为何 Anthropic 要把 Claude 从"模型 API"推向"Managed Agents"?更进一步,为什么 Agent 时代真正值钱的东西,可能不再只是 token,而是模型之外那一整层 harness、runtime 和 infra?
先从语言模型怎么回答问题说起
如果只用一句话解释语言模型,它首先是一个条件续写器。你给它一段上下文,它根据这段上下文预测下一个 token;把这个 token 接回上下文,再预测下一个 token;如此循环,直到生成停止。
这个朴素的概念模型,是理解 Agent 成本、KV Cache、Prompt Cache、Harness 设计的基石。因为无论外层包装成聊天、代码助手、研究员、浏览器操作员,最后进入模型的,仍然是一段上下文;模型做的,仍然是在这段上下文后面继续生成。
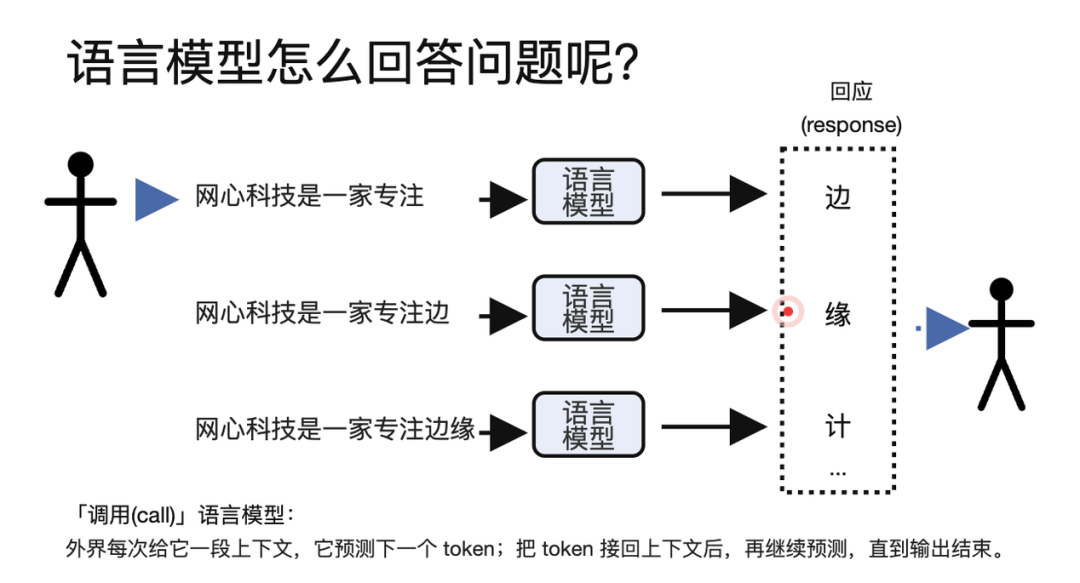
比如用户问:"网心科技是一家什么公司?"模型可能先看到完整问题,然后生成"专注";接着新的上下文变成"网心科技是一家专注",模型再生成"边缘计算";上下文继续变成"网心科技是一家专注边缘计算的",模型再生成"高科技公司"。最后我们看到的完整回答"网心科技是一家专注边缘计算的高科技公司"。这结果像是一次性想出来的,但从推理过程看,它是由很多个 token 逐步拼接起来。
而这个过程分成两个阶段:
第一个阶段叫 prefill,模型读取用户给定的全部上下文,计算每个位置的中间状态。
第二个阶段叫 decode,模型一个 token 一个 token 地生成后续内容。
prefill 更像一次大规模并行计算,decode 更像一步一步地读取历史状态并追加新 token。很多 LLM serving 论文和系统都会把这两个阶段分开讨论,因为它们对 GPU 资源的压力并不相同。DistServe 这类工作甚至直接把 prefill 和 decode 做成分离式服务,说明它们已经是推理系统设计中的一等问题。
Hugging Face 的 KV Cache 文档(详见参考文献)把这件事讲得很清楚:
自回归模型在生成时会反复用到过去 token 的 key / value 状态,缓存这些状态可以避免重复计算历史 token。也就是说,模型不是每生成一个 token 都从头把整篇上下文重新算一遍;它会复用已经算过的中间结果。
但这里有一个关键限制:缓存能不能复用,取决于前缀是否稳定。
如果每一次请求的前缀都稍微不同,哪怕语义上差不多,底层 token 序列也发生了变化。Token 序列一变,cache 就不能命中,每次请求都要重新计算。
但更深的影响不光是成本------上下文的微小漂移甚至有可能导致整个系统的失控。这就是为什么在Agent场景里,"怎么组织送给模型的内容"成为一个一等工程问题。要理解谁来负责组织好送给模型的内容,我们从一次完整的Agent交互说起。
从一次模型调用到一个 Agent
最简单的模型交互很容易理解:client 把 system prompt 和 user content 发给 LLM,LLM 返回 response。System prompt 规定模型的身份、边界和工作方式;user content 是用户这一次真正想做的事情。
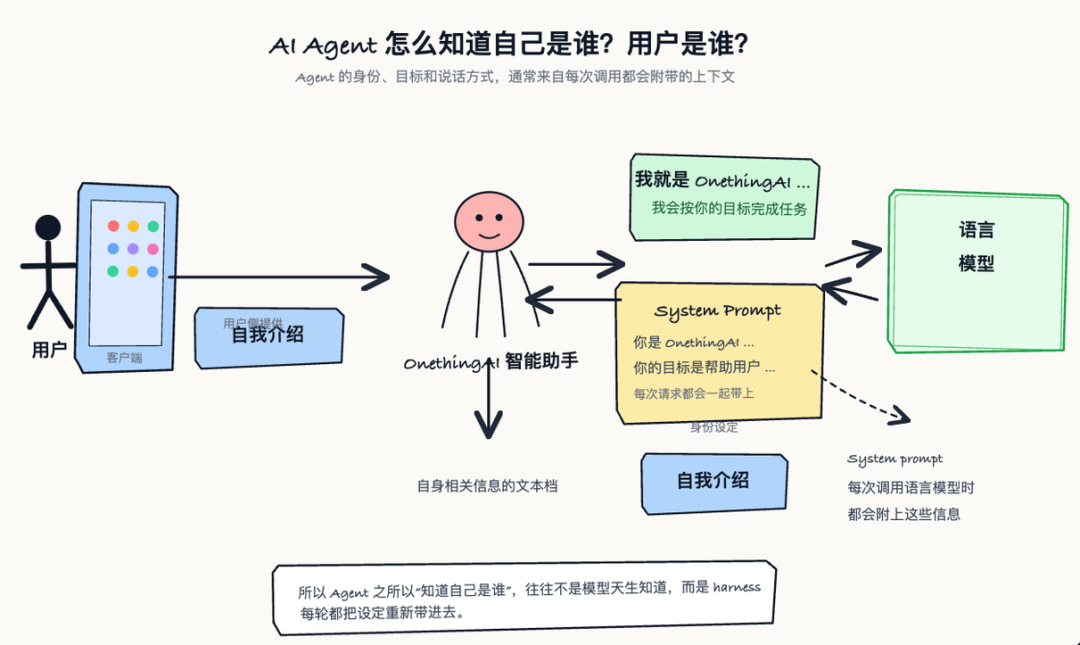
但 Agent 不是一次简单问答。一个 Agent 至少要能做三件额外的事。
✅ 它要有身份和任务边界
比如它叫 OnethingAI,目标是帮助用户完成某类任务,回答时要遵守某些安全规则。这些东西并不是模型"天生知道"的,而是 harness 每次把 system prompt、工具说明、策略约束放进上下文,模型才在这一次调用中表现得像一个特定 Agent。
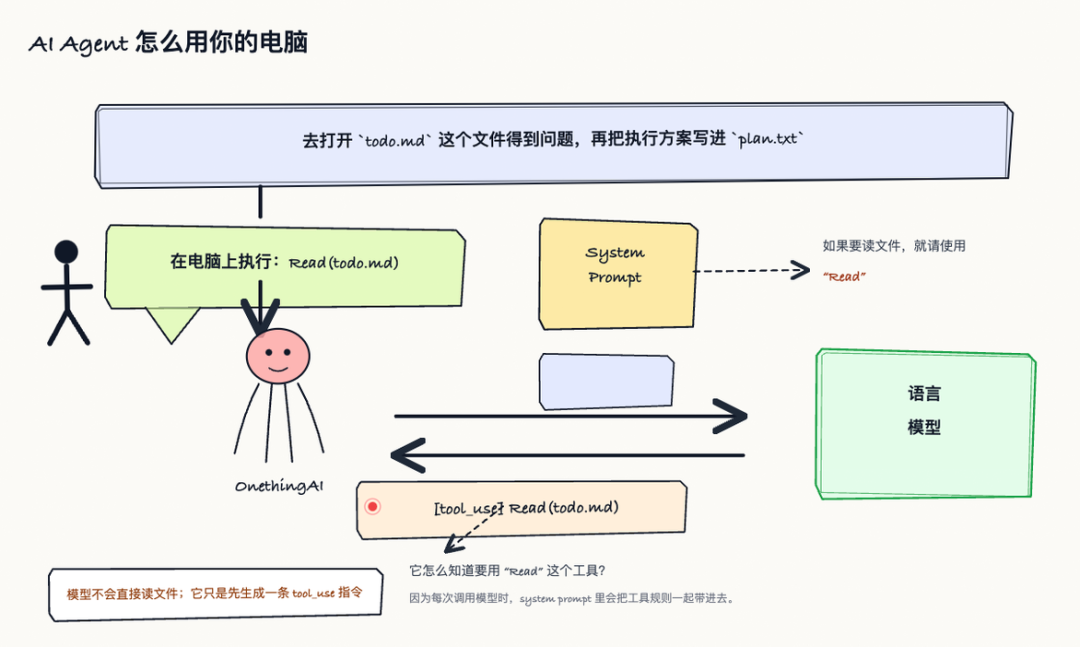
✅ 它要能使用工具
模型本身不会真的读文件、执行 shell、打开网页。它能做的是生成一段结构化意图,比如 tool_use Read(question.txt)。Harness 看到这段 tool use 之后,才会在真实电脑或沙箱里调用对应工具,把结果包装成 tool result,再塞回下一轮模型上下文。
✅ 它要能维持多轮状态
第一轮工具调用返回了什么,第二轮要不要引用它,第三轮是否已经完成任务,这些都要被组织成上下文或外部状态。于是一个 Agent 的真实结构不是"模型 + 循环"这么简单,而是以下有个部分构成:
-
稳定前缀:system prompt、工具 schema、权限规则、输出格式。
-
用户任务:用户这一轮真正输入的目标。
-
运行历史:模型输出过什么、调用过哪些工具、工具返回了什么。
-
外部状态:文件系统、浏览器、数据库、沙箱、checkpoint、任务队列。
而 Harness 的职责,就是把这些东西组织成模型下一次能理解、能继续、成本又不要爆炸的上下文。
如果把这个结构再抽象一层,你会发现 Agent 从来都不是"一个更会聊天的模型",而是一个带控制面的执行系统:
模型负责根据上下文做判断,工具负责接触外部世界,harness 负责解释两边,runtime 负责保证这一整套流程能持续运行。Agent 的稳定性因此不取决于某一次回答有多惊艳,而取决于十几轮、几十轮之后它还能不能不失忆、不跑偏、不乱用工具。
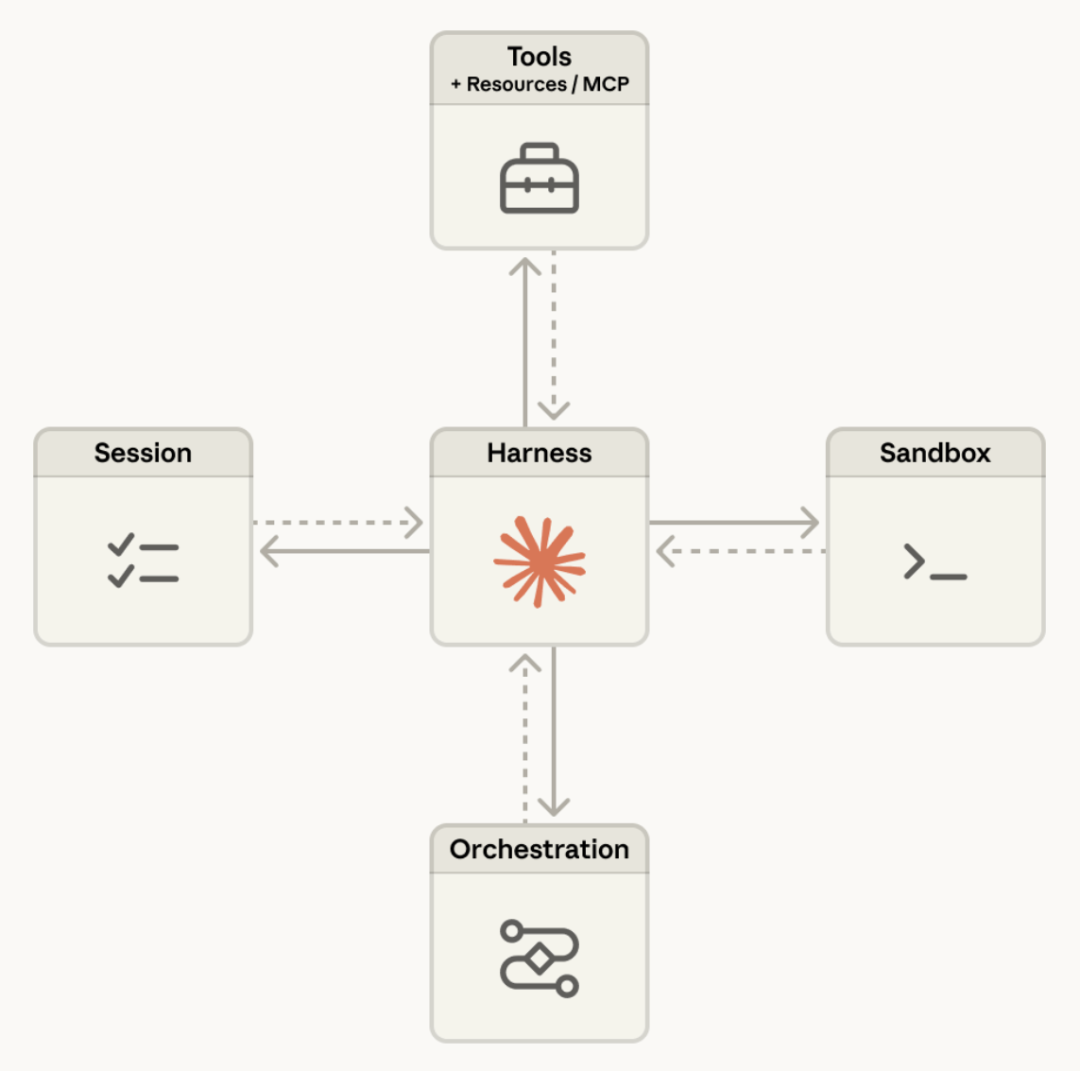
Anthropic 在 Managed Agents 的结构图里把 Session、Harness、Sandbox、Orchestration、Tools / Resources / MCP 明确画在一起,本质上就在强调:生产级 Agent 不是"多加几个函数调用",而是一套围绕模型运转的系统。
这也解释了为什么很多人第一次体验 coding agent 时,会同时感到"神奇"和"脆弱"。神奇在于模型真的能读代码、改文件、跑测试;脆弱在于只要 tool result 回灌得太乱、system prompt 稍微漂移、历史没有被整理好,后面几轮它就会表现出一种似懂非懂的状态:看起来还在工作,实际上已经把任务主线丢了。
Agent 的持续运行带来了一个直接问题:每一轮调用都要把越来越长的上下文发给模型,而模型的推理成本正是由这份上下文的体量与结构决定的。要理解为什么上下文管理如此关键,必须先看清楚推理系统如何对待它。
KV Cache、Prefix Cache 和推理成本
要理解为什么坏 harness 会贵,必须先理解 KV Cache 和 Prefix Cache 。
KV Cache 是模型生成过程中的运行时缓存。Transformer 每一层 self-attention 都会为历史 token 计算 key 和 value。生成第 1000001 个 token 时,模型要关注前 1000000 个 token;如果每一步都重新计算前 1000000 个 token 的 key/value,成本会非常高。因此推理引擎会把历史 token 的 key/value 缓存下来,decode 时直接复用。
Prefix Cache 更接近 serving 层面的复用:如果两个请求共享相同前缀,就可以复用这个前缀已经计算过的结果。vLLM 的 Automatic Prefix Caching 就是典型设计:它把 prompt 分块,用 block hash 判断哪些前缀块可以复用。这里最重要的不是某个实现细节,而是原则:相同前缀才有复用空间。
Anthropic 的 prompt caching 文档也体现了同一个思想。Prompt cache 适合放那些大而稳定的内容,比如工具定义、系统说明、长文档、代码库上下文;如果这些内容频繁改变,缓存收益就会下降。Anthropic 文档还强调,prompt caching 对 prompt 结构和 cache breakpoint 有要求,这说明缓存不是魔法,而是需要调用方配合设计。
这就把问题带回 Agent。一个普通聊天请求也许只有几千 token,但一个 coding agent 的请求可能包含:
-
几万 token 的 system prompt 和工具说明;
-
当前仓库的目录、文件片段、错误日志;
-
多轮 tool result;
-
历史推理轨迹;
-
压缩摘要和任务计划。
如果这些内容每轮都重新排序、重新格式化、重新摘要,prefix cache 很难命中。更糟的是,有些变化在语义上毫无价值,却足以破坏底层 token 前缀。例如:
-
MCP 工具列表每次返回顺序不同;
-
tool result 的 JSON 字段顺序不稳定;
-
日志里带有时间戳、随机 ID、临时路径;
-
system prompt 在每轮被动态拼接,位置和内容轻微漂移;
-
临近上下文窗口时粗暴压缩,每几轮就把历史改写成新摘要。
如果一个 Agent 框架每次工具调用都携带 100K token 以上上下文,同时这些前缀又无法稳定复用,那么它对推理系统来说就不只是"多花一点 token",而是在不断制造 prefill 和 cache miss 压力。这个压力最终会体现在显存占用、带宽、延迟、吞吐和账单上。
把问题讲得更直白一点:更长的上下文窗口,不等于可以更任性地把一切都扔进去。窗口大只是容量变大,不代表也变便宜。一个 200K 上下文如果装的是稳定、分层、可复用的信息,那是能力;如果装的是反复改写的摘要、顺序漂移的工具结果和大量重复历史,那只是更昂贵的混乱。
无论是 Hugging Face 对 KV Cache 的解释,还是 vLLM 对 prefix caching 的实现说明,复用成立的前提都不是"语义大致相同",而是"前缀在 token 层面保持一致"。这意味着许多产品层看起来无伤大雅的变化------时间戳、随机 ID、字段重排、动态摘要------在推理系统里都可能非常昂贵,因为它们切断的是缓存复用。
从这个角度看,"长上下文 Agent 很贵"很多时候并不只是模型问题,而是前缀管理问题、状态外化问题和工具回传规范化问题。
记忆整理
长会话最大的问题不是"上下文窗口不够大",而是"上下文越来越脏"。人写文章会分章,每章有主题,章节之间有承接;Agent 的历史也应该被整理成结构,而不是把所有对话、日志、工具输出按时间顺序无限堆叠。
Anthropic 的 compaction 文档把它定义为一种上下文管理技术:当上下文变长时,把历史压缩成更紧凑的表示,以便继续任务。这个方向是正确的,但实现方式很关键。粗暴压缩会带来两个问题:第一,丢掉后续需要的细节;第二,压缩摘要本身每次都变化,破坏前缀稳定。
Claude Code 被社区拆解后讨论的 Auto-Dream(社区分析概念,并非 Anthropic 官方功能),核心想法可以理解为"睡眠式记忆整理":不是等上下文爆了再临时压缩,而是在任务过程中把历史整理成更长期、结构化、可复用的记忆。它像人在写长文时做章节总结:第一章讲了什么,第二章得出了什么结论,哪些决定已经确定,哪些 TODO 还没做,哪些文件和约束最重要。
一个好的 memory consolidation 至少要区分四类信息:
-
稳定身份和规则:system prompt、工具说明、权限边界,适合放在稳定前缀。
-
任务状态:当前目标、已完成步骤、未完成步骤,适合放在 checkpoint 或计划文件。
-
高价值事实:用户偏好、项目约束、关键设计决策,适合长期记忆。
-
低价值噪声:原始日志、重复错误、临时输出,应该被裁剪或外部存储。
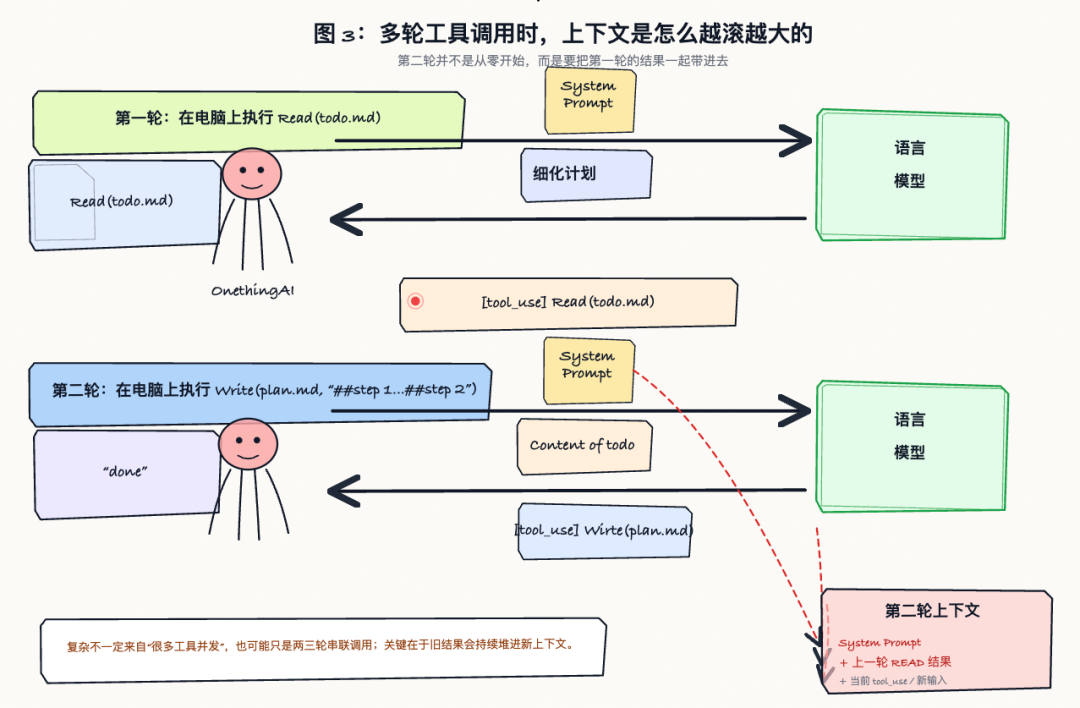
以一个简单场景为例:
两轮工具调用------第一轮 Read(todo.md),第二轮 Write(plan.md)。复杂性并不一定来自十几个工具并发;只要上一轮结果要进入下一轮上下文,history 就会滚起来。如果每一轮都把全部上下文重发,且压缩方式不稳定,cache 友好性就会下降。
所以记忆整理真正要解决的,不是"怎么把所有历史缩短",而是"怎么让模型下次还看得懂,而且缓存还能复用"。很多系统直到窗口快满时,才开始临时摘要历史;这时摘要既不稳定,也没有清晰结构。
更好的方式是:在任务推进过程中持续抽取稳定事实,把短期噪声及时外化,把长期记忆以固定结构沉淀下来。这样下一轮重建上下文时,模型看到的是清晰的章节和索引,而不是一团被打碎后重新缝起来的历史。
Agent Token 的虚假繁荣
罗福莉(Fuli Luo)的观点以及 Chayenne Zhao《Agent Token 的虚假繁荣:停止用消防水龙头浇花》这篇文章,都在指向一个行业里越来越难回避的问题:Agent 创造了巨大的 token 需求,但其中有相当一部分可能不是"真实任务需求",而是框架设计制造出来的浪费。
Chayenne Zhao 作为推理引擎开发者,批评的重点不是"Agent 不该用 token",而是很多 Agent 框架没有为 Prefix Cache 命中率、KV Cache 内存布局、请求前缀稳定性做认真设计。文章里的比喻很锋利:推理引擎工程师像水利工程师一样精心设计节水系统,却看到有人拿消防水龙头浇花。
这个比喻能解释为什么"token 用量增长"不一定等于"Agent 价值增长"。一个长 session 消耗 700K token,可能说明任务确实复杂;也可能说明:
-
相同的 system prompt 被重复发送;
-
已经确认过的 tool result 被反复 parse;
-
低信息密度历史被完整保留;
-
本该外部持久化的状态被塞进 prompt;
-
本该结构化索引的文件系统状态被重复转成自然语言。
这就是"Agent Token 的虚假繁荣":表面上 token 需求暴涨,背后却可能是一套低效 harness 把简单任务放大成了高成本长会话。
以一个典型场景估算:
假设 system prompt 30K token、工具 schema 20K token、每轮 tool result 平均 5K token,一个 20 轮的 coding session 如果没有 prefix cache 命中,每轮都全量 prefill,总 prefill 量可能超过 1.5M token。
同样的任务,如果前缀稳定、cache 命中率达到 80%,实际计费 prefill 可以降到 300K 以下。这个差距不是优化细节,而是成本量级的区别。
如果 harness 知道哪些前缀应该稳定,哪些工具结果应该规范化,哪些状态应该存在外部数据库而不是 prompt,哪些历史应该摘要成记忆,哪些文档应该按需检索,它就能显著减少无效 token。
反过来,如果推理引擎能理解 Agent session 的语义,也可能做更聪明的缓存淘汰和前缀复用。未来真正有价值的方向,很可能是 Agent-Inference 协同设计。
"停止用消防水龙头浇花"这个比喻的力量就在这里。消防水龙头不是没价值,而是它服务的目标和浇花不匹配。今天很多 Agent token 消耗也是类似逻辑:不是 token 本身有问题,而是我们用一种极度粗放的方式去完成原本可以更精细完成的任务。
如果这件事只是多花一点钱,也许更便宜的算力最终会把问题掩盖掉;但 Agent 时代的 token 浪费不只影响账单,还会影响延迟、并发、容量和用户体验。用户最终感知到的不是"你用了多少 token",而是"为什么它这么慢""为什么它反复做无用功""为什么它明明做了很多轮,却没有把事做完"。
Claude Code 和 Managed Agents 到底在托管什么
Anthropic 的 Managed Agents 文档用一句话概括了产品方向:你定义 agent 的任务、工具和 guardrails,Anthropic 在自己的基础设施上运行它。官方图里出现了几个关键词:Session、Harness、Sandbox、Orchestration、Tools / Resources / MCP。
这几个词连起来,基本就是生产级 Agent 的最小系统。
✅ Session
一次持续任务的容器。
用户不是只发一个问题,而是在一个可恢复的任务上下文里持续推进目标。Session 需要保存状态、历史、进度和权限。
✅ Harne ss
模型外面的控制层。
它负责把用户输入、系统提示、工具定义、历史结果、环境状态组织成下一次模型调用;负责解释模型输出;负责把 tool use 转成真实执行;负责把结果再回灌给模型。
✅ Sandbox
安全执行环境。
Coding agent、browser agent、data agent 都可能执行高风险动作:写文件、跑命令、访问网络、修改数据库。没有 sandbox,Agent 的自主性越强,系统风险越高。
✅ Orchestration
调度与编排。
复杂任务不是一轮模型调用能完成的。它可能要串行执行多个步骤,也可能并发启动子任务,还可能在失败时重试、在高风险时请求人类确认。
✅ Tools / Resources / MCP
Agent 接触外部世界的接口。
工具 schema 是否稳定、返回是否规范、权限是否可控、资源是否可索引,都会直接影响 Agent 的质量和成本。
所以 Managed Agents 卖的不是"Claude 多回答几句话"。它卖的是:Anthropic 帮你托管这套 Agent 运行系统。换句话说,它从"模型 API"向"Agent runtime"上移了一层。
这个变化看似只是产品包装升级,实则很关键。传统 API 模式下,用户买到的是一次次独立推理;Managed Agents 模式下,用户买到的是一个连续运行过程。连续运行意味着 Anthropic 可以统一控制 session 生命周期、工具调用格式、上下文压缩、失败恢复、沙箱边界和调度策略。对于用户来说,这不只是"少写一点 glue code",而是少承担大量基础设施决策。
Managed Agents 的产品描述强调的是 tasks、tools、guardrails 和 Anthropic infrastructure。这里的关键词不是 completion,而是 run。Anthropic 并不是在说"我们帮你包装 prompt",而是在说"你给出任务和边界,我们替你运行 Agent"。
它和云计算历史有点相似。最早大家买的是裸机器,后来买虚拟机,再后来买托管数据库、托管消息队列、托管函数。原因不是开发者不会搭这些系统,而是托管服务在规模、稳定性和运维成本上更划算。Managed Agents 很可能是这条路在 AI 时代的延伸:从托管算力,走向托管"任务执行系统"。
为什么 Anthropic 要发布 Managed Agents
这个问题可以从三个层面看:
工程层
一个能跑进生产的 Agent,不只是模型强。它需要会话管理、工具治理、沙箱、编排、可观测性、错误恢复、权限控制、上下文压缩。这些东西每家公司自己做一遍,门槛高、重复劳动多、质量参差不齐。Managed Agents 把这些通用基础设施托管起来,降低用户构建生产 Agent 的门槛。
成本层
订阅制 coding agent 和按量 API 的成本结构天然有张力。订阅用户希望"多用就是赚到",模型公司则要承担真实推理成本。如果第三方 harness 通过订阅入口发起大量低效长上下文请求,成本会失控。据报道,Anthropic 已限制第三方 harness 通过 Claude 订阅入口发起不可控的大规模请求,从商业角度并不意外:订阅价格很难覆盖无限制、不可控、低缓存命中的 agent token 消耗。
商业模式层
token 定价适合单次模型调用,但 Agent 的价值不只在 token。用户真正需要的是任务完成:代码改好、报告写完、数据分析完成、工单处理结束。Managed Agents 让 Anthropic 有机会把价格从"每百万 token"扩展到"托管会话、运行时、工具、安全和结果交付"。
如果未来 Agent 成为主流使用形态,单纯卖便宜 token 会越来越难。因为最稀缺的不只是模型输出,而是稳定、高效、可审计地把模型输出转化成任务结果。谁能把 harness 和 infra 做好,谁就能把 token 成本转化成可控的服务能力。
还有一个容易被忽略的变化:当产品从模型 API 上移到 Managed Agents,厂商也获得了更大的优化空间。它可以统一控制工具 schema、缓存边界、session 压缩策略、沙箱环境和调度器行为。很多在"第三方随意拼接请求"的模式下做不到的优化,在托管模式下反而可做。这未必意味着托管一定更便宜,但往往意味着托管更可控。
一个好的 Harness 到底要解决什么
把前面的技术和产业逻辑合起来,一个好的 harness 至少要解决七件事。
✅ 稳定前缀
System prompt、工具 schema、权限规则、输出格式应该尽量稳定,并且放在固定位置。不要每轮动态拼接出不同顺序的工具列表,也不要让无意义字段破坏前缀一致性。
✅ 工具结果规范化
Tool result 不是原样回灌越多越好。它应该有固定 schema、稳定字段顺序、明确成功/失败状态、可行动摘要。日志和大文件内容应该按需引用,而不是全部塞进上下文。
✅ 上下文分层
不同信息应该去不同位置:稳定规则放 prompt prefix,任务进度放 state store,长期偏好放 memory,原始日志放外部文件或数据库,当前必要信息才进入模型窗口。
✅ cache-aware session
Harness 不能假装推理引擎不存在。它应该知道哪些内容适合 prompt caching,哪些前缀必须保持 token 级稳定,哪些动态内容应该后置,哪些历史重写会破坏 cache hit。
✅ 工具调度节制
不是每个问题都需要工具,不是每个工具结果都需要再次调用模型,不是每个子任务都应该并发。低价值 tool call 会把一次用户请求拆成多次昂贵的长上下文请求。
✅ 可观测性和预算控制
一个生产 Agent 应该能看到每轮 token、cache hit、tool call 数、失败原因、重试次数、上下文压缩次数。没有这些指标,就无法区分"任务真的复杂"和"harness 在浪费"。
✅ 安全和恢复
Sandbox、权限审批、checkpoint、human-in-the-loop 不是可选项。Agent 越能做事,就越需要明确边界和可恢复状态。
所以,Managed Agents 的意义不是替开发者省掉几行 API 调用代码,而是把这些原本分散在工程团队里的能力产品化。它告诉市场:Agent 时代的竞争不再只是模型参数、上下文窗口和 token 单价,而是整套系统如何用算力。
如果把这七件事压缩成一句工程语言,那就是:一个好的 harness 必须同时对模型负责,也对系统负责。对模型负责,意味着它给模型的是干净、稳定、可接续的上下文;对系统负责,意味着它控制风险、可观测、可恢复、可优化。只做到前者,Agent 可能聪明但不安全;只做到后者,Agent 可能很稳但不够灵活。
也正是在这个意义上,harness 不是附属件,而是 Agent 产品真正的操作系统。模型给了它认知能力,harness 决定这些认知能力如何被调度、约束、保存和放大。
结语
Agent 时代一定会消耗更多 token。更长任务、更强工具、更深探索,都会带来真实需求。但这不意味着所有 token 增长都是健康增长。
如果一个 harness 反复发送不稳定前缀,回灌冗长工具结果,把状态全部堆进 prompt,用粗暴压缩破坏 cache 命中,那么它制造出来的繁荣就是虚假的。它看起来像"Agent 很努力",实际可能只是"上下文管理很粗糙"。
Anthropic 推 Managed Agents,罗福莉(Fuli Luo)讨论 Token Plan,推理引擎开发者批评 Agent token 浪费,这些事情放在一起看,指向同一个趋势:**模型公司、推理系统、Agent 框架必须开始协同设计。更便宜的 token 不是唯一答案;更聪明地使用 token,才是长期答案。**Agent 时代不属于烧算力最凶的人,而属于最会组织上下文、最会复用缓存、最会把模型能力转化为可靠任务结果的人。
参考资料与材料边界
Anthropic 官方文档:
-
https://platform.claude.com/docs/en/build-with-claude/prompt-caching
-
https://platform.claude.com/docs/en/build-with-claude/compaction
技术资料:
Claude Code / Auto-Dream 相关材料:
社区与行业观察:
- Fuli Luo 关于 Claude 订阅、第三方 harness 与 compute allocation 的观点;Chayenne Zhao《Agent Token 的虚假繁荣:停止用消防水龙头浇花》