目录
Redis常用数据结构
String
设置缓存
bash
# 设置key value
set name xht
# 设置带过期时间的key value
set name xht ex 3获取缓存
bash
get name删除缓存
bash
# 返回值表示删除的个数
# 可以删除一个或多个
# 批量删除时为保证保证执行效率,防止Redis服务长时间阻塞对其他应用不可用,使用scan命令分批次删除
del name [age address]设置过期时间
bash
# expire 单位是秒
expire key time
# pexpire 单位是毫秒
pexpire key time获取过期时间
bash
# 返回值是过期时间,单位秒,-1表示永久,-2表示不存在
ttl key判断key是否存在
bash
exists key加减
bash
# 自增key指定大小
incrby key delta
# 自减key指定大小
decrby key delta不存在时设置值
bash
# 不存在时设置值,返回值为是否成功
set key value nx
# 添加过期时间
set key value nx ex timeHash
设置字段和值
bash
hset key field1 value1 [field2 value2...]获取字段值
bash
hget key field1获取所有字段和值
bash
# 返回值为map集合
hgetall key删除字段值
bash
hdel key field1 [field2...]判断字段是否存在
bash
hexists key field1获取字段集合
bash
hkeys key获取所有值集合
bash
hvals keyList
左侧插入
bash
# 队列左侧插入1 2 3,插入后队列中元素为1 2 3
lpush queue 3 2 1右侧插入
bash
#接上一步操作,队列中元素为1 2 3 4 5 6
rpush queue 4 5 6左侧弹出
bash
# 弹出1
lpop queue右侧弹出
bash
rpop queue范围读取队列元素
bash
# 读取整个队列元素 左右闭区间,下标从0开始
lrange queue 0 -1获取队列长度
bash
llen queue根据索引获取元素
bash
# 下标从0开始
lindex queue 0删除指定值元素
bash
# 删除指定数量的元素值,0表示无数量限制
lrem queue count value裁剪队列
bash
#左右闭区间
#将队列裁剪成指定大小,这里queue少了一个元素
ltrim queue 0 -2Set
添加元素
bash
sadd set m1 [m2,m3...]获取集合元素
bash
#重复元素只保留一个
smembers set判断是否存在
bash
sismember set m1获取集合大小
bash
scard set删除元素
bash
srem set m1随机选取元素
bash
# 获取指定数量的集合元素
srandmember set count集合运算
bash
# 交集
sinter s1 s2
# 并集
sunion s1 s2
# 差集
sdiff s1 s2ZSet
添加元素
bash
#先添加分数再添加元素
zadd key score1 m1 [score2 m2]获取范围内元素
bash
# 获取指定范围内的元素,这个范围是按分数升序排序的结果,左右都是闭区间
zrange key index1 index2
# 降序获取
zrevrange key index1 index2按分数获取元素
bash
#分数按区间取值升序
zrangebyscore key score1 score2
#分数按区间取值降序score1>score2
zrevrangebyscore key score1 score2获取集合大小
bash
zcard key获取排名
bash
# 升序排名
zrank s1 m1
# 降序排名
zrevrank s1 m1获取分数
bash
# 返回m1的分数
zscore s1 m1删除元素
bash
zrem s1 m1按排名删除
bash
#按分数升序排列,删除[r1,r2]区间内的元素
zremrangebyrank s1 r1 r2按分数删除
bash
zremrangebyscore s1 min max增加分数
bash
zincyby s1 increment m1缓存问题
缓存穿透
查询到不存在的数据,绕过缓存直接查数据库,数据库也不存在
场景:
恶意攻击,查询不存在的商品ID
错误示范
java
public Product getProductWrong(Long productId) {
// 1. 查缓存
Product product = (Product) redisUtils.get("product:" + productId);
if (product != null) {
return product;
}
// 2. 缓存没有,直接查数据库
product = queryFromDatabase(productId);
if (product != null) {
redisUtils.set("product:" + productId, product, 30, TimeUnit.MINUTES);
}
return product;
}解决方案1
缓存空值,先查redis缓存,若存在,看是否为空值,若为空值,直接返回;
否则,查数据库,看是否能查到,若查到,缓存redis,设置过期时间,否则,存空值,设置过期时间
java
public Product getProductWithNullValue(Long productId) {
String cacheKey = "product:"+ productId;
//先查询缓存
Product product = (Product) redisUtils.get(cacheKey);
if (product != null) {
//已经缓存了空值,直接返回空
if(product.getId()==null&&"NULL".equals(product.getName())){
log.info("商品不存在,缓存为空");
return null;
}
return product;
}
// 查询数据库
product = queryFromDatabase(productId);
if (product == null) {
product = new Product();
product.setId(null);
product.setName("NULL");
redisUtils.set(cacheKey, product, 30, TimeUnit.MINUTES);
log.warn("商品不存在");
return null;
}
redisUtils.set(cacheKey, product, 30, TimeUnit.MINUTES);
return product;
}解决方案2
布隆过滤器,先通过布隆过滤器判断数据是否存在,不存在直接返回,否则执行解决方案1
java
public Product getProductWithBloomFilter(Long productId, BloomFilter bloomFilter) {
// 1. 布隆过滤器判断
if (!bloomFilter.mightContain(productId)) {
log.info("布隆过滤器判定商品不存在: productId={}", productId);
return null;
}
// 2. 继续正常查询流程
return getProductWithNullValue(productId);
}缓存击穿
热点key过期瞬间,大量请求打到数据库
场景:
热门商品过期,秒杀商品
错误示例:
大量并发请求同时查数据库
java
public Product getHotProductWrong(Long productId) {
String cacheKey = "hot:product:" + productId;
// 1. 查缓存
Product product = (Product) redisUtils.get(cacheKey);
if (product != null) {
return product;
}
// 2. 大量并发同时到这里,同时查数据库
log.warn("缓存击穿风险!多个线程同时查询数据库: productId={}", productId);
product = queryFromDatabase(productId);
if (product != null) {
redisUtils.set(cacheKey, product, 30, TimeUnit.MINUTES);
}
return product;
}解决方案1
互斥锁,只有一个线程去查数据库,其他线程等待
java
public Product getHotProductWithLock(Long productId) {
String cacheKey = "hot:product:" + productId;
String lockKey = "lock:product:" + productId;
// 1. 查缓存
Product product = (Product) redisUtils.get(cacheKey);
if (product != null) {
return product;
}
// 2. 获取分布式锁
String lockValue = UUID.randomUUID().toString();
//setIfAbsent是互斥锁
boolean locked = redisUtils.tryLock(lockKey, lockValue, 10, TimeUnit.SECONDS);
if (locked) {
try {
// 3. 双重检查:获取锁后再次查缓存
product = (Product) redisUtils.get(cacheKey);
if (product != null) {
return product;
}
// 4. 查询数据库
log.info("获取锁成功,查询数据库: productId={}", productId);
product = queryFromDatabase(productId);
if (product != null) {
redisUtils.set(cacheKey, product, 30, TimeUnit.MINUTES);
}
return product;
} finally {
// 5. 释放锁
redisUtils.unlock(lockKey, lockValue);
}
} else {
// 6. 未获取到锁,短暂休眠后重试
try {
Thread.sleep(50);
return getHotProductWithLock(productId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
}
}
}解决方案2
逻辑过期,缓存永不过期,后台异步更新
java
public ProductCache getHotProductWithLogicExpire(Long productId) {
String cacheKey = "hot:product:logic:" + productId;
// 1. 查缓存
ProductCache cacheData = (ProductCache) redisUtils.get(cacheKey);
if (cacheData == null) {
// 2. 首次访问,需要加锁查询
Product product = getHotProductWithLock(productId);
// 将Product转换为ProductCache
ProductCache result = new ProductCache();
result.setProduct(product);
result.setExpireTime(System.currentTimeMillis() + 30 * 60 * 1000);
return result;
}
Product product = cacheData.getProduct();
long expireTime = cacheData.getExpireTime();
// 3. 判断是否过期
if (expireTime > System.currentTimeMillis()) {
// 4. 未过期,直接返回
return cacheData;
}
// 5. 已过期,异步重建缓存
asyncRebuildCache(productId);
// 6. 返回旧数据
log.info("缓存已过期,返回旧数据,异步重建中: productId={}", productId);
return cacheData;
}
//异步更新,需要上锁
private void asyncRebuildCache(Long productId) {
String lockKey = "lock:rebuild:product:" + productId;
String lockValue = UUID.randomUUID().toString();
boolean locked = redisUtils.tryLock(lockKey, lockValue, 10, TimeUnit.SECONDS);//防止一直上锁,因此设置缓存时间为10秒,即使更新未完成也不会受影响
if (locked) {
try {
// 查询数据库
Product newProduct = queryFromDatabase(productId);
if (newProduct != null) {
// 构建新的缓存数据
ProductCache cacheData = new ProductCache();
cacheData.setProduct(newProduct);
// 逻辑过期时间:30分钟
cacheData.setExpireTime(System.currentTimeMillis() + 30 * 60 * 1000);
// 写入缓存
String cacheKey = "hot:product:logic:" + productId;
redisUtils.set(cacheKey, cacheData, 1, TimeUnit.HOURS);
log.info("异步重建缓存成功: productId={}", productId);
}
} finally {
redisUtils.unlock(lockKey, lockValue);
}
}
}缓存雪崩
大量key同时失效,或Redis宕机
场景:
批量设置相同过期时间、系统重启后缓存全部失效
错误示例:
所有商品设置相同过期时间
java
public void cacheProductsWrong(Product... products) {
for (Product product : products) {
// 所有商品都是30分钟过期,会同时失效
redisUtils.set("product:" + product.getId(), product, 30, TimeUnit.MINUTES);
}
log.warn("所有商品设置相同过期时间,可能导致缓存雪崩!");
}解决方案1
随机过期时间,给不同的key设置随机过期时间
java
public void cacheProductsWithRandomExpire(Product... products) {
for (Product product : products) {
// 基础过期时间:30分钟
int baseMinutes = 30;
// 随机过期时间:5-10分钟
int randomMinutes = 5 + (int) (Math.random() * 5);
// 总过期时间
int totalMinutes = baseMinutes + randomMinutes;
redisUtils.set("product:" + product.getId(), product, totalMinutes, TimeUnit.MINUTES);
log.info("缓存商品,过期时间: {}分钟, productId={}", totalMinutes, product.getId());
}
}解决方案2
缓存预热,系统启动时预热热点数据
java
public void warmupCache() {
log.info("开始缓存预热...");
// 1. 查询热门商品
for (int i = 1; i <= 100; i++) {
Product product = queryFromDatabase((long) i);
if (product != null) {
// 2. 使用随机过期时间缓存
cacheProductsWithRandomExpire(product);
}
}
log.info("缓存预热完成");
}解决方案3
多级缓存,本地缓存+Redis缓存+数据库
java
public Product getProductWithMultiLevel(Long productId) {
String cacheKey = "product:" + productId;
// 1. 本地缓存(Caffeine/Guava)
Product product = getFromLocalCache(cacheKey);
if (product != null) {
log.info("命中本地缓存: productId={}", productId);
return product;
}
// 2. Redis缓存
product = (Product) redisUtils.get(cacheKey);
if (product != null) {
// 回写本地缓存
putToLocalCache(cacheKey, product);
log.info("命中Redis缓存: productId={}", productId);
return product;
}
// 3. 数据库
product = queryFromDatabase(productId);
if (product != null) {
// 4. 写入多级缓存
putToLocalCache(cacheKey, product);
redisUtils.set(cacheKey, product, 30, TimeUnit.MINUTES);
log.info("从数据库加载,写入多级缓存: productId={}", productId);
}
return product;
}
private Product getFromLocalCache(String key) {
// 这里应该使用Caffeine或Guava Cache
// 为了演示简化,返回null
return null;
}解决方案4
部署Redis集群,防止单个Redis服务器宕机服务不可用
缓存与数据库一致性问题
缓存与数据库数据不一致问题
解决方案1
旁路缓存技术(Cache Aside Parttern)
读:命中返回,未命中,读数据,更新缓存
写:写数据库,删除缓存(这里不更新缓存,因为更新缓存可能因复杂逻辑带来并发冲突(如多个线程写同一个缓存),删除则简单且下次读会加载最新值。)
若删除缓存失败,引入重试机制(消息队列、订阅 binlog 异步重试)
解决方案2
延迟双删
先删缓存,再更新数据库,然后异步延迟一段时间再次删除缓存,用于解决并发读导致的脏缓存问题。(读缓存失败,读数据库旧值,又将旧值更新到缓存)
缺点:延迟时间难以确定,会降低性能
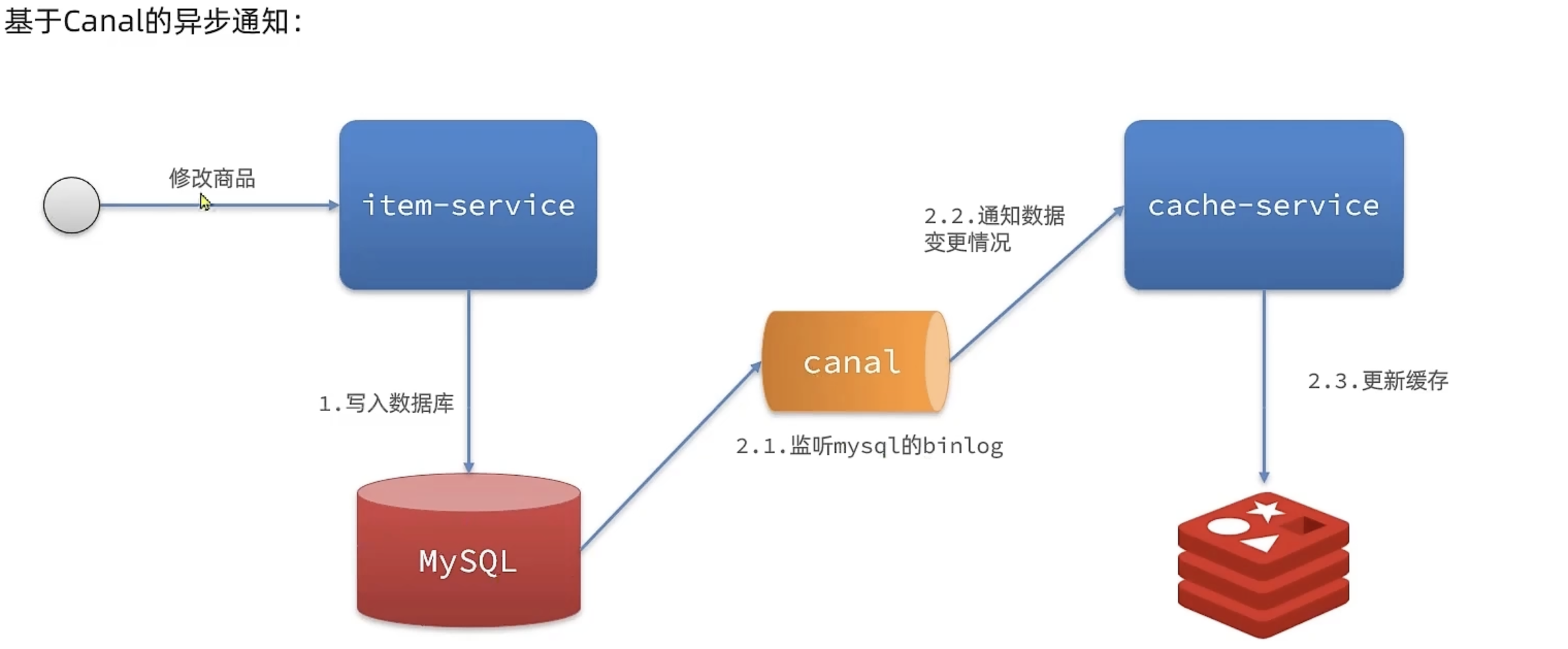
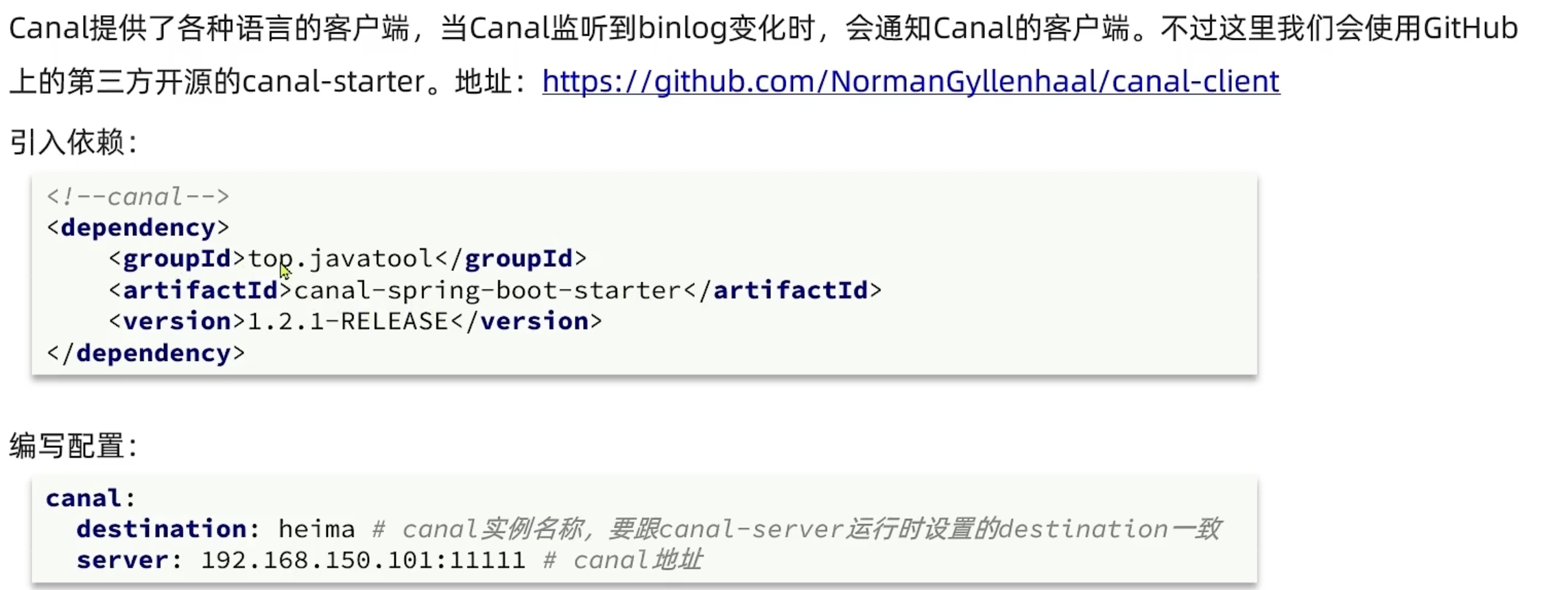
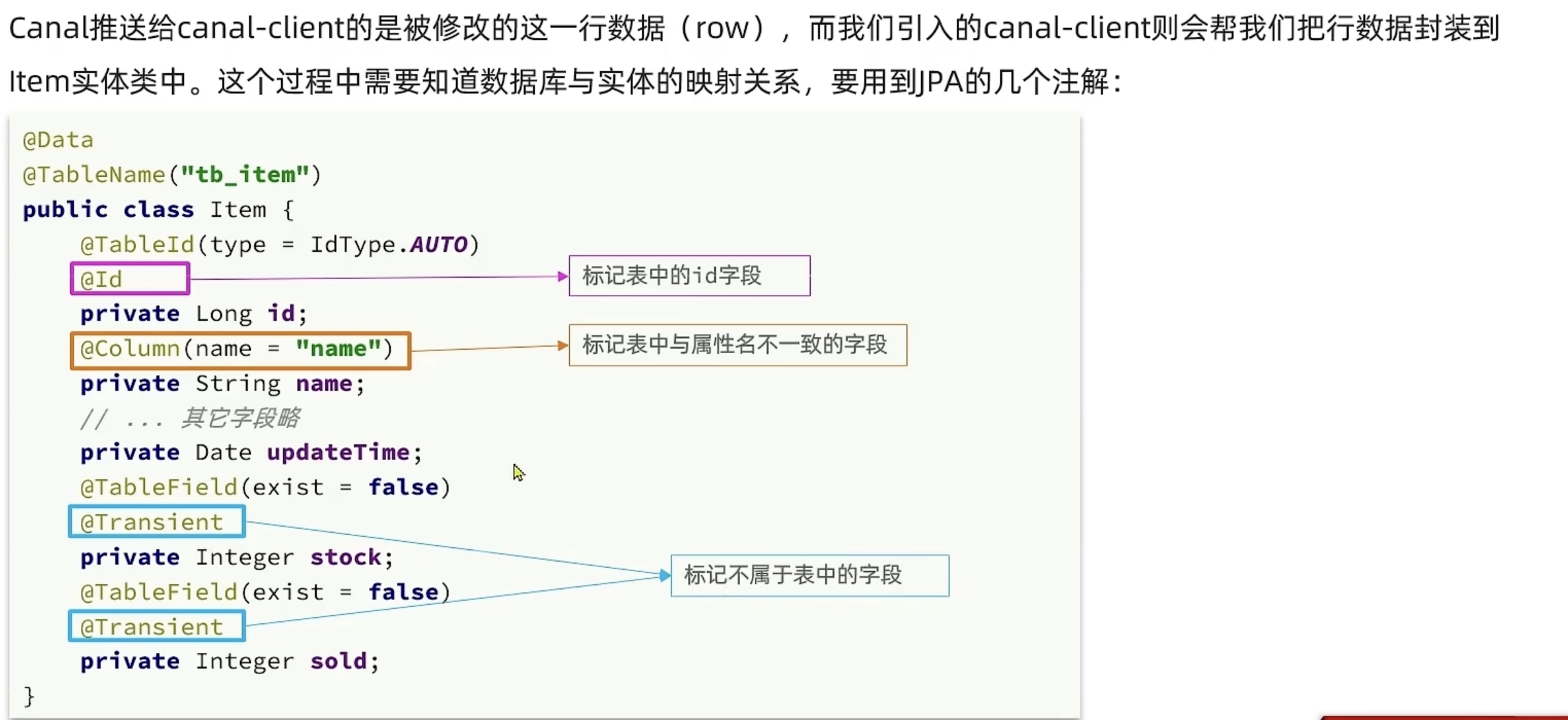
解决方案3
订阅数据库变更日志(Canal + MQ)
使用 Canal 监听 MySQL binlog,解析出数据变更事件(insert/update/delete)
将事件发送到 MQ,消费端异步删除或更新 Redis 缓存
优点:解耦,保证最终一致性,不侵入业务代码
缺点:引入中间件增加复杂度,延迟稍高
解决方案4
先更新数据库,再更新缓存(不推荐)
并发下容易导致缓存脏数据,比如两个线程先后更新数据库,但以相反顺序更新缓存。
解决方案5
读写锁(强一致性)
写操作加写锁,阻塞所有读操作;读操作加读锁,阻塞写操作
实现:使用分布式锁(如 Redisson)或数据库悲观锁。性能较差,适合强一致性要求极高的场景
解决方案6
设置合理的缓存过期时间
作为最终兜底:即使短暂不一致,缓存过期后自然会从数据库加载最新值。适用于对一致性要求不高的场景。通常过期时间不宜过长
避免陷阱的最佳实践
- 优先删除缓存,而不是更新缓存。
- 确保删除缓存操作的重试机制(本地消息表、MQ 等)。
- 读操作时写缓存需谨慎:可先加缓存锁防止并发写,或使用 setnx 避免重复写入。
- 缓存与数据库的操作顺序:先操作数据库,再操作缓存(因为数据库是事实源)。
- 监控缓存与数据库的差异,可定期对账修复。
分布式锁
基础实现
加锁
java
//利用Redis里的set key value nx ex timeout
//这里nx表示如果not exist才设置,ex是毫秒,timeout超时时间
public boolean tryLock(String lockKey, String lockValue, long expireTime, TimeUnit timeUnit) {
try {
boolean locked = redisUtils.tryLock(lockKey, lockValue, expireTime, timeUnit);
if (locked) {
log.info("获取锁成功: lockKey={}, lockValue={}", lockKey, lockValue);
} else {
log.warn("获取锁失败: lockKey={}", lockKey);
}
return locked;
} catch (Exception e) {
log.error("获取锁异常: lockKey={}", lockKey, e);
return false;
}
}
public boolean tryLock(String lockKey, String value, long time, TimeUnit timeUnit) {
return Boolean.TRUE.equals(
redisTemplate.opsForValue().setIfAbsent(lockKey, value, time, timeUnit)
);
}解锁
使用lua脚本解锁,保证redis操作的原子性
java
public void unlock(String lockKey, String lockValue) {
try {
redisUtils.unlock(lockKey, lockValue);
log.info("释放锁成功: lockKey={}, lockValue={}", lockKey, lockValue);
} catch (Exception e) {
log.error("释放锁异常: lockKey={}", lockKey, e);
}
}
public void unlock(String lockKey, String value) {、
String script = "if redis.call('get', KEYS[1]==ARGV[1]) then" +
"return redis.call('del', KEYRS[1])" +
"else return 0 end";
redisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Collections.singletonList(lockKey),value
);
}存在问题
- 业务超时后,锁会自动释放
- 单点故障,若主节点宕机,锁未同步,可能导致多个客户端持有锁
- 不可重入,通客户端请求时会失败
进阶优化
锁续约
客户端持有锁以后,定期将锁的过期时间重置,直到业务完成或客户端宕机,此时要另开启线程执行续约任务,而且线程需要设置为守护线程
java
import redis.clients.jedis.Jedis;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLockWithRenewal {
private static final String LOCK_KEY = "myLock";
private static final int EXPIRE_SECONDS = 30;
private static final int RENEWAL_INTERVAL_SECONDS = 10;
private Thread renewalThread;
private volatile boolean running;
private String lockValue;
private Jedis jedis;
public boolean tryLock(String identifier) {
this.lockValue = identifier;
this.jedis = new Jedis("localhost");
String result = jedis.set(LOCK_KEY, lockValue, "NX", "EX", EXPIRE_SECONDS);
if ("OK".equals(result)) {
startRenewalThread();
return true;
}
return false;
}
private void startRenewalThread() {
running = true;
renewalThread = new Thread(() -> {
while (running) {
try {
TimeUnit.SECONDS.sleep(RENEWAL_INTERVAL_SECONDS);
// 使用 Lua 脚本原子地检查和续期
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('expire', KEYS[1], ARGV[2]) " +
"else " +
" return 0 " +
"end";
Long result = (Long) jedis.eval(script, 1, LOCK_KEY, lockValue, String.valueOf(EXPIRE_SECONDS));
if (result == 0) {
// 锁可能已被释放或抢占,停止续约
running = false;
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
});
renewalThread.setDaemon(true); // 看门狗线程需要设置为守护线程
renewalThread.start();
}
public void unlock() {
running = false;
if (renewalThread != null) {
renewalThread.interrupt();
}
// 释放锁(同样需要 Lua 脚本保证原子性)
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
jedis.eval(script, 1, LOCK_KEY, lockValue);
jedis.close();
}
}可重入锁
不使用String,使用Hash,将field作为唯一标识,value作为重入计数
解决单点故障
红锁,解决单点故障,向多个独立的Redis节点加锁,超半数成功才算成功
Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网络。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现
java
RLock lock = redissonClient.getLock("myLock");
boolean isLock = lock.tryLock();
if(!isLock){
return ;
}
try{
//业务处理
}finally{
lock.unlock();
}可重入锁原理
使用Redis中的哈希数据类型保存锁,其中field是线程唯一标识,value是重入次数,通过lua脚本保证原子性
加锁脚本
lua
if(redis.call('exists',KEYS[1])==0) then
redis.call('hincrby', KEYS[1],ARGV[2],1);
redis.call('pexpire',KEYS[1],ARGV[1]);
return nil;
end
if(redis.call('hexists',KEYS[1],ARGV[2])==1) then
redis.call('hincrby',KEYS[1],ARGV[2],1);
redis.call('hexpire',KEYS[1],ARGV[2]);
return nil;
end
return redis.call('pttl',KEYS[1]);解锁脚本
lua
if(redis.call('hexists',KEYS[1],ARGV[3])==0) then
return nil;
end
local count = redis.call('hincrby',KEYS[1],ARGV[3],-1);
if(count>0) then
redis.call('pexpire',KEYS[1],ARGV[2]);
return 0;
else
redis.call('del',KEYS[1]);
redis.call('publish',KEYS[2],ARGV[1]);
return 1;
end
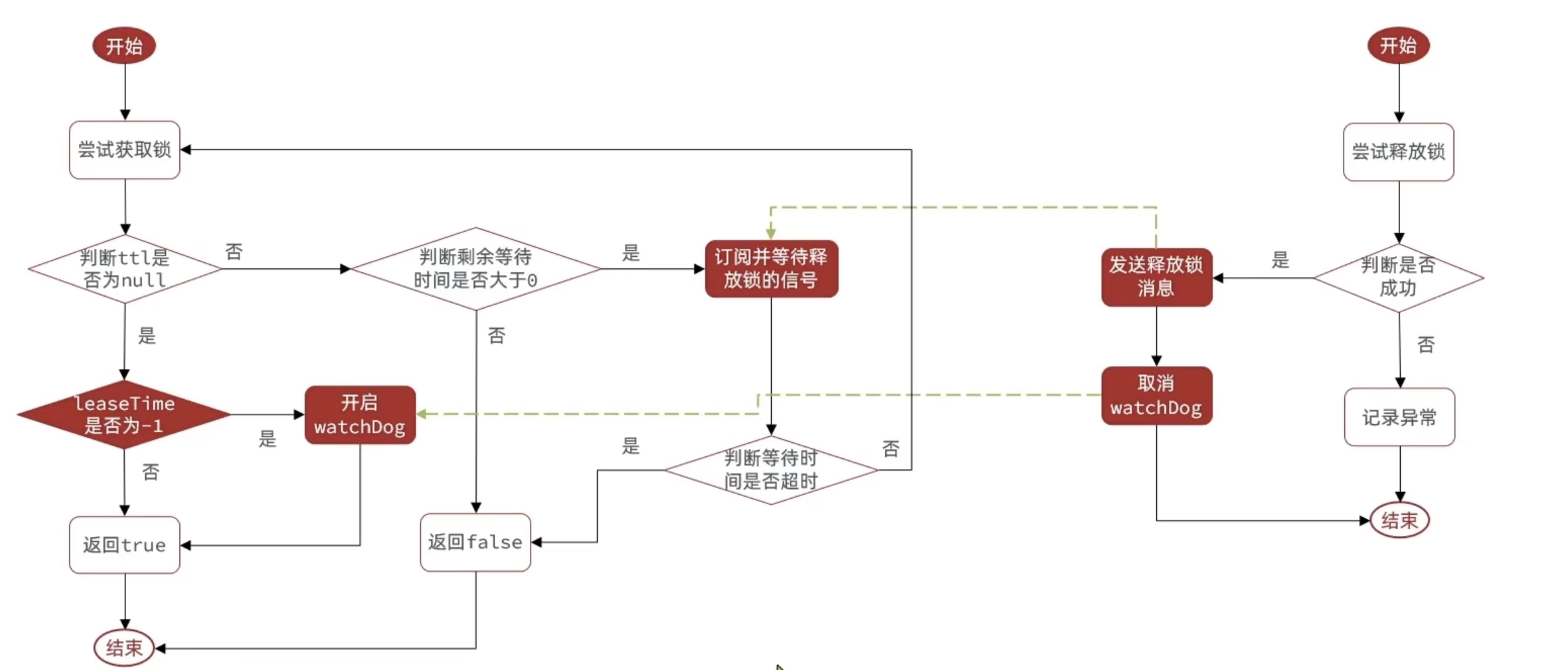
return nil;超时续约机制--看门狗机制
java
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
// 创建一个定时任务,延迟 internalLockLeaseTime / 3 后执行 (默认 30/3 = 10秒)
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 执行续期
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
// 续期成功后,递归调用自己,实现无限循环续期
if (res) {
//递归调用当前方法
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
//重新设置任务对象,覆盖掉了之前执行的定时任务对象
ee.setTimeout(task);
}
MultiLock和RedLock
略
分布式缓存
单节点Redis存在的问题
持久化机制
RDB(Redis Database Backup file)
Redis数据快照。简单来说就是将内存中的所有数据以二进制形式记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件被称为RDB文件,默认是保存在当前运行目录
Redis停机时会执行一次RDB(宕机时不会执行)
触发机制
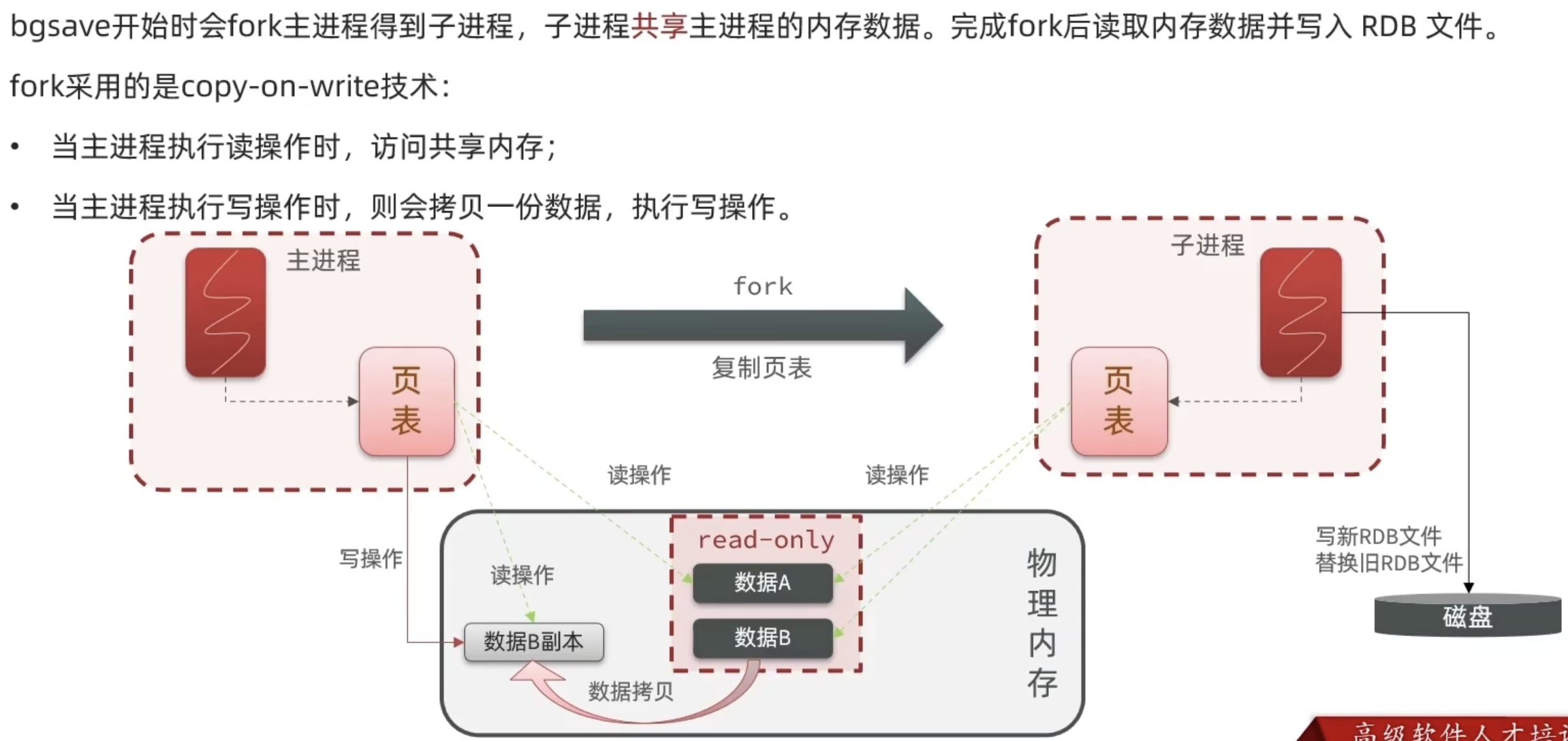
- 手动触发:save命令,主进程阻塞
- 手动触发:bgsave命令,主进程fork子进程生成RDB,不阻塞
- 自动触发:save time change 多少时间内多少修改会触发
- redis-cli shutdown正常关闭redis服务时会自动备份
执行流程
缺点
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程,压缩,写出RDB文件都比较耗时
AOF(Append Only File)持久化
Redis处理的每一个写命令都会记录到AOF文件,可以看做是命令日志文件
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF
触发机制
通过配置redis.conf文件来确定操作频率
bash
# 每执行一次写命令,立刻写入AOF文件,可靠性高,但性能损失大
appendfsync always
# 写命令执行完先放AOF缓冲区,每个1秒将缓冲区数据写入到AOF文件,默认方案,最多丢失一秒数据
appendfsync everysec
# 写命令执行完先放AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘,可靠性差,可能丢失大量数据
appendfsync no文件重写
AOF会记录对同一个key的多次写入操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令可以让AOF执行重写功能,用最少的命令达到相同效果
- 子进程遍历自身内存中的数据库快照,将其转化为 Redis 命令,并写入到一个新的临时 AOF 文件。
- 子进程完成任务后,会向父进程发送完成信号。
- 父进程收到信号后,会将 AOF 重写缓冲区中累积的增量命令,追加到新 AOF 文件的末尾。
- 最后,父进程调用 rename 系统调用,将新 AOF 文件原子地重命名为旧的 AOF 文件名,完成新旧文件的替换。至此,整个重写过程结束。
Redis也可以在触发阈值时去重写AOF文件,阈值配置如下:
bash
# AOF文件比上次文件增长超过多少百分比时,才触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最少多大以上才触发重写
auto-aof-rewrite-min-size 64mb持久化策略对比
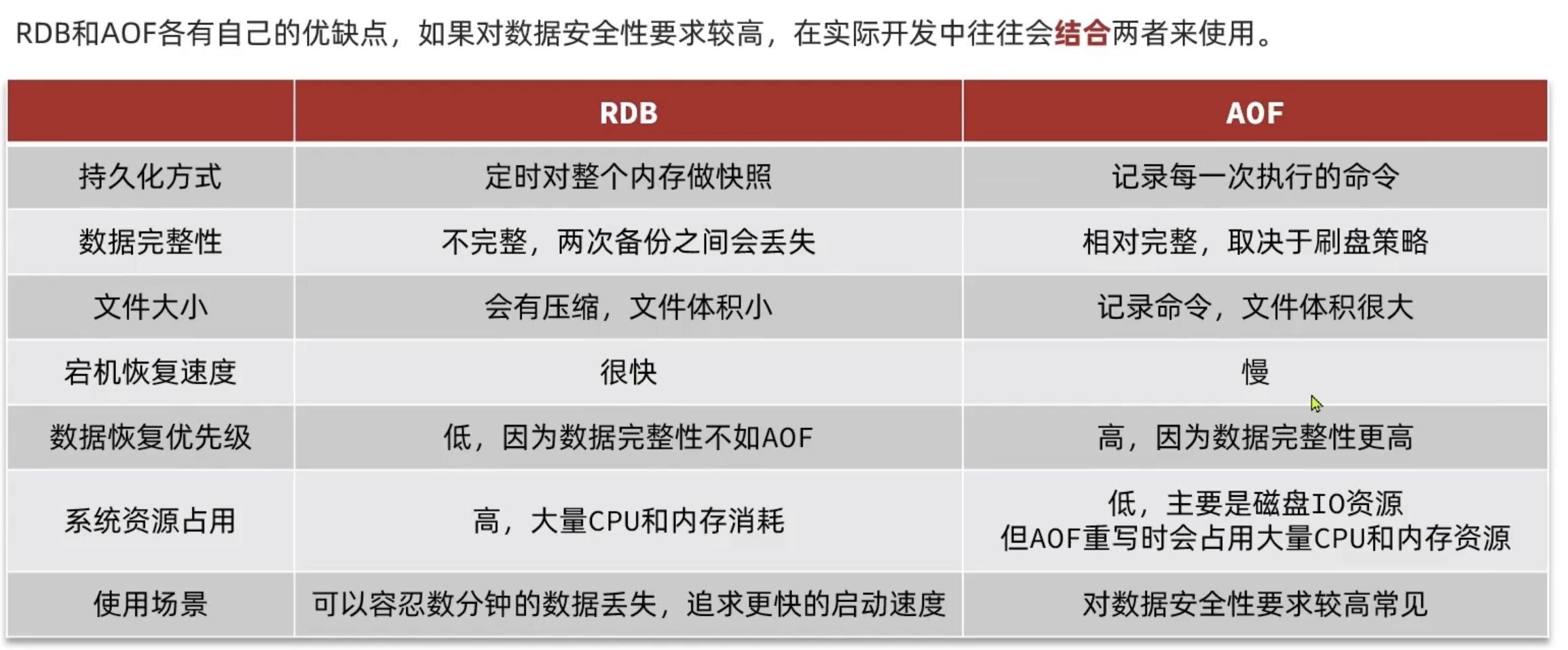
混合持久化
在AOF重写时,Redis会先生成一个当前内存数据的RDB快照,将其作为AOF文件的"开头";后面再继续以传统AOF的方式,追加记录增量命令。最终产出的AOF文件,就成了一个RDB数据与AOF数据的混合体
设置
bash
appendonly yes
aof-use-rdb-preamble yesRedis主从
搭建主从节点
bash
# 从节点配置文件中配置主节点的ip和端口
replicaof <masterIp> <masterPort>数据同步原理
全量同步
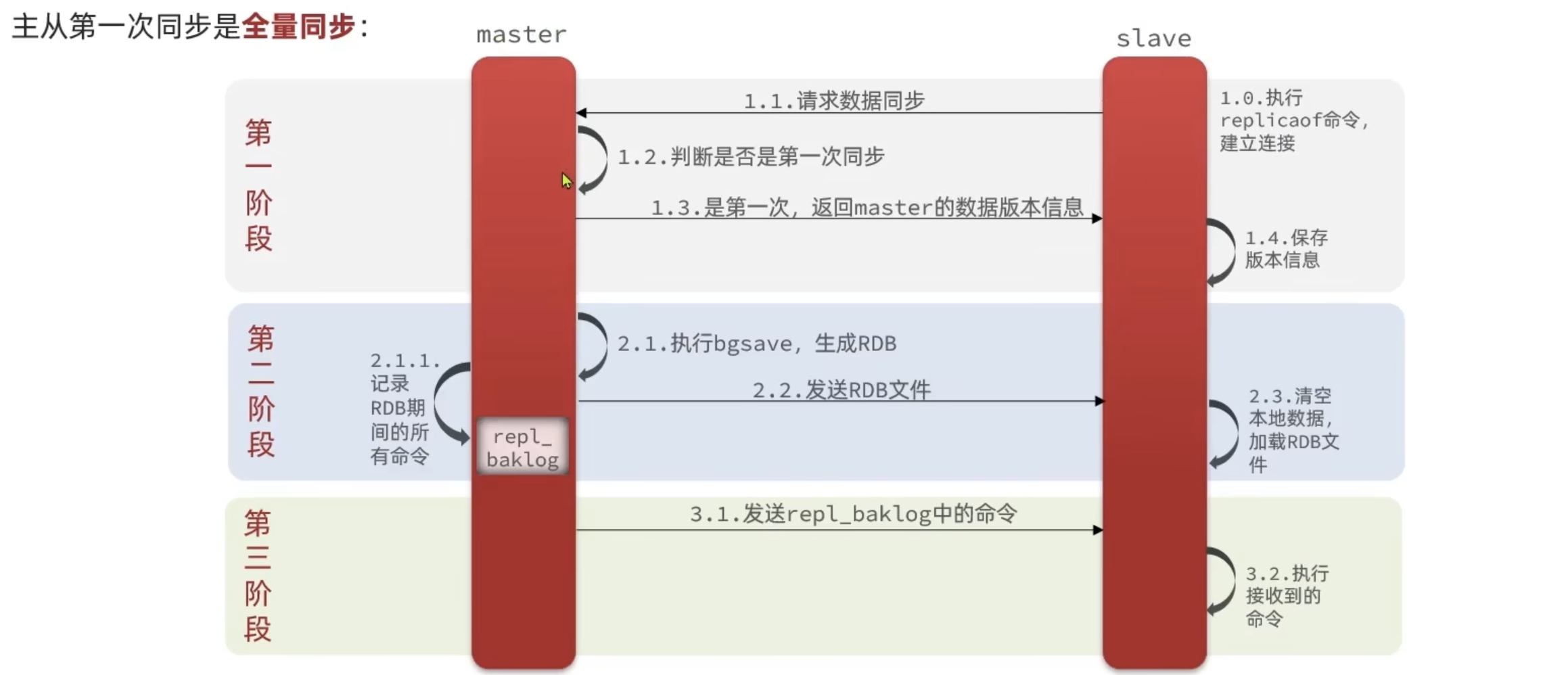

当从节点向主节点发送信息时会带上自己的replication id和offset,主节点发现从节点的replication id与自己的replication id不一致,说明是第一次来。主节点开始执行bgsave命令,备份rdb,然后发送给从节点,从节点接收到rdb文件后,先清空所有旧数据,再恢复新数据。然后master持续向slave发送新的写命令

增量同步
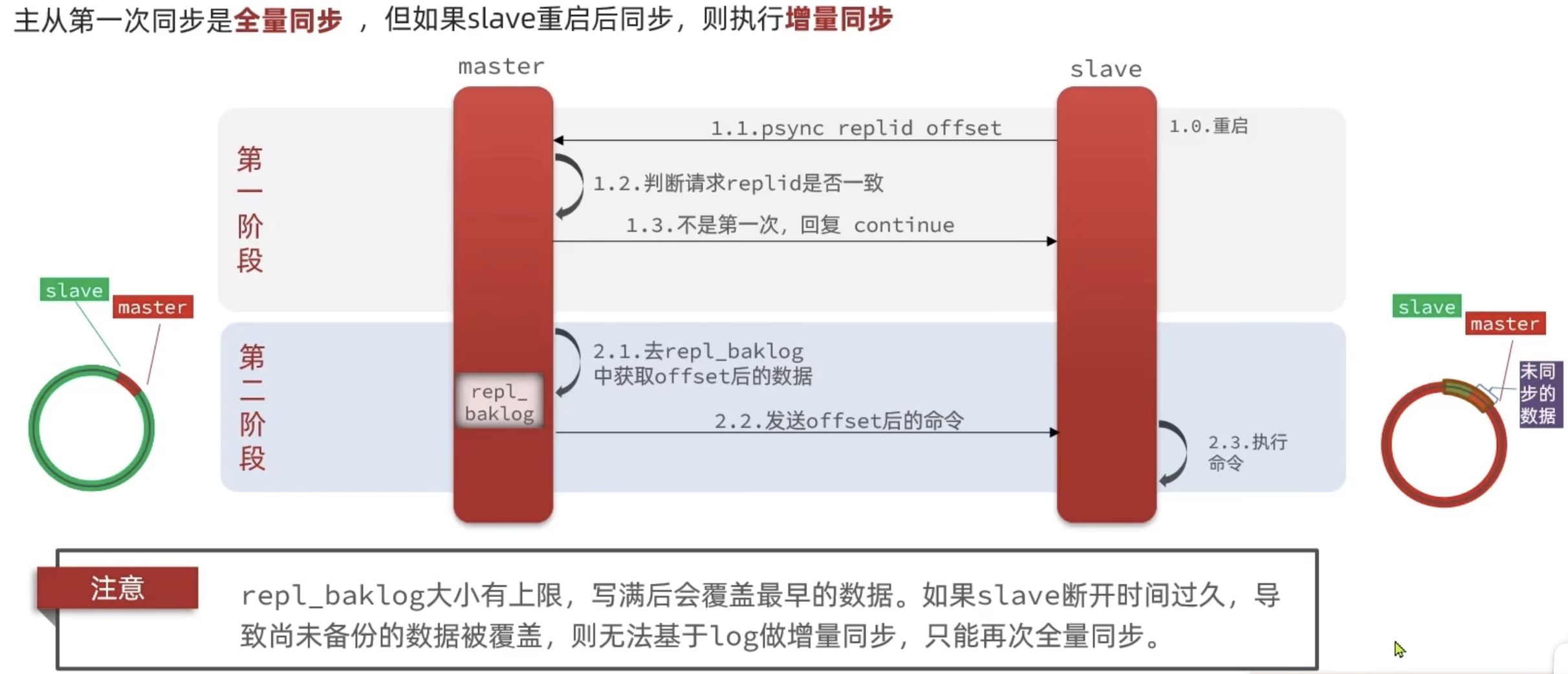
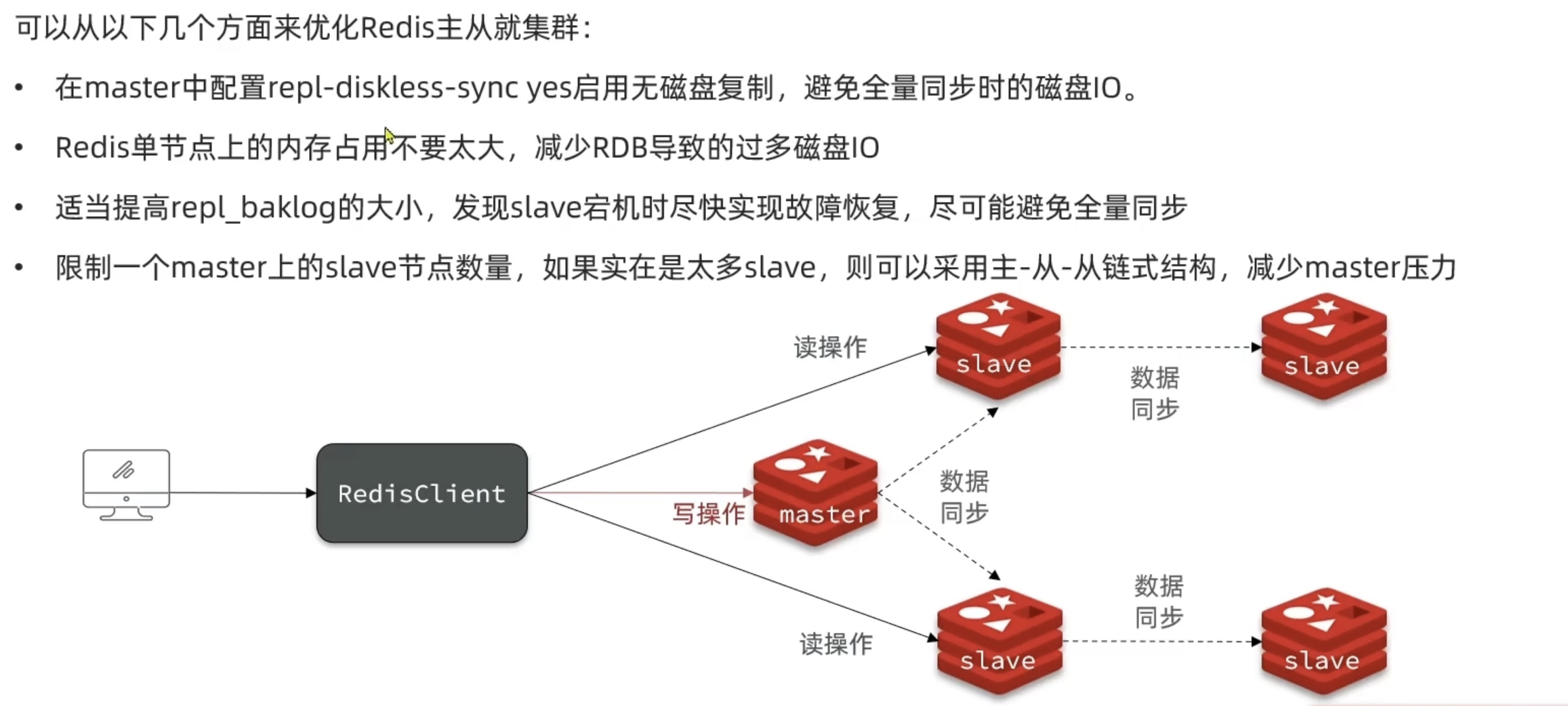
哨兵机制
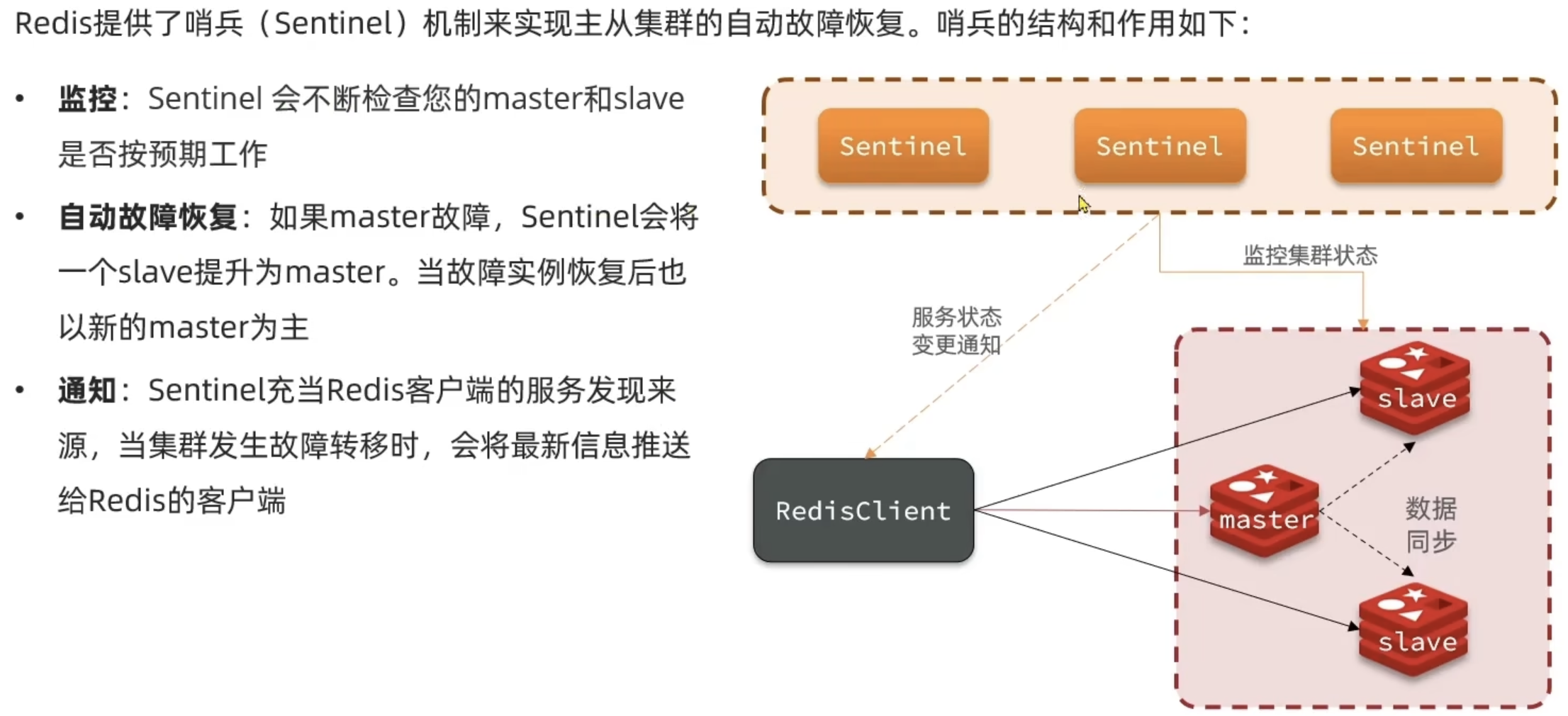
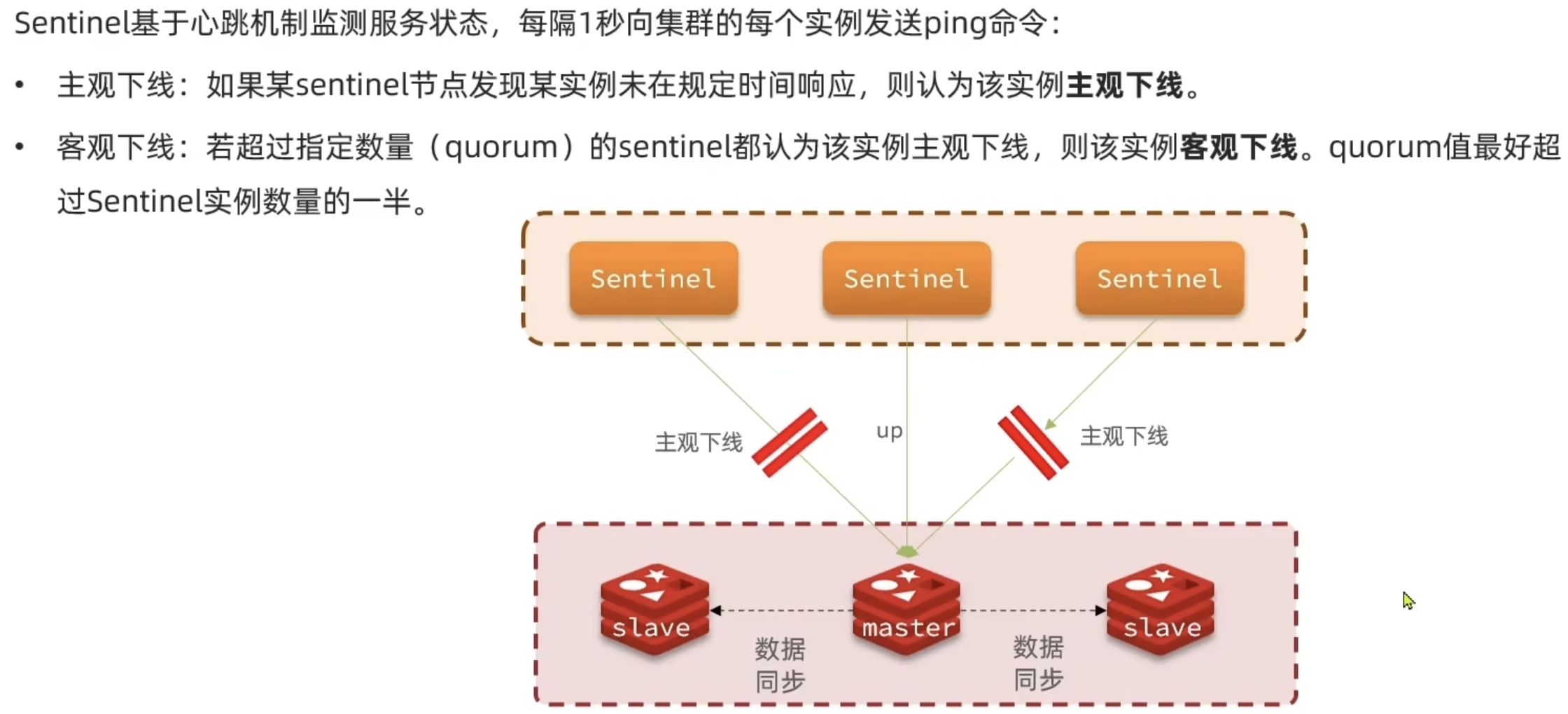
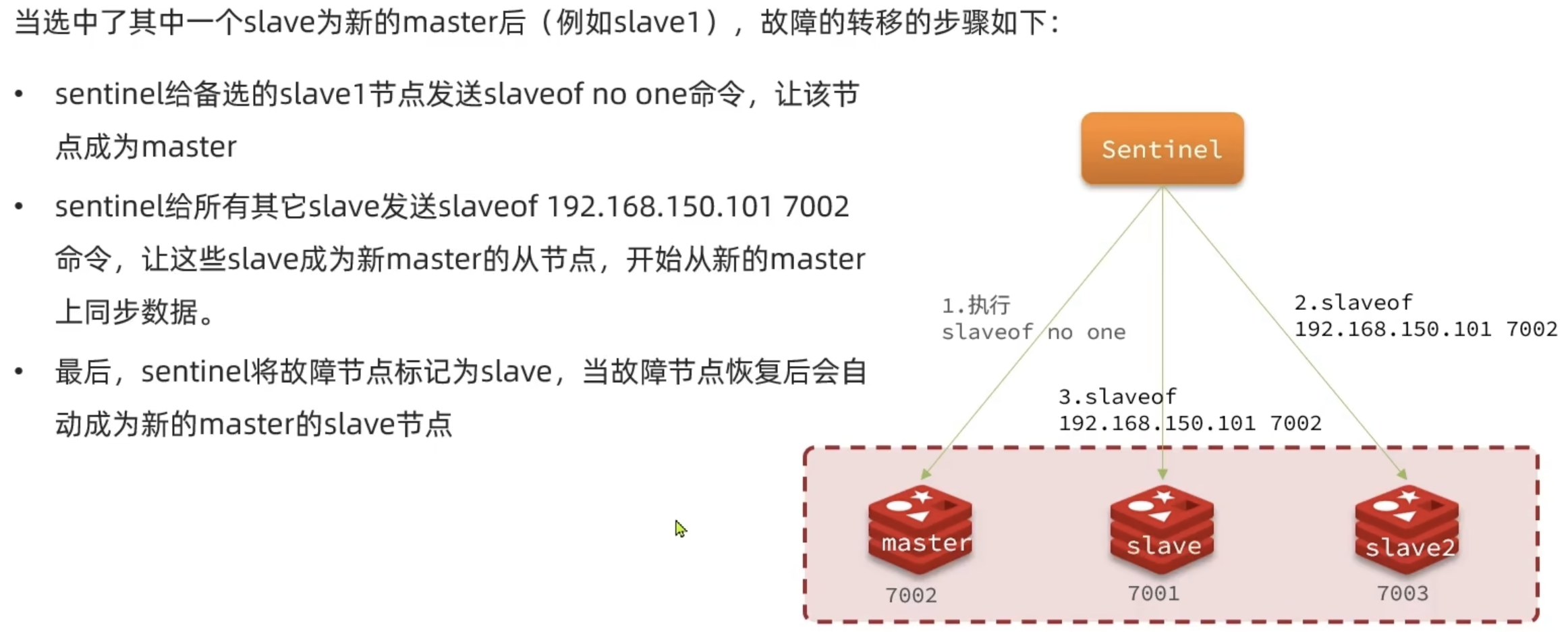
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:

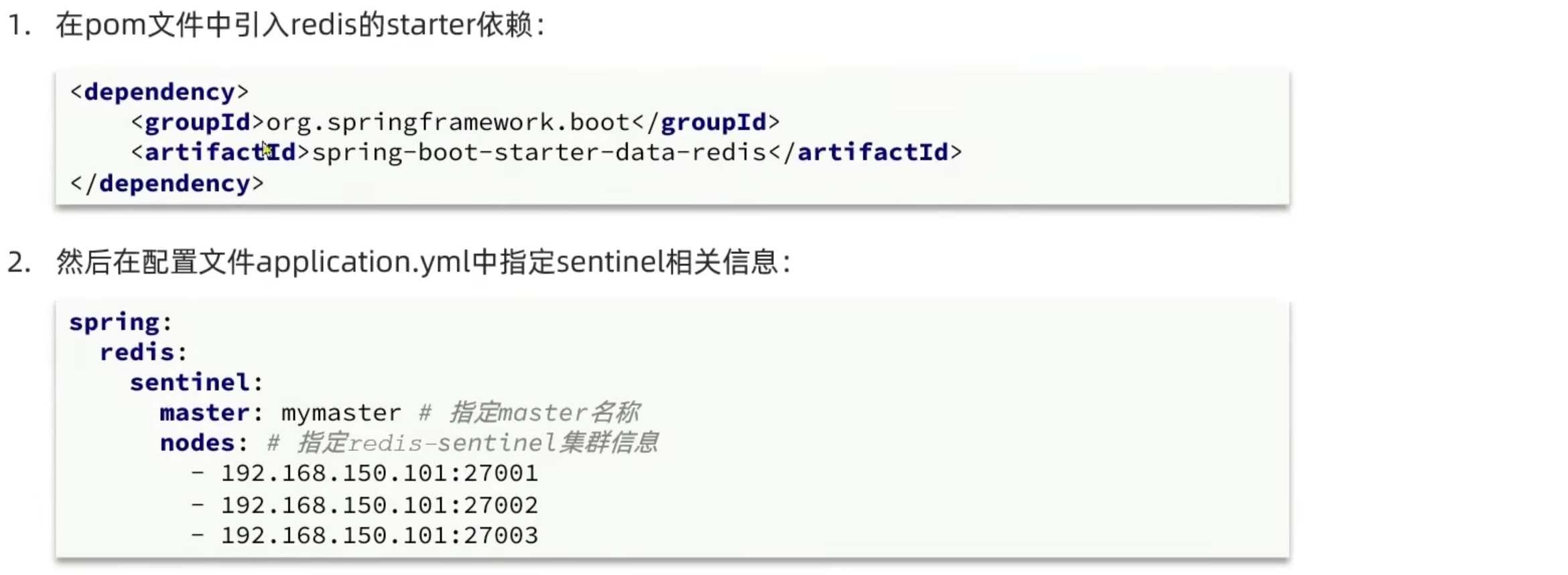
搭建哨兵模式

分片集群
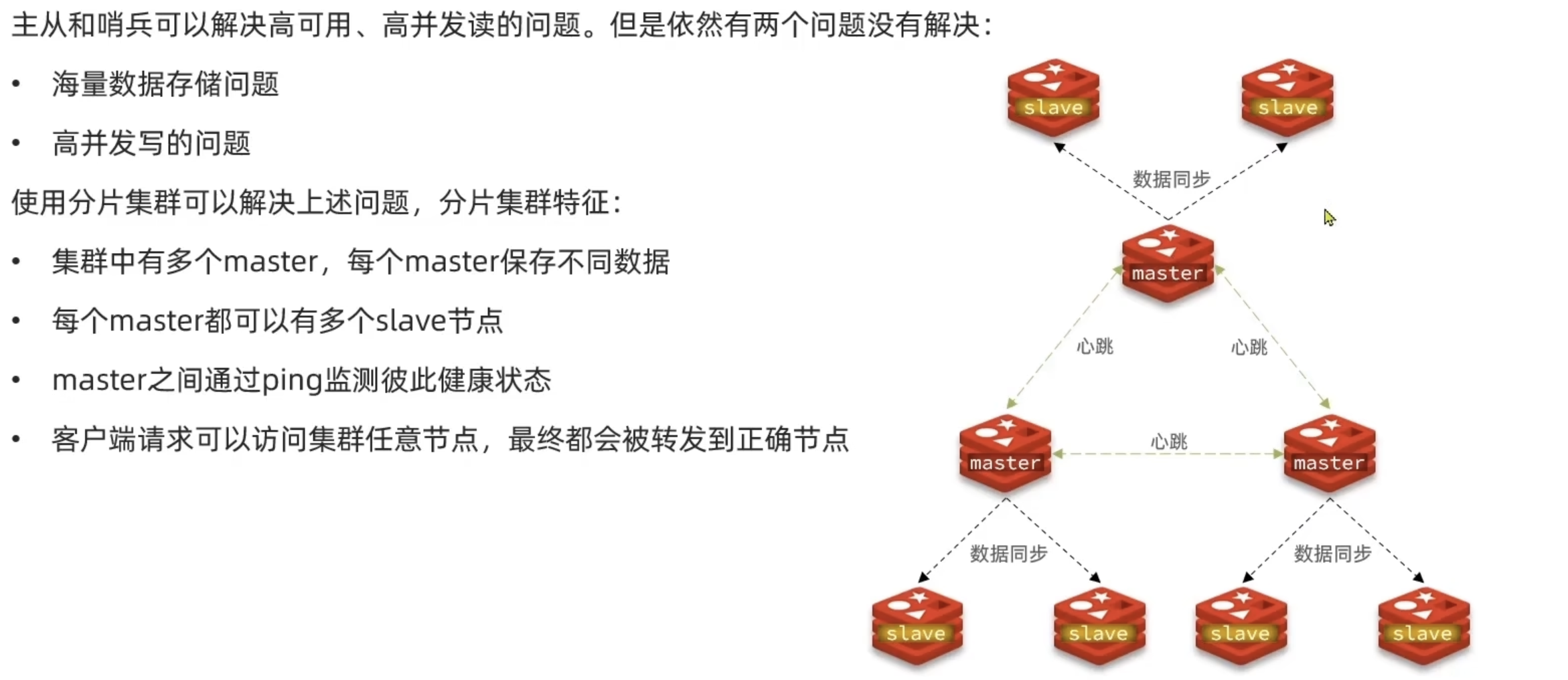
搭建集群
依据上述配置文件启动的redis服务还是单独的节点,没有建立联系
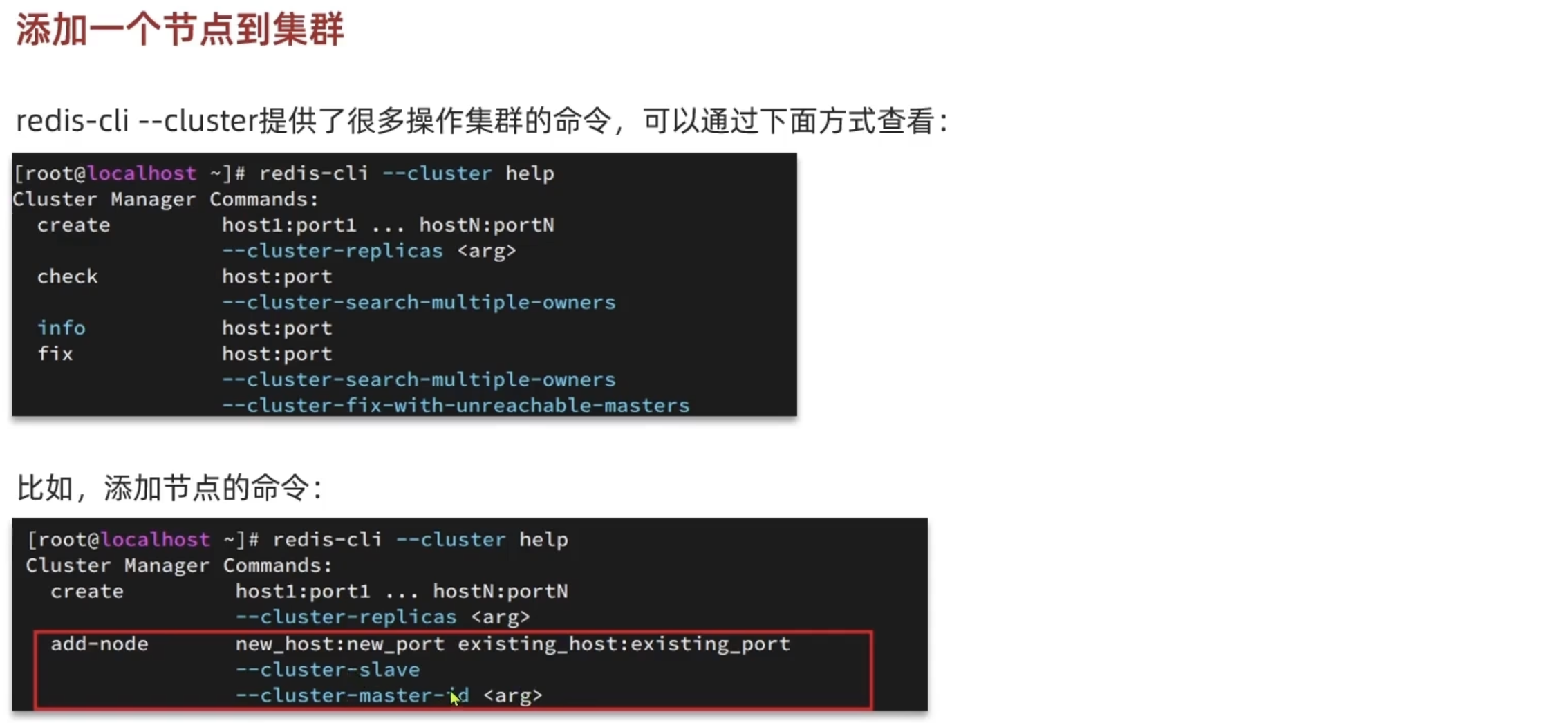
下面启动命令可以创建集群

散列插槽

集群伸缩
对节点进行插槽重分配

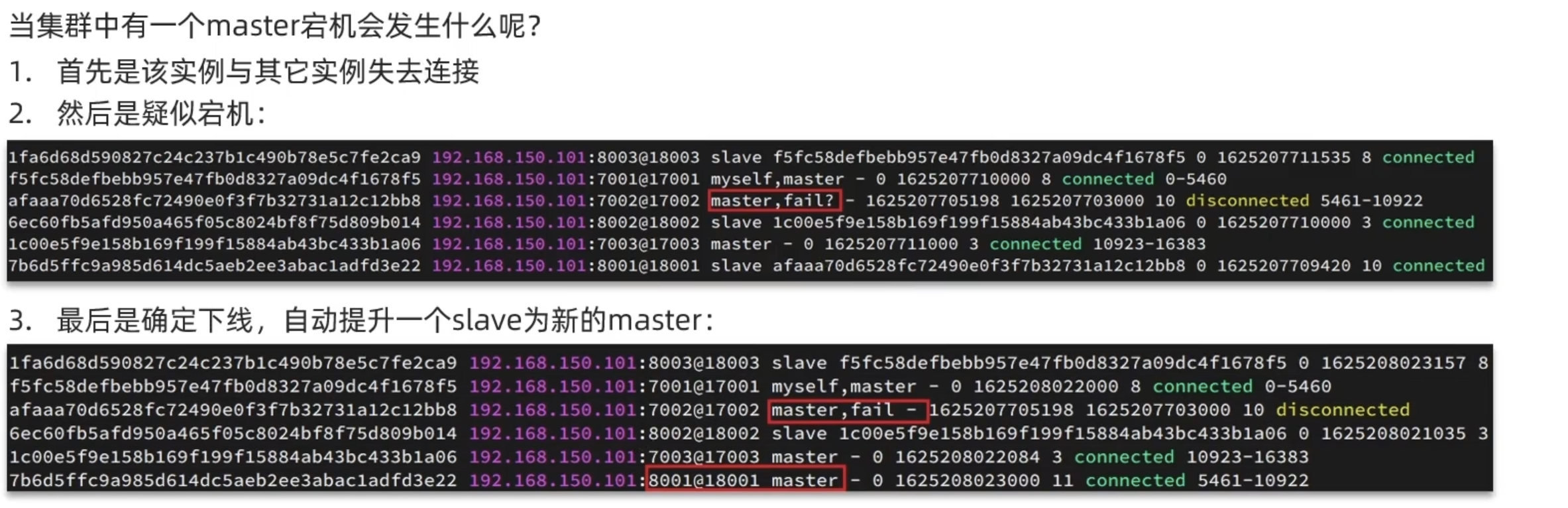
故障转移
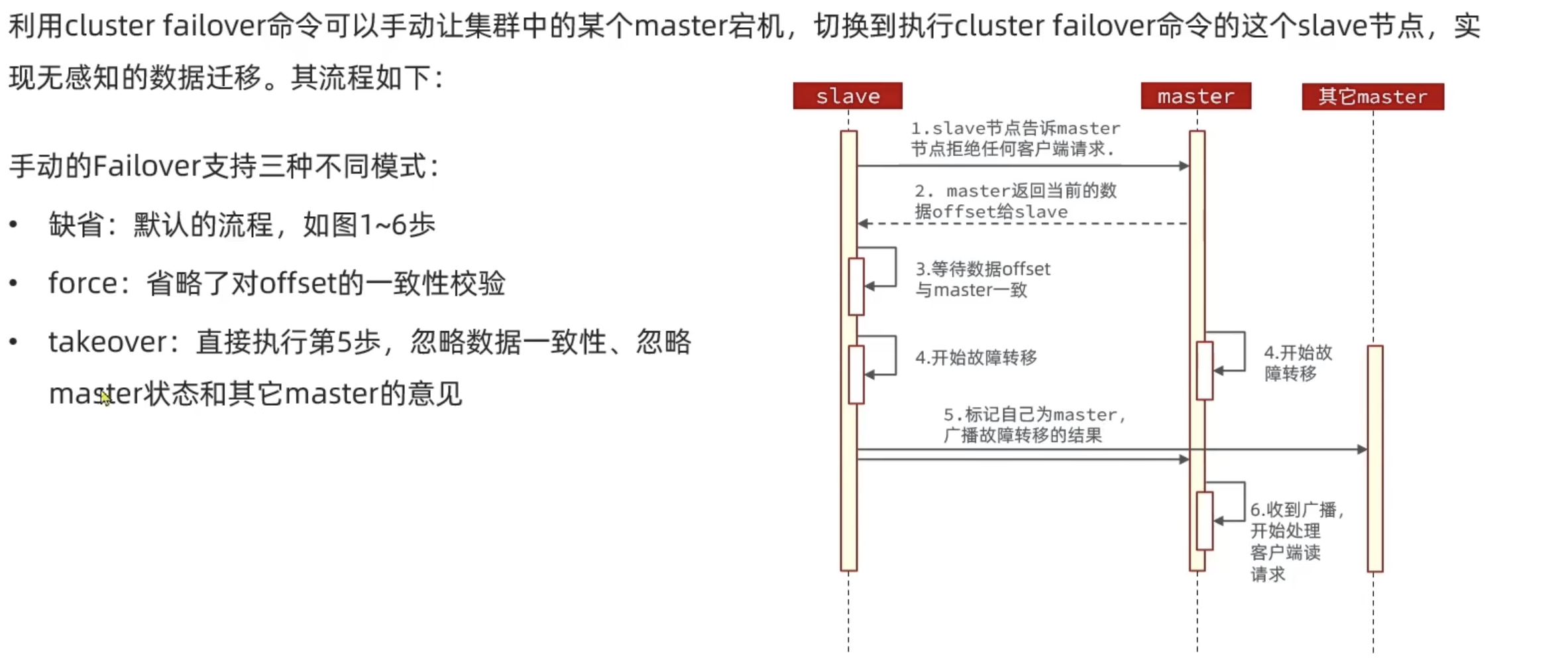
RedisTemplate访问分片集群

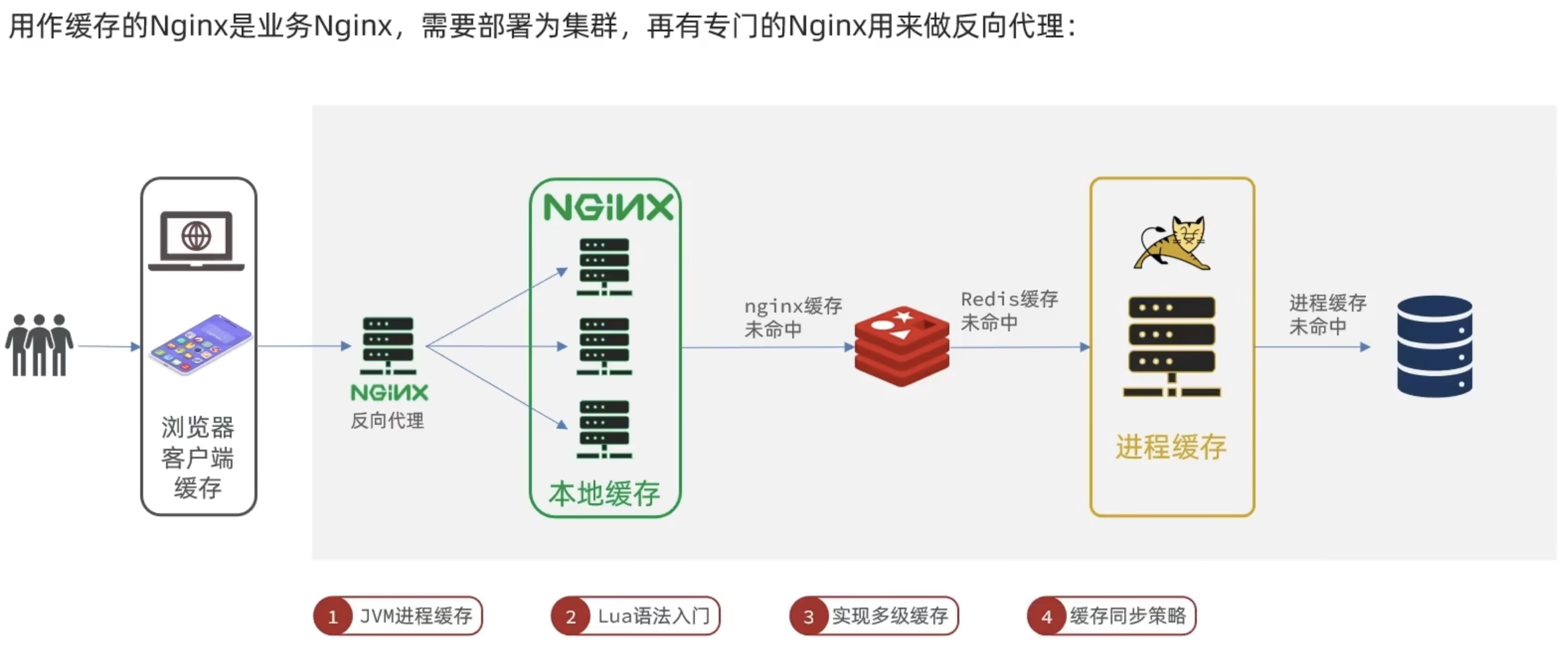
多级缓存
多级缓存方案
JVM进程缓存


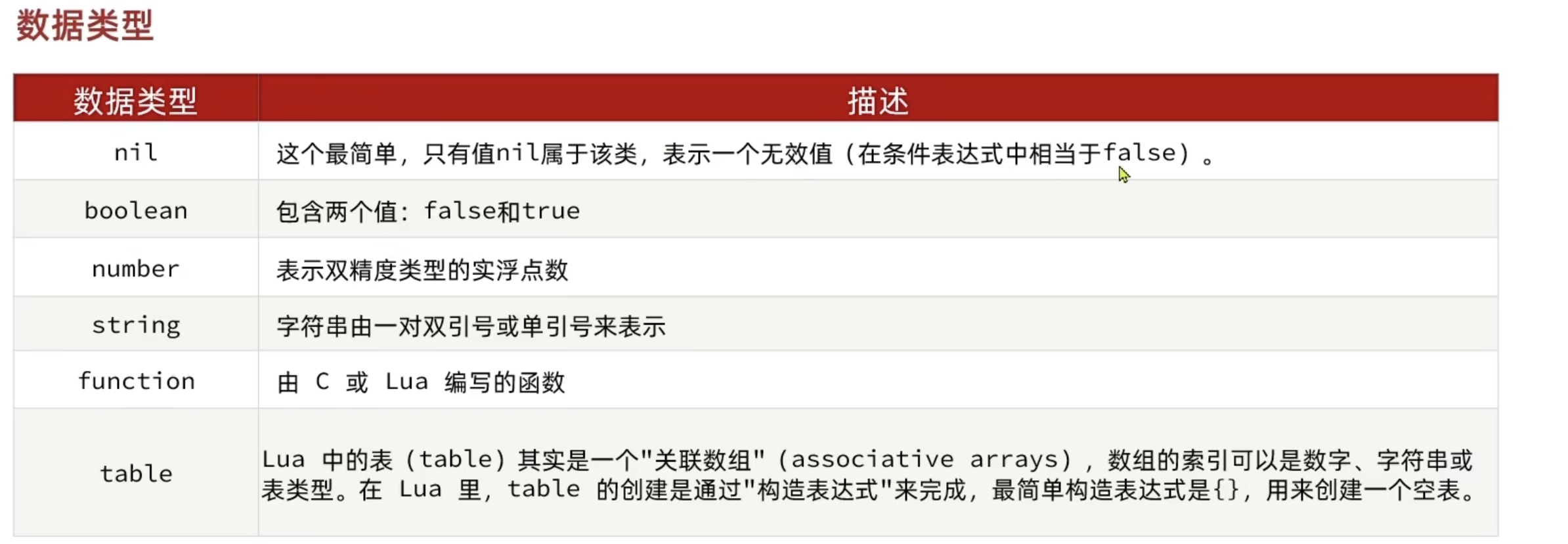
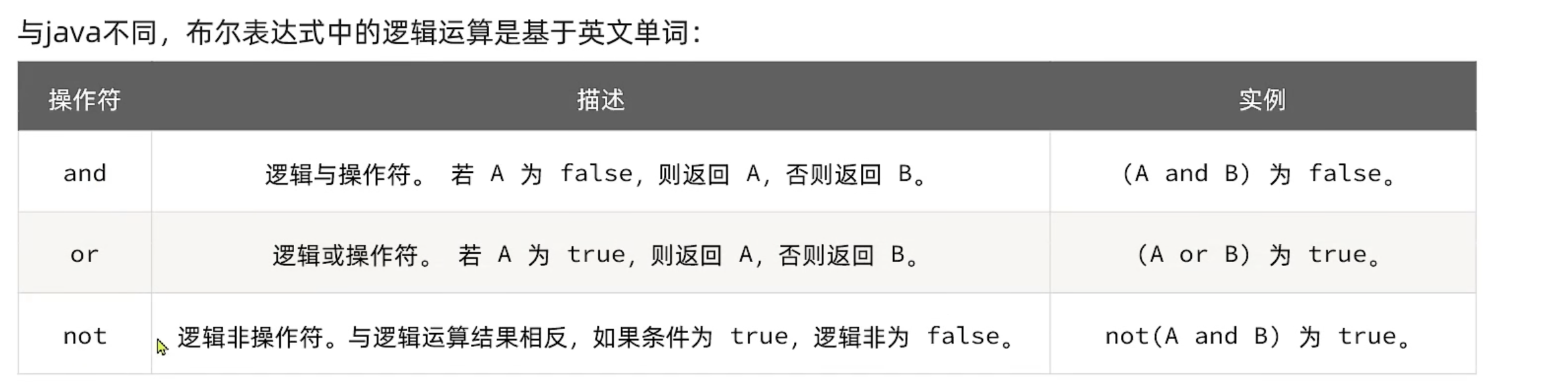
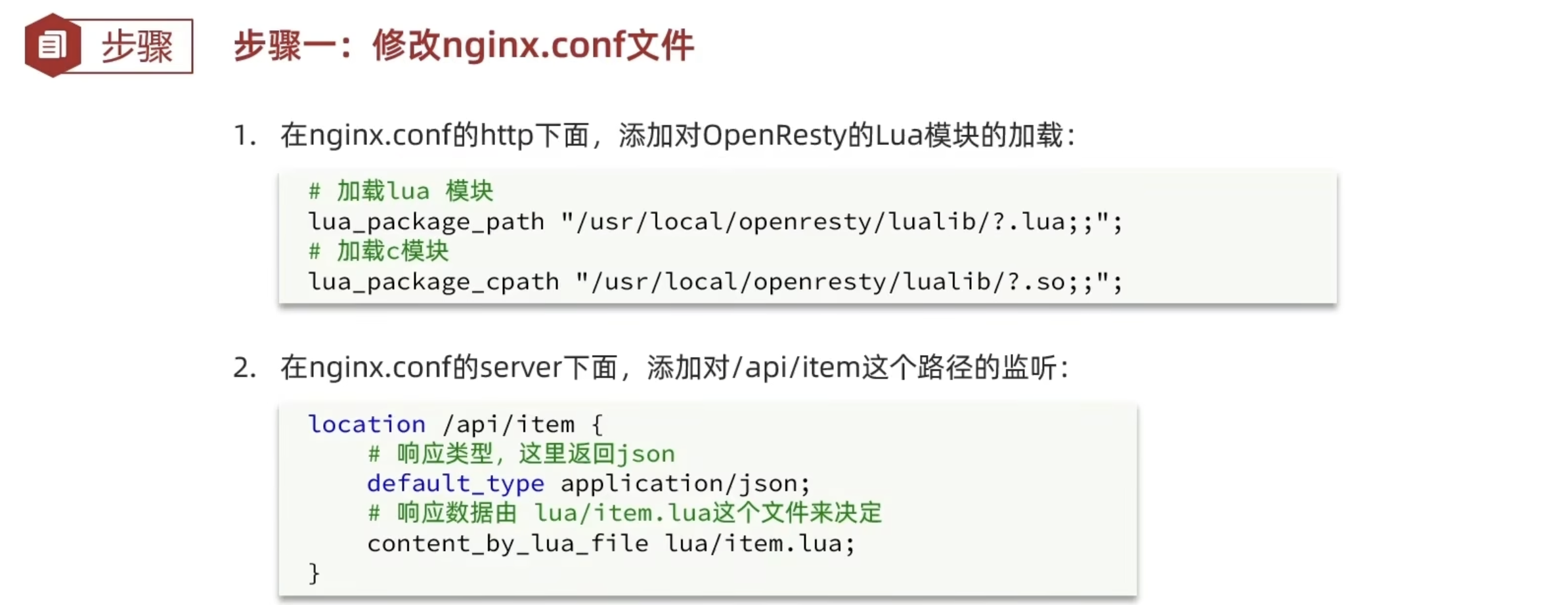
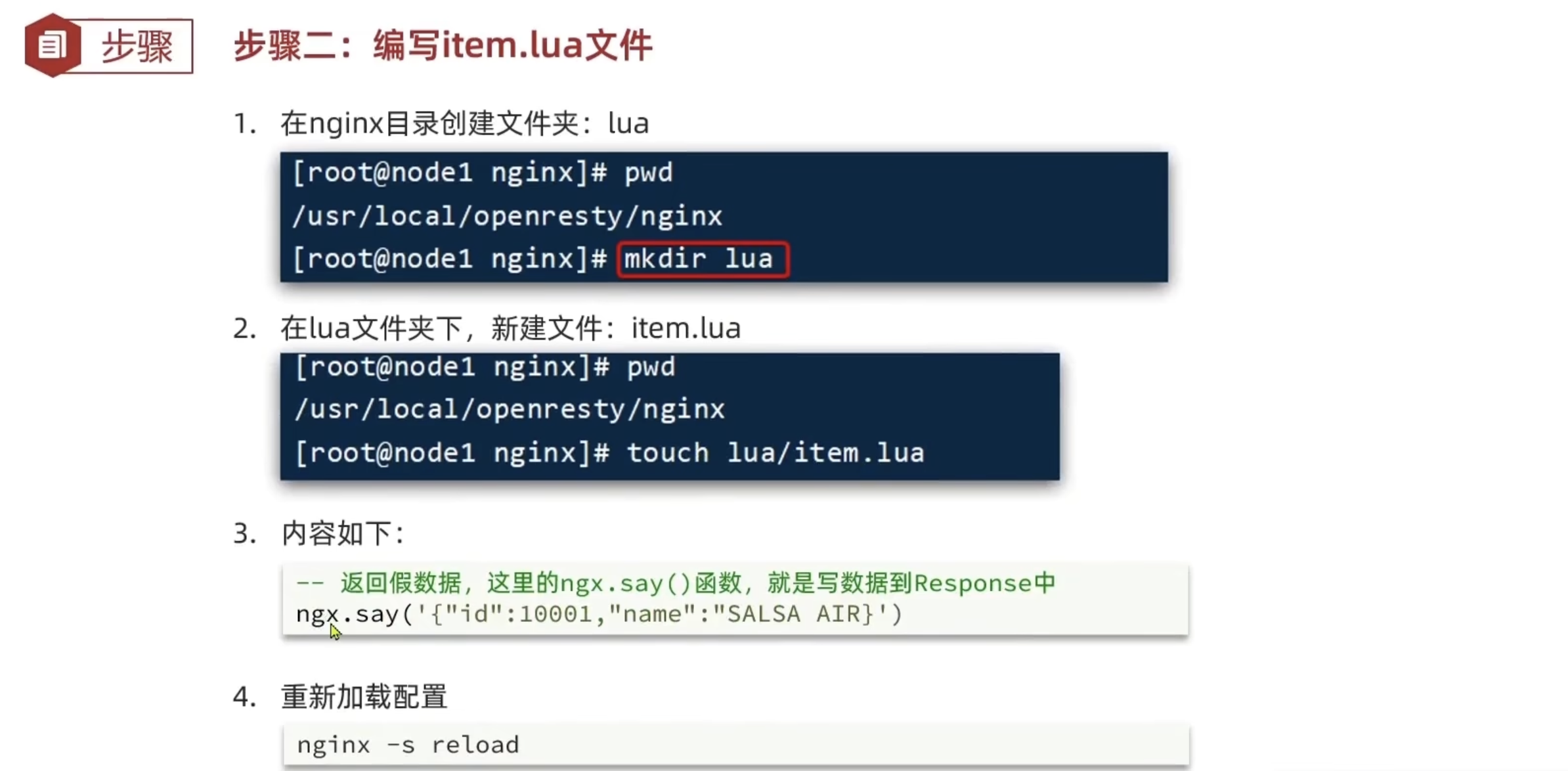
Lua语法入门

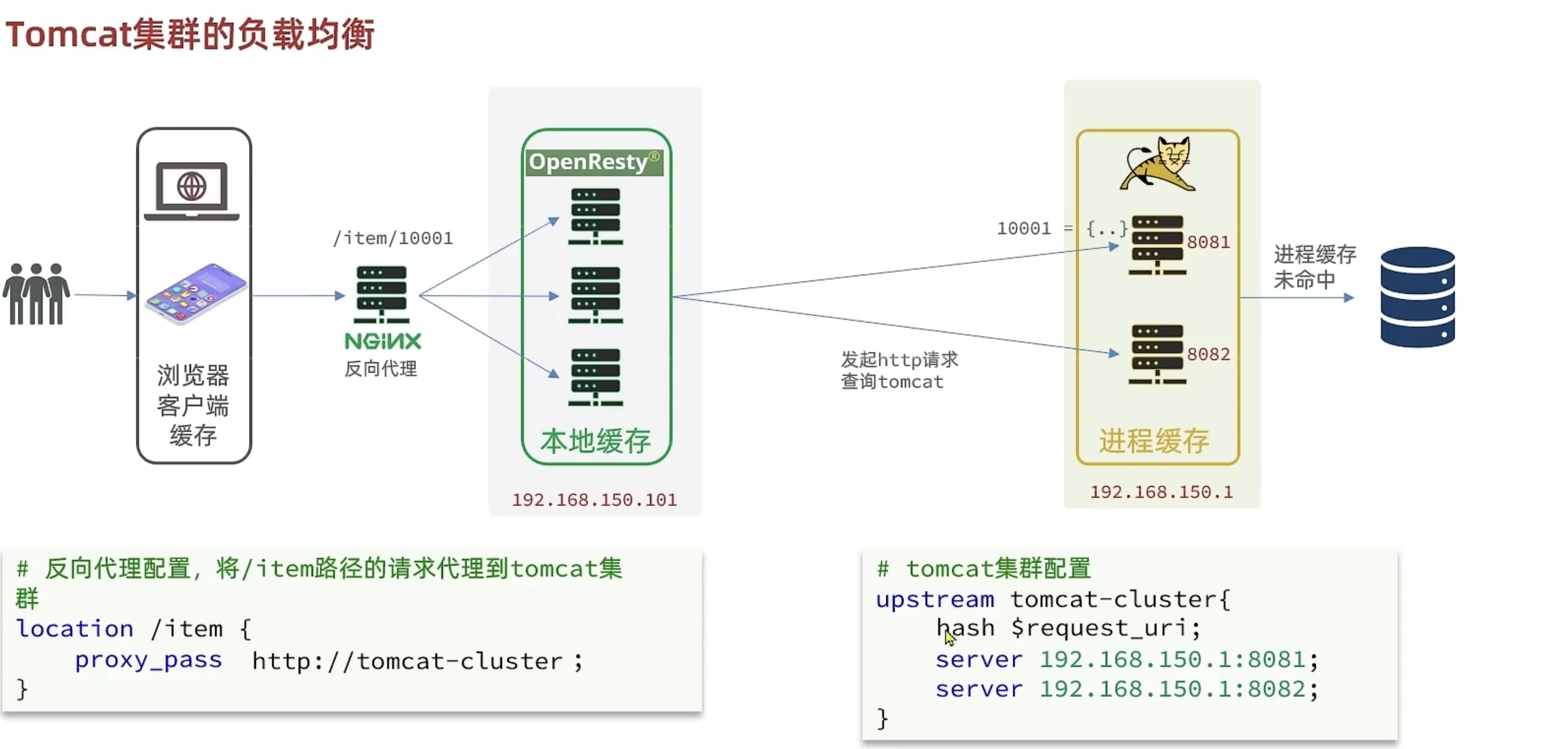
实现多级缓存



负载均衡
缓存预热

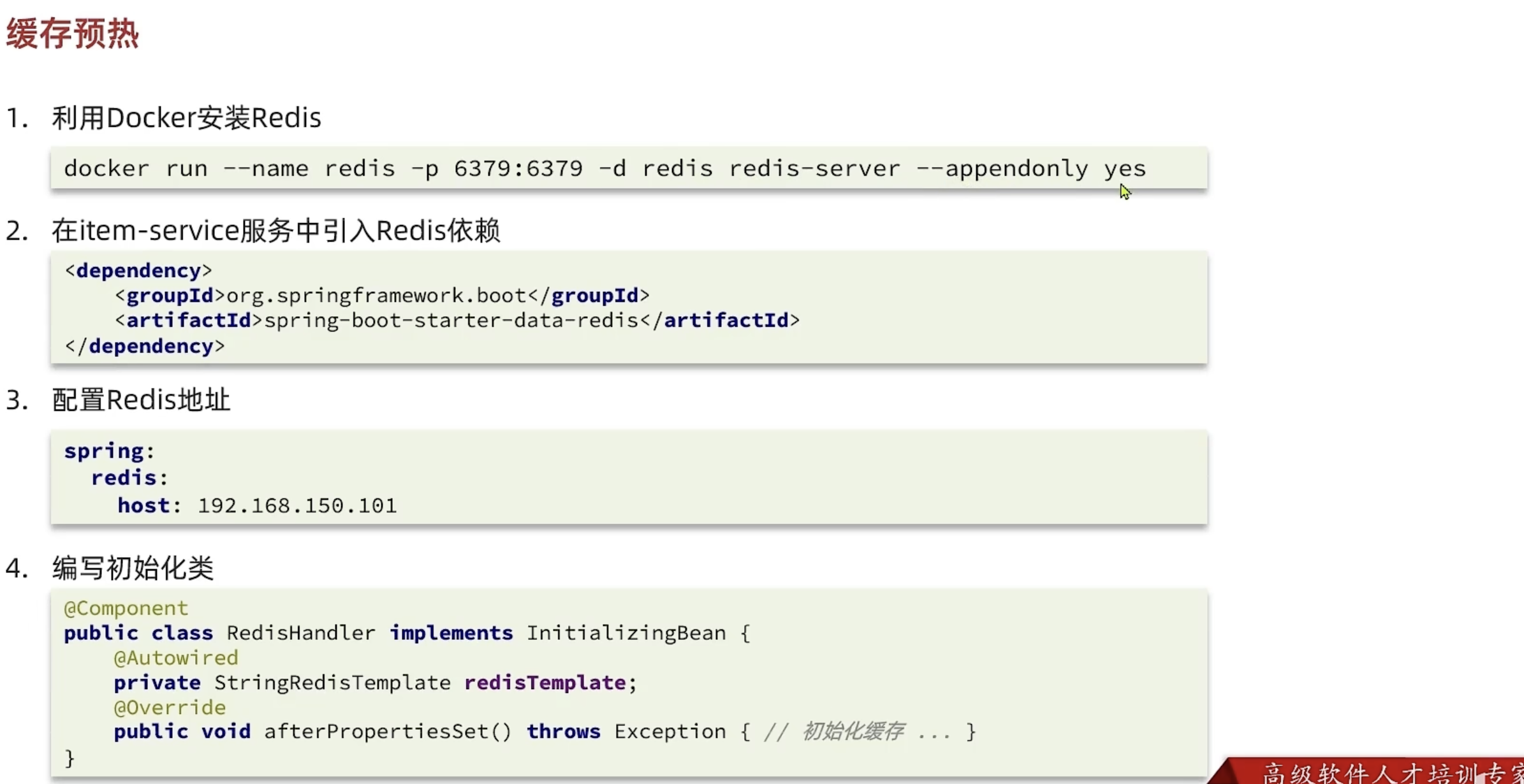
查询Redis



nginx本地缓存



缓存同步
缓存同步策略


Redis最佳实践
Redis键值设计
优雅的Key结构
Redis的Key虽然可以自定义,但是最好遵循以下几个最佳实践约定:
- 遵循基本格式:业务名称:数据名:id
- 长度不超过44字节
- 不包含特殊字符
优点
key是String类型,底层编码包含int,embstr和raw三种。embstr在小于等于44字节使用,采用连续内存存储,内存占用更小
避免BigKey
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
- Key本身的数据量过大:一个String类型的Key,它的大小为5MB
- Key中的成员数过多:一个ZSet类型的Key,它的成员数量为10000个
- Key中成员的数据量过大,一个Hash类型的Key,它的成员数量虽然只有1000个,但这些成员的Value总大小为100MB
推荐值:
单个Key的value小于10KB
对于集合类型的Key,建议成员数量小于1000
危害

如何发现BigKey

如何删除BigKey
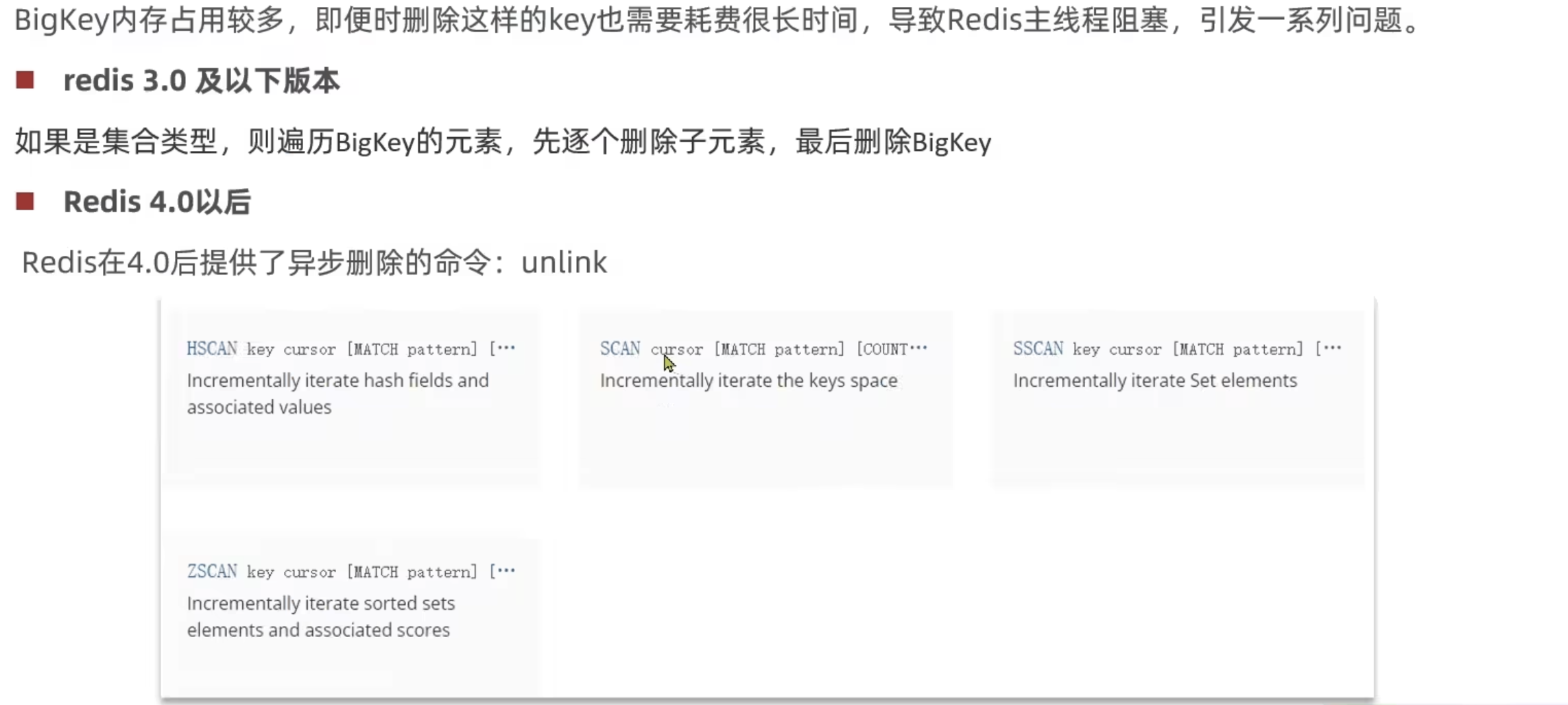
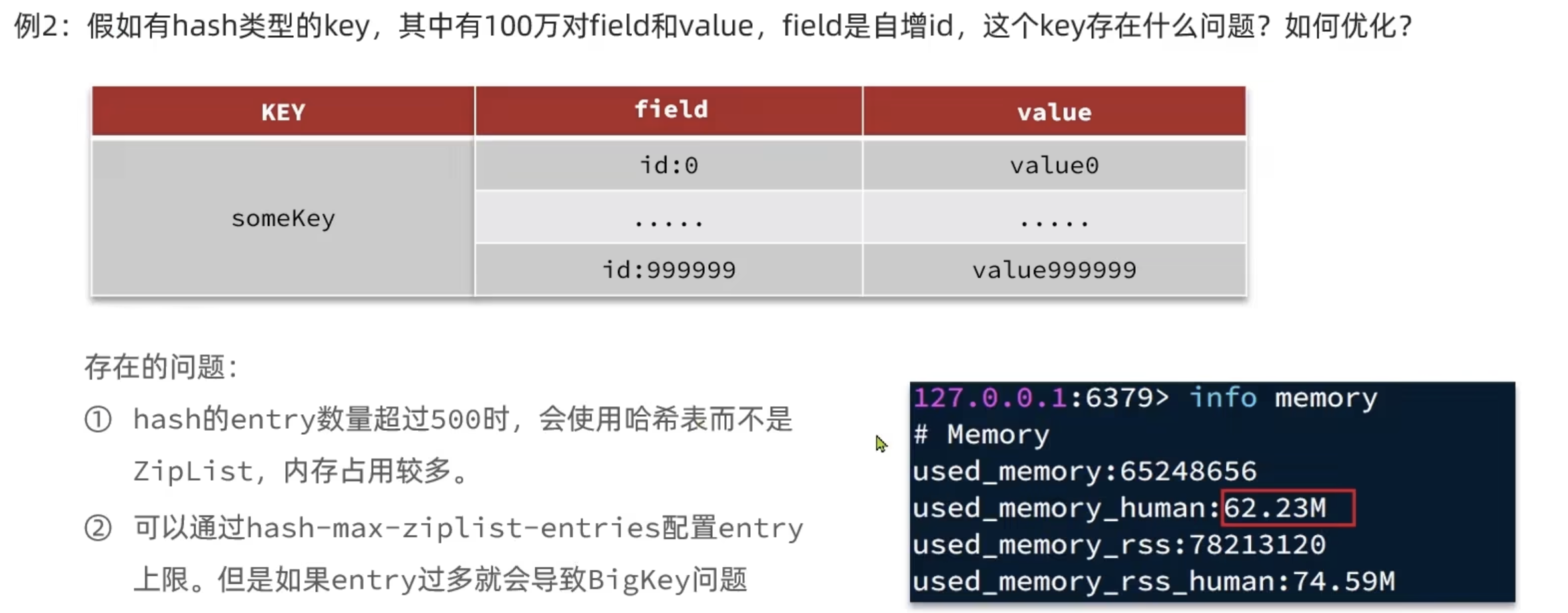
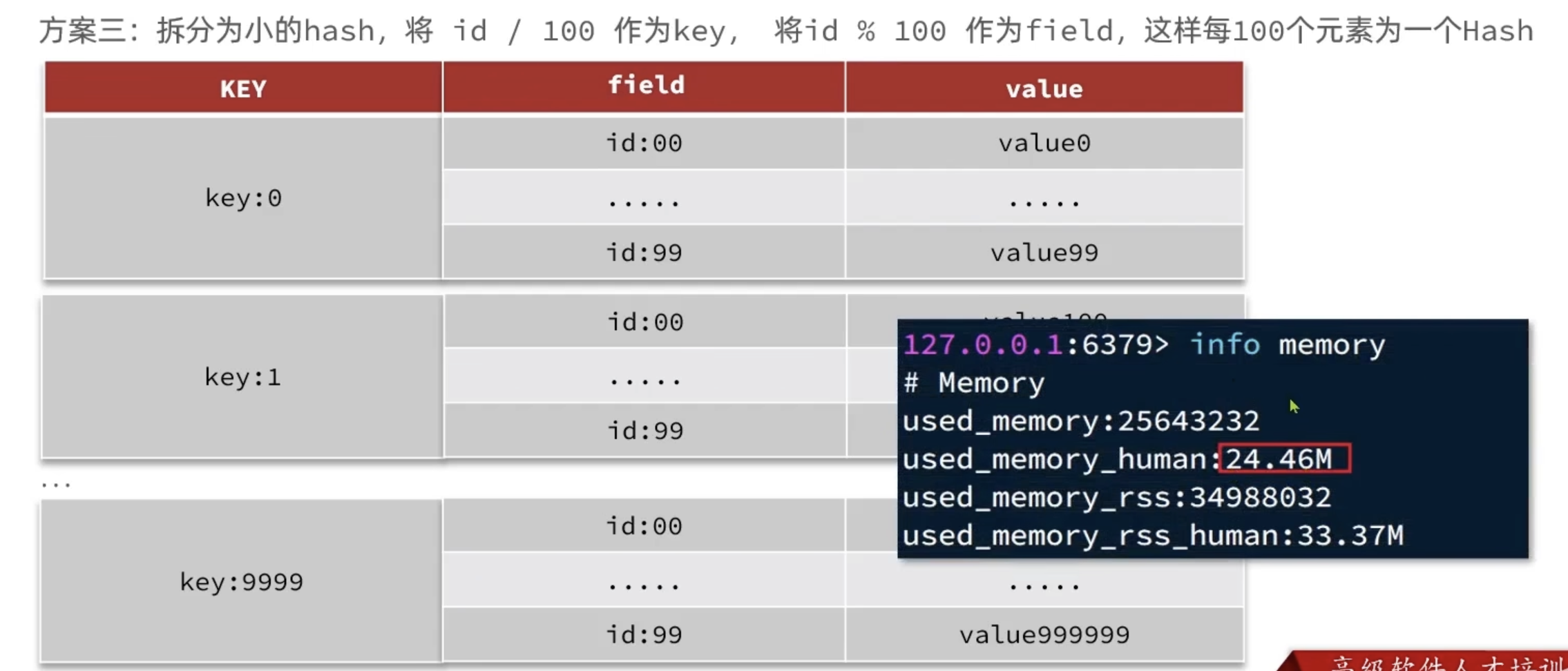
恰当的数据类型

批处理优化
Pipeline
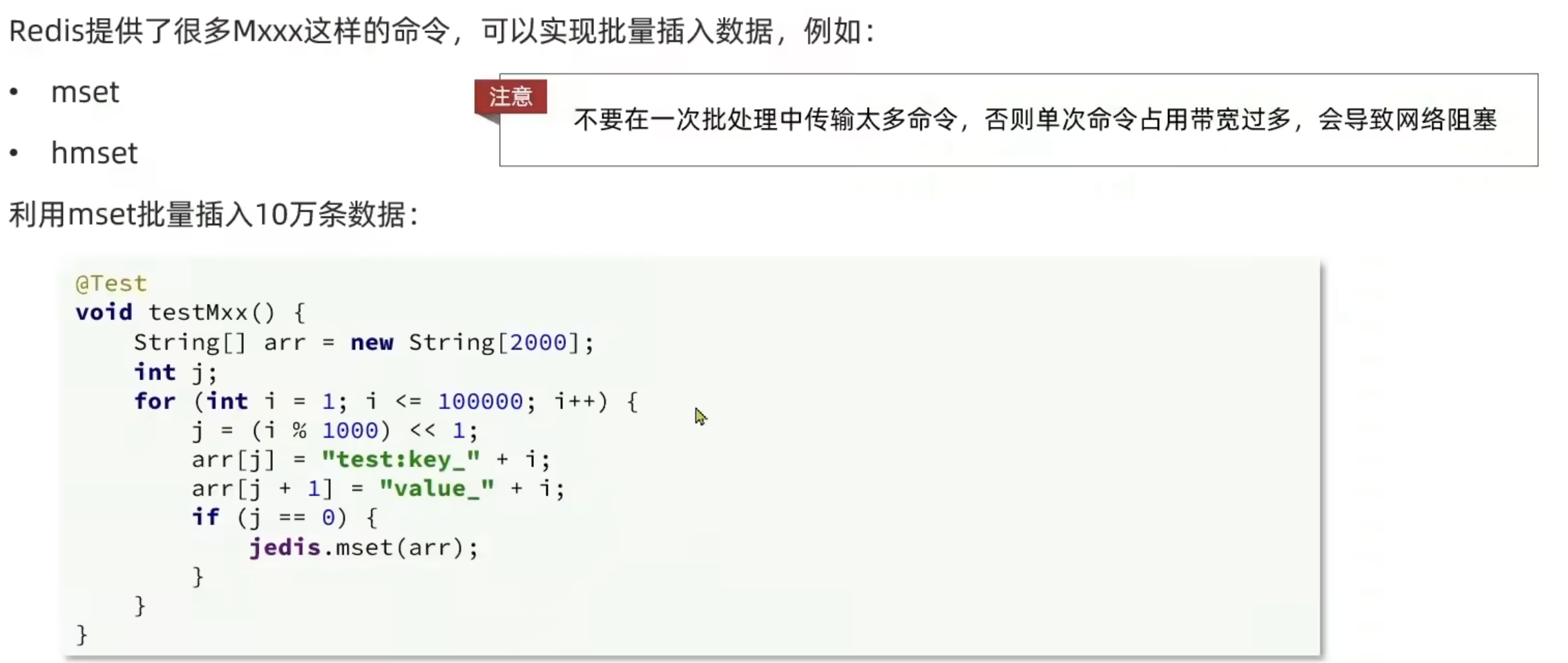

原生的M操作是原子的,而Pipeline的多个命令之间不具备原子性,即会根据到达先后顺序进行操作
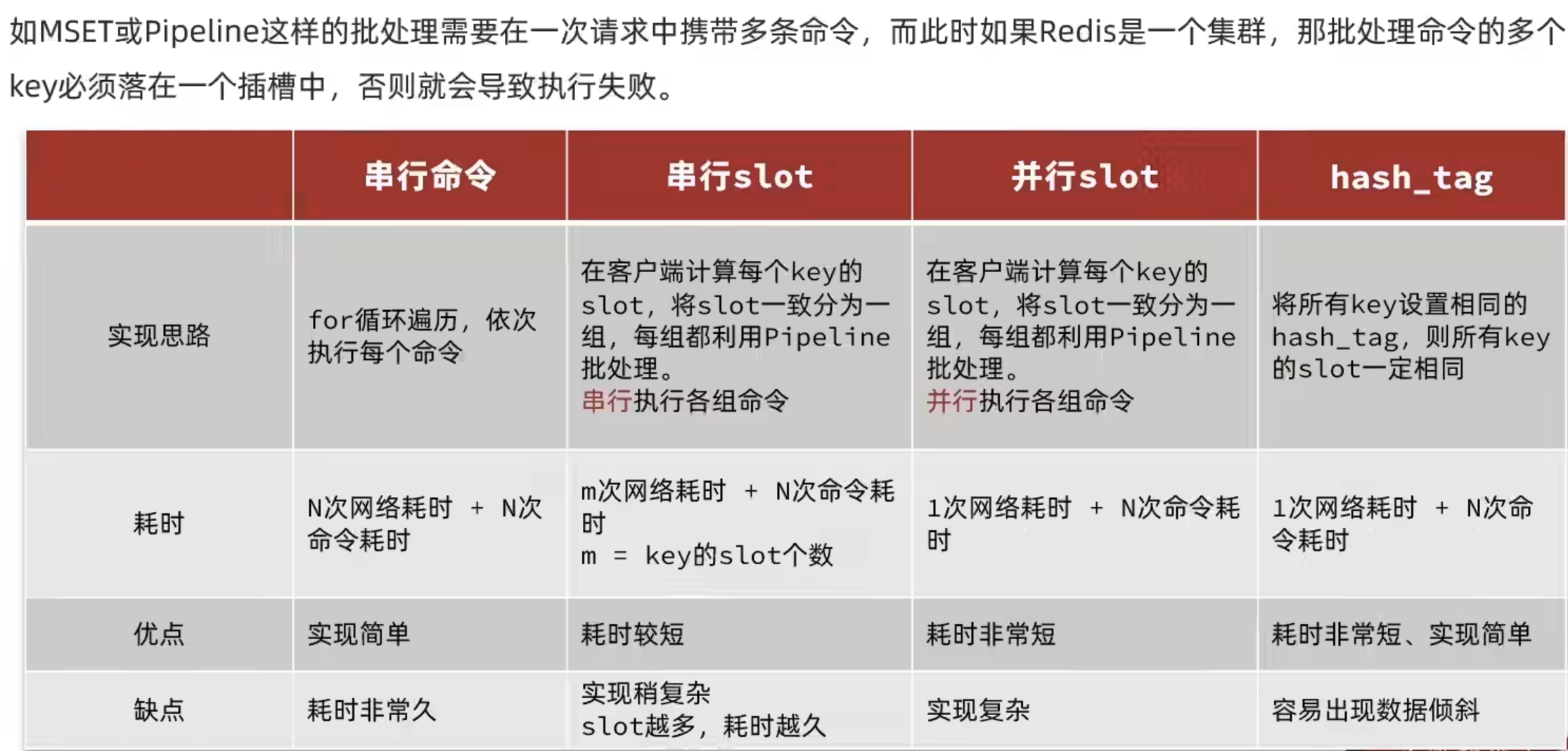
集群下的批处理
服务端优化
持久化配置

慢查询
Redis执行时耗时超过某个阈值的命令,称为慢查询


命令及安全配置

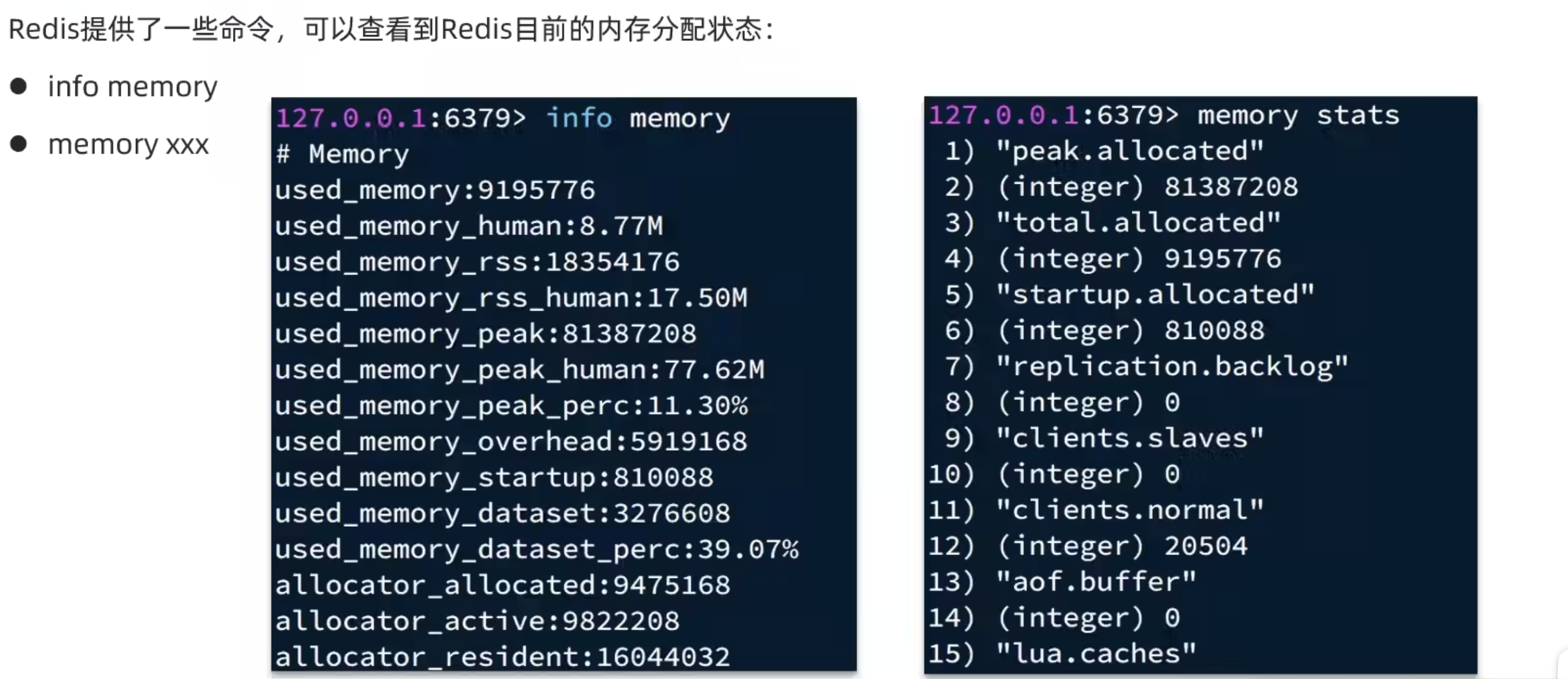
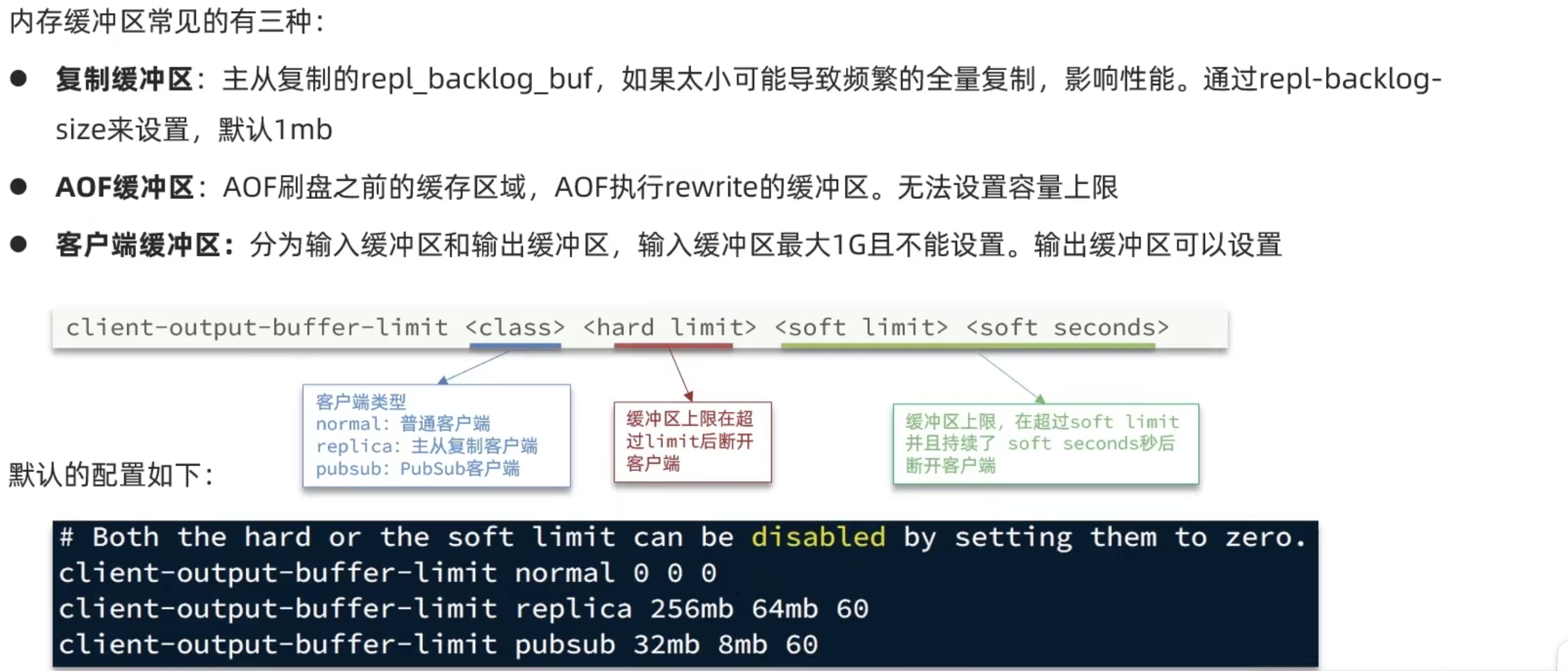
内存配置

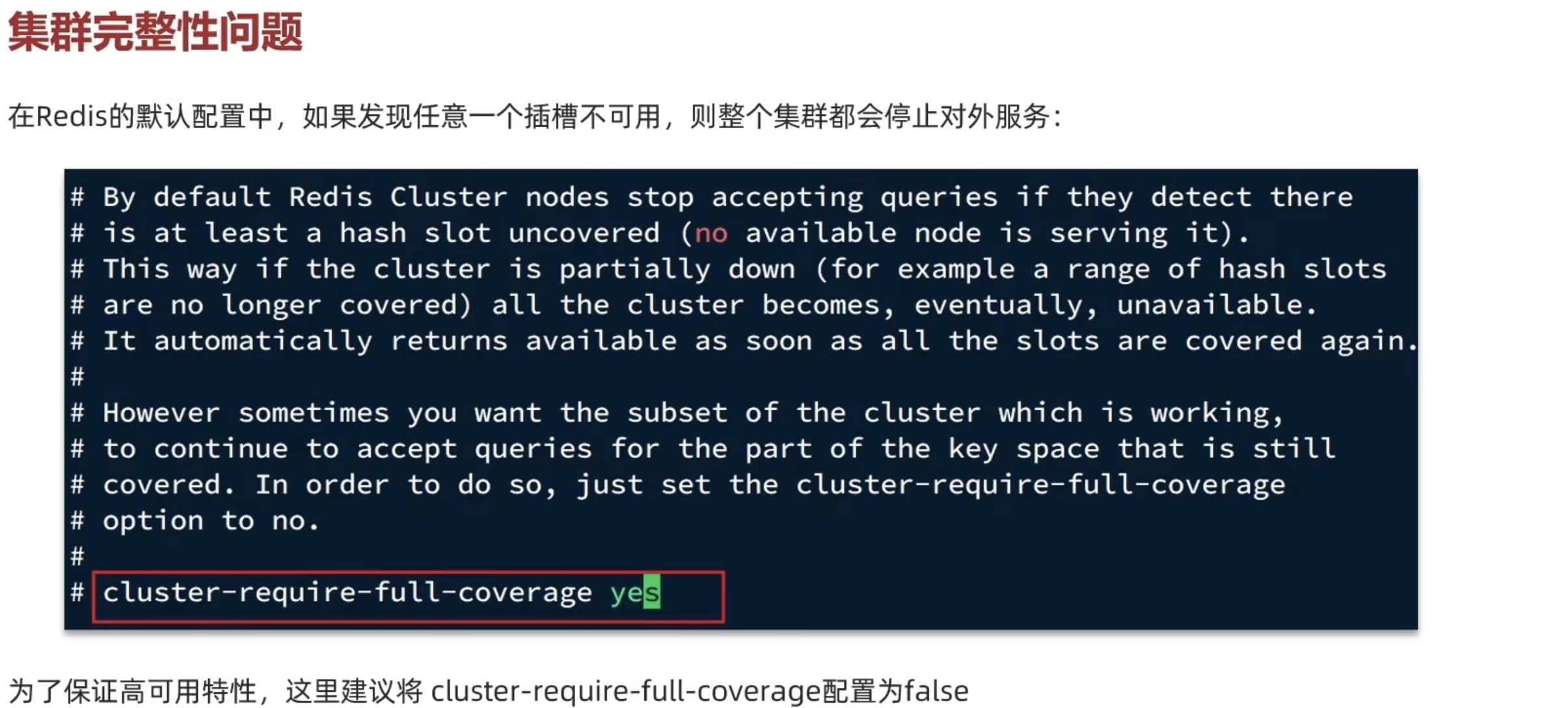
集群最佳实践


原理
数据结构
动态字符串(Simple Dynamic String)
Redis中保存的Key是字符串,Value往往也是字符串或字符串集合,字符串是Redis最常见的一种数据结构
不过Redis没有用C语言自带的字符串,因为其存在以下问题:
- 获取字符串长度需要计算
- 非二进制安全,字符串须以'\0'结尾,因此'\0'不能使用
- 不可修改



IntSet
Redis中set集合实现的一种方式,基于整数数组来实现,具备长度可变,有序的特征

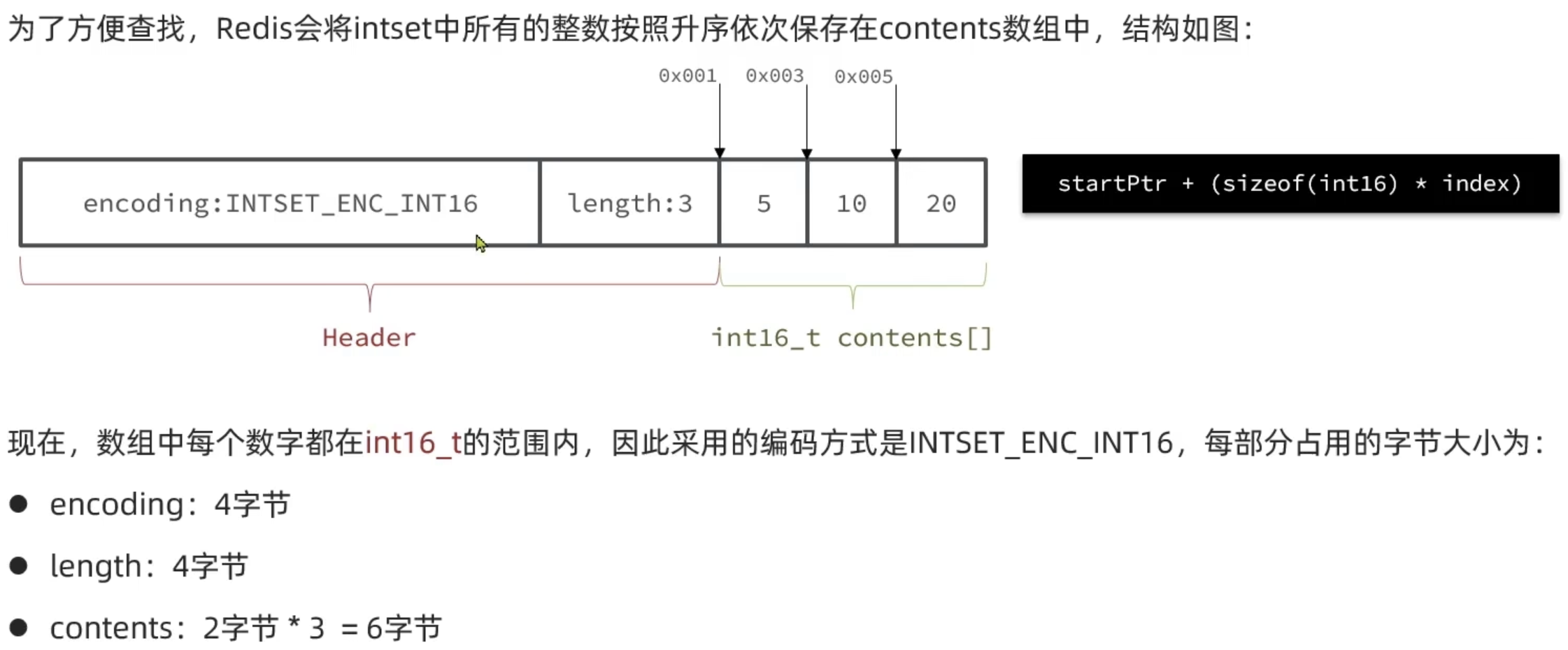
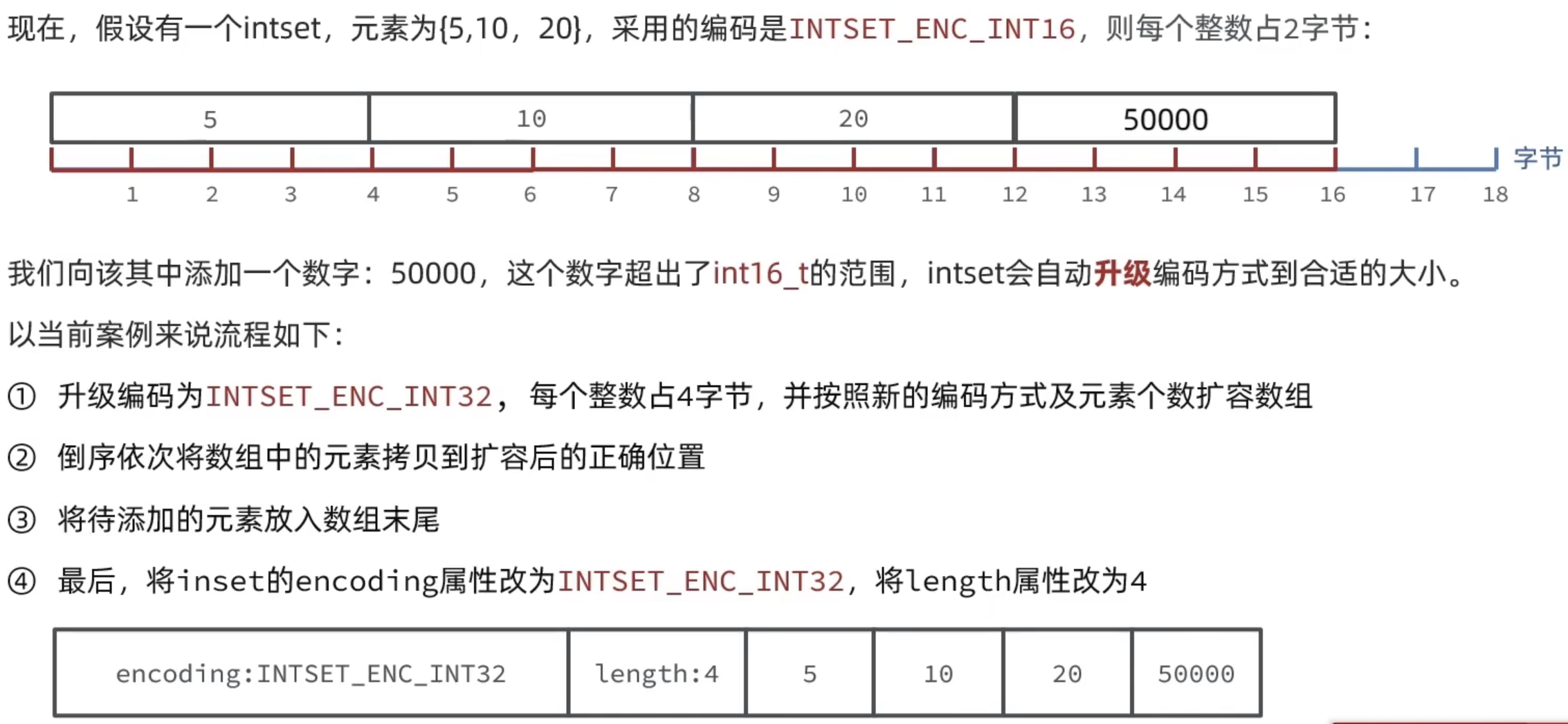

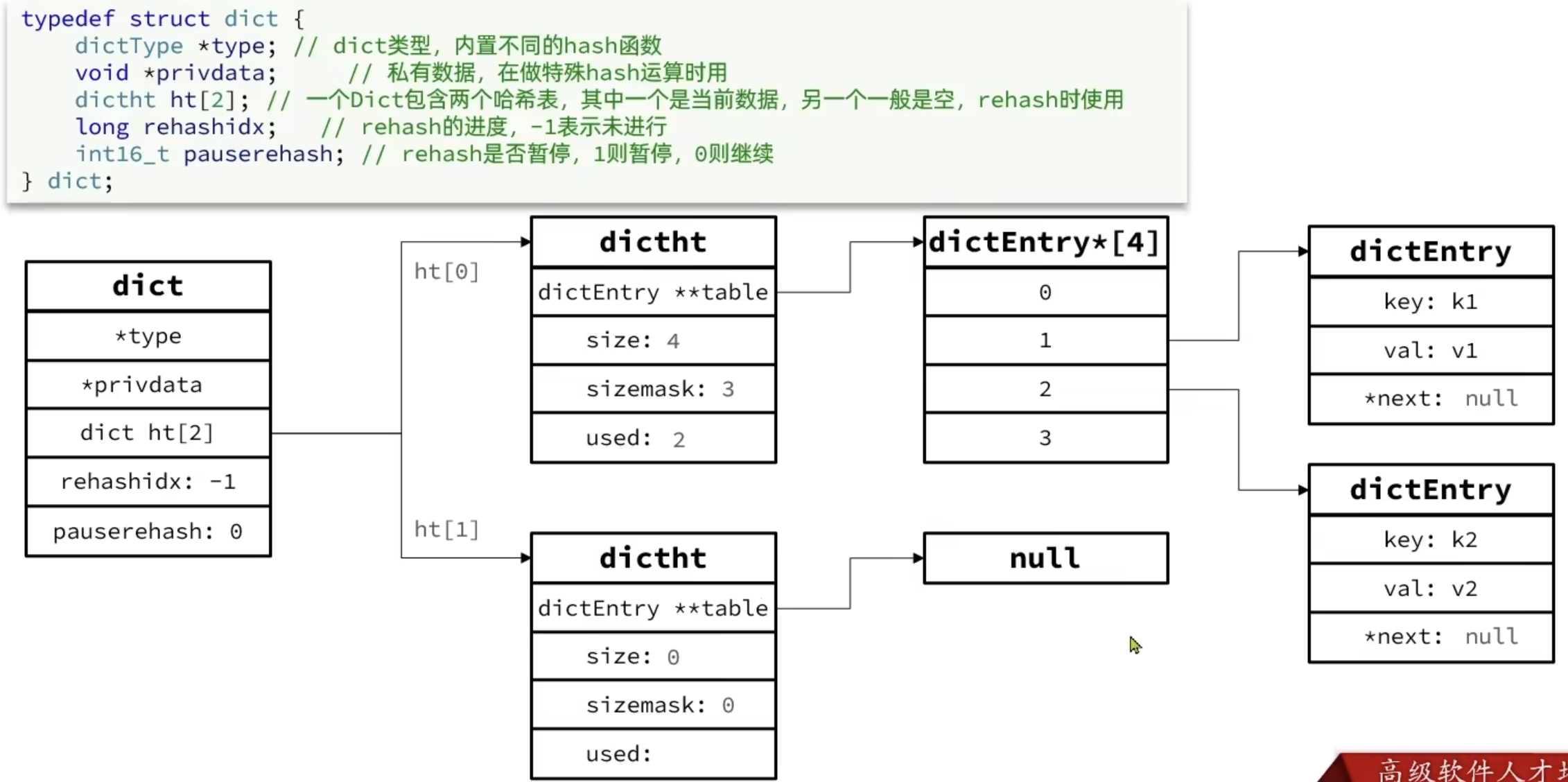
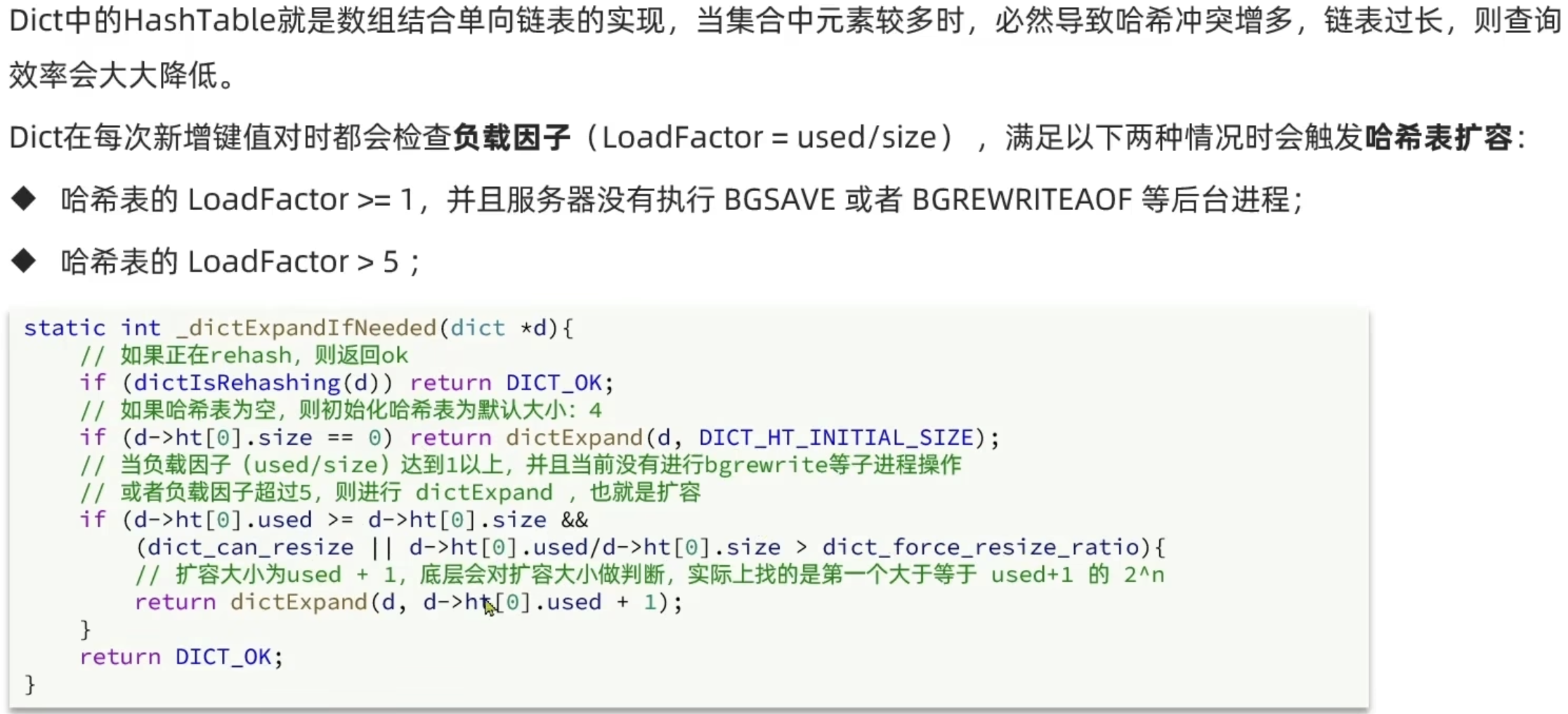
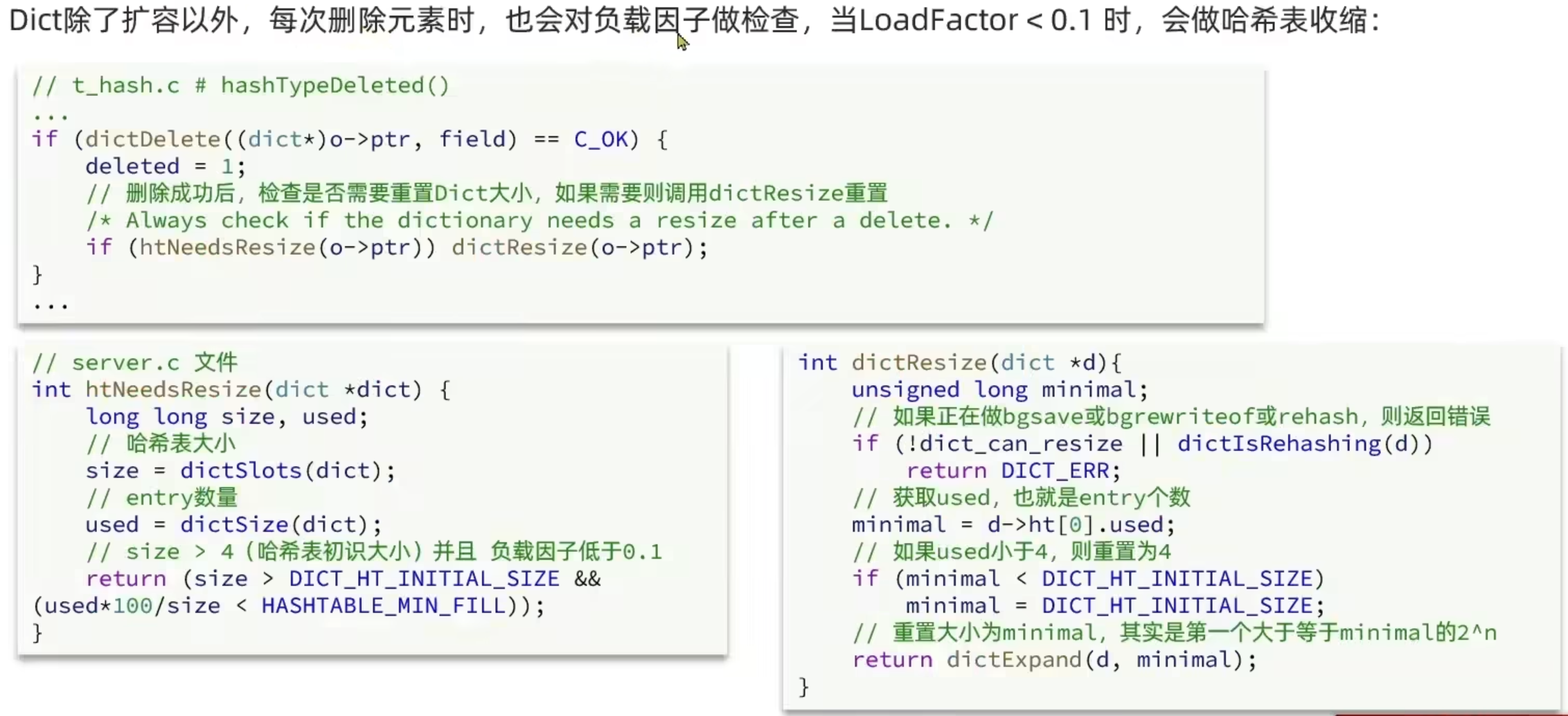
Dict
字典包含哈希表,哈希表包含哈希节点


ZipList
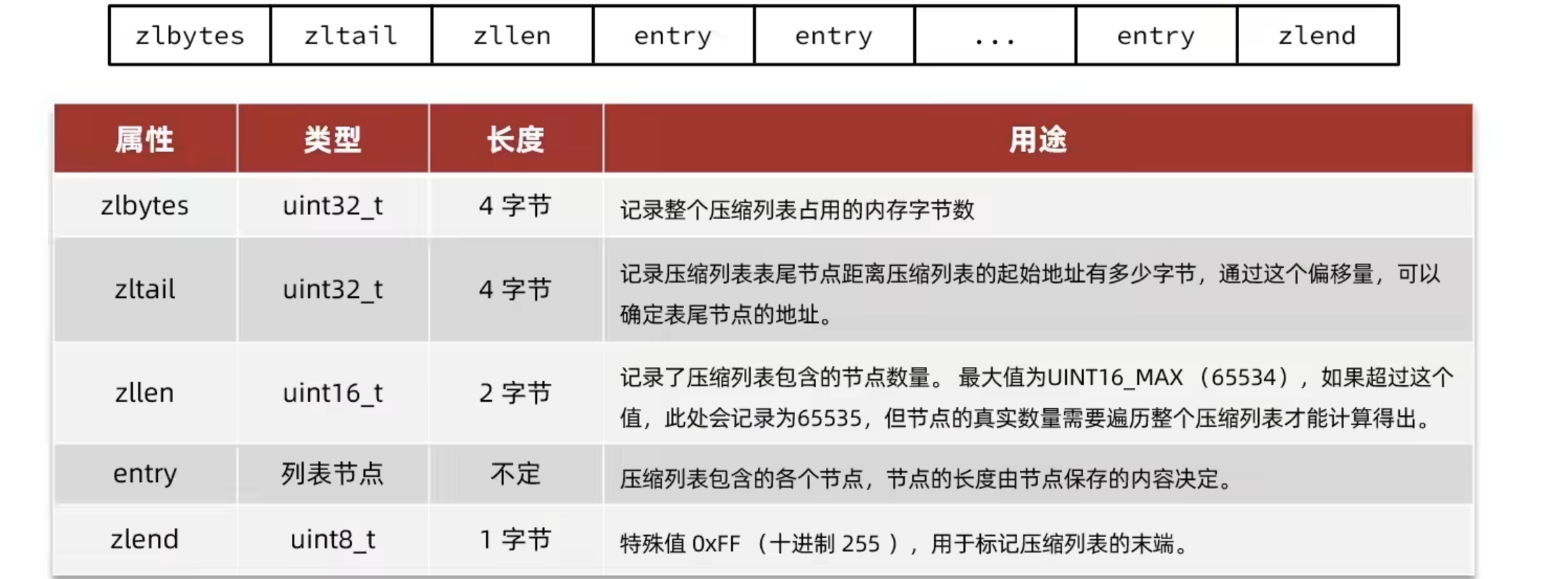
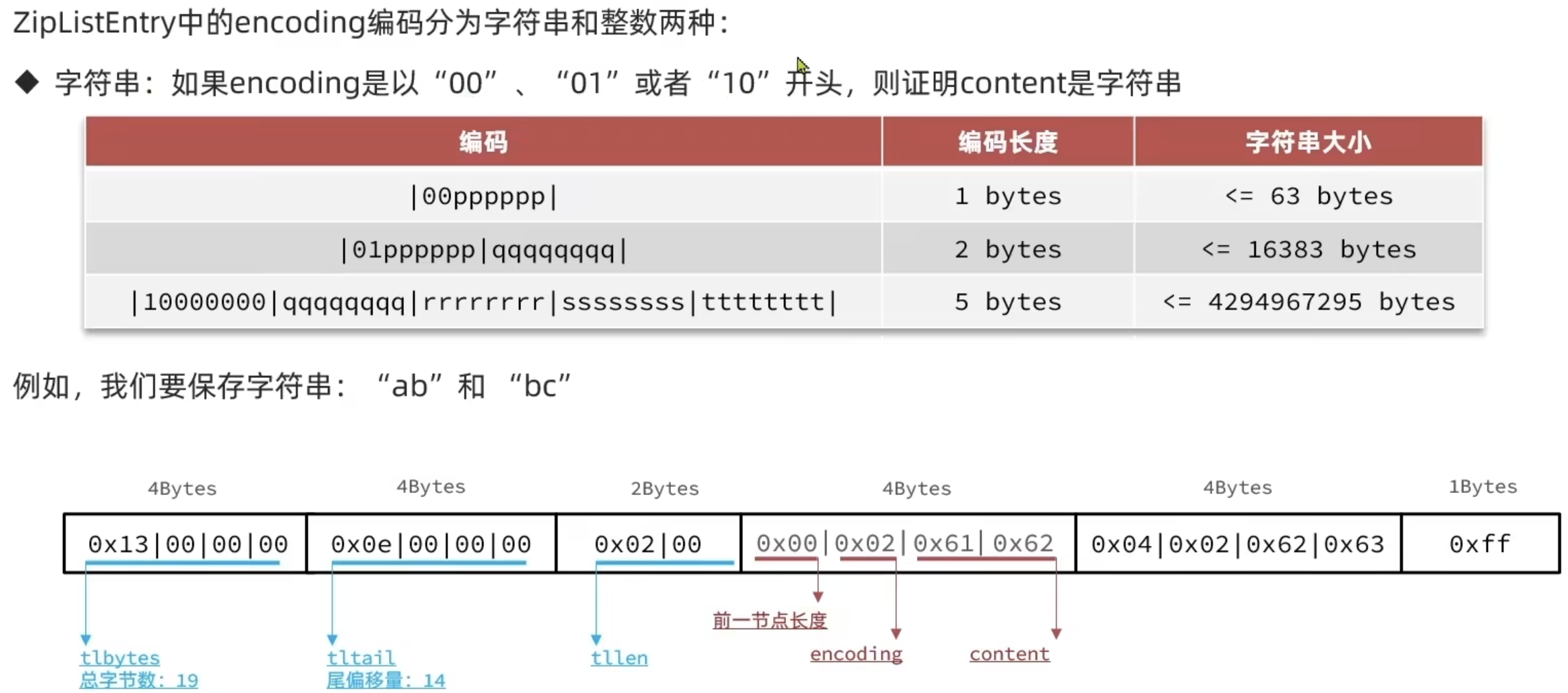
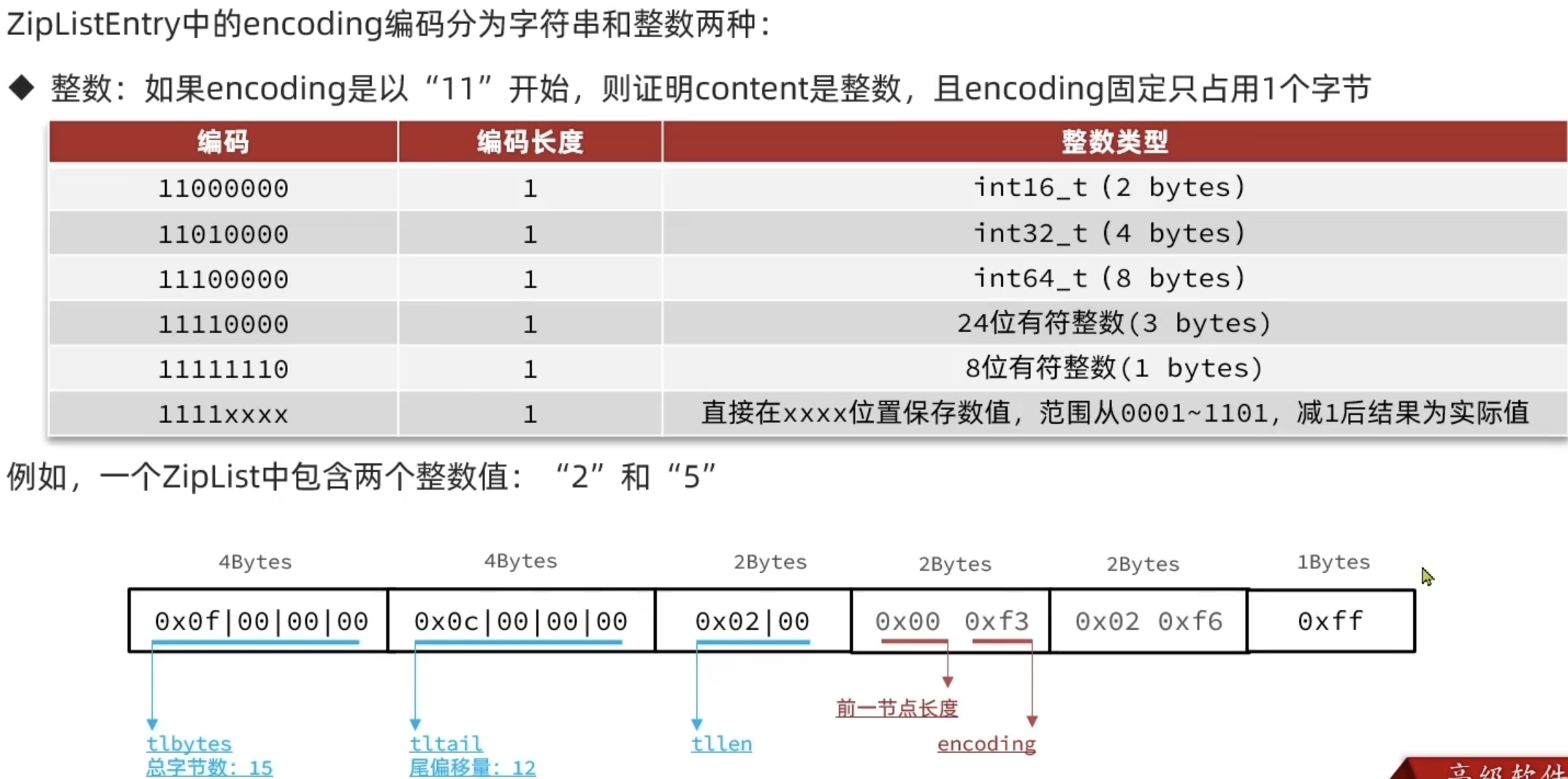
ZipList是一种特殊的双端链表,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入弹出操作,并且该操作的时间复杂度为 O ( 1 ) O(1) O(1)

级联更新问题

最坏情况下级联更新的时间复杂度是 O ( N 2 ) O(N^2) O(N2)
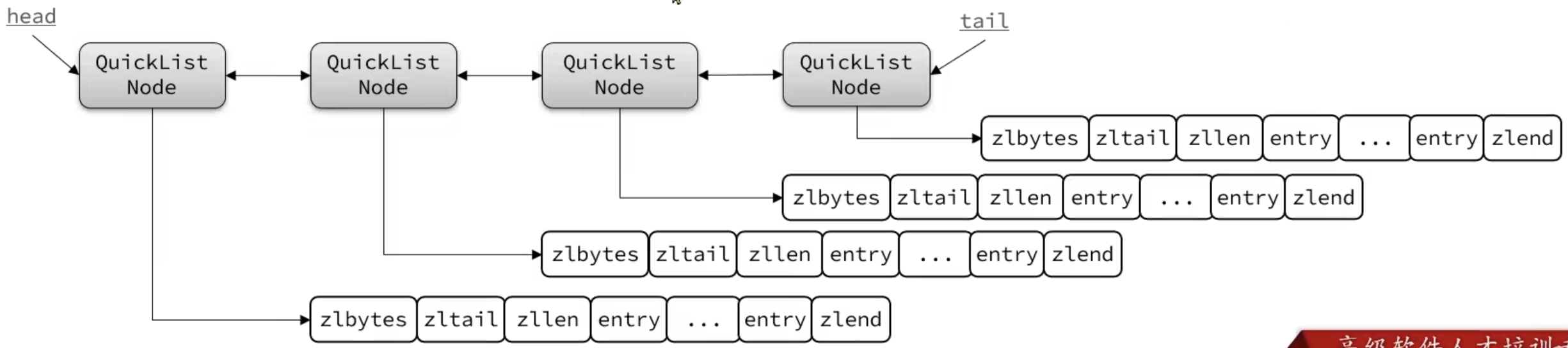
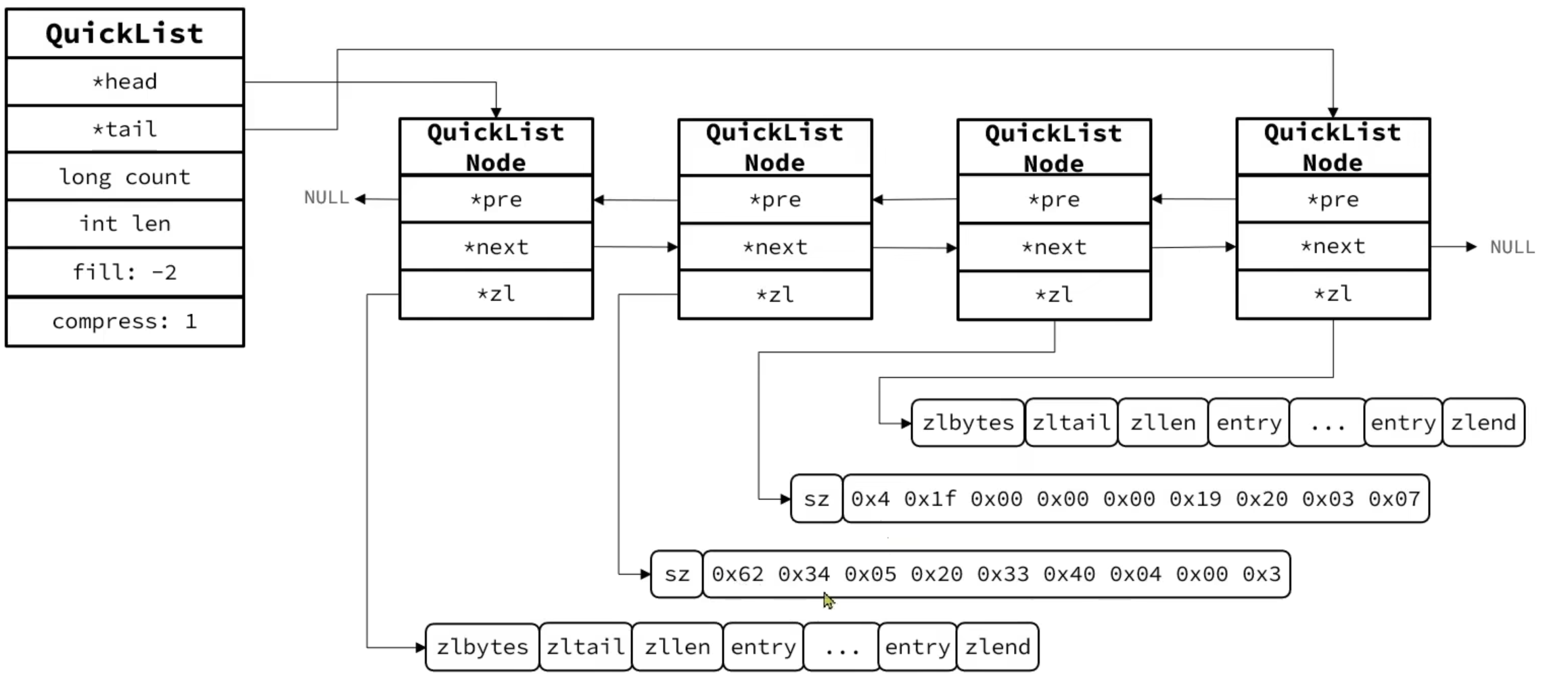
QuickList
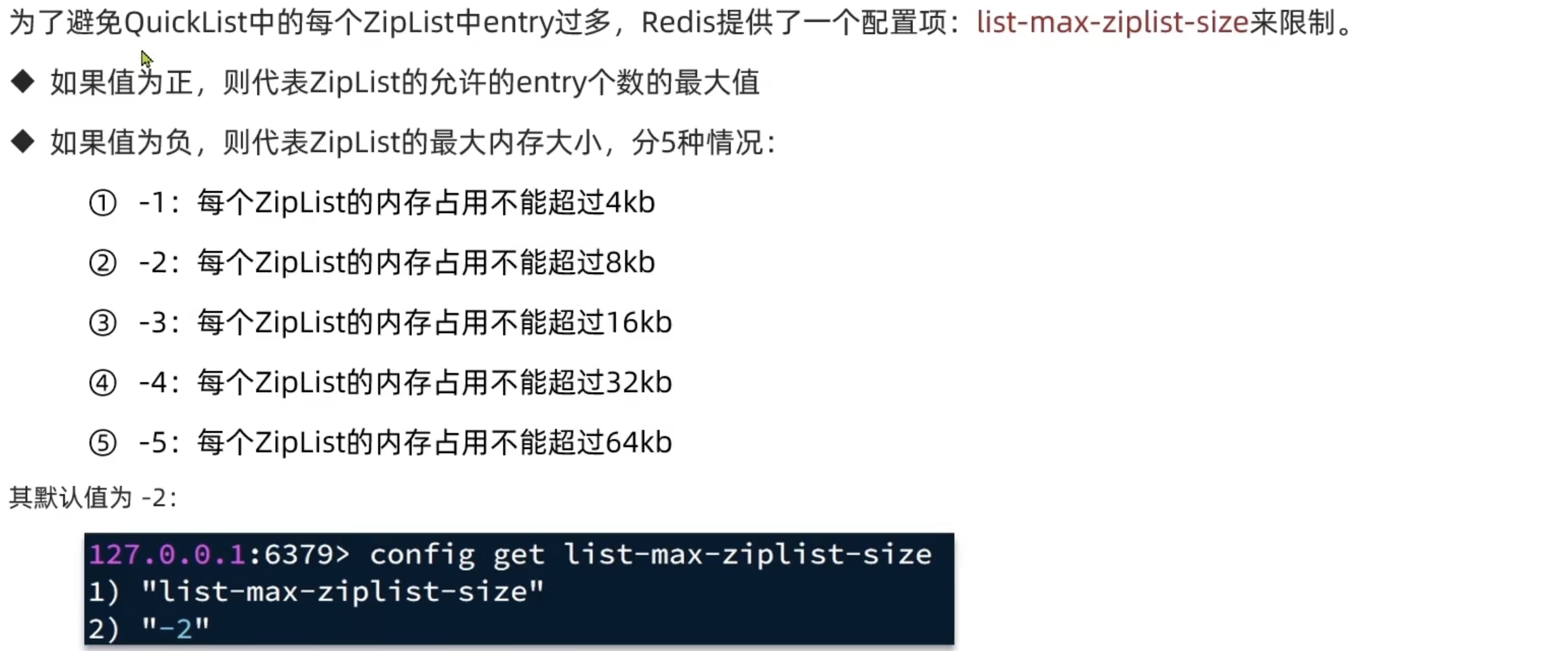
QuickList是一个双端链表,其中每个节点是ZipList

SkipList
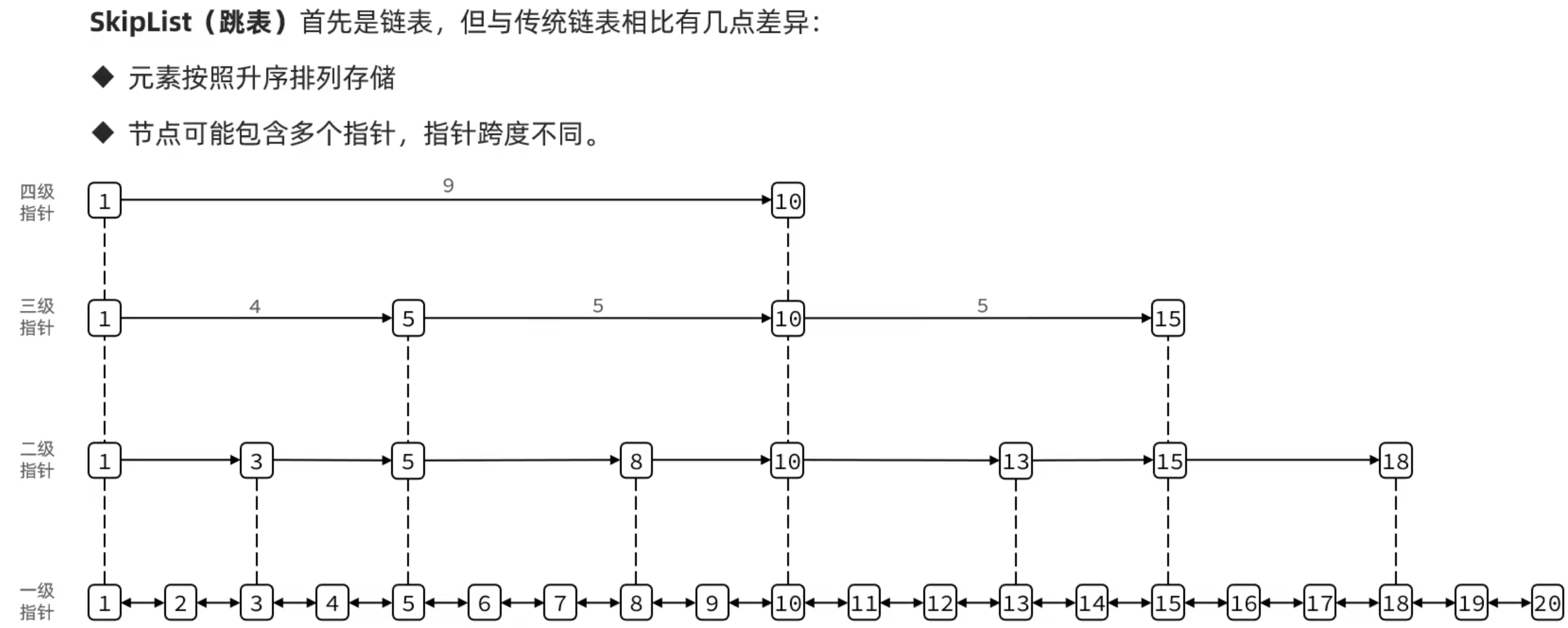
跳表在新增节点时,先找到节点的插入位置,然后通过随机函数为新节点增加一个层高K,如果K大于当前最大层高,则头节点会增加到K层, 然后连接到新节点的K层

RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis 对象
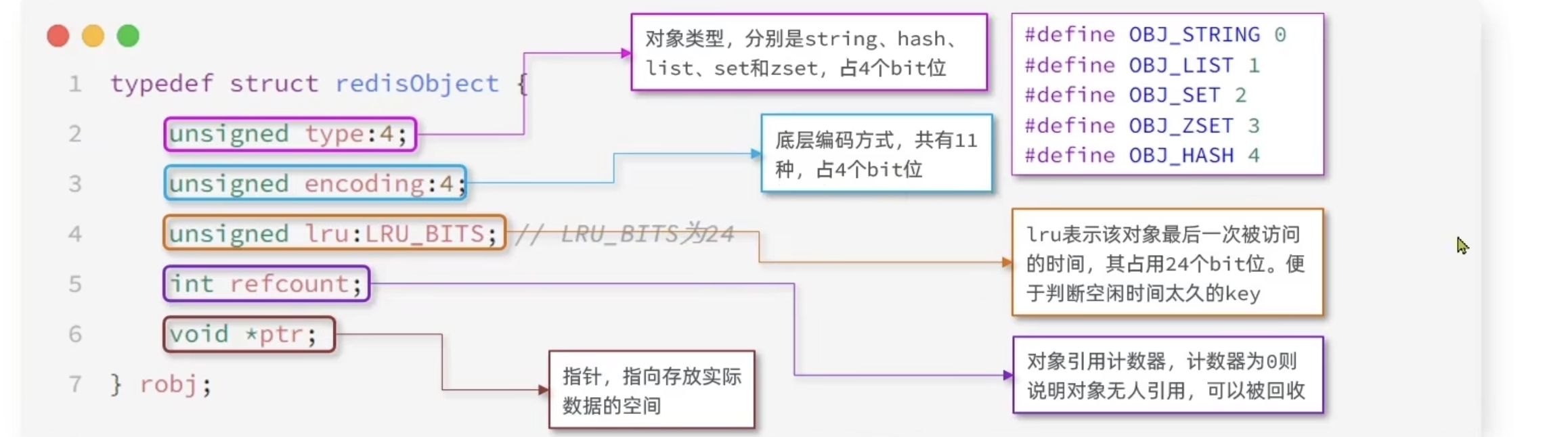
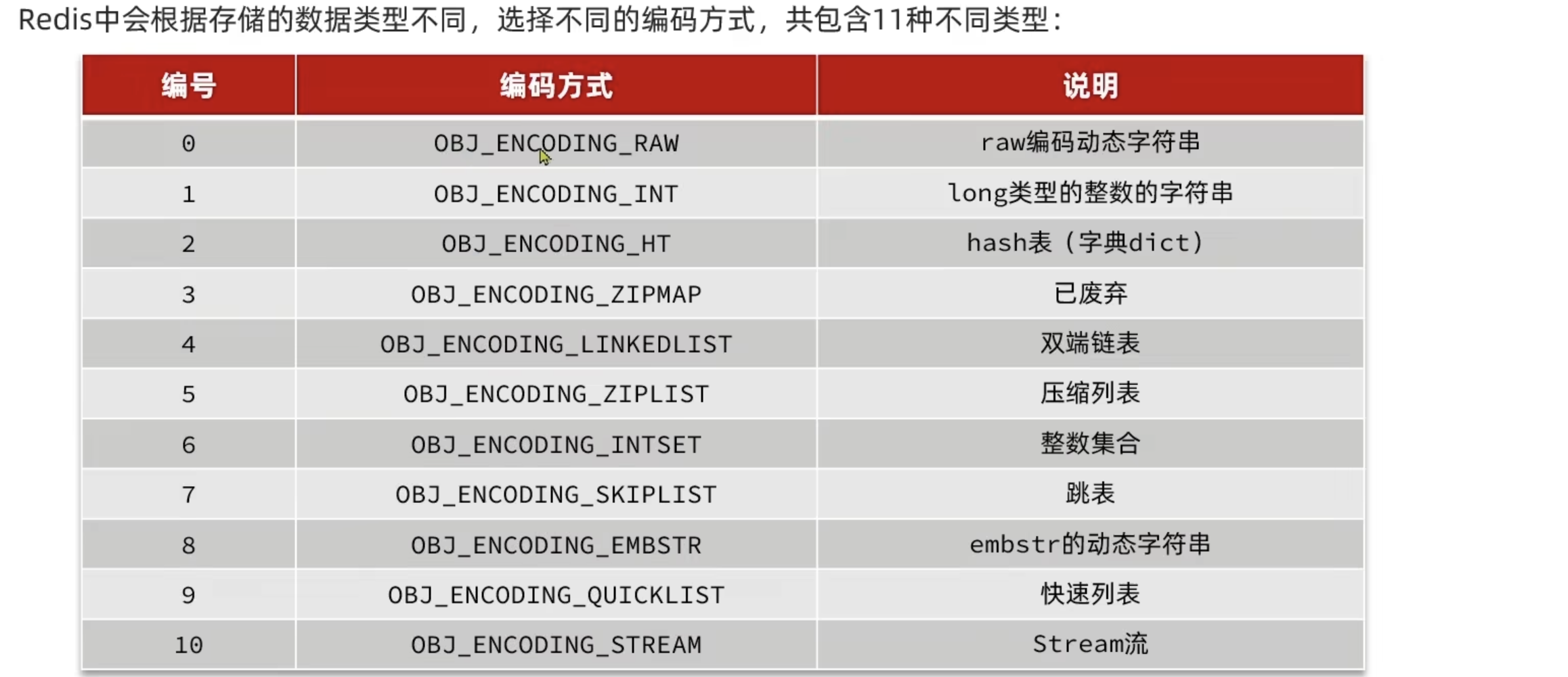
编码方式
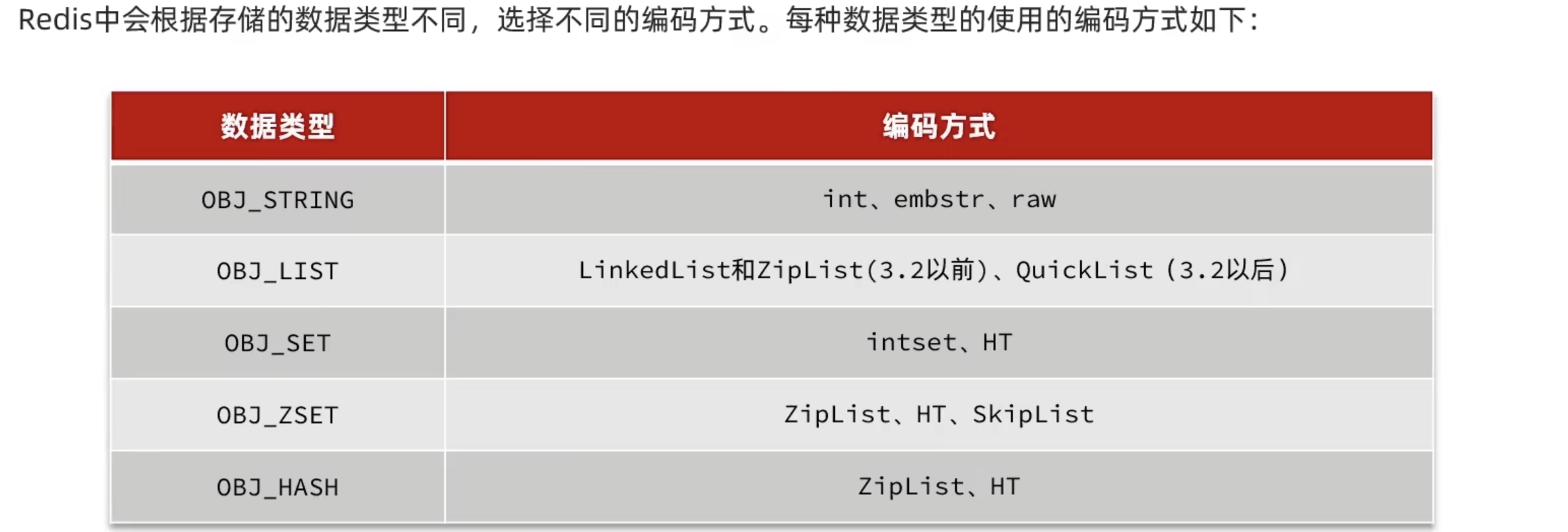
五种数据类型
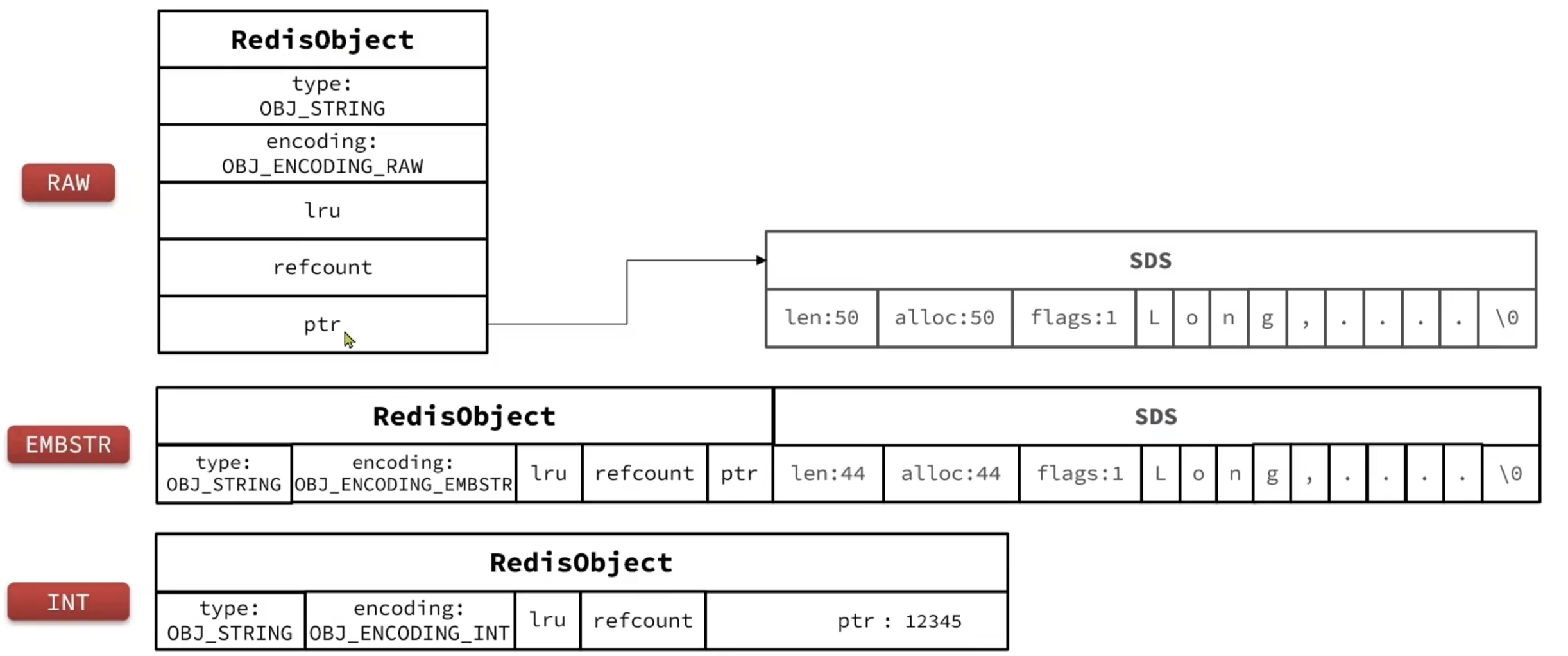
String
每次申请内存时都涉及用户态和内核态的切换,消耗CPU时间,当采用Embstr编码时,只用申请一次内存(64字节)即可,而RAW需要申请两次内存,一次申请保存RedisObj头部,另一次申请保存数据部分

List
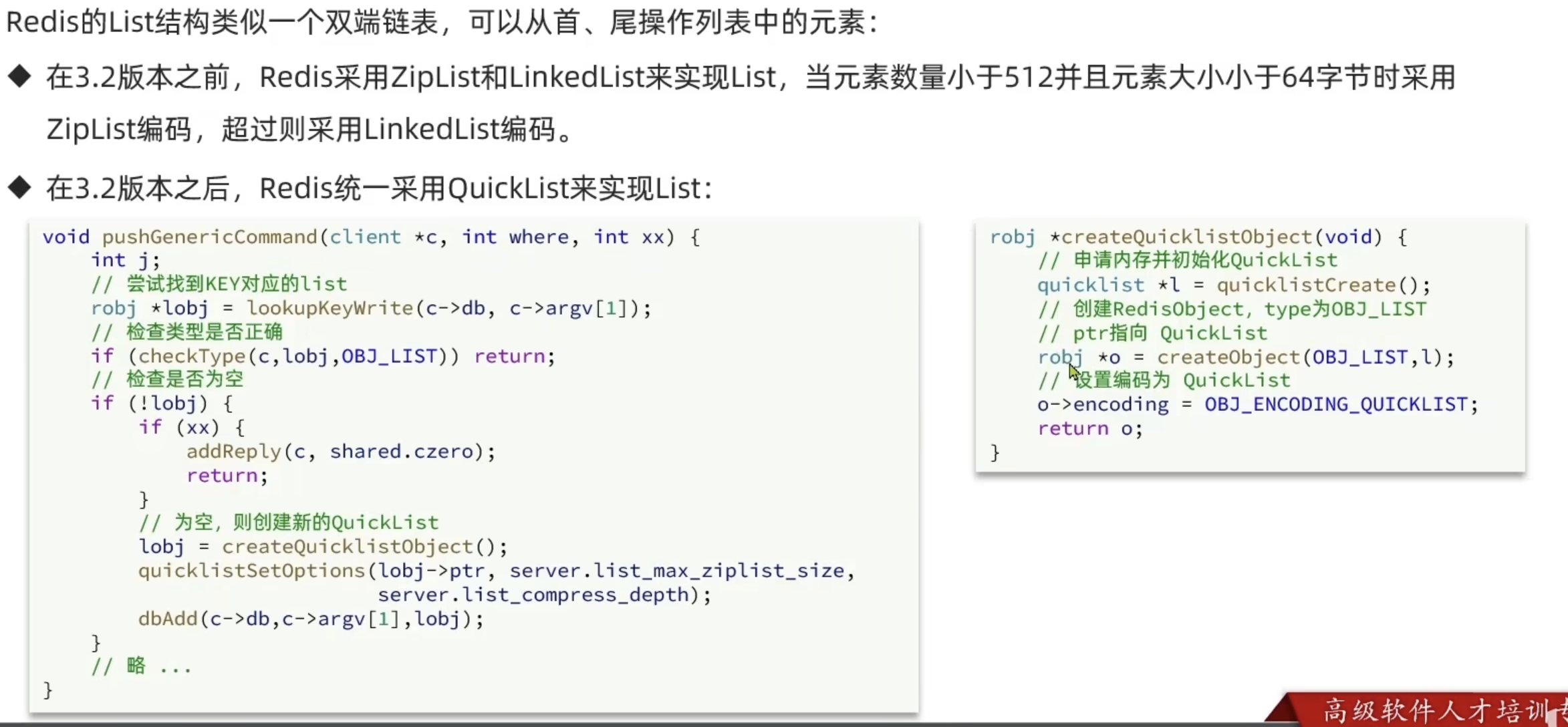
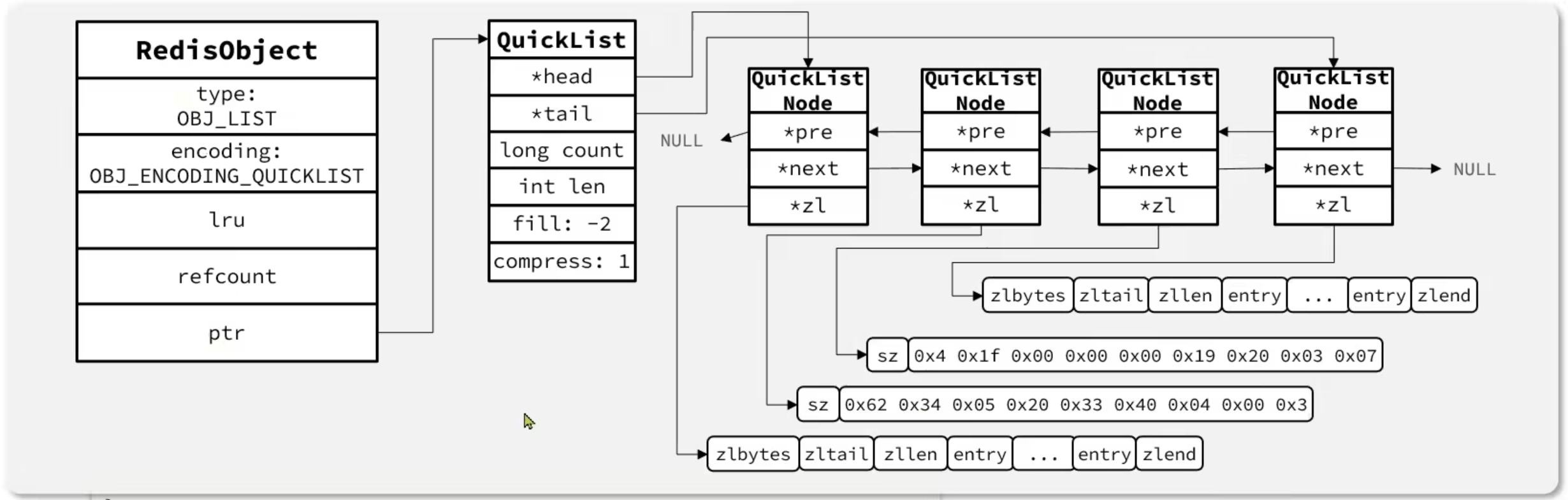
Set
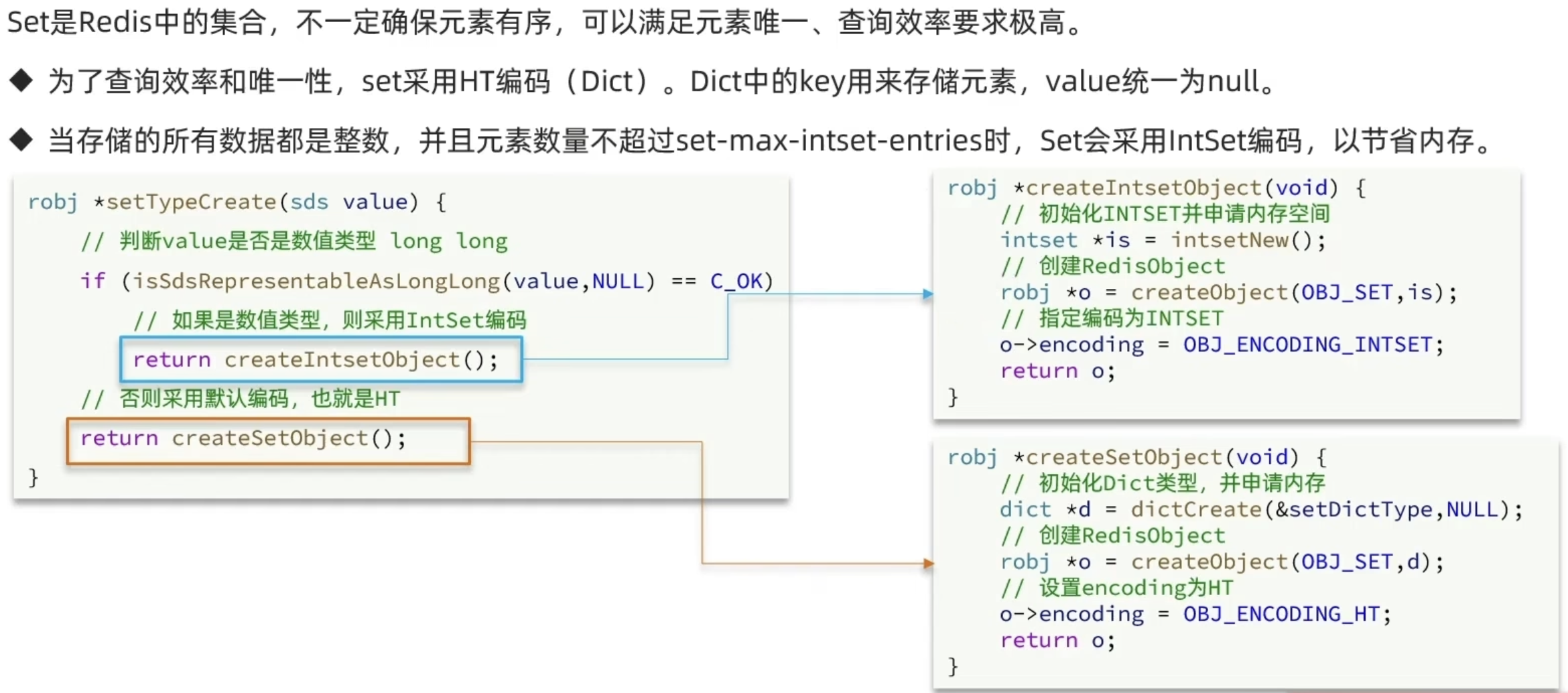
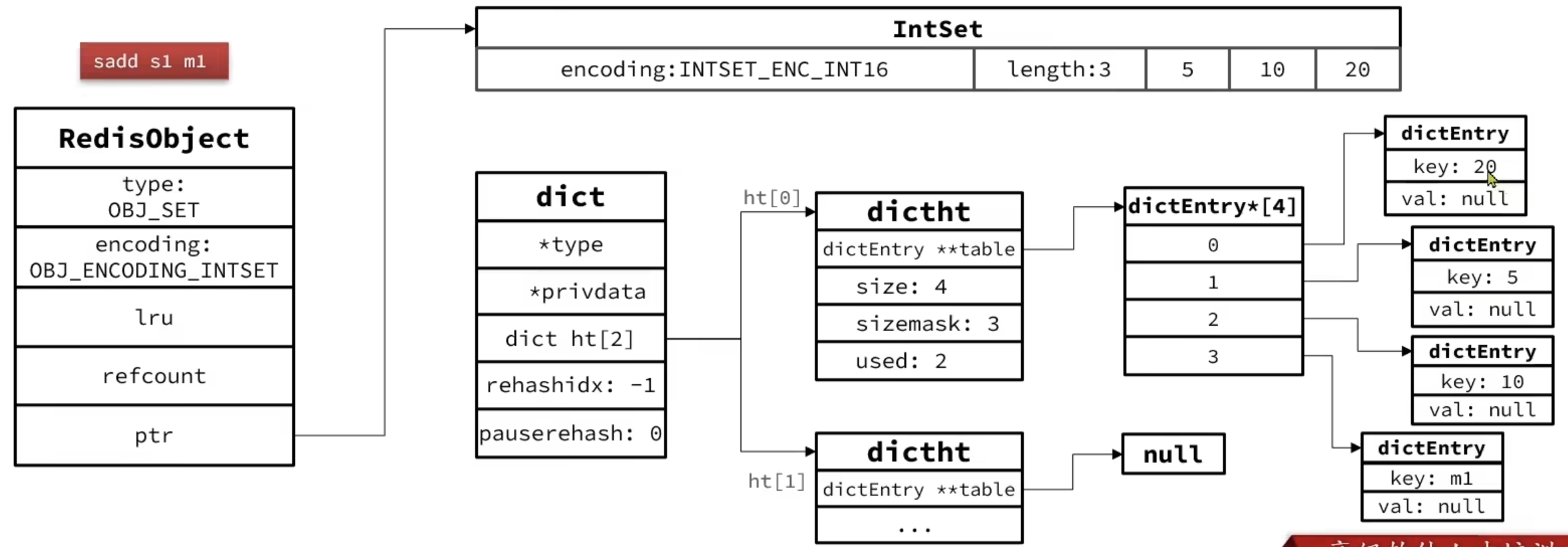
ZSet
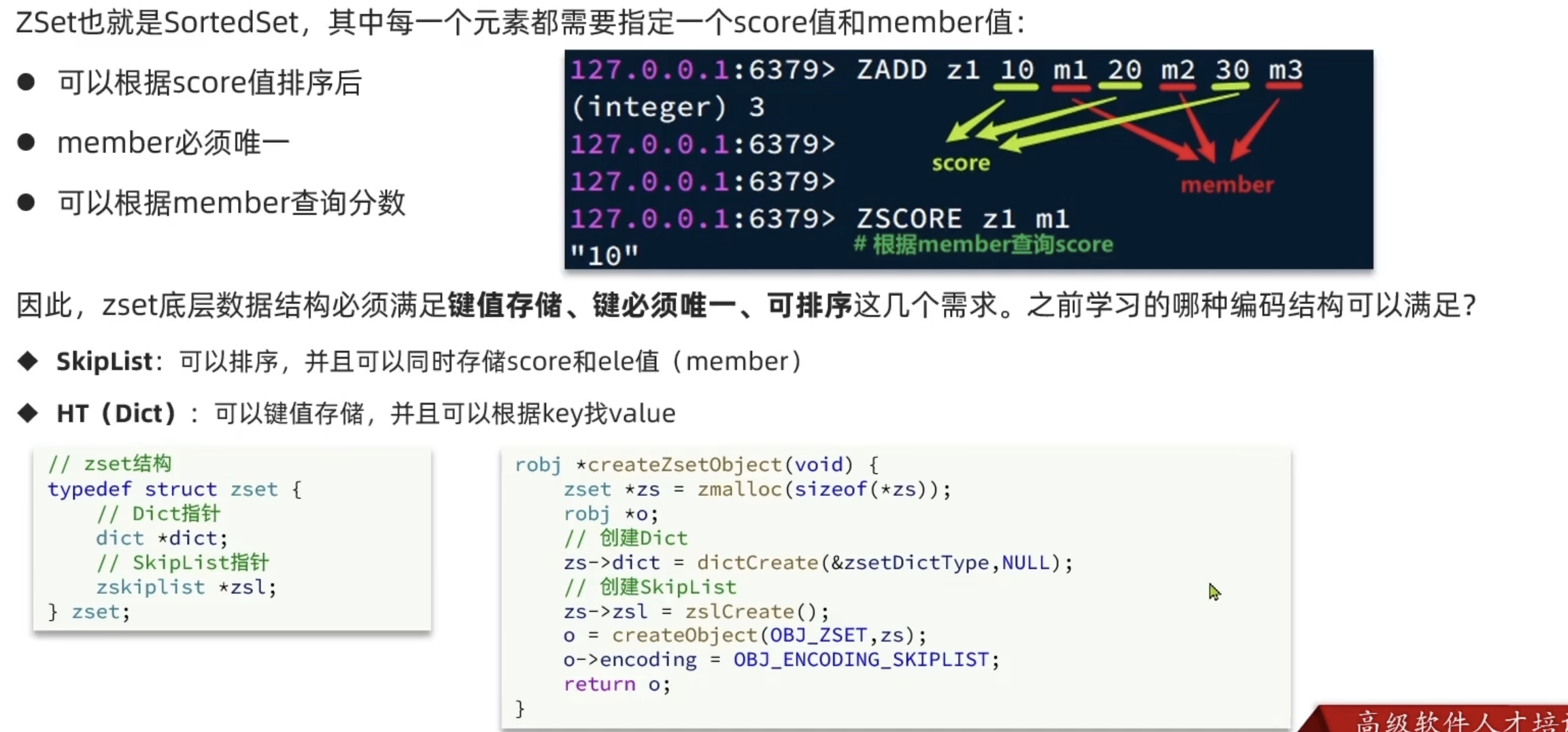
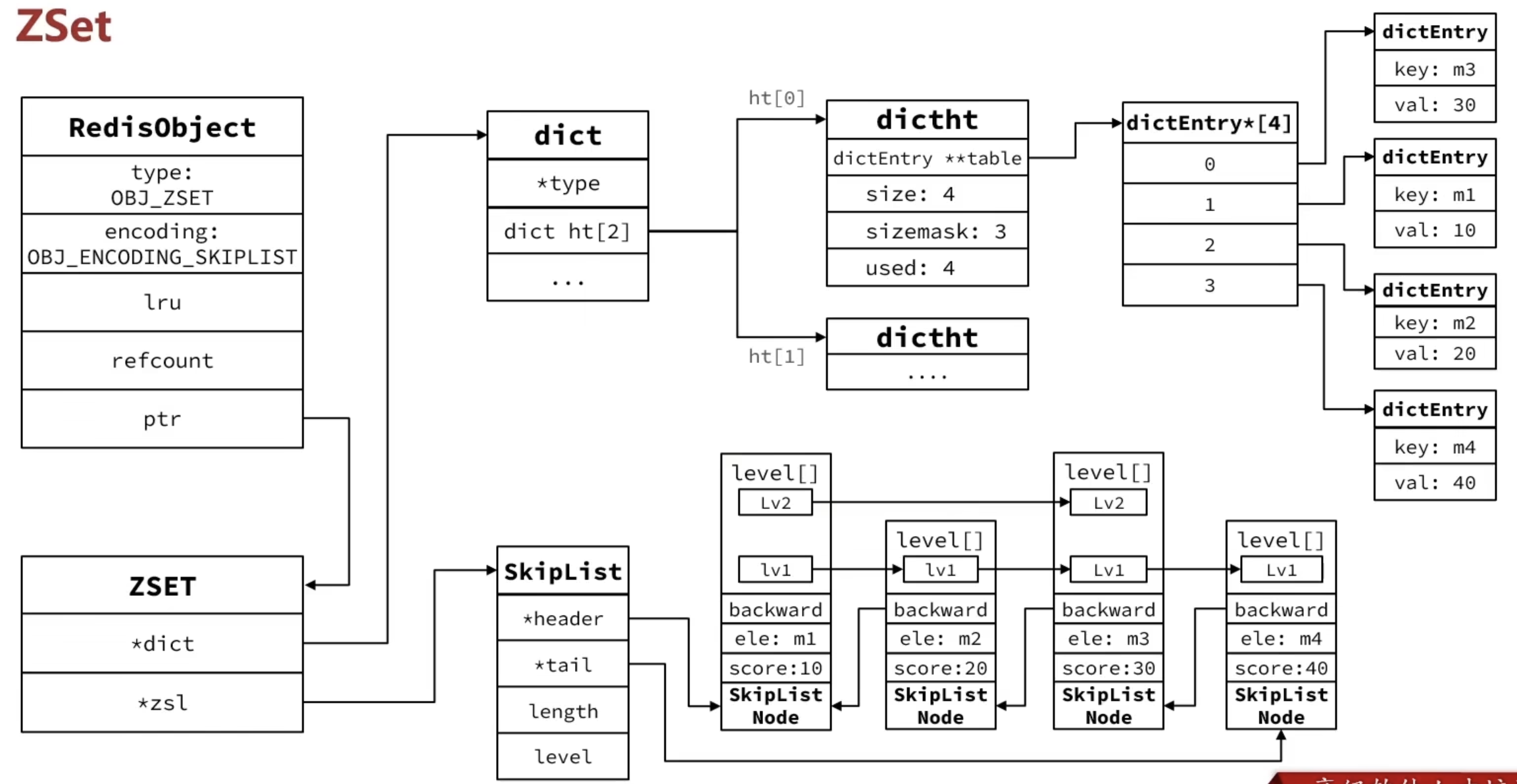


Hash
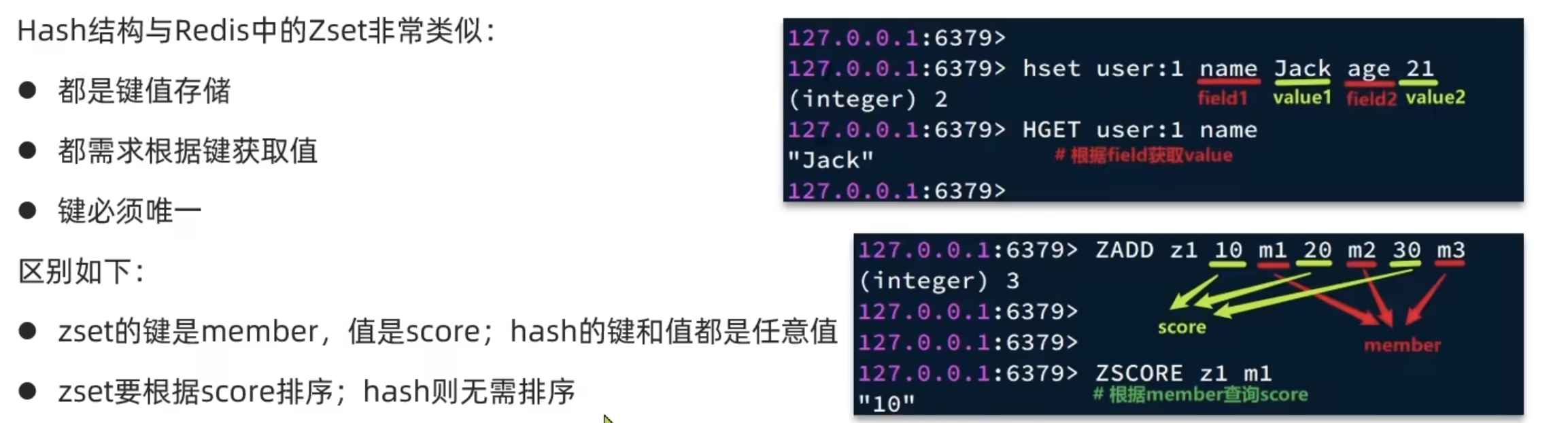
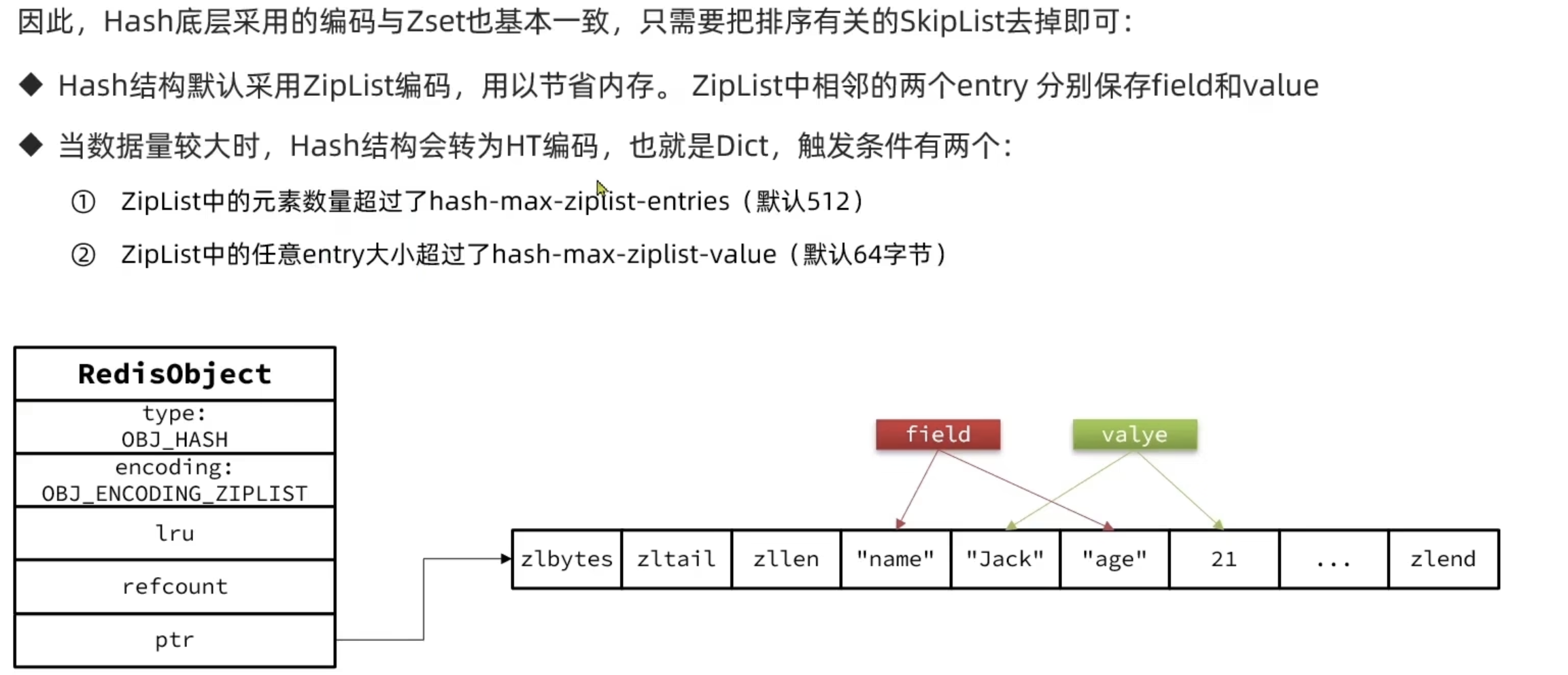
Redis网络模型
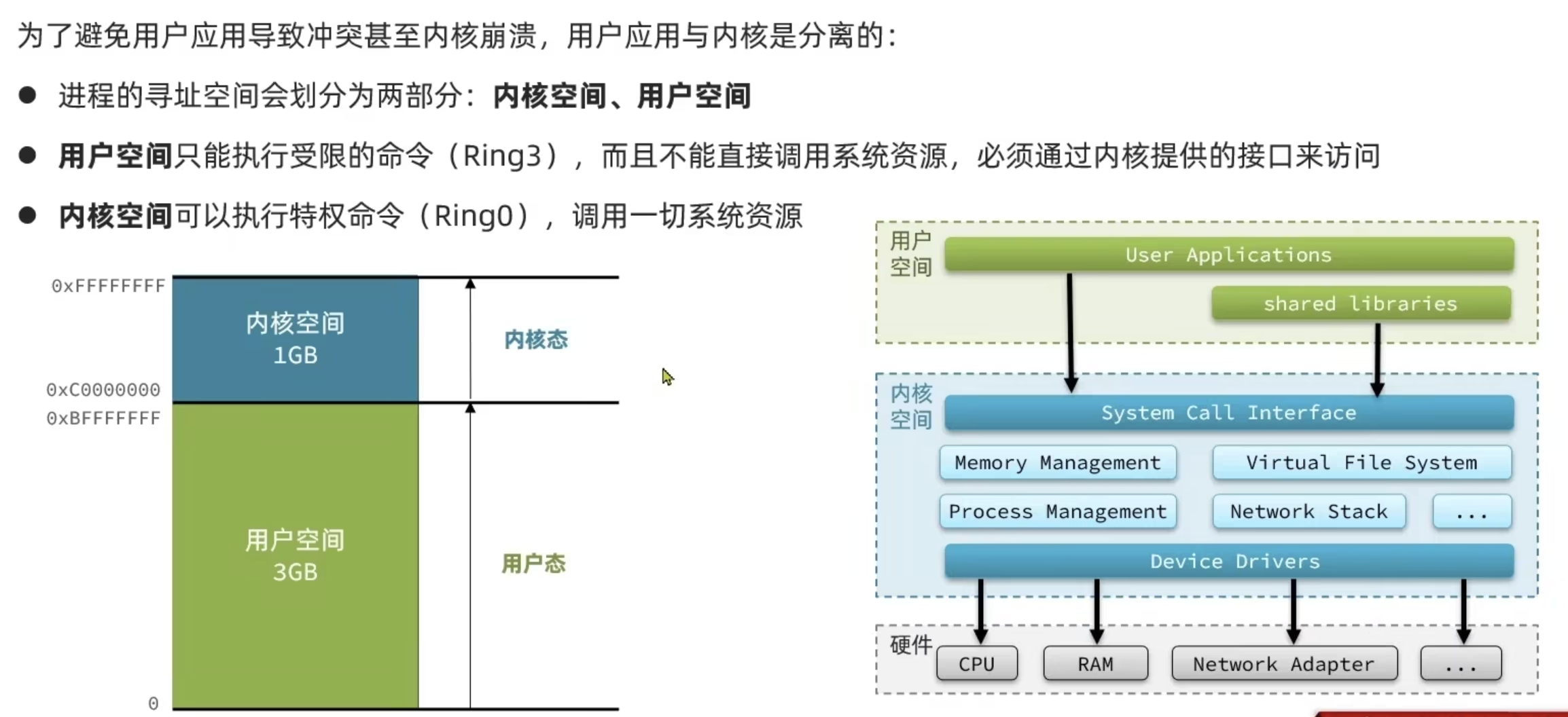
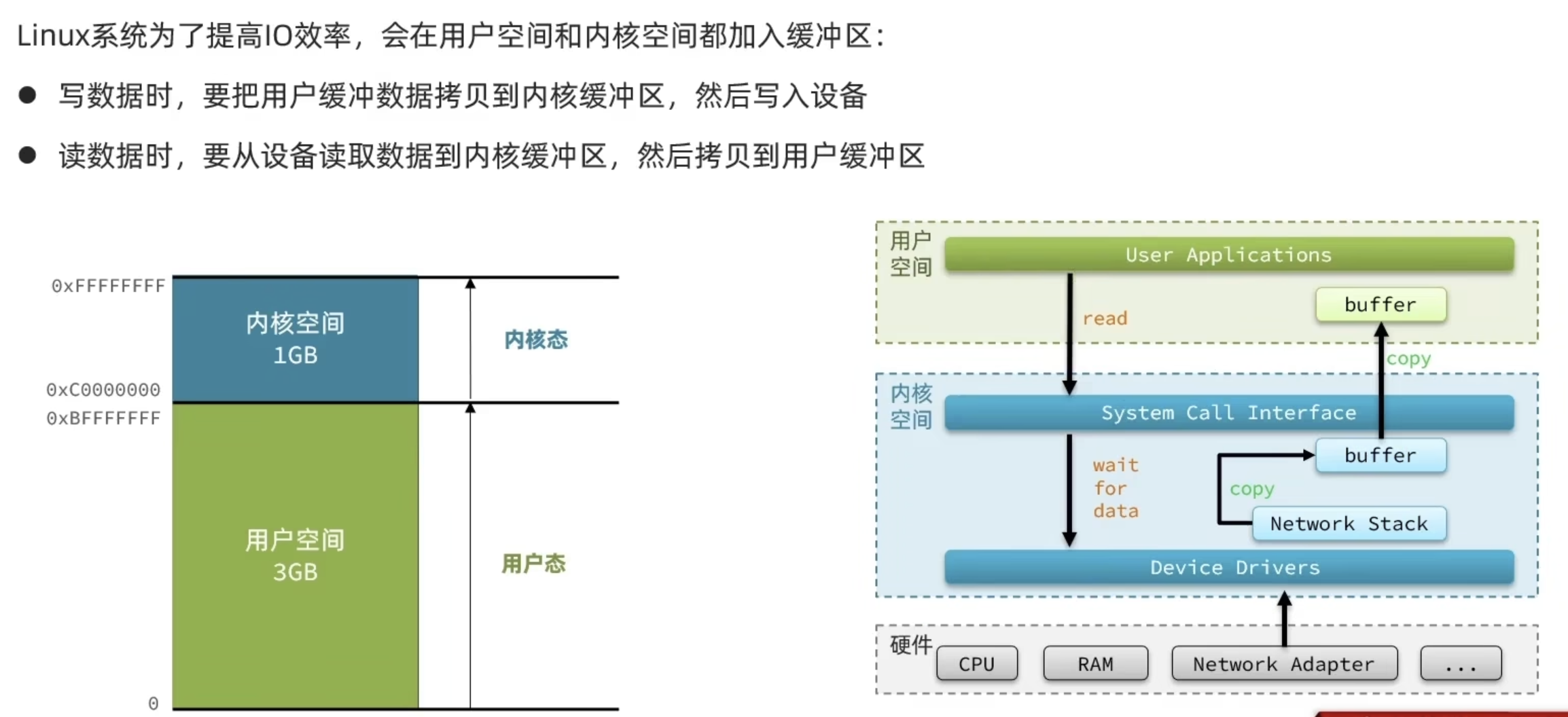
用户空间和内核空间
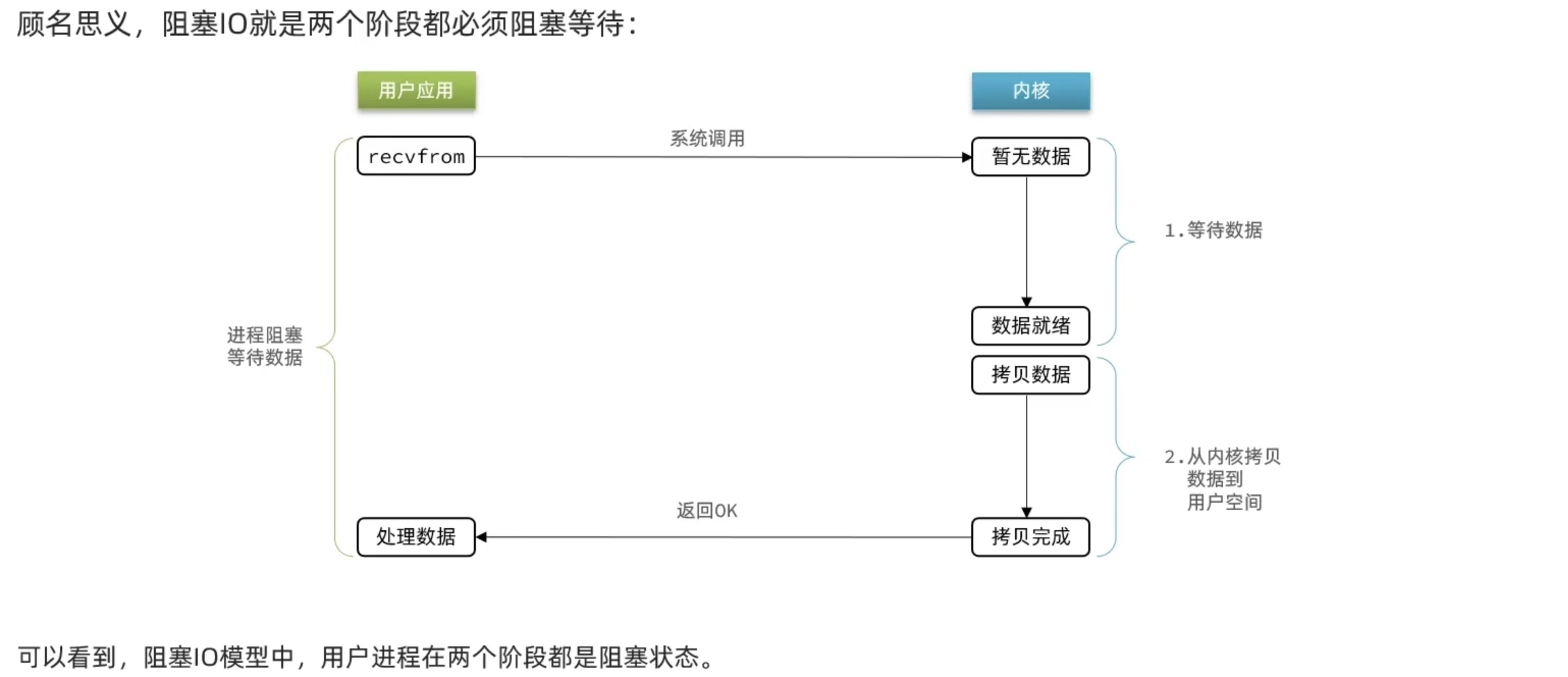
阻塞IO
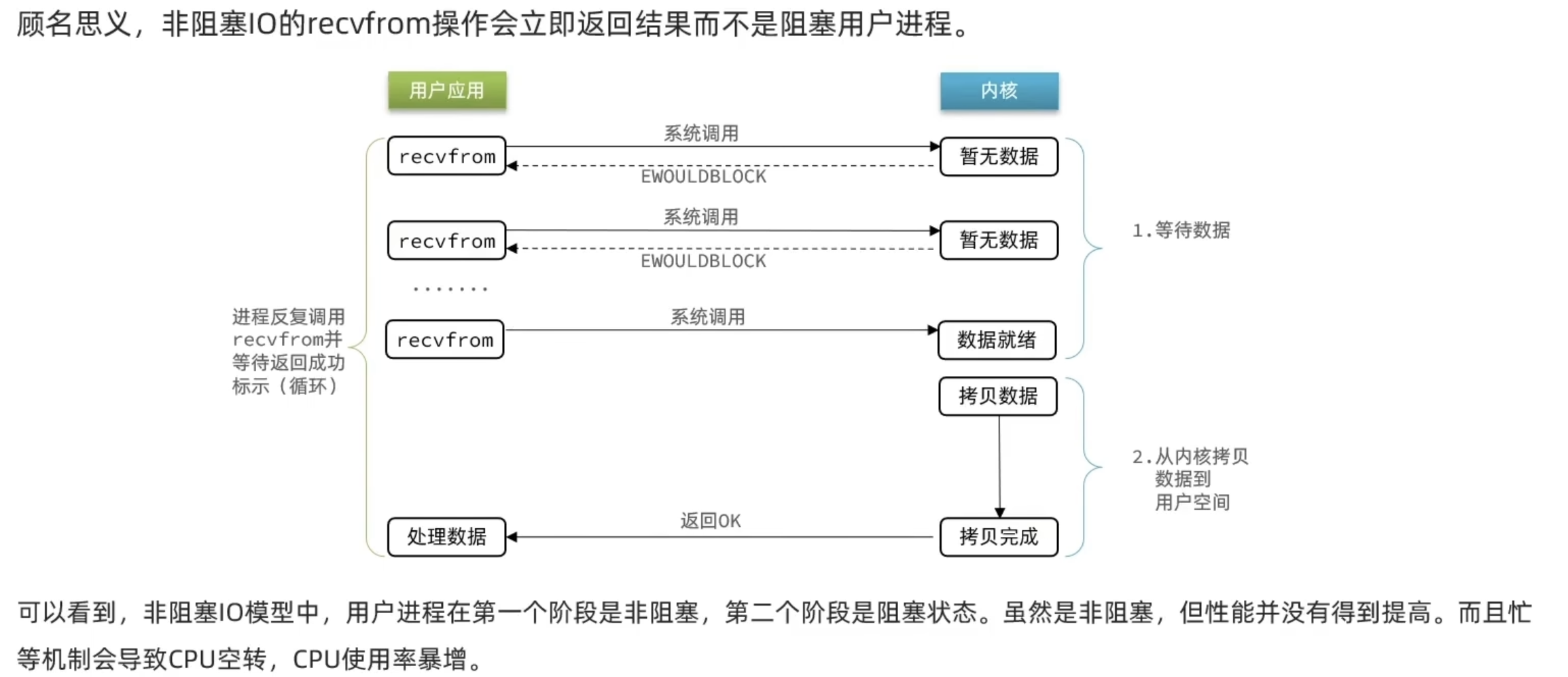
非阻塞IO
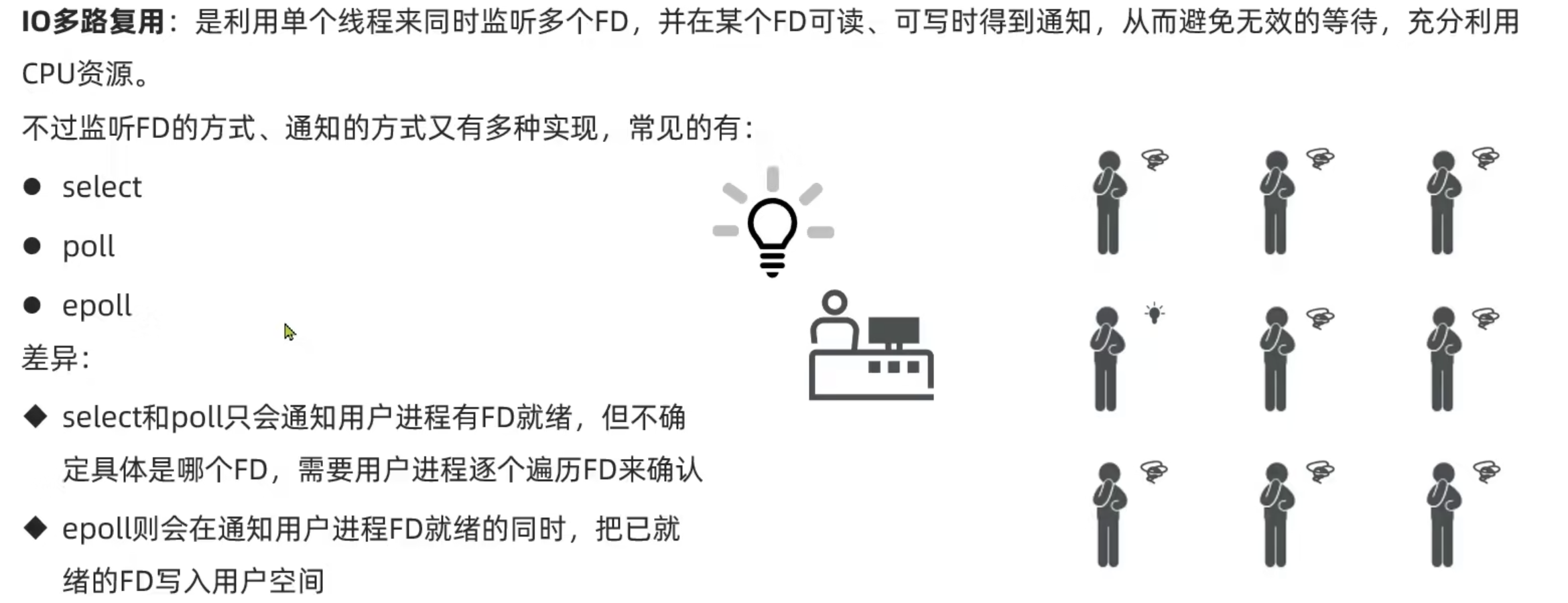
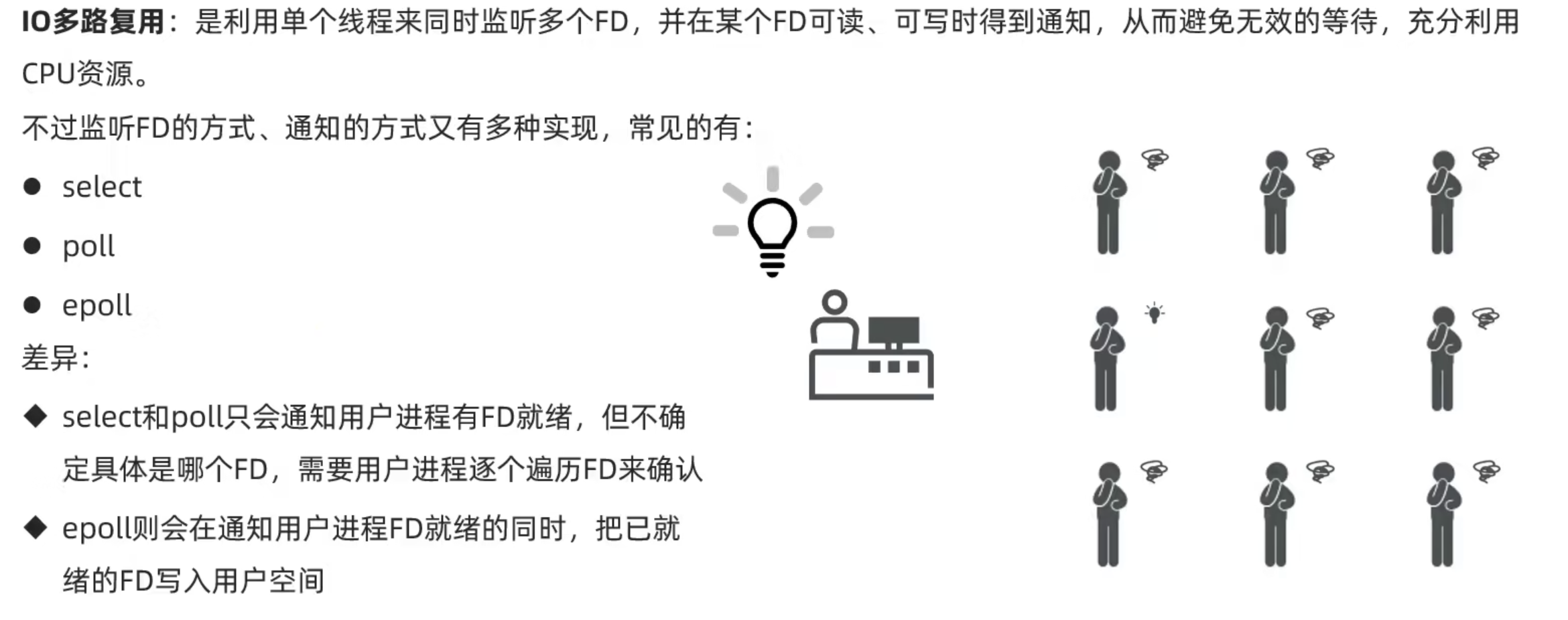
IO多路复用
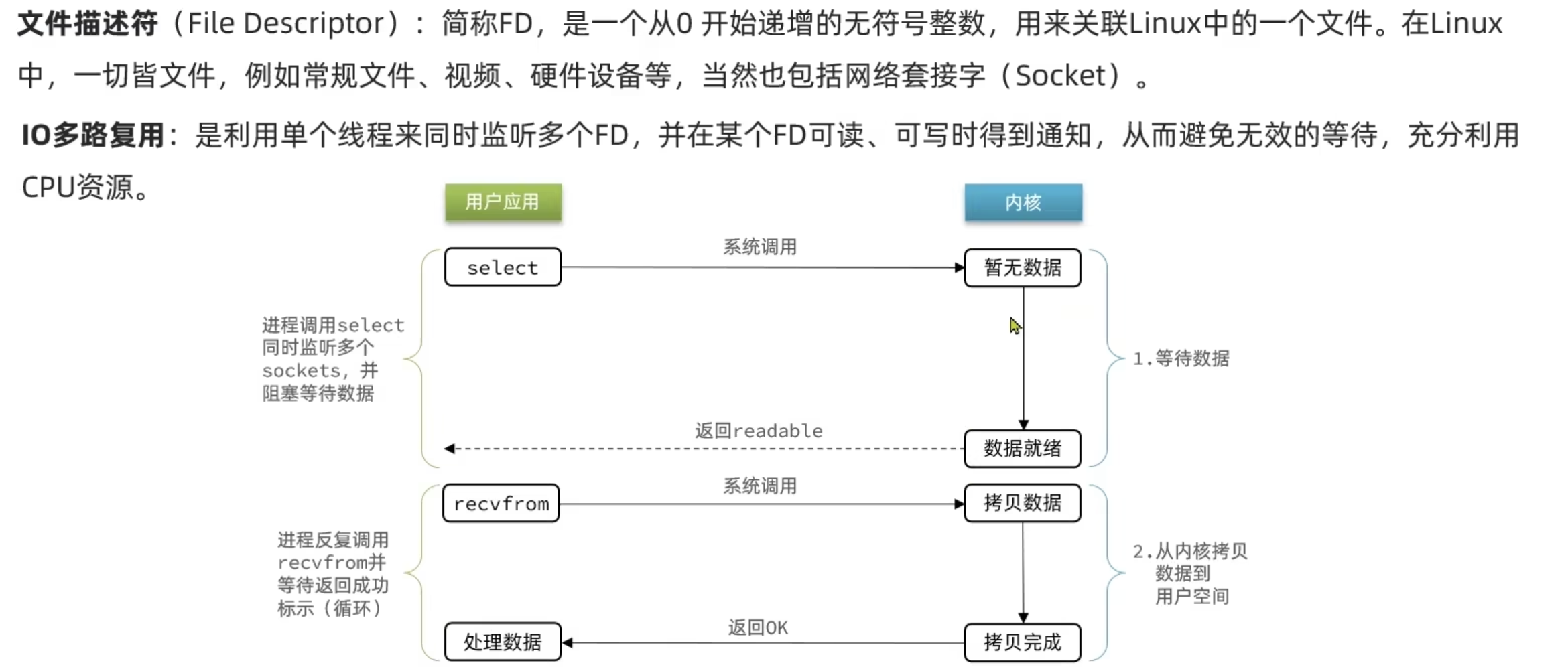
Select
FD的编号是内核给所有文件分配的索引号,因此文件数只能小于等于1024才可以用Select
其次select函数只会传回就绪的FD数量,但内核会直接修改FD_SET,将准备就绪的置为1
监听线程就是调用select方法的线程

poll

epoll
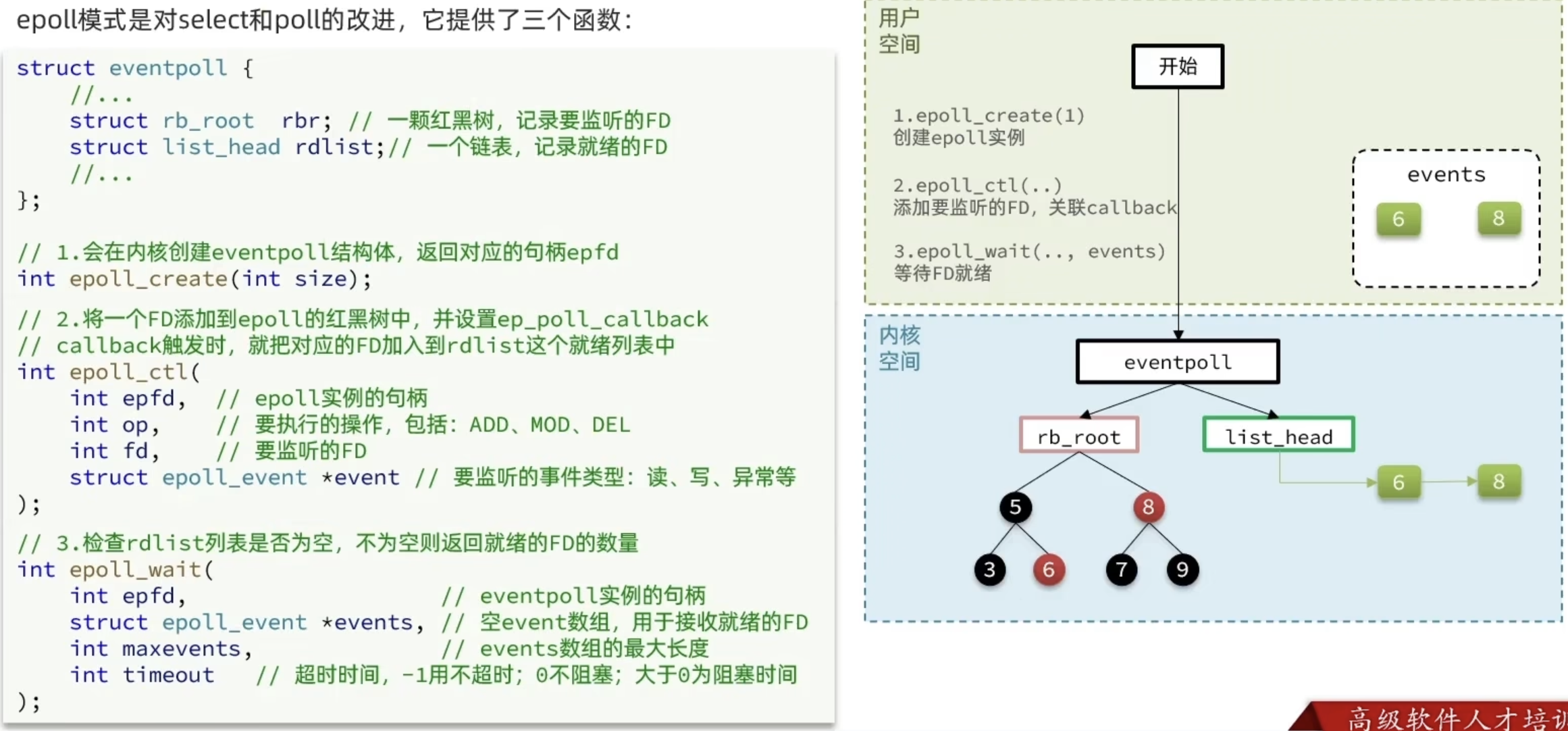

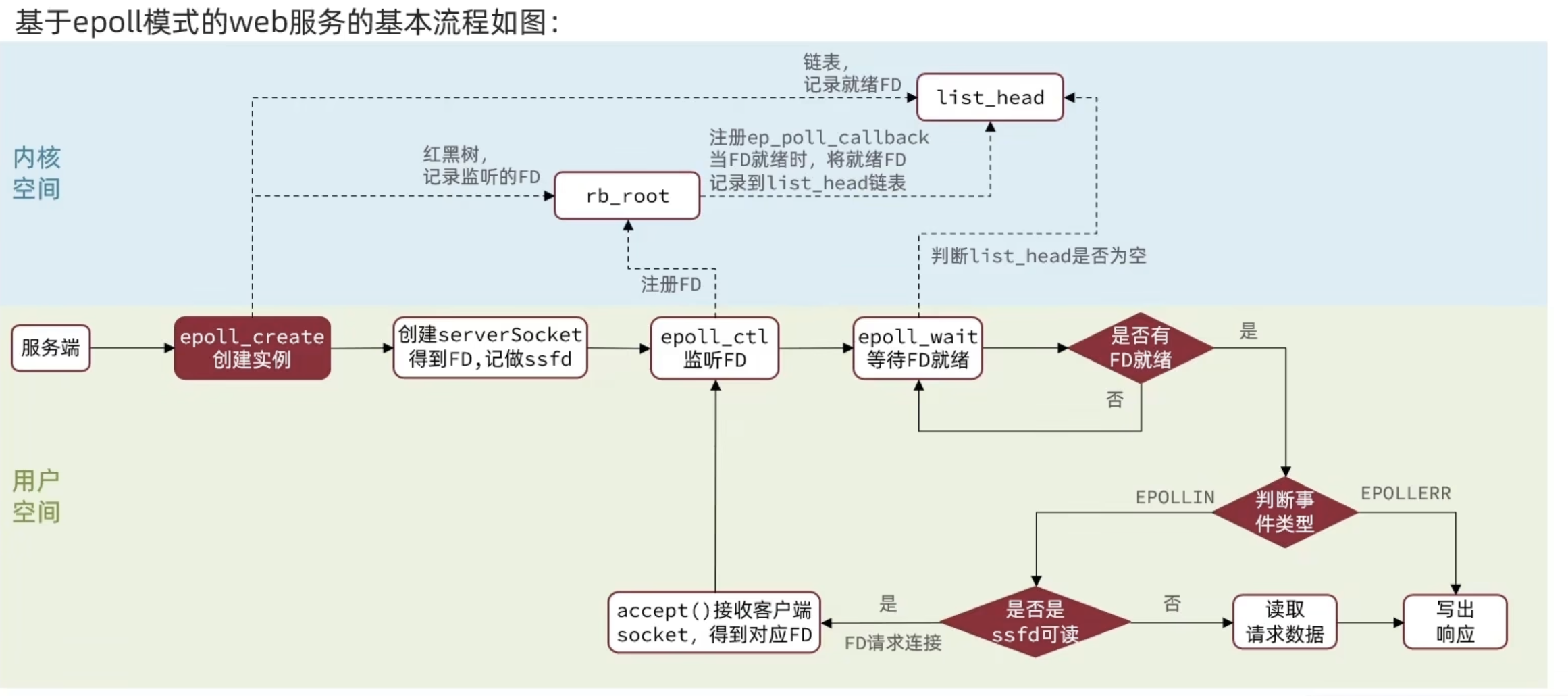
本质上epoll比select快的原因是select把注册和监听放在一个方法里,导致每次执行完一个select方法内核就没了之前的数据,而epoll将注册和监听拆分,使得每个fd只用注册一次,监听到就绪后就可以删除,不用反复将数据在内核与用户空间进行传递
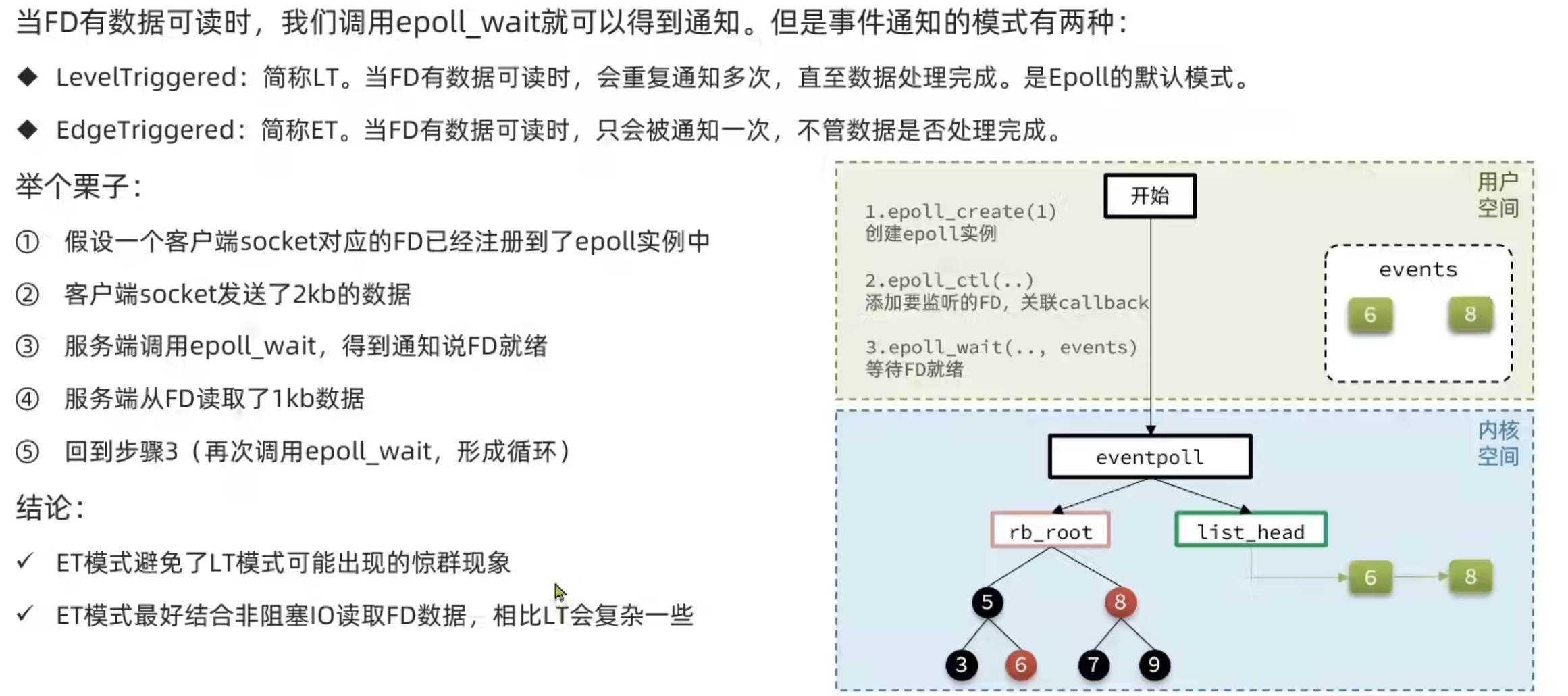
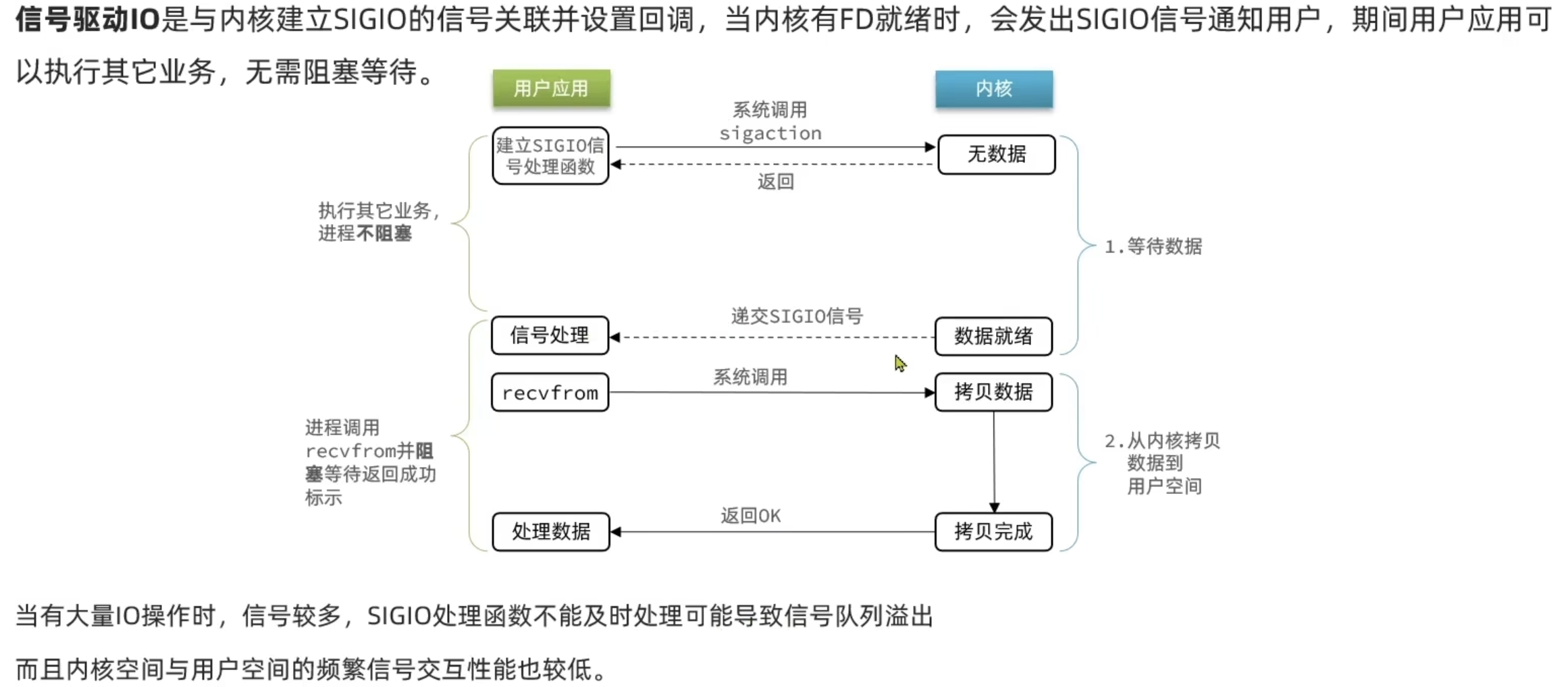
信号驱动IO
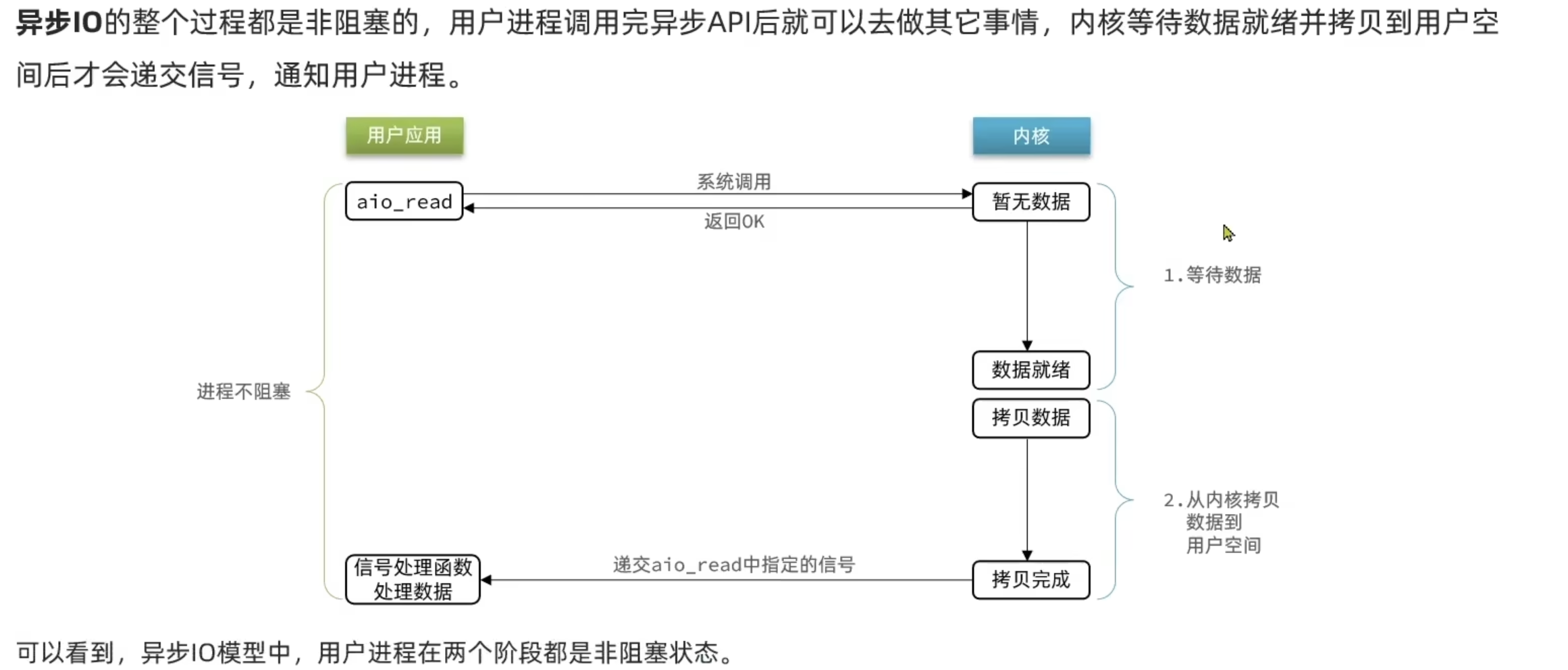
异步IO
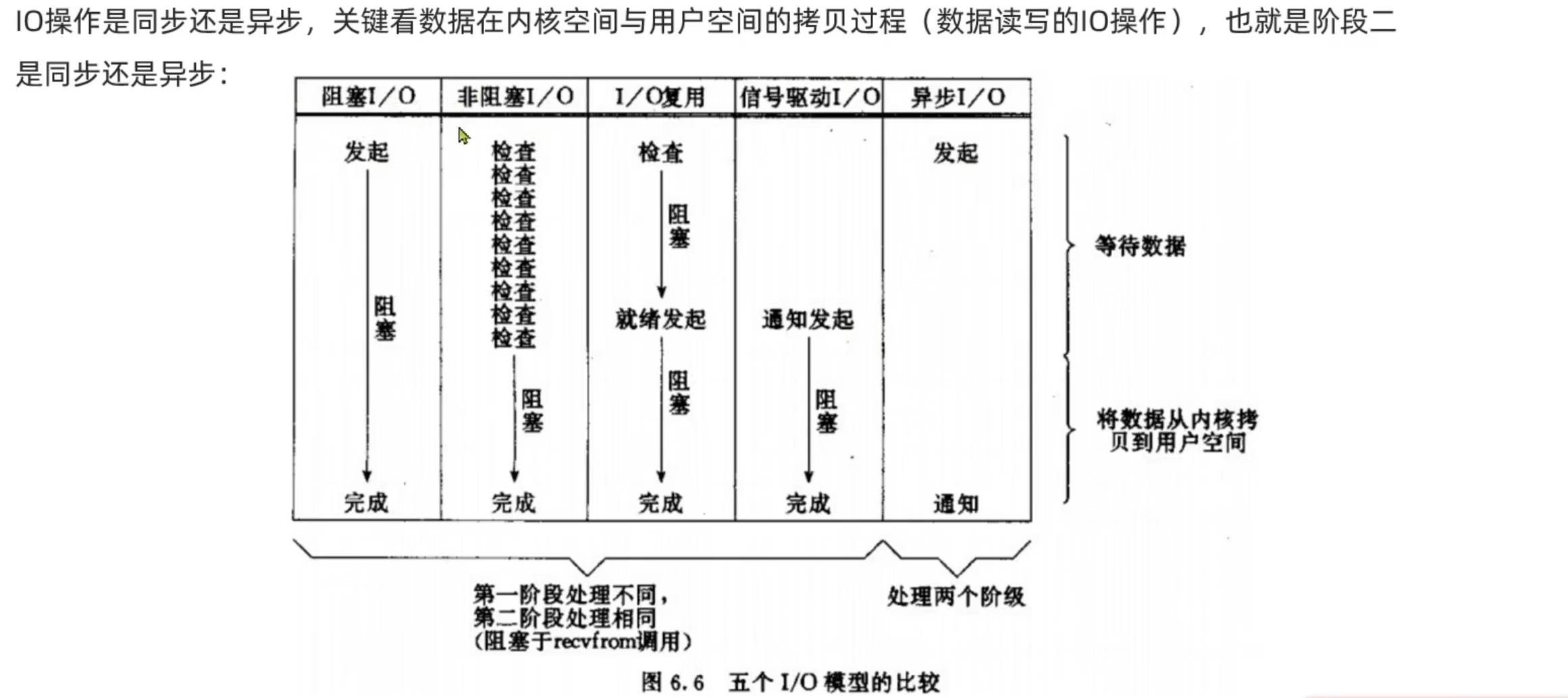
Redis网络模型
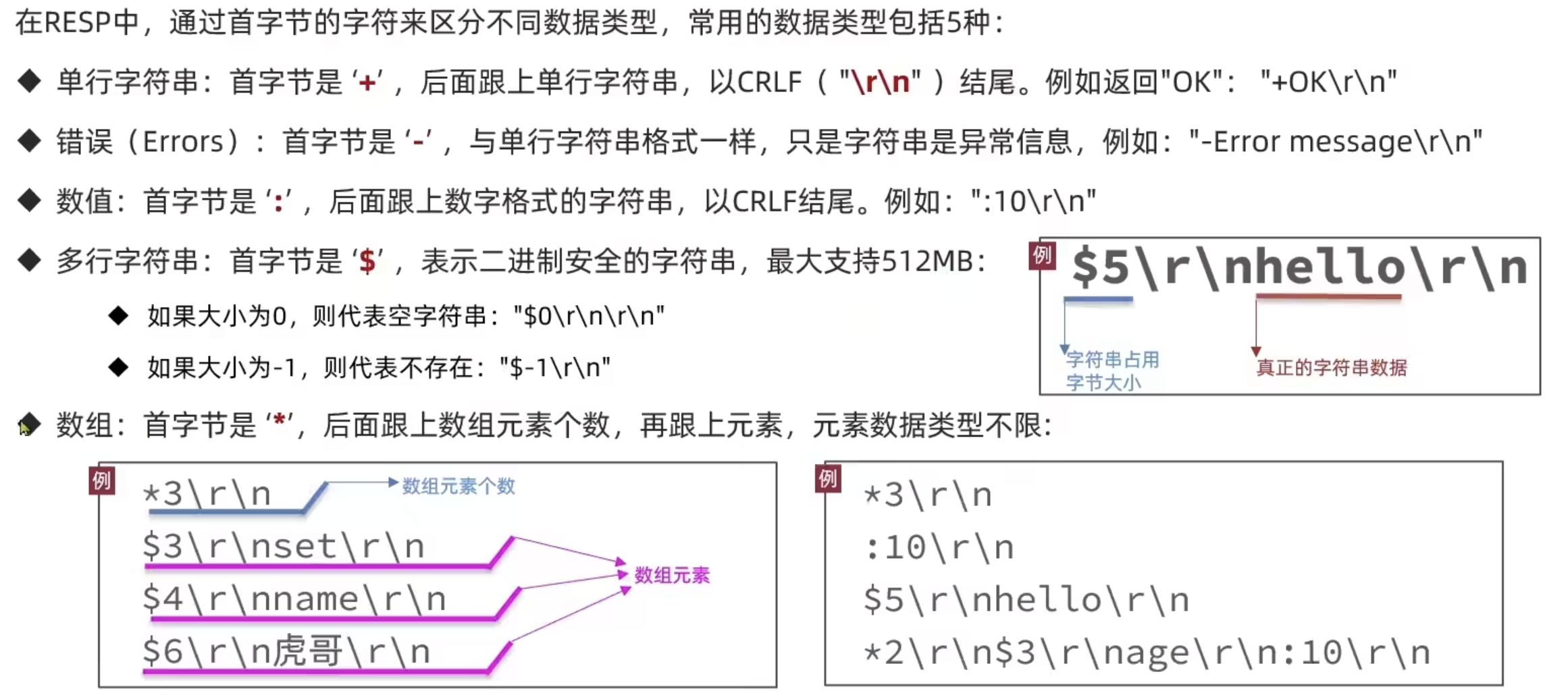
Redis通信协议
RESP协议

Redis内存策略

过期策略

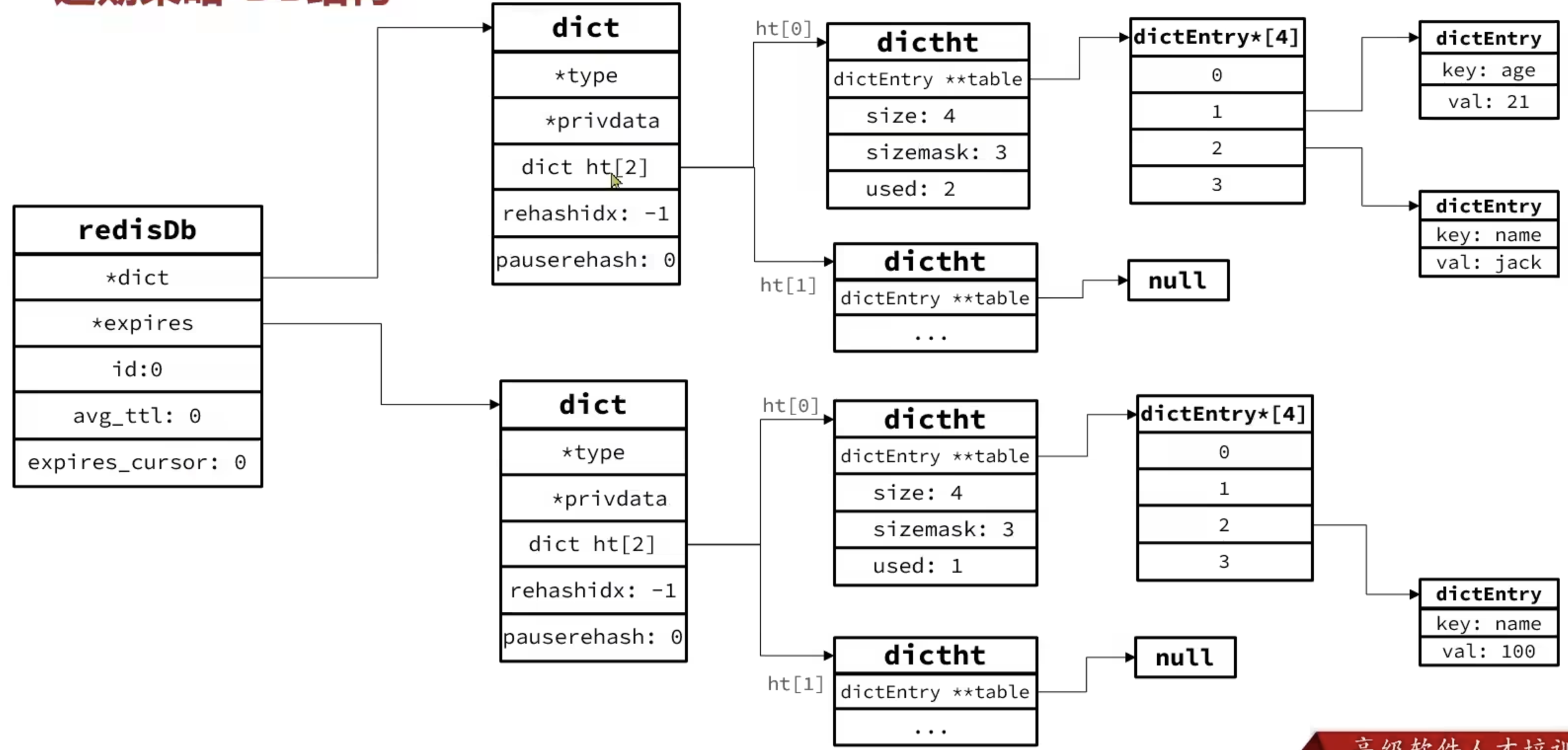
惰性删除

周期删除


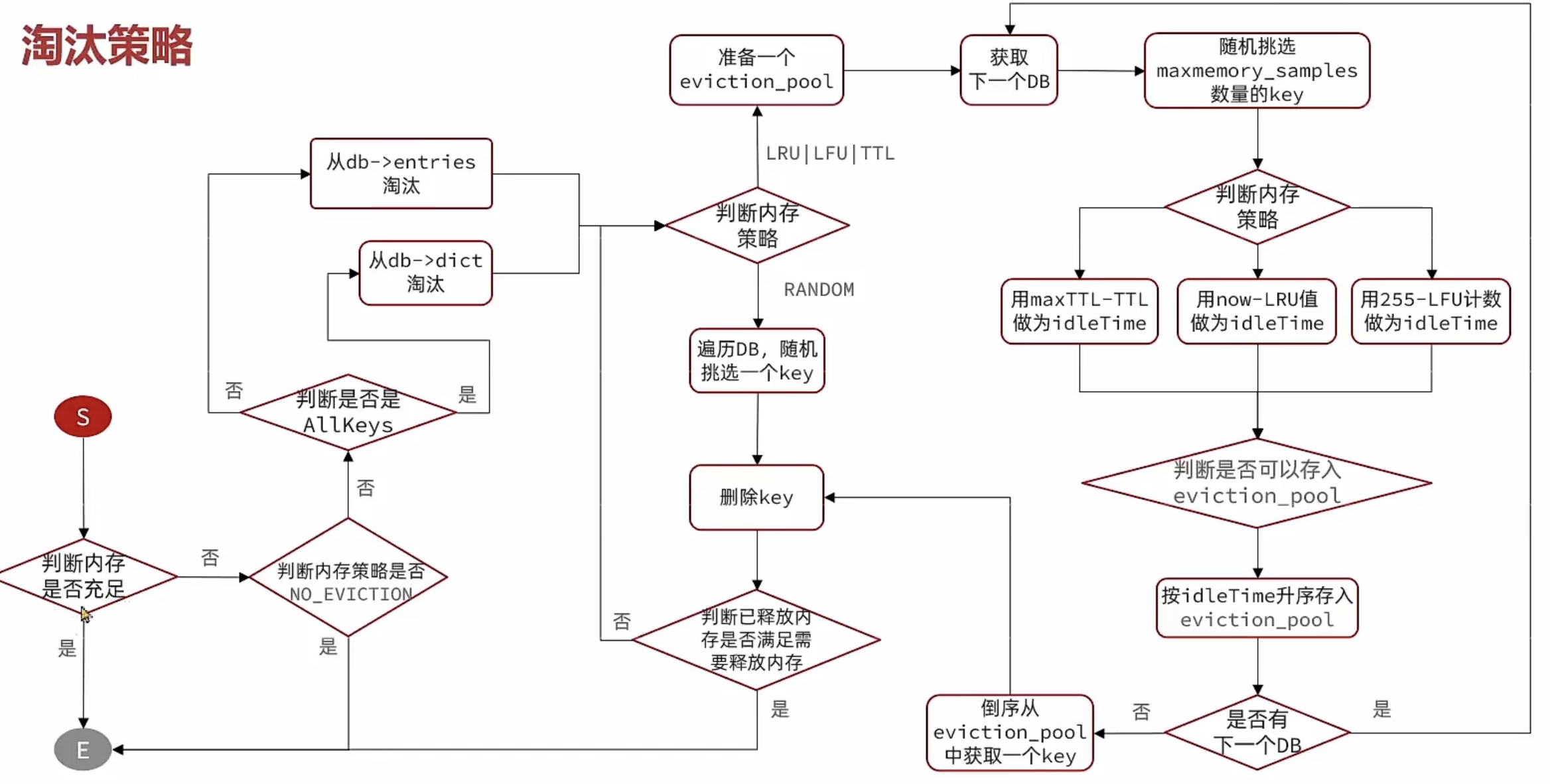
淘汰策略



这里LFU采用的是先衰减再概率性加1的计算方式,有利于前期访问频率很高,但很长时间没有访问,又突然增加访问频率的Key快速摆脱过去历史的影响,早点加入热点Key的行列