1.进程优先优先级
是进程得到CPU的先后顺序,由于CPU少但进程多,因此要通过优先级确定谁先谁后的问题。
(1)优先级VS权限
优先级:得到资源的前提下获取资源的先后问题。
权限:能否得到某种资源的资格。
优先级在struct_task中是一个整形,其的值越低表明优先级越高,反之越低。
(2)基于时间片的分时操作系统
每一个进程依次占用CPU的时间是有限的,即时间片的时间到了该进程就只能等下一轮了。
OS在分配顺序时要考虑公平性,即进程的优先级可能会发生变化,但变化的幅度不能太大(后面会有具体体现)。
2.系统是如何知道访问文件的是拥有者,所属组,还是other的
//-a表示所有 -l表示展示进程的优先级
ps -al
//-n表示将显示用户名的地方转换为显示用户的UID
ls -n其实对于OS而言,拥有者,所属组的名字本质就是UID,访问文件的本质就是调用进程,而进程访问时会记录访问该文件用户的UID。OS通过对比这两处的UID来匹配访问该文件的用户时拥有者,所属组还是other的。
因此在linux中,用户访问/运行任何资源的本质都是进程访问,也就是是由进程来帮助用户进行各种操作的,进程就代表了用户。
3.PRI和NI
PRI:进程优先级的值,默认值为80.
NI:进程优先级的修改数据值,全称为nice,默认为0.
进程的真实优先级 = PRI(永远是默认) + NI.
top的本质是修改进程和数据。
r + pid(top内的一个操作):修改该进程的nice值
在调整后会发现PRI和NI的值都会变,此时能说明PRI的实际展现的是真实优先级。优先级的更新都是在默认值80的基准上进行更新的,即并不是根据上一次的优先级来更新的。
4.优先级的极值问题
renice的用法(renice修改的是nice值):
(1)-n + num:对当前的进程的nice值变化mun值,不加-n nice值直接变为num值。
(2)-p + pid:调整指定pid的进程。
//将指定的pid的nice值修改num值
renice -n num -p pidnice的调整范围为[-20,20),因此PRI的范围为[60,100)。
当优先级的分布不合理时,会导致优先级低的进程长期得不到资源造成进程饥饿。
5.竞争,独立,并行,并发
竞争:受CPU个数的限制,不同进程之间存在竞争关系。
独立:不同进程之间互不影响。
并行:多个进程分别在多个CPU下运行。
并发:多个进程在一个CPU下采用进程切换的方式,让每个进程各跑一小会来让所有进程一起推进。
6.进程切换
(1)死循环进程的运行
一旦一个进程占有CPU的时间是受时间片限制的。因此死循环进程不会杀死系统,因为CPU再会在该死循环呆一会,走了之后就可以关闭该进程了。
(2)CPU与寄存器
PCB的核心功能是让CPU找到该进程,找到后PCB的用途就没什么了,此时CPU就注重于操作代码和数据了,而进行操作的就是CPU内部的寄存器,而寄存器的功能管理正在运行的进程中的临时数据。
总结有:
(1)寄存器就是CPU内部的临时空间
(2)寄存器!=寄存器里面的数据。寄存器是其所处的物理空间,而里面的数据是内容,内容是可变的而空间只有一份且不可变。
(3)切换的核心操作
首先明白:每一次的时间片走完时,OS会存一份此时寄存器中的临时数据放在该进程的PCB中以便下一次能直接调用。因此CPU内的寄存器只有一份,但大部分进程有自己的上下文(上下文就是CPU的所有进程器最后所有的临时数据)。
(1)来了一个新进程时:CPU直接调用起的代码与数据,当时间片到期时,CPU会将此时所有点的寄存器数据拷贝一份给该进程然后再切断连接后找下一个进程。
(2)来了一个旧进程时:CPU先寻找其之前的上下文数据,拷贝到对应寄存器中从而继续运行该进程,当时间片到期时,CPU又会将此时所有点的寄存器数据拷贝一份给该进程然后再切断连接后找下一个进程。
因此进程切换最核心的操作就是保存和恢复当前进程的上下文数据。
task_struct中有一个TSS的结构体,该PCB的上下文数据就是存在该struct中的。同时还有一个bool类型isrunning的变量,用于区分一个进程是新进程还是旧进程。
7.linux版的调度算法
调度器=调度+切换。即功能为进程切换+选择进程。
下面的所有变量名都出自于这张图:
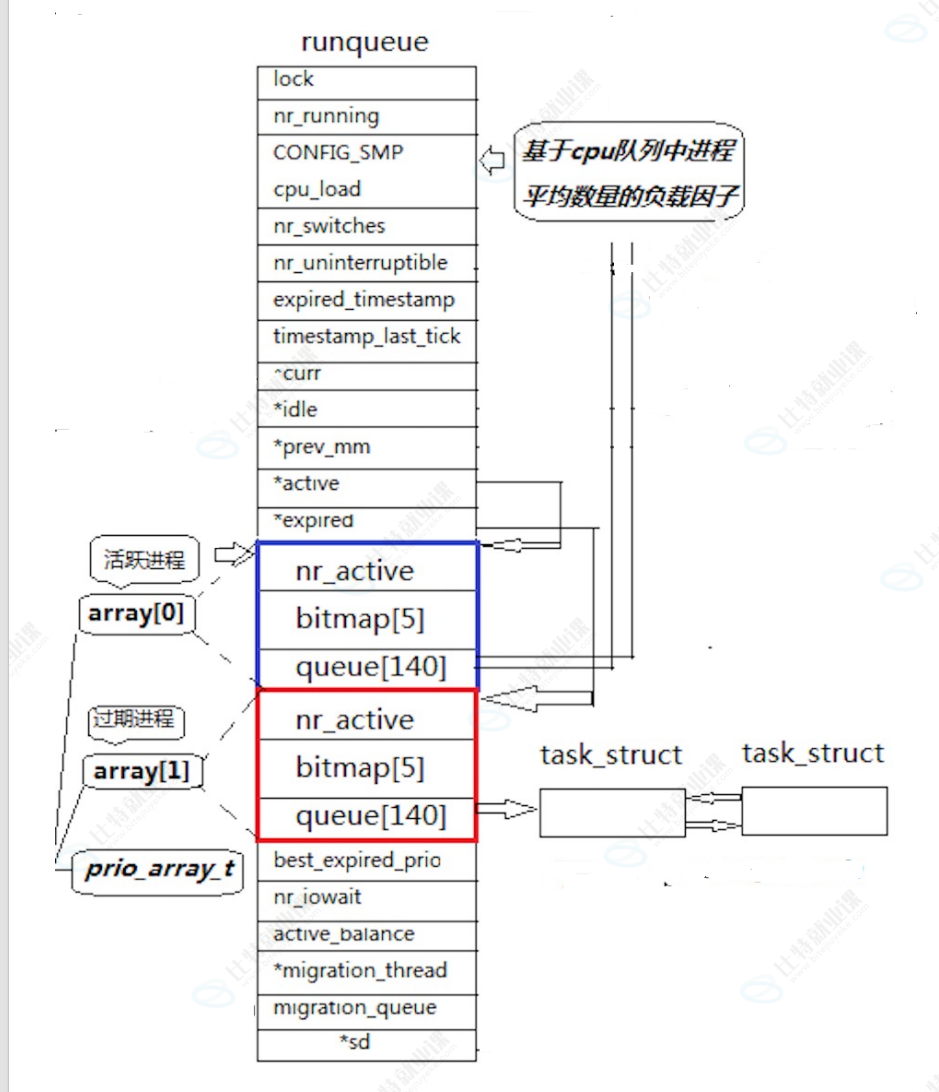
1.一个CPU对应一个运行队列(runqueue)
(1)queue140=>struct task_struct* queue140 =>即是一个指针数组
补充:操作系统分为两种:
(1)分时OS:基于时间片公平调度。
(2)实时OS:来了一个进程就知道处理完才到下一个(只有优先级被调整了才能强行改变进程顺序)
其实一个OS是可以兼容实时OS于分时OS的,只是内核中经常会将实时OS的代码条件编译掉。
因此由于queue\[\]中的0,100)是用于实时OS的,因此我们当下只考虑\[100,140)这部分,此时可以发现剩余的40个正好对应PRI的范围大小。(PRI和queue\[之间的关系就是哈希表)
FIFO:ququq140存的元素类型是task_struct*,因此所有优先级相同的进程会在该地址处形成链表连接起来。故在宏观上就是从小下标往大下标遍历,先找到先调度,有多个调第一个。
总结CPU的运行路程就是:CPU先去runqueue这个结构体,再去里面的queue\[\]中找进程调度。
2.调度器快速找到优先级最高进程的方式
有一个数组:size_t bitmap5;
该数组有160个bit位,前140个bit位代表了每一个queue140的空间,每个bit位的0/1代表了这个空间是否有节点。
用法:当bitmap对应下标的值位0就继续往下传,不为0是就查bit位,找到bit位1时就去找对应的进程结点。此时的查找效率就会比直接遍历queuq140要高。
8.O(1)调度算法
CPU查找找到一个进程的整个过程叫O(1)调度算法。
nr_active:说明整个调度队列目前一共有多少个进程的。
目前可以如此理解:O(1)调度算法找到一个进程,将这个进程取出来后就接到一个struct task_struct* current的指针,CPU对该进程进行进程切换后,current就将该进程接给CPU了。
此时存在一个问题:
一个进程的优先级不会随着时间片的到期而改变,只会从当前结点链表的第一个去到最后一个,此时如果有一个死循环的话,后面优先级低的进程就无法被调度造成进程饥饿。
解决方式:
//封装
struct prio_array {int nr_active,size_t bitmap[5],struct task_struct* queue[140];}
//设计+封装两rqueue_elem
struct rqueue_elem {prio_array[2] array;}
//设计两指针分别指向两数组
struct prio-array*active = &array[0];
struct prio-array*expired = &array[1];意义:当active指向的array中的quque140中的进程被调用后,该进程下一次就接入到expired中的queue140中,然后就以这种逻辑重复调度。当active的进程全部调度完了后就将两个指针的指向进行交换,交换后再重复操作即可。
内存优先级抢占:新插入的进程是进入active指向的array中的queue140中的,该进程优先级高的话就直接先运行该新进程了。
cpu_load:int,统计一个CPU所要操作的进程数,用于有多个CPU时,平衡每个CPU所挂的进程数。
cpu_switches:统计当前cpu的进程切换次数。
总结:PRI和NI之NI出现的意义,说白了NI就是用于延迟更新的,也就是该进程要进入expired指向的array的queue140时,NI才会将PRI更新。防止了直接修改PRI导致OS不知是将其直接更新还是用新变量更新等矛盾情况。