同样的数据,放在不同的系统里,成本可以相差数倍。这是我们的用户完成 Google Spanner 到 StarRocks 迁移后的真实结果,分析成本直接降低了 70%--80%。
这一差距主要是因为 Spanner 是为事务设计的,计费模型也围绕事务场景构建。当分析负载逐渐堆积在上面时,不仅查询慢,资源利用率低,成本更是不断攀升。而 StarRocks 面向实时分析场景,从架构、性能到成本都更适合承载分析查询业务。
本文将介绍如何实现 Google Spanner 到 StarRocks 的数据迁移同步,让数据库架构更合理,同时有效控制成本。
Google Spanner 的局限
Google Spanner 是一款全球分布式关系型数据库,在强一致性、跨区域事务和高可用性方面有着成熟的应用。对于金融交易、订单系统、多区域数据一致性等核心业务场景,Spanner 都是非常可靠的选择。
但当分析查询开始大量集中到 Spanner 上时,它的局限性也逐渐显现。
在技术层面,Spanner 的设计目标是 OLTP。它采用行式存储,并围绕分布式事务做了大量优化,这些能力在事务写入场景中非常高效,但在大规模扫描、宽表聚合或复杂 Join 等分析型操作上并没有优势。在报表类 SQL 场景中,常常需要等待几十秒,甚至可能出现超时。
成本问题则更突出。Spanner 按处理单元(Processing Unit)持续计费,1 个节点约 6.2 元/小时。即使没有查询,计算资源仍然产生费用。在分析高峰期,为了避免查询变慢甚至影响线上事务,通常需要提前扩容节点。而在低峰期,这些扩容节点大多处于闲置状态,但费用却在不断累积。
举个例子,假设数据规模在 2TB 左右,部署 3 个节点用于分析负载,仅基础成本每月就接近 17000 元(计算约 13000 元,存储约 4000 元)。一旦分析查询增多,节点数通常需要扩展到 5--6 个,每月成本很容易超过 27000 元。
核心问题在于,Spanner 并不是为分析而设计的系统。 把分析负载运行在上面,既跑不快,成本又高。
为什么同步数据到 StarRocks
为了提高分析性能,控制成本,很多团队开始选择把数据同步到 StarRocks。StarRocks 是面向实时分析的云原生高性能 OLAP 数据库,在这一场景下可以帮助团队极大地降本增效:
- 查询性能:StarRocks 采用列式存储与向量化执行引擎,在聚合分析、宽表扫描场景下性能表现突出,与 Spanner 相比,同类分析查询通常有数十倍的提升。
- 分析成本 :StarRocks 支持存储计算分离架构,冷数据可以落到对象存储(如 GCS 或 S3)。计算节点可以按需使用,避免为闲置容量持续付费。整体成本相比 Spanner 可以降低约70%-80%。
通过把数据从 Spanner 同步到 StarRocks,将事务层与分析层解耦,Spanner 继续承载核心交易业务,StarRocks 专注分析查询,性能更强,也更省钱。
数据同步方案选型
明确目标之后,关键问题在于如何将 Spanner 中的数据同步到 StarRocks。
常见方案其实并不少,但实现方式和复杂度差异很大。
定时导出 + 导入
这是最直接的一种方式,通过定时任务做数据导出,比如将 Spanner 数据周期性导出到对象存储(如 GCS),再导入到 StarRocks。
这种方式实现简单,但数据延迟较高,更适合离线分析或一次性迁移。
Dataflow 方案
借助 Dataflow 订阅 Spanner Change Streams,并将处理结果写入 StarRocks。
这种方式技术上可行,但开发周期长,而且 Dataflow 本身也在 GCP 计费,并不能达到降本的目的。
自建 CDC 链路
也可以基于 Google Spanner 的 Change Streams,自己实现一套 CDC(Change Data Capture)链路。通常做法是从 Spanner 拉取变更日志,解析成标准事件,再通过自建程序写入 StarRocks。
这种方式灵活性高,但也意味着你需要从头搭建一套系统,处理数据顺序、事务一致性、断点续传等各种问题。
上面这些方案都有一个共同点:需要团队自己开发,落地成本和运维成本都较高。
如果希望开箱即用、减少自研投入,也可以考虑产品化的数据同步平台,比如 CloudCanal。
CloudCanal 最近支持了 Spanner 源端的数据迁移同步能力,是目前少数原生支持 Google Spanner 作为数据源的数据同步平台。在 CloudCanal,全量迁移和 CDC 增量同步集成在同一个数据链路里,系统内置类型映射与数据处理能力,全程可视化操作、可观测、可管理,完全不需要写代码。
整体数据链路如下:

在常规业务写入量下,同步延迟通常可以稳定在 3 秒内,满足绝大多数分析场景对数据实时性的要求。
实操演示
接下来,我们将演示如何在几分钟内,搭建出一条 Spanner 到 StarRocks 的实时链路。
步骤 1:安装 CloudCanal
进入 CloudCanal 官网,点击 免费社区版。
参考 全新安装(Docker),安装 CloudCanal 私有部署版本。
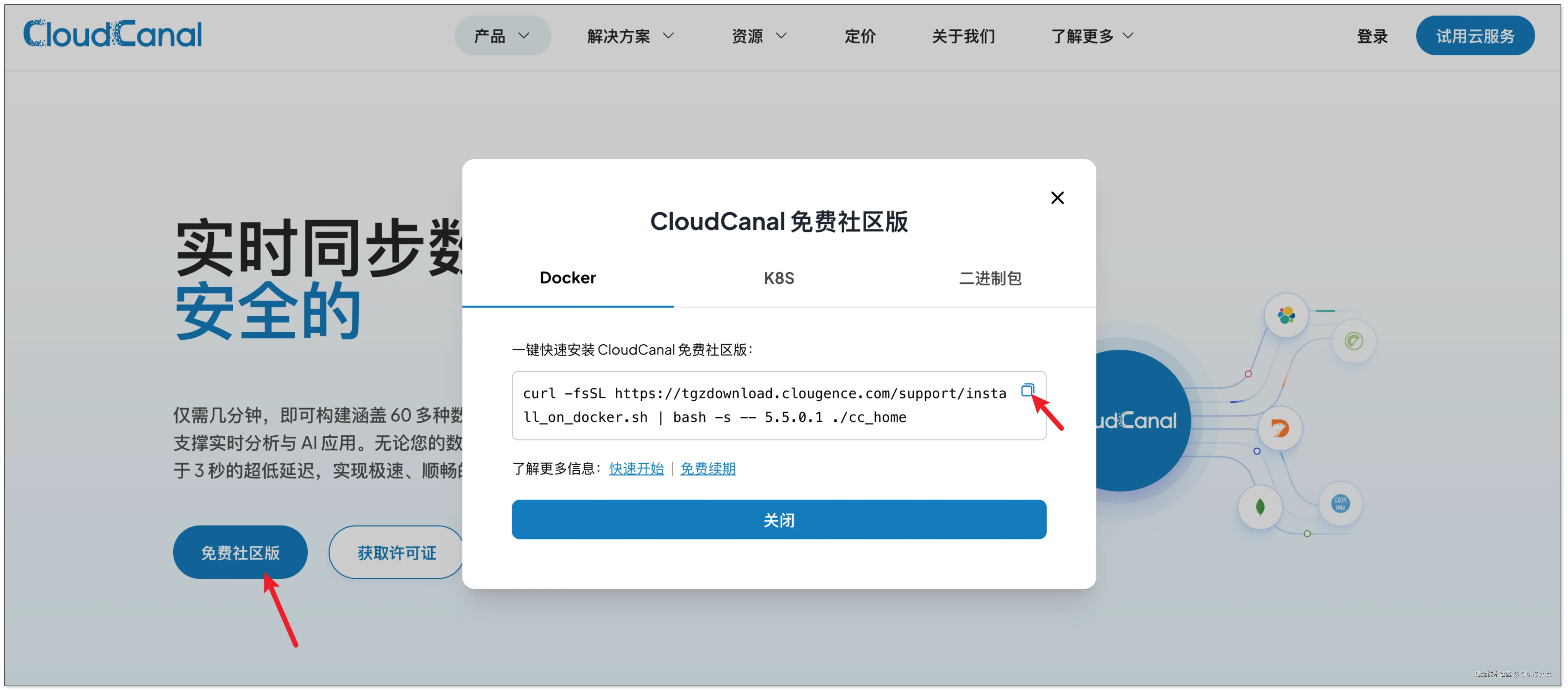
安装完成后,用默认账号(test@clougence.com / clougence2021)登录控制台。
步骤 2:添加数据源
点击 数据源管理 > 新增数据源,填写以下信息,分别添加 Google Spanner 和 StarRocks。
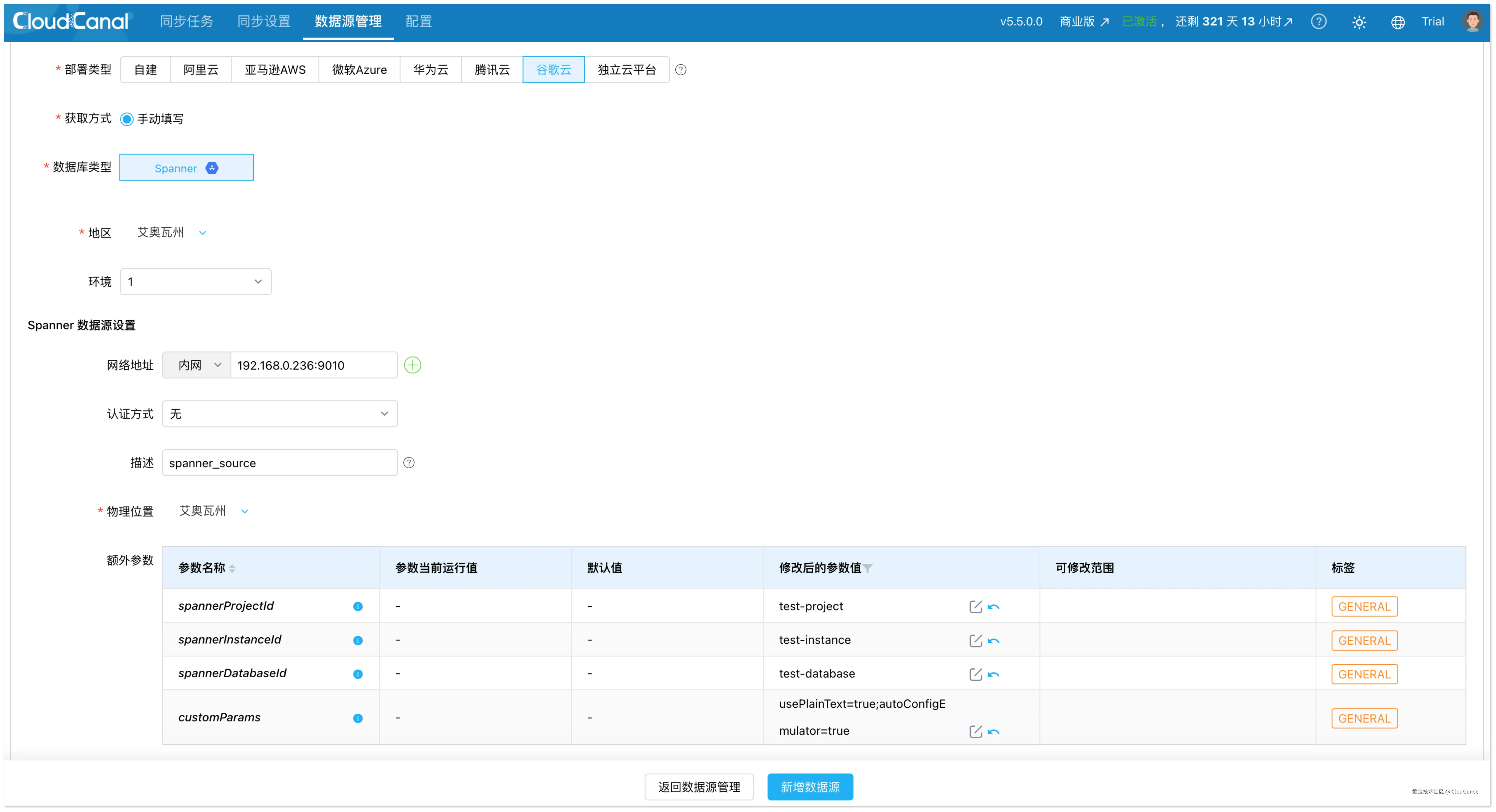
添加 Google Spanner
- 部署类型:谷歌云
- 数据库类型:Spanner
- 网络地址:填写连接 Spanner 实例的 IP 和 host
- 认证方式:选择合适的认证方式
修改以下额外参数:
- spannerProjectId:修改为 Google Cloud 项目 ID
- spannerInstanceId:修改为 Spanner 实例 ID
- spannerDatabaseId:修改为 Spanner 数据库 ID
- customParams:修改为 Spanner 连接自定义 JDBC 参数
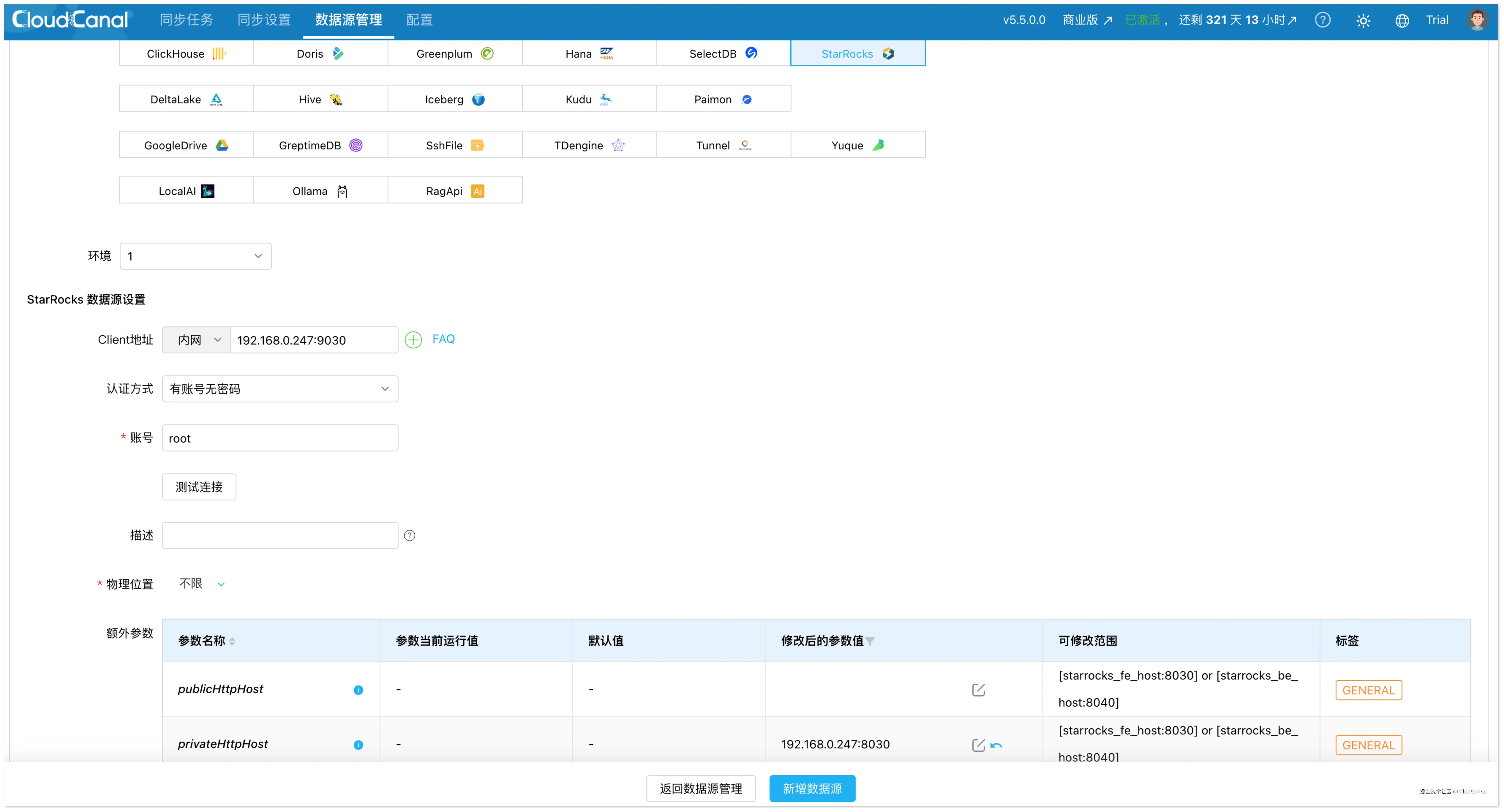
添加 StarRocks
- 部署类型:自建
- 数据库类型:StarRocks
- Client 地址:填写连接 StarRocks 实例的 IP 和 host
- 认证方式:选择合适的认证方式
修改以下额外参数:
- privateHttpHost:修改为 FE/BE 节点的 IP 和 host
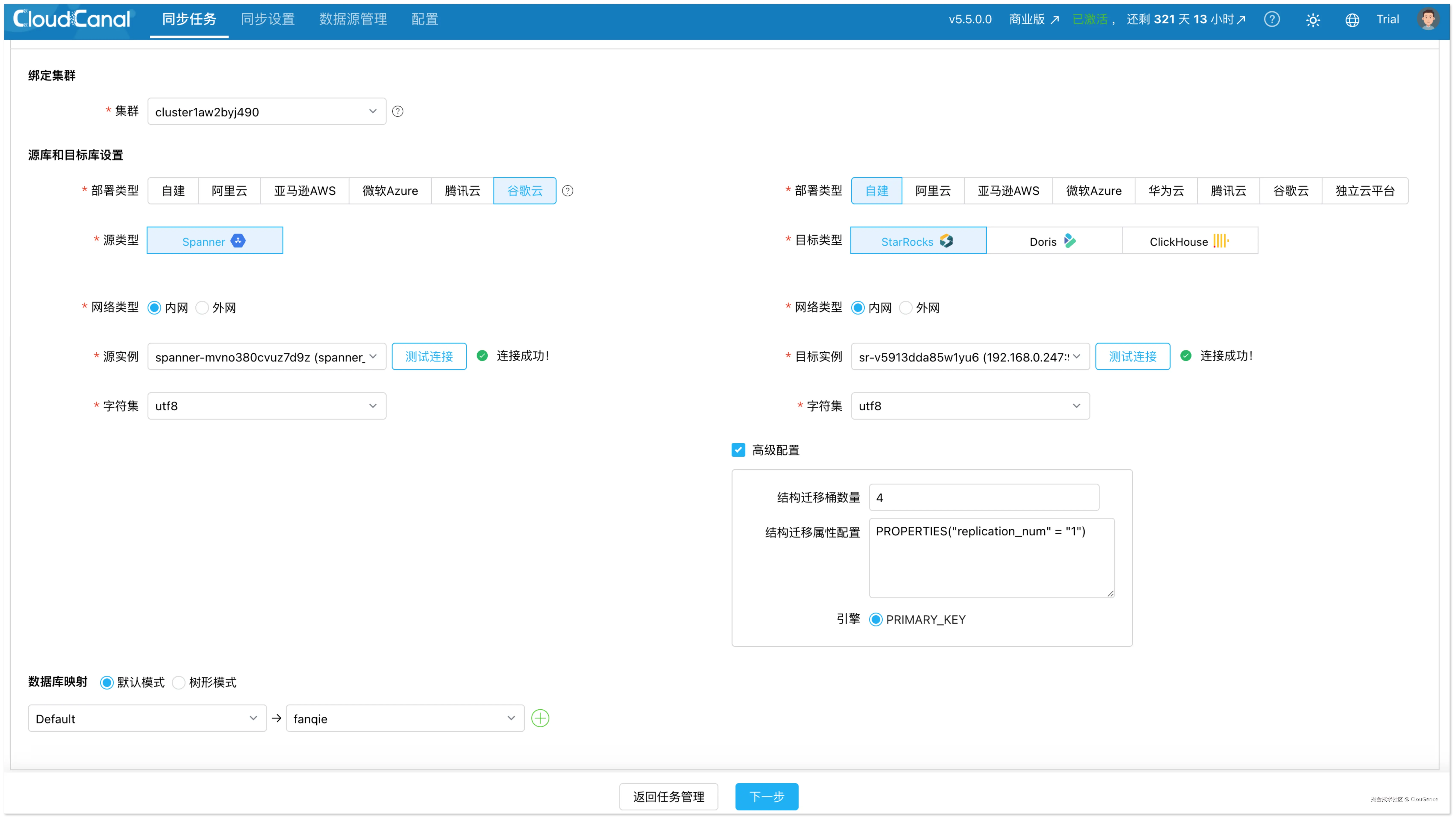
步骤 3:创建链路
点击 同步任务 > 创建任务,进入任务创建流程。
选择源端和目标端数据源,点击 测试连接。
在功能配置页面,任务类型 选择 增量同步 ,并勾选 全量初始化。
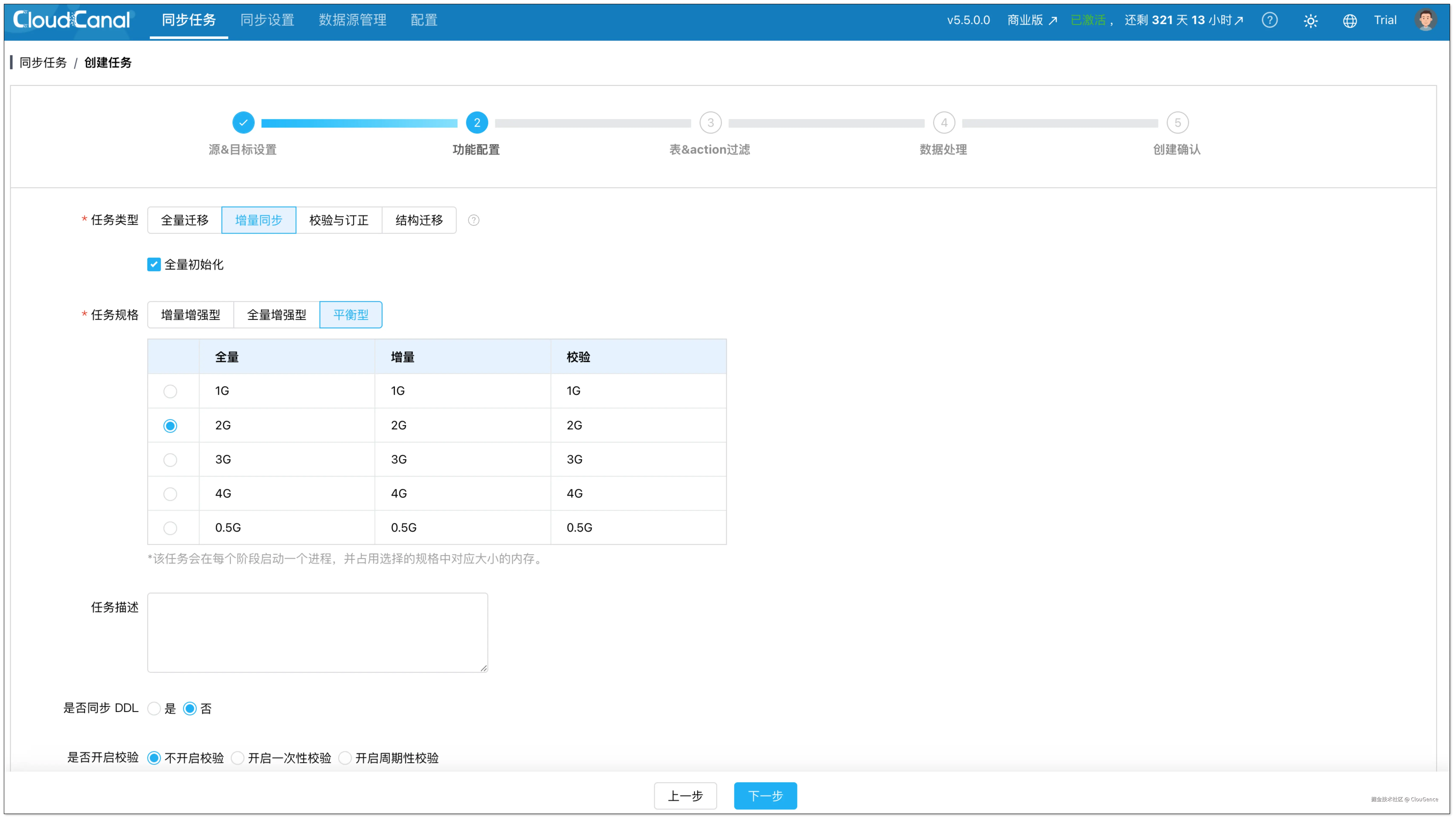
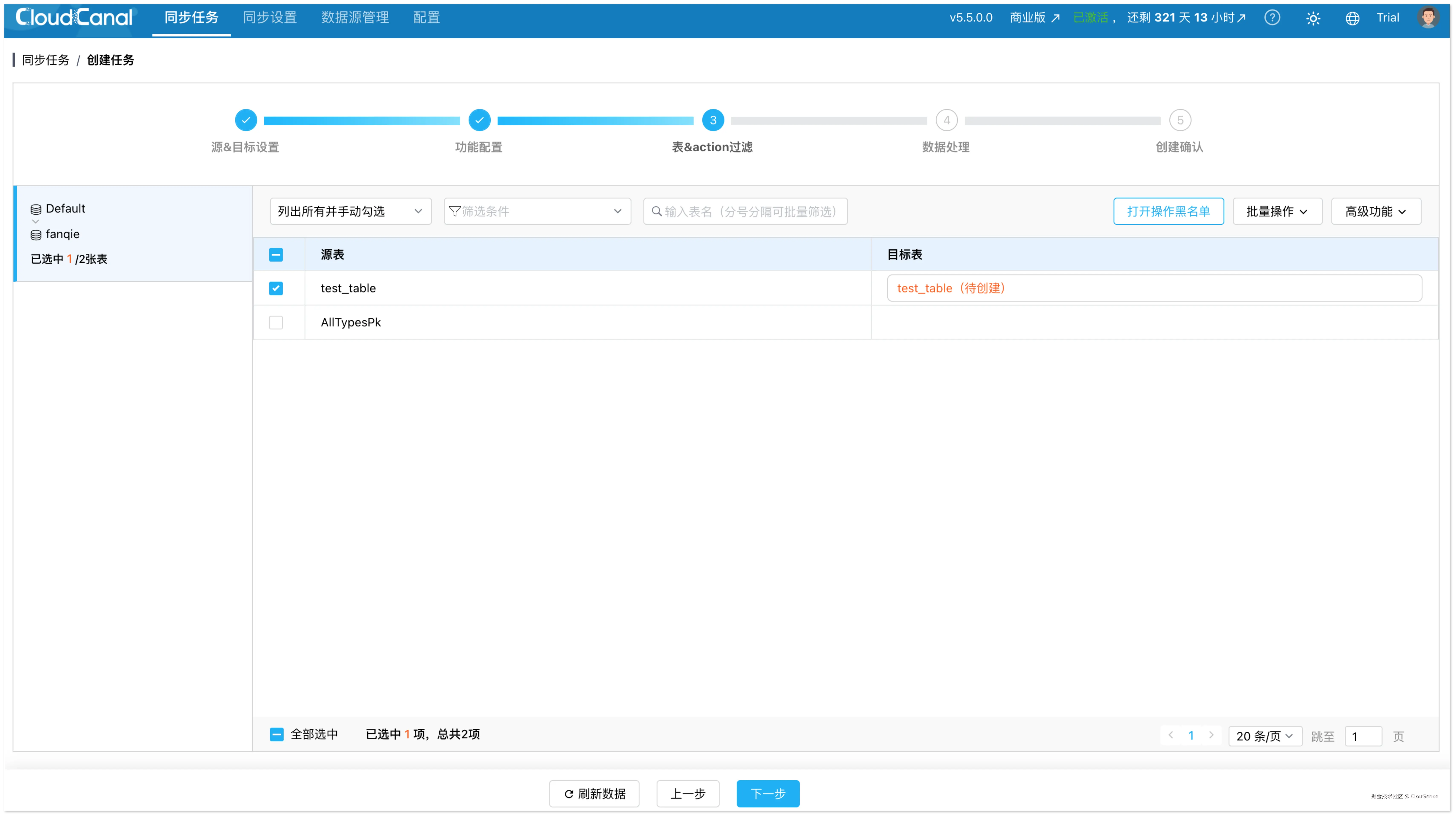
在表 & action 过滤页面,勾选要迁移的表。
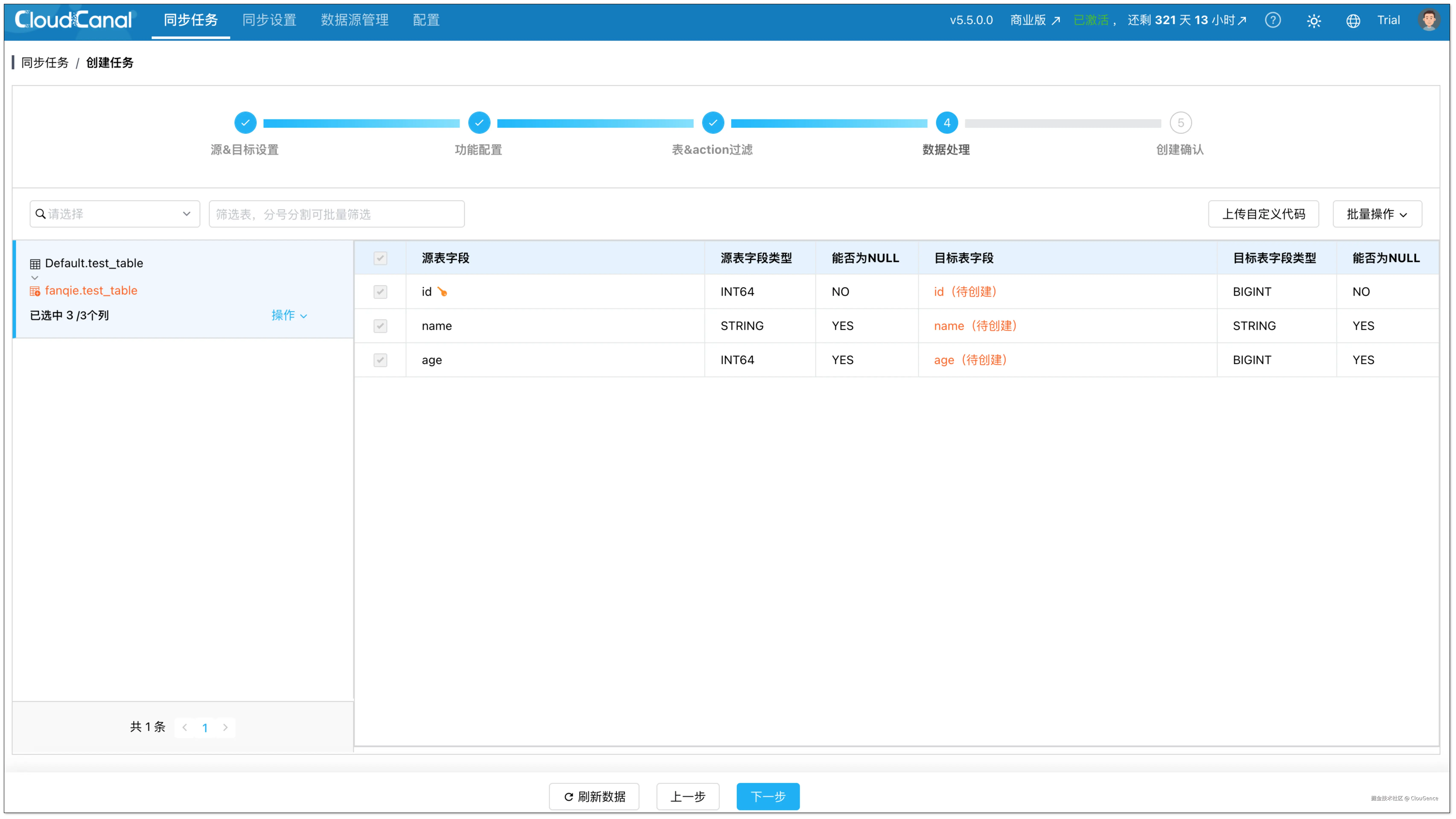
在数据处理页面,勾选要迁移的列。
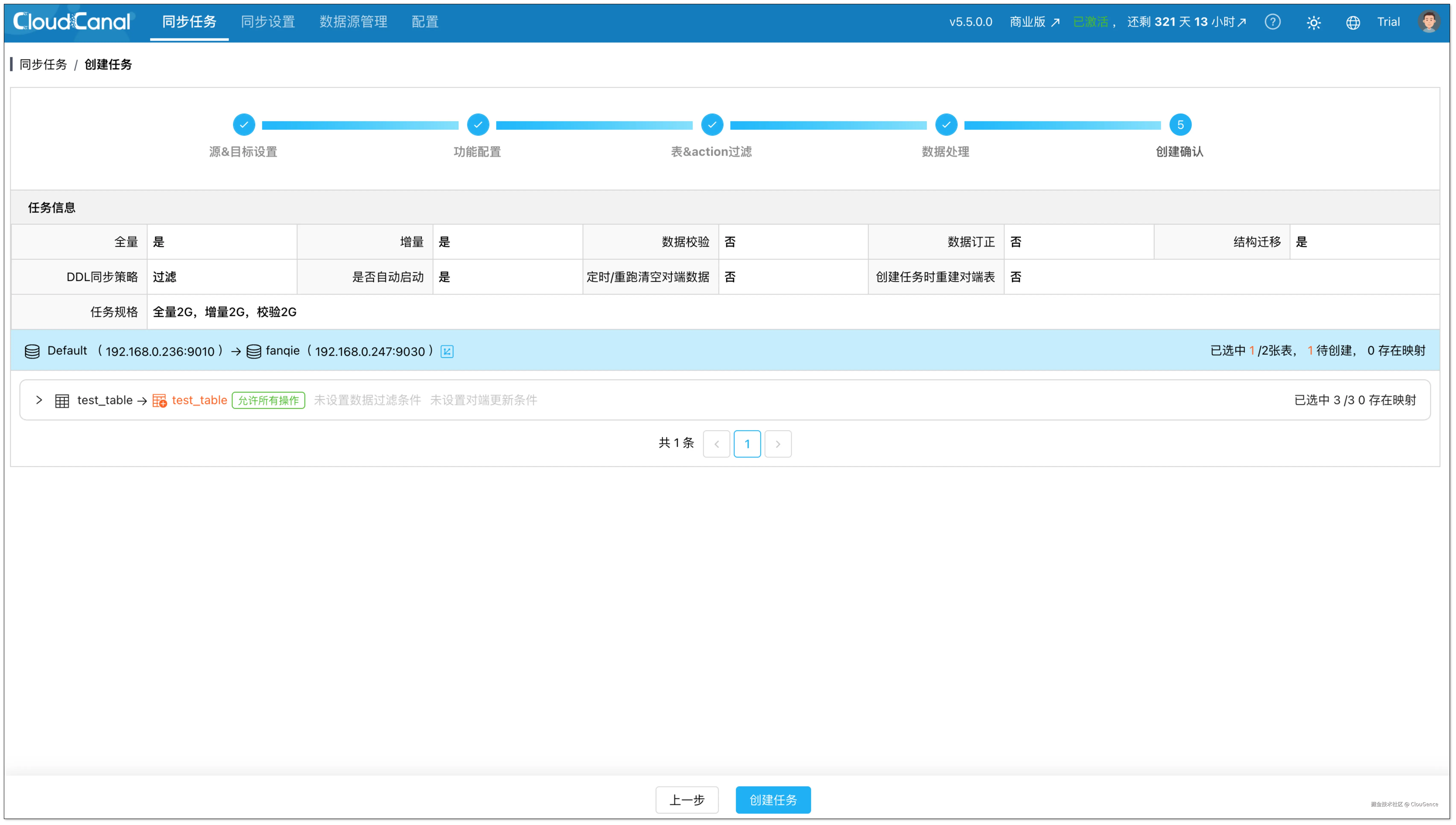
在创建确认页面,点击 创建任务。
CloudCanal 将自动开始运行任务,在任务列表可查看进度。

总结
把分析负载从 Spanner 放到 StarRocks,解决的不只是一个成本问题,更是让两个系统各自负责自己更擅长的部分。Spanner 继续承担事务处理,StarRocks 专注分析查询,而 CloudCanal 作为中间的数据链路,负责把数据持续、稳定地连接起来。
当事务与分析不再混跑,架构会更清晰,资源使用也更合理,成本自然随之下降。
如果你也在寻找 Spanner 数据迁移同步的方案,或希望验证方案可行性,欢迎尝试 CloudCanal 免费社区版。