1. HTTP 协议
HTTP 在日常生活中十分常见。在互联网世界中,HTTP(HyperTextTransferProtocol,超文本传输协议)是⼀个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如HTML文档)。
HTTP协议是客户端与服务器之间通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP协议是一个无连接、无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
现在公网中,一般使用的都是HTTPS,在内网环境,依旧会使用HTTP。
2. URL 和 URI
平时我们俗称的"网址"就是说的URL。URL叫做统一资源定位符。
这是一个示例网站:http://www.example.jp:80/dir/index.htm?uid=1#ch1。
一个网址的构成:
1. 协议方案名
- http:// 或 https:// 等
- 作用:规定浏览器与服务器之间的通信规则
2. 服务器地址
- www.example.jp 或 mp.csdn.net
- 作用:定位互联网上的目标服务器
3. 端口号
- 标准端口可省略:浏览器会自动根据协议补充默认端口
- 非标准端口必须显式写出 : http://www.example.jp:8080
4. 文件路径
- /dir/index.htm 或 /
- 作用:定位服务器上的具体资源位置
5. 查询参数
- ?uid=1&spm=1000.2115.3001
- 作用:向服务器传递额外数据,以 ? 开头,多个参数用 & 连接
urlencode 和 urldecode
像 / ? : 等这样的字符,已经被 url 当做特殊意义理解了。因此这些字符不能随意出现。比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成 %XY格式。
urldecode 就是 urlencode 的逆过程。
人的上网行为两种:
- 输入(I):将服务器的数据给我(浏览、下载)
- 输出(O):将我的数据给服务器(上传、提交)
IO传输的是什么?网页 。网页本质是文件(HTML/CSS/JS/图片等)。
服务器上那么多文件,怎么保证找到想要的那个?需要全网唯一标识:
- IP地址 → 找到哪台服务器
- 端口号 → 找到服务器上的哪个服务
- 文件路径 → 找到服务里的哪个文件
三者合起来就是 URL(统一资源定位符)。 与URL对应的概念:URI(统一资源标识符)。
URL 与 URI 的对比:URL 侧重 怎么定位(地址),URI 侧重 是什么(身份标识)。
URL 里写 IP 地址太反人类,于是延伸出域名 :域名是IP的人类可读别名;计算机底层只认IP,域名是给人记的。
域名怎么转成IP?需要域名解析服务器(DNS)
解析流程 :输入 www.csdn.net -> 问DNS服务器-> DNS返回IP地址 -> 浏览器用IP访问。
如果本地服务器不知道,"树形向上查找" :本地DNS不知道 → 问根服务器 → 问顶级域服务器 → 问权威服务器。
三个问题:
浏览器怎么知道DNS服务器在哪?操作系统/网络配置提供IP地址
为什么要使用域名,直接使用ip,不好吗?对人类友好:记字符串比记数字容易
根服务器作用?全球域名查询的总入口 。关了:新网站打不开,已缓存的还能用
站在前端的视角来看 URI
站在前端视角,URI就是一个字符串 ,用来告诉服务器:我要请求什么。
但这个字符串有两种完全不同的含义:
静态资源,本质Linux web根目录下的真实文件路径。文件必须存在,直接返回文件内容。
HTML、CSS、JS、图片、音视频等静态资源 ,本质上都是服务器文件系统中的文件。HTTP传输时,它们都被封装为字节流,通过TCP连接传输。客户端获取后,浏览器根据Content-Type识别类型并做相应处理(渲染、执行、解码等)。
大部分静态资源只需读取并返回,无需服务器端动态生成。
动态服务,本质用户自定义的服务标识 。路径在web根目录不存在,由后端程序处理。
关键区分 :动态服务的路径是用户设计的逻辑标识 ,不是真实文件位置。后端根据URI字符串做功能路由,执行对应代码,返回动态生成的结果。
一个搜索链接:https://cn.bing.com/search?form=QBLH\&q=C%2B%2B
/search不是文件,而是后端提供的服务,根据参数返回动态结果。
正因为HTTP支持传参(GET/POST)+ 表单提交 ,后端才能根据URI做功能路由:
- /Login + 用户名密码 → 验证身份
- /Search + 关键词 → 查询数据库返回结果
HTTP服务从而产生动态效果。
3. HTTP请求与应答格式
HTTP底层,浏览器底层,用的都是TCP socket,用的都是 ip+port 的进程间通信机制。
1. HTTP请求的格式
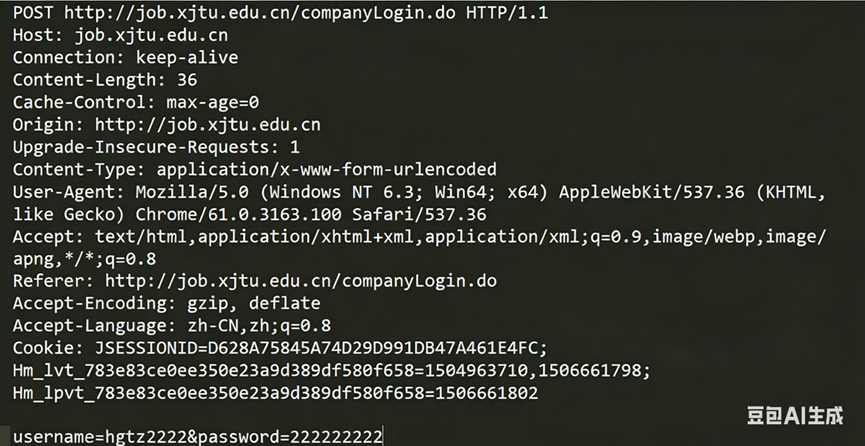
首行:方法+url+版本
Header:请求的属性,冒号分割的键值对。每组属性之间使用 \r\n 分隔,遇到空行表示 Header 部分结束。
Body:空行后面的内容都是 Body。Body 允许为空字符串。如果 Body 存在,则在Header中会有一个 Content-Length 属性来标识 Body 的长度。
网络传输中,HTTP请求本质上是一串连续的字节流,接收方需要正确"切割"和"理解"它。
怎么知道读完了? HTTP报文格式规定:报头以空行(\r\n\r\n)结束。虽然不知道整个请求多长,但一定能确定报头读完了(遇到\r\n\r\n即停)。
报头读完后,正文有多长?关键属性:Content-Length。
报头是纯文本,怎么变成结构化数据?接收方自主完成反序列化,无需外部协议协助。
网页与HTTP请求的关系
网页确实可以看作多叉树结构 。用户访问一个页面时,浏览器首先请求主HTML文档,解析后发现其中引用的各类资源(CSS、JS、图片等),再递归发起后续HTTP请求获取这些资源。
一个网页通常由一个HTML文档 + 多种资源构成。浏览器需要将所有必需资源通过HTTP获取后,才能完整渲染页面。
2. HTTP 应答的格式
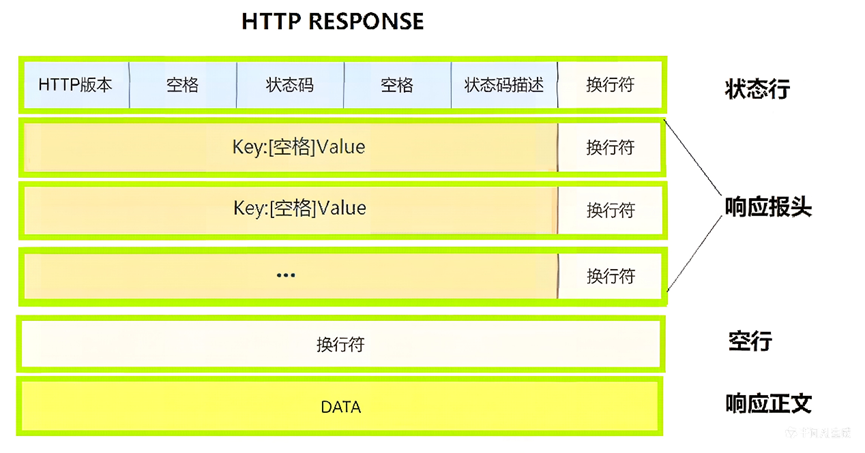
首行:版本号+状态码+状态码解释
Header:请求的属性,冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示 Header 部分结束
Body:空行后面的内容都是 Body。Body 允许为空字符串。如果 Body 存在,则在 Header 中会有一个 Content-Length 属性来标识Body的长度;如果服务器返回了一个 html 页面,那么html 页面内容就是在 body 中。
3. 格式出现的内容
1. HTTP 版本
HTTP版本(1.0、1.1、2.0等)标识了通信协议的规范和能力:
| 版本 | 核心特性 |
|---|---|
| HTTP/1.0 | 短连接(每次请求-响应后关闭TCP连接) |
| HTTP/1.1 | 长连接 (Keep-Alive,复用TCP连接) |
| HTTP/2.0 | 多路复用、头部压缩、服务器推送 |
请求报文中的HTTP版本表示客户端支持的协议版本 ,服务端应尽量兼容。但服务端返回的响应版本不一定必须比客户端新 ------服务端根据自身支持情况返回,通常与请求版本一致或降级兼容。
2. HTTP 方法
HTTP请求的请求方法,最常用(99%)的就两种:GET 和 POST。
GET方法 → URL传参
请求格式:
GET /submit?first_name=张&last_name=三 HTTP/1.1
Host: yourdomain.com
| 属性 | 说明 |
|---|---|
| action="/submit" | 指定提交给服务器的哪个服务/路径 |
| method="GET" | 参数拼接到URL后 |
| 参数格式 | ?key1=value1&key2=value2 |
本质:URI携带参数 → ip:port/path?参数。
URI与Web根目录
- URI是服务器上特定资源的路径标识
- Web根目录是服务器文件系统的映射起点
- 当URI为/时,服务器默认返回首页文件(通常是index.html)
HTTP服务的本质:将服务器特定目录下的文件,以HTTP响应形式返回给客户端(浏览器或App)。这些文件多为超文本类型,因此称为"超文本传输协议"。
POST方法 → 正文传参
请求格式:
POST /submit HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 35
first_name=xxxx&last_name=xxxx
GET 和 POST 方法的核心区别
| GET | POST | |
|---|---|---|
| 核心区别 | 传参形式不同 :URL传参 | 传参形式不同 :正文传参 |
| 用途 | 获取资源、简单查询 | 提交数据、登录、上传 |
| 私密性 | 参数暴露(回显) | 参数不直接显示 |
| 安全性 | 都不安全 | 都不安全 |
为什么它俩**不安全?**因为HTTP明文传输。
解释:
传输流程:HTTP报文 = 纯文本字符串 -> 经过路由器、交换机、中间设备... -> 同一局域网内,其他主机也能收到报文(只是MAC地址不匹配会丢弃) -> 非法分子抓包工具绕过丢弃机制 → 直接看到密码等敏感信息。
如何解决?根本问题 :HTTP传输的是明文,任何人截获都能直接阅读。只要加密了,不就不是明文了吗?使用 HTTPS 协议,HTTPS = HTTP + SSL/TLS。
传输流程:HTTP请求 -> SSL/TLS加密层 → 整个报文变成密文 -> 网络传输(即使被截获也是乱码) -> 对端解密 → 还原HTTP请求。
HTTP 与 HTTPS 的对比:
| 对比 | HTTP | HTTPS |
|---|---|---|
| 端口 | 80 | 443 |
| 安全性 | 明文,不安全 | 加密,传输安全 |
| 效率 | 高 | 略低(加密消耗计算) |
| 使用场景 | 内网、公开数据 | 公网、敏感数据 |
注意 :加密保证的是传输过程安全,不是服务端安全。客户端知道访问的是443端口的服务,但身份验证靠证书机制,不是仅靠端口。
除了 GET 和 POST 这两种常用的方法之外,还有其它的方法:
1. PUT 方法
用途:用于传输文件,将请求报文主体中的文件保存到请求URL指定的位置。
特性:不太常用,但在某些情况下,如RESTfulAPI中,用于更新资源。
2. HEAD 方法
用途:与GET方法类似,但不返回报文主体部分,仅返回响应头。
特性:用于确认 URL 的有效性及资源更新的日期时间等
3. DELETE 方法
用途:用于删除文件,是PUT的相反方法
特性:按请求URL删除指定的资源。
4. OPSITIONS
用途:用于查询针对请求URL指定的资源支持的方法
特性:返回允许的方法,如 GET、POST 等。
使用 curl 工具测试这些方法,curl:命令行HTTP客户端,模拟浏览器行为。
PUT方法 → 上传覆盖
请求示例:
curl -X PUT -d "file content" http://example.com/upload/file.txt
显示:
css
PUT /upload/file.txt HTTP/1.1
Host: example.com
Content-Type: text/plain
Content-Length: 12
file content响应示例:
css
HTTP/1.1 201 Created ← 新建成功
Location: /upload/file.txt
HTTP/1.1 204 No Content ← 覆盖成功,无返回体HEAD方法 → 只取"头"不取"身"
请求示例:
curl --head http://www.baidu.com 或 curl -X HEAD -i http://example.com
显示:
css
HEAD /index.html HTTP/1.1
Host: www.baidu.comDELETE方法 → 删除资源
请求示例:
curl -X DELETE http://example.com/api/users/123
显示:
css
DELETE /api/users/123 HTTP/1.1
Host: example.com
Authorization: Bearer token_here ← 通常需要认证响应示例:
css
HTTP/1.1 204 No Content ← 删除成功,无返回体
HTTP/1.1 200 OK ← 删除成功,返回确认信息
Content-Type: application/json
{"message": "User 123 deleted", "status": "success"}
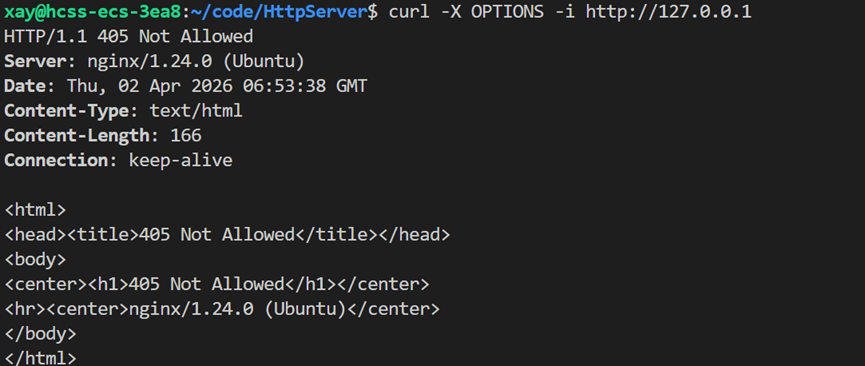
HTTP/1.1 404 Not Found ← 资源不存在,无法删除OPTIONS方法 → "你能干什么?
请求示例:
curl -X OPTIONS -i http://api.example.com,或带具体路径:curl -X OPTIONS -i http://example.com/upload
响应示例**(服务器允许时):**
css
HTTP/1.1 204 No Content
Allow: GET, POST, HEAD, OPTIONS ← 支持的方法列表
Access-Control-Allow-Origin: * ← 跨域许可
Access-Control-Allow-Methods: GET, POST, PUT, DELETE
Access-Control-Allow-Headers: Content-Type, Authorizatio响应示例**(服务器不允许时)**
css
HTTP/1.1 405 Not Allowed
Server: nginx/1.24.0 (Ubuntu)nginx ------ 轻量级Web服务器
安装与使用
sudo apt install nginx ------ 安装
sudo nginx ------ 启动
ps ajx | grep nginx ------ 查看进程(master + worker)
sudo nginx -s stop ------ 停止
nginx特点
| 特性 | 说明 |
|---|---|
| 静态资源服务器 | 默认根目录 /var/www/html |
| 高并发 | 多worker进程处理请求 |
| 反向代理 | 可转发到后端动态服务 |
| 方法控制 | 可配置允许/拒绝特定HTTP方法 |
部署自己的网页:将HTML文件放入 /var/www/html/ 即可通过 nginx 访问。
nginx默认关闭OPTIONS方法,防止攻击者探测服务器能力。
3. 状态码
HTTP 状态码(HTTP Status Codes)是服务器对客户端 HTTP 请求的响应状态的三位数字代码,用于表示请求的处理结果。最常见的状态码,比如200(OK),404(Not Found),403(Forbidden),302(Redirect, 重定向),504(Bad Gateway)。
它们被分为五类,由第一位数字标识:
1xx:信息性状态码
表示请求已被接收,继续处理。
- 100 Continue:客户端应继续发送请求体。
- 101 Switching Protocols:服务器同意切换协议。
- 102 Processing:服务器已收到请求并正在处理。
2xx:成功状态码
表示请求已成功被服务器接收、理解并接受。
- 200 OK:请求成功,响应体包含所请求的资源。
- 201 Created:请求成功并创建了新资源。
- 202 Accepted:请求已接受,但尚未处理完成(异步处理)。
- 204 No Content:请求成功,但响应中无内容返回。
3xx:重定向状态码
表示需要进一步操作才能完成请求,通常用于 URL 重定向。
- 301 Moved Permanently:资源已永久移动到新位置。
- 302 Found(临时重定向):资源临时位于另一个 URI。
- 304 Not Modified:资源未修改,可使用缓存(用于条件请求)。
4xx:客户端错误状态码
表示请求有错误,服务器无法处理。
- 400 Bad Request:请求语法错误或无法被服务器理解。
- 401 Unauthorized:需要身份认证(通常配合 WWW-Authenticate 头)。
- 403 Forbidden:服务器理解请求,但拒绝执行(权限不足)。
- 404 Not Found:请求的资源不存在。(最具有代表性)
5xx:服务器错误状态码
表示服务器在处理请求时发生内部错误。
- 500 Internal Server Error:通用服务器错误。
- 501 Not Implemented:服务器不支持请求的功能。
- 502 Bad Gateway:作为网关或代理时,从上游服务器收到无效响应。
- 503 Service Unavailable:服务器暂时不可用(如维护或过载)。
- 504 Gateway Timeout:作为网关或代理时,上游服务器未及时响应。
重点谈谈重定向状态码:
HTTP状态码301(永久重定向)和302(临时重定向)都依赖 Location 选项。
以下是关于两者依赖 Location选项的详细说明:
HTTP状态码301(永久重定向):
当服务器返回HTTP301状态码时,表示请求的资源已经被永久移动到新的位置。
在这种情况下,服务器会在响应中添加一个 Location 头部,用于指定资源的新位置。这个 Location 头部包含了新的URL地址,浏览器会自动重定向到该地址。
例如,在HTTP响应中,可能会看到类似于以下的头部信息:
css
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\nHTTP状态码302(临时重定向):
当服务器返回HTTP302状态码时,表示请求的资源临时被移动到新的位置。
同样地,服务器也会在响应中添加一个 Location 头部来指定资源的新位置。浏览器会暂时使用新的 URL 进行后续的请求,但不会缓存这个重定向。
例如,在HTTP响应中,可能会看到类似于以下的头部信息:
css
HTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n无论是 HTTP301 还是 HTTP302 重定向,都需要依赖 Location 选项来指定资源的新位置。这个 Location 选项是⼀个标准的 HTTP 响应头部,用于告诉浏览器应该将请求重定向到哪个新的 URL 地址。
什么是重定向? 用户访问一个网址时,自动跳转到另一个网址的过程。
技术上怎么实现?3xx状态码 + Location 。服务器通过HTTP响应告诉浏览器"去别的地方":3xx状态码告知"需要重定向" ;Location告知"新地址在哪里"。
浏览器识别流程:收到3xx响应 → 提取Location中的新URL → 自动向新URL发起第二次请求 → 显示最终页面。
临时 vs 永久的核心区别:客户端是否"记住"
临时重定:状态码:302,表示这次跳转是暂时的,客户端的行为:不记录,每次仍访问旧URL
永久重定向:状态码:301,表示这个资源已永久搬家,客户端的行为:更新书签,以后直接访问新URL
应用场景对比:
临时重定向(302)→ 这次去别处,但地址没变
| 场景 | 为什么用302 |
|---|---|
| 登录成功跳转首页 | 登录页还在,只是这次让你去首页 |
| 注册成功跳转登录页 | 注册页还在,只是这次让你去登录 |
| 未登录跳转登录页 | 原页面还在,登录完还要回来 |
流程:用户访问 /profile(个人中心) → 服务器:你没登录(302 + Location: /login) → 浏览器跳转到 /login → 用户登录后,/profile 还能正常访问(原地址有效)。
永久重定向(301)→ 地址永久变更,以后别来了
| 场景 | 为什么用301 |
|---|---|
| 网站域名更换 | 老域名永久不用了 |
| HTTP升级HTTPS | http:// 永久改为 https:// |
| 页面URL结构调整 | 旧路径永久废弃 |
流程:用户收藏了 http://old.com/article/123 → 服务器返回 301 + Location: https://new.com/p/123 → 浏览器更新书签:以后直接访问 https://new.com/p/123 → 再也不访问 http://old.com/...。
为什么搜索引擎需要301?
搜索引擎的核心工作:抓取网页 → 建立索引(关键词→URL映射) → 用户搜索 → 返回对应URL。
如果没有301:网站从 old.com 搬到 new.com,搜索引擎索引里还是 old.com 的链接,用户点击 → 404找不到页面。
有了301:搜索引擎爬虫访问 old.com/article → 返回 301 + Location: new.com/article → 搜索引擎更新索引:旧URL → 新URL → 用户搜索时,直接得到 new.com 的有效链接。
301的双重价值:
- 对用户:浏览器自动去新地址
- 对搜索引擎:更新全网链接索引,保证搜索结果有效
4. header
1. Content-Type 字段
Content-Type:数据类型(text/html等)
浏览器怎么知道文件格式?仅靠浏览器"猜"不可靠
早期浏览器尝试根据内容自动识别格式,但:不同浏览器能力参差不齐;同样文件可能识别结果不同;二进制文件(图片/视频)容易误判。
解决方案:Content-Type字段。
HTTP响应头中新增标准字段:
css
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8 ← 明确告知:这是HTML文本
Content-Length: 1024Content-Type(内容类型):
text/html ------ HTML网页
text/css ------ 样式表
image/png ------ PNG图片
application/json ------ JSON数据
video/mp4 ------ MP4视频
字段的作用 :服务器主动声明格式,浏览器无需猜测,统一处理。
服务器拿到请求 /index.html,怎么知道返回 text/html?文件后缀名
数据类型和后缀有一张 Content-Type 对照表,它可以根据 Content-Type 对照表,看清楚后缀和属性之间的关系。
| 类型 | Content-Type |
|---|---|
| HTML | text/html |
| CSS | text/css |
| JavaScript | application/javascript |
| JSON | application/json |
| XML | application/xml |
| 纯文本 | text/plain |
| Markdown | text/markdown |
| 格式 | Content-Type |
| JPEG | image/jpeg |
| PNG | image/png |
| GIF | image/gif |
| SVG | image/svg+xml |
| WebP | image/webp |
| 类型 | Content-Type |
| application/pdf | |
| ZIP | application/zip |
| 通用二进制 | application/octet-stream |
响应时 服务器根据请求URL中的文件后缀,查表设置Content-Type返回给客户端。
2. Cookie 字段
Cookie:用于在客户端存储少量信息。通常用于实现会话(session)的功能。
HTTP的核心特点
| 特点 | 含义 | 表现 |
|---|---|---|
| 无状态 | 不记住之前的请求 | 每次请求都是独立的"陌生人" |
| 无连接 | HTTP层不管理连接 | 连接由TCP负责,HTTP只认文件描述符 |
如此一来:用户需要"一次登录,长期在线",但HTTP天生"健忘"。
登录流程:
POST /login → 服务器验证通过 → 返回"登录成功"
GET /article/123 → 服务器:你是谁?请重新登录!
↑___________________________|
HTTP无状态,不认识你
解决方案:Cookie机制。
Cookie的工作流程:
| 步骤 | 方向 | 关键字段 | 动作 |
|---|---|---|---|
| 1 | 服务器 → 客户端 | Set-Cookie: user=zhangsan; pwd=123456 | 登录成功,写入身份凭证 |
| 2 | 客户端保存 | --- | 将Cookie存到特定路径的文件或内存 |
| 3 | 客户端 → 服务器 | Cookie: user=zhangsan; pwd=123456 | 后续每个请求自动携带 |
| 4 | 服务器解析 | --- | 读取Cookie,识别用户,无需重复登录 |
Cookie的存储方式:
| 类型 | 存储位置 | 生命周期 | 场景 |
|---|---|---|---|
| 持久化Cookie | 本地文件 | 由expires或max-age控制,到期自动删除 | 长期登录状态 |
| 会话Cookie | 进程内存 | 浏览器关闭即消失 | 临时登录,更安全 |
现代浏览器默认会话Cookie,需要服务器显式设置expires才持久化。
HTTP会话管理 :通过Set-Cookie和Cookie字段,在无状态的HTTP协议上模拟状态保持的机制。
Cookie的安全隐患:
黑客获取A的Cookie文件 → 将Cookie写入自己浏览器 → 访问网站 → 携带A的Cookie → 服务器:欢迎回来,zhangsan! → 黑客修改密码 → A永久失去账号
核心问题
Cookie是身份凭证 ------ 谁持有Cookie,服务器就认为是谁
Cookie可复制 ------ 文件形式,无绑定设备
明文存储敏感信息 ------ 用户名密码直接写在Cookie中
Session+Cookie 来解决问题:Session+Cookie工作流程:
- 登录成功 → 服务端创建Session文件,生成唯一Session ID
- Set-Cookie: sessionid=a3f7c9d2e8b1...(仅ID,无敏感信息)
- 后续请求携带Session ID → 服务端查Session文件获取用户信息
安全优势: 即使Session ID被盗,服务端掌握主动权,可通过策略使其失效。
仔细分析,可以发现,这种方法还是存在安全问题呀?既然Cookie信息可以被盗取,Session 信息也可以呀?安全问题并没有解决呀?
| 方案 | 存储内容 | 解决的问题 | 仍存在的问题 |
|---|---|---|---|
| 纯Cookie | 用户敏感信息(用户名、密码、权限等) | 无 | 数据泄露+身份冒充 |
| Session+Cookie | 仅存储Session ID(随机字符串),敏感信息存服务端 | 数据泄露 | 身份冒充 (Session ID仍可被盗) |
在之前所讲的问题:只用 Cookie 保存用户的私密信息。它面临两种问题:1. 用户数据泄漏问题;2. 冒充用户身份的问题。
Session 只是解决了用户信息泄漏的问题,另一个问题仍未彻底解决。要想彻底解决冒充用户身份问题,HTTP协议是做不到的。因为 HTTP 至少需要一个标识符来标识用户的身份,必用 Cookie。
既然 HTTP 层解决不了这个问题,就需要更靠近上层的软件逻辑来解决。session 和 Cookie 信息被盗取了,主动权在服务端,服务端可以采用各种策略来发现问题,解决问题只需要保证 session id 失效即可,让盗走的 session id 无用。
3. Connection 字段
HTTP 中的 Connection 字段是HTTP报头的一部分,它主要用于控制和管理客户端与服务器之间 的连接状态。
语法格式:
Connection:keep-alive:表示希望保持连接以复用TCP连接
Connection: close:表示请求/响应完成后,应该关闭TCP连接
核心功能:
管理持久连接: Connection 字段还⽤于管理持久连接(也称为长连接)。持久连接允许客户端和服务器在请求/响应完成后不立即关闭TCP连接,以便在同⼀个连接上发送多个请求和接收多个响应。
持久连接(长连接):
HTTP/1.0:默认短连接,每次请求需新建TCP连接,响应后立即关闭。
HTTP/1.1 :默认启用长连接,通过请求头Connection: keep-alive(1.1中可省略,默认即长连接)实现TCP连接复用。
长连接的工作机制:
- 浏览器对同一域名下的多个资源请求,复用同一条TCP连接
- 请求按串行顺序发送:先发送请求1,等待响应1,再发送请求2...
注意:HTTP协议本身不支持一个请求获取多个资源 。长连接是指多个请求复用同一连接,而非合并请求。浏览器仍需为每个资源单独发起HTTP请求,只是避免了重复建立TCP连接的开销。
浏览器解析HTML时,对资源引用(如<img src="...">)的处理:
| 路径类型 | 处理方式 |
|---|---|
| 绝对路径(/开头) | 相对于Web根目录,如/css/style.css |
| 相对路径 | 相对于当前HTML所在目录 |
| 完整URL | 提取协议、域名、路径,向该地址发起新请求 |
外部资源托管 :
若资源指向其他域名(如https://cdn.example.com/image.jpg),浏览器会向该服务器发起独立请求。图片托管服务称为**图床** ,音视频等静态资源常通过CDN(内容分发网络)加速分发。
4. 其它
Content-Length:Body的长度(正文部分的长度,如果没有正文部分,不需要存在 Content-Length)
Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
User-Agent:声明用户的操作系统和浏览器版本信息(通常在HTTP请求中携带,应答中没有)。有些抓包软件可以凭借它来进行抓包
Referer:当前页面是从哪个页面跳转过来的
Location:搭配3xx状态码使用,告诉客户端接下来要去哪里访问
5. 动态网站与静态网站
静态网站与动态网站的区别:
静态网站:
| 特征 | 说明 |
|---|---|
| 内容 | 预先存在的文件(HTML/CSS/JS/图片) |
| 交互 | 单向:服务器 → 客户端(只读) |
| 请求方法 | GET (获取资源) |
| 响应 | 直接读取文件,返回文件内容 |
| 例子 | 个人博客、企业官网、文档站点 |
示例流程:
客户端请求 GET /about.html
↓
服务器查找 /var/www/html/about.html
↓
查后缀 .html → Content-Type: text/html
↓
返回文件内容
动态网站
| 特征 | 说明 |
|---|---|
| 内容 | 根据请求实时生成 |
| 交互 | 双向:客户端 ↔ 服务器(读写) |
| 请求方法 | GET (获取)+ POST(提交) |
| 处理 | 服务器执行程序,处理数据,生成响应 |
| 例子 | 登录、注册、搜索、电商、社交 |
示例流程:登录流程(动态交互):
客户端请求 GET /login → 服务器返回登录表单(静态HTML)
用户填写:邮箱="user@qq.com", 密码="123456"
客户端 POST /login 提交数据
请求体:email=user@qq.com&password=123456
- 服务器接收 → 查询数据库验证 → 生成响应
成功:设置Cookie,返回"登录成功,3秒后跳转首页"
失败:返回"账号或密码错误"
- 客户端根据响应,动态更新页面(跳转/提示错误)
动态的本质 :URI不再指向文件 ,而是指向处理程序。