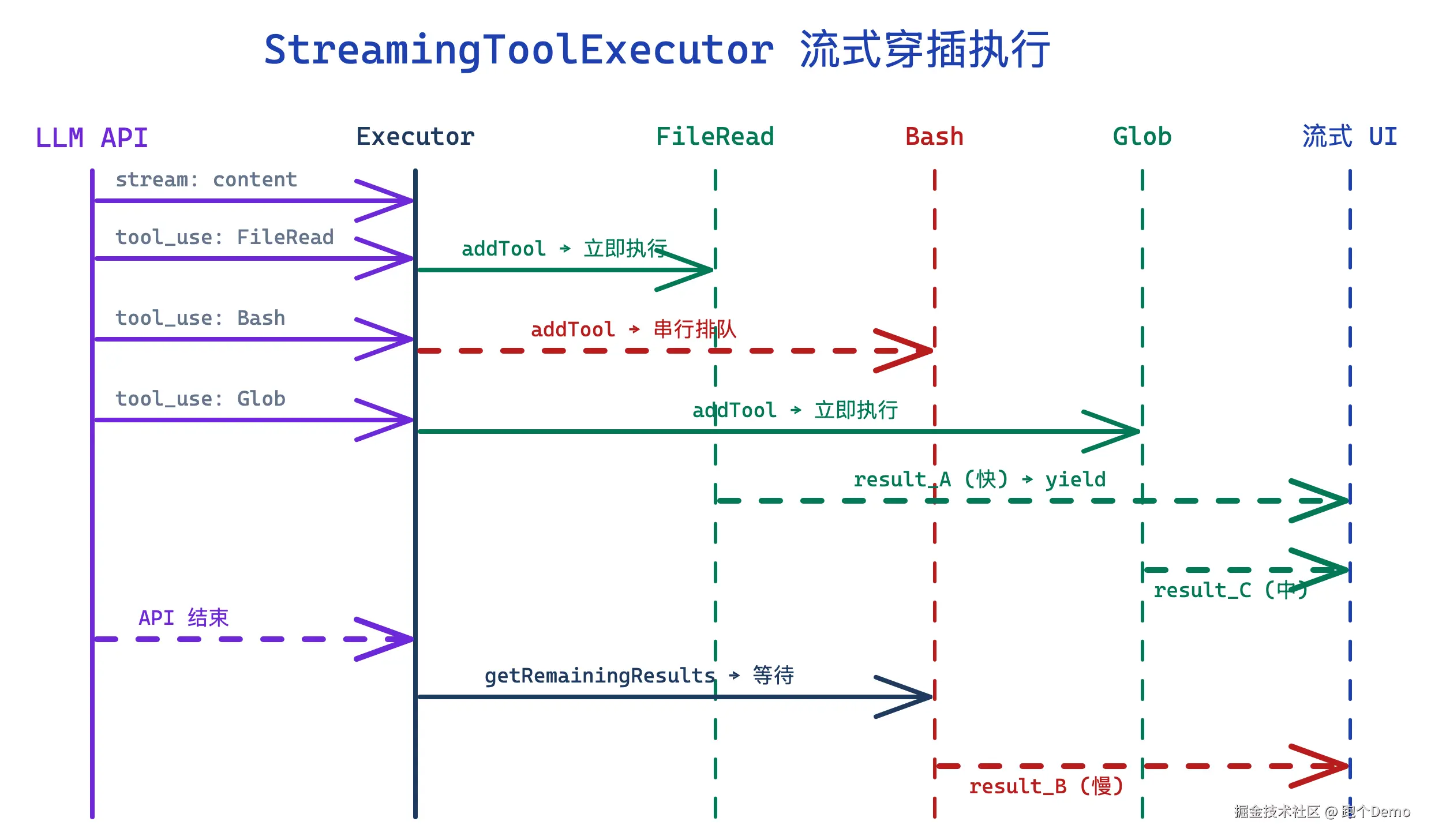
| 方法 | 作用 | 阻塞? |
|---|---|---|
addTool(toolBlock) |
注册工具到执行器 | 否,立即返回 |
getCompletedResults() |
获取已完成的结果 | 否,非阻塞轮询 |
getRemainingResults() |
获取所有剩余结果 | 是,等待完成 |
API 流式返回时,每收到一个 tool_use block 就 addTool() 注册。注册完不等待,工具已经开始跑了。等 API 返回结束后,再 getRemainingResults() 拿到所有剩余结果。
这就是 Claude Code 快的核心原因之一:API 和工具不是串行的,是重叠的。
并发安全三标记
工具能不能并行执行?每个工具定义时有三个安全标记:
vbnet
TOOL_DEFAULTS = {
isConcurrencySafe: false, // 默认不安全
isReadOnly: false, // 默认会写入
isDestructive: false,
}| 工具 | isConcurrencySafe | 行为 |
|---|---|---|
| FileRead | true | 可多个同时读 |
| Glob | true | 可多个同时搜索 |
| Bash | false | 独占,必须串行 |
| FileEdit | false | 独占,避免并发写入 |
只读工具(FileRead、Glob)标记为 isConcurrencySafe: true,可以并行。写入工具(Bash、FileEdit)必须串行。
错误传播:siblingAbortController
如果一个 Bash 命令出错了怎么办?Claude Code 的做法是:取消所有兄弟工具。
arduino
// 一个 Bash 出错
siblingAbortController.abort() // 取消所有并行中的工具这避免了"一个工具失败了,其他工具还在跑,最后拿到一个不一致的状态"。
容错三层恢复
如果 API 返回被截断了怎么办?Claude Code 有三层恢复:
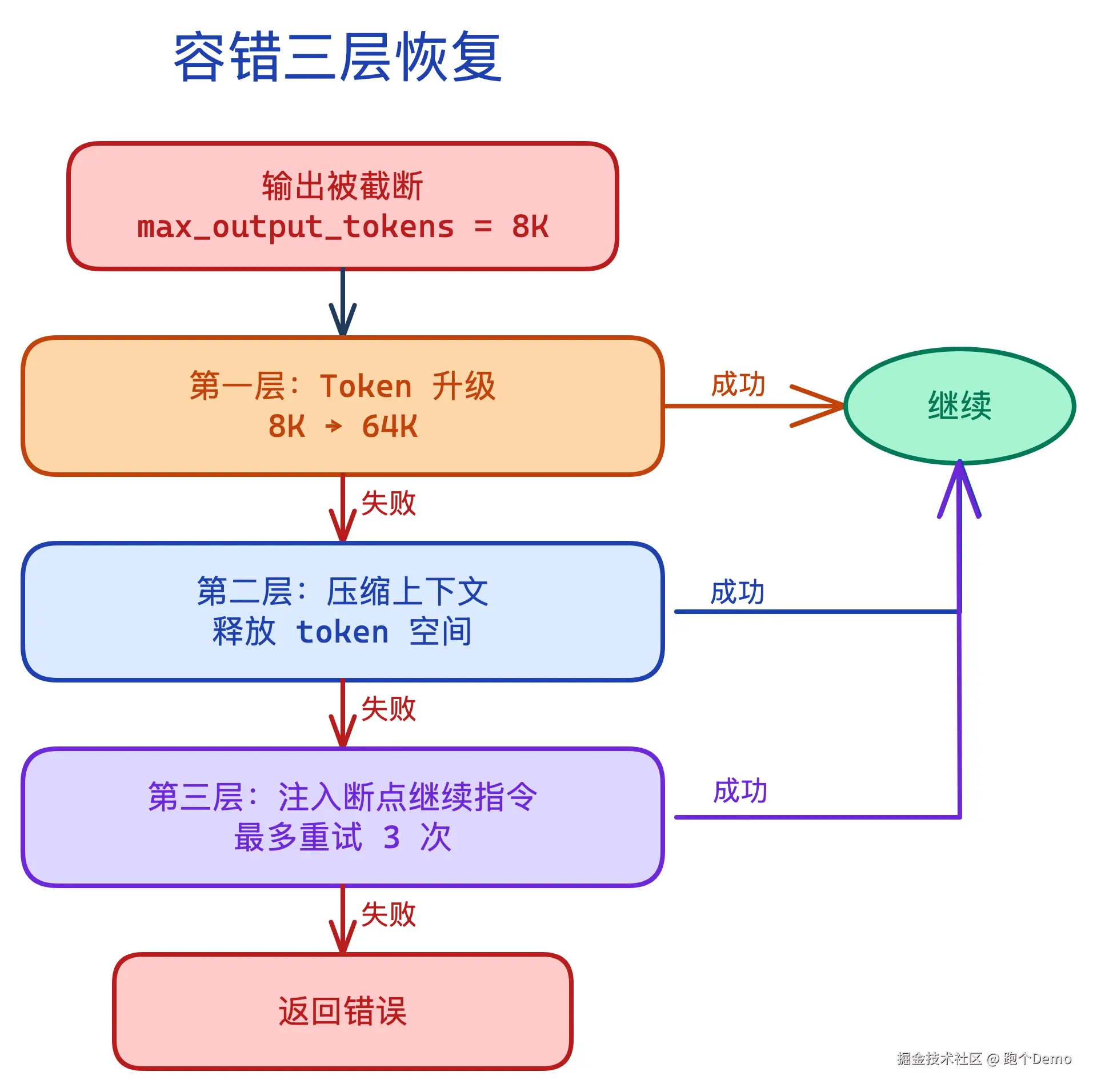
第一层是 token 升级(max_output_tokens 从 8K 升到 64K),第二层是压缩上下文后重试,第三层是注入 meta 消息让模型从断点继续。
设计哲学
能并发的绝不串行,失败路径也是主路径。
StreamingToolExecutor 把 API 和工具执行重叠起来;三层恢复确保 API 截断不是致命错误。Claude Code 假设一切都会失败,并为此做了准备。
第 6 章:权限系统 --- 8 层安全检查链
工具要执行了,Claude Code 要回答一个问题:这个操作安全吗?
大多数 AI 工具的权限处理方式是弹一个框:"这个命令要运行,你确认吗?" Claude Code 不是。它有一套完整的 8 层检查链。
8 层检查
- 工具类型判断:是读操作还是写操作?
- tree-sitter AST 解析 Bash:不是简单的正则匹配,而是用 tree-sitter 把 Bash 命令解析成 AST,理解真正的语义
- 包装器剥离 :
npx xxx、uv run xxx这些命令会被拆开,检查最终执行的真实命令是什么 - 环境变量白名单:不是所有环境变量都能传给子进程
- 路径安全检查:要访问的文件路径是否在允许范围内?
- YOLO Classifier:auto 模式下用独立 LLM 调用判断 allow / deny / ask
- 决策记录(decisionReason) :每个权限决策都有原因记录,可追溯
- 沙箱隔离:高危命令在沙箱中执行
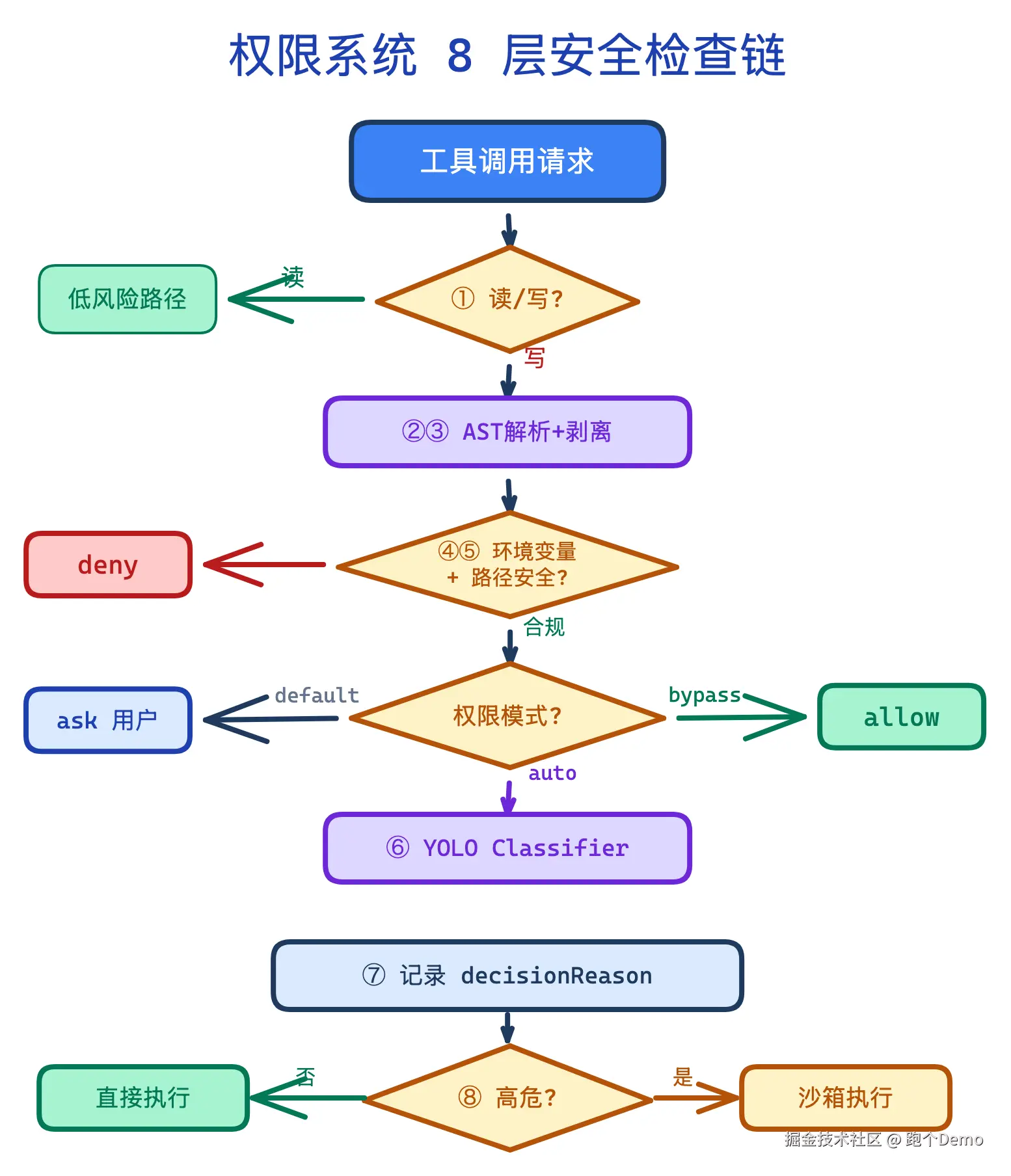
其中第 2 和第 3 层值得多说两句。
tree-sitter AST 解析 意味着 Claude Code 能理解 rm -rf /tmp/foo && cat /etc/passwd 是两个独立操作的组合,而不是当成一个字符串匹配正则。它能识别出 && 连接的命令链。
包装器剥离 意味着 npx create-next-app my-app 不会被当成"npx 是安全的"就放行,而是会被拆开,检查最终执行的是 create-next-app 这个命令。
AFK Mode:YOLO Classifier
用户可以用 Auto Mode(也叫 AFK Mode,Away From Keyboard)让 Claude Code 自动执行命令,不需要每次确认。
但这不是"无脑全放"。AFK Mode 的核心是 YOLO Classifier (yoloClassifier.ts)------一个用单独 LLM 调用 做安全判断的分类器,有专门的 prompt 模板(yolo-classifier-prompts/)。
每次工具调用前,YOLO Classifier 接收完整的工具调用上下文(工具类型、命令内容、路径、环境变量等),返回三种判断:
- 安全 → 自动执行
- 危险 → 仍然需要用户确认
- 不确定 → 询问用户
这不是正则匹配,是一次真正的 LLM 推理。代价是每次 auto 模式下的工具调用都有一次额外的 API 调用,但换来了远比规则引擎灵活的安全判断。
两个容易忽略的防御机制
规则矛盾检测(shadowedRuleDetection) :用户可以在配置中定义权限规则(比如 Bash(git:*) 表示允许所有 git 命令)。但如果用户同时写了 allow Bash(git:*) 和 deny Bash(git push:*),这两条规则是矛盾的。shadowedRuleDetection.ts 会检测这种情况并警告。
拒绝追踪(denialTracking) :如果用户连续拒绝了多次权限请求,Claude Code 会调整行为------不再频繁请求同类权限,避免"疯狂弹框"的体验。这是一个简单但重要的 UX 优化。
权限四级
| 模式 | 行为 | 场景 |
|---|---|---|
| default | 每个命令需用户确认 | 日常交互 |
| auto (AFK) | 分类器判断,安全的自动执行 | 长时间任务 |
| bypass | 全部自动执行 | 隔离环境(如 CI) |
设计哲学
不是弹框,是可解释的执行链。
权限系统不是"弹个框让用户点",而是 8 层检查 + 决策记录 + 分类器判断 + 沙箱隔离的完整执行链。每一步都有据可查,每个决定都有原因。
第 7 章:附加消息 --- 模型看不到的上下文
工具执行完,结果要灌回模型。但不止是工具结果。
Claude Code 每轮还会注入附加消息 (attachment)------这些是系统注入、模型可见,但用户不一定能看到的上下文信息。
5 种附加消息
| 类型 | 作用 | 示例 |
|---|---|---|
| edited_text_file | 文件变更通知 | 用户用 VSCode 改了文件 |
| queued_command | 排队的用户命令 | 用户在 Claude 跑任务时又丢了一个 prompt |
| task-notification | 后台任务完成 | npm install 跑完了 |
| memory | 记忆目录检索 | MEMORY.md 中的备忘 |
| skill_discovery | 动态发现的 Skill | 发现 .claude/skills/ 目录 |
这些消息以 tool_result 的形式注入。模型会看到并响应它们,但它"知道"这些是系统注入的信息。
drain 机制:只消费发给自己的消息
在多 Agent 场景下,有一个重要的机制叫 drain(消费/排空队列)。
less
全局命令队列:
[cmd1: agentId=undefined] ← 主线程 drain
[cmd2: agentId="agent-A"] ← 子 Agent A drain
[cmd3: agentId="agent-B"] ← 子 Agent B drain每个 Agent 只消费发给自己的消息,不碰别人的。子 Agent 只接收 task-notification,即使有人发了 prompt 也忽略------防止用户的 prompt 误入子 Agent。
扩展点的收敛设计:Skill → Command → Tool
这是第 7 章最重要的架构洞察。外部看到的 Skills、MCP、Plugins 是三套不同的生态,但在 Claude Code 内部,它们最终收敛成两种对象。
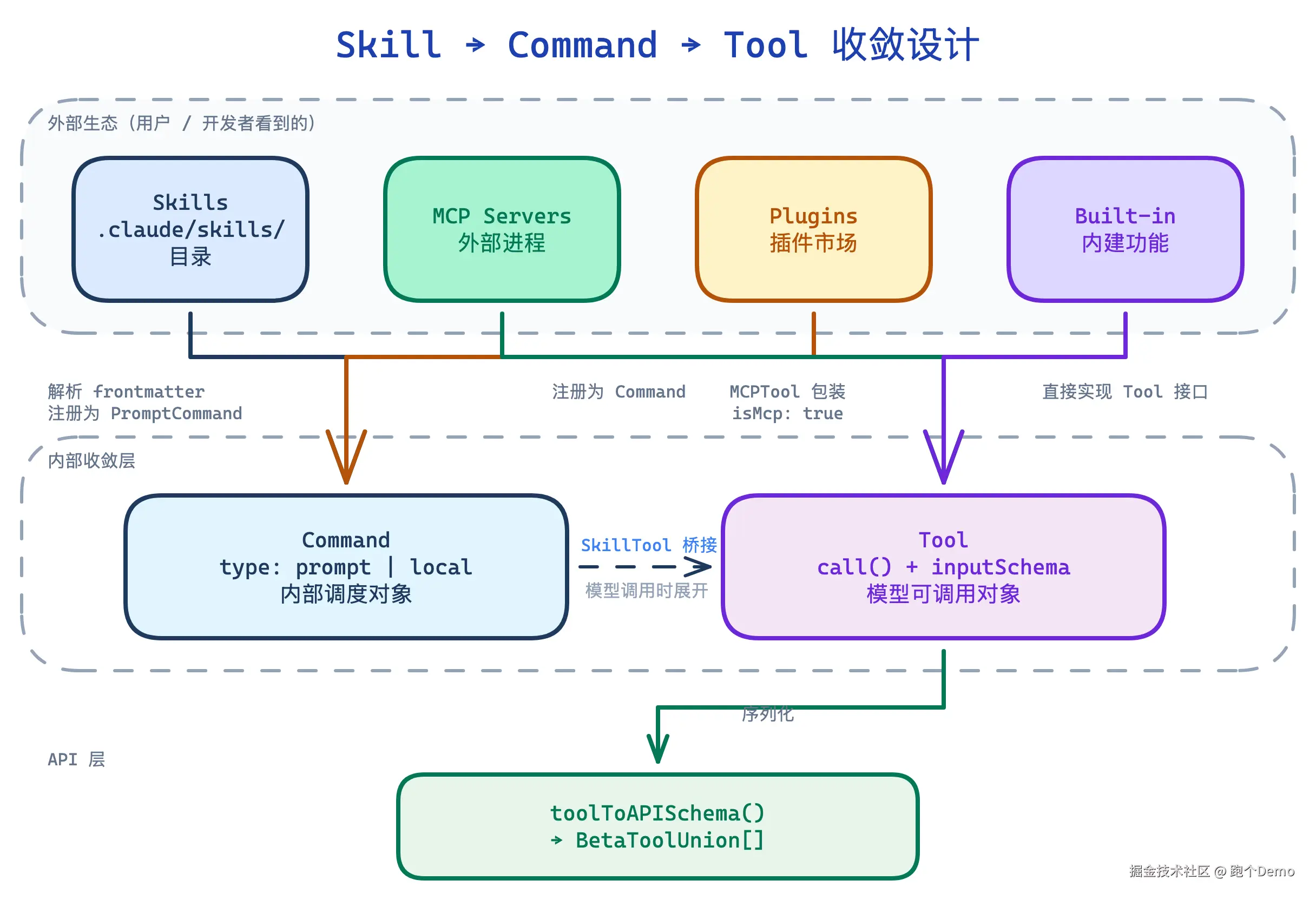
关键路径解析:
Skills 路径 (commands.ts:355-400):Skills 从磁盘加载后,本质上就是 Command (type: prompt,source: skills)。它们不直接变成 Tool,而是通过一个叫 SkillTool 的桥接工具暴露给模型。模型调用 SkillTool({ skill: "commit" }),SkillTool 在运行时查找对应的 Command 并展开执行。
MCP 路径 (services/mcp/client.ts:1743-1850):MCP 工具在运行时从外部服务器拉取定义,直接包装成 MCPTool(实现了 Tool 接口),带上 isMcp: true 标记用于权限检查。
最终序列化 (utils/api.ts:toolToAPISchema()):无论来源是什么,所有 Tool 最终通过 toolToAPISchema() 序列化成 BetaToolUnion[],这就是模型 API 调用时看到的 tools 参数。
为什么 Command 和 Tool 要分开?
| 维度 | Command | Tool |
|---|---|---|
| 面向谁 | CLI / 内部调度 | 模型 API |
| 有 inputSchema? | 否 | 是(JSON Schema) |
| 有 call()? | 否,由调度器执行 | 是,自包含执行逻辑 |
| 有权限检查? | 否 | 是(8 层检查链) |
| 示例 | /compact、/model |
BashTool、FileEditTool、SkillTool |
Command 是人用的(CLI 命令),Tool 是模型用的(API 调用)。SkillTool 是两者之间的桥------它本身是一个 Tool(模型可以调用),但它的作用是执行 Command。
设计哲学
外部热闹(MCP/Skills/Plugins),内部只有两种对象:Command 和 Tool。
理解这个收敛设计后,你就不会被外部生态的复杂性吓到。无论未来出现多少种扩展方式,内部永远只需要维护 Command 和 Tool 两条路径。SkillTool 是桥,toolToAPISchema() 是出口。
第 8 章:多 Agent --- 递归的边界
如果 Claude Code 判断一个任务需要拆分成子任务(比如同时跑测试和改代码),它会启动子 Agent。
但子 Agent 不是你想象中的"开一个新进程"。
子 Agent 的本质:递归调用 query()
经过源码验证(runAgent.ts:748),子 Agent 的本质是:
ini
子 Agent = 递归调用 query() 的 AsyncGenerator 实例它不是新进程,不是新线程,就是同一个进程里的一次递归调用。父 Agent 把自己的 query() 调用栈往下压了一层,创建了一个新的 AsyncGenerator 实例来执行子任务。
6 种子 Agent 类型
Claude Code 定义了 6 种不同类型的子 Agent,对应不同的任务场景(比如独立的代码分析、并行的测试执行、后台的编译任务等)。每种类型有不同的资源限制和权限范围。
Fork Agent:上下文继承 + 输出隔离 + 递归防护
Fork Agent 是一种特殊的子 Agent,它有三个关键特性:
- 上下文继承:子 Agent 继承了父 Agent 的上下文(文件状态、对话历史等)
- 输出隔离:子 Agent 的输出不会直接混入父 Agent 的流,而是通过特定通道返回
- 递归防护:防止无限递归(A 调用 B,B 调用 A,A 调用 B......)
递归防护是重点。如果没有防护,模型可能会陷入"创建一个 Agent 来创建一个 Agent 来创建一个 Agent......"的死循环。
Mailbox 通信:文件系统的 proper-lockfile
父 Agent 和子 Agent 之间怎么通信?不是内存中的消息队列,而是文件系统。
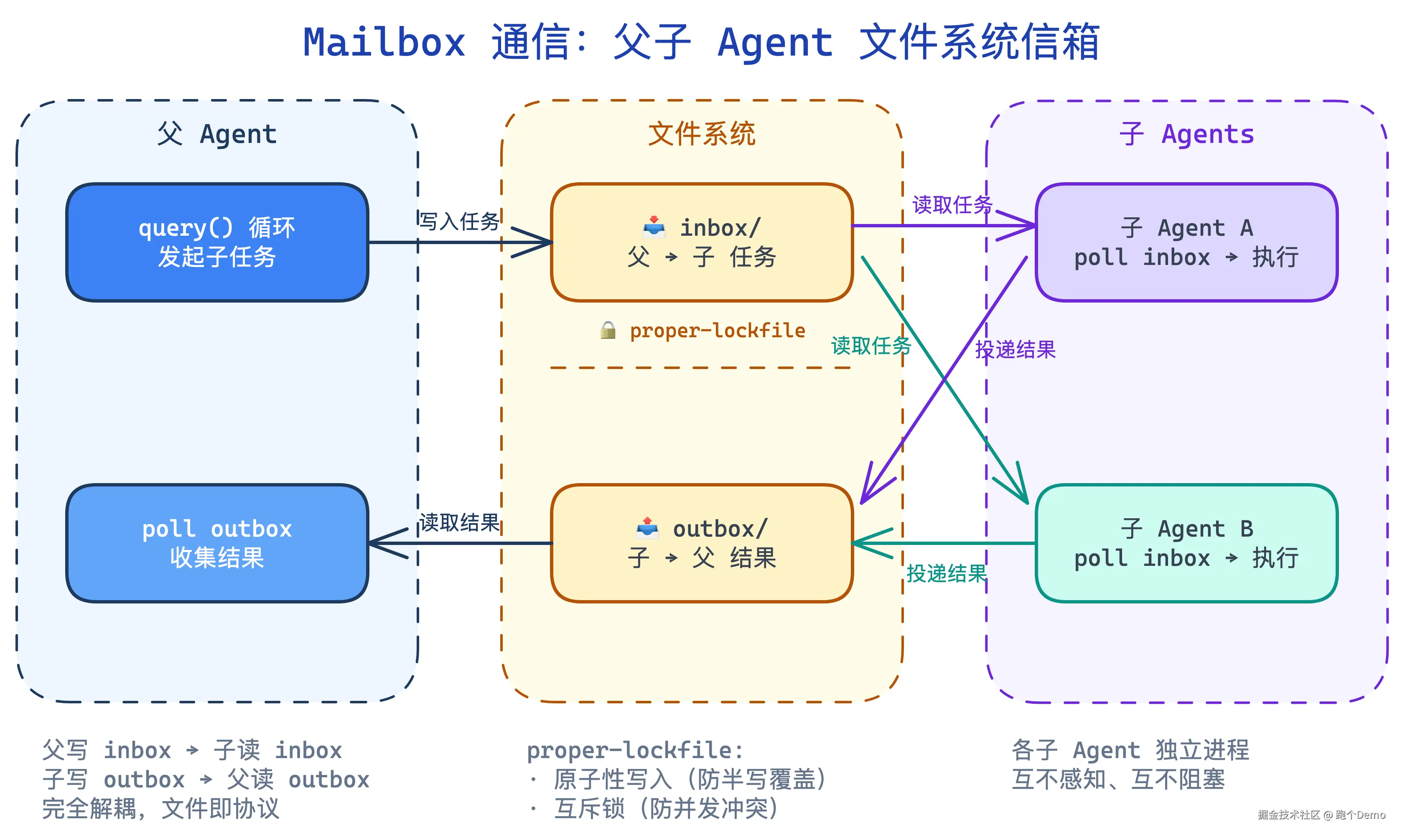
消息以文件形式投递,用 proper-lockfile 防止并发冲突。12+ 种消息类型覆盖了任务通知、权限请求、结果返回等场景。
权限上收
子 Agent 不能直接向用户提问。如果子 Agent 需要用户确认(比如一个危险操作),它必须把请求"上收"到父 Agent,由父 Agent 统一处理。
arduino
子 Agent → 权限请求 → Mailbox → 父 Agent → 用户确认 → Mailbox → 子 Agent这保证了用户只需要和一个"窗口"交互,不会突然出现"第二个 Claude"来问你问题。
Agent Swarm:三种后端
当多个子 Agent 需要并行运行时,Claude Code 支持三种后端:
| 后端 | 方式 | 特点 |
|---|---|---|
| TmuxBackend | tmux split-pane + send-keys | 最隔离,每个子 Agent 一个 pane |
| ITermBackend | macOS iTerm 脚本 | macOS 专用 |
| InProcessBackend | 同进程 AsyncGenerator | 最轻量,无额外进程 |
tmux 方案看似最"笨",但安全性最高------每个子 Agent 运行在独立的终端 pane 里,环境隔离、信号隔离。
横向对比:为什么 Claude Code 选择这种方式?
| 维度 | Claude Code | LangGraph | AutoGen |
|---|---|---|---|
| Agent 本质 | 递归 query(),同进程 | 图节点,编排引擎驱动 | 独立进程/线程 |
| 通信方式 | 文件系统 Mailbox + proper-lockfile | 内存 State 对象传递 | 消息队列传递 |
| 权限模型 | 上收到父 Agent,统一审批 | 无内建权限 | 各 Agent 独立 |
| 上下文共享 | 继承父 Agent 文件状态 | 共享 State graph | 显式消息传递 |
| 隔离方式 | tmux pane / 进程内 AsyncGenerator | 无隔离 | 进程级隔离 |
Claude Code 的选择本质上是把 Agent 当 Task 而不是 Actor。不追求 Agent 的"自主性",而是追求任务的"可控性"。这和 LangGraph 的图编排、AutoGen 的多 Actor 对话是完全不同的设计哲学。
设计哲学
多 Agent = 任务系统,先是 Task,才是智能体。
Claude Code 没有把子 Agent 当成"一个独立的 AI 助手"来设计,而是把它当成"一个递归的任务执行单元"。Mailbox 是任务通信,权限上收是任务审批,tmux 是任务隔离。
先有 Task,再有 Agent。顺序不能反。
第 9 章:三层可观测性 --- 用户看不到的记录
在整个生命周期中,每一步都在被记录。
用户看到的是:
● 读取 3 个文件... ● 运行 bash: npm test... ● 编辑 src/utils.ts...
✔ Done in 12.4s | $0.03
内部记录的是三层独立但互补的可观测体系:
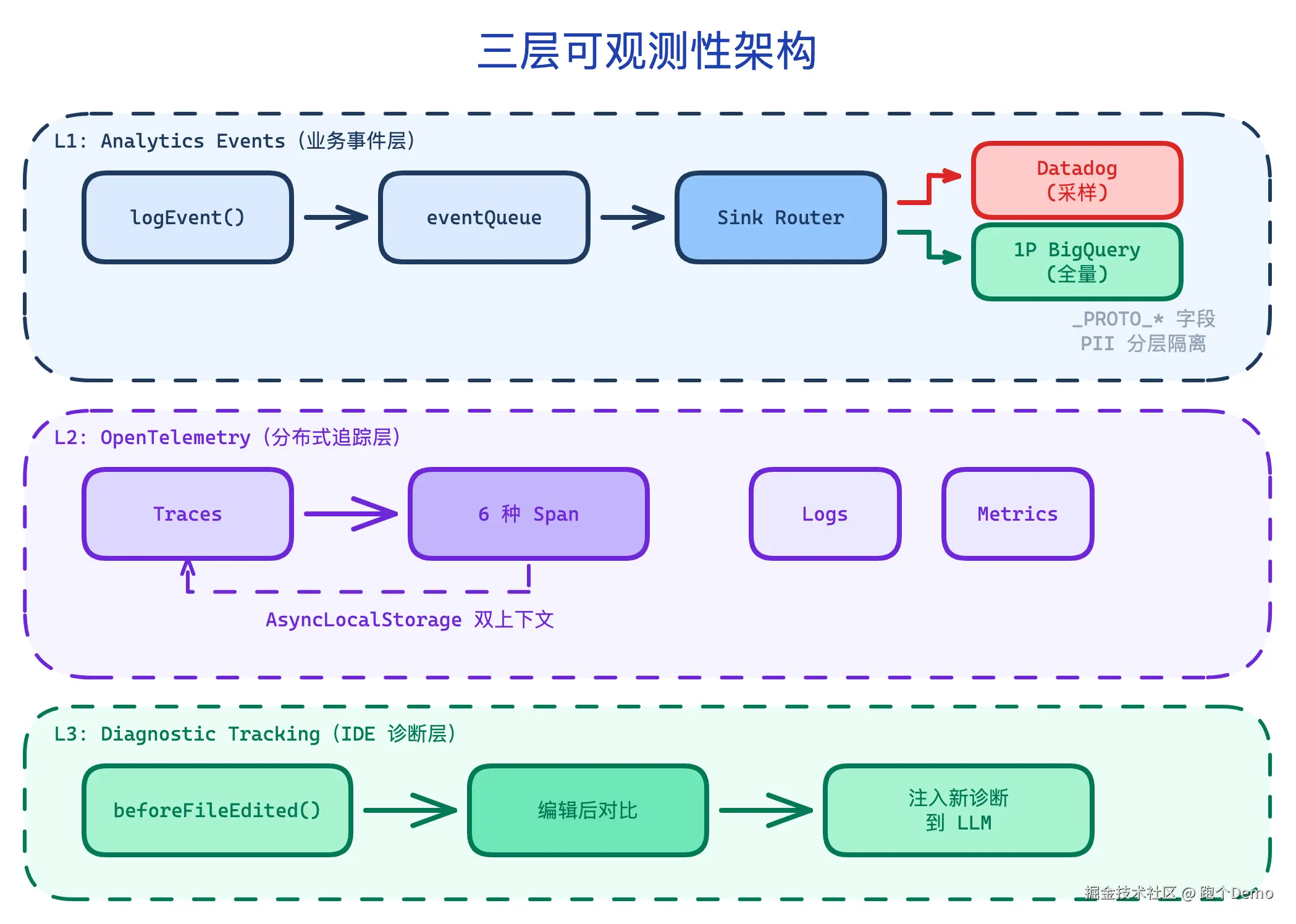
L1 用途:产品分析、用户行为、功能使用率
L1: Analytics Events --- 业务事件层
代码任意位置调用 logEvent("tengu_tool_use", {...}),经过事件队列 + Sink 路由,分别发送到两个后端:
- Datadog :采样后的事件,
_PROTO_*字段被剥离 - 1P BigQuery:完整 payload,包含特权列
_PROTO_* 字段是 PII(个人可识别信息)隔离机制:文件路径、未脱敏数据等只有 1P BQ 的 privileged column 能访问,Datadog 拿不到。
每个事件自动携带的元数据包括:模型、会话 ID、用户类型、环境上下文(平台、架构、Node 版本等)、进程指标(CPU% delta-based、内存)、多 Agent 标识等。
L2: OpenTelemetry --- 分布式追踪层
Claude Code 定义了 6 种 Span:
| Span 类型 | 含义 |
|---|---|
| interaction | 用户请求 → Claude 回复的完整周期 |
| llm_request | 单次 API 调用 |
| tool | 工具注册(权限检查前) |
| tool.blocked_on_user | 等待用户确认权限 |
| tool.execution | 工具实际执行 |
| hook | Hook 执行 |
Span 层级是嵌套的:
css
Interaction Span (root)
├── LLM Request Span
├── Tool Span
│ ├── blocked_on_user
│ ├── execution
│ └── hook
└── ...下一轮交互...Claude Code 使用了两个独立的 AsyncLocalStorage 来管理 span 上下文:interactionContext(交互级)和 toolContext(工具级)。为什么需要两个?因为工具可能有自己的子 span(blocked-on-user、execution),需要独立于交互的上下文。
孤儿 Span 有 30 分钟 TTL 自动清理------setInterval + WeakRef,正常路径立即清理,异常路径 30 分钟兜底。
L3: Diagnostic Tracking --- IDE 诊断反馈
Claude Code 编辑文件后,会自动检查 IDE 的 LSP 诊断:
scss
编辑文件前 → beforeFileEdited() → 获取诊断基线
编辑文件后 → getNewDiagnostics() → 对比基线 → 过滤出新诊断新发现的诊断(比如类型错误、lint 报错)会注入到下一轮 LLM 上下文,让 Claude Code "知道"自己改出了 bug,可以自动修复。
用户看到的 vs 内部记录的
| 用户看到 | 内部记录 |
|---|---|
| 读取 3 个文件 | tengu_session_file_read ×3,含 file_extension、read_method |
| 运行测试 | tengu_tool_use + tengu_tool_use_completed,含 duration_ms、success |
| Auto Mode 切换 | tengu_auto_mode_decision,含 classifier_confidence |
| AutoCompact 触发 | original_message_count、pre/post compact token 数 |
| 模型 fallback | original_model → fallback_model |
设计哲学
用户看到的越少,内部记录的越多------但敏感数据必须分层隔离。
如果三层系统共享同一个数据管道,一个 Datadog 的配置错误就可能泄露文件路径。_PROTO_* 机制的本质是:记录一切,但让不同的消费者只看到自己该看的。
第 10 章:全局设计哲学 --- 一张表看懂 Claude Code
10 个环节走完,最后用一张总表回扣。
| 设计原则 | 一句话概括 | 在哪体现 |
|---|---|---|
| 复杂度前置 | 启动层先定边界,主循环更纯 | 第 1 章:Fast Path、动态 import、并行预取 |
| 状态机心智 | 不是函数调用,是 while-true + 五级压缩 | 第 4 章:Query Loop |
| 工具制度化 | Tool 是带 schema/permission/并发/结果的运行时对象 | 第 5 章:StreamingToolExecutor |
| 权限可解释 | 不是弹框,是 8 层执行链 | 第 6 章:tree-sitter AST、包装器剥离、decisionReason |
| 失败也是主路径 | 三层恢复、fallback model、reactive compact | 第 5 章:容错三层恢复 |
| 外部热闹内部收敛 | 内部只有 Command 和 Tool 两种对象 | 第 7 章:Skill→Command→Tool 收敛设计 |
| 多 Agent = 任务系统 | 递归 query(),先是 Task | 第 8 章:Mailbox、权限上收 |
| 分层可观测 | 三套独立系统 | 第 9 章:Analytics / OTEL / Diagnostic |
把这些设计原则串起来,你会发现 Claude Code 的工程哲学可以浓缩成一句话:
假设一切都会失败,但让失败变得可恢复、可追踪、可解释。
Transcript 先写后调(可恢复)、三层容错(可恢复)、transition 字段(可追踪)、decisionReason(可解释)、三层可观测(可追踪)------每一层都在为失败做准备。
这不是因为 Claude Code 的代码质量差,而是因为它面对的是一个本质上不可靠的系统:LLM API 可能超时、可能截断、可能返回无效内容、可能产生有害命令。在这样的环境下,"假设一切正常"才是最危险的设计。
第 11 章:带走什么 --- 可复用的工程 Pattern
读完 10 个环节,回到一个实际问题:如果你自己要做一个 LLM 驱动的工具,能从 Claude Code 里偷到什么?
Pattern 1:Sticky-on Latch --- 保护缓存的通用范式
Sticky-on Latch 不只适用于 Prompt Cache。任何带缓存的系统都有类似问题:用户操作改变了缓存 Key,导致缓存失效。
通用做法:把影响缓存 Key 的参数锁定(Latch),只在显式重置点(如 /clear)才释放。适用于 CDN 缓存策略、数据库查询缓存、前端状态管理等场景。
Pattern 2:while(true) 状态机 --- 对比递归的工程优势
很多 Agent 框架(如早期 LangChain)用递归实现 tool-use 循环:模型返回 tool_use → 执行工具 → 递归调用自己。Claude Code 用 while(true) + State 对象 + transition 字段。
| 维度 | 递归 | while(true) 状态机 |
|---|---|---|
| 栈深度 | 随轮次增长 | 恒定 |
| 状态管理 | 分散在栈帧 | 集中在 State 对象 |
| 可测试性 | 难以断言中间状态 | transition 字段可断言 |
| 调试 | 50 层调用栈 | 一层循环 + 日志 |
如果你的 Agent 循环可能超过 10 轮,while(true) 几乎总是更好的选择。
Pattern 3:流式穿插执行 --- 通用 Pipeline 优化
"API 还在返回,工具已经开始跑"这个思路可以泛化为:在 pipeline 的任意两个阶段之间,只要数据依赖允许,就重叠执行。
这和 CPU 流水线(instruction pipelining)是同一个思想。适用于任何有多阶段处理的系统:ETL pipeline、CI/CD、甚至前端渲染流程。
Pattern 4:权限上收 --- 多 Agent 系统的 UX 原则
子 Agent 不能直接向用户提问------这不只是技术约束,更是 UX 原则:用户只应该和一个"窗口"交互。
如果你在做多 Agent 系统,无论技术上 Agent 有多独立,对用户来说它应该是一个统一的界面。所有需要用户决策的请求都上收到一个控制点。