
🦌云深麋鹿
专栏 :C++ | 用C语言学数据结构 | Java

回顾:上一篇我们结束了 容器stack&queue,接下来这篇文章让我们进入到新的内容 模板 的学习,体会新的设计思路吧~
放个目录
- [一 泛型编程](#一 泛型编程)
-
- [1.1 原先写Swap函数](#1.1 原先写Swap函数)
- [1.2 泛型编程](#1.2 泛型编程)
- [二 函数模板](#二 函数模板)
-
- [2.1 给编译器一个函数模板](#2.1 给编译器一个函数模板)
- [2.2 C++库里也有实现swap函数](#2.2 C++库里也有实现swap函数)
- [2.3 函数模板的实例化](#2.3 函数模板的实例化)
-
- [2.3.1 隐式实例化](#2.3.1 隐式实例化)
- [2.3.2 显式实例化](#2.3.2 显式实例化)
- [2.4 模板参数的匹配原则](#2.4 模板参数的匹配原则)
-
- [2.4.1 非模板函数优先匹配](#2.4.1 非模板函数优先匹配)
- [2.4.2 指定调用模板函数](#2.4.2 指定调用模板函数)
- [2.4.3 模板函数更加匹配](#2.4.3 模板函数更加匹配)
- [三 类模板](#三 类模板)
-
- [3.1 stack类](#3.1 stack类)
- [3.2 类实例化](#3.2 类实例化)
-
- [3.2.1 int版](#3.2.1 int版)
- [3.2.2 double版](#3.2.2 double版)
- [3.3 成员函数声明和定义分离](#3.3 成员函数声明和定义分离)
- [四 非类型模板参数](#四 非类型模板参数)
- [五 模板的特化](#五 模板的特化)
-
- [5.1 函数模板特化](#5.1 函数模板特化)
-
- [5.1.1 使用场景](#5.1.1 使用场景)
- [5.1.2 注意点](#5.1.2 注意点)
- [5.2 类模板特化](#5.2 类模板特化)
-
- [5.2.1 全特化](#5.2.1 全特化)
- [5.2.2 偏特化](#5.2.2 偏特化)
- [5.2.3 统一测试](#5.2.3 统一测试)
- [5.2.4 可以对参数进行限制](#5.2.4 可以对参数进行限制)
- [六 必须用typename的场景](#六 必须用typename的场景)
-
- [6.1 写一个通用的Print函数](#6.1 写一个通用的Print函数)
-
- [6.1.1 尝试写一下](#6.1.1 尝试写一下)
- [6.1.2 为什么编译没通过?](#6.1.2 为什么编译没通过?)
- [6.1.3 总结](#6.1.3 总结)
- [七 模板分离编译](#七 模板分离编译)
-
- [7.1 什么是分离编译](#7.1 什么是分离编译)
- [7.2 为什么要分离编译?](#7.2 为什么要分离编译?)
- [7.3 (回顾)编译和链接过程](#7.3 (回顾)编译和链接过程)
-
- [7.3.1 预处理](#7.3.1 预处理)
- [7.3.2 编译](#7.3.2 编译)
- [7.3.3 汇编](#7.3.3 汇编)
- [7.3.4 链接](#7.3.4 链接)
- [7.4 模板声明和定义分离](#7.4 模板声明和定义分离)
-
- [7.4.1 为什么报错](#7.4.1 为什么报错)
- [7.4.2 解决方案](#7.4.2 解决方案)
- [八 总结](#八 总结)
-
- [8.1 优点](#8.1 优点)
- [8.2 缺陷](#8.2 缺陷)
一 泛型编程
1.1 原先写Swap函数
cpp
void Swap(int& n1,int& n2) {
int tmp = n1;
n1 = n2;
n2 = tmp;
}
void Swap(double& n1, double& n2) {
double tmp = n1;
n1 = n2;
n2 = tmp;
}
void Swap(char& n1, char& n2) {
char tmp = n1;
n1 = n2;
n2 = tmp;
}类似的代码,只是参数类型不同,我们却需要手动编写3次。
相对于泛型编程的不足:
- 新类型出现,需要自己手动添加对应的函数。
- 代码的可维护性低,一个函数错了,其他函数大概率也要改。
1.2 泛型编程
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。
模板是泛型编程的基础,我们接下来介绍模板。
二 函数模板
2.1 给编译器一个函数模板
上代码:
cpp
template<typename T>
void Swap(T& t1,T& t2) {
T tmp = t1;
t1 = t2;
t2 = tmp;
}我们在函数前加上 template ,后续就可以一个T走天下了。
== typename 是定义模板参数的关键字,也可以使用 class(但是不能用struct)==
测试:
cpp
int t1 = 1;
int t2 = 2;
cpp
Swap(t1, t2);
当我们要调用这个Swap函数的时候,根据实参不同,编译器会调用对应版本的Swap函数。
2.2 C++库里也有实现swap函数
cpp
using namespace std;
int main(){
int t1 = 1;
int t2 = 2;
swap(t1,t2);
return 0;
}2.3 函数模板的实例化
函数模板的实例化:用不同类型的参数使用函数模板。
2.3.1 隐式实例化
编译器根据实参推演T。
cpp
T Add(T t1,T t2) {
return t1 + t2;
}
int main() {
int t1 = 1;
int t2 = 2;
cout << Add(t1, t2) << endl;
return 0;
}编译器推演出T为int类型,自动调用int版本Add函数。
运行结果符合预期:

2.3.2 显式实例化
有些情况下,编译器无法推演出T是什么类型:
cpp
int t1 = 1;
double t2 = 2.1;
cout << Add(t1, t2) << endl;编译器报错:

这个时候需要我们显式实例化:
cpp
cout << Add<int>(t1, t2) << endl;运行结果符合预期:

2.4 模板参数的匹配原则
场景:同名 函数模板 和 非模板函数 同时存在。
2.4.1 非模板函数优先匹配
cpp
int Add(int n1, int n2) {
return n1 + n2;
}
int main() {
int t1 = 1;
int t2 = 2;
cout << Add(t1, t2) << endl;
return 0;
}调试:

可以看到调用了我们自己实现的int版本Add函数。
2.4.2 指定调用模板函数
cpp
cout << Add<int>(t1, t2) << endl;调试:
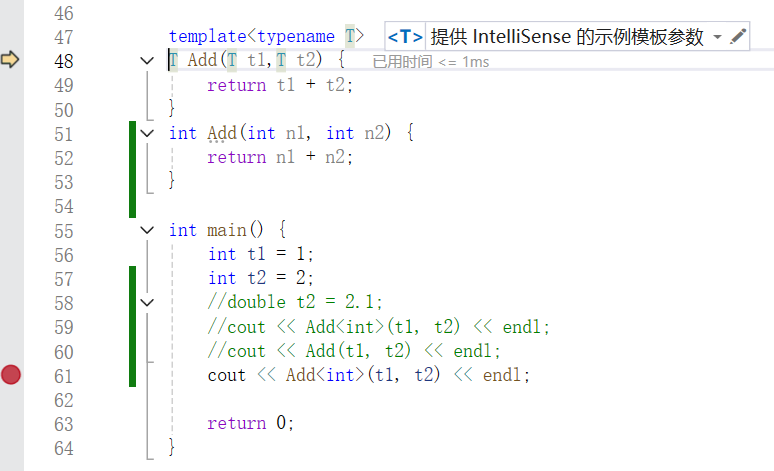
可以看到调用了模板函数。
2.4.3 模板函数更加匹配
cpp
double t1 = 1.1;
double t2 = 2.1;
cout << Add(t1, t2) << endl;t1,t2都是double,我们的自定义Add不适配。
调试:

可以看到调用了更加适配的模板函数。
运行结果:

三 类模板
3.1 stack类
cpp
template<class T>
class Stack {
public:
Stack(size_t capacity = 4) {
_arr = new T[capacity];
_capacity = capacity;
_top = 0;
}
void Push(const T& data);
// ...
~Stack() {
delete[] _arr;
_capacity = _top = 0;
}
private:
T* _arr;
size_t _capacity;
size_t _top;
};跟模板函数类似的写法,在Stack类里,把arr元素类型换成通用类型T。
3.2 类实例化
类模板基本都是显式实例化。
3.2.1 int版
cpp
Stack<int> st1;
st1.Push(1);调试:
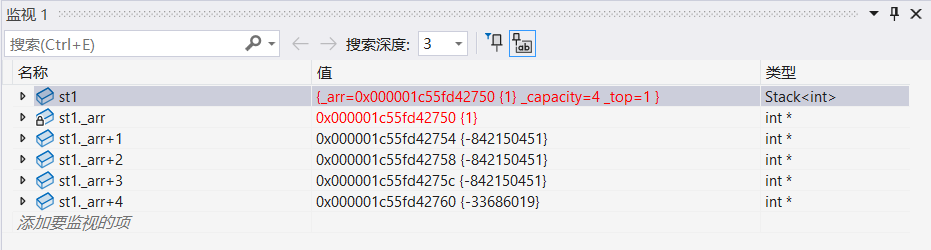
3.2.2 double版
cpp
Stack<double> st2;
st2.Push(1.1);调试:
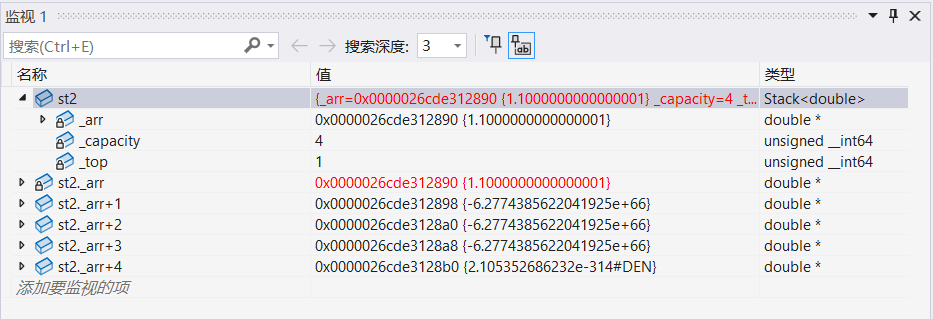
3.3 成员函数声明和定义分离
上面没有给出Push函数的定义:
cpp
template<class T>
void Stack<T>::Push(const T& data) {
if (_top == _capacity) {
// 扩容
exit(1);
}
_arr[_top++] = data;
}现在我把这段代码放到cpp文件里。
四 非类型模板参数
4.1 使用场景
cpp
#define N 100;
template<class T>
class myArray {
public:
//...
private:
T _arr[N];
size_t _size;
};宏函数不能适应所有需求,不可能所有需要的array都是100容量的。
所以我们加一个模板参数:
cpp
template<class T,size_t N = 10>4.2 库内实例:array

4.2.1 越界检查
array越界检查更加严格。
(1)原生数组
①越界读
cpp
char str[] = "hello world";
cout << str[15] << endl;运行,什么都不输出:

②越界写
cpp
char str[] = "hello world";
str[15] = 'a';编译报错:
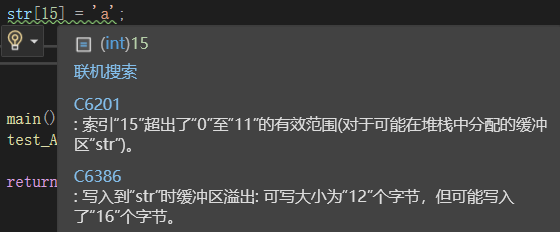
(2)array
①越界读
cpp
array<int, 5> arr = { 1,2,3,4,5 };
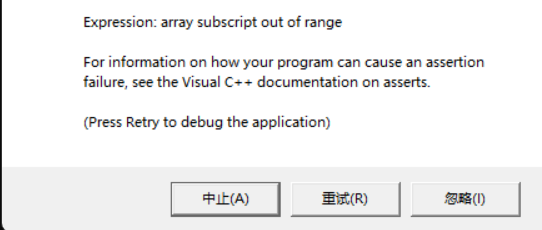
cout << arr[5] << endl;编写完就有报错了:

运行崩了:
②越界写
cpp
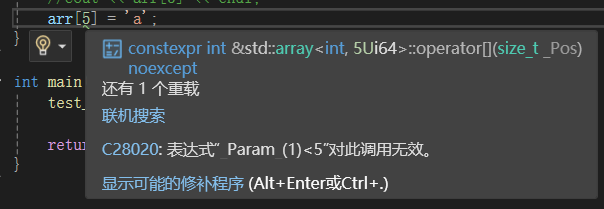
array<int, 5> arr = { 1,2,3,4,5 };
arr[5] = 'a';一样:
4.3 注意点
非类型模板参数的类型有要求:

五 模板的特化
5.1 函数模板特化
5.1.1 使用场景
cpp
template<typename T>
bool myLess(T a,T b) {
return a < b;
}测试代码:
cpp
int a = 2;
int b = 1;
cout << wyzy::myLess(a, b) << endl;
cout << wyzy::myLess(&a, &b) << endl;运行:

这里遇到特殊情况,比较的是指针。
可以特殊处理:
cpp
template<>
bool myLess<int*>(int* a, int* b) {
return *a < *b;
}使用场景不是很多,更推荐推荐函数重载
5.1.2 注意点
- 不能漏掉上面的template<>。
- 这个 函数形参类型 必须属于 模板形参类型 那一类。
cpp
template<typename T>
bool myLess(T& a, T& b) {
return a < b;
}
template<>
bool myLess<int*>(int* a, int* b) {
return *a < *b;
}这样就会报错:

- 遇到指针的话,要注意const放的位置。
cpp
template<typename T>
bool myLess(const T a, const T b) {
return a < b;
}
template<>
bool myLess<int*>(int* const a, int* const b) {
return *a < *b;
}5.2 类模板特化
先写个类模板:
cpp
template<typename T1, typename T2>
class myAa {
public:
myAa() {
cout << "original template" << endl;
}
private:
T1 A;
T2 a;
};5.2.1 全特化
就是模板参数全都确定化:
cpp
template<int, double>
class myAa {
public:
myAa() {
cout << "full specialization" << endl;
}
private:
int A;
double a;
};5.2.2 偏特化
特化部分模板参数:
cpp
template<typename T1,int>
class myAa {
public:
myAa() {
cout << "partial specialization" << endl;
}
private:
T1 A;
int a;
};5.2.3 统一测试
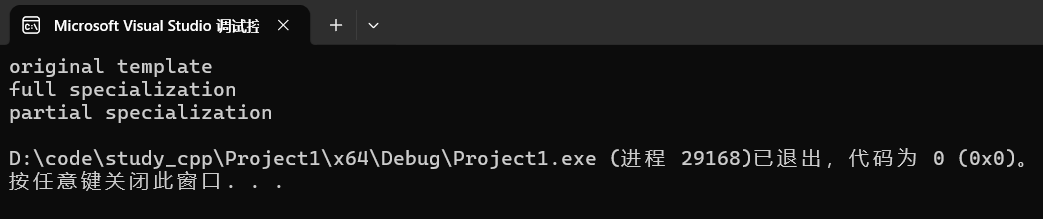
cpp
wyzy::myAa<char, char> aa1;
wyzy::myAa<int, double> aa2;
wyzy::myAa<char, int> aa3;运行:
5.2.4 可以对参数进行限制
针对指针场景:
cpp
template<typename T1, typename T2>
class myAa<T1*,T2*> {
public:
myAa() {
cout << "limit parameter" << endl;
}
private:
T1 A;
T2 a;
};测试:
cpp
wyzy::myAa<int*, int*> aa4;运行:

六 必须用typename的场景
6.1 写一个通用的Print函数
6.1.1 尝试写一下
- 借助迭代器。
cpp
template<class Container>
void Print(const Container& con) {
Container::const_iterator it = con.begin();
for (; it != con.end(); ++it) {
cout << *it << " ";
}
cout << endl;
}6.1.2 为什么编译没通过?

cpp
Container::const_iterator it = con.begin();问题在于这行代码。
- 编译器不清楚是静态成员变量还是类型。
- 注意要在前面加typename,告诉编译器这是个类型。
6.1.3 总结
只要是从模板参数里取类型,都要加typename。
cpp
typename Container::const_iterator it = con.begin();七 模板分离编译
7.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
7.2 为什么要分离编译?
- 编译速度:改一个源文件,只重编这一个就行。
- 降低耦合:多个源文件分离,有问题改其中一个源文件就行。
- 保护源码:头文件放声明,源文件放实现。可以保护源码实现细节。
- 方便看代码:头文件看声明,源文件看实现,清晰明了。
7.3 (回顾)编译和链接过程
7.3.1 预处理
- 展开头文件,宏替换。
- 处理以#开头的指令,条件编译(方便版本控制,多平台兼容)。
- 删除注释。
- 从 .cpp文件 到 .i文件。
7.3.2 编译
- 检查 预处理后的代码 的语法。
- 生成汇编代码(符号指令)。
- 从 .i文件 到 .s文件。
7.3.3 汇编
- 汇编代码转二进制机器码。
- 从 .s文件 到 .o文件。
7.3.4 链接
- 符号解析:将多个目标文件和库文件合并。
- 重定位:为符号分配最终的内存地址。
- 地址绑定:修正代码中的地址引用。
- 生成 .exe可执行文件。
链接报错
一般是因为只有声明,没有定义。
7.4 模板声明和定义分离
7.4.1 为什么报错
我们分离到俩文件。
头文件:
cpp
template<class T>
void Print(T t);实现文件:
cpp
template<class T>
void Print(T t) {
cout << t << endl;
}测试文件:
cpp
int main() {
Print(1);
return 0;
}报错:
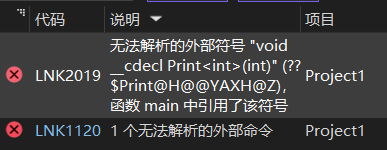
因为模板没有实例化。
- 定义的地方不知道实例化成什么类型,无法生成对应函数的指令。
- 调用的地方知道什么类型,但是没有定义。
7.4.2 解决方案
(1)显式实例化
但是太麻烦了,不推荐。
(2)声明和定义在同一个头文件
直接定义,或者声明和定义分离在同一个头文件。
cpp
template<class T>
void Print(const T& t);
template<class T>
void Print(const T& t) {
//...
}为什么这样可以解决问题?
调用的时候,直接就可以实例化出来。
编译的时候就能确定函数地址。
八 总结
8.1 优点
- 复用代码,节省资源,迭代开发效率更高。
- 增强代码的灵活性。
8.2 缺陷
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误。
模板 的学习就到这里,下一篇我们就要开始学习C++面向对象的特性啦,今天一起更出来~

