前言
在数据库开发中,索引是提升查询性能最核心、最有效的手段。一个设计精良的索引可以将查询速度提升数个数量级,而一个糟糕的索引设计,不仅无法提升性能,反而会浪费磁盘空间,拖慢数据写入速度。
一、在IDEA中图形化创建索引
IntelliJ IDEA(及其专业版内置的DataGrip)的Database工具窗口功能强大,让我们无需手写SQL即可高效地管理数据库对象。对于索引的创建,图形化界面不仅直观,还能有效避免因拼写错误导致的语法问题。
我们以一个电商系统中的商品表 pms_product 为例,该表包含 product_code (商品编码), category_id (分类ID), brand_id (品牌ID), shop_price (商城价格), product_name (商品名称) 等字段。
-
定位目标表
在IDEA右侧的
Database工具窗口中,展开你的数据源,找到目标数据库,再找到pms_product表。 -
打开表结构编辑器
右键点击
pms_product表,在弹出的菜单中选择Modify Object...(或者直接使用快捷键F4)。这将打开一个详细的表结构编辑界面。 -
切换到索引标签页
在表结构编辑界面的上方,你会看到
Columns,Keys,Indices,Foreign Keys等多个标签页。点击Indices标签页。 -
新建索引
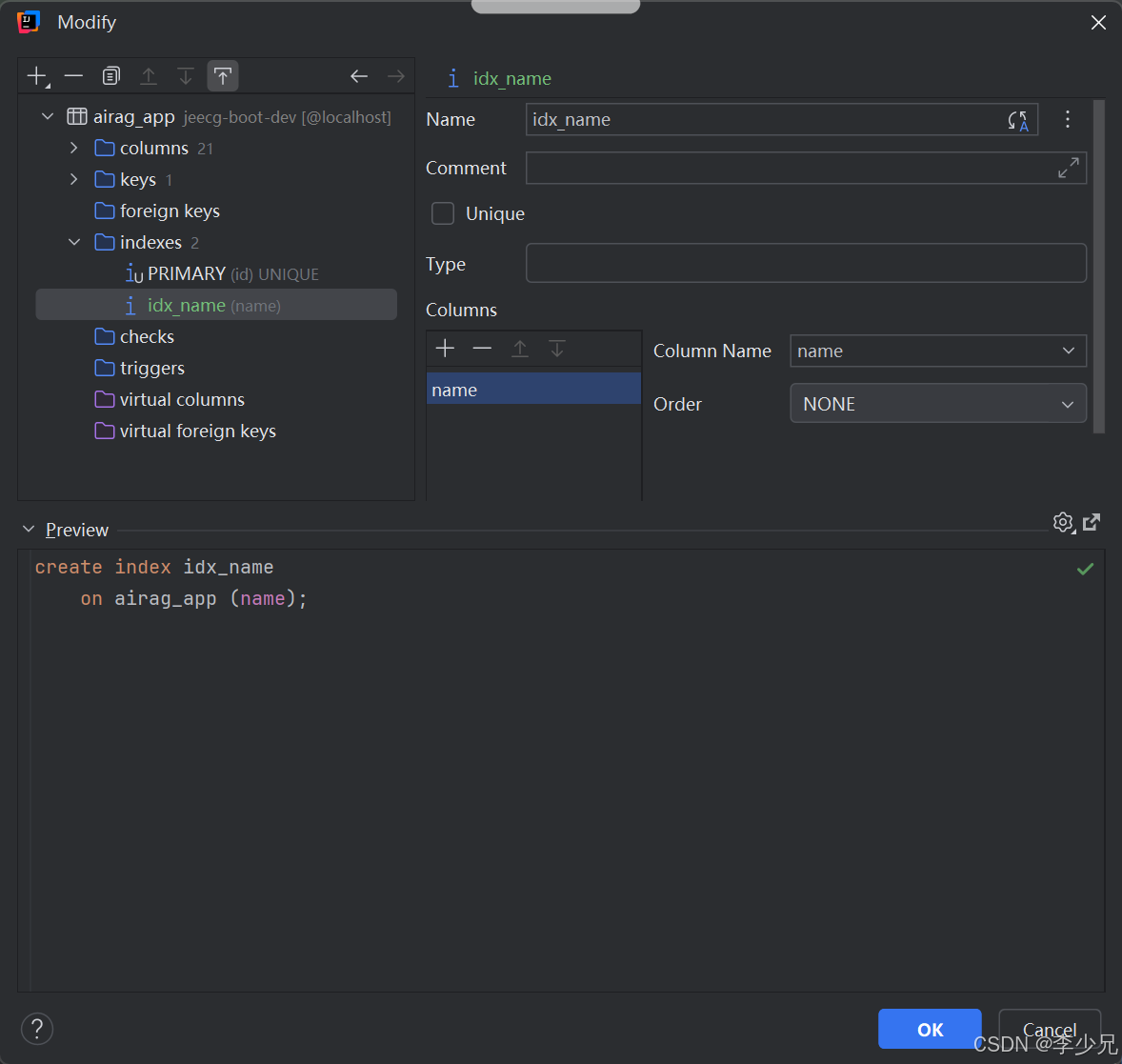
在
Indices标签页中,点击工具栏上的+号(或使用快捷键Alt + Insert),从下拉菜单中选择Index。此时,界面下方会出现一个新的索引配置行。 -
配置索引属性
这是最核心的一步,我们需要仔细填写每一项:
- Name (索引名称) : 将默认生成的名称(如
index)修改为一个符合规范的、有意义的名称。业界通用的规范是idx_字段名[_字段名]。例如,我们可以命名为idx_category_brand。 - Type (索引类型) : 保持默认的
BTREE。这是MySQL InnoDB引擎中最常用、最通用的索引类型,它支持等值查询、范围查询和排序操作。 - Columns (索引字段) : 点击
Columns区域下方的+号,会弹出当前表所有字段的列表。- 首先选择
category_id。 - 再次点击
+号,选择brand_id。 - 关键点:这里的上下顺序就是索引的实际顺序,它直接关系到"最左前缀原则"。
- 首先选择
- Unique (唯一索引) : 这是一个复选框。如果业务逻辑要求
category_id和brand_id的组合在表中是唯一的,则勾选它。对于普通的查询优化,不要勾选。
- Name (索引名称) : 将默认生成的名称(如
-
保存并应用
配置完成后,点击窗口右下角的
OK按钮。IDEA会自动在后台生成并执行对应的CREATE INDEXSQL语句。
二、MySQL索引的常见类型与SQL创建方式
虽然图形化界面很方便,但理解其背后的SQL语句是成为高级工程师的必经之路。索引的类型多种多样,每种都有其特定的应用场景。
-
普通索引(Index)
这是最基本的索引类型,没有任何限制。它的作用是加速对表中数据的查询。
-
场景 :
product_name字段经常被用于搜索,但允许重复。 -
SQL
sql-- 在 product_name 字段上创建普通索引 CREATE INDEX idx_product_name ON pms_product(product_name);
-
-
唯一索引(Unique Index)
唯一索引与普通索引类似,但索引列的值必须唯一,允许有空值。它能保证数据列的唯一性。
-
场景 :
product_code是商品的唯一编码,绝不允许重复。 -
SQL
sql-- 在 product_code 字段上创建唯一索引 CREATE UNIQUE INDEX uk_product_code ON pms_product(product_code);
-
-
联合索引(Composite Index)
联合索引是在多个字段上创建一个索引。它遵循"最左前缀原则",即查询条件中必须包含索引定义的最左侧字段,索引才能生效。
-
场景 :经常需要根据
category_id和brand_id组合查询商品。 -
SQL
sql-- 创建 (category_id, brand_id) 联合索引 CREATE INDEX idx_category_brand ON pms_product(category_id, brand_id);
-
-
全文索引(Fulltext Index)
全文索引主要用于对大文本字段(如
TEXT,VARCHAR)进行关键词搜索。它比LIKE '%keyword%'高效得多。-
场景 :在
product_description(商品详情)字段中进行全文搜索。 -
SQL
sql-- 在 product_description 字段上创建全文索引 ALTER TABLE pms_product ADD FULLTEXT INDEX ft_product_desc(product_description);
-
-
主键索引(Primary Key)
主键索引是一种特殊的唯一索引,不允许有空值。一个表只能有一个主键。通常在创建表时定义。
-
SQL
sqlCREATE TABLE pms_product ( id BIGINT NOT NULL AUTO_INCREMENT, product_code VARCHAR(64), -- ... 其他字段 PRIMARY KEY (id) -- 定义主键索引 );
-
三、核心原理:深入理解最左前缀原则
最左前缀原则是理解联合索引的钥匙,也是面试和实战中最常被考察的知识点。很多开发者误以为SQL语句中字段的书写顺序必须和索引定义完全一致,或者不理解为何索引会"莫名其妙"地失效。
什么是"最左前缀"?
联合索引 (category_id, brand_id) 在底层的B+树数据结构中,是按照以下规则进行排序和存储的:
- 首先,所有数据严格按照
category_id的值进行排序。 - 在
category_id值相同的情况下,再按照brand_id的值进行排序。
这就像一本电话簿,首先是按"姓氏"排序,在姓氏相同的人群内部,再按"名字"排序。
场景实战分析
基于我们刚刚创建的索引 idx_category_brand (category_id, brand_id),我们来看几种不同的查询场景:
| 场景 | SQL查询语句 | 索引使用情况 | 解析 |
|---|---|---|---|
| 精准匹配 | WHERE category_id = 10 AND brand_id = 5 |
完全生效 | 既用了"姓",也用了"名",可以精准定位到目标记录,效率最高。 |
| 只查最左列 | WHERE category_id = 10 |
生效 | 只要知道"姓氏",就能快速找到所有该姓氏的人。索引被有效利用。 |
| 跳过最左列 | WHERE brand_id = 5 |
失效 | 只知道"名"而不知道"姓",在电话簿里"名"是无序的,只能从头到尾翻找(全表扫描)。 |
| SQL顺序颠倒 | WHERE brand_id = 5 AND category_id = 10 |
完全生效 | MySQL的查询优化器非常智能,它会自动识别并调整条件的匹配顺序,依然能完美利用索引。 |
结论 :SQL语句中 WHERE 子句的书写顺序不会 影响索引的使用。但查询条件中必须包含 联合索引定义的最左侧字段(即 category_id),索引才能被激活。如果缺少最左列,索引将完全失效。
四、索引失效的常见"陷阱"
即使建立了索引,如果SQL语句编写不当,索引依然会失效,导致数据库进行低效的全表扫描。以下是生产环境中最常见的几种"陷阱"。
-
在索引列上进行函数运算或计算
这是新手最容易犯的错误,也是最容易被忽略的性能杀手。
-
错误写法
sql-- 对 create_time 字段使用了 YEAR() 函数 SELECT * FROM pms_product WHERE YEAR(create_time) = 2023;后果 :索引失效。数据库为了判断每一行是否符合条件,必须取出
create_time的值并执行YEAR()函数。这个操作破坏了索引列的原始值,导致无法利用B+树的有序性进行快速查找,只能进行全表扫描。 -
正确写法
sql-- 将计算移到等号右边,使用范围查询 SELECT * FROM pms_product WHERE create_time >= '2023-01-01 00:00:00' AND create_time < '2024-01-01 00:00:00';这种写法直接对索引列进行范围比较,可以高效地利用索引。
-
-
隐式类型转换
这是一个非常隐蔽的"陷阱",往往在上线后才暴露问题。
-
场景 :假设
product_code字段在数据库中被定义为VARCHAR(64),并且已经为其建立了索引。 -
错误写法
sql-- 查询值没有加单引号,被MySQL识别为数字类型 SELECT * FROM pms_product WHERE product_code = 10001;后果 :MySQL发现字段是字符串类型,而查询值是数字类型,会自动执行一个隐式转换,相当于
WHERE CAST(product_code AS SIGNED) = 10001。这等同于在索引列上使用了函数,导致索引失效。 -
正确写法
sql-- 加上单引号,确保查询值的类型与字段类型一致 SELECT * FROM pms_product WHERE product_code = '10001';
-
-
模糊查询以通配符开头
-
错误写法
sql-- 百分号在最前面 SELECT * FROM pms_product WHERE product_name LIKE '%手机%';后果 :B+树是按照字段值的前缀进行排序的。
%开头意味着无法确定查找的起点,数据库只能扫描表中所有行的product_name字段,导致索引失效。 -
正确写法
sql-- 百分号在后面(前缀匹配) SELECT * FROM pms_product WHERE product_name LIKE '华为%';这种前缀匹配可以利用索引快速定位到以"华为"开头的记录。
-
-
使用
OR连接非索引字段-
场景 :
category_id字段有索引,但remark(备注)字段没有索引。 -
错误写法
sqlSELECT * FROM pms_product WHERE category_id = 10 OR remark = '热销商品';后果 :只要
OR连接的任意一个字段没有索引,MySQL优化器通常会认为使用索引的成本更高,从而直接放弃索引,选择全表扫描。
-
五、进阶优化与注意事项
-
索引冗余与覆盖索引
- 避免冗余索引 :如果你已经创建了联合索引
idx_a_b (a, b),那么不需要 再单独为字段a创建索引。因为联合索引本身就包含了a字段的有序信息,单独为a创建索引是完全多余的,只会浪费存储空间并降低INSERT、UPDATE等写入操作的性能。 - 利用覆盖索引 :如果一个查询所需的所有字段都包含在索引中,数据库引擎无需再"回表"查询原始数据行,性能极佳。
- 推荐 (覆盖索引) :
SELECT category_id, brand_id FROM pms_product WHERE category_id = 10; - 不推荐 (需要回表) :
SELECT * FROM pms_product WHERE category_id = 10;
后者在查完索引后,还需要拿着主键ID回到主索引(聚簇索引)中去获取其他字段的值,多了一次查找操作。
- 推荐 (覆盖索引) :
- 避免冗余索引 :如果你已经创建了联合索引
-
联合索引的字段顺序设计
在设计联合索引
(A, B)时,字段的顺序至关重要,通常遵循以下两个原则:- 区分度高的字段放前面 :区分度是指字段中不重复值的数量与总行数的比值。区分度越高,筛选能力越强。例如,
user_id的区分度远高于gender。将高区分度的字段放在前面,可以更快地缩小数据范围。 - 范围查询的字段放最后 :如果查询中既有等值查询(
=),又有范围查询(>、<、BETWEEN),必须将范围查询的字段放在联合索引的最后 。- 例如:
WHERE category_id = 10 AND shop_price > 100。 - 索引应建为:
(category_id, shop_price)。如果反过来(shop_price, category_id),那么查询时只能用到shop_price的索引,category_id将无法利用索引进行过滤。
- 例如:
- 区分度高的字段放前面 :区分度是指字段中不重复值的数量与总行数的比值。区分度越高,筛选能力越强。例如,
-
如何验证索引是否生效?
不要靠猜测,一定要使用
EXPLAIN命令。在你的SELECT语句前加上EXPLAIN,重点关注结果中的以下两列:key:显示实际被优化器选中使用的索引名称。如果为NULL,则说明没有使用任何索引。type:显示表的连接类型,代表了查询的效率。- 高效 :
const,eq_ref,ref,range。 - 低效(需优化) :
index(全索引扫描),ALL(全表扫描)。
- 高效 :
六、常见疑难问答
-
最左前缀原则只会出现在联合索引中吗?
是的,最左前缀原则是联合索引的专属特性。对于单列索引(只有一个字段的索引),数据库要么用,要么不用,不存在"用一半"的情况,所以谈不上"最左"前缀。
-
我可以在一张表中创建一个
INDEX idx_form_task (form_id, task_id),再创建一个INDEX idx_task_form (task_id, form_id)吗?技术上完全允许,但在实际开发中往往没必要,甚至属于资源浪费。
假设你创建了联合索引:
INDEX idx_form_task (form_id, task_id):- 查询
WHERE form_id = ?:能用上索引(最左前缀)。 - 查询
WHERE form_id = ? AND task_id = ?:能用上索引(完整匹配)。 - 查询
WHERE task_id = ?:用不上(跳过最左)。
此时,如果你再创建一个INDEX idx_task_form (task_id, form_id):
它是专门为了优化WHERE task_id = ?这种查询的。
只有当你有大量 单独查询task_id的需求时,才需要建(task_id, form_id)。
如果你既有WHERE form_id = ?的需求,又有WHERE task_id = ?的需求。 - 错误做法:只建一个联合索引
(form_id, task_id)。(因为查task_id会失效) - 正确做法:建两个单列索引,或者建一个联合索引 + 一个单列索引。
- 冗余做法:同时建
(form_id, task_id)和(task_id, form_id)。这通常浪费空间,除非你的查询经常涉及ORDER BY form_id, task_id和ORDER BY task_id, form_id这种截然不同的排序。
- 查询
-
能既创建联合索引,又创建单个索引吗?
可以,但要注意冗余。
假设你创建了联合索引:
INDEX idx_union (A, B)- 情况一:你再给 A 建单列索引
- 操作:
INDEX idx_union (A, B)+INDEX idx_single (A) - 结果:完全冗余,浪费资源!
- 原因:根据最左前缀原则,联合索引
(A, B)已经包含了A的索引功能。数据库在查询WHERE A = ?时,会直接使用联合索引。再单独给 A 建索引,就像是在字典里给"姓"排了一次序,又单独拿个小本本把"姓"排了一次序,纯属多此一举。 - 建议:删掉单列索引
idx_single (A)。
- 操作:
- 情况二:你再给 B 建单列索引
- 操作:
INDEX idx_union (A, B)+INDEX idx_single (B) - 结果:合理,且经常需要这样做。
- 原因:联合索引
(A, B)无法优化WHERE B = ?的查询。如果你经常需要根据 B 单独查询,就必须给 B 单独建一个索引。 - 建议:保留。
- 操作:
- 情况一:你再给 A 建单列索引
-
我创建了联合索引
INDEX idx_form_task (form_id, task_id),SQL是WHERE task_id = '5' AND form_id = '101'。这种有违反最左前缀原则吗?完全没有违反,索引依然会生效。
这其实是数据库开发中一个非常经典的问题,很多新手都会误以为 SQL 里的字段顺序必须和索引顺序一模一样。
核心结论:MySQL 的查询优化器非常聪明,它会自动分析你的 SQL 语句。无论你写成:
sqlWHERE task_id = '5' AND form_id = '101'还是:
sqlWHERE form_id = '101' AND task_id = '5'数据库在执行时,都会识别出这两个条件,并根据你建立的索引
INDEX idx_form_task (form_id, task_id),自动调整匹配顺序。它会先利用form_id定位,再利用task_id过滤。所以,SQL 语句中 WHERE 条件的书写顺序,不影响索引的使用。
"最左前缀原则"里的顺序,指的是索引定义时的顺序以及查询条件是否包含最左边的列,而不是 SQL 语句的书写顺序。
你的索引定义:
(form_id, task_id)你的查询:
WHERE task_id = '5' AND form_id = '101'分析:
- 优化器看到了
form_id = '101',发现它是索引的第一列(最左列),匹配成功。 - 优化器看到了
task_id = '5',发现它是索引的第二列,匹配成功。 - 结果:两个字段都用上了索引,效率最高。
怎么验证?
你可以使用EXPLAIN命令来查看执行计划:
sqlEXPLAIN SELECT * FROM fc_form_data WHERE task_id = '5' AND form_id = '101';在结果中,你会看到:
key字段显示使用了idx_form_task。key_len字段显示的长度应该是两个字段长度之和(说明两个字段都参与了索引查找)。
总结:只要你的 SQL 语句中包含了联合索引的最左前缀字段(即form_id),哪怕你把task_id写在前面,或者把form_id写在最后面,索引都能正常工作。
- 优化器看到了
-
MySQL可以对相同字段创建不同索引吗?
可以。MySQL允许对同一个字段创建多个名称不同但结构相同的索引,但这是一种极其糟糕的实践,会造成严重的资源浪费。
例如,以下两条SQL语句都可以成功执行:
sqlALTER TABLE test ADD INDEX idx_test02 USING BTREE(UPDATED); ALTER TABLE test ADD INDEX idx_test03 USING BTREE(UPDATED);从效果上看,这两个索引保留一个即可。因为它们只是名称不同,索引字段相同,实际上就是相同的索引。创建重复索引会:
- 浪费磁盘空间。
- 降低
INSERT、UPDATE、DELETE等写入操作的性能,因为每次数据变动都需要更新多个相同的索引树。
因此,应严格避免创建重复索引。
-
不同表的索引命名相同会冲突吗?
不会。MySQL对索引名称的作用域限制在单个表内。也就是说,同一数据库中不同表可以拥有相同名称的索引而不会产生冲突。
然而,同一张表内的索引名称必须唯一,不能重复。
尽管如此,在实际开发中,建议采用统一规范为索引命名,比如结合表名和字段名来定义索引名称。这样不仅有助于区分不同表的索引,还能提高代码可读性和维护性。例如,对于用户表
user的id字段索引,可以命名为idx_user_id;订单表order的日期字段date索引则命名为idx_order_date。
七、拓展:索引底层原理深度剖析------为什么加了索引会更快?
我们在前面学会了如何创建索引、如何避免索引失效,但你是否思考过:为什么加了索引,查询速度就能从几秒甚至几分钟缩短到几毫秒?这背后到底发生了什么?
要理解这个问题,我们需要深入到MySQL的存储引擎(以最常用的InnoDB为例)的底层,从数据结构 和磁盘I/O两个维度来揭开索引的神秘面纱。
1. 索引的本质:空间换时间
索引的本质,其实就是一种数据结构。
如果把数据库表比作一本书,那么索引就是书的目录。
- 没有索引(全表扫描):就像你要找书中关于"MySQL原理"的内容,如果没有目录,你只能从第一页翻到最后一页,逐字逐句地找。数据量小的时候无所谓,如果书有几百万页(几千万行数据),这将是灾难性的。
- 有了索引:你可以直接查目录,找到对应的页码,翻过去就能找到内容。
在计算机领域,这是一种典型的**"空间换时间"**的策略。索引文件需要占用额外的磁盘空间来存储,但它能极大地减少查询时需要扫描的数据量,从而换取查询时间的缩短。
2. 为什么MySQL选择B+树?(数据结构层面的降维打击)
MySQL InnoDB引擎默认使用的索引结构是B+树 。为什么不是数组、链表或者二叉树?这完全是为了适应磁盘存储的特性。
-
磁盘I/O的瓶颈 :
计算机的内存速度极快,但数据是持久化存储在磁盘上的。磁盘的读写速度(I/O)比内存慢几十万倍。因此,数据库性能优化的核心目标就是:尽量减少磁盘I/O的次数 。
磁盘读取数据是按"页"(Page)为单位的,InnoDB中默认一页的大小是16KB。每次I/O,至少读取一页。
-
二叉树的缺陷(树太高了) :
如果使用二叉树(每个节点最多两个分叉),数据量一大,树的高度就会变得非常高(瘦高型)。
查找一个数据,可能需要从根节点遍历到叶子节点,经过几十层。每一层节点如果不在内存中,就需要一次磁盘I/O。如果树高20,就需要20次I/O,这在数据库领域是不可接受的慢。
-
B+树的优势(矮胖子) :
B+树是一种多路平衡查找树。
- 多路:一个节点可以有非常多的分叉(InnoDB中一个节点可以存储上千个键值)。这意味着树非常"矮胖"。
- 高度极低:对于千万级数据的表,B+树的高度通常只有2到3层。这意味着,查找任意一条数据,最多只需要2到3次磁盘I/O。
3. B+树是如何实现的?(硬核原理解析)
让我们通过一个简单的计算,来看看B+树到底有多快。
假设:
- InnoDB页大小为16KB。
- 主键是
BIGINT类型,占8字节。 - 指针占6字节。
- 那么一个键值对(Key+Pointer)大约14字节。
一个非叶子节点能存多少个键值?
16KB / 14B ≈ 1170个。
这意味着,B+树的一个节点(一页)可以指向1170个子节点。
B+树的存储能力:
- 树高为1:只能存一页数据(很少见)。
- 树高为2:根节点指向1170个叶子节点。假设每页存10行数据,能存 1170 * 10 ≈ 1万行。
- 树高为3:根节点 -> 1170个中间节点 -> 1170 * 1170个叶子节点。能存 1170 * 1170 * 10 ≈ 1300万行数据!
结论 :几千万行数据的表,B+树高度仅为3。也就是说,无论数据量多大,InnoDB主键索引查询最多只需要3次磁盘I/O。这就是为什么加了索引会快的根本原因------它将O(N)的全表扫描复杂度降低到了O(log N),且常数极小。
4. 聚簇索引与非聚簇索引(数据到底存在哪?)
在InnoDB中,索引不仅仅是"目录",它和数据是绑定在一起的。
-
聚簇索引(主键索引) :
B+树的叶子节点 直接存储了整行数据 。
当你通过主键查询时,一旦在B+树中定位到叶子节点,数据就已经拿到了,不需要再做任何操作。这就是为什么主键查询最快。
-
非聚簇索引(二级索引/普通索引) :
我们在
form_id上建立的索引就是二级索引。它的B+树叶子节点不存整行数据 ,只存索引列的值 和主键值。
5. 回表(Table Lookup):为什么查主键最快?
这就引出了一个重要的概念------回表。
假设你执行了这样一条SQL:
sql
SELECT * FROM fc_form_data WHERE form_id = '101';因为你查的是SELECT *(所有字段),而form_id索引树上只有form_id和id(主键)。
- 第一步 :先在
form_id的二级索引树中找到form_id = '101'的记录,拿到主键id(假设是1001)。 - 第二步 :拿着主键
id = 1001,去**主键索引树(聚簇索引)**中再查找一遍,获取完整的行数据(如task_id,create_time等)。
这个过程叫回表。回表意味着多了一次B+树查询(多几次I/O)。
6. 覆盖索引(Covering Index):高手的优化技巧
如果你执行的是:
sql
SELECT id, form_id FROM fc_form_data WHERE form_id = '101';你会发现,查询需要的字段id和form_id在form_id的索引树上全都有 !
这时候,MySQL就不需要去查主键索引树了,直接返回索引树上的数据即可。
这就叫覆盖索引。覆盖索引避免了回表,是性能优化的重要手段。
总结
索引之所以快,是因为:
- 使用了B+树 数据结构,将树高控制在极低水平(2-3层),极大地减少了磁盘I/O次数。
- 利用了数据的有序性,让数据库能像查字典一样通过二分查找快速定位,而不是逐行扫描。
- 通过覆盖索引等机制,避免了额外的数据读取操作。
八、可视化图解:B+树结构与回表流程
为了更直观地理解索引的运作机制,我们使用 Mermaid 流程图来展示 InnoDB 中 B+ 树的结构以及"回表"查询的全过程。
假设我们有一张表 user,包含字段 id (主键), name (普通索引), age。
1. B+树结构图解
InnoDB 中,主键索引(聚簇索引)的叶子节点存储整行数据,而普通索引(二级索引)的叶子节点只存储主键值。
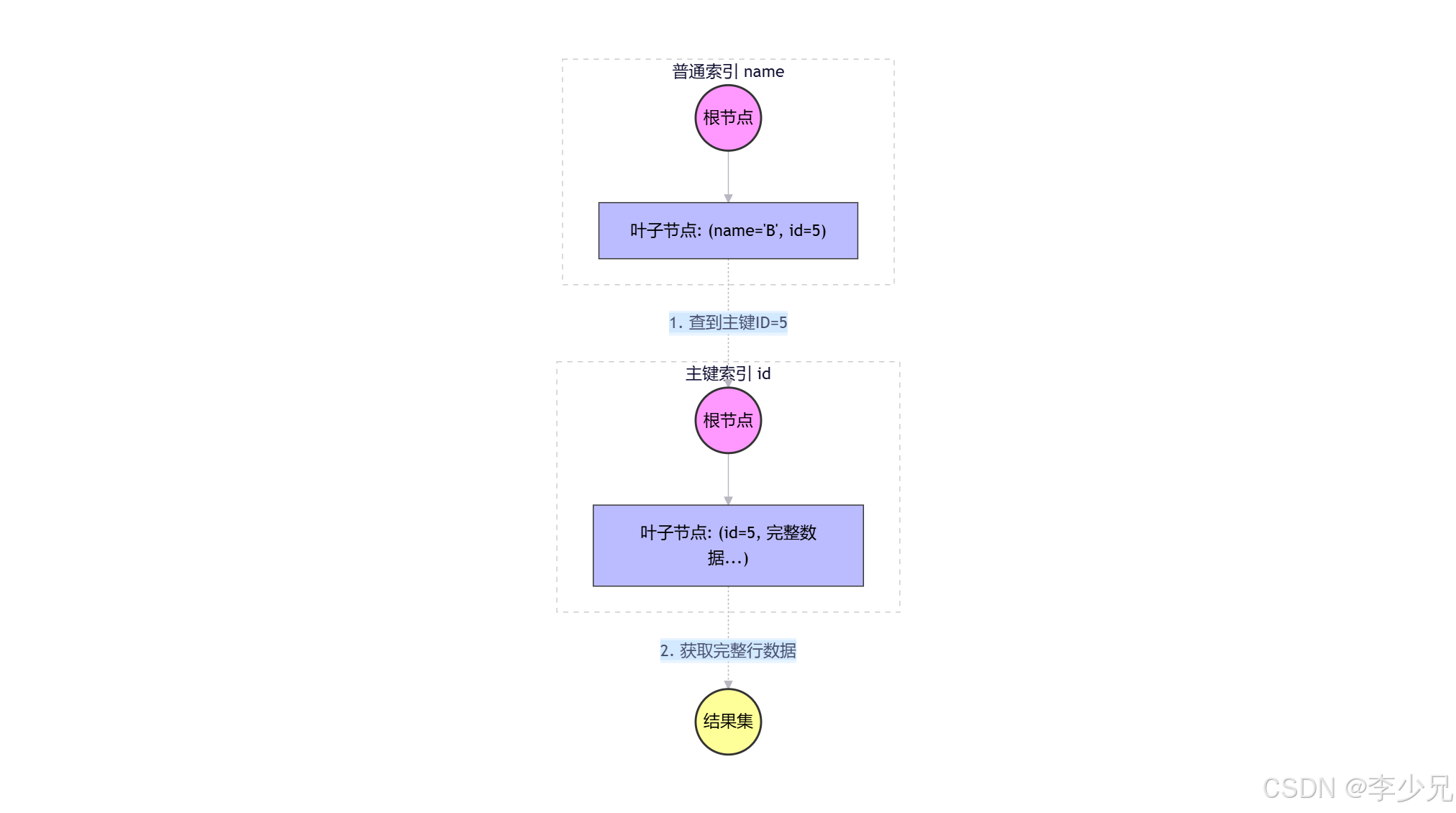
图解说明:
- 左侧(普通索引) :当我们执行
SELECT * FROM user WHERE name = 'B'时,首先在name的索引树中找到记录。 - 中间(获取主键) :在
name索引的叶子节点中,我们只找到了主键值id=5。 - 右侧(回表) :拿着
id=5回到主键索引树(聚簇索引)中查找,最终获取到完整的行数据(name,age等)。这个过程就是回表。
2. 覆盖索引流程图
如果 SQL 优化为 SELECT id, name FROM user WHERE name = 'B',则不需要回表。
是 (覆盖索引)
否 (需回表)
SQL查询: SELECT name FROM user WHERE name = 'B'
普通索引树查找
所需字段是否在索引中?
直接返回结果
拿着主键ID去聚簇索引查
返回完整数据
九、深度对比:B+树、B树与哈希索引
MySQL 之所以选择 B+ 树作为默认索引结构,是因为它在磁盘 I/O、范围查询和稳定性之间取得了最佳平衡。以下是三种主流索引结构的详细对比。
| 对比维度 | B+ 树 (MySQL InnoDB默认) | B 树 (平衡多路查找树) | 哈希索引 (Hash Index) |
|---|---|---|---|
| 数据存储位置 | 仅叶子节点存储完整数据,内部节点仅存索引键。 | 所有节点都存储索引键和对应数据。 | 仅存储哈希值和指向数据的指针。 |
| 树的高度 | 更低(矮胖)。因内部节点不存数据,单页可存更多键值,IO次数更少。 | 较高。因节点存数据,单页存储的键值少,树更高。 | 无树结构,基于哈希表。 |
| 范围查询 | 极强 。叶子节点通过双向链表连接,只需遍历链表即可。 | 较弱。需进行中序遍历,涉及大量随机 IO。 | 不支持。哈希值是无序的,无法进行范围扫描。 |
| 排序查询 | 支持 。索引本身有序,可直接利用索引顺序进行 ORDER BY。 |
支持。 | 不支持。 |
| 模糊查询 | 支持前缀匹配 (如 LIKE 'abc%')。 |
支持。 | 不支持。 |
| 等值查询 | 快 (O(log N))。所有查询都需走到叶子节点,性能稳定。 | 快 (可能 O(1)~O(log N))。若数据在非叶子节点命中则极快,但不稳定。 | 极快 (O(1))。直接计算哈希地址定位,无 IO 冲突时最快。 |
| 适用场景 | 通用型。绝大多数业务场景,尤其是涉及范围查询、排序、分页的。 | 较少用于数据库主索引,多用于文件系统元数据管理。 | 特定型。仅适用于内存数据库(如Redis)或纯等值查询场景(如配置表)。 |
核心总结:
- B+ 树胜在"范围查询"与"I/O友好" :B+ 树的内部节点不存数据,这使得它比 B 树更"矮胖",同样的磁盘页能容纳更多索引键,大大降低了树的高度,减少了磁盘 I/O 次数。同时,叶子节点的链表设计让它成为了范围查询(
BETWEEN,>,<)和排序(ORDER BY)的王者。 - 哈希索引胜在"精准打击" :虽然哈希索引在
=查询上速度无敌,但它是个"偏科生"。一旦遇到>、<或者ORDER BY,它就完全失效。因此,InnoDB 仅在内存中提供"自适应哈希索引"来辅助热点数据的等值查询,而不会将其作为默认的持久化索引结构。 - B 树的"中庸之道":B 树虽然也能工作,但由于其内部节点存储数据导致树高较高,且范围查询效率不如 B+ 树,因此在现代关系型数据库中逐渐被 B+ 树取代。