北京时间凌晨 3 点,直播准时开始,OpenAI 发布了 ChatGPT Images 2.0。

据介绍,「ChatGPT Images 2.0 是下一步进化:一个最先进的模型,能够处理复杂的视觉任务,并生成精确、可直接使用的视觉内容。」
似乎也正因为此,OpenAI 发布的官方博客内容还提供了两个版本(图像模式与经典模式),其中图像模式下的内容完全是由该模型生成的!
在博客中,OpenAI 表示:「图像是一种语言,而不是装饰。好的图像,就像好的句子一样,会进行选择、组织与呈现。它可以解释机制,营造氛围,验证想法,或构建论证。」
ChatGPT Images 2.0 模型在细致遵循指令方面实现了质的跃迁,能够准确放置与关联对象,并渲染高密度文本,同时支持多种宽高比生成。它在构图与视觉审美上的能力,使输出不再像「AI 生成」,而更像「有意设计」。
并且其在多语言环境下同样表现准确,并能利用扩展的视觉与世界知识为你补全细节,从而以更少提示词获得更智能的图像。
为应对最复杂的任务,Images 2.0 首次引入「思考能力」。在 ChatGPT 中选择 thinking 或 pro 模型时,Images 2.0 可以联网获取实时信息,从一个提示生成多张不同图像,并对自身输出进行复核。借助「思考」,模型能够承担从想法到图像之间更多的工作,尤其在准确性、时效性、一致性与视觉统一性至关重要时。
结合 OpenAI 推理模型的智能与对视觉世界的深刻理解,这一模型将图像生成从「渲染」提升为「策略性设计」,从工具进化为视觉系统,帮助人们将想法转化为可理解、可分享、可教学、可构建的成果。
该能力已从今日起向 ChatGPT、Codex 与 API 的所有用户开放。
更高的精度与控制力
Images 2.0 为图像创作带来了前所未有的具体性与还原度。它不仅能构思更复杂的图像,还能有效将其实现,能够严格遵循指令,保留关键细节,并渲染以往模型容易失真的精细元素:小文本、图标、UI 元素、高密度构图以及细微风格约束。在 API 中最高支持 2K 分辨率。结果不再是「差不多」,而是「可以直接使用」。
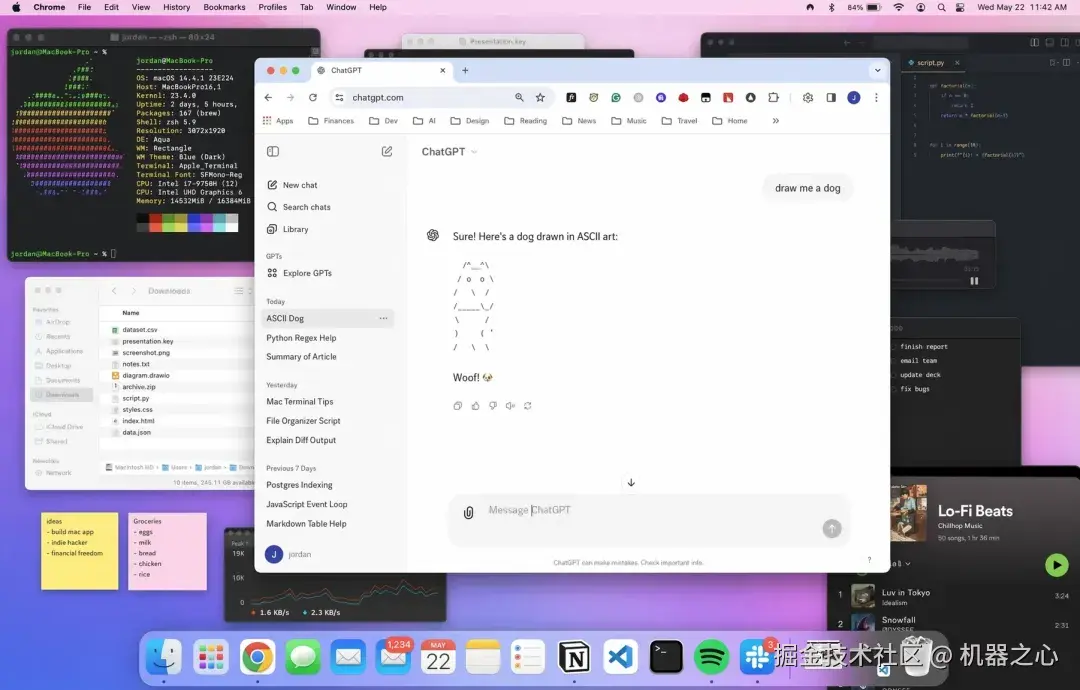
注意看,下面这张截图整体上其实是 Images 2.0 生成的!
更强的多语言能力
以往图像生成模型在英语及拉丁字母语言中表现更稳定,但在其他语言,尤其是复杂或密集文本时精度较低。
Images 2.0 突破了这一限制,在多语言理解上显著增强,尤其是在日语、韩语、中文、印地语与孟加拉语的文本渲染方面有明显提升。它不仅能正确生成非英语文本,还能保证语言表达自然流畅。

这不仅意味着翻译标签,而是让语言本身成为设计的一部分,从海报、说明图,到图解与漫画,都能实现视觉与语言的统一。这使模型具备更强的全球适用性,让用户能够在真实使用的语言环境中创作视觉内容。
在直播中,OpenAI 图像研究团队的成员陈博远展示了一个案例,他给出提示词:「Make a artisitic marketing poster for a fictional OpenAI bakery.The poster should be inJapanese language.」
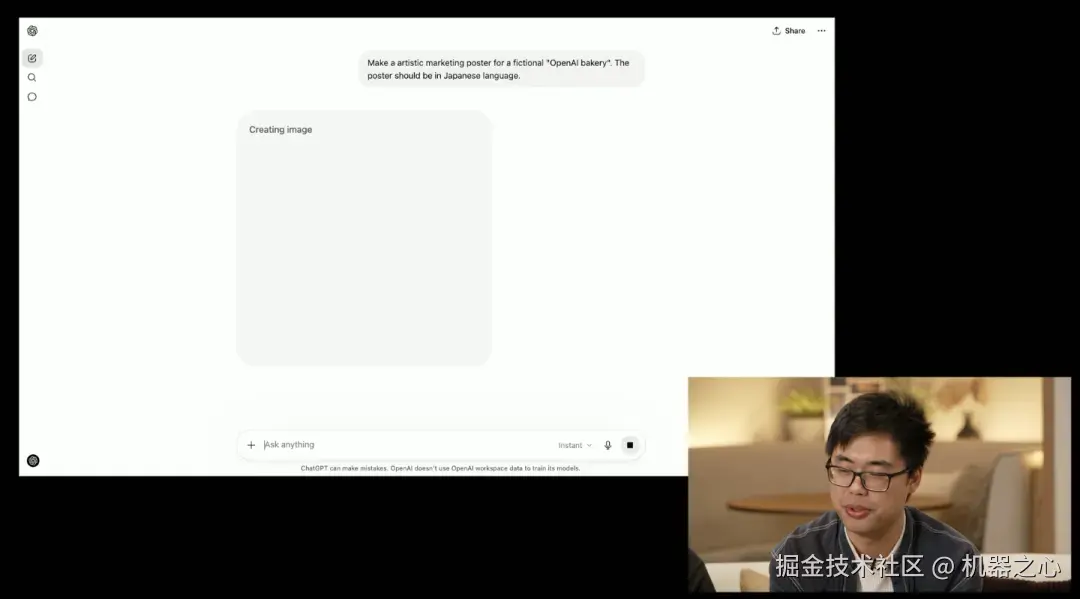
结果生成的海报完全符合提示词,且在细节上也能够做到精准。

「它非常擅长遵循非常详细的指令,所以如果你有非常具体的品牌语言、设计美学 ------ 所有那些对创意工作至关重要的东西 ------ 你都可以使用 ChatGPT 来创建和完善你的想法,从而得到你想要的结果。」陈博远说道。
更成熟的风格表达与真实感
Images 2.0 在多种视觉风格上的还原度显著提升。它更擅长捕捉照片的关键特征,包括那些增强真实感的微小瑕疵,同时也能稳定呈现电影感画面、像素艺术、漫画等多种视觉语言,在纹理、光影、构图与细节上更一致。
因此,模型输出更贴近指定风格,而非近似模仿。这对于游戏原型设计、分镜制作、营销创意,以及特定媒介或类型的资产创作尤为有价值。
灵活的宽高比
新模型在输出形式上更灵活,支持从 3:1 到 1:3 的多种宽高比,可直接适配横幅、演示文稿、海报、手机界面、书签及社交媒体图形等不同场景。你可以在提示中指定宽高比,或通过预设选项将已有图像重新生成至新的尺寸。
下面展示了两个非常规宽高比的示例:

更强的现实世界理解
Images 2.0 引入了截至 2025 年 12 月的知识,使生成结果在相关性与语境准确性上更进一步。这对于说明图、教育图形与可视化总结尤为关键,因为在这些场景中,正确性与清晰度与美观同样重要。
其智能能力还体现在端到端任务处理上:整合信息、撰写内容,并以清晰结构、合理留白与良好视觉流进行排版。

视觉思考伙伴
在 ChatGPT 中启用 thinking 模型后,系统会在后台进行更深入的理解与执行。它可以联网检索信息,将上传材料转化为清晰的视觉说明,并在生成前对图像结构进行推理。
在这种模式下,Images 2.0 更像一个视觉思考伙伴,帮助你将初步概念推进为完整成品,大幅降低工作量。

它还支持一次生成多张不同图像,这在 ChatGPT 图像生成中尚属首次。这使得诸如多页漫画、整屋设计方案、系列海报或多语言多尺寸社交素材等工作流变得高效可行。
你无需逐张生成再手动拼接,只需一次请求,即可获得最多八张在角色与元素上保持一致、且具有连续性的输出。
在 Codex 中使用图像生成
Images 能力被整合进 Codex,使视觉创作、迭代与交付在同一工作空间内完成,拓展了其在设计、营销、产品、销售及学习等领域的应用。
例如,你可以快速生成多种 UI 方向与原型,比较方案,并将最佳设计直接转化为产品或网页体验,无需离开 Codex。通过 ChatGPT 订阅即可使用,无需额外 API 密钥。
通过 API 将图像能力嵌入产品
开发者与企业可通过 gpt-image-2 API 将这些能力集成进自身产品,在现有工作流中加入高质量图像生成与编辑能力。
凭借更强的文本渲染、多语言生成、指令遵循能力,以及更多输出格式与宽高比支持,API 更易于构建真实业务场景中的图像工作流,例如本地化广告、信息图、说明图、教育内容、设计工具、创意平台及网页生成产品。
局限性
OpenAI 也在博客中提到了该模型的局限性:尽管 Images 2.0 是重要进步,但仍不完美。对于需要完整物理世界建模的任务(如折纸教程、魔方等复杂结构),以及隐藏面、倾斜面或反向表面的精确细节,模型仍可能表现不足。
极高密度或重复性细节(如细沙)也可能带来挑战。标签与图示在涉及精确箭头或部件标注时,仍建议人工校对。
这些都是未来改进的重要方向。
在 API 中,超过 2K 的输出目前仍处于测试阶段,可能出现不稳定情况。
定价与可用性
ChatGPT Images 2.0 今日起已向所有 ChatGPT 与 Codex 用户开放。具备「思考」能力的高级输出对 ChatGPT Plus、Pro 与 Business 用户提供。
gpt-image-2 模型已在 API 中提供,价格根据图像质量与分辨率有所不同。

OpenAI 也在官网上线了大量案例,感兴趣的读者可自行前往查看。
我们也进行了一些简单测试,比如让其生成了一张中国高考数学试卷第 2 页,看着还行:

实测中,我们可以在页面上看到 ChatGPT Images 2.0 生成一张图片通常会经历多个步骤:创建→打个草稿→生成初稿→搭建场景→打磨细节→收尾→最后润色→最后微调。
接下来我们继续,「生成一张《将敬酒》繁体中文草书书法作品,宽高比 3:1,内容是李白的《将敬酒》全文。落款是 ChatGPT Images 2.0」:

不过很显然该模型并没有生成完整,且也明显不是草书。
最后来一页闪电五连鞭的功夫招式图解说明:
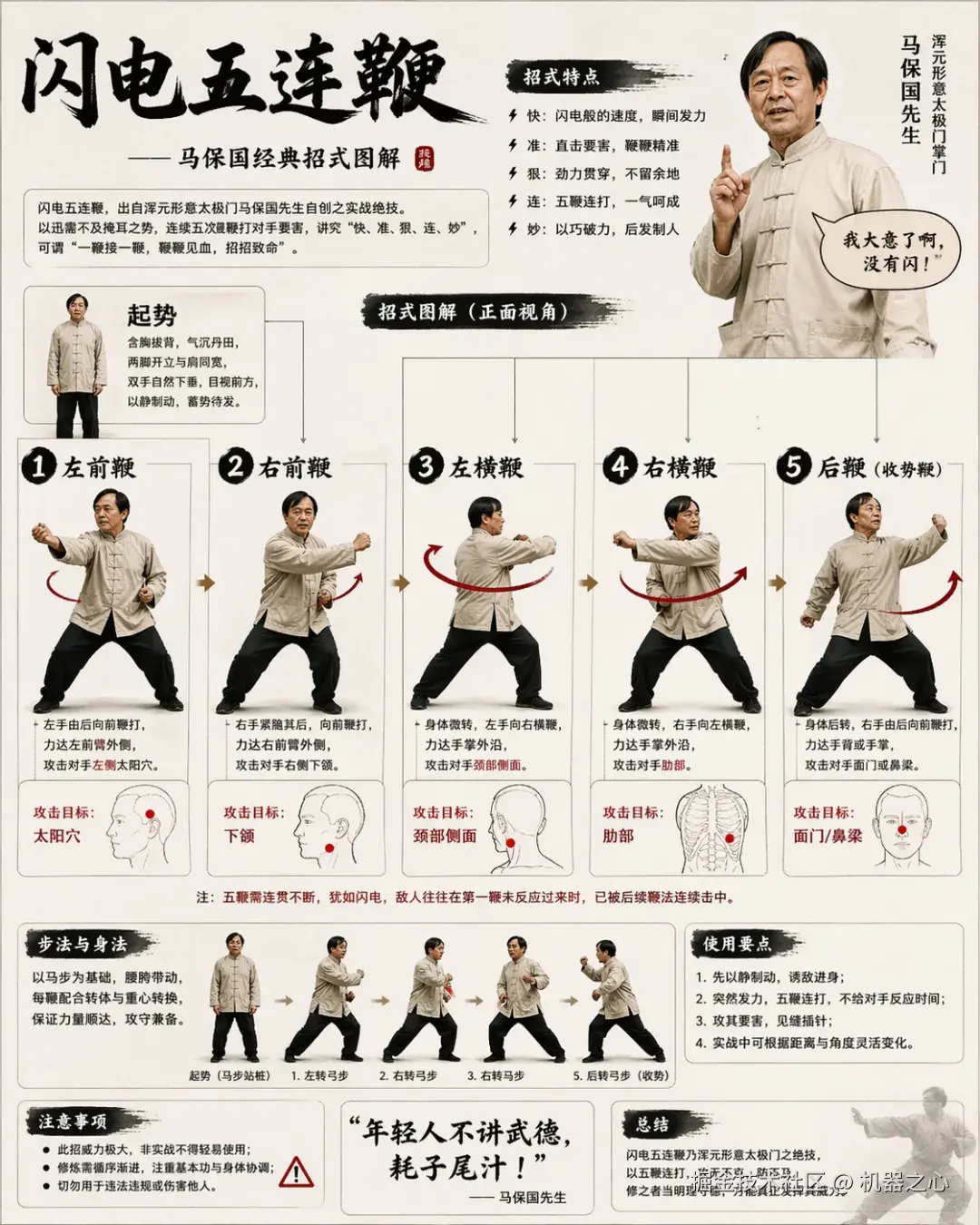
还挺有趣。
整体体验下来,我们感觉 ChatGPT Images 2.0 确实比目前的 Nano Banana 2 强大不少;看看接下来谷歌如何接招。
你试过 ChatGPT Images 2.0 了吗?感觉如何?