
前言
之前我们讲过Midscene,js工具的基本搭建过程和使用方式,但是离落地企业级的自动化方案还差得远,顶多是个开胃菜,让大家先初步了解这个工具,颠覆以前对传统selenium等工具需要元素定位方式实现WEB自动化的认知,让我们积极拥抱AI,探索AI。
背景
做过WEB自动化的都清楚一个事实,基于selenium等传统工具实现WEB自动化,有以下三个主要的缺点:
1 学习成本高 ,对测试人员要求较高,需要懂html,懂python或者java,懂
pytest/RobotFramework/testng等框架。
2.开发效率低,需要花费大量的时间找元素,写Xpath,编写用例和调试用例。
3.维护工作量大,后期一旦版本有大的变动,之前好不容易写好的的代码都可能推倒重来。
而Midscene.js工具是基于纯视觉模式,只需要通过自然语言描述,工具通过跟AI大模型的交互就能完成用例的执行过程并返回可视化的html报告,让测试人员更简单更直观的进行WEB自动化测试。
不过要想使用好Midscene.js工具,得先知道工具的2个缺点:
-
工具需要跟大模型交互,耗费很多的tokens(需要money)。
-
工具基于纯视觉,不停的截图跟大模型交互,运行时间上会较长(需要时间)
总结:想用Midscene.js AI工具,得接受时间和金钱的高成本。
该工具特别适合内部已经搭建好大模型的公司,或者不差钱的公司,或者节省人力成本增加tokens成本的公司,或者只是想尝试探索新技术的公司等等。
企业级落地方案
因为Midscene.js工具本身并不具备通用化,简单化和工程化的能力,而且该工具使用的js语言对于很多测试人员来说有些陌生,很难让测试人员尤其是无编码能力的人员方便使用。
因此想尝试一种能像写http接口一样简单的方式,以下实践已经在内部项目上运行,分享出来供大家参考。
1 思路
在windows server机器上通过python语言将midscene.js工具封装为http通用api接口。这样不管是python/java,或者公司内部的自动化平台等都能很好的进行http的调用。
http接口支持解析传参并提取json(json格式严格按照midscene.js工具支持的yaml内容格式)后,转为yaml文件存储,然后调用midscene工具执行yaml文件,然后实时获取运行日志,通过正则提取html报告和结果信息,并组装html报告的get请求地址等内容返回。
2 环境搭建
1、windows 安装 midscene.js 工具
1)安装 node.js
2)安装 midscene.js
打开 cmd 命令窗口,执行如下命令:
#配置国内nmp源或者公司内部的npm源 以阿里云举例
npm config set registry https://registry.npmmirror.com
#配置不安装google浏览器(如果在内网安装可能导致下载报错,如果上网无限制可以跳过该步骤)
set PUPPETEER_SKIP_DOWNLOAD=true
#安装midscene.js最新版本
npm install -g @midscene/cli
#检查midscene.js的版本(如果有版本信息就安装成功了)
midscene --version
1.6.02、配置大模型和谷歌浏览器程序路径的环境变量
打开我的电脑的环境变量配置页面,将如下配置到环境变量:
#大模型信息
MIDSCENE_MODEL_BASE_URL=大模型http地址
MIDSCENE_MODEL_API_KEY=你的APIKEY
MIDSCENE_MODEL_NAME=doubao-seed-20-pro #以豆包举例
MIDSCENE_MODEL_FAMILY=doubao-vision #以豆包举例
#谷歌浏览器的程序地址,midscene.js执行时使用(如果上面步骤安装了谷歌浏览器,该步骤跳过)
PUPPETEER_EXECUTABLE_PATH=C:\Users\appadmin\AppData\Local\Google\Chrome\Application\chrome.exe #你自己的谷歌浏览器地址
#配置跟模型交互的最大次数(默认是20次)
MIDSCENE_REPLANNING_CYCLE_LIMIT=1003、使用midscene.js工具执行yaml文件的方式,完成一个web自动化的示例
yaml 文件示例:
web:
url: https://www.baidu.com
tasks:
- name: 搜索天气
flow:
- ai: 搜索 "今日天气",点击"百度一下"
- sleep: 3000
- aiAssert: 搜索后结果显示天气信息打开cmd,执行命令:midscene yaml文件。
4、python封装midscene.js工具,支持通用的http接口调用能力
通过 python的Flask封装http接口,具备2个能力:
-
通过post请求,解析传参中的用例名称和yaml所需的测试步骤,然后后台调用midscene.js 工具执行yaml文件,解析日志,生成测试结果和报告。将测试结果以 json 数据格式返回。
-
通过get请求获取html报告。
a、http接口用于执行用例
- 接口类型:Http Post 接口
- 接口地址:http://xxxxxxx:5000/execute/testcase
- 传参格式:JSON
- 消息体:{"caseName":"", "Steps":""}
caseName:用例名称,会生成以它命名的 yaml 文件和 html 报告
Steps:yaml 文件格式内容,为json格式数据
举例:
{'caseName':'百度搜索天气','Steps':{'web': {'url': 'https://www.baidu.com'}, 'tasks': {'name': '搜索天气', 'flow': \[{'ai': '搜索 "今日天气",点击"百度一下"'}, {'sleep': 3000}, {'aiAssert': '搜索后结果显示天气信息'}}]}}
响应json数据
返回字段说明:code:1 代表成功,0 代表失败;output:工具的一些输出信息;report:html 报告的http请求地址,可访问和下载。
举例(返回数据)
{
"code": 0,
"output": "查看截图左侧菜单栏,能够看到「人员管理」选项处于选中状态,是明确展示在左侧菜单栏的,因此"在左侧菜单栏不应该展示用户管理"的表述不成立,对应布尔值为false。",
"report": "http://127.0.0.1:5000/execute/htmlreport/登录web成功_1775184223.588202.html"
}b.通过 get 请求可以获取到 html 报告的内容
- 接口方式:HttpGet 请求
- 功能:访问 report 字段中的地址,直接返回 HTML 报告的完整内容
- 特点:支持在浏览器打开、下载报告,可视化查看执行步骤、截图、断言结果等
5 搭建后台flask工程
工程结构如下:
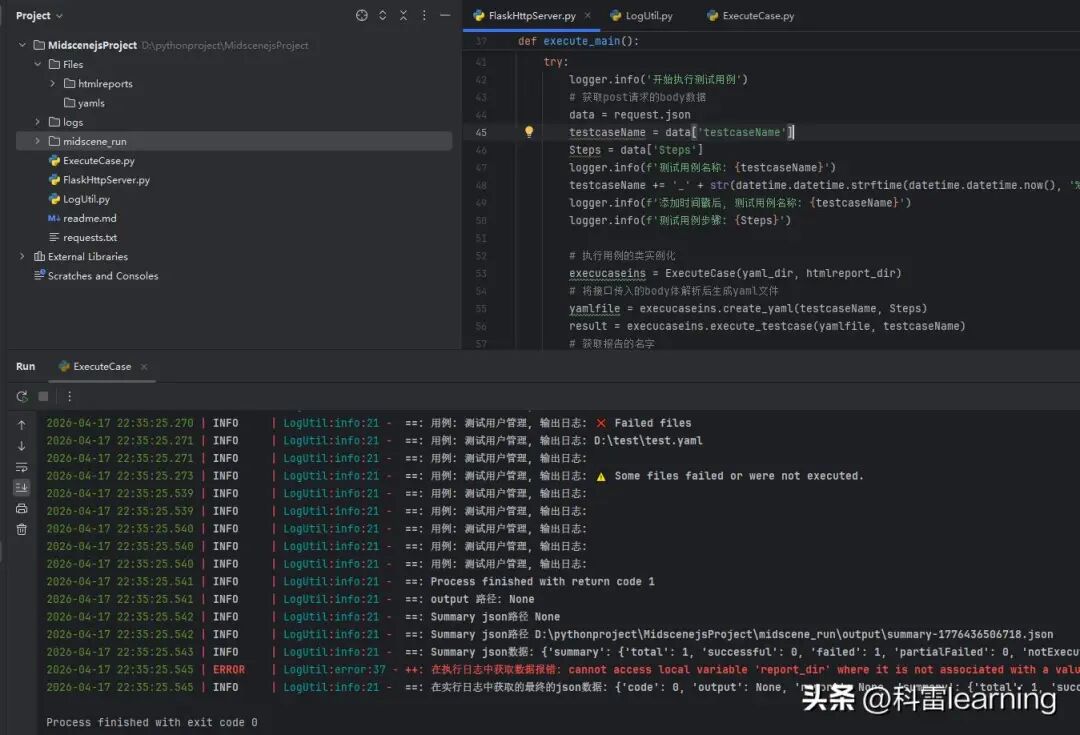
python文件结构
FlaskHttpServer.py:Flask主程序,负责路由与接口调用。
ExecuteCase.py:执行用例,生成yaml文件并执行,然后提取html报告并返回数据。
logUtil.py:日志存储管理。
用到的python包:
flask/waitress/loguru/yaml (需要安装),其他如subprocess/os/shutil/re/datetime/json等
6 Flak程序运行后,就可以通过http接口调用
以python的requests工具调用举例:
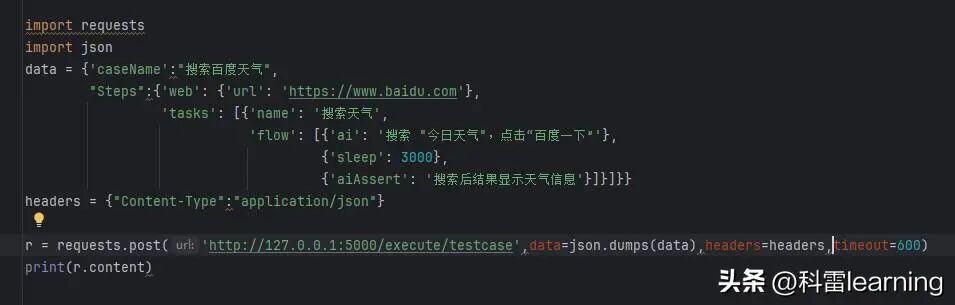
希望能给大家带来一些经验,感兴趣的请点赞收藏加关注。
有需要部署代码的的可以私信联系。