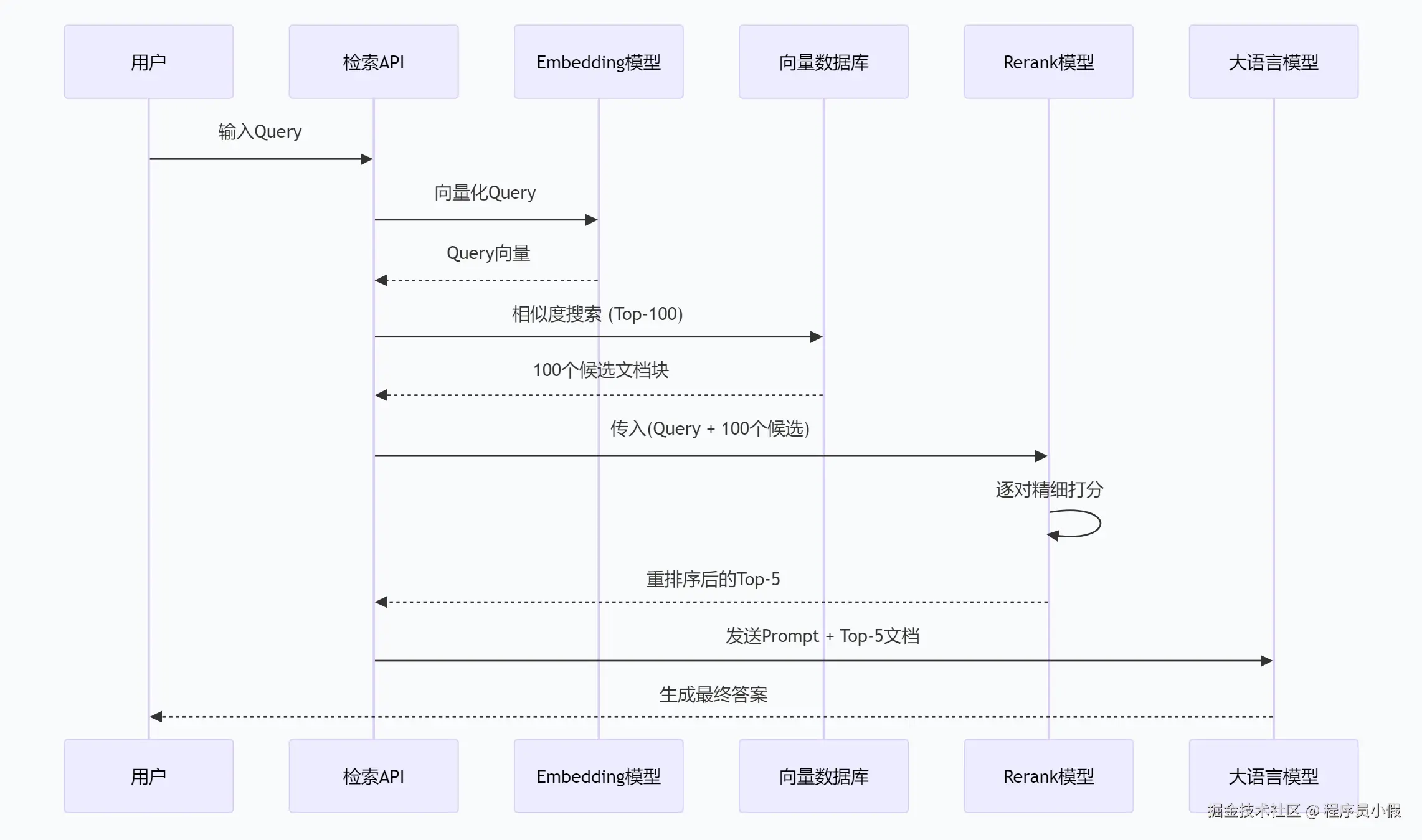
一、向量检索的整体流程
向量检索通常用于语义搜索、RAG(检索增强生成)、推荐系统 等场景。其标准流程可以分为 离线阶段 和 在线阶段。
离线阶段(索引构建)
- 文档切分(Chunking)
将长文档切分成较小的文本块(如 200--500 字),便于后续精准检索。 - Embedding 向量化
使用 Embedding 模型将每个文本块转换成固定长度的浮点数向量 (例如 768 维、1536 维)。
→ 向量代表该文本的语义特征。 - 构建向量索引
将所有向量存入向量数据库(如 Milvus、Faiss、Qdrant),并建立近似最近邻(ANN)索引(如 HNSW、IVF),以支持快速检索。
在线阶段(检索与重排)
- 用户输入 Query
例如用户问:"如何提高跑步速度?" - Query 向量化
使用同一个 Embedding 模型将 Query 转换成向量。 - 向量相似度搜索
在向量数据库中检索与 Query 向量最相似的 Top-K 个向量(例如 K=100)。
-
- 常用相似度:余弦相似度、内积、欧氏距离。
- 这一步是粗排,追求快,不追求极准。
- Rerank(重排序)
使用一个更强大的交叉编码器(Cross-Encoder) 模型,对候选的 K 个文本块与 Query 进行精细的相关性打分,重新排序,输出 Top-N(例如 N=5)。 - 返回最终结果
将重排后的最相关文本块返回给下游任务(如 LLM 生成答案)。
二、Embedding 的作用
Embedding 模型(又称双编码器,Bi-Encoder)将文本映射到向量空间。
核心特点
- 独立编码:Query 和 Document 分别独立通过模型生成向量。
- 计算速度快:文档向量可以离线预计算并建索引,在线只需计算 Query 向量。
- 语义表示:相似语义的文本在向量空间中距离更近。
具体作用
- 将非结构化文本转换成可计算的数学对象(向量) ,使得语义相似度可以通过向量距离度量。
- 支持大规模快速检索:通过 ANN 索引,可以在百万/十亿级向量中毫秒级召回。
- 泛化能力强:可以匹配同义词、上下位词、不同表达方式的相同语义(相比关键词检索)。
局限性
- 精度有限:Embedding 是压缩的语义表示,会丢失细粒度信息(如否定、特定关系)。
- 对复杂查询(如多条件、逻辑组合)不够精准。
例:
Query:"不是苹果公司的产品"
可能依然会匹配到"iPhone"相关文本,因为"苹果"语义太强。
三、Rerank 的作用
Rerank 模型(通常是交叉编码器,Cross-Encoder)对(Query, Document)对进行联合打分。
核心特点
- 联合编码:将 Query 和 Document 拼接在一起输入模型,通过 Transformer 的 Self-Attention 进行深层交互。
- 计算速度慢:无法预计算,每个候选对都要单独通过模型,因此只能对小规模候选集(如 100 个)进行重排。
- 精度高:能捕捉 Query 与 Document 之间的细粒度语义匹配、逻辑关系、否定、条件等。
具体作用
- 修正 Embedding 粗排的误差
Embedding 可能召回语义相似但实际不相关的文档(例如"跑步速度" vs "汽车速度")Rerank 能区分。 - 提升排序的相关性
尤其适合 Query 复杂、需要精确理解用户意图的场景。 - 引入更多信号
可以结合业务规则、时间新鲜度、权威性等,但标准的 Rerank 模型本身只做语义匹配打分。 - 最终决定输出顺序
给 LLM 的上下文通常是 Rerank 后排名靠前的少量文档。
例:
Query:"如何提高跑步速度?"
- Embedding 召回的第 1 名可能是"跑步机速度调节方法"(语义较近但不完全对)。
- Rerank 会将"步频训练、间歇跑技巧"提到前面。

四、两者对比与配合
| 维度 | Embedding (Bi-Encoder) | Rerank (Cross-Encoder) |
|---|---|---|
| 输入方式 | Query 和 Doc 独立编码 | Query + Doc 拼接联合编码 |
| 计算速度 | 快(可预计算) | 慢(无法预计算) |
| 精度 | 中等 | 高 |
| 适用阶段 | 粗排(召回) | 精排(重排序) |
| 候选集大小 | 百万/十亿级 | 百/千级 |
| 模型复杂度 | 较低(如 BERT 的池化输出) | 较高(需全连接分类层) |
配合逻辑
Embedding 负责"广",Rerank 负责"准"。
- 没有 Embedding:每次检索都要对全库文档做 Cross-Encoder,无法实用。
- 没有 Rerank:可能召回很多"貌似相关但实际无用"的内容,影响下游 LLM 生成质量。
五、一个具体例子
文档库(已切块):
- D1:"步频训练是提高跑步速度的关键,每分钟 180 步为佳。"
- D2:"提高汽车速度需要加大油门和优化空气动力学。"
- D3:"跑步前热身可以预防受伤,但对速度提升帮助有限。"
Query:"怎么通过步频提升跑步速度?"
流程
- Embedding 召回 Top-2:
-
- D1(相似度 0.92)
- D2(相似度 0.78,因为"速度"一词)
(D3 相似度 0.65,未进 Top-2)
- Rerank 对 (Q,D1) 和 (Q,D2) 打分:
-
- (Q,D1) → 0.99
- (Q,D2) → 0.10(因为发现"汽车"与"跑步"无关)
- 最终输出:只返回 D1。
面试回答
我觉得可以把向量检索理解成一个 '从粗到细的查找过程',主要分三步:
- 提前建库:先把所有文档(或商品、图片等)通过 Embedding 模型转成向量,存到向量数据库里。
- 查询转换 :用户输入一个问题,用同一个 Embedding 模型把问题也转成向量。
- 近似检索:用 FAISS 这类工具,在库里快速找到最相似的 Top-K 个向量(比如 100 个)。这一步是近似最近邻搜索,牺牲一点精度换速度。
Embedding 的作用是把非结构化数据变成语义向量 ,核心是召回。
- 它要保证:意思相近的内容,在向量空间里距离也近。比如'怎么退火车票'和'取消高铁订单'的向量会很接近。但它有个局限:为了效率,只能用一个向量代表整个句子或段落,所以细节上会丢。比如两个词义相近但实际不相关的句子,也可能被误认为相似。
Rerank 是用来给召回结果重新精细打分的。
- 它的模型通常更大,会把用户 Query 和每个召回文档拼在一起输入模型,直接输出一个相关性分数(比如 0.1 到 0.9)。这个过程精度很高,能理解对比、否定、多跳推理等复杂关系,但计算量也大,没法对几百万条数据做。所以典型做法是:先用 Embedding 快速召回 100 条,再用 Rerank 挑出最相关的 10 条给用户。
总结一句话:Embedding负责'快而粗'地召回候选集,Rerank负责'慢而精'地重排Top结果。两者结合,兼顾速度和效果,这是工业界标准做法。