SFTTrainer官方案例
1、环境准备
Auto算力云上租一个4090,要选可扩容的,然后打开JupyterLab在上面操作。
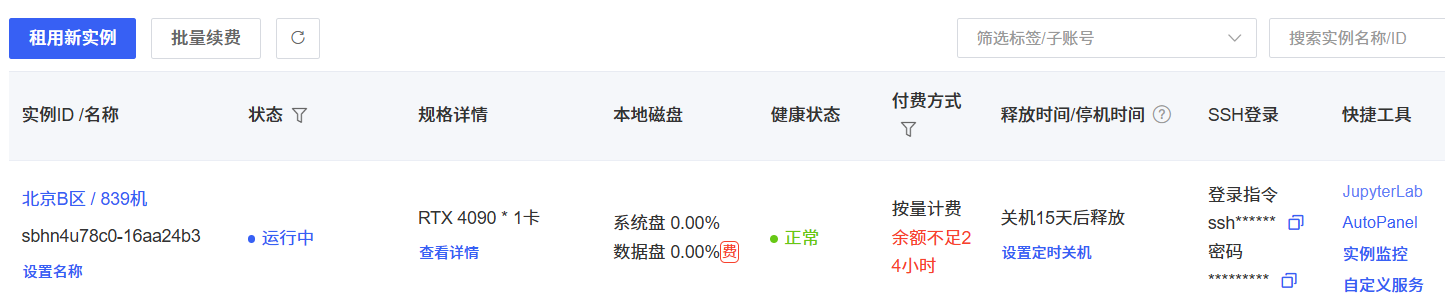
创建一个notebook

找到数据盘的路径,因为可扩容且空间大

在终端进入数据盘,创建hf文件
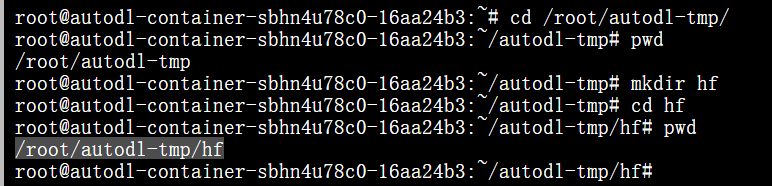
把家目录,也就是模型要存放的地方改成hf,现在就是下模型从hf-mirror.com里下,缓存模型到刚
创建的hf中。

2、模型加载&数据集预处理
在终端中pip install trl datasets
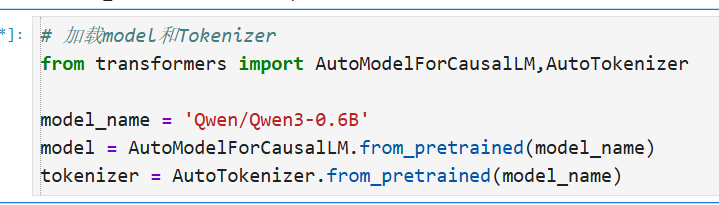
加载model和Tokenizer
检查一下已经加载成功了

新建data文件夹上传一下train,test数据集
数据处理
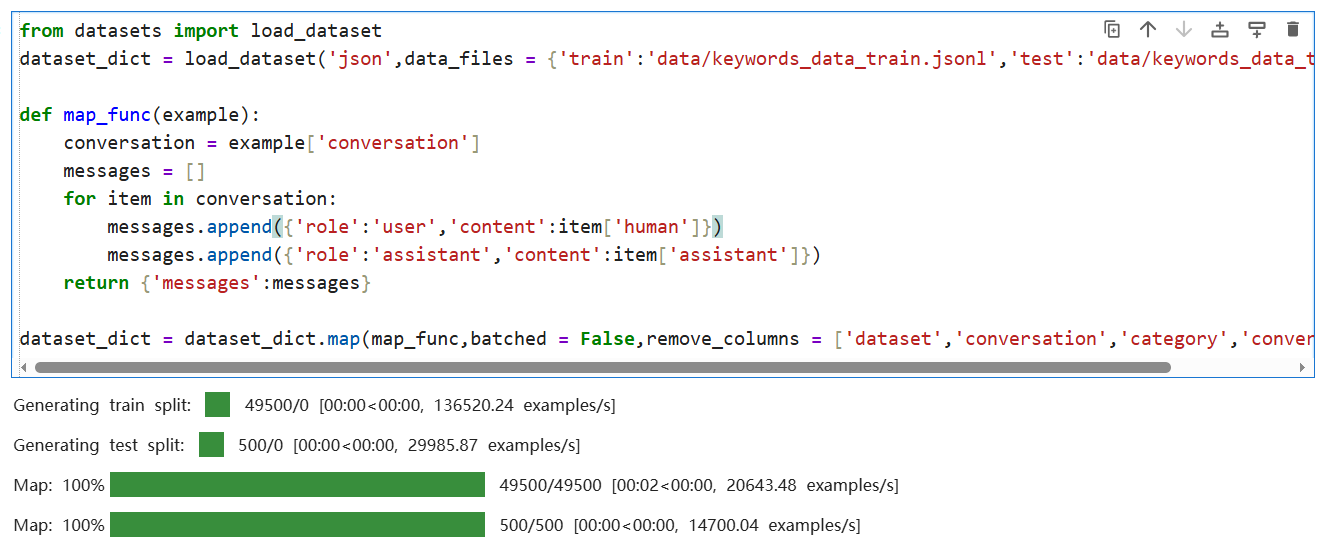
检查一下是否成功

3、Trainer配置&训练
创建目录
AutoPanel中有日志存放位置
初始化config和trainer,并执行
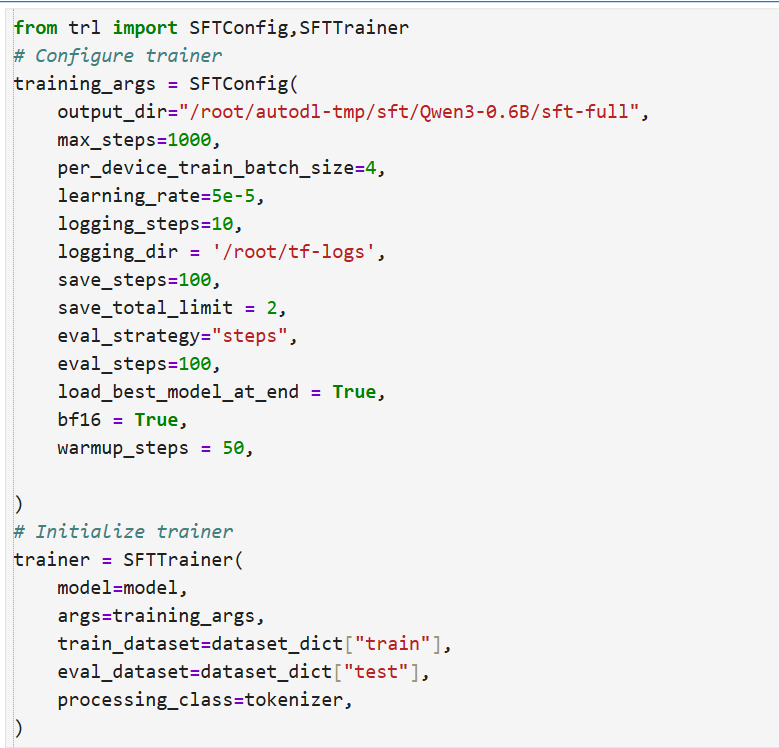
tokenizer开始处理数据

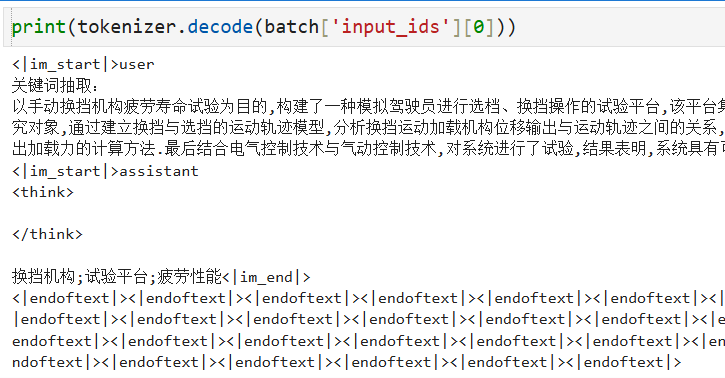
接下来可以开始训练
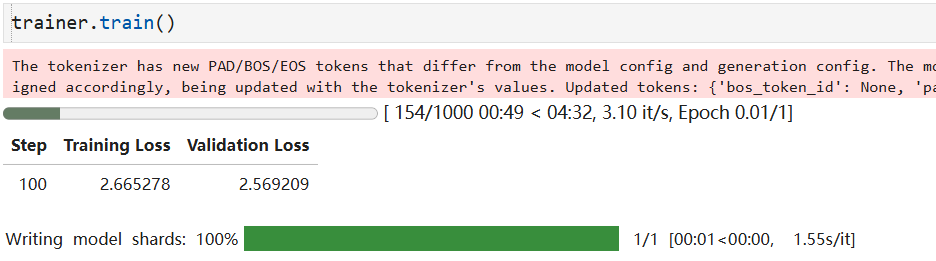
进入目录可以查看

保存最佳模型并查看

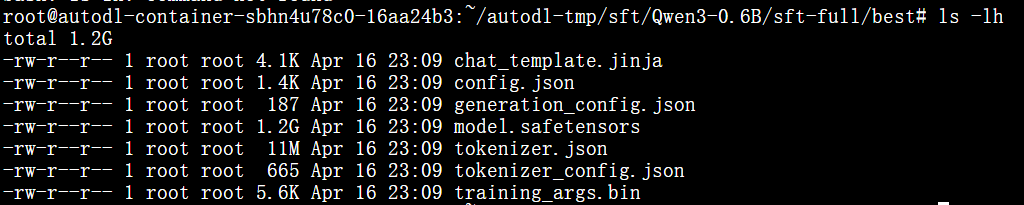
4、推理演示
做推理之前要先关闭内核,就是停掉训模型那个文件,把显存释放出来。
然后去huggingface的model card上找代码
这里是做的测试,然后可以加载我们之前训好的best_model:/root/autodl-tmp/sft/Qwen3-0.6B/sft-full/best
SFTTrainerLoRA案例
先装一下peft,这个是参数高效微调库。
训练代码
loraconfig的代码去hugging face官网的learn里有SFTTrainer的LoRA案例
python
%env HF_ENDPOINT=https://hf-mirror.com
%env HF_HOME=/root/autodl-tmp/hf
# 加载model和Tokenizer
from transformers import AutoModelForCausalLM,AutoTokenizer
model_name = 'Qwen/Qwen3-8B'
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
from datasets import load_dataset
dataset_dict = load_dataset('json',data_files = {'train':'data/keywords_data_train.jsonl','test':'data/keywords_data_test.jsonl'})
def map_func(example):
conversation = example['conversation']
messages = []
for item in conversation:
messages.append({'role':'user','content':item['human']})
messages.append({'role':'assistant','content':item['assistant']})
return {'messages':messages}
dataset_dict = dataset_dict.map(map_func,batched = False,remove_columns = ['dataset','conversation','category','conversation_id'])
from trl import SFTConfig,SFTTrainer
from peft import LoraConfig
# TODO: Configure LoRA parameters
# r: rank dimension for LoRA update matrices (smaller = more compression)
rank_dimension = 4
# lora_alpha: scaling factor for LoRA layers (higher = stronger adaptation)
lora_alpha = 8
# lora_dropout: dropout probability for LoRA layers (helps prevent overfitting)
lora_dropout = 0.05
# lora_config
peft_config = LoraConfig(
r=rank_dimension, # Rank dimension - typically between 4-32
lora_alpha=lora_alpha, # LoRA scaling factor - typically 2x rank
lora_dropout=lora_dropout, # Dropout probability for LoRA layers
bias="none", # Bias type for LoRA. the corresponding biases will be updated during training.
target_modules="all-linear", # Which modules to apply LoRA to
task_type="CAUSAL_LM", # Task type for model architecture
)
# Configure trainer
training_args = SFTConfig(
output_dir="/root/autodl-tmp/sft/Qwen3-8B/sft-lora",
max_steps=1000,
per_device_train_batch_size=4,
learning_rate=5e-5,
logging_steps=10,
logging_dir = '/root/tf-logs',
save_steps=100,
save_total_limit = 2,
eval_strategy="steps",
eval_steps=100,
load_best_model_at_end = True,
bf16 = True,
warmup_steps = 50,
)
# Initialize trainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset_dict["train"],
eval_dataset=dataset_dict["test"],
processing_class=tokenizer,
# 新增参数
peft_config = peft_config
)
trainer.train()
trainer.save_model('/root/autodl-tmp/sft/Qwen3-8B/sft-lora/best')解决OOM问题(out of memory)
可以设置dtype
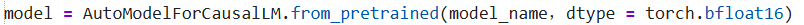
小技巧:一秒钟监听一次smi
合并&推理
保存adaptor合并到W0中,保存完整模型
python
%env HF_ENDPOINT=https://hf-mirror.com
%env HF_HOME=/root/autodl-tmp/hf
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
model_name = "Qwen/Qwen3-8B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype = torch.float16,
)
# Load the PEFT model with adapter
peft_model = PeftModel.from_pretrained(
base_model, "/root/autodl-tmp/sft/Qwen3-8B/sft-lora/best", dtype=torch.float16
)
merged_model = peft_model.merge_and_unload()
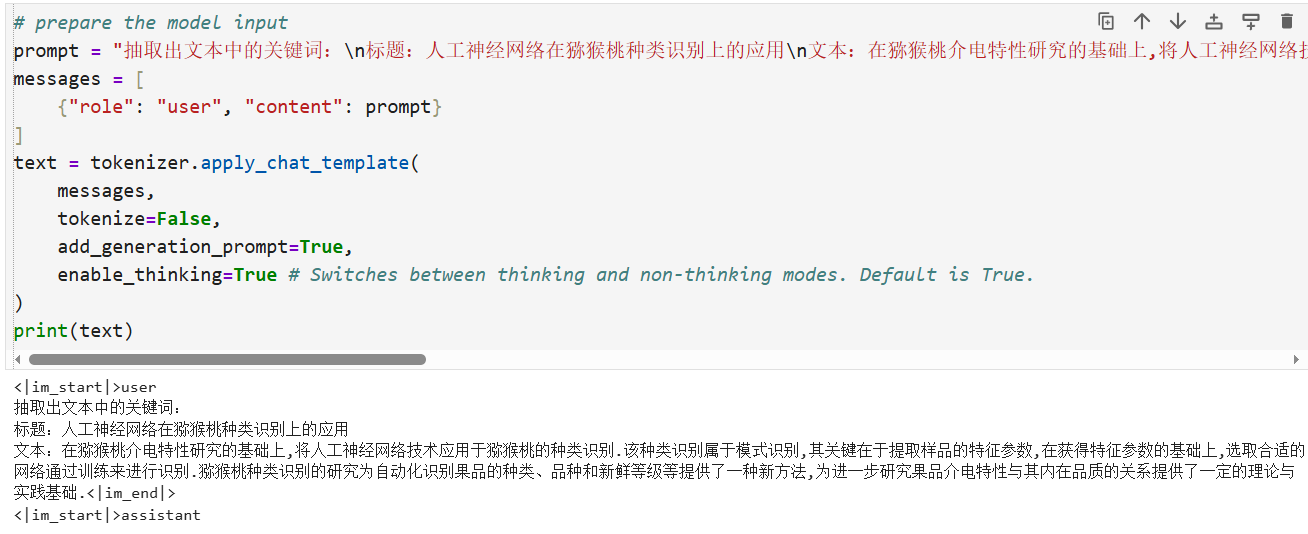
# prepare the model input
prompt = "抽取出文本中的关键词:\n标题:人工神经网络在猕猴桃种类识别上的应用\n文本:在猕猴桃介电特性研究的基础上,将人工神经网络技术应用于猕猴桃的种类识别.该种类识别属于模式识别,其关键在于提取样品的特征参数,在获得特征参数的基础上,选取合适的网络通过训练来进行识别.猕猴桃种类识别的研究为自动化识别果品的种类、品种和新鲜等级等提供了一种新方法,为进一步研究果品介电特性与其内在品质的关系提供了一定的理论与实践基础."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
print(text)
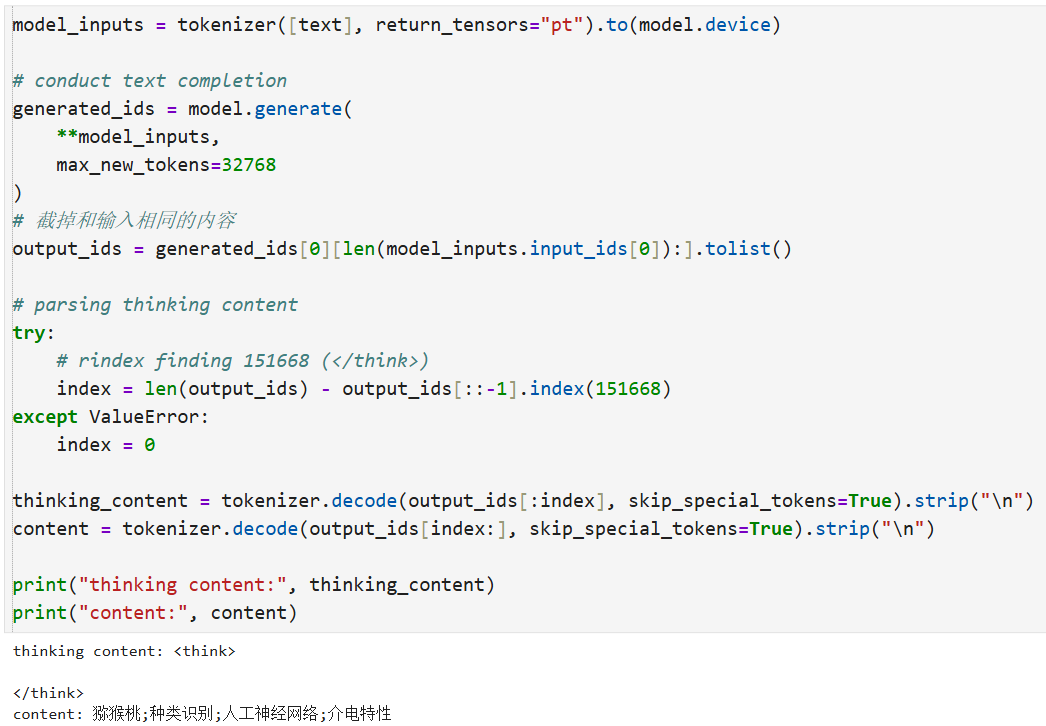
model_inputs = tokenizer([text], return_tensors="pt").to(merged_model.device)
# conduct text completion
generated_ids = merged_model.generate(
**model_inputs,
max_new_tokens=32768
)
# 截掉和输入相同的内容
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
merged_model.save_pretrained("/root/autodl-tmp/sft/Qwen3-8B/sft-lora/merged")
tokenizer.save_pretrained("/root/autodl-tmp/sft/Qwen3-8B/sft-lora/merged")参数高效微调QloRA
编码
装一下量化的库。

核心代码,在lora基础上变动:
加载model和Tokenizer
from transformers import AutoModelForCausalLM,AutoTokenizer
加一个量化操作
import torch
from transformers import BitsAndBytesConfig
from peft import prepare_model_for_kbit_training
config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_name = 'Qwen/Qwen3-8B'
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=config)
模型准备工作
model = prepare_model_for_kbit_training(model)
tokenizer = AutoTokenizer.from_pretrained(model_name)
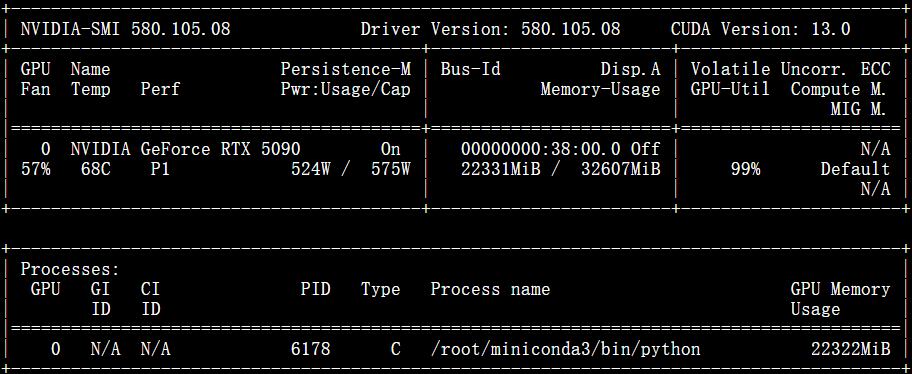
可以查看nvidia-smi看看显存情况
推理&合并
我们用QloRA训出来的adaptor最后合并的时候还是要与基础模型合并,而不是量化后的模型。
代码和LoRA的合并&推理一样,就是把目录改一改。
参数高效微调之Unsloth

官网:https://unsloth.ai/,这个相当于是独立的用法,在hugging face的TRL库里也可也找到。
训练
先装一下unsloth
对比lora具体改动就是前面的创建模型,还有后面trainer里peft_config的参数要删掉,后面的
loraconfig也可以删掉。前面需要在数据处理的时候重新map一个formatting_func,代码去unsloth
官网上找https://unsloth.ai/docs/get-started/fine-tuning-llms-guide/datasets-guide。
python
%env HF_ENDPOINT=https://hf-mirror.com
%env HF_HOME=/root/autodl-tmp/hf
# 加载model和Tokenizer
from transformers import AutoModelForCausalLM,AutoTokenizer
from unsloth import FastLanguageModel
model_name = 'Qwen/Qwen3-8B'
max_length = 2048 # Supports automatic RoPE Scaling, so choose any number
# Load model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_length,
dtype=None, # For auto-detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit=True, # Use 4bit quantization to reduce memory usage. Can be False
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0, # Dropout = 0 is currently optimized
bias="none", # Bias = "none" is currently optimized
use_gradient_checkpointing=True,
random_state=3407,
)
from datasets import load_dataset
from unsloth.chat_templates import get_chat_template
dataset_dict = load_dataset('json',data_files = {'train':'data/keywords_data_train.jsonl','test':'data/keywords_data_test.jsonl'})
# 将数据转为标准对话格式OpenAI
def map_func(example):
conversation = example['conversation']
messages = []
for item in conversation:
messages.append({'role':'user','content':item['human']})
messages.append({'role':'assistant','content':item['assistant']})
return {'messages':messages}
dataset_dict = dataset_dict.map(map_func,batched = False,remove_columns = ['dataset','conversation','category','conversation_id'])
# 将对话格式数据转为字符串chat template
tokenizer = get_chat_template(
tokenizer,
chat_template = "qwen3", # change this to the right chat_template name
)
def formatting_prompts_func(examples):
convos = examples["messages"]
texts = [tokenizer.apply_chat_template(convo, tokenize = False, add_generation_prompt = False) for convo in convos]
return {'text':texts}
dataset_dict = dataset_dict.map(formatting_prompts_func,batched = True,remove_columns = ['messages'])
from trl import SFTConfig,SFTTrainer
# Configure trainer
training_args = SFTConfig(
output_dir="/root/autodl-tmp/sft/Qwen3-8B/sft-unsloth",
max_steps=1000,
per_device_train_batch_size=4,
learning_rate=5e-5,
logging_steps=10,
logging_dir = '/root/tf-logs',
save_steps=100,
save_total_limit = 2,
eval_strategy="steps",
eval_steps=100,
load_best_model_at_end = True,
bf16 = True,
warmup_steps = 50,
)
# Initialize trainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset_dict["train"],
eval_dataset=dataset_dict["test"],
processing_class=tokenizer,
)
trainer.train()
trainer.save_model('/root/autodl-tmp/sft/Qwen3-8B/sft-unsloth/best')这边虽然model_name是Qwen3-8B,但是还是unsloth还是会自己下,可能是量化。

合并
python
model.save_pretrained_merged("/root/autodl-tmp/sft/Qwen3-8B/sft-unsloth/merged", tokenizer, save_method = "merged_16bit",)分布式训练
Accelerate使用说明
https://hf-mirror.com/docs/trl/deepspeed_integration
https://hf-mirror.com/docs/accelerate

这边GPU数量选多卡

运行脚本
先和之前一样写一个全参微调的train.py文件
参数配置要先pip accelerate和deepspeed,然后他会通过问答的方式配置常用参数。资源充足从
ZeRO1开始,不足从3开始。
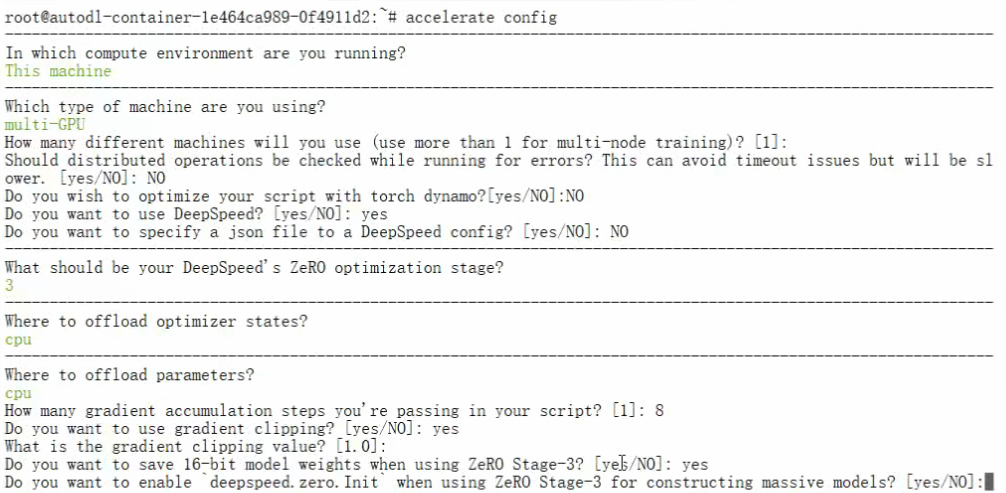

config配置完毕之后,运行。

推理
推理和之前的全参微调推理差不多,可以加一个流式输出,以下是使用案例。
python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
inputs = tokenizer(["The secret to baking a good cake is "], return_tensors="pt")
streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)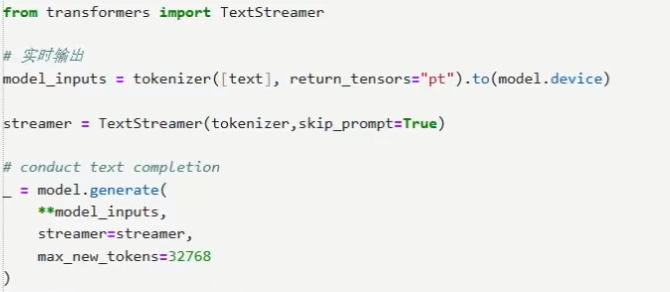
LLaMA Factory
https://llamafactory.readthedocs.io/en/latest/,进到官网,找到installation。
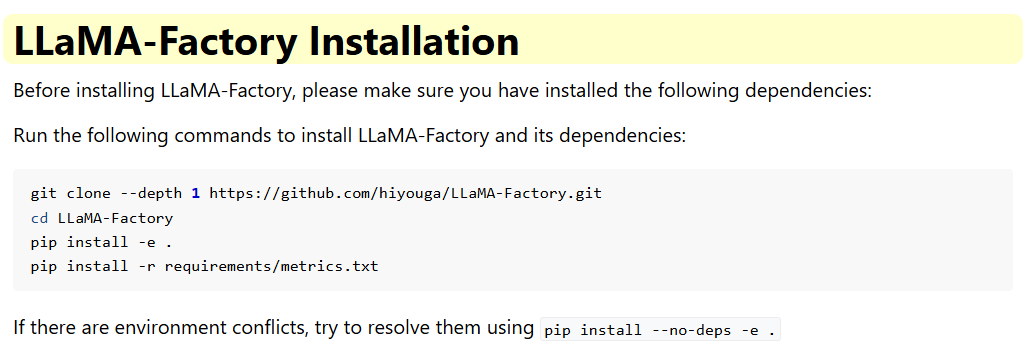
这个好像也行,但是没试过pip install -e ".[torch,metrics]"安装
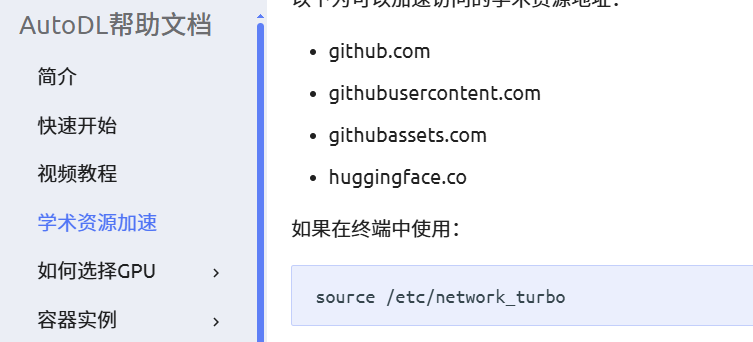
Auto算力云里有一个学术加速,可以帮助快速下载。如果出现环境冲突问题,可以conda创建一个
新环境。


WebUI

下载一个MobaXterm,进入tunnelling,添加新的SSH tunnel。
左边相当于是自己的电脑,右边的下面是租的服务器,上面是LLaMA Factory,可以这么理解。
我们的要求是通过SSH客户端访问LF。
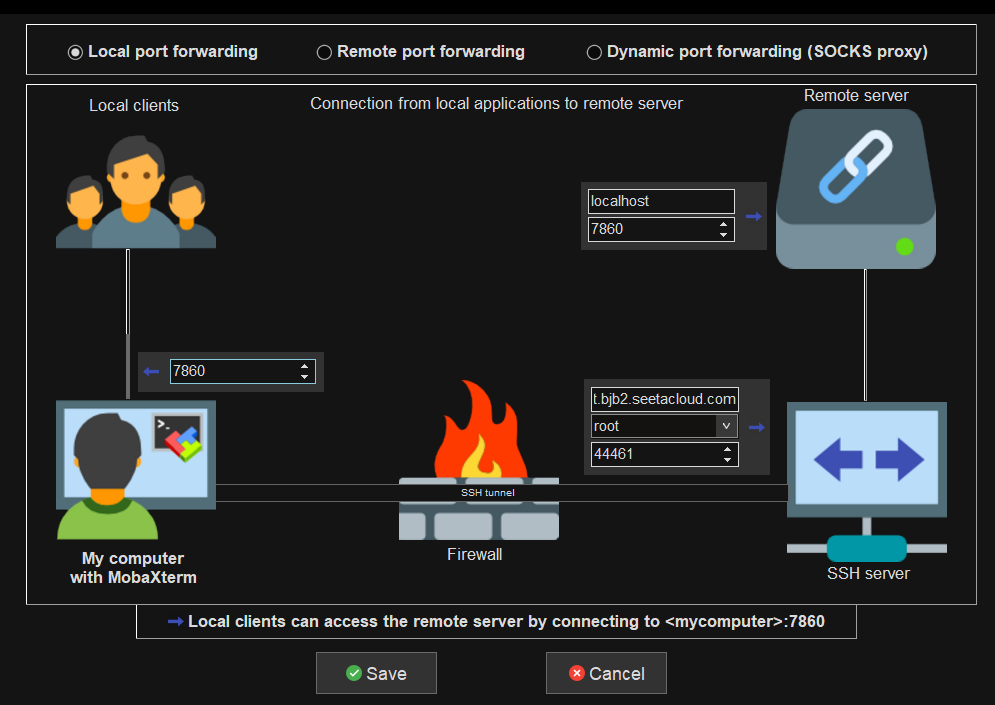
创建好了之后,启动并输入密码。

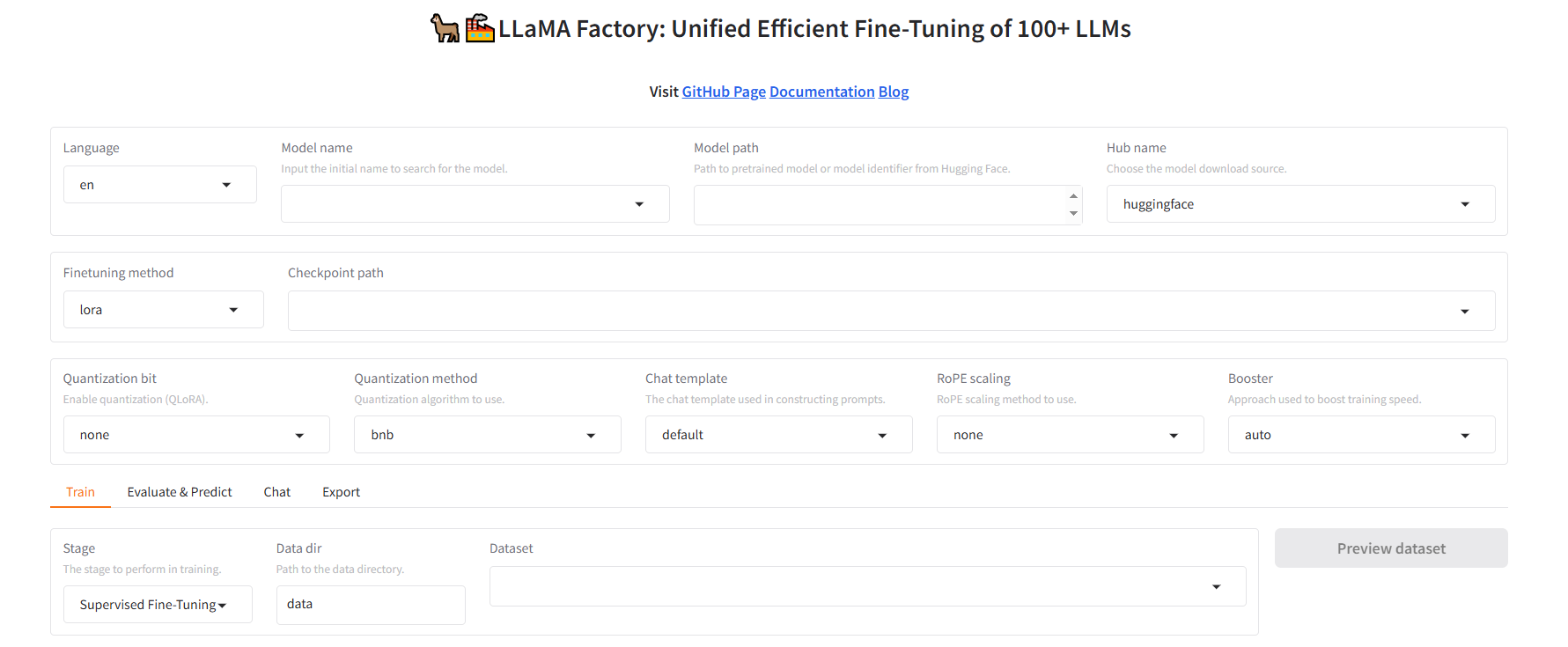
这个数据集是我们创建的llama factory下的data也就是/root/autodl-tmp/LLaMA-Factory/data,要把
我们自己的数据集放进去。
数据处理
先在data下面生成一个keywords.jsonl的文件,这个文件是在root/data下的,然后把这个文件移到
llama factory的data下面。
python
from datasets import load_dataset
dataset_dict = load_dataset('json',data_files = {'train':'data/keywords_data_train.jsonl','test':'data/keywords_data_test.jsonl'})
def map_func(example):
conversation = example['conversation']
messages = []
for item in conversation:
messages.append({'role':'user','content':item['human']})
messages.append({'role':'assistant','content':item['assistant']})
return {'messages':messages}
dataset_dict = dataset_dict.map(map_func,batched = False,remove_columns = ['dataset','conversation','category','conversation_id'])
dataset_dict['train'].to_json('data/keywords.jsonl')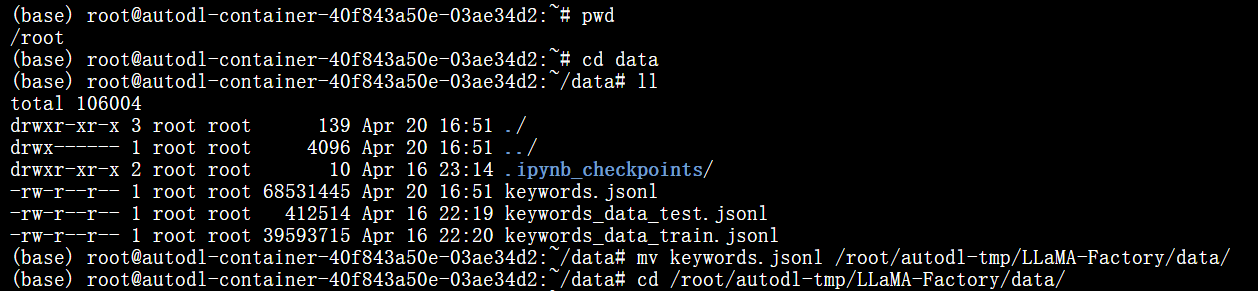
修改

这里的file_name填我们的名字,然后给数据集起个名字,具体代码见,这是llama factory的openai
格式下的文档。https://llamafactory.readthedocs.io/en/latest/getting_started/data_preparation.html#openai

配好之后就可以在页面上找到我们的数据集。

训练配置
在打开UI界面之前设置一下环境变量,这个是镜像环境和允许设置额外参数。

训练参数配好了可以保存,下次可以加载。
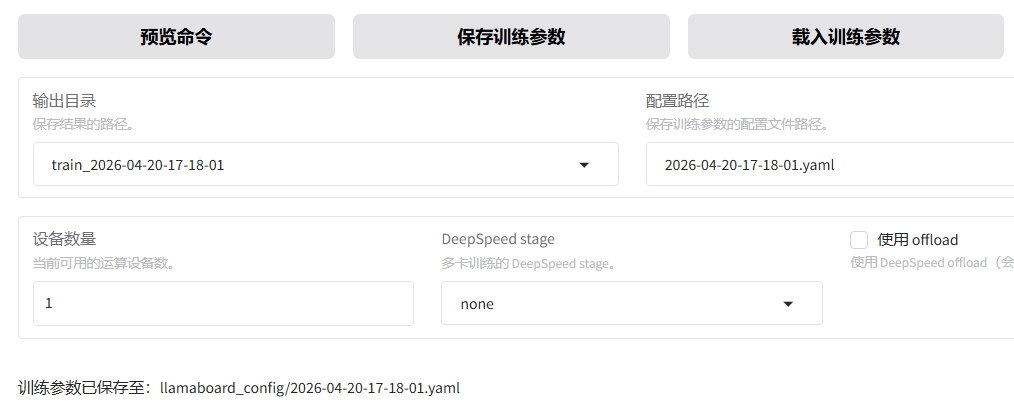
开始训练
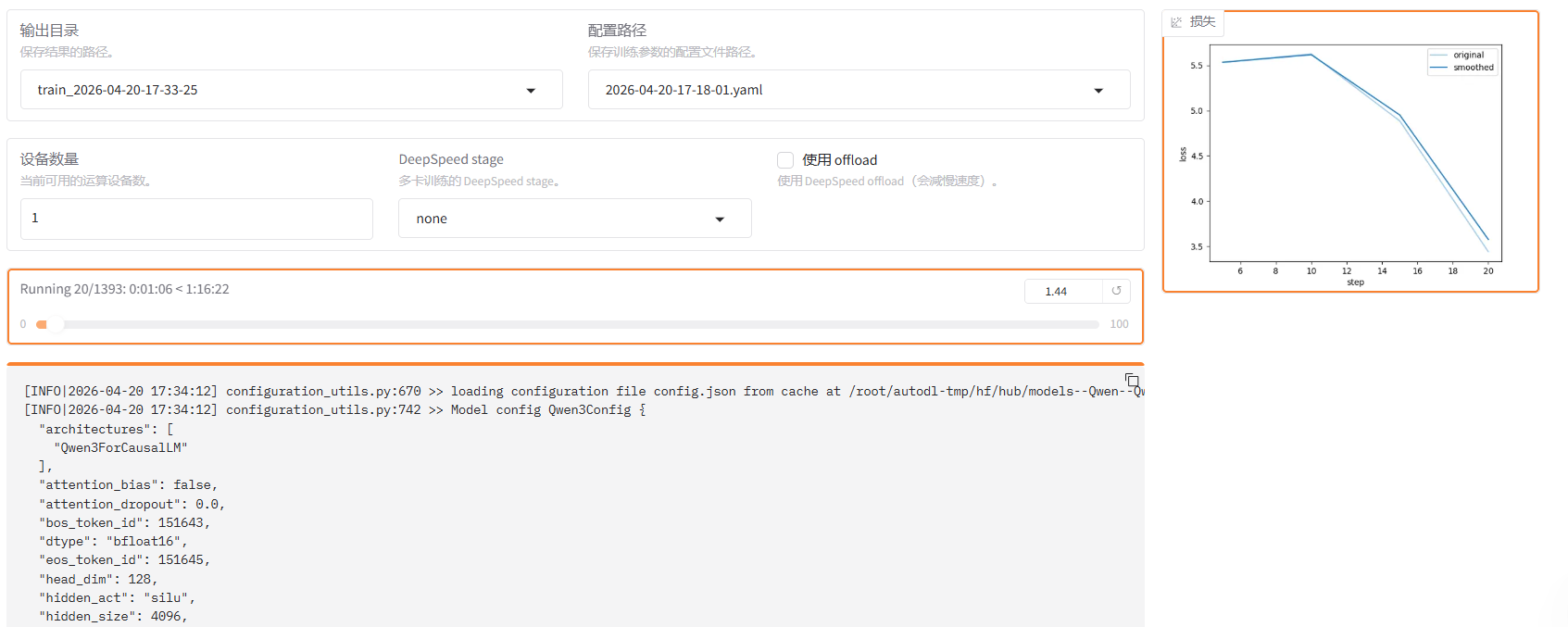
测试&合并&导出
llama factory下面有一个saves

一直沿着找到保存的目录,输出目录和llama factory中的输出目录显示是一样的。
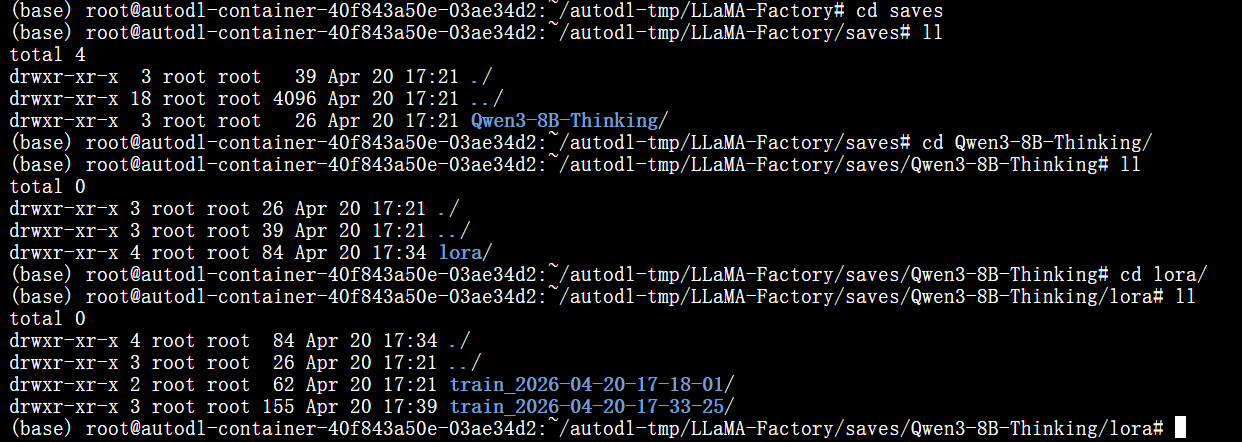
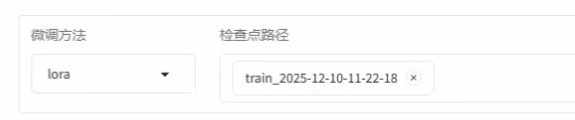
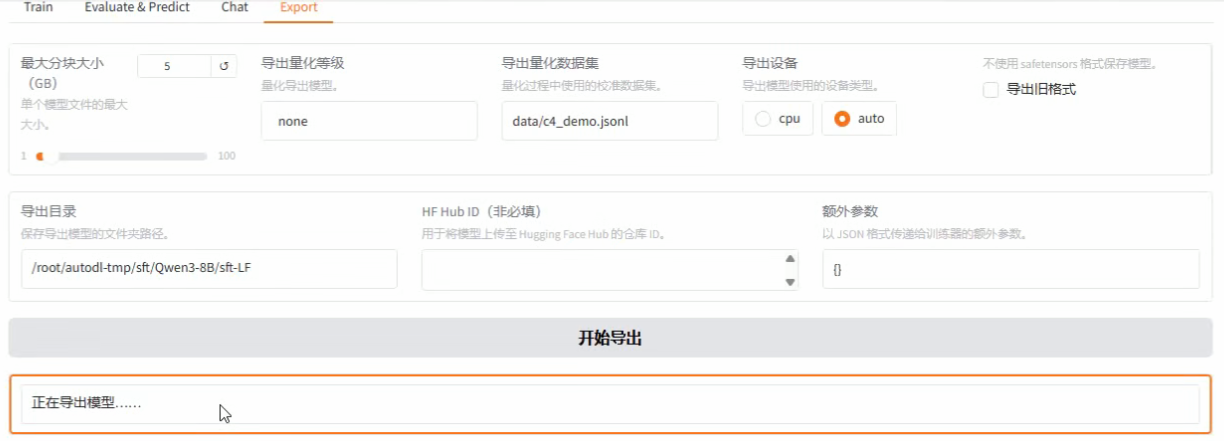
在检查点选择我们训好的adaptor,这样他能自己识别,然后导出模型。
vLLM模型部署
day6 9