在学习HTTP 协议时,一直是在应用层,接下来我们继续向下,学习传输层的协议。传输层最具代表的协议:UDP和TCP。
1. UDP 协议
1. 端口号 port
端口号 port 标识主机上进行通信的不同的应用程序。
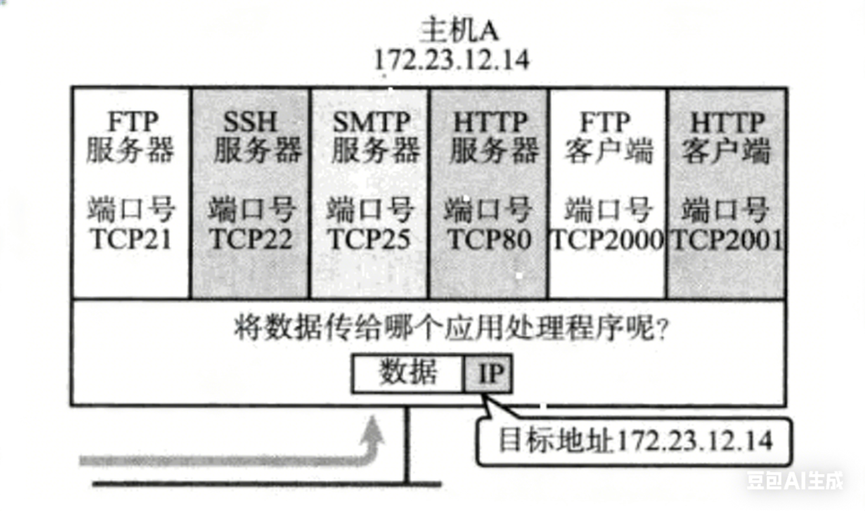
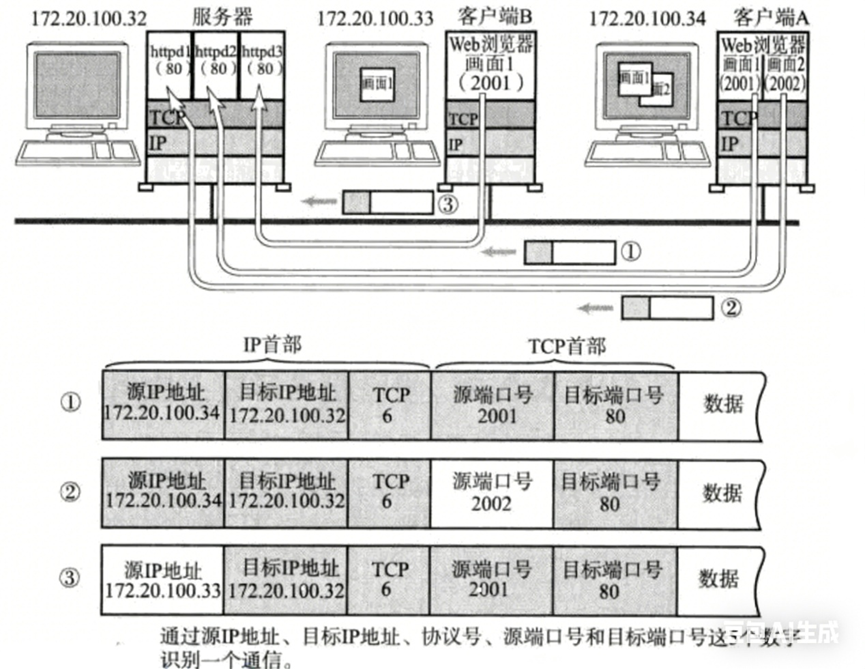
在TCP/IP协议中,用"源IP","源端口号","目的IP","目的端口号","协议号"这样一个五元组来标识一个通信(可以通过netstat-n查看)。
端口号范围划分:
0-1023:知名端口号,HTTP,FTP,SSH等这些广为使用的应用层协议,它们的端口号都是固定的。
1024-65535:操作系统动态分配的端口号。客户端程序的端口号,就是由操作系统从这个范围分配的
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下这些固定的端口号:
ssh 服务器 ------ 使用22端口
ftp 服务器 ------ 使用21端口
telnet 服务器 ------ 使用23端口
http 服务器 ------ 使用80端口
https 服务器 ------ 使用443端口
有关端口号的问题
一个端口号是否可以被多个进程绑定?不能,因为端口号是一个key值,它需要标识进程的唯一性。
一个进程是否可以绑定多个端口号?可以。端口号对进程是1对1,进程对端口号可以是1对多。
2. UDP 协议的格式
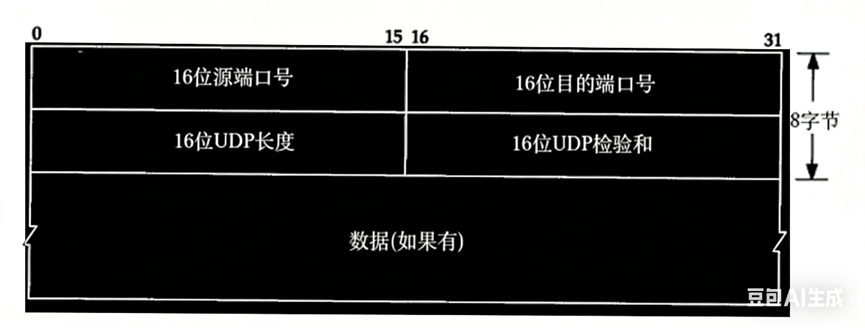
UDP 协议整个报头部分分为5个区域。数据部分就是从应用层获取到的数据。UDP协议规定端口号是16位的(0-65535)。
协议的两个核心问题
问题1:报头和有效载荷如何分离?
| 协议 | 分离机制 |
|---|---|
| HTTP | 根据空行(\r\n\r\n)分离请求行/头部和正文 |
| UDP | 固定长度报头 (8字节),无需额外分隔符 |
UDP的具体做法:
- 报文前8个字节固定为UDP报头
- 报头中的len字段(16位UDP长度)表示整个报文的长度
- 通过len - 8即可准确计算数据部分长度
问题2:有效载荷如何分用(交付给上层)?
| 协议 | 分用机制 |
|---|---|
| HTTP | 反序列化后交给应用层处理 |
| UDP | 根据报头中的16位目的端口号(dest),确定交付给哪个进程 |
延申出的问题:
问题1:UDP是否存在粘包问题?不存在。
UDP协议设计时就是用户数据报协议 。每个UDP报文都是独立的、边界明确的 :每次 recvfrom 返回一个完整的UDP数据报,不会出现TCP那种"读一半"或"多读"的情况。
问题2:如何理解UDP报头?
UDP报头本质就是一个C语言结构体,如下所示:
cpp
struct udphdr {
__u16 source; // 源端口
__u16 dest; // 目的端口
__u16 len; // 总长度
__u16 check; // 校验和
};是否需要序列化/反序列化?不需要。 UDP传输层属于操作系统内核 ,通信双方(内核之间)可以直接传递结构体变量。序列化/反序列化是应用层为了跨平台/跨语言通信才需要的。
问题3:如何理解报文封装过程?
封装的本质:指针移动 + 结构体拷贝。
用户缓冲区(应用层数据)
↓ 拷贝到内核缓冲区(中间位置)
预留报头空间 \| 应用层数据
↑ data指针 ↑ tail指针
向下交付到UDP层:
data指针向左移动8字节(报头长度)
填充struct udphdr到预留空间
封装就是对结构体变量进行拷贝,填充到预留的报头空间。
问题4:如何理解报文的内核管理?
OS内部存在海量报文,管理原则:先描述,再组织。真正的报文 = struct sk_buff(管理结构)+ 报文数据。
struct sk_buff关键字段:
cpp
struct sk_buff {
unsigned char *head, // 缓冲区起始
*data, // 有效数据起始(可移动)
*tail, // 有效数据结束
*end; // 缓冲区结束
// ... 其他管理字段
};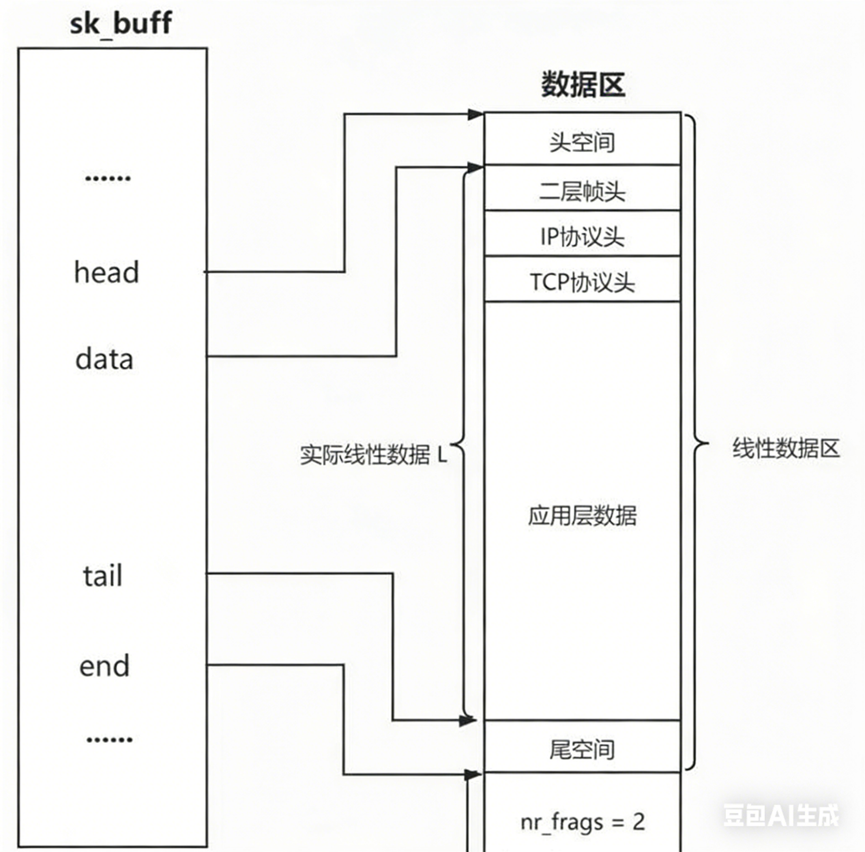
四个指针的作用:
- head/end:标记整个缓冲区的边界(固定)
- data/tail:标记当前有效数据的边界(移动)
封装/解包的核心就是移动data指针:
- 封装(向下层): data指针向上(低地址)移动,留出报头空间
- 解包(向上层): data指针向下(高地址)移动,跳过报头
报文贯穿协议栈的过程,就是data指针不断移动的过程。
问题5:如何用文件原理读取数据到应用层?
结构体关联链:
struct socket(VFS层)
├── struct file *file ←→ 关联文件描述符fd
├── wait_queue_head_t wait // 阻塞进程等待队列
└── struct sock *sk // 指向具体协议结构(多态基类指针)
↓
struct inet_sock(INET层,继承自sock)
├── struct sock sk // 基类嵌入
├── __u32 daddr/rcv_saddr // 目的/源IP
├── __u16 dport/num // 目的/源端口
└── struct sock *sk → 指向...
↓
struct udp_sock(UDP专用,继承自inet_sock)
├── struct inet_sock inet // 基类嵌入
└── __u16 len // 待发送数据总长度
示意图:
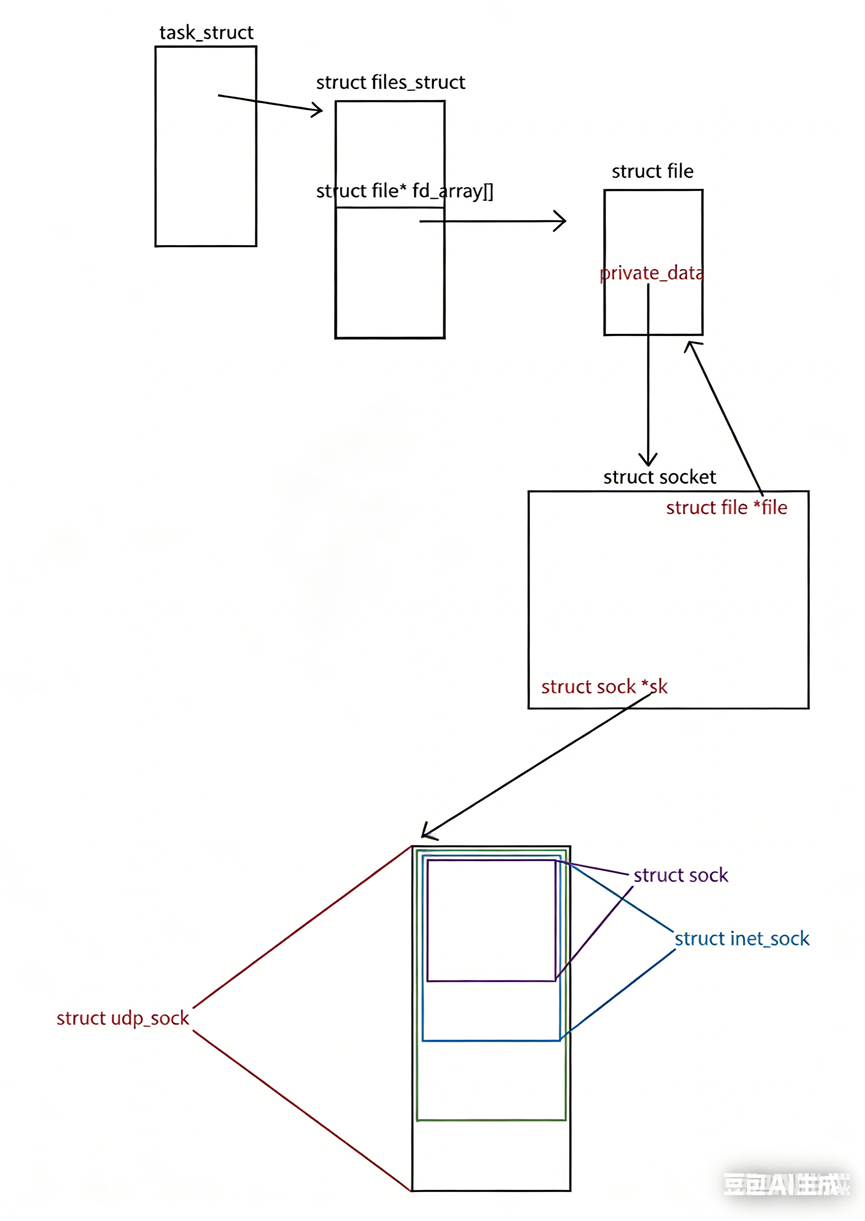
多态实现: struct sock *sk是基类指针,指向udp_sock/tcp_sock等派生类,实现不同协议的分发处理。
接收队列: sk_receive_queue(struct sk_buff_head)管理所有待读取的报文。
文件原理读取:
- 用户read/recvfrom → 查fd表 → 找到struct file
- struct file → private_data → struct socket
- socket → sk → 协议专用结构
- 从sk_receive_queue取sk_buff,拷贝数据到用户空间
3. UDP
UDP的特点总结
| 特性 | 说明 |
|---|---|
| 无连接 | 知道对端IP和端口就直接传输,无需建立连接(像寄信) |
| 不可靠 | 无确认机制、无重传机制;丢包后协议层不通知应用层 |
| 面向数据报 | 应用层给多少,UDP发多少;不拆分、不合并 |
用 UDP传输100个字节的数据:如果发送端调用一次 sendto,发送100个字节,那么接收端也必须调用对应的一次 recvfrom,接收 100 个字节;而不能循环调用10次 recvfrom,每次接收10个字节。
既然 udp 协议都不可靠了,为什么还要有它呢?
不可靠并不是说,数据传不过去,只是在传输过程中,对于丢包了不关心。在传输过程中,丢包发生的概率很低。udp不可靠,并不代表它不能用。
| 角度 | 说明 |
|---|---|
| 丢包概率 | 现代网络丢包率很低,UDP简单高效 |
| 实时性 | 视频通话、游戏等场景,重传延迟比丢包更可怕 |
| 轻量级 | 无需维护连接状态,资源消耗极低 |
| 灵活性 | 应用层可自行实现可靠性(如QUIC基于UDP) |
UDP的缓冲区机制
| 缓冲区 | 存在性 | 特点 |
|---|---|---|
| 发送缓冲区 | 无真正意义上的发送缓冲区 | 调用sendto直接交给内核,立即返回 |
| 接收缓冲区 | 有 | 不保证接收顺序与发送顺序一致;满了则丢弃新数据 |
全双工: UDP 的 socket 既能读也能写,同时支持收发。
UDP使用注意事项
16位长度字段的限制:
- UDP首部中len字段是16位无符号整数
- 最大长度 = 64K(65535字节),包含UDP首部
- 有效数据最大 = 64K - 8 = 65527字节
现代互联网的挑战:
- 64K在当今是非常小的数字(高清图片几MB,视频流更大)
- 超过64K的解决方案: 应用层手动分包 → 多次发送 → 接收端手动拼装
注意: 实际中还需考虑MTU限制(以太网通常1500字节),过大的UDP包会在IP层分片,增加丢包风险。
2. TCP 协议
TCP协议全称"传输控制协议"。
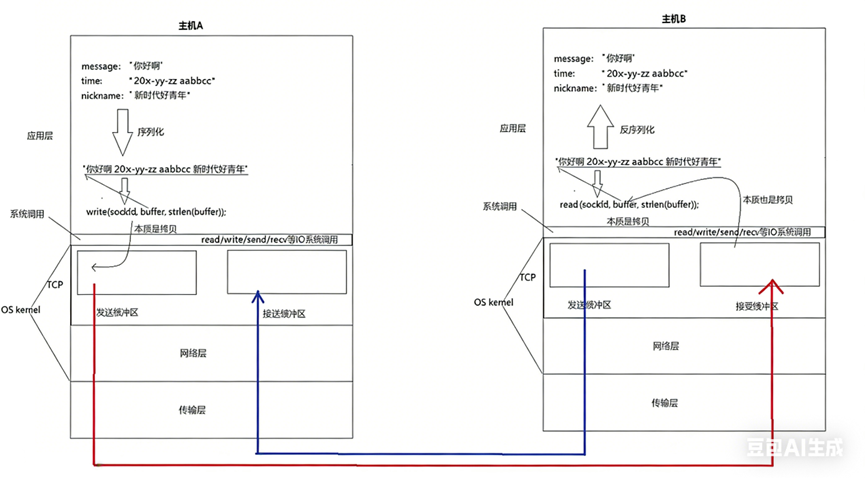
应用层将报文序列化形成字节流,通过write/send拷贝到内核发送缓冲区后,数据何时发送、发送多少、出错如何处理,完全由TCP协议自主控制------这正是"传输控制"的核心含义。
1. TCP 报文的格式
TCP报头本质上是C语言结构体 struct tcphdr,网络字节序统一采用大端序,主机通过ntohs/ntohl进行转换。struct tcphdr 源码如下所示:
cpp
struct tcphdr {
__u16 source;
__u16 dest;
__u32 seq;
__u32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
doff:4,
fin:1,
syn:1,
rst:1,
psh:1,
ack:1,
urg:1,
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__u16 window;
__u16 check;
__u16 urg_ptr;
};从源码可以看出,明显的区分了大小端问题。TCP报头就是上述的结构体。
- __u16 source 是源端口号 ,__u16 dest 是目的端口号,都是16位;
- __u32 seq 是序号 ,__u32 ack_seq 是确认序号,都是32位。
- __u16 window ------ 16位窗口大小;__u16 check ------ 16位检验和;__u16 urg_ptr ------ 16位紧急指针。
关于TCP协议的相关问题
TCP如何解决报头和有效载荷分离问题?
TCP 报文段由 固定+可变长度的头部 和 应用层数据(有效载荷) 组成。由于 TCP 支持选项字段(如 MSS、SACK、时间戳等),其头部长度是可变的(20~60 字节)。为实现精确解析,TCP 在报头中定义了 4 位的"首部长度"(Data Offset)字段。
- 该字段以 4 字节为单位 表示整个 TCP 头部的长度。
- 最小值为 5(对应 5 × 4 = 20 字节,即无选项的标准头部);
- 最大值为 15(对应 15 × 4 = 60 字节)。
- 接收方读取该字段后,乘以 4 即可得到实际头部字节数。
- 有效载荷起始位置 = TCP 段起始地址 + Data Offset × 4。
示例:若 Data Offset = 10,则头部长度为 40 字节,第 41 字节开始即为有效载荷。
因此,无需"有效载荷长度"字段------只要知道头部结束位置,剩余部分自然就是数据。
为何 TCP 报头中没有"有效载荷长度"字段?
这与 TCP 的面向字节流 设计密切相关:
UDP 是面向报文的:每个 UDP 数据报是独立、完整的消息,因此需要"总长度"字段来界定边界。
TCP 是面向字节流的:它不关心应用层如何划分消息(如 HTTP 请求、JSON 对象等),只负责将发送方写入的数据按序、无损地传递到接收方的缓冲区。应用层自行处理消息边界。
此外,一旦通过 Data Offset 硗定头部长度,剩余部分必然是有效载荷,再引入"payload length"会造成冗余且违背设计原则。
TCP 如何实现分用?
TCP 通过以下机制实现:
- 报头中包含 16 位目的端口号(Destination Port)。
- 内核维护一个 套接字(Socket)表,记录活跃连接或监听端口的信息。
- 对于监听状态的 socket(如 listen(80)),内核根据目的端口号匹配;
- 对于已建立连接的 socket,使用 四元组(源IP、源端口、目的IP、目的端口) 唯一标识连接,并据此路由数据。
示例:收到一个目的端口为 80 的 TCP 段 → 内核查找监听 80 端口的 Web 服务器进程 → 将数据放入其接收缓冲区 → 应用调用 recv() 获取。
2. 报头中的字段
1. 32位序列号(seq)
TCP被称为可靠协议,但我们必须正确认识"可靠性"的内涵。
主机A给主机B发送了一个报文,主机A无法100%确定主机B一定收到了。为此,TCP引入了确认应答(ACK)机制:主机B在收到报文后,必须向主机A发送一个应答报文。收到此应答,主机A便能100%确信其历史报文已被对方成功接收。
然而,这个过程似乎会陷入无穷递归:主机B如何确定自己的应答报文被主机A收到了呢?答案是:在互联网中,不存在100%可靠的协议 。最新的、尚未被确认的报文,其可靠性永远是未知的。但TCP的可靠性主要体现在对所有已确认的历史报文的100%送达保证上。
超时重传机制是ACK机制的必要补充。主机A在发出报文后会启动一个计时器。如果在规定时间内(RTO, Retransmission Timeout)未收到ACK,主机A便会判定报文(或ACK)丢失,并执行重传。这个"规定时间"是动态计算的,基于网络的实际往返时延(RTT)。
重传会带来一个问题:主机B可能会收到重复的报文。此时,32位序列号(seq) 就派上了用场。接收方通过检查序列号,可以轻松识别并丢弃重复的数据,确保向上层交付的数据流是唯一的。
看下图:
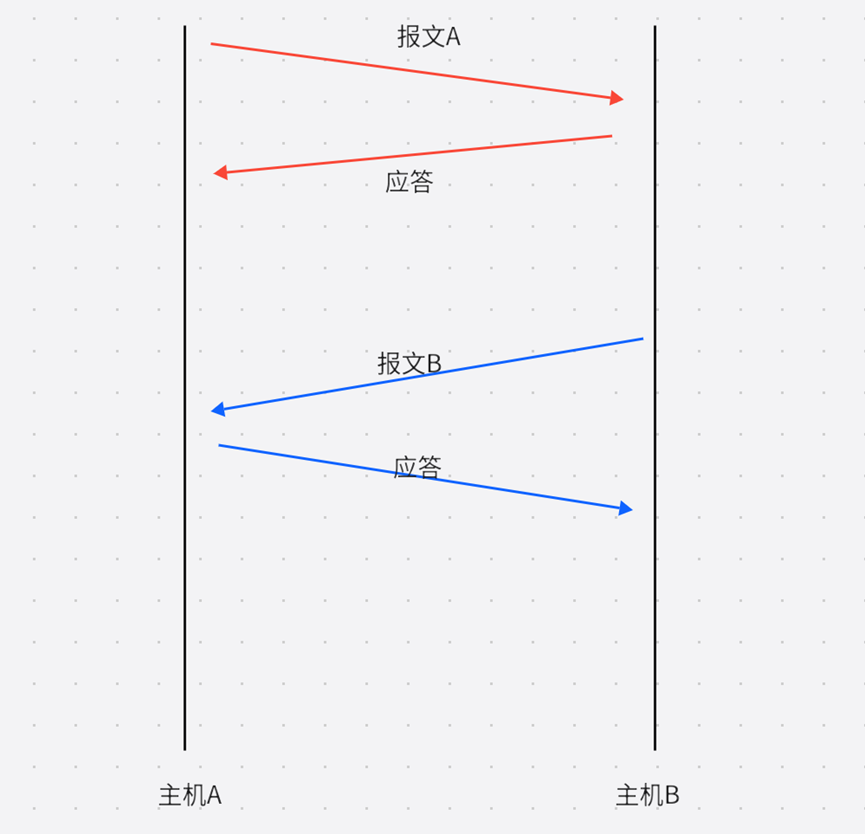
**我们将这种两个方向上的互发数据,对报文进行应答,保证报文本身的可靠性叫做确认应答机制。**确认应答机制保证可靠性,体现在"你收到了,我得知道"。"如果你没有收到,我也得知道"。
主机A没有收到主机B的应答需要分情况考虑:
- 报文真的丢了;
- 主机B收到报文了,但是发送给主机A的应答报文丢了。
主机A没有收到应答,它会判定报文丢失了。但是A怎么知道自己会不会收到应答呢?收到应答是一个100%确定的事,没有收到应答怎么确定?现在没有收到应答,不代表未来不会收到应答呀?主机A会给自己设置一个deadline,过了这个deadline,就判定100%没有收到应答,判定报文丢失了。丢包是"规定"出来的。
为什么丢包只能规定出来?没有别的办法确定报文确实丢了呢? 对于发送方,它是无法判定数据是真的丢失了,还是应答丢失了,对它而言,它只知道它没有收到应答。
双方基于TCP通信,TCP是不能保证数据能够送到对方,这是网络决定的,它能确定对方是否收到数据。确认应答机制的核心,不是保证数据100%发送给对方,这是由网络决定的。对于发送方,对方是否收到报文,发送方有一个确定的结果。 如果没有收到应答,就重传报文。
尽管,主机A没有接收到应答的原因是应答报文丢失,主机A依旧需要重传。如此一来,主机B就会接收到两个一样的报文,主机B就需要对报文做去重。在TCP协议报头格式中,32位序号 就派上用场了,它的核心功能就是判断是否需要去重。如果序号相同,将之前收到的报文丢弃,保留新收到的报文。重传就是在没有收到应答之后的补发措施。
TCP常见的工作方式:
很多人以为TCP是这样工作的:主机A发一个报文给主机B,必须等到B的应答回来,才能发下一个;B也一样,收到A的报文后,才发应答。这看起来很"可靠",对吧?但这其实是停等协议 ,效率极低。所有发送和接收都是串行的,网络空闲时间太多。真实的TCP根本不用这种方式。
那TCP真实怎么干?它让主机A一口气发一批报文 出去,比如4个、10个,甚至更多。然后A一边等应答,一边还能继续发------把等待时间重叠起来,并行化,效率就上去了。
但问题来了:主机A发了4个报文,主机B收到的顺序,和A发送的顺序一样吗?不一定 。网络太复杂了,不同报文可能走不同路径,先发的反而后到。这就叫乱序。
乱序是不是不可靠?是的,底层网络就是不可靠的。但TCP号称"可靠协议",那就必须解决乱序问题。
怎么解决?给每个字节打上序号 。TCP用32位序列号(seq) 标记每个字节在整个连接中的位置。接收方一看序号,就知道这个报文该放哪儿------重复的丢掉,乱序的先缓存,等前面的补齐了,再按序交给上层。这样,应用层看到的永远是整齐的字节流。
2. 32位确认序号
主机B要对A的报文做应答。如果B一个个回 ACK,比如对 seq=1000 回 ack=1001,对 2000 回2001......万一中间某个 ACK 丢了,A怎么知道到底是数据丢了,还是 ACK 丢了?是不是得重传?
这里就体现出TCP设计的巧妙了。TCP的确认序号(ack)不是"我收到了这个报文",而是"这个序号之前的所有数据我都收到了"。
比如A发了四段:seq=1000、2000、3000、4000(每段1000字节),B全收到了,就回一个ack=5000。就算中间ack=3001那个应答丢了,只要A最终收到了ack=5000,它就能100%确定:1000~4999的所有字节B都收到了 ,根本不用重传!一个确认号,就把前面所有数据都"打包"确认了。这大大减少了不必要的重传,也容忍了部分ACK丢失。
再深入一个问题:
主机A发报文给B,发的是什么?B应答A,应答的又是什么?答案是:双方互发的都是完整的TCP报文,也就是"报头 + 有效载荷"这个结构体,前面简述 ACK,只是为了方便语言描述,并不是直接发送 ACK 标志位就完事了。
那有人会问:A发数据时,只需要32位序号(seq)就行了吧?B回ACK时,只需要32位确认序号(ack)就够了呀?为什么报头里要同时存在seq和ack两个字段?一个不就够了吗?
关键在于:TCP是全双工的 !A可以给B发消息的同时,B也在给A发消息。这两个方向的数据流完全独立,各有各的字节序号。
举个例子:A发给B的数据,seq从1000开始;B发给A的数据,seq从10000开始。它们互不影响。
那既然B也要给A发数据,干嘛不把应答"捎带"在自己的数据里一起发?这正是TCP的做法!这种策略叫捎带应答。
于是,B发给A的报文里,既包含自己的数据(所以要有seq=10000),又包含对A的确认(所以要有ack=5000)。一个报文,两件事一起办。
所以我们看到的"应答",很可能既有确认,也有有效载荷。数据和确认可以同时传输,效率更高。
最后总结一下:
TCP报文里的32位序号(seq)和32位确认序号(ack),共同支撑了四大核心能力:
- 去重:靠seq识别重复报文;
- 按序到达:靠seq重组乱序数据;
- 高效确认:靠ack的累积语义减少ACK数量;
- 捎带应答:靠seq+ack共存,实现全双工高效通信。
所以,TCP的"可靠",不是靠死等、不是靠100%不丢包,而是靠聪明的编号、灵活的确认、并行的传输和双向的协同,在不可靠的网络上,硬生生造出一条可靠的字节流通道。
3. 16位窗口大小
主机A向主机B疯狂发报文,发得太快了,结果主机B的接收缓冲区满了,新来的报文直接被丢弃。
这时候你可能会说:"没关系啊!TCP有确认序号和超时重传机制,丢了就重传呗?"
听起来好像没问题,但仔细一想------这太浪费了 !假设一个报文千辛万苦穿越半个地球,终于到了主机B,结果B一看:"我缓存满了,不要了",啪一下丢掉。这个报文本身没出错,网络也没问题,纯粹是因为接收方来不及处理。可TCP还得把它重传一遍,白白消耗带宽、时间、计算资源。
那有没有办法提前告诉发送方:"我快装不下了,你慢点发" ?有!这就是流量控制(Flow Control) ------发送的速度,必须以接收方的接收能力为上限。
流量控制不只是"别发太快",它其实是个双向调节机制 。
比如有时候,发送方发得太慢,接收方处理得飞快,缓冲区一直很空------这时候窗口很大,等于在说:"你快点发啊,我吃得下!"。发送方看到大窗口,自然就加速。
所以,流量控制既防"撑死"(接收方溢出),也防"饿着"(发送太慢),在可靠性和效率之间找到最佳平衡。
那问题来了:
问题1:接收方怎么知道自己还能收多少数据?
很简单------看自己的接收缓冲区里还剩多少空闲空间 。
比如缓冲区总共64KB,已经存了50KB的数据,那还能收14KB。这个"14KB"就是当前的接收能力。
问题2:发送方怎么知道接收方现在能收多少?
靠TCP报头里的一个字段:16位窗口大小(Window Size) 。
每次接收方发ACK应答时,都会把自己的当前剩余缓冲区大小填进这个字段,告诉发送方:"我现在最多还能收这么多字节"。
发送方一看这个值,就知道接下来该发多少、能不能发。如果窗口是0,那就先别发了,等对方通知有空间再说。
所以,TCP原则上要对每个报文(或批量)做应答,不只是为了确认收到,更是为了持续同步窗口大小------这样才能动态调整发送节奏,既不压垮接收方,也不浪费网络。
问题3:16位最大只能表示65535,那TCP窗口最大就64KB吗?
早期确实是这样,但在高速或高延迟网络中(比如跨洋传输),64KB窗口根本跑不满带宽。所以后来在TCP首部的选项字段(最多40字节)里加了一个"窗口扩大因子(Window Scale Factor)M"。
实际窗口大小 = 窗口字段的值 × 2^M(或者说"左移M位")。比如窗口字段是65535,M=3,那实际窗口就是 65535 × 8 ≈ 524KB。这样,TCP就能支持几MB甚至更大的窗口,适应现代网络需求。
注意:窗口扩大因子只在三次握手阶段 通过SYN报文协商,一旦连接建立就不能改了。
问题4:三次握手完成后,第一次发数据时,该发多大?
虽然是第一次发应用数据 ,但不是第一次交换TCP报文 。
因为在三次握手中:
- A发SYN时,会带上自己的初始窗口大小;
- B回SYN+ACK时,也带上了自己的窗口大小;
- A再回ACK,连接就建立了。
所以,双方在发第一个数据包之前,就已经知道对方的初始接收能力了 。A第一次发数据,绝不会瞎发,而是严格遵守B在SYN+ACK里通告的窗口大小。
4. 标志位
多个客户端同时向同一个服务端发报文,服务端收到的报文五花八门:有的是建连请求(SYN),有的是应答(ACK),有的是断连通知(FIN),有的是纯数据(DATA),还有的是"我出错了,重来!"(RST)......
那问题来了:报文自己怎么知道自己是哪一类? 答案就在 TCP 报头里------6 个标志位(Flags) :URG, ACK, PSH, RST, SYN, FIN。
它们本质就是比特开关:0 表示"没这事",1 表示"有这个功能"。靠这些位的组合,TCP 就能区分报文类型,决定下一步动作。
1. ACK 标志位
ACK 标志位:确认序号是否有效
只要报文里有 ack 字段(即确认序号),就必须把 ACK 位置 1;反过来,ACK=1 时,ack 字段才被解释为"期望接收的下一个字节序号"。
你可能会说:"那纯数据报文不带 ACK 吗?"几乎不存在 。因为 TCP 连接建立后, 几乎所有报文都带 ACK (哪怕只是重复确认)。
为什么?因为捎带应答太香了 :B 要给 A 发数据,顺手就把对 A 的 ACK 带上,省一个纯 ACK 报文。
所以,ACK 标志位 ≠ "这是个纯应答报文",而是"这个报文包含确认信息"。
2. SYN 标志位
SYN 标志位:请求建立连接
SYN=1 表示"我想和你建连",是三次握手的起点。流程:主机 A 发 SYN → 主机 B 回 SYN+ACK → 主机 A 再回 ACK,连接建立。
那为什么一般是 3 次握手?因为要最小成本验证全双工通畅 + 双方意愿一致:
- A 发 SYN(A 能发)→ B 收到(B 能收);
- B 回 SYN+ACK(B 能发)→ A 收到(A 能收);
- A 回 ACK(A 能发)→ B 收到(B 能收)。
三次握手就像结婚:双方同意 + 双方家长(网络)点头,缺一不可。4 次?没必要;2 次?无法验证 B 是否真能发。
三次握手中,最后那个 ACK 是客户端主动发出的 。客户端只要把 ACK 发出去,就认为连接建好了(即使服务端没收到)。如果这个 ACK 丢了,客户端开始发数据,服务端一看:"谁啊?没建连就发数据?"------立刻回一个 RST,告诉客户端:"你连都没建好,别闹!"
3. FIN 标志位
FIN 标志位:我要关写端了
FIN=1 表示"我不会再发送新数据了",不是"我要彻底断开连接"!关键理解:TCP 是全双工的,读和写可以独立关闭。
举个例子:
客户端发 FIN → 服务端回 ACK → 此时客户端进入 FIN_WAIT_2,它确实不再向服务端写数据了 ,但仍可读服务端的数据(比如服务端还在回传响应)。直到服务端也发 FIN,客户端回 ACK,才进入 TIME_WAIT。
所以:
- FIN 不代表"连接没了",只代表"我这端不写了";
- ACK 依然可以发------因为 ACK 是报头的一部分,不占 payload,发 ACK 不违反"不写数据"的承诺。
你可能会问:"那客户端 fd 都 close() 了,怎么还能发 ACK?"
答:close(sockfd) 在应用层调用后, OS 会:
- 立即停止应用层写入(fd 的写端关闭);
- 但 TCP 层仍需完成挥手流程(发 FIN、等 ACK、发 LAST_ACK);
挥手是内核干的,和应用层是否 close 无关。所以,close() 后,连接还没真正释放,要等 TIME_WAIT 结束。
4. RST 标志位
RST 标志位:连接复位,强制中断
RST=1 表示:"这连接有问题,立刻终止,别玩了。"
常见场景:
- 连接未建立成功时:如客户端发完第三次 ACK 后直接发数据, 服务端发现"这连接根本没建好",回 RST;
- 收到非法报文:比如 seq 严重错乱、窗口为负、或对方已关闭连接却还发数据;
- 应用层主动 reset:比如用 shutdown(sockfd, SHUT_RDWR) 或 setsockopt(..., SO_LINGER) 强制关闭。
RST 的特点是:不等待、不重传、立即终止。它是 TCP 的"紧急刹车",比 FIN 更暴力,但更可靠------避免无效连接占用资源。
5. PSH 标志位
PSH 标志位:催促对方"快点交数据!"
PSH=1 的意思是:"请接收方 TCP 层立刻把缓冲区里的数据交给应用层,别攒着!"
很多人以为 PSH 是让对方"马上发数据",其实不是------PSH 是催接收方的应用层赶紧读数据。
极端例子:
服务端接收缓冲区满了(window=0),客户端停发数据,但服务端应用层迟迟不 read(),缓冲区一直满着......
这时客户端可以发一个 纯 ACK + PSH=1 的报文(无 payload),服务端 TCP 层一看 PSH=1,就立刻通知应用层:"有数据!快 read!"
虽然不能强迫应用层读,但至少给了它一个" urgent 提醒"。
现实中,PSH 很少被显式设置。需要注意:PSH 不保证"立即交付",它只是个提示。最终读不读,还是看应用层调度。
6. URG 标志位
URG=1 表示"这个报文里有紧急数据",配合 16 位紧急指针(Urgent Pointer) 使用。
紧急指针不是指向"紧急数据本身",而是指向紧急数据之后的那个字节的序号 。
比如发送字节流:1000A 1001B 1002C 1003D 1004E,你想标 D 为紧急数据,那么紧急指针 = 1004(即 D 的下一个字节序号)。

接收方 TCP 层看到 URG=1,会:
- 通知应用层:"有紧急数据!";
- 允许通过 recv(sockfd, buf, len, MSG_OOB) 读取带外数据(OOB);
- 正常数据仍按序放入缓冲区,紧急数据插队优先交付。
但真相是:URG 几乎没人用 。
为什么?因为设计混乱:
- 不同系统对"紧急数据范围"解释不同(有的指 1 字节,有的指到指针前所有);
- 应用层很难可靠处理 OOB 数据;
- 现代协议(用应用层帧控制代替了紧急机制。
所以 URG 是 TCP 的"历史遗迹"------保留是为了兼容老系统,新开发基本忽略它。
3. 连接
什么是连接?多个客户端可以向同一个服务端建立连接,因此存在多个连接,有的连接是正在建立中,有的连接是正在通信中,有的连接是将要断开......。
既然如此,OS就需要将它们管理起来,怎么管理?"先描述,再组织"。
主机双方建立连接成功后,都会在OS内构建连接结构体 ------ struct tcp_sock。struct tcp_sock 结构体中存在一个结构体变量struct inet_connection_sock inet_conn,struct inet_connection_sock 结构体的源码为:
cpp
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
struct request_sock_queue icsk_accept_queue;
struct inet_bind_bucket *icsk_bind_hash;
unsigned long icsk_timeout;
struct timer_list icsk_retransmit_timer;
struct timer_list icsk_delack_timer;
__u32 icsk_rto;
__u32 icsk_pmtu_cookie;
const struct tcp_congestion_ops *icsk_ca_ops;
const struct inet_connection_sock_af_ops *icsk_af_ops;
unsigned int (*icsk_sync_mss)(struct sock *sk, u32 pmtu);
__u8 icsk_ca_state;
__u8 icsk_retransmits;
__u8 icsk_pending;
__u8 icsk_backoff;
__u8 icsk_syn_retries;
__u8 icsk_probes_out;
__u16 icsk_ext_hdr_len;
struct {
__u8 pending; /* ACK is pending */
__u8 quick; /* Scheduled number of quick acks */
__u8 pingpong; /* The session is interactive */
__u8 blocked; /* Delayed ACK was blocked by socket lock */
__u32 ato; /* Predicted tick of soft clock */
unsigned long timeout; /* Currently scheduled timeout */
__u32 lrcvtime; /* timestamp of last received data packet */
__u16 last_seg_size; /* Size of last incoming segment */
__u16 rcv_mss; /* MSS used for delayed ACK decisions */
} icsk_ack;
struct {
int enabled;
/* Range of MTUs to search */
int search_high;
int search_low;
/* Information on the current probe. */
int probe_size;
} icsk_mtup;
u32 icsk_ca_priv[16];
#define ICSK_CA_PRIV_SIZE (16 * sizeof(u32))
};inet_connection_sock 结构体中存在一个结构体变量:struct inet_sock icsk_inet。inet_sock 结构体中存在一个结构体变量:struct sock sk。
这里的层级就和UDP处的一样了,如下图所示:
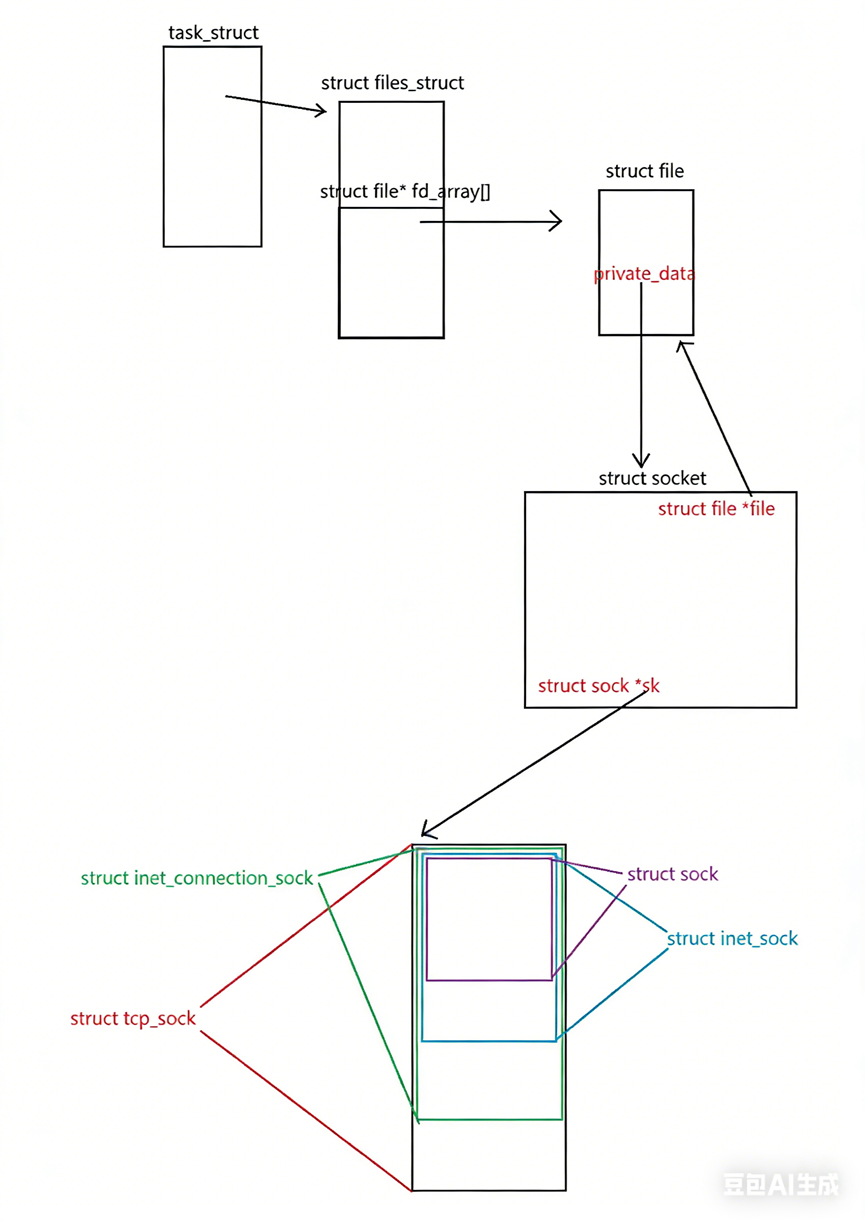
总结:task_struct → files_struct → fd_array\[\] → struct file → private_data → struct socket → struct sock *sk。而 sk 实际指向的是 struct inet_connection_sock → struct tcp_sock 的继承链。
也就是说:
- 每个 TCP 连接,在内核里就是一个 struct tcp_sock 对象;
- 它维护着:seq/ack、窗口、重传定时器、状态(如 ESTABLISHED)、接收/发送缓冲区......
- 建立连接 = 创建这个结构体;断开连接 = 释放它。
所以,listen() 和 accept() 干了什么?
- listen():创建一个监听套接字,初始化 tcp_sock,并准备两个队列:
- 半连接队列(SYN_RCVD 状态的连接,未完成三次握手);
- 全连接队列(ESTABLISHED 状态,等待 accept() 取走);
- accept():从全连接队列取出一个已建好的连接,复制一份 tcp_sock 给新 socket,返回新的 fd。
注意:accept() 不参与三次握手!握手是内核自动完成的。
4. 三次握手和四次挥手
三次握手,四次挥手流程图如下所示:
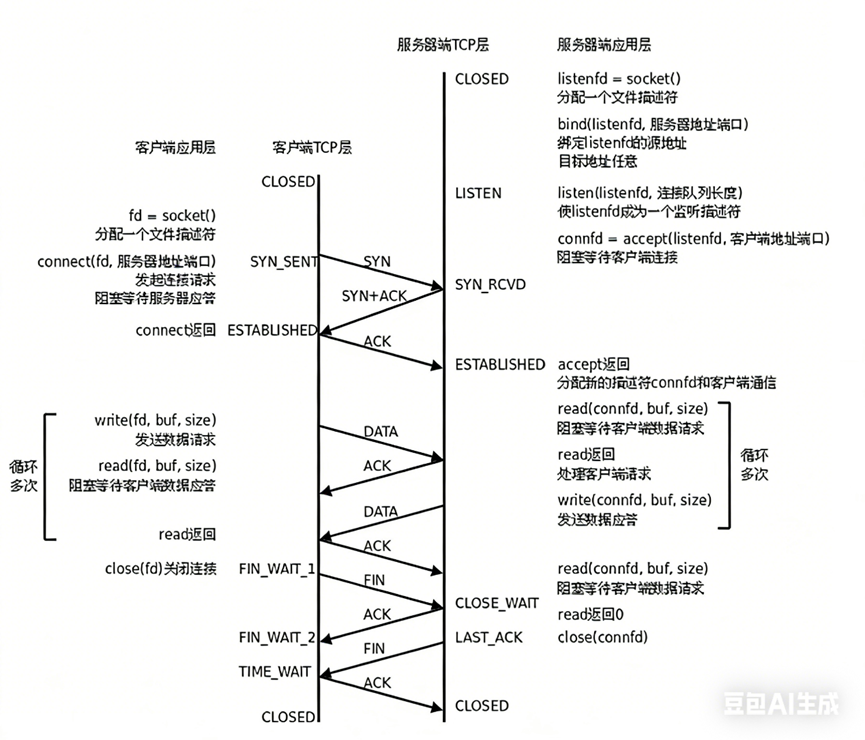
服务端典型路径:
CLOSED
→ listen() → LISTEN
→ 收到 SYN → SYN_RCVD(放入半连接队列)
→ 收到 ACK → ESTABLISHED(移入全连接队列)
→ accept() 取走 → 应用层读写
→ 客户端发 FIN → CLOSE_WAIT(服务端仍可写!)
→ 服务端调用 close() → 发 FIN → LAST_ACK
→ 收到 ACK → CLOSED
客户端典型路径:
CLOSED
→ connect() → SYN_SENT
→ 收到 SYN+ACK → ESTABLISHED
→ 主动 close() → FIN_WAIT_1
→ 收到 ACK → FIN_WAIT_2(可读,不可写)
→ 收到服务端 FIN → TIME_WAIT
→ 等 2MSL → CLOSED
重点纠正一个误区:
FIN_WAIT_2 不代表"连接已断",它只是"我发完 FIN,等对方 FIN" 。如果服务端卡在 CLOSE_WAIT(即收到 FIN 后,迟迟不 close()),就会导致量 CLOSE_WAIT 积压------这通常是服务端代码 Bug:忘了 close() 对应的 fd!
为什么要有 TIME_WAIT?
等 2MSL(Maximum Segment Lifetime),确保:
- 网络中残留的旧报文(比如延迟的 ACK)能自然消亡;
- 如果最后一个 ACK 丢了,服务端重传 FIN,客户端还能响应;
- 防止新连接误收旧连接的残余报文(IP+port 相同,seq 可能撞车)。
所以:TIME_WAIT 是主动关闭方的"善后期",不是"没关",而是"正在安全收尾"。
三次握手:不是"建连接",而是"确认双方能收能发"。
主机A想和主机B通信,为什么不能发一个SYN就完事?为什么非要3次? 你可能会说:"因为要可靠嘛。"但可靠不是靠次数多,是靠验证能力。
TCP 要建立的是全双工信道------A 能发、B 能收;同时 B 能发、A 能收。这四个动作,必须都被确认过。
我们模拟一下:
第一次:A → B:SYN(seq=x)
-
A 知道自己能发(报文已发出)
-
B 收到后,知道 A 能发、自己能收
-
此时只验证了单向通路(A→B)
第二次:B → A:SYN+ACK(seq=y, ack=x+1)
-
B 知道自己能发(仅假设,尚未确认)、知道自己能收、知道 A 能发
-
A 收到后,知道:自己能收、自己能发、B 能发、B 能收
-
此时双向通路已验证(A 已确认全双工),但 B 尚未确认自己能发(需等第三次握手)
第三次:A → B:ACK(ack=y+1)
-
A 知道自己能发(发出 ACK)
-
B 收到后,确认:A 能收、自己能发(闭环完成)
-
至此,双方都确认:A 能发/能收,B 能发/能收 ------ 全双工确认完成
所以,三次握手的本质是:用最少的报文,让双方都亲自"发出 + 接收"各一次,从而共同确认:我们之间,双向都通!
常见误解纠正:
- "服务端无条件答应" → 实际上,B 在收到 SYN 后会检查资源(比如全连接队列是否满),满了就丢弃 SYN,A 就卡在 SYN_SENT;
- "第三次 ACK 可有可无" → 如果丢了,A 以为连好了就开始发数据, B 却认为"连接没建好",直接回 RST,连接失败;所以:第三次 ACK 是必要的"最终确认",不是形式主义。
类比理解:两个人约见面。
A 发消息:"我在东门等你"(SYN)
B 回:"我出发了,5分钟后到东门"(SYN+ACK)
A 再回:"收到,我也快到了"(ACK)
只有这时, 双方才敢放下手机、走向东门.
少一句,可能一人到了,另一人还在犹豫:"他到底来不来?"
四次挥手:不是"断连接",而是"分阶段关读写"
既然建连要3次,为什么断连要4次?不能3次搞定吗? 答案是:可以3次,但前提是"双方同时想断" ------这叫"同时关闭",现实中极少发生。绝大多数情况是:一方先说"我不写了",另一方过会儿再说"我也不写了"。
我们看标准流程(客户端主动关闭):
第一次:A → B:FIN(seq=u)
- A 说:"我数据发完了,不再向你写数据了。"(注意:不是"断连",是关写端)
- A 进入 FIN_WAIT_1
- B 收到后,知道"A 不写了",但 B 可能还有数据要发给 A(比如响应未完成),所以 B 不能立刻关连。
第二次:B → A:ACK(ack=u+1)
- B 说:"收到,你不用写了。"
- B 进入 CLOSE_WAIT(此时 B 仍可向 A 发数据!)
- A 收到后,进入 FIN_WAIT_2 ------ 它确实不写了,但还能读 B 的数据
- 关键点:ACK 不是断连信号,只是对 FIN 的确认
第三次:B → A:FIN(seq=v)
- B 说:"我数据也发完了,我也不写了。"
- B 进入 LAST_ACK
- A 收到后,知道"B 也不写了",于是准备最后一步。
第四次:A → B:ACK(ack=v+1)
- A 说:"收到,连接可以彻底关了。"
- A 进入 TIME_WAIT,等 2MSL;
- B 收到后,立即进入 CLOSED。
所以,4 次挥手 = 2 次"关写端" + 2 次"确认" ,本质是全双工的对称关闭。
3次挥手可能吗? 可能!当双方几乎同时发 FIN 时:
- A 发 FIN → B 正好也要发 FIN
- B 把自己的 FIN 和对 A 的 ACK 捎带在一起:FIN+ACK
- A 收到后,回一个 ACK
- 完成:FIN → FIN+ACK → ACK,共3次。
这叫 "同时关闭"(Simultaneous Close),在 TCP 状态图里对应:
A: ESTABLISHED → CLOSED (经 FIN_WAIT_1 → CLOSING → TIME_WAIT)
B: ESTABLISHED → CLOSED (经 CLOSE_WAIT → LAST_ACK → CLOSED)
但注意:这不是"简化版挥手",而是特殊场景下的自然合并,就像两个人同时说"拜拜",一人顺手把对方的"再见"也回了。
对比握手与挥手:
- 握手必须3次:因为建连是单向发起、双向确认,无法合并;
- 挥手通常4次:因为关连是双向独立决策,多数情况不同步;
- 但两者底层逻辑一致:每一次交互,都要求"发出 + 接收"闭环。
为什么挥手后,主动方要等 TIME_WAIT?
很多人觉得:"我都发完 ACK 了,怎么还不 CLOSE?"其实,TIME_WAIT 不是"没关",而是"正在安全收尾"。
它解决两个关键问题:
- 防止旧报文干扰新连接
假设 A 和 B 的连接刚关,A 立刻用相同 IP:port 建新连接。
如果网络中还飘着上次连接的延迟 ACK(比如 seq=1000 的 ACK),新连接误收它,就会乱序甚至崩溃。
等 2MSL(一般 60s),确保所有旧报文自然死亡。 - 保证最后的 ACK 到达
如果 A 发的最后一个 ACK 丢了, B 会重传 FIN;
A 处于 TIME_WAIT 就能响应这个重传 FIN,避免 B 卡在 LAST_ACK 永久等待.
所以:TIME_WAIT 是主动关闭方的"责任期"------它关得最晚,但关得最稳。
从握手到挥手,TCP 的"生命周期"
你可以把一个 TCP 连接想象成一个人的一生:
| 阶段 | 对应动作 | 内核干了什么 |
|---|---|---|
| 出生 | socket() | 分配 struct sock,初始化为 CLOSED |
| 报名 | bind() | 绑定 IP:port,准备监听 |
| 等待面试 | listen() | 创建半/全连接队列,进入 LISTEN |
| 初试 | A 发 SYN | A 进入 SYN_SENT;B 收到,放入半队列,进入 SYN_RCVD |
| 复试 | B 回 SYN+ACK | B 进入 SYN_RCVD → ESTABLISHED(待 accept) |
| 录用 | A 回 ACK | A 进入 ESTABLISHED;连接真正可用 |
| 工作期 | read/write 循环 | 双方持续交换 DATA + ACK + 窗口更新 |
| 辞职申请 | A 发 FIN | A 进入 FIN_WAIT_1;B 收到,进入 CLOSE_WAIT |
| 批准离职 | B 回 ACK | A 进入 FIN_WAIT_2;B 仍可发数据 |
| 交接完毕 | B 发 FIN | B 进入 LAST_ACK;A 收到,进入 TIME_WAIT |
| 档案封存 | A 回 ACK + 等 2MSL | A 释放资源;连接彻底结束 |
5. TCP的可靠性和效率
问题:网络本来就不可靠------报文会丢、会乱序、会重复。TCP 却号称"可靠传输",它靠什么做到的?
依靠三套协同机制:
- 确认应答(ACK) ------ 你知道我收到了吗?
- 超时重传 + 快重传 ------ 你没回?我等一会儿再发;你连回三次"我要1001",那我立刻重发!
- 滑动窗口 ------ 不是等一个ACK再发下一个, 而是一口气发一串,边发边等,把等待时间"压扁"。
这三者不是独立的,而是拧成一股绳:
- ACK 告诉你"收到哪了";
- 滑动窗口根据 ACK 动态决定"还能发多少";
- 超时/快重传在 ACK 长期不来时兜底。
下面我们就按这个逻辑,一条一条捋清楚。
1. 确认应答(ACK)
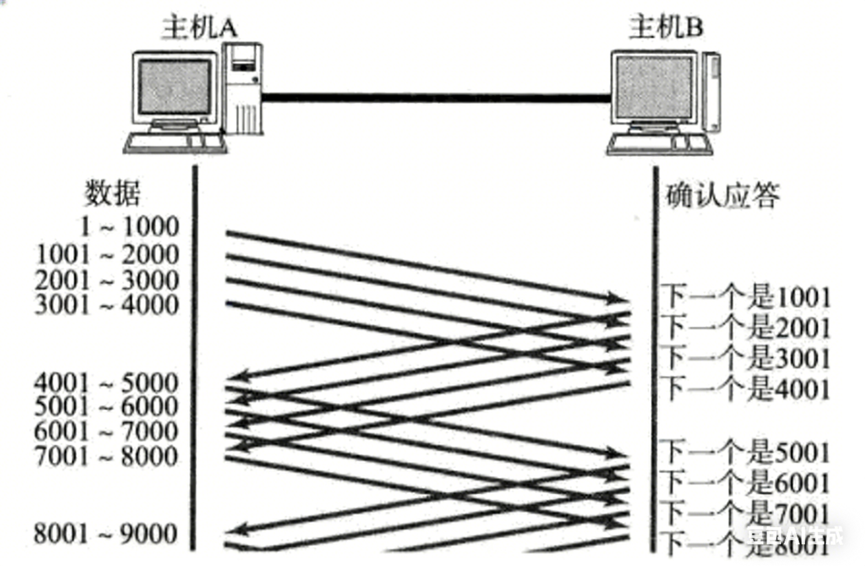
尤其需要注意:ACK 字段的值,不是"我收到了这个报文",而是"我收到了这个序号之前的所有字节"。
为什么这么设计?因为 TCP 是面向字节流 的,不是面向报文的。
想象发送缓冲区是一个大数组 char outbuf∞,每个字节有唯一序号(从随机初始值开始)。
- A 发 1~1000 → seq=1
- B 收到 → 回 ack=1001
- A 发 1001~2000 → seq=1001
- B 收到 → 回 ack=2001
ack=2001 的含义是:1~2000 全收到了,下个要 2001 。
这样,哪怕中间某个 ACK 丢了(比如 ack=1001 没收到),只要最终收到ack=2001,A 就知道:1~2000 全 OK,不用重传!
所以 ACK 的本质是累积确认------它压缩了确认信息,极大减少 ACK 数量,也天然支持乱序重组。
2. 超时重传机制
等待特定的时间,特定的时间间隔不能太短,会导致多次重传;也不能太长,会拖慢效率。它应该随网络状态浮动。
那这个"超时时间"到底谁定?怎么定?在 Linux 及 Windows 中, TCP 用 RTO (Retransmission Timeout) 控制重传时机,其基础单位是 500ms。但 RTO 不是固定 500ms,而是动态计算的:
- 初始 RTO ≈ 1s(保守起见);
- 每次成功收到 ACK,就用新测得的 RTT(往返时间)更新平滑 RTT(SRTT);
- RTO = SRTT + 4×RTTVAR(RTT 方差),公式保证它既灵敏又稳定。
重传策略
如果第一次超时没收到 ACK:
- 第1次重传:等 RTO
- 第2次重传:等 2×RTO
- 第3次重传:等 4×RTO
- ...... 依次翻倍
为什么指数增长?避免在网络拥塞时雪崩式重传(大家都疯狂重发,更堵了)。
一般默认最多重传 15 次(Linux 可调),累计超时总时间约 9 分钟。超过后,TCP 认为:
- 对端挂了?
- 网络断了?
- 路由器黑洞了?
直接发 RST,强制关闭连接。关键结论:超时重传是"兜底机制"------平时靠 ACK 和滑动窗口高效运转;一旦 ACK 长期不来,它才出手救场。
3. 滑动窗口
问题:发出去的报文,在收到 ACK 前,OS 会丢掉吗? 绝对不会!
因为:
- 如果丢了,后续发现数据没到,却找不到原始报文重传;
- 更糟的是,如果 ACK 到了,但原始报文已被删,你连"确认了哪段"都对不上。
所以:所有已发送、未确认的报文,必须保留在发送缓冲区里 ------而这块区域,就是滑动窗口的覆盖范围。
滑动窗口示意图:
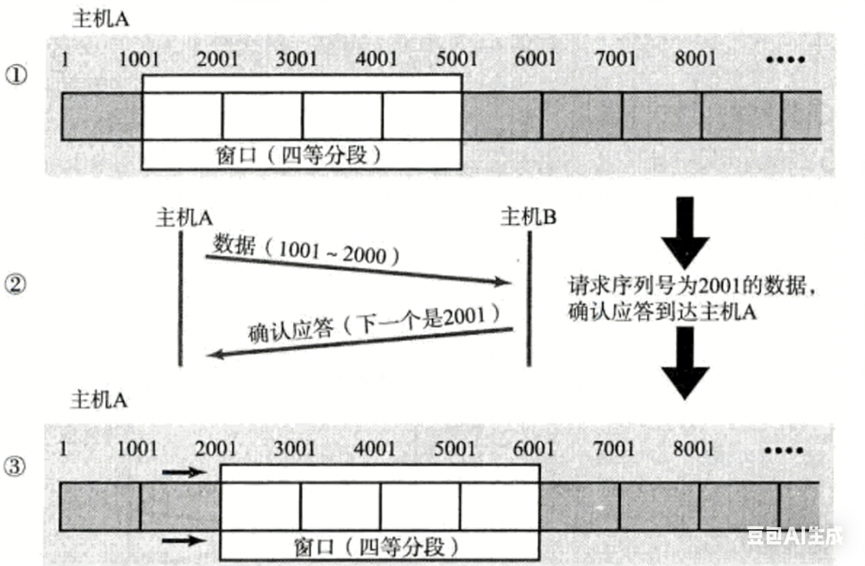
滑动窗口到底在哪?怎么表示?
把发送缓冲区想象成一个无限长的数组。
滑动窗口 = 一个左闭右开区间 [send_base, send_base + window_size)
- send_base:最小未确认序号(即下一个该 ACK 的值)
- window_size:当前允许发送的字节数(来自对端通告的窗口大小)
而窗口右边界:send_next = send_base + window_size ------ 这就是你还能发到哪里。
所以发送缓冲区被分为三段:
| 区域 | 范围 | 状态 |
|---|---|---|
| 已确认 | < send_base | 已安全交付,可删除 |
| 正在发送(窗口内) | [send_base, send_next) | 已发未确认,必须缓存 |
| 待发送 | >= send_next | 还没轮到,等窗口滑动 |
窗口会变大、变小、不变?会左移吗?
会变大:当接收方上层读得快,缓冲区空了
- B 的接收窗口从 3000 → 6000
- 下次 ACK 中 window=6000
- A 更新:send_next = ack + 6000 → 窗口右移,可发更多
会变小:当接收方上层卡住, 缓冲区满了
- B 的接收窗口从 4000 → 1000
- 下次 ACK 中 window=1000
- A 更新:send_next = ack + 1000 → 窗口右边界左移(注意:是右边界动,不是整个窗口左移!)
绝对不会整体左移!
- 左边界 send_base = ack,而 ack 是单调不减的(序号只增不减),所以左边界只能不动或右移;
- 右边界 send_next = send_base + window,若 window 缩小,右边界可能左移------但这只是"窗口收缩",不是"窗口倒着滑";
- 整个窗口永远不会向左滑动,否则就违反了"已确认数据不可逆"的可靠性原则。
举个例子:
初始:send_base=1001, window=4000 → 可发 1001~5000
收到 ack=2001, window=3000 → send_base=2001, send_next=5001
窗口从 [1001,5001) → [2001,5001),左移1000,右不动
再收到 ack=3001, window=2000 → [3001,5001),左再移1000
左边界前进,右边界可能因 window 缩小而滞后,但绝不会退回到 2000 之前!
来看下图:
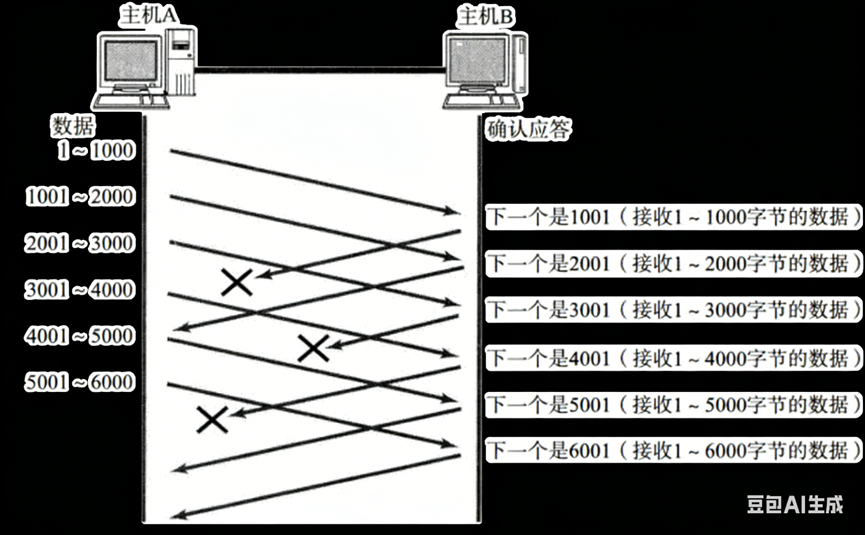
主机A发 1~1000, 1001~2000, 2001~3000, 3001~4000......结果 1001~2000 丢了,B 一直回 "下一个该收1001"。
我们可以敏锐地指出:收到3个相同的ACK(都是1001),就触发快重传(Fast Retransmit)。
为什么是"3个相同ACK"?
- 第1个 ACK=1001:可能是延迟,正常;
- 第2个 ACK=1001:有点怪,但还忍;
- 第3个 ACK=1001:几乎可以确定 1001~2000 丢了(因为 B 已收到后续数据,却还在要 1001);
A 立刻重传 1001~2000,不等超时!快重传的本质:用重复 ACK 当"丢包信号",比等超时快得多(通常节省 1~2 个 RTT)。
如果报文丢的是中间段呢?比如 3001~4000 丢了?
流程
- 收到 1~1000 → ack=1001
- 收到 1001~2000 → ack=2001
- 收到 3001~4000(但 2001~3000 丢了)→ 仍回 ack=2001!
因为 2001 是第一个缺失的序号,TCP 要求"确认序号 = 最小未收到序号"。
所以,无论丢哪一段,只要它是最左边未收到的,后续所有 ACK 都会卡在同一个值 ------这就保证了:任何丢包,最终都会表现为"多个重复 ACK",从而触发快重传。只有极端情况(如最后一批数据丢了,且连接马上关闭)才依赖超时重传。
滑动窗口会越界吗 ?不会,将滑动窗口理解成环形数组。
4. 拥塞控制
既然客户端得到了服务端的接收能力,假设为4000字节,那么客户端发送的时候,为什么不直接发送4000字节,反而发送了多个报文?
因为:接收能力 ≠ 网络容量。
- 接收窗口(rwnd)告诉你是"对方能存多少";
- 但网络中间可能有路由器、交换机、链路带宽瓶颈------它们才是真正的"堵点"。
- 如果你不管三七二十一,按接收窗口满打满发,很可能把网络塞爆,导致大量丢包,反而更慢。
所以 TCP 必须引入一个新变量:拥塞窗口(cwnd) ,它代表的是------当前网络能承受多少数据。
发送方实际能发的数据量,取两者最小值:发送窗口= min ( rwnd*,* cwnd*)***。这才是最终限制你发多少的"闸门"。
拥塞窗口怎么来的?
1. 慢启动:从 1 开始,指数试探
TCP 连接刚建立时,对网络一无所知。
它不会直接冲上去发 4000 字节,而是:
- 设 cwnd = 1(单位是 MSS,即最大段大小,比如 1460 字节);
- 每收到 1 个 ACK,cwnd += 1;
- 也就是说:第 1 轮发 1 段 → 收到 1 个 ACK → cwnd=2 → 第 2 轮发 2 段;
- 收到 2 个 ACK → cwnd=4 → 第 3 轮发 4 段;
- ...... 指数增长:1 → 2 → 4 → 8 → 16 → ...
为什么是指数?因为早期网络空闲时,资源充足,快速探测上限是合理的;而如果网络真拥塞了,一开始只发 1 段,就算丢了,损失也最小------这是"安全第一"的试探策略。
2. 慢启动阈值:从"狂奔"到"稳跑"的切换点
指数增长不能永远持续------万一撞上拥塞,会雪崩式丢包。
所以 TCP 引入一个临界值:慢启动阈值 ssthresh。
- 初始时,ssthresh 通常设为一个较大值(如 65535 字节),或等于接收窗口;
- 当 cwnd < ssthresh:走慢启动,每轮 ACK 增 1(指数增长);
- 当 cwnd ≥ ssthresh:进入拥塞避免阶段,改为每轮增加 1/cwnd(近似线性增长);
举例:cwnd=16,收到 16 个 ACK 后,cwnd += 1 → 变成 17;再收 17 个 ACK,cwnd += 1 → 18......
所以增长变慢了,但仍在稳步上升。
这个设计很精妙:
- 前期快探底(慢启动),快速利用空闲带宽;
- 后期稳推进(拥塞避免),避免突然压垮网络。
拥塞发生了怎么办?------两种响应机制
网络拥塞的典型信号是:大量丢包(注意:不是个别丢包!)。
- 丢 1~2 个包?正常,靠超时重传或快重传解决;
- 丢 3% 以上?大概率拥塞;5%?严重拥塞。
一旦检测到拥塞,TCP 必须立刻刹车,否则全网一起瘫痪。
情况一:超时重传触发(严重拥塞)
- 当 RTO 超时,说明不仅丢包,而且 ACK 长期没回来 → 网络可能已断或极度拥堵;
- 此时 TCP 做两件事:
- ssthresh = cwnd / 2(阈值砍半,记住这次教训);
- cwnd = 1(回到慢启动起点,重新试探);
- 下一轮又从 1 开始指数增长------就像吵架后冷战,重新追人一样。
情况二:快重传触发(轻度拥塞)
- 收到 3 个重复 ACK(如连续三次 ACK=1001),说明有单段丢失,但网络尚通;
- 此时 TCP 认为:"可能只是局部丢包,还没全局拥塞",于是:
- ssthresh = cwnd / 2(阈值减半);
- cwnd = ssthresh + 3(不是归 1!留一点余量,继续发);
- 进入快速恢复阶段:每收到 1 个重复 ACK,cwnd += 1;直到收到新 ACK,才切回拥塞避免。
为什么快重传后不归零?因为网络还没崩溃,只是有点堵,没必要从头爬坡。这就像两个人吵架,一方认错+递杯水,关系就不用彻底重启。
具体过程如下图所示:
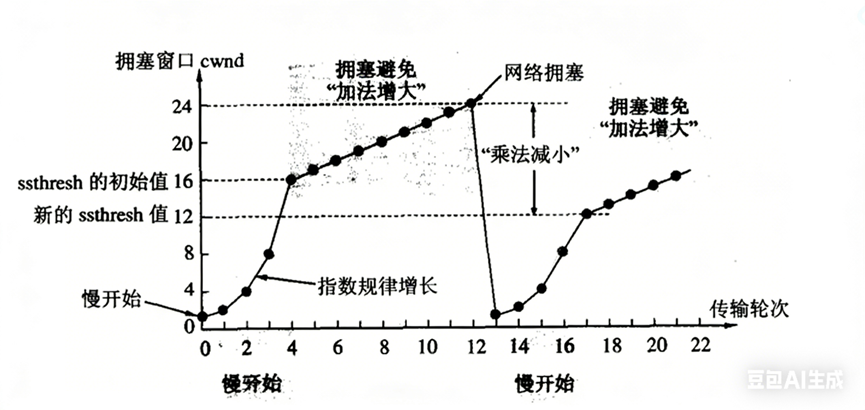
拥塞窗口一定是变化的,因为网络状态时刻在变。TCP 根本不可能提前知道"现在能发多少",它只能不断试探。
所以整个拥塞控制过程,本质上是一场动态探索实验:
- 慢启动:大胆试探上限;
- 拥塞避免:谨慎逼近瓶颈;
- 丢包发生:立即收缩,重新学习;
- 网络恢复:缓慢回升,再次试探。
图中那条曲线------先指数上升,到 ssthresh 后线性增长,遇到拥塞骤降,再重启慢启动------
这不是人为规定,而是 TCP 在安全、可靠、效率三者间反复权衡的结果:
- 太保守?吞吐太低;
- 太激进?全网拥塞;
- 刚刚好?就是现在这套算法。
拥塞控制与前面机制的关系
| 机制 | 负责对象 | 关键变量 | 作用 |
|---|---|---|---|
| 接收窗口(rwnd) | 接收端缓冲区 | 对端通告的 window 字段 | 流量控制:别把对方撑爆 |
| 拥塞窗口(cwnd) | 网络链路容量 | 发送端维护的 cwnd | 拥塞控制:别把网络堵死 |
| 实际发送窗口 | min(rwnd, cwnd) | --- | 最终发多少,由两者共同决定 |
- 没有 rwnd → 会压垮接收方;
- 没有 cwnd → 会压垮网络;
- 两者都有 → TCP 才能在复杂网络中既快又稳地传数据
拥塞控制不是"不让发",而是"聪明地发":前期像新手司机,慢慢踩油门;中期像老司机,匀速跟车;一见前车急刹(丢包),立刻松油+点刹;等路况好转,再缓缓提速。
5. 延迟应答
你发一个报文给主机 B,B 收到后不立刻回 ACK,而是等一会儿------比如 200ms 内,如果又有新数据到来,或者上层应用把缓冲区里的数据读走了,那它就可以在同一个 ACK 里,告诉对方:"我现在能收更多了!"
举个例子:
- 主机 B 的接收缓冲区是 1M;
- 主机 A 一次发了 500K 数据过来;
- 如果 B 立刻回 ACK,通告窗口就是 1M - 500K = 500K;
- 但如果 B 等 10ms,而在这 10ms 内,应用层把这 500K 全读走了,缓冲区又空了;
- 那它回的 ACK 就可以带 window=1M ------ 窗口翻倍!
而我们知道:窗口越大,吞吐越高 。
所以延迟应答的本质,就是用一点点等待时间,换一个更大的接收窗口,从而提升整体效率。
但这不是无限制等。TCP 规定:
- 延迟时间一般不超过 200ms(Linux 默认是 40ms 或 200ms,取决于配置);
- 或者,最多延迟两个报文------收到第一个不回,收到第二个必须回;
- 另外,如果接收方有数据要发给对方,也可以直接把 ACK 捎带上(这就是捎带应答,后面讲)。
所以,并不是所有 ACK 都能延迟:
- 如果对端正在等这个 ACK 才能继续发(比如窗口卡住了),就不能拖;
- 如果超时重传的 RTO 很短(比如 10ms),你等 200ms 再回,人家早就重传了,反而浪费带宽;
- 因此,延迟应答是有条件的:只在安全、不影响可靠性的情况下启用。
6. 捎带应答
TCP 是全双工的,双方都能同时发数据。当 A 给 B 发数据时,B 要回 ACK;但如果 B 正好也有数据要发给 A ,那它就可以把 ACK 字段塞进自己的数据包里,一起发过去。这就叫捎带应答。
好处很明显:省下一个纯 ACK 包,减少网络开销,提高链路利用率。
典型场景就是交互式通信:
- 你 telnet 登录服务器,敲一个命令;
- 服务器回结果的同时,顺便确认你刚发的命令字节;
- 不需要单独发一个"我收到了"的空包。
再比如三次握手:
- 第一次 SYN:不能带数据(连接未建);
- 第二次 SYN+ACK:也不能带数据(虽然有些实现允许,但标准不推荐);
- 第三次 ACK:可以带数据!
因为客户端发完这个 ACK,连接就算建立了。既然连接已通,干嘛不让它顺手把第一个请求(比如 HTTP GET)一起发出去?这就是典型的捎带应答,也是为什么很多协议能在 1-RTT 内完成首请求。
3. TCP总结
TCP 为什么这么复杂? 因为它的目标太"贪心"了:既要绝对可靠,又要尽可能高效。
为了可靠,它堆了一整套机制:
- 校验和:防比特错误;
- 序列号:保证按序到达 + 自动去重;
- 确认应答(ACK):核心反馈机制;
- 超时重传 + 快重传:丢包兜底;
- 连接管理(三次握手/四次挥手):确保两端状态同步;
- 流量控制(接收窗口):别把对方缓冲区撑爆;
- 拥塞控制(拥塞窗口):别把网络链路堵死。
为了高效,它又加了一堆优化:
- 滑动窗口:并发发送,压扁等待时间;
- 快重传:3 个重复 ACK 就重发,不等超时;
- 延迟应答:等一等,可能通告更大窗口;
- 捎带应答:有数据要发?顺路把 ACK 带上!
这些机制环环相扣:
- 没有 ACK,滑动窗口不知道往哪滑;
- 没有拥塞控制,滑动窗口会把网络干崩;
- 没有延迟应答,窗口可能长期偏小,吞吐上不去;
- 没有捎带应答,交互式通信会多出一堆空包。
4. 其它
1. 面向字节流
创建一个 TCP socket,内核会自动给它配两个缓冲区:
- 发送缓冲区:你调 write() 写的数据,先扔进去,由 TCP 协议栈慢慢发;
- 接收缓冲区:对端发来的数据,先存这里,等你 read() 来取。
正因为有这两个缓冲区,读写完全解耦:
- 你可以一次 write(100),也可以 100 次 write(1) ------ 对 TCP 来说,都是一串连续的字节;
- 对方可以一次 read(100),也可以 100 次 read(1) ------ 它看到的只是缓冲区里的一堆字节,根本不知道你是怎么写的。
这就是"面向字节流 "的本质:没有消息边界。
对比 UDP 的"面向数据报":你发一个包,对方收一个包,包和包之间天然隔离。而 TCP 不是这样。它把所有数据熔成一锅粥,按序号排好,倒进接收缓冲区。应用层从里面舀汤喝,但没人告诉你"这一勺是一个请求,下一勺是另一个响应"。
面向字节流:缓冲区是核心。
2. 粘包问题
粘包"这个词容易误导人------好像 TCP 把包"粘"错了。其实 TCP 根本没"包"的概念!所谓的"包",是应用层自定义的消息单元 。TCP 只负责按序交付字节,至于你怎么切分这些字节,它不管。
为什么会"粘"?
- 应用层发了两条消息:"Hello" 和 "World";
- TCP 可能合并成一个报文段发出去(Nagle 算法);
- 或者分成多个报文段,但接收方一次 read() 全读回来了;
- 结果应用层拿到 "HelloWorld",傻眼了:这是 1 个消息?还是 2 个?
更糟的是"拆包":一个长消息被切成两段,第一次 read() 只拿到一半,程序误以为是完整消息,解析出错。
所以粘包/拆包的本质是:应用层无法从字节流中还原出原始消息边界。
怎么解决?三种主流方案:
- 定长消息
每条消息固定 N 字节。读的时候每次读 N 字节就行。
简单粗暴,但浪费空间(短消息也要补全),一般只用于内部高性能通信。 - 带长度头的变长消息
在每条消息前加 4 字节(或 2 字节)表示"后面跟多少字节"。
例如:len=5Hellolen=5World
接收方先读 4 字节得到 len,再读 len 字节,就精准切出一条消息。
这是最常用、最可靠的方式(HTTP/2、Protobuf、Redis 协议都这么干)。 - 特殊分隔符
用 \n、\r\n 或其他不会出现在正文中的字符做分隔。
例如 HTTP/1.1 的 header 就用 \r\n\r\n 分隔头部和 body。
缺点:正文不能包含分隔符,否则要转义,增加复杂度。
记住:粘包问题永远在应用层解决,TCP 层无能为力。
3. TCP 异常情况
TCP 连接是两个进程之间的状态。一旦一方出问题,连接就可能"假死"或"半开",连接不是永生的。
场景 1:客户端进程退出(正常 or 异常)
- 进程退出 → OS 关闭其所有文件描述符 → socket 被 close;
- 内核自动发送 FIN → 进入四次挥手流程;
- 服务端收到 FIN 后,也会走完挥手,连接正常释放。
这是最干净的情况,TCP 自己能处理。
场景 2:客户端主机重启
- 重启前,OS 会先终止所有进程 → 同场景 1,正常挥手;
- 如果是强制断电(来不及挥手),那就变成"突然断网",见下一条。
场景 3:物理断网(拔网线)
- 客户端视角:网卡 down 了,本地立刻知道连接失效,直接释放资源;
- 服务端视角:完全不知情!它还以为连接好着,继续往缓冲区塞数据;
- 如果服务端一直不发数据,连接会永久挂在那里(半开连接);
- 如果服务端尝试发数据,因为收不到 ACK,会不断重传;
- 重传超时(通常几分钟后),才判定对端不可达,释放连接。
为了解决"服务端不知道客户端挂了"的问题,TCP 提供了 TCP Keep-Alive(保活机制):
- 开启后,如果连接空闲超过一定时间(默认 2 小时),会发送探测包;
- 连续几次没回应,就认为对端死了,关闭连接。
但现实中很少用 TCP Keep-Alive,因为:
- 默认超时太长(小时级),业务等不了;
- 它只能检测"连接是否通",不能判断"应用是否活着"(比如进程卡死但 TCP 栈还在回 ACK)。
场景 4:服务端断网又恢复
- 客户端以为连接还在,继续发数据;
- 服务端重启后,内核已清空所有连接状态;
- 当它收到客户端的数据包(带旧 seq 号),发现"这连接我根本不认识";
- 于是回复一个 RST(复位)包,强制关闭这个"幽灵连接";
- 客户端收到 RST,就知道连接已失效,需要重新三次握手。
真正靠谱的保活:心跳机制(应用层)
既然 TCP 层的 Keep-Alive 不够用,那怎么办?
答案:自己在应用层实现心跳。
- 客户端每隔 30 秒发一个 {"type": "ping"};
- 服务端回一个 {"type": "pong"};
- 如果连续几次没收到 pong,就认为对端宕机,主动关闭连接。
这就是**"心跳机制"**。
它的好处:
- 时间可控(秒级);
- 能验证整个链路 + 应用逻辑是否正常(不只是网络通);
- 可携带业务信息(比如上报状态)。
几乎所有长连接服务都靠心跳维持连接有效性。
4. 用UDP实现可靠传输
在它之上叠加适当的控制逻辑,就能构建出满足业务需求的可靠通道。
要做的,就是回答三个问题:
- 怎么知道对方收到了? → ACK;
- 怎么知道数据顺序对不对? → 序列号;
- 没收到怎么办? → 超时重传(+ 快速重传)。
剩下的,比如要不要窗口、要不要拥塞控制、ACK 频率多高......全看你的场景。可以做一个极简版(只保不丢),也可以做一个 TCP Pro Max(带拥塞控制、选择性确认、快速恢复)。