文章目录
前言
上一章节学习了 人工智能(AI)、机器学习(ML) 和 深度学习(DL)的基本概念和三者直接的包含关系,可以看出 机器学习(ML) 是人工智能很重要的一个实现途径 ,现在主要详细对 机器学习基本的知识点 进行阐述,主要有 机器学习常用术语 、机器学习算法分类 、机器学习建模流程 等三个大体方面。
一、机器学习常用术语
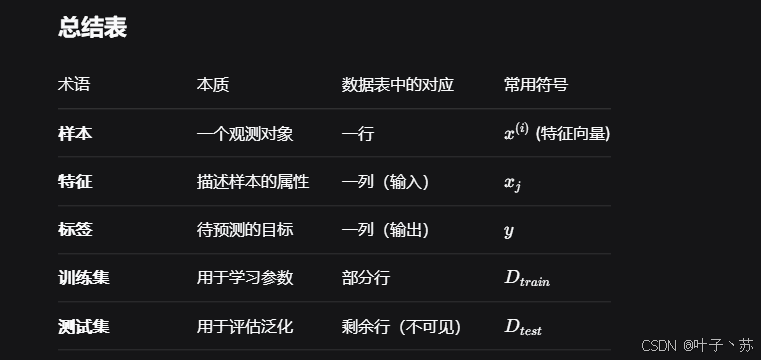
机器学习中有五个核心术语,分别是:样本 、特征 、标签 、训练集 、测试集 ,理解这些概念是学习机器学习的第一步。
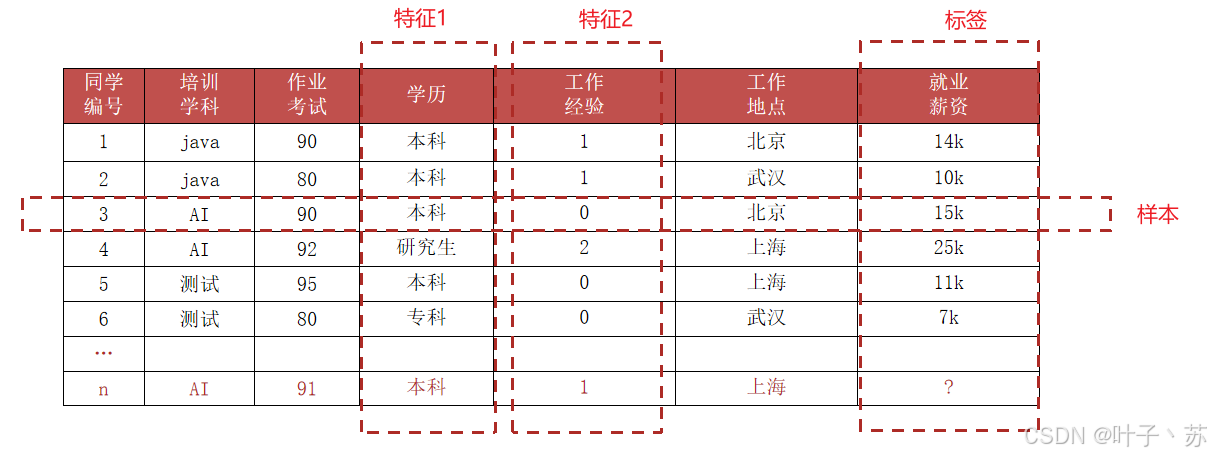
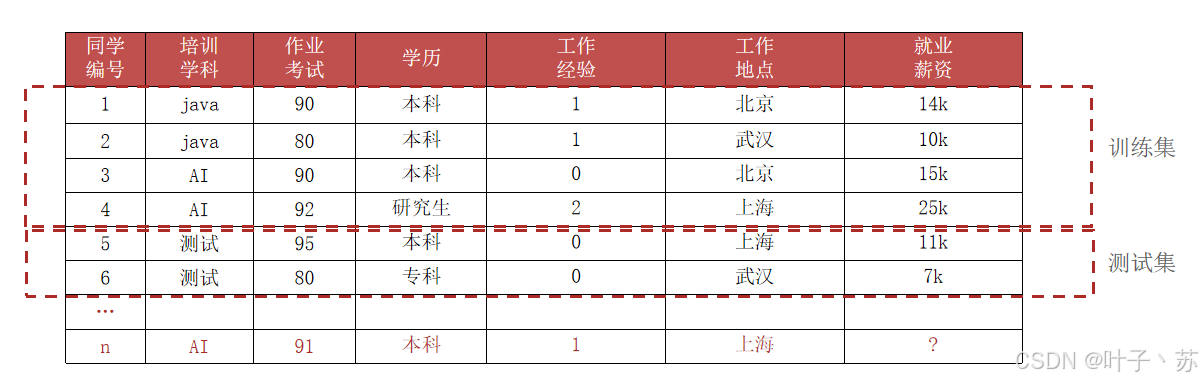
我们从上述表格来理解 机器学习的核心术语:
1.样本 (Sample)
定义 :样本是机器学习处理的基本数据单元,通常表示一个独立的观测对象或事件,在数据表中,一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录。
2.特征 (Feature)
定义 :特征是描述样本某个方面的可 测量属性 或 输入变量 。它是机器学习模型进行预测的依据。在数据表中,一列数据一个特征,有时也被称为属性。
3.标签 (Label)
定义 :标签是我们希望模型 预测的目标值,即样本的真实答案。在监督学习中,每个样本都有一个对应的标签。在数据表中,模型要预测的那一列数据。本场景是就业薪资,与 培训学科、作业考试、学历、工作经验、工作地点 5个特征有关系。
4.训练集 (Training Set)
定义:训练集是用于训练机器学习模型的样本集合。模型通过反复观察训练集中的样本(特征与对应的标签),学习输入到输出的映射规律。
5.测试集 (Test Set)
定义:测试集是用于评估模型泛化能力的样本集合。模型在训练过程中完全看不到测试集中的任何信息。训练完成后,我们用测试集来模拟"全新未见数据",检验模型预测的准确性。
重点:①训练集 和 测试集 的比例大概是 8:2 或者 7:3 。
②在后续代码中或者称呼中,经常把训练集的特征总称为 x_train ;把训练集的标签总称为 y_train ;把测试集的特征总称为 x_Text ;把测试集的标签总称为 y_Test 。
二、机器学习算法分类
下面详细阐述机器学习算法的四大分类:有监督学习、无监督学习、半监督学习 和 强化学习。这四种范式的主要区别在于训练数据的性质以及学习目标的不同。
1.有监督学习 (Supervised Learning)
定义
输入数据是由输入 特征值 和 目标值 所组成,即输入的训练数据 有标签的 ;数据集 需要标注数据的 标签/目标值。
核心特点
① 数据要求:需要大量人工标注的标签,成本较高;
② 精度高:可解释性相对较好(取决于模型);目标明确;
分类
根据 标签值 是否连续,将有监督分成 回归 和 分类 两个子类:
① 回归 (Regression):输出标签是连续数值;
② 分类 (Classification):输出标签是离散类别。
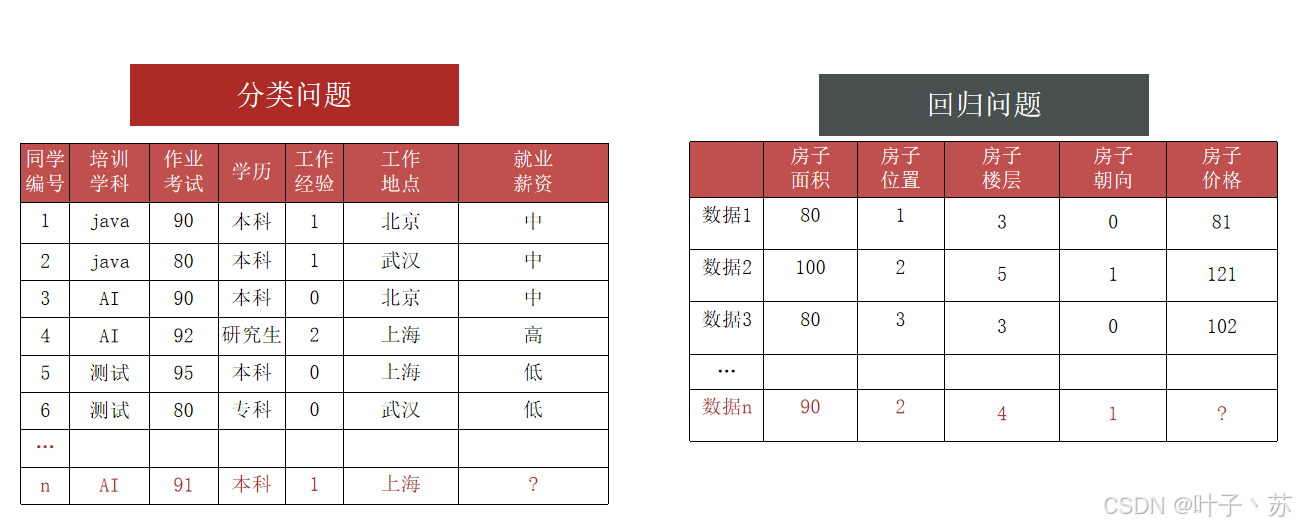
从上图可以看出表格数据中的 就业薪资 和 房子价格 代表着标签,但是 就业薪资 是由 高 中 低 来表示结果,没有连续性,所以代表分类问题;房子价格 是线性的,有连续性,所以代表回归问题。
2.无监督学习 (Unsupervised Learning)
定义
输入数据没有被标记,即样本数据类别未知,没有标签,根据样本间的相似性,对样本集聚类,以发现事物内部结构及相互关系。
核心特点
① 数据要求:仅需原始数据,无需人工标注,成本低;
② 不需要标注数据,可扩展性强;能发现人类未知的模式;
③ 结果难以量化评估;解释性可能差;聚类结果受算法和参数影响大。
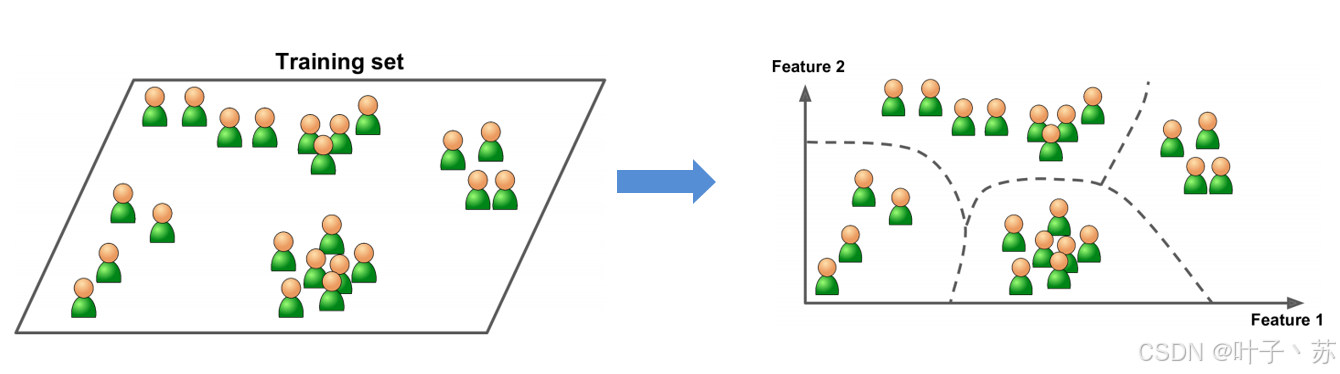
重点:根据样本间的相似性,对样本集聚类,没有直接的正确/错误判断,通常靠人工评估或间接指标。
3.半监督学习 (Semi-supervised Learning)
定义
半监督学习介于监督和无监督之间:使用少量有标签数据 + 大量无标签数据进行训练。它试图利用 无标签数据 来增强模型对数据分布的理解,从而提升学习性能。
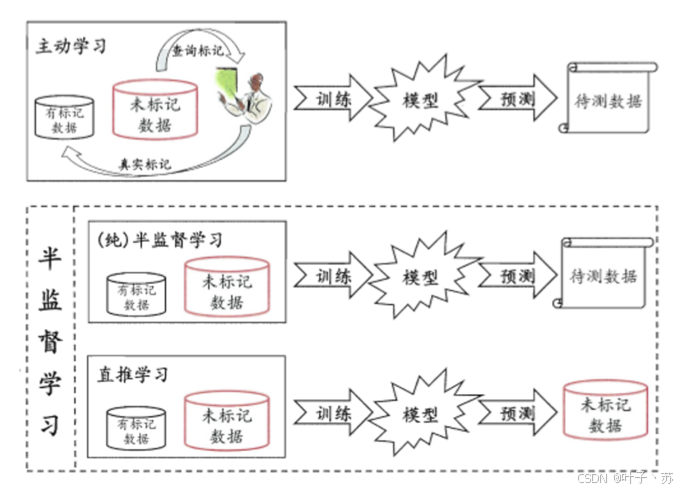
工作原理
① 让专家标注少量数据,利用已经标记的数据(也就是带有类标签)训练出一个模型;
② 再利用该模型去套用未标记的数据;
③ 通过询问领域专家分类结果与模型分类结果做对比,从而对模型做进一步改善和提高。
优点:显著降低标注成本;往往比纯监督学习(仅用少量标签)效果更好;
缺点:如果无标签数据分布与有标签数据不一致,可能引入噪声;方法设计较复杂。
4.强化学习 (Reinforcement Learning)
定义
强化学习不依赖静态的 "样本-标签" 对。而是让一个 智能体 在与 环境 的交互中,通过试错和延迟反馈(奖励或惩罚)来学习最优策略,以最大化累积奖励。
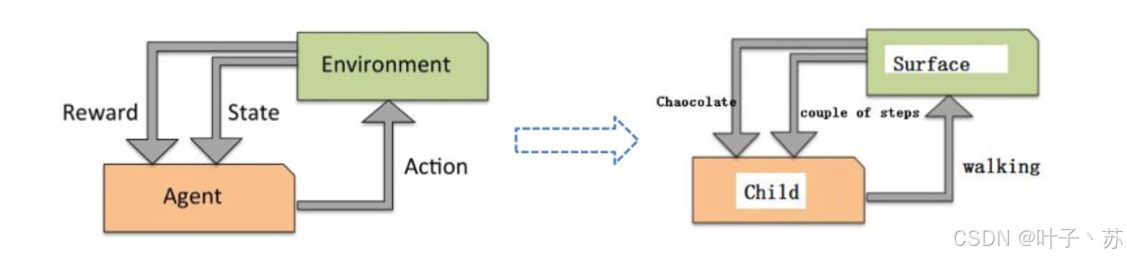
核心要素
① 智能体 (Agent):学习者、决策者;
② 环境 (Environment):智能体与之交互的外部系统;
③ 状态 (State):环境在某一时刻的描述;
④ 动作 (Action):智能体可以采取的操作;
⑤ 奖励 (Reward):执行动作后环境返回的即时反馈信号(可正可负)。
agent根据环境状态进行行动获得最多的累计奖励。
优点:适用于序列决策问题,能处理延迟反馈;无需标注数据。
缺点:训练需要大量交互,样本效率低;奖励函数设计困难;训练过程不稳定;难以模拟真实环境。
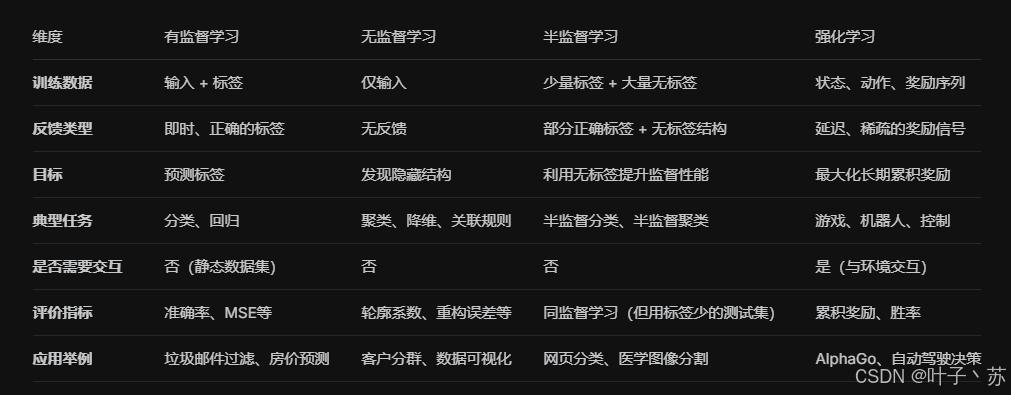
5.四者对比总结表
上述四种机器学习算法,应用非常多,需要掌握每类算法的基础概念,对后续学习很重要。
三、机器学习建模流程
下面详细阐述机器学习的标准建模流程。这是一个从业务问题到可部署模型的完整路径,通常包含以下五个关键阶段。
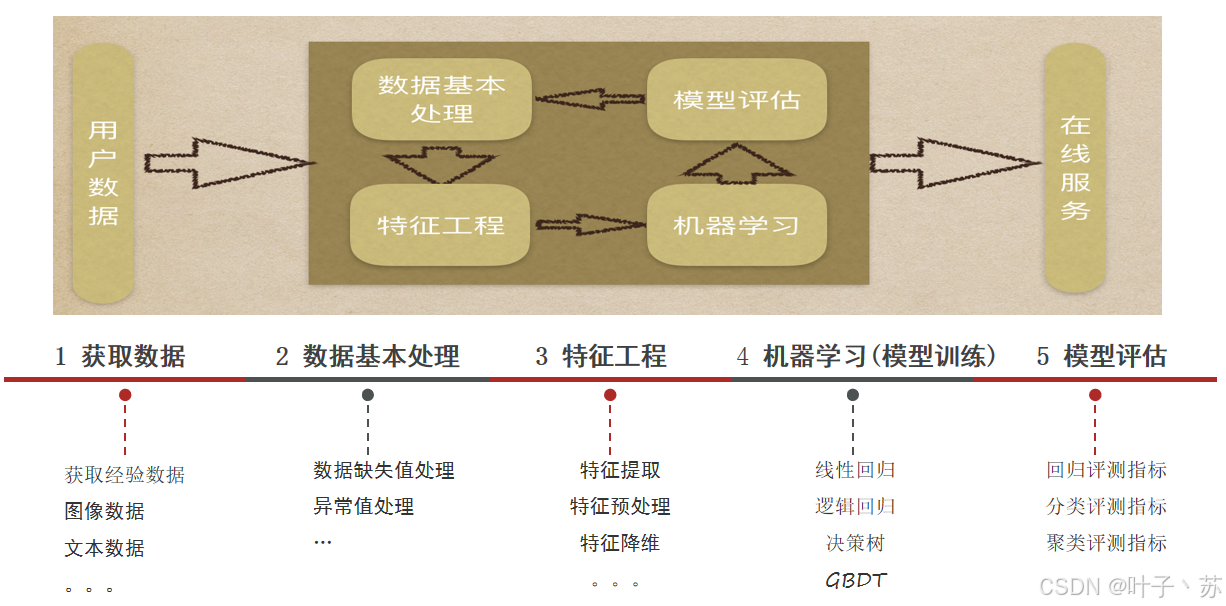
机器学习建模的步骤
① 获取数据:搜集与完成机器学习任务相关的数据集;
② 数据基本处理:数据集中异常值,缺失值的处理等;
③ 特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果;
④ 机器学习(模型训练):选择合适的算法对模型进行训练;
⑤ 模型评估:评估效果好上线服务,评估效果不好则重复上述步骤。
重点:在整个建模流程中,数据基本处理、特征工程一般是耗时、耗精力最多的,后续也会着重解释这两个步骤,尤其是特征工程。
总结
以上就是关于 机器学习基本知识点 介绍,都是非常重要的概念,掌握了 机器学习常用术语 、算法分类 和 建模流程 等方面后才能对机器学习有个大体的了解,后续的学习都是在 算法 和 建模流程 的总体框架下进行运用。