随着图像生成技术不断进步,AI 已经不再只是"生成一张看起来不错的图片",而是开始真正参与到创意表达、设计生产和内容构建的完整流程中。从海报、插画、UI 概念图,到多语言宣传素材、教育信息图和视觉叙事内容,图像模型正在从单一工具演变为更智能、更可控的视觉生产系统。
这篇教程将围绕 ChatGPT Image 2展开,系统介绍它在精细指令遵循、多语言文本渲染、风格表现、宽高比适配、现实知识理解以及 thinking 模式下的视觉推理能力等方面的提升。同时,我们也会结合实际场景,看看它如何在 ChatGPT、Codex 和 API 中帮助个人开发者、设计师、内容创作者与企业团队,把想法更高效地转化为真正可用的视觉成果。

GPT Image 2官方详细介绍
图像是一种语言,而不是装饰。好的图像就像好的句子一样------它会进行选择、组织并揭示内容。它可以解释一种机制,营造一种氛围,验证一个想法,或者提出一个论点。
一年前,我们发布了 ChatGPT Images,证明了由 AI 创建的图像既可以美观,也可以实用。ChatGPT Images 2.0 是下一步:这是一个最先进的模型,能够承担复杂的视觉任务,并生成精确、可立即投入使用的视觉作品。
这个模型在细致遵循指令、准确放置并关联对象、渲染密集文本方面实现了跃升,并且能够适配多种宽高比进行生成。它在构图和视觉审美上的能力,使结果看起来不再那么像"AI 生成",而更像是经过有意设计的作品。它能准确处理多种语言,并利用其扩展后的视觉知识和世界知识为你补足空缺,因此你只需更少的提示,就能得到更聪明的图像。
为了将模型能力扩展到最复杂的任务,Images 2.0 是我们首个具备思考能力的图像模型。当你在 ChatGPT 中选择 thinking 或 pro 模型时,Images 2.0 可以联网搜索实时信息、根据一条提示生成多张彼此不同的图像,并对自己的输出进行复核。借助思考能力,模型可以在"想法"与"图像"之间承担更多繁重工作,尤其是在准确性、时效性、一致性和视觉统一性最重要的时候。
结合 OpenAI 推理模型的智能与对视觉世界的广泛理解,这个模型让图像生成从"渲染"迈向"策略性设计",从一个工具进化为一个视觉系统,帮助人们把想法转化为能够被理解、分享、教学和继续构建的成果。从今天起,它已面向 ChatGPT、Codex 和 API 的所有用户开放。
更高的精度与控制力
gpt-image-2为图像创作带来了前所未有的具体性和保真度。它不仅能够构思更复杂的图像,还能真正高效地将这种构想变为现实:能够遵循指令、保留所要求的细节,并渲染那些常常会让图像模型失效的精细元素------小号文字、图标、UI 元素、复杂构图以及微妙的风格限制;在 API 中,输出分辨率最高可达 2K。与其得到一个只是"大概接近"你想法的结果,你现在会得到一个真正可以使用的成果。
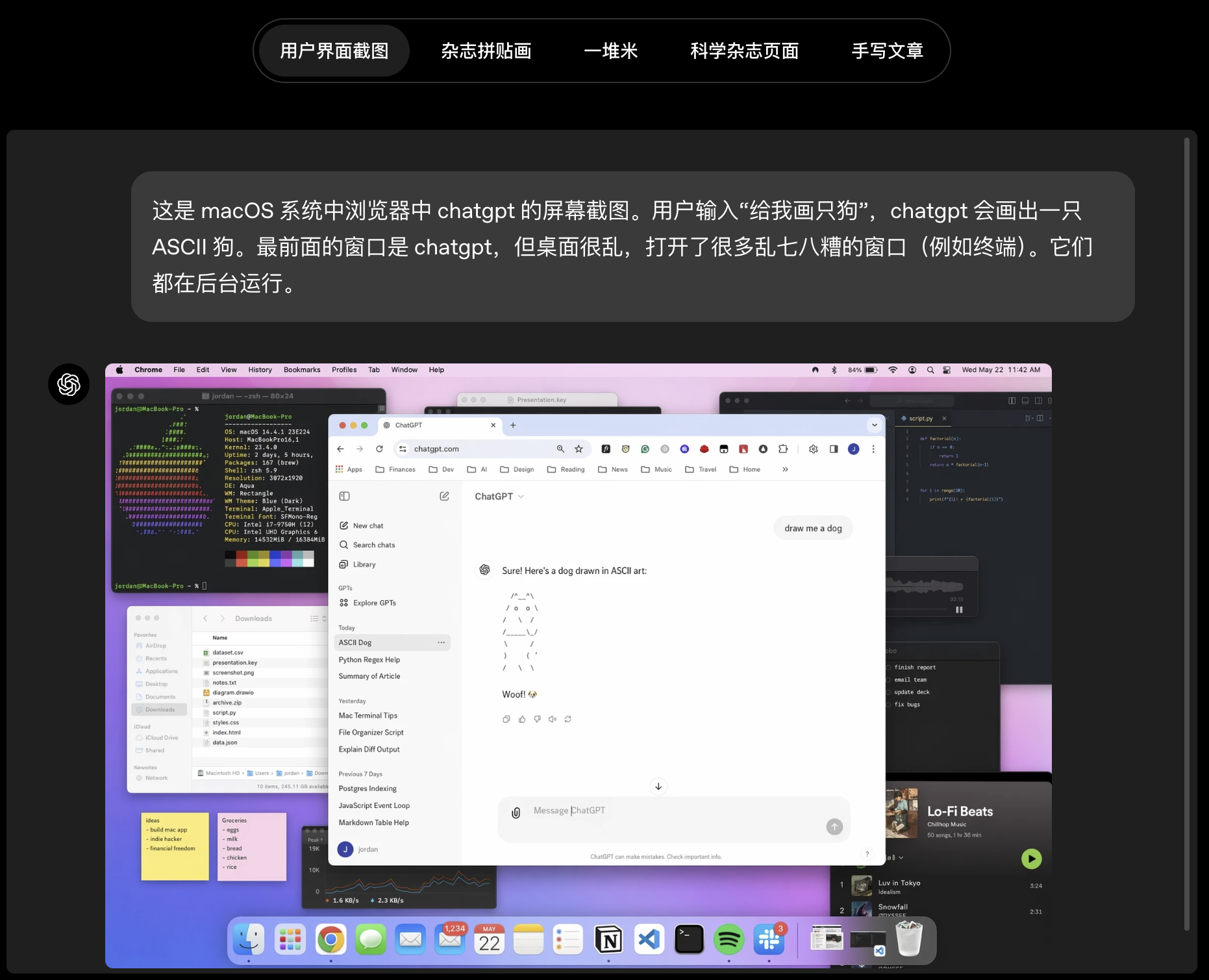
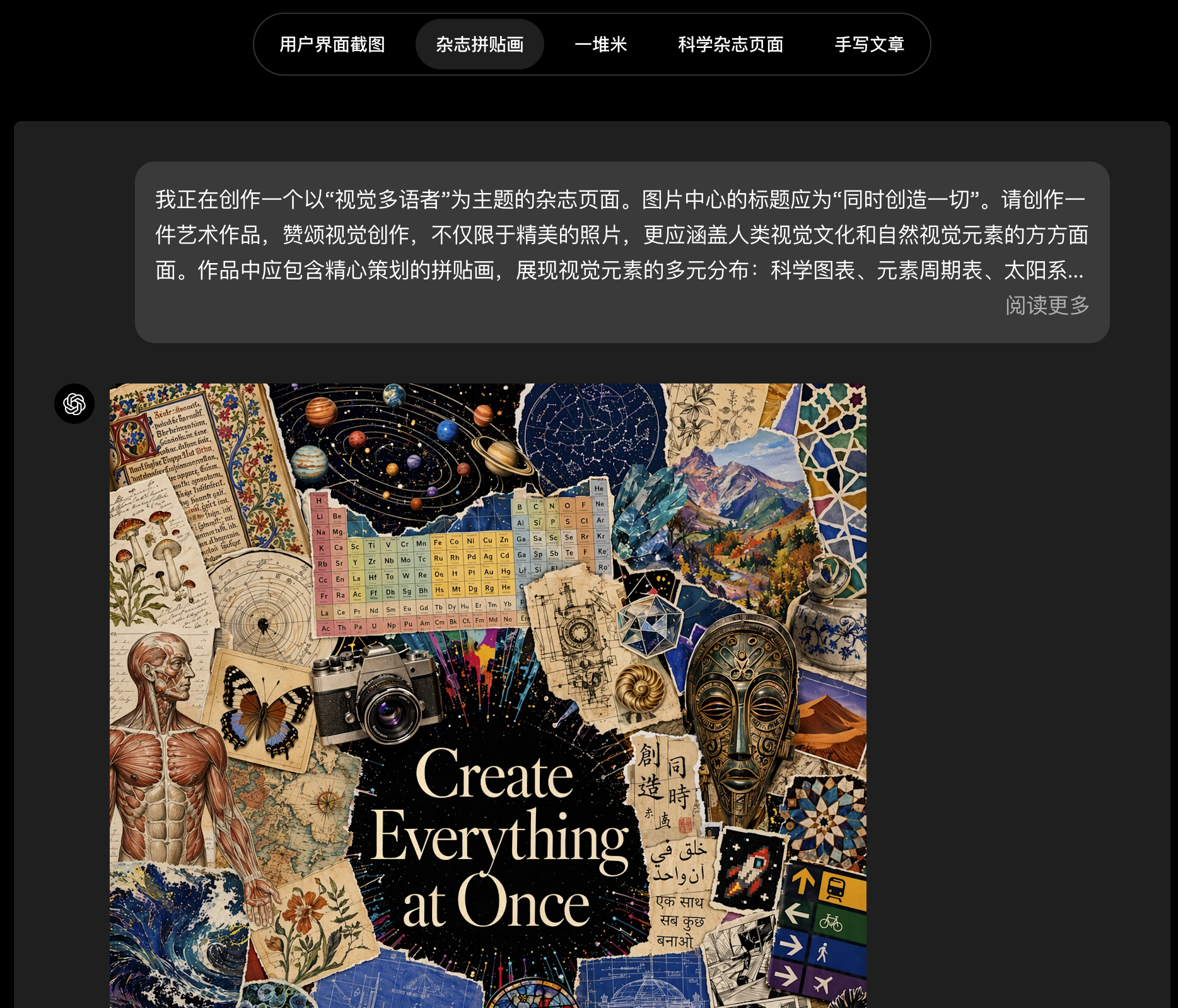
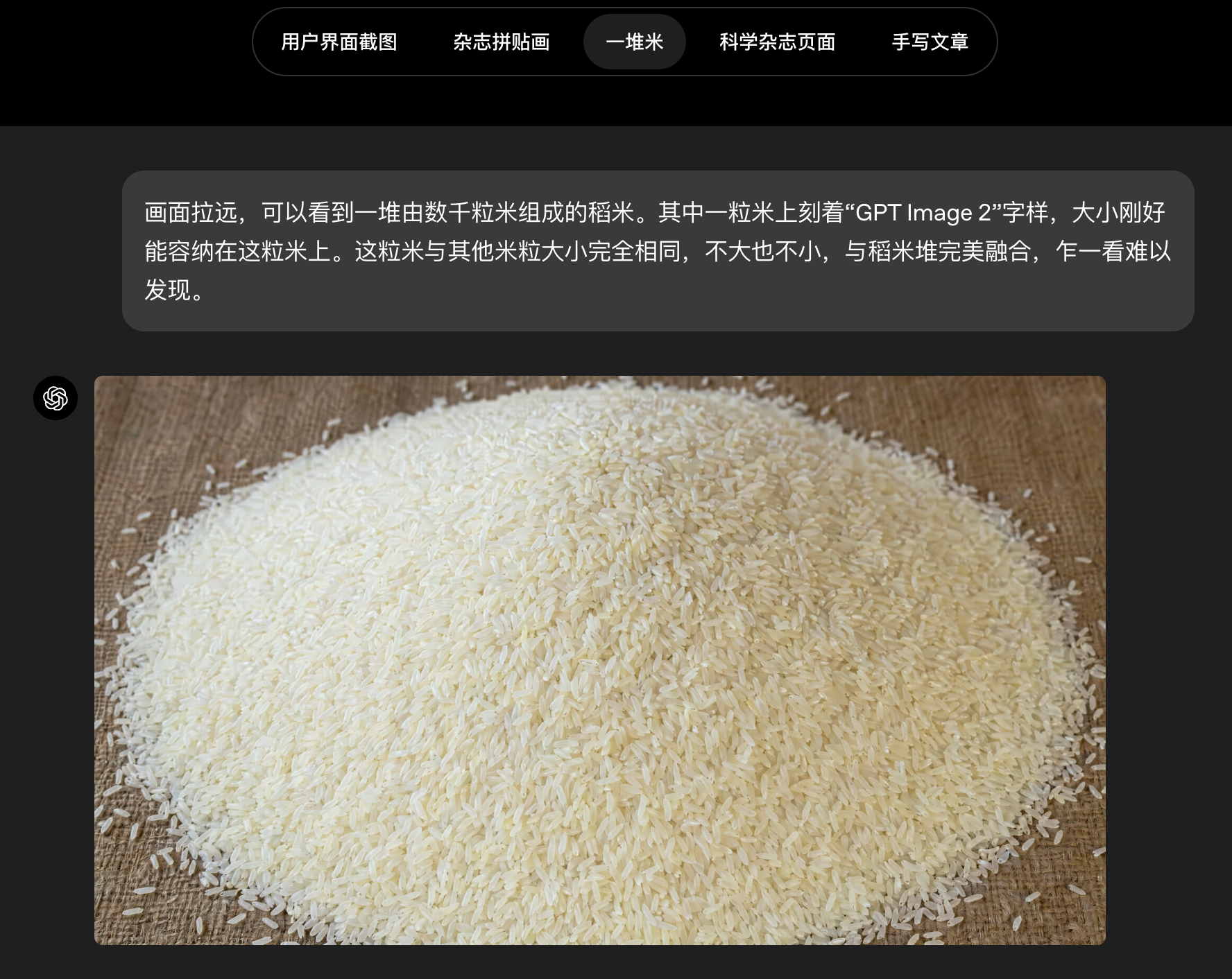


多语言能力更强
到目前为止,我们的图像生成模型在英语及其他拉丁字母语言中的表现更稳定,但在这些语言之外,尤其是当文本复杂或密集时,准确性就会下降。
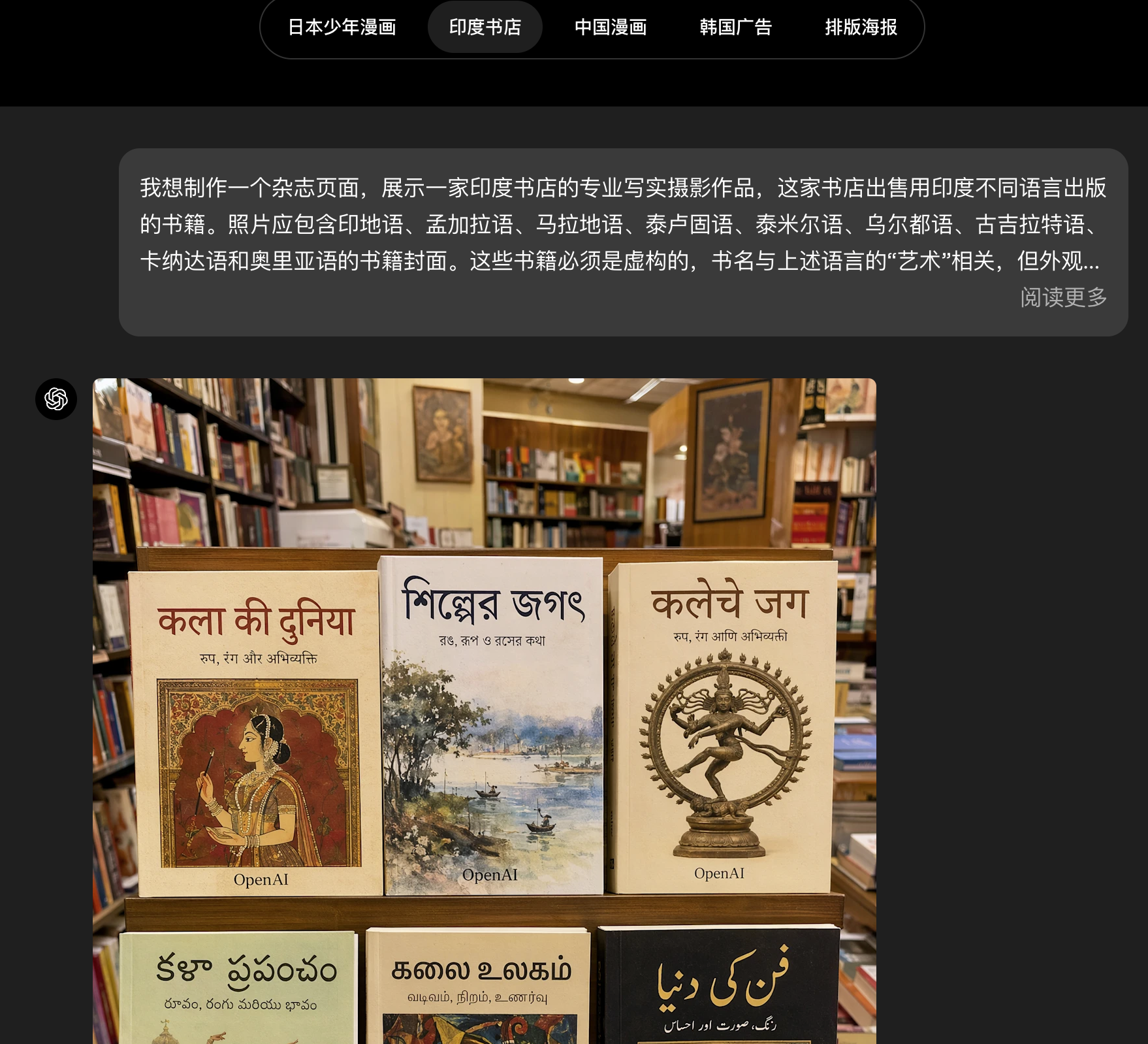
gpt-image-2突破了这一障碍,具备更强的多语言理解能力,并在非拉丁文字渲染方面取得了显著进步,尤其是在日语、韩语、中文、印地语和孟加拉语方面。它不仅能生成带有非英语文本的图像,而且这些文本不仅渲染正确,语言表达也连贯自然。
这不仅仅意味着翻译一两个标签,而是能够生成语言本身就是设计一部分的、视觉上连贯的作品------从海报、说明图到图表和漫画。这让模型在全球范围内更实用,也帮助人们用自己真正使用的语言去创作视觉内容。
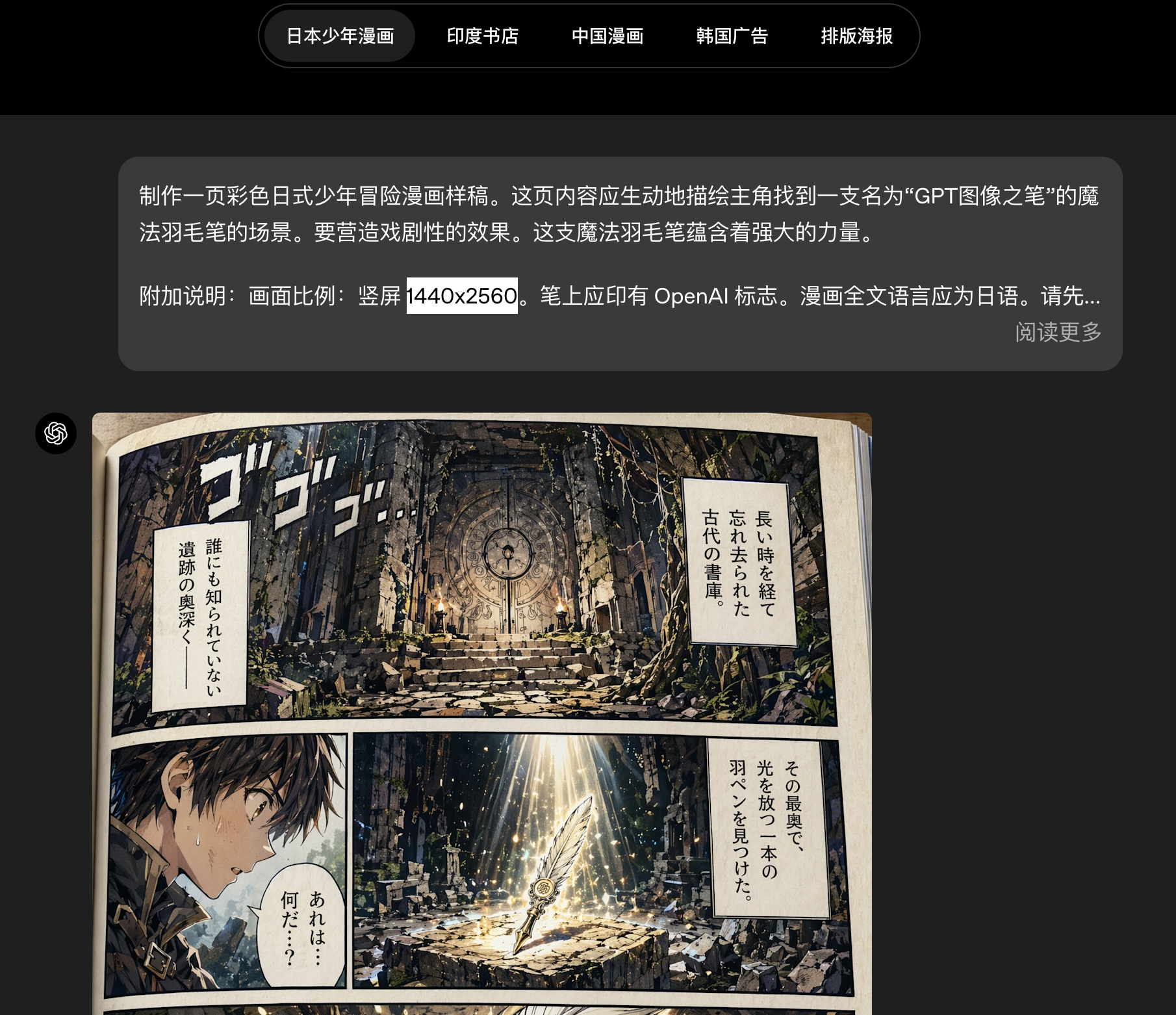


更成熟的风格表现与真实感
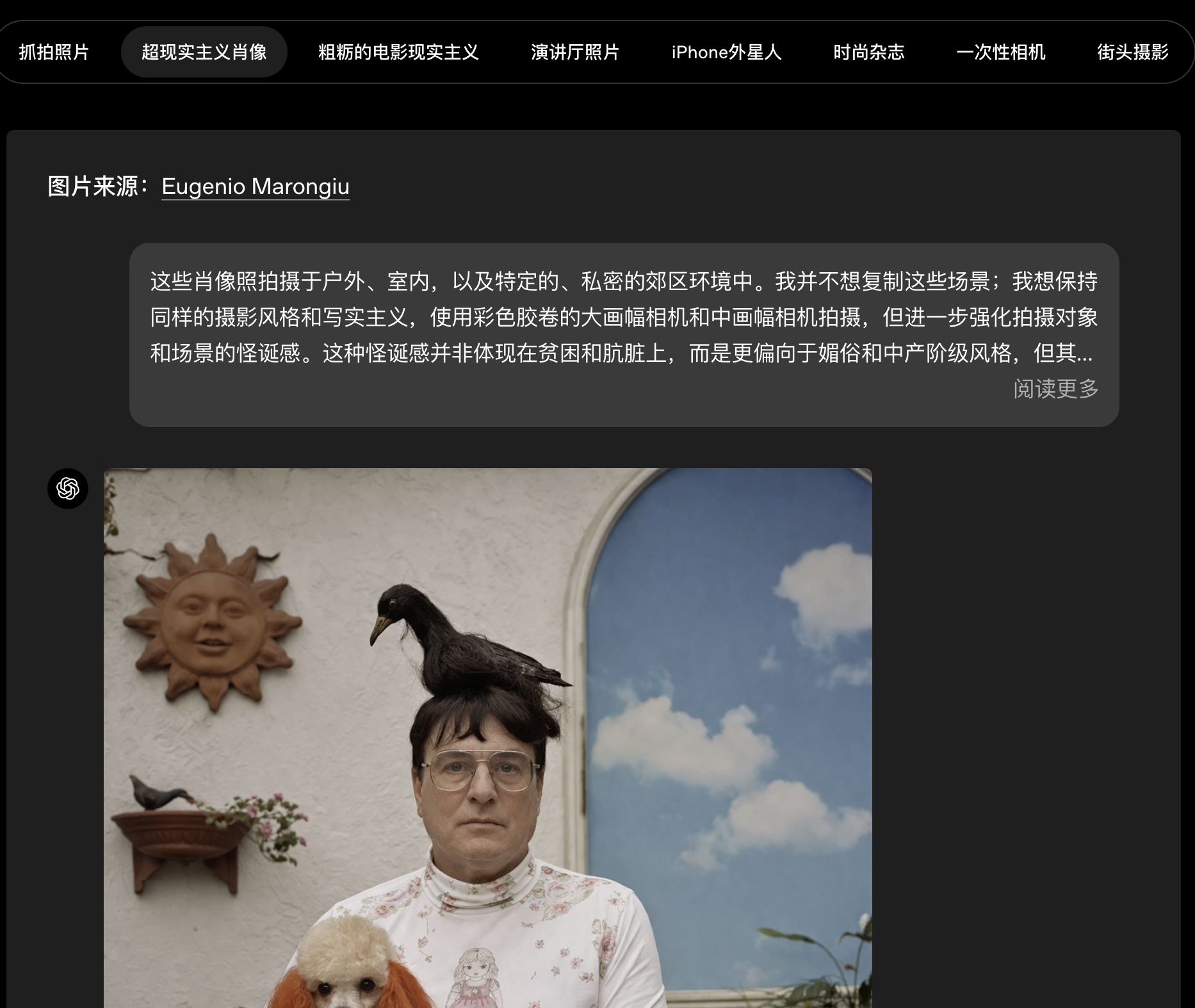
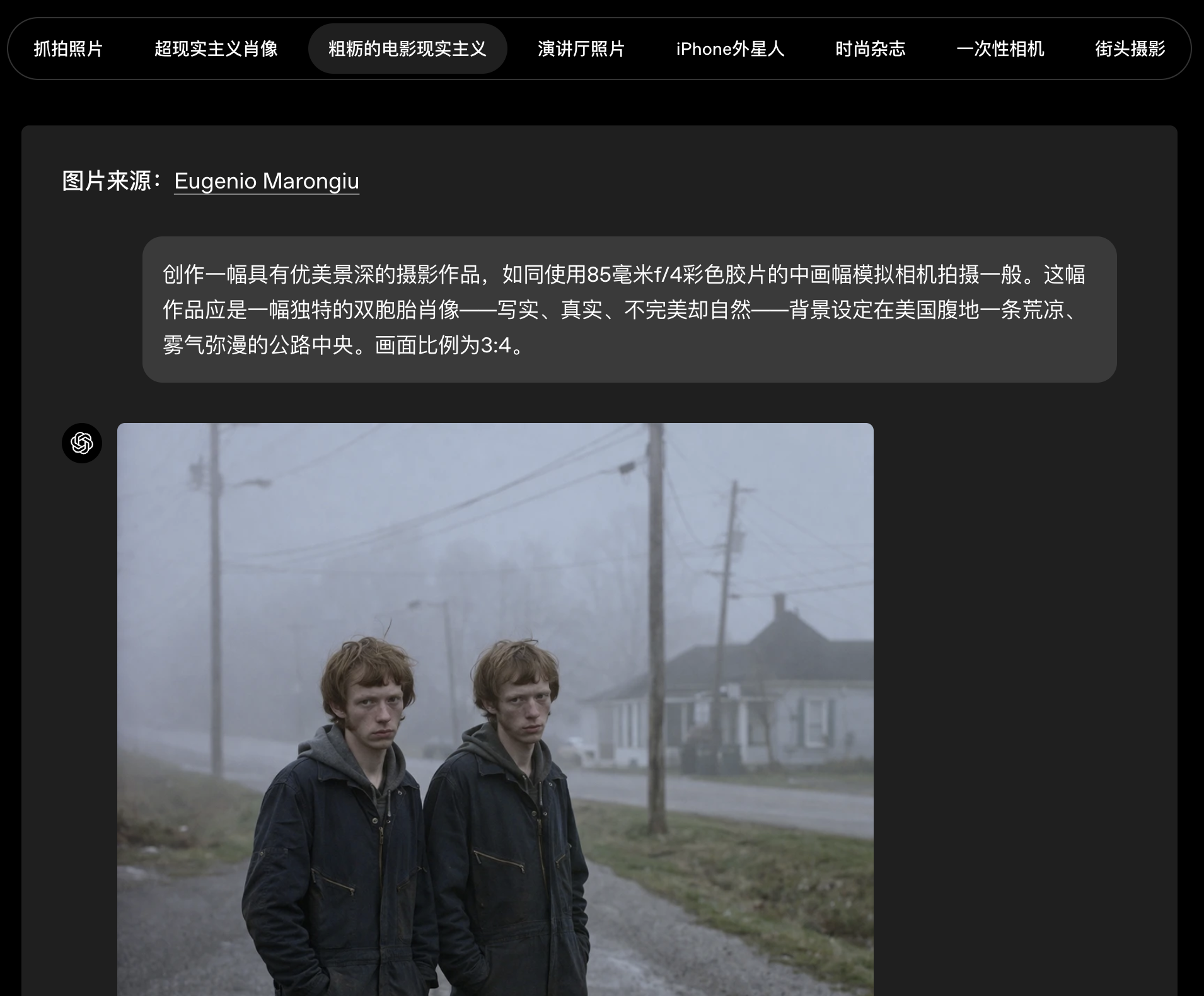
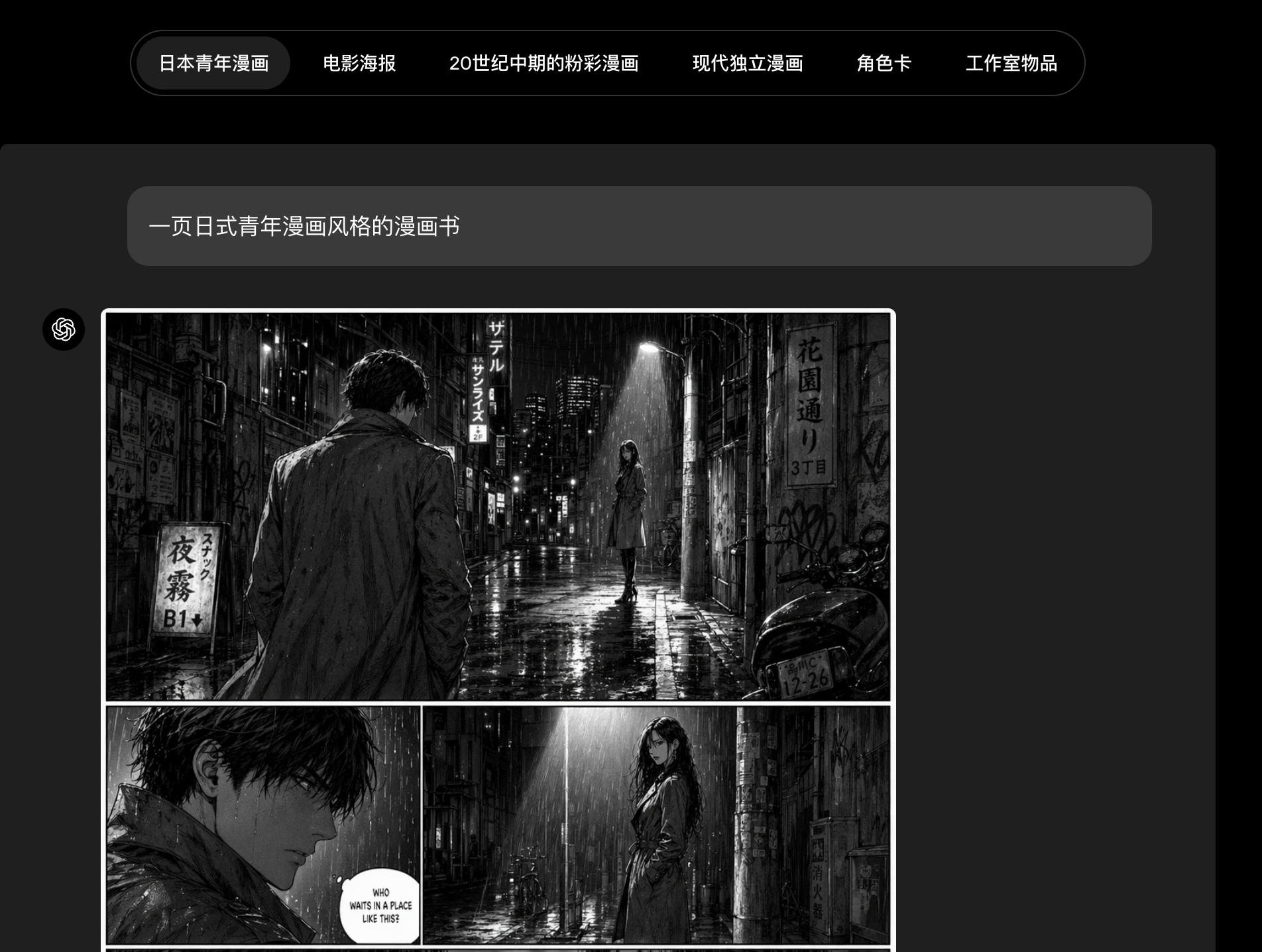
gpt-image-2在广泛的视觉风格中也展现出显著提升的保真度。它更擅长捕捉照片的决定性特征------包括那些增加真实感的细微瑕疵------同时也能更稳定地呈现电影剧照、像素艺术、漫画以及其他独特的视觉语言,在纹理、光线、构图和细节方面具有更高的一致性。
因此,这个模型能够生成更忠实于所要求风格的输出,而不只是对风格进行粗略模仿。这对于游戏原型设计、分镜脚本、营销创意,以及创建特定媒介或类型的素材尤其有用。
照片级真实感

风格

灵活的宽高比
新模型还让你在图像输出形式上拥有更大灵活性。支持从最宽 3:1 到最高 1:3 的宽高比,gpt-image-2能够生成适配你所需格式的输出,从横幅和演示文稿幻灯片,到海报、手机屏幕、书签和社交媒体图像。你可以在提示词中指定想要的宽高比,或者从预设选项中选择,将任意图像重新生成到新的尺寸。
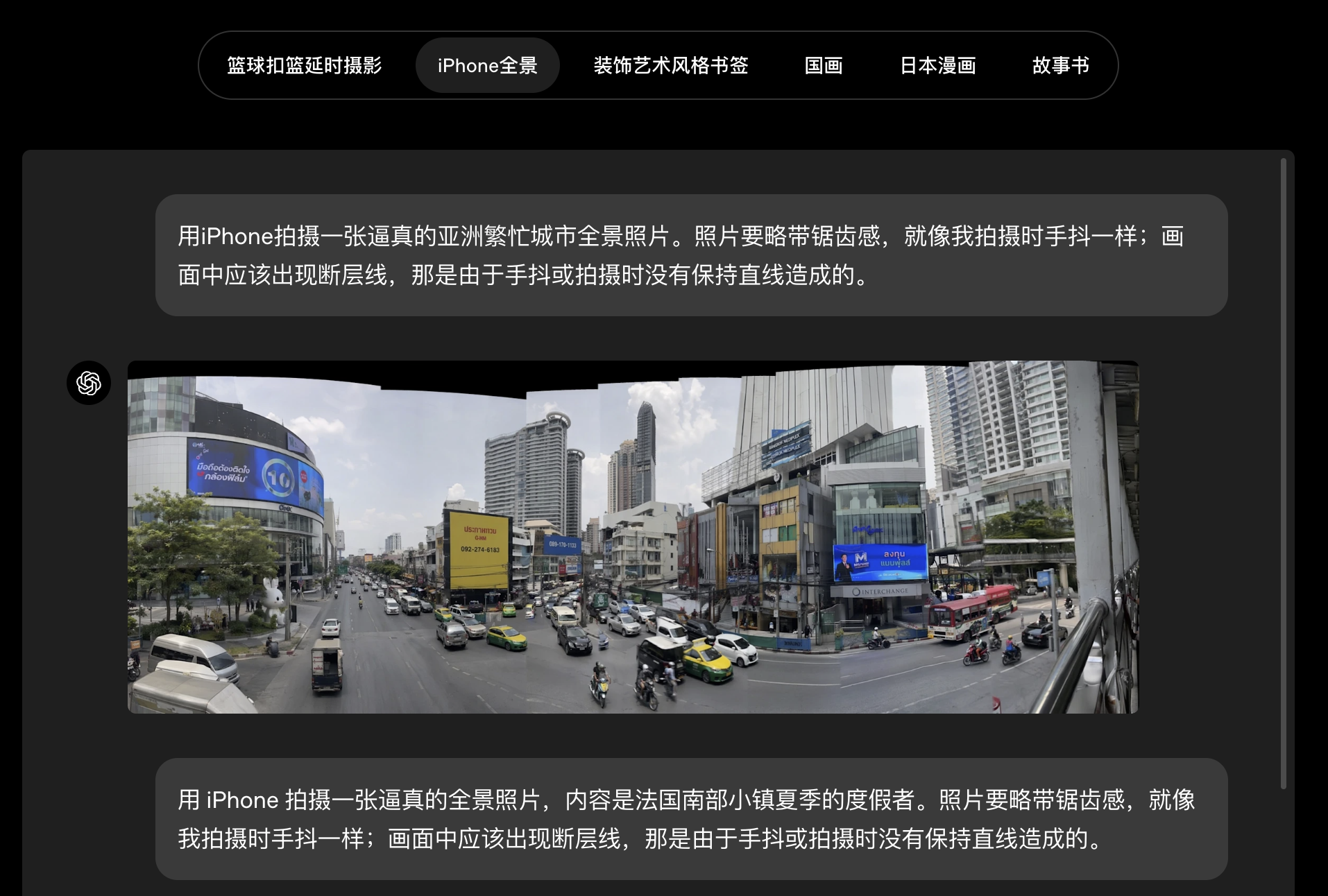
现实世界智能
Images 2.0 在图像创作中融入了对现实世界更及时的理解,知识截止日期为 2025 年 12 月,因此能够生成更贴切、更符合语境的结果。这对于说明图、教育图形和视觉摘要等内容尤其重要,因为这类内容中,正确性和清晰度与美观程度同样关键。
它的智能使其能够端到端地出色完成任务:综合信息、撰写内容,并以清晰的结构、有意留白和强烈视觉流动感完成排版。
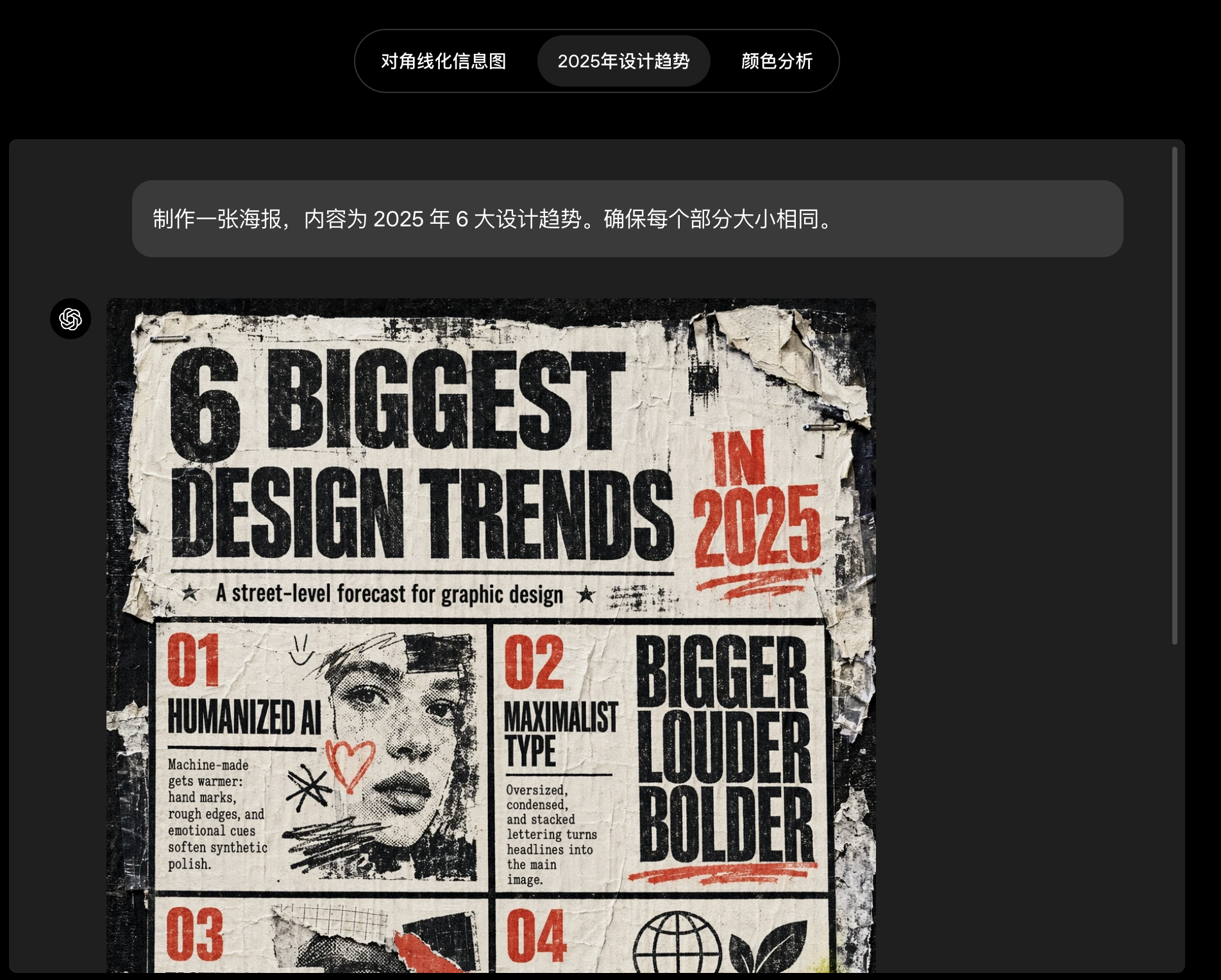
一个视觉思考伙伴
当你在 ChatGPT 中选择 thinking 模型时,模型会花更多时间,并在幕后以更强的自主性来充分理解和执行任务。它可以联网查找相关信息,把上传的材料转化为清晰的视觉说明图,并在生成前先推理图像结构。在这种模式下,gpt-image-2更像一个视觉思考伙伴,帮助你以明显更少的工作量,把项目从粗略概念推进到最终成品。
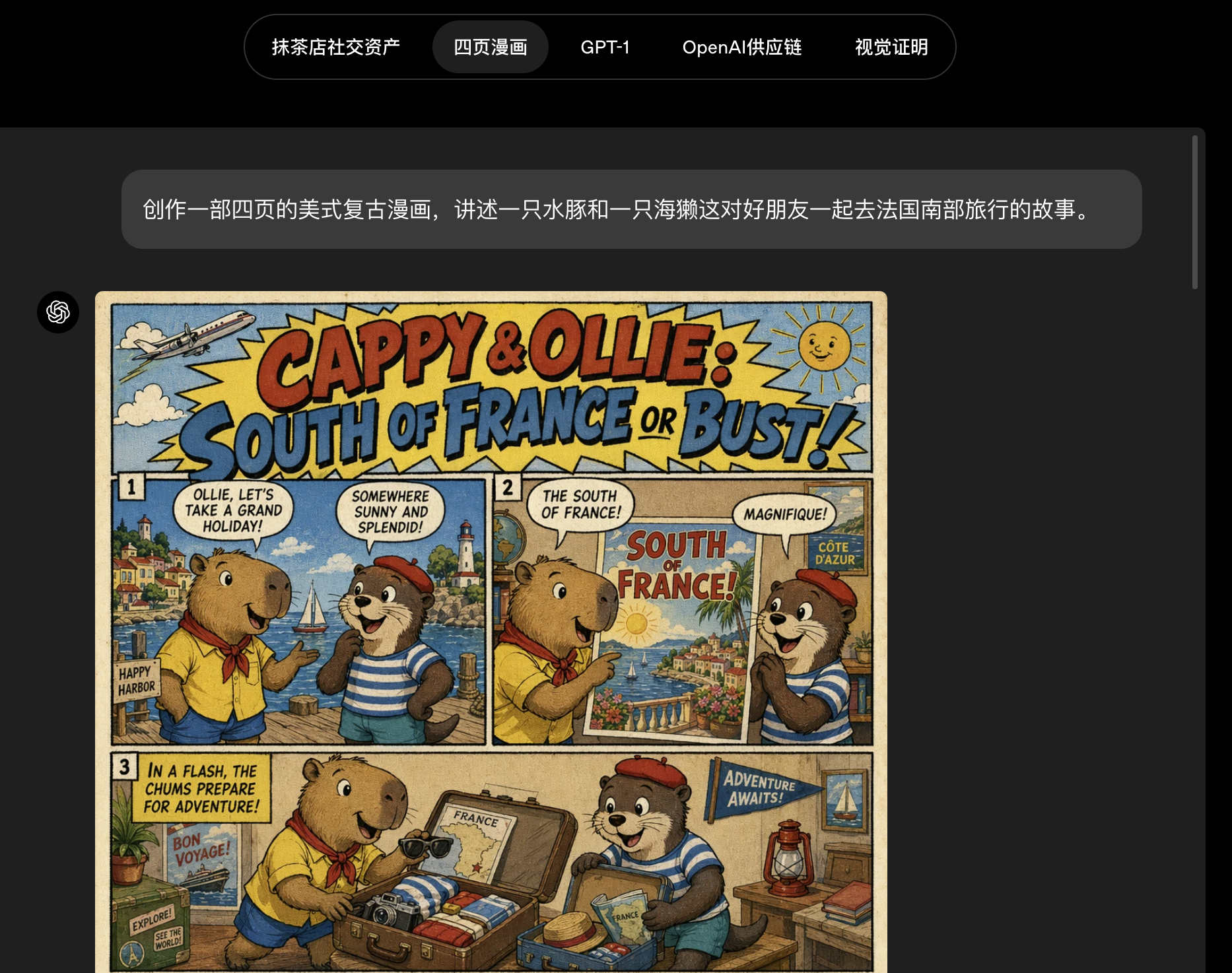
借助思考能力,它还可以一次生成多张彼此不同的图像,这是 ChatGPT 图像生成中的首次。这开启了此前很麻烦的工作流:连续的漫画页面、一整套房屋各房间改造方向、一组海报概念,或是一系列具有不同宽高比和语言版本的社交媒体图形。
你不再需要一次只提示一张图、然后自己把整个项目拼接起来;你可以一次性要求最多八个彼此连贯的输出,在角色和物体上保持连续性,并让它们按顺序逐步展开。
在 Codex 中使用图像生成
Codex 中的图像功能将视觉创作带入一个统一工作空间,用于创建、迭代和交付应用、幻灯片以及其他作品,使 Codex 在设计、营销、产品、销售以及学习与发展等更广泛任务上更有用。
例如,你可以生成多个 UI 方向、概念和原型,快速比较不同选项,然后无需离开 Codex 应用,就能把最强的想法变成真实产品或网站体验。你可以使用自己的 ChatGPT 订阅在 Codex 中创建图像,而不必单独创建 API 密钥。
通过 API 中的 gpt-image-2 将图像能力集成到你的产品中
开发者和企业可以通过 API 中的 gpt-image-2,将这些同样的能力带入他们正在开发的产品中,为其已有工作流加入高质量的图像生成与编辑能力。
借助更强的文本渲染、多语言生成、改进的指令遵循能力,以及对更多输出格式和宽高比的支持,API 让构建适用于真实商业场景的图像工作流变得更容易,例如本地化广告、信息图、说明图、教育内容、设计工具、创意平台和网页创建产品。
以下是客户对在生产工作流中使用 gpt-image-2 的反馈,这些工作流涵盖视觉叙事、设计软件、网站创建和创意自动化:

局限性
ChatGPT Images 2.0 是一次重大进步,但它并不完美。它仍然可能在需要完整而连贯的物理世界模型的任务上遇到困难,例如折纸指南、像魔方这样的谜题,以及那些需要在隐藏表面、倾斜表面或反向表面上正确出现的细节。非常密集或重复的视觉细节------例如细小的沙粒------也可能会触及模型能力的边界。标签和图表在准确性上仍可能需要人工审查,尤其是当它们依赖精确箭头或部件标注时。我们将这些限制视为未来工作的重要前沿。
在 API 中,超过 2K 的输出目前仍处于测试阶段,在某些情况下可能会产生不一致的结果。
定价与可用性
gpt-image-2从今天起已向所有 ChatGPT 和 Codex 用户开放。带有 thinking 的高级输出则面向 ChatGPT Plus、Pro 和 Business 用户提供。
gpt-image-2 模型已在 API 中可用;其定价会根据所选图像质量和分辨率而有所不同。
GPT-image-2官方价格
图像:
$8.00(输入)
$2.00(缓存输入)
$30.00(输出)
文本:
$5.00(输入)
$1.25(缓存输入)
$10.00(输出)
神马中转API价格
神马中转API请求GPT-image-2示例:
import http.client
import json
conn = http.client.HTTPSConnection("api.openai.com")
payload = json.dumps({
"model": "gpt-image-2",
"prompt": "生成一只猫",
"size": "1024x1024"
})
headers = {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
}
conn.request("POST", "/v1/images/generations", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))也可以去机灵助手小程序免费测试使用
总体来看,ChatGPT Images 2.0 的意义并不只是"图像生成效果更好了",而是在于它进一步缩短了想法与成品之间的距离。它让图像不再只是最后一步的输出,而是成为思考、表达、沟通与构建过程中的一部分。无论是快速验证创意、制作多语言视觉内容,还是将图像能力集成进产品和工作流中,这一代模型都展现出了更高的实用性与更强的生产价值。
当然,它仍然存在一些边界和限制,尤其是在复杂物理结构、极高密度细节和精确标注等方面,依旧需要人工校对与判断。但正因为如此,它更适合作为一个强大的"视觉协作伙伴"来使用。随着模型能力持续提升,未来的图像生成将不只是辅助设计,而会越来越深入地参与到完整的创作与产品生产体系之中。