文章目录
- [📋 基于 LangChain、RAG、LoRA 的知识库问答客服系统](#📋 基于 LangChain、RAG、LoRA 的知识库问答客服系统)
-
- [🎯 1. 项目概述](#🎯 1. 项目概述)
- [🏗️ 2. 系统架构](#🏗️ 2. 系统架构)
- [📊 3. 数据准备](#📊 3. 数据准备)
-
- [3.1 数据集格式](#3.1 数据集格式)
- [3.2 数据增强](#3.2 数据增强)
- [🔧 4. 详细实现方案](#🔧 4. 详细实现方案)
-
- [4.1 环境准备](#4.1 环境准备)
- [4.2 资源下载与配置](#4.2 资源下载与配置)
- [4.3 模型微调LoRA](#4.3 模型微调LoRA)
- [4.4 模型部署](#4.4 模型部署)
-
- [4.4.1 vLLM](#4.4.1 vLLM)
- [4.4.2 SGLang](#4.4.2 SGLang)
- [4.5 知识库](#4.5 知识库)
-
- [4.5.1 配置文件](#4.5.1 配置文件)
- [4.5.2 混合检索策略](#4.5.2 混合检索策略)
- [4.5.3 知识库构建与演示](#4.5.3 知识库构建与演示)
- [4.6 RAG 总结](#4.6 RAG 总结)
- [4.7 Agent](#4.7 Agent)
- [5. 评估系统](#5. 评估系统)
-
- [5.1 RAGAS评估](#5.1 RAGAS评估)
- [5.2 评估指标](#5.2 评估指标)
- [6. 对话客服部署](#6. 对话客服部署)
📋 基于 LangChain、RAG、LoRA 的知识库问答客服系统
项目名称 : KB-CustomerService
基座模型 : Qwen2.5-3B-Instruct
核心架构 : LangChain + RAG + LoRA 微调
部署环境: 云服务器 + 4090 GPU
🎯 1. 项目概述
目标
构建一个基于企业知识库的单轮问答客服系统,用户提问后,系统从知识库检索相关信息,生成准确、专业的回答。
技术选型理由
| 组件 | 选择 | 理由 |
|---|---|---|
| 基座模型 | Qwen2.5-3B-Instruct | 指令跟随能力强,单轮问答优化,3B参数适合4090 |
| 微调方式 | LoRA | 轻量,快速,节省显存 |
| 向量库 | Milvus | 高性能,支持混合检索 |
| 框架 | LangChain | RAG 成熟框架 |
| 检索策略 | Dense + BM25 + RRF | 提高召回率 |
| 精排 | Cross-Encoder | 提高答案相关性 |
| 评估 | RAGAS | 标准化评估指标 |
🏗️ 2. 系统架构
用户提问 → 查询解析 → 混合检索 → 精排重排序 → 生成回答
↓ ↓ ↓
Milvus向量库 Cross-Encoder Qwen2.5-Instruct核心模块
- 知识库构建模块 - 文档处理、向量化
- 检索优化模块 - 混合检索、精排
- 问答生成模块 - Instruct 模型集成
- 评估监控模块 - 质量评估、性能监控
📊 3. 数据准备
数据集可以从HuggingFace社区获取,本次参考地址:对话数据集
3.1 数据集格式
注意:input不是用户的输入,而是上下文内容,包含额外信息/知识库内容
json
[
{
"instruction": "怎么查询订单状态?",
"input": "",
"output": "您可以在个人中心的订单页面查看订单状态。"
},
{
"instruction": "退货需要什么条件?",
"input": "",
"output": "退货条件:商品未使用、保留完整包装、7天内申请。"
}
]3.2 数据增强
简单同义词替换处理
python
# data/synonyms_augment.py
import random
import json
import os
SYNONYMS = {
"怎么": ["如何", "怎样"],
"查询": ["查看", "了解"],
"订单": ["购买记录", "交易"],
"退款": ["退钱", "返还"],
"物流": ["快递", "配送"],
"申请": ["提交申请", "办理"],
"修改": ["更改", "调整"],
"需要": ["要求", "必须"]
}
def simple_synonym_replace(text):
"""最简单的同义词替换"""
flag = 0
for word, syns in SYNONYMS.items():
if word in text and random.random() > 0.5:
text = text.replace(word, random.choice(syns), 1)
flag = 1
return flag, text
with open("./raw/output.json", "r", encoding="utf-8") as f:
data = json.load(f)
ls = []
for item in data:
flag, text = simple_synonym_replace(item["instruction"])
if flag == 1:
item["instruction"] = text
ls.append(item)
out_dir = "./processed"
# 确保out_dir存在
if not os.path.exists(out_dir):
os.makedirs(out_dir)
print("数据增强生效的样本数量:", len(ls))
# for i, item in enumerate(ls):
# print(item["instruction"], item["output"])
# if i == 10:
# break
data.extend(ls)
with open(out_dir+"/aug_output.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)执行后:

此时本地的项目目录为:
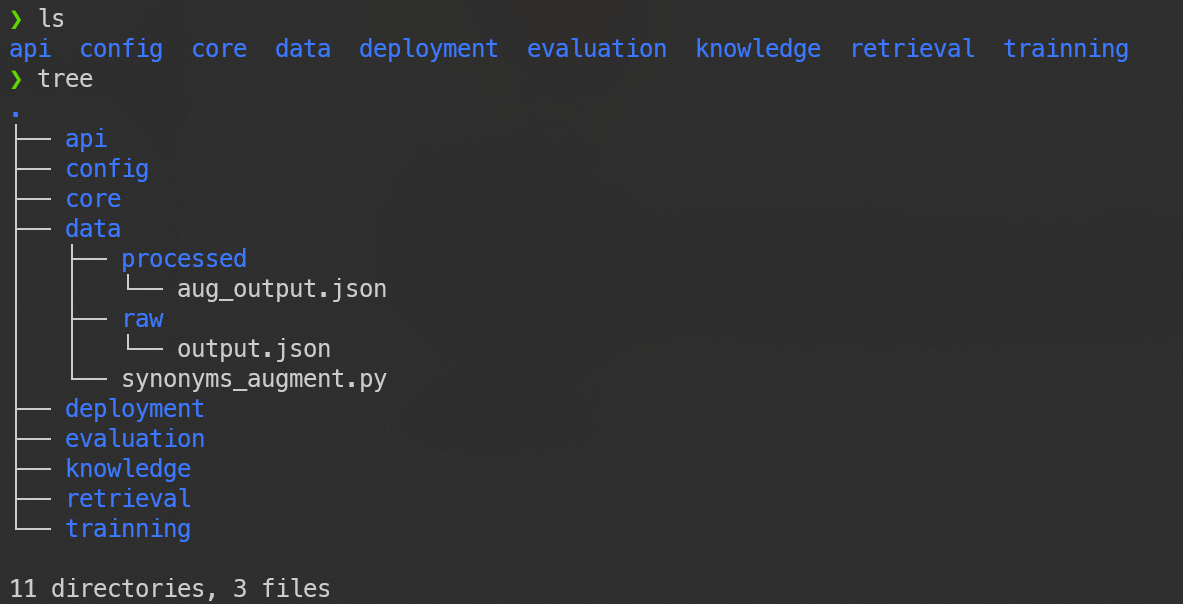
上传至云服务器:

🔧 4. 详细实现方案
4.1 环境准备
这里建议看我的上篇文章的云服务器环境搭建:待补充
bash
# 基础环境
# python3.11
# vllm torch ...
# 核心依赖
pip install transformers torch accelerate
pip install peft bitsandbytes
pip install langchain langchain-community
pip install pymilvus sentence-transformers
# 评估工具
pip install ragas datasets4.2 资源下载与配置
将Qwen2.5-3B-Instruct基座模型下载到云服务器:
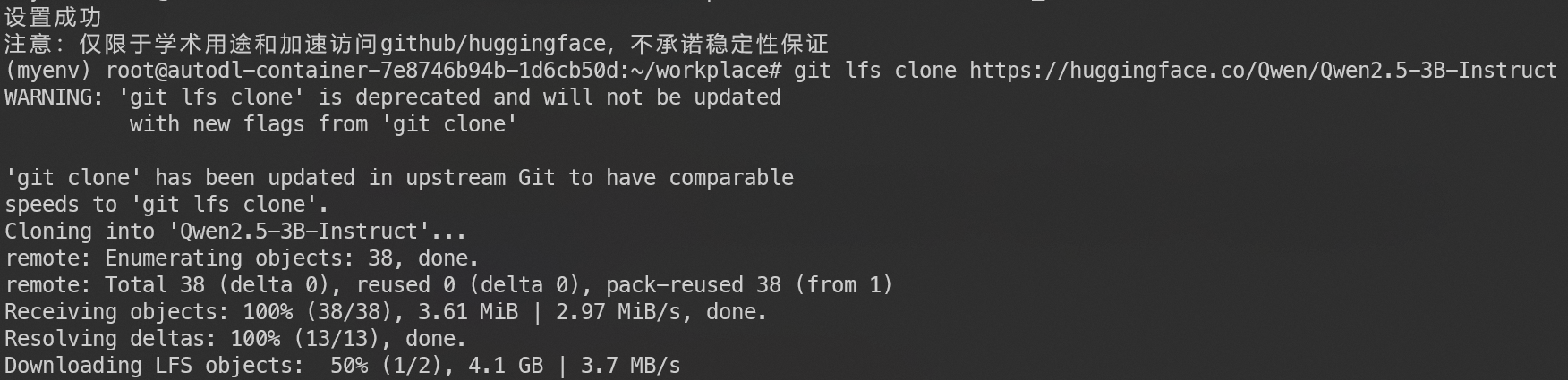
LLaMA-Factory,称之为拉马工厂,能够可视化训练过程,参数可选,比较好用
拉取LLaMA-Factory并安装环境:
bash
# 拉取指令
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 安装指令
cd LLaMA-Factory
# 安装依赖
pip install -e .然后将拉马工厂和模型都放在项目目录里:
接下来,为了正常使用拉马工厂,需要修改一些配置,修改src目录下的webui.py:

为了能够使用可视化界面,需要配置dataset_info.json文件(一定要和数据集放在同一个目录):

4.3 模型微调LoRA
在Llama-factory所在目录执行命令:python LLaMA-Factory/src/webui.py
此时,打开云服务器界面,按序操作:
在浏览器粘贴,可以看到该界面:
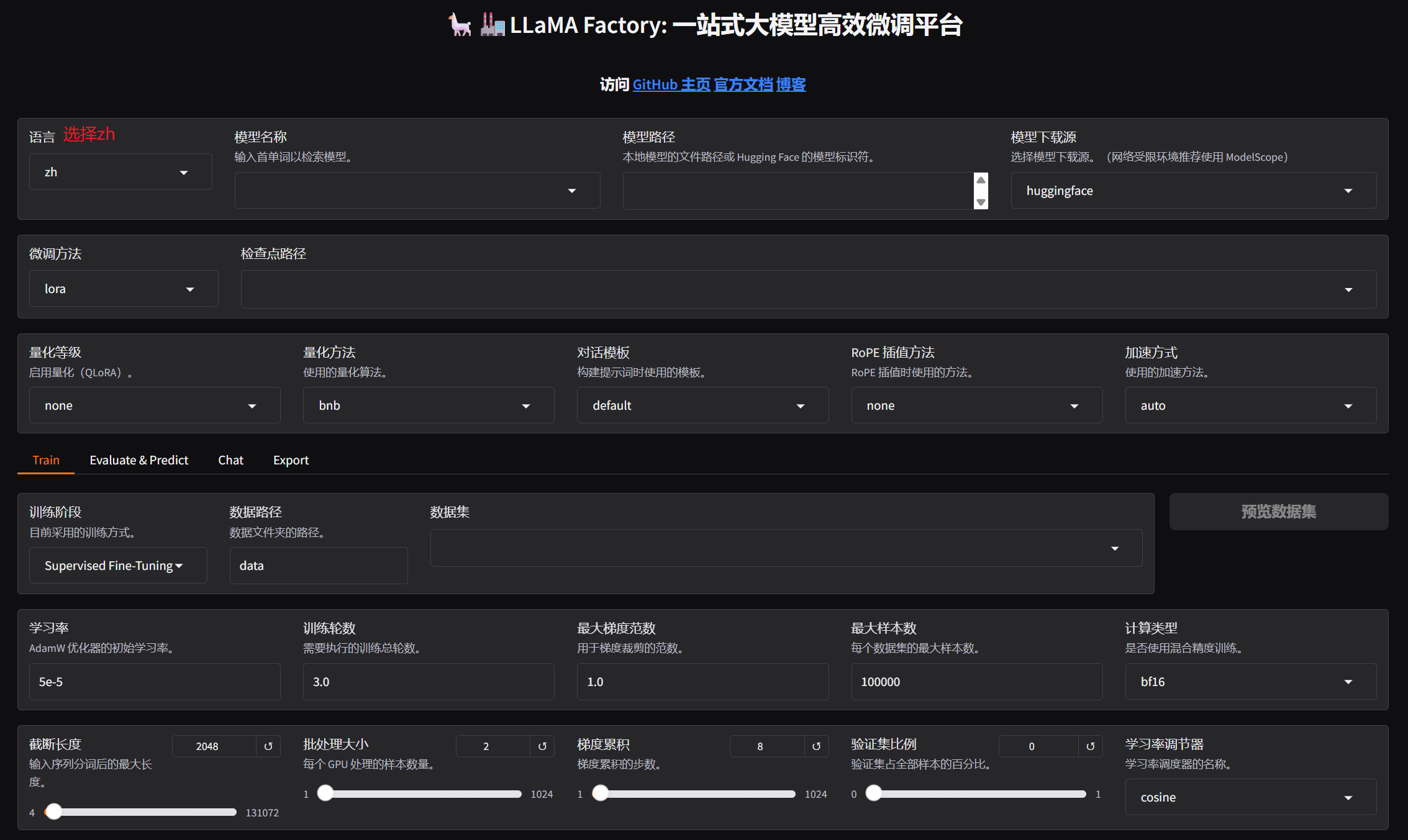
填写完训练参数后,点击预览命令,得到:
建议提前下载一个量化库:pip install bitsandbytes
bash
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path ./Qwen/Qwen2.5-3B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data/processed \
--dataset robot-qa \
--cutoff_len 2048 \
--learning_rate 0.0001 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 32 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 10 \
--save_steps 150 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to none \
--output_dir saves/Qwen2.5-3B-Instruct/lora/train_2026-04-19-23-55-06 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--quantization_bit 8 \
--quantization_method bnb \
--double_quantization True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target q_proj,v_proj然后直接点击开始训练:
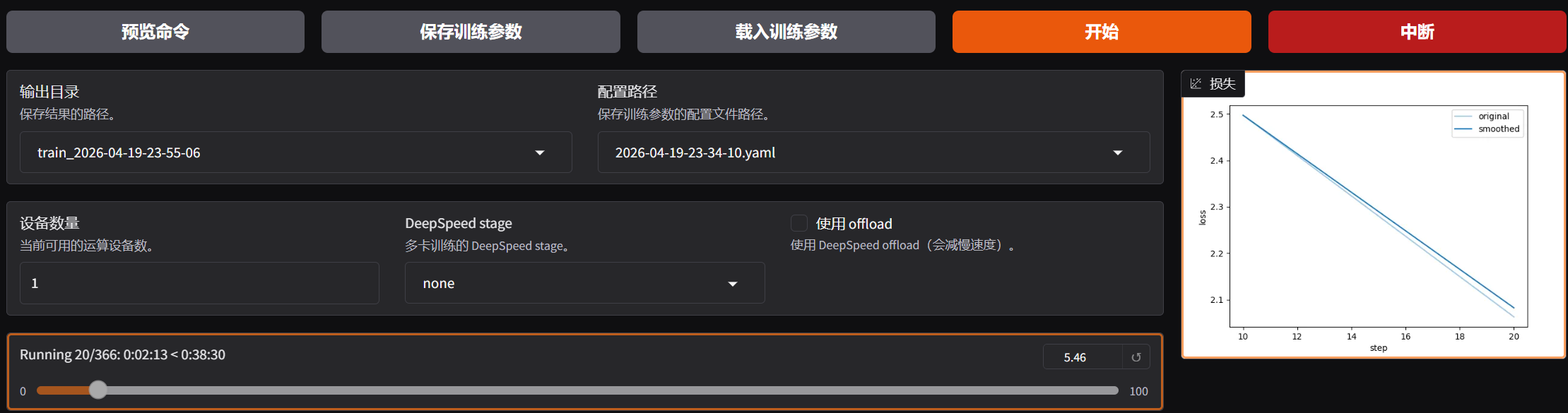
批次32其实有点太大,实际训练可改为16,更为稳妥:

训练结束:
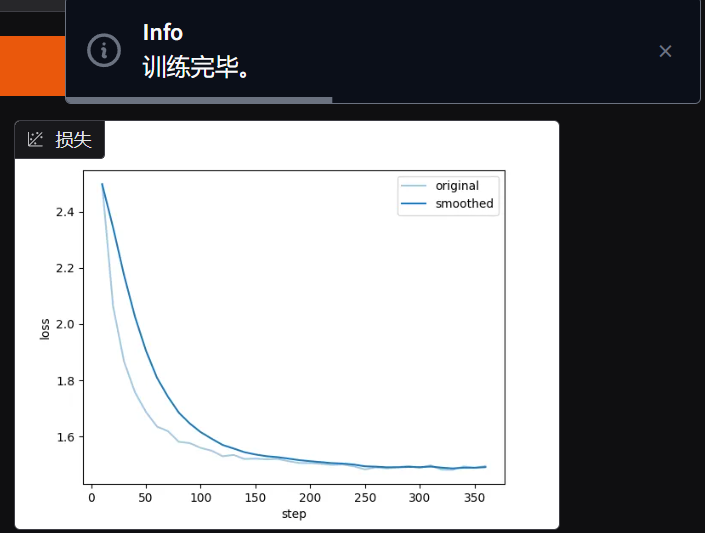
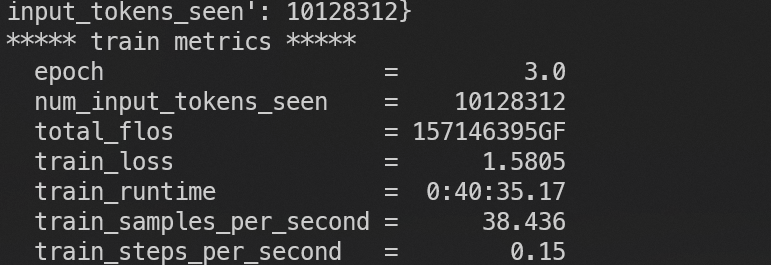
然后我们就可以部署使用微调后的客户风格模型了
4.4 模型部署
提供vLLM和SGLang两种部署方案,这里由于云服务器限制,我选择vLLM
4.4.1 vLLM
在项目目录执行:
bash
python -m vllm.entrypoints.openai.api_server \
--model ./Qwen2.5-3B-Instruct \
--enable-lora \
--lora-modules customer_service=./lora \
--host 0.0.0.0 \
--port 6006 \
--served-model-name customer_service \
--max-model-len 4096 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes部署成功的图例:
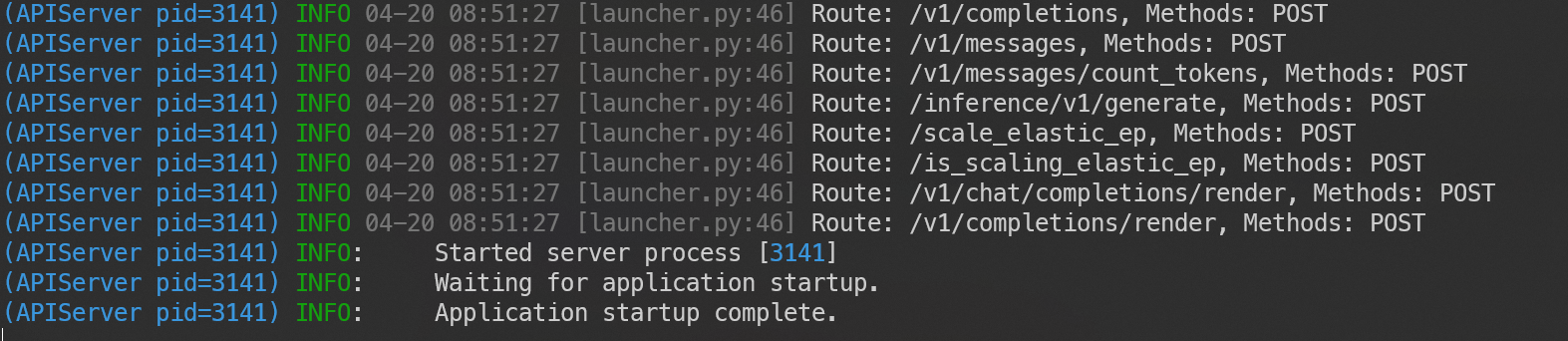
简单测试调用:
bash
curl -X POST http://localhost:6006/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "customer_service",
"prompt": "是否有货?",
"max_tokens": 100,
"temperature": 0.7
}'回答如下:

4.4.2 SGLang
不幸的是,之前安装的vLLM版本与这里的冲突
建议新建一个conda环境,然后执行安装依赖的命令
bash
# 使用稳定的python3.10
conda create -n sgl_cuda12 python=3.10 -y
conda activate sgl_cuda12
# 装 CUDA12 对齐的 torch
pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# 装 sglang
pip install sglang执行命令:
可能会出现部分依赖冲突,借助gpt修正即可
bash
sglang serve \
--model-path Qwen/Qwen2.5-3B-Instruct \
--lora-path ./lora/kf \
--attention-backend triton \
--sampling-backend pytorch \
--disable-cuda-graph \
--port 6006 \
--host 0.0.0.04.5 知识库
由于pymilvus向量数据库在python3.10版本能够稳定使用,所以需要用conda来创建3.10版本的python环境
不用担心,按照代码报错来安装库就可以,一般都可以成功run起来!
这里为了方便,我把文档加载、切片、向量化、向量入库都写进了同一个py文件,混合检索独占一个文件。
4.5.1 配置文件
将json文件和读取json的py文件放入config目录
agent_config.json:
json
{
"knowledge_source_path": "/knowledge/data",
"knowledge_base_path": "/knowledge/db/milvus_kb.db",
"documents_path": "/knowledge/documents/",
"base_model": "/config/qwen2.5-3B-Instruct",
"vllm_endpoint": "https://u952005-ade7-00405470.westc.seetacloud.com:8443/v1",
"vllm_endpoint": "http:127.0.0.1:6006/v1", # 二选一
"embedding_model": "/config/bge-small-zh-v1.5",
"cross_encoder_model": "/config/mmarco-mMiniLMv2-L12-H384-v1",
"embedding_dimension": 512,
"chunk_size": 512,
"chunk_overlap": 100,
"system_prompt": "/core/prompts/system_prompt.txt",
"rag_summize_prompt": "/core/prompts/rag_prompt.txt"
}config_loader.py
python
# config/config_loader.py
import json
from pathlib import Path
from typing import Dict, Any
import logging
logger = logging.getLogger(__name__)
class ConfigLoader:
"""配置加载器"""
def __init__(self):
"""初始化配置加载器"""
self.config = {}
# 项目根目录:config_loader.py 的父目录的父目录
self.project_root = Path(__file__).parent.parent
def load_json(self, config_file: str) -> Dict[str, Any]:
"""加载JSON配置"""
try:
# 如果是相对路径,则相对于当前文件所在目录
if not Path(config_file).is_absolute():
config_file = Path(__file__).parent / config_file
with open(config_file, 'r', encoding='utf-8') as f:
self.config = json.load(f)
return self.config
except Exception as e:
logger.error(f"❌ JSON配置加载失败 {config_file}: {e}")
raise
def get(self, key: str, default: Any = None) -> Any:
"""获取配置值,自动解析以 / 开头的路径"""
value = self.config.get(key, default)
if value is None:
return default
# 如果是字符串且以 / 开头,则视为路径,解析为绝对路径
if isinstance(value, str) and value.startswith("/"):
return str(self.project_root / value.lstrip("/"))
return value
loader = ConfigLoader()
loader.load_json("agent_config.json")4.5.2 混合检索策略
bash
# /knowledge/hybridRetriever.py
import sys
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent.parent))
import os
import json
import hashlib
from typing import List, Dict, Any
import logging
from sentence_transformers import SentenceTransformer, CrossEncoder
from rank_bm25 import BM25Okapi
from config.config_loader import loader
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class HybridRetriever:
"""混合检索器(向量检索 + BM25 + RRF + Cross-Encoder精排)"""
def __init__(self, chunks: List[Dict[str, Any]], embedder,
cross_encoder_model: str = loader.get("cross_encoder_model")):
"""
初始化混合检索器
Args:
chunks: 所有的chunk数据
embedder: 向量化引擎
cross_encoder_model: 交叉编码器模型
"""
self.chunks = chunks
self.embedder = embedder
# 初始化BM25
self.corpus = [chunk["content"] for chunk in chunks]
self.bm25 = BM25Okapi(
[chunk["content"].split() for chunk in chunks]
)
logger.info("初始化BM25引擎完成")
# 初始化Cross-Encoder
try:
self.cross_encoder = CrossEncoder(cross_encoder_model)
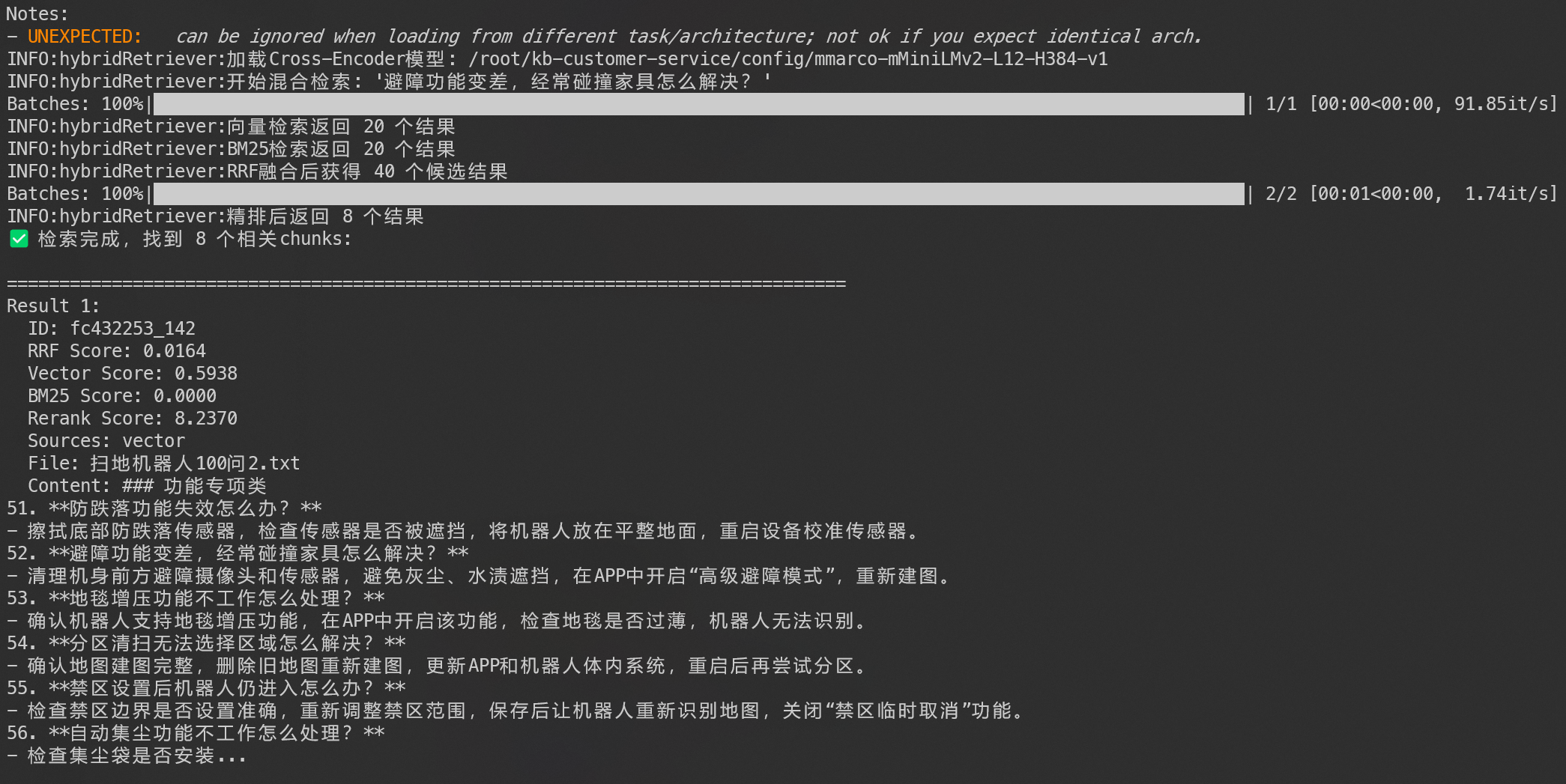
logger.info(f"加载Cross-Encoder模型: {cross_encoder_model}")
except Exception as e:
logger.warning(f"Cross-Encoder加载失败: {e},将跳过精排")
self.cross_encoder = None
def vector_search(self, store, query_vector: List[float], collection_name: str,
top_k: int = 8) -> List[Dict[str, Any]]:
"""向量检索"""
# 兼容两种调用方式:MilvusLiteStore 或 MilvusClient
client = store.client if hasattr(store, 'client') else store
res = client.search(
collection_name=collection_name,
data=[query_vector],
limit=top_k,
output_fields=["content", "metadata", "source_file"]
)
results = []
for hit in res[0]:
results.append({
"id": hit["id"],
"score": hit["distance"],
"content": hit["entity"]["content"],
"metadata": json.loads(hit["entity"]["metadata"]),
"source_file": hit["entity"]["source_file"]
})
return results
def bm25_search(self, query: str, top_k: int = 8) -> List[Dict[str, Any]]:
"""BM25关键词检索"""
query_tokens = query.split()
scores = self.bm25.get_scores(query_tokens)
# 获取top_k的索引
top_indices = sorted(
range(len(scores)),
key=lambda i: scores[i],
reverse=True
)[:top_k]
results = []
for idx in top_indices:
chunk = self.chunks[idx]
results.append({
"id": chunk["id"],
"score": float(scores[idx]),
"content": chunk["content"],
"metadata": chunk["metadata"],
"source_file": chunk["source_file"]
})
return results
def rrf_fusion(self, vector_results: List[Dict], bm25_results: List[Dict],
k: float = 60.0) -> Dict[str, Dict]:
"""
RRF (Reciprocal Rank Fusion) 融合两种检索结果
RRF公式: score = 1 / (k + rank)
Args:
vector_results: 向量检索结果
bm25_results: BM25检索结果
k: 平滑系数,默认60
Returns:
融合后的结果字典 {doc_id: {score, ..., sources: [vector, bm25]}}
"""
fused_scores = {}
# 处理向量检索结果
for rank, result in enumerate(vector_results, 1):
doc_id = result["id"]
rrf_score = 1 / (k + rank)
if doc_id not in fused_scores:
fused_scores[doc_id] = {
"rrf_score": 0,
"vector_score": result["score"],
"bm25_score": 0,
"sources": [],
**result
}
fused_scores[doc_id]["rrf_score"] += rrf_score
if "vector" not in fused_scores[doc_id]["sources"]:
fused_scores[doc_id]["sources"].append("vector")
# 处理BM25结果
for rank, result in enumerate(bm25_results, 1):
doc_id = result["id"]
rrf_score = 1 / (k + rank)
if doc_id not in fused_scores:
fused_scores[doc_id] = {
"rrf_score": 0,
"vector_score": 0,
"bm25_score": result["score"],
"sources": [],
**result
}
else:
fused_scores[doc_id]["bm25_score"] = result["score"]
fused_scores[doc_id]["rrf_score"] += rrf_score
if "bm25" not in fused_scores[doc_id]["sources"]:
fused_scores[doc_id]["sources"].append("bm25")
# 按RRF分数排序
sorted_results = sorted(
fused_scores.items(),
key=lambda x: x[1]["rrf_score"],
reverse=True
)
return dict(sorted_results)
def rerank_with_cross_encoder(self, query: str, fused_results: Dict,
top_k: int = 5) -> List[Dict[str, Any]]:
"""
使用Cross-Encoder进行精排
Args:
query: 查询文本
fused_results: 融合后的结果
top_k: 返回的top_k结果
Returns:
精排后的结果
"""
if not self.cross_encoder:
# 如果没有Cross-Encoder,直接返回融合结果的top_k
results = list(fused_results.values())[:top_k]
for r in results:
r["rerank_score"] = r.get("rrf_score", 0)
return results
# 准备交叉编码器的输入
query_doc_pairs = [
(query, result["content"])
for result in fused_results.values()
]
# 获取Cross-Encoder分数
cross_encoder_scores = self.cross_encoder.predict(query_doc_pairs)
# 更新结果并排序
results = list(fused_results.values())
for i, result in enumerate(results):
result["rerank_score"] = float(cross_encoder_scores[i])
# 按Cross-Encoder分数排序
results = sorted(
results,
key=lambda x: x["rerank_score"],
reverse=True
)[:top_k]
return results
def hybrid_search(self, store, query: str, collection_name: str,
top_k: int = 5) -> List[Dict[str, Any]]:
"""
混合检索主函数
流程:
1. 向量检索 + BM25检索
2. RRF融合
3. Cross-Encoder精排
Args:
store: Milvus存储实例
query: 查询文本
collection_name: 集合名称
top_k: 返回结果数
Returns:
精排后的检索结果
"""
logger.info(f"开始混合检索: '{query}'")
# 1. 向量检索
query_vector = self.embedder.encode(query)
query_vector = query_vector.tolist() if hasattr(query_vector, 'tolist') else query_vector
vector_results = self.vector_search(store, query_vector, collection_name, top_k=20)
logger.info(f"向量检索返回 {len(vector_results)} 个结果")
# 2. BM25检索
bm25_results = self.bm25_search(query, top_k=20)
logger.info(f"BM25检索返回 {len(bm25_results)} 个结果")
# 3. RRF融合
fused_results = self.rrf_fusion(vector_results, bm25_results)
logger.info(f"RRF融合后获得 {len(fused_results)} 个候选结果")
# 4. Cross-Encoder精排
final_results = self.rerank_with_cross_encoder(query, fused_results, top_k=top_k)
logger.info(f"精排后返回 {len(final_results)} 个结果")
return final_results4.5.3 知识库构建与演示
主要有两个执行函数:create 和 test_retrieval,前者是流程综合,后者是检索测试
python
# /knowledge/build_kb_langchain.py
import sys
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent.parent))
from langchain_text_splitters import RecursiveCharacterTextSplitter
import os
import json
import hashlib
from typing import List, Dict, Any
import logging
from sentence_transformers import SentenceTransformer, CrossEncoder
from rank_bm25 import BM25Okapi
from hybridRetriever import HybridRetriever
from config.config_loader import loader
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# ========== LangChain文档处理 ==========
def load_documents(docs_dir: Path) -> List[Dict[str, Any]]:
"""使用LangChain加载文档"""
from langchain_community.document_loaders import (
PyPDFLoader,
TextLoader,
DirectoryLoader
)
all_docs = []
# 加载PDF文件
try:
pdf_loader = DirectoryLoader(
str(docs_dir),
glob="**/*.pdf",
loader_cls=PyPDFLoader,
show_progress=True
)
pdf_docs = pdf_loader.load()
all_docs.extend(pdf_docs)
logger.info(f"加载 {len(pdf_docs)} 个PDF文档")
except Exception as e:
logger.error(f"PDF加载失败: {e}")
# 加载TXT文件
try:
txt_loader = DirectoryLoader(
str(docs_dir),
glob="**/*.txt",
loader_cls=TextLoader,
show_progress=True
)
txt_docs = txt_loader.load()
all_docs.extend(txt_docs)
logger.info(f"加载 {len(txt_docs)} 个TXT文档")
except Exception as e:
logger.error(f"TXT加载失败: {e}")
return all_docs
def split_documents(docs: List, chunk_size: int = 500, overlap: int = 50) -> List[Dict[str, Any]]:
"""使用递归字符分割器"""
# 配置分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap,
length_function=len,
separators=[
"\n\n", # 段落
"\n", # 换行
"。", # 中文句子
"!", # 中文感叹
"?", # 中文问号
";", # 中文分号
".", # 英文句号
"!", # 英文感叹
"?", # 英文问号
";", # 英文分号
" ", # 空格
"" # 最后按字符分割
]
)
# 分割文档 chunks = List[Dict[str, Any]]
chunks = text_splitter.split_documents(docs)
# 转换为标准化格式
processed_chunks = []
for i, chunk in enumerate(chunks):
# 生成唯一ID(基于内容和索引)
chunk_id = f"{hashlib.md5(chunk.metadata.get('source', '').encode()).hexdigest()[:8]}_{i}"
# 构建metadata
metadata = {
"source": Path(chunk.metadata.get('source', 'unknown')).name,
"file_path": chunk.metadata.get('source', ''),
"page": chunk.metadata.get('page', 0),
"chunk_index": i,
**chunk.metadata # 可能包含其他原始metadata字段
}
processed_chunks.append({
"id": chunk_id,
"content": chunk.page_content,
"metadata": metadata,
"source_file": Path(metadata["source"]).name
})
# 如果"./documents"目录下没有文件,就将chunks保存到本地JSON文件,方便调试
if not any(Path(loader.get("documents_path")).iterdir()):
with open(loader.get("documents_path") + "/chunks.json", "w", encoding="utf-8") as f:
json.dump(processed_chunks, f, ensure_ascii=False, indent=2)
logger.info("已将chunks保存到 " + loader.get("documents_path") + "/chunks.json 以供调试")
logger.info(f"分割完成: {len(chunks)} 个chunks")
return processed_chunks
# ========== 向量化(bge-small-zh-v1.5) ==========
class EmbeddingEngine:
"""向量化引擎"""
def __init__(self, model_path: str = loader.get("embedding_model")):
logger.info("加载embedding模型...")
self.model = SentenceTransformer(model_path)
self.dim = self.model.get_embedding_dimension()
logger.info(f"向量维度: {self.dim}") # 512
def encode_documents(self, texts: List[str]) -> List[List[float]]:
"""向量化文档"""
texts_with_prefix = [f"为这个句子生成表示以用于检索相关文章: {text}" for text in texts]
return self.model.encode(
texts_with_prefix,
normalize_embeddings=True,
show_progress_bar=True
)
def encode_queries(self, queries: List[str]) -> List[List[float]]:
"""查询向量化(搜索用)"""
queries_with_prefix = [f"为这个句子生成表示以用于检索相关文章:{query}" for query in queries]
return self.model.encode(
queries_with_prefix,
normalize_embeddings=True
)
def encode(self, query: str) -> List[float]:
"""编码单个查询"""
return self.encode_queries([query])[0]
# ========== Milvus Lite存储 ==========
class MilvusLiteStore:
"""Milvus Lite存储"""
def __init__(self, db_path: str = loader.get("knowledge_base_path")):
from pymilvus import MilvusClient
self.db_path = db_path
self.client = MilvusClient(self.db_path)
self.collection_name = "customer_service_kb"
self.dimension = 512 # BGE-small默认维度
def create_collection(self, recreate: bool = True):
"""recreate=True表示如果集合已存在则删除重建"""
from pymilvus import CollectionSchema, FieldSchema, DataType
if self.client.has_collection(collection_name=self.collection_name):
if recreate:
logger.info(f"删除已有集合: {self.collection_name}")
self.client.drop_collection(collection_name=self.collection_name)
else:
logger.info(f"集合已存在: {self.collection_name}")
return
# 定义schema,指定id为string类型
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=100),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=self.dimension),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="metadata", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="source_file", dtype=DataType.VARCHAR, max_length=255),
FieldSchema(name="chunk_index", dtype=DataType.INT64)
]
schema = CollectionSchema(fields=fields, description="Customer Service Knowledge Base")
# 在向量字段上创建索引
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX"
)
self.client.create_collection(
collection_name=self.collection_name,
schema=schema,
index_params=index_params
)
logger.info(f"创建集合成功: {self.collection_name}")
def insert_chunks(self, chunks: List[Dict[str, Any]], vectors: List[List[float]]):
"""插入chunks和对应的向量"""
if len(chunks) != len(vectors):
raise ValueError("chunks和vectors数量不匹配")
data = []
for chunk, vector in zip(chunks, vectors):
data.append({
"id": chunk["id"],
"vector": vector,
"content": chunk["content"],
"metadata": json.dumps(chunk["metadata"], ensure_ascii=False),
"source_file": chunk["source_file"],
"chunk_index": chunk["metadata"]["chunk_index"]
})
res = self.client.insert(
collection_name=self.collection_name,
data=data
)
logger.info(f"插入 {res['insert_count']} 个chunks")
return res
# ========== 存储流程 ==========
def create():
"""主构建函数"""
print("🧠 开始构建知识库 (LangChain + Milvus Lite)...")
print("=" * 60)
# 配置
docs_dir = loader.get("knowledge_source_path")
db_path = loader.get("knowledge_base_path")
# 1. 检查文档目录
if not docs_dir:
print(f"❌ 文档目录为空: {docs_dir}")
print("请将PDF/TXT文件放入 documents/ 目录")
return
# 2. 使用LangChain加载文档
print(f"📄 加载文档...")
docs = load_documents(docs_dir)
if not docs:
print("❌ 未加载到任何文档")
return
print(f"✅ 加载 {len(docs)} 个文档")
# 3. 使用递归字符分割器
print(f"\n✂️ 分割文档...")
chunks = split_documents(docs, chunk_size=512, overlap=100)
if not chunks:
print("❌ 分割失败")
return
print(f"✅ 分割完成: {len(chunks)} 个chunks")
# 4. 向量化
print(f"\n🔢 向量化chunks...")
try:
embedder = EmbeddingEngine()
texts = [chunk["content"] for chunk in chunks]
vectors = embedder.encode_documents(texts)
print(f"✅ 向量化完成 (维度: {embedder.dim})")
except Exception as e:
print(f"❌ 向量化失败: {e}")
# 5. 存储到Milvus Lite
print(f"\n💾 存储到Milvus Lite...")
try:
store = MilvusLiteStore(db_path=db_path)
store.create_collection(recreate=True)
store.insert_chunks(chunks, vectors)
print(f"✅ 存储完成: {len(chunks)} 个chunks")
except Exception as e:
print(f"❌ 存储失败: {e}")
# 检索测试
def test_retrieval(query: str):
print(f"\n🔍 测试检索: '{query}'")
try:
# 1. 初始化embedder
embedder = EmbeddingEngine()
# 2. 加载Milvus存储
store = MilvusLiteStore(db_path= loader.get("knowledge_base_path"))
# 3. 加载所有chunks用于BM25(实际应用中可以优化为只加载必要字段)
# 为了演示,我们从JSON文件读取chunks
chunks_file = Path(loader.get("documents_path")) / "chunks.json"
if not chunks_file.exists():
print("❌ chunks.json文件不存在,请先运行create()构建知识库")
return
with open(chunks_file, "r", encoding="utf-8") as f:
chunks = json.load(f)
# 4. 初始化混合检索器
retriever = HybridRetriever(chunks, embedder)
# 5. 执行混合检索
results = retriever.hybrid_search(store, query, store.collection_name, top_k=8)
print(f"✅ 检索完成,找到 {len(results)} 个相关chunks:")
for i, res in enumerate(results, 1):
print(f"\n{'='*80}")
print(f"Result {i}:")
print(f" ID: {res.get('id', 'N/A')}")
print(f" RRF Score: {res.get('rrf_score', 0):.4f}")
print(f" Vector Score: {res.get('vector_score', 0):.4f}")
print(f" BM25 Score: {res.get('bm25_score', 0):.4f}")
print(f" Rerank Score: {res.get('rerank_score', 0):.4f}")
print(f" Sources: {', '.join(res.get('sources', []))}")
print(f" File: {res.get('source_file', 'N/A')}")
print(f" Content: {res['content'][:400]}...")
except Exception as e:
print(f"❌ 检索失败: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
create()
test_retrieval("机器人如何保养")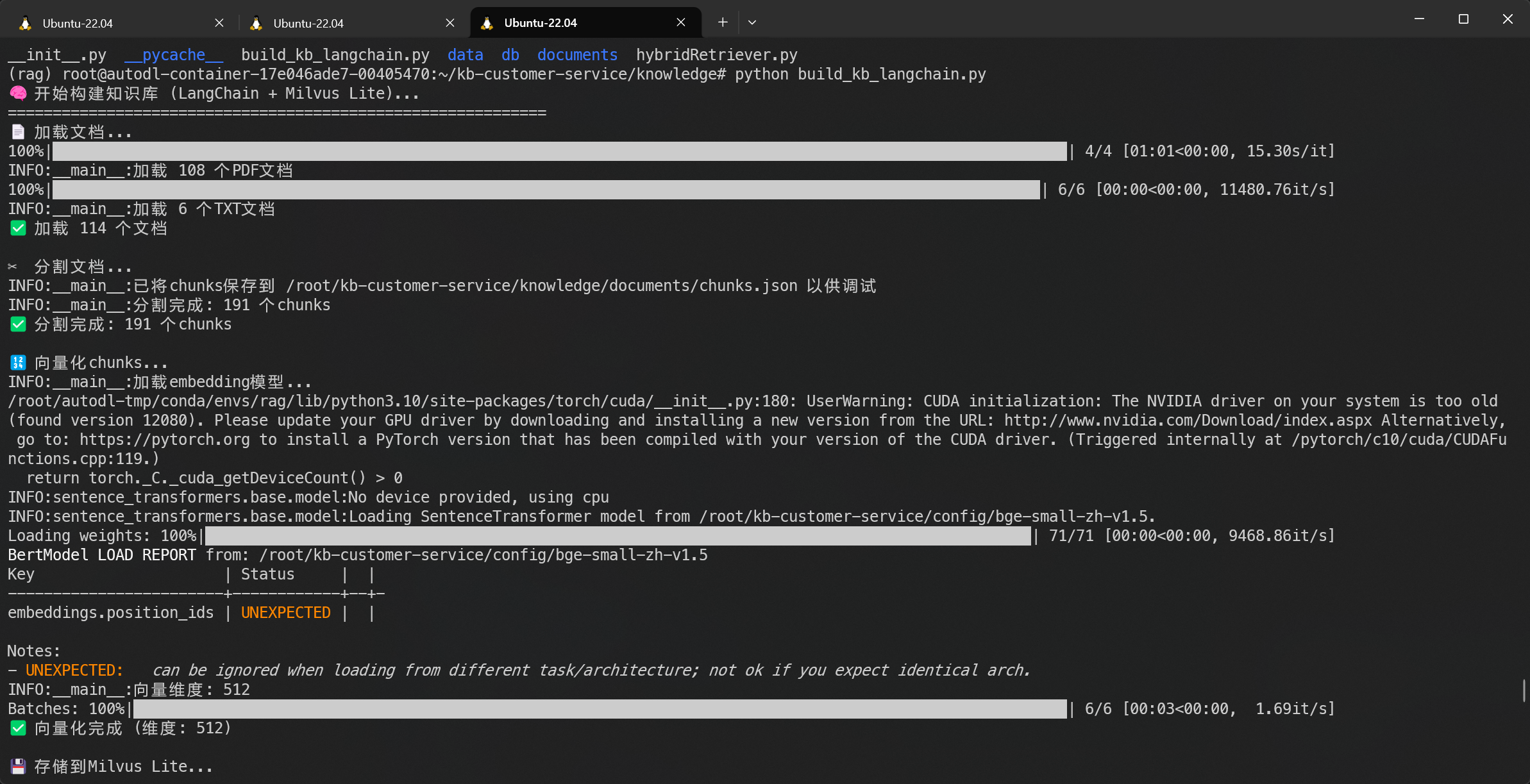
4.6 RAG 总结
该项目中,我需要把RAG的整个流程封装为一个工具,供agent 自主 调用。
该代码算是该项目最复杂的一环了,但是逻辑是比较清晰的。
封装的代码如下:
python
# core/rag_summize.py
"""
rag 总结服务
"""
import sys
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent.parent))
import json
import logging
from typing import List, Dict, Any, Optional
from config.config_loader import loader
from knowledge.hybridRetriever import HybridRetriever
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import PromptTemplate
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 自定义可视化
def print_prompt(prompt):
print("="*25)
print(prompt.to_string())
print("="*25)
return prompt
class RagSummarize:
def __init__(
self,
# 向量库路径
knowledge_base_path: str = loader.get("knowledge_base_path"),
# vLLM API端点
vllm_endpoint: str = loader.get("vllm_endpoint"),
# 本地embedding模型路径
embedding_model_path: str = loader.get("embedding_model")
):
# 初始化参数
self.kb_path = knowledge_base_path
self.vllm_endpoint = vllm_endpoint
self.embedding_model_path = embedding_model_path
# 初始化组件
self._init_knowledge_base()
self._init_llm_client()
self._init_embedding_model()
self._init_hybrid_retriever()
self._init_prompt_templates()
self.prompt_template = PromptTemplate.from_template(self.prompt_text)
self.chain = self._init_chain()
logger.info(f"✅ vLLM RAG客服Agent初始化完成")
logger.info(f" 知识库: {self.kb_path}")
logger.info(f" vLLM端点: {self.vllm_endpoint}")
def _init_knowledge_base(self):
"""初始化知识库(Milvus Lite)"""
try:
from pymilvus import MilvusClient
self.kb_client = MilvusClient(self.kb_path)
self.collection_name = "customer_service_kb"
# 检查集合是否存在
if not self.kb_client.has_collection(collection_name=self.collection_name):
raise ValueError(f"知识库集合不存在: {self.collection_name}")
logger.info(f"✅ 知识库加载: {self.collection_name}")
# 获取chunks,用于混合检索
self.chunks = []
res = self.kb_client.query(
collection_name=self.collection_name,
output_fields=["content", "metadata", "source_file"],
limit=10000, # Milvus限制limit范围在[1, 16384]之间
)
for idx, item in enumerate(res):
self.chunks.append({
"id": item.get("id", idx), # 使用Milvus返回的id,或者使用索引
"content": item["content"],
"metadata": json.loads(item["metadata"]),
"source_file": item["source_file"]
})
logger.info(f"✅ 从知识库加载了 {len(self.chunks)} 条数据")
except ImportError:
logger.error("❌ 需要安装 pymilvus: pip install pymilvus")
raise
except Exception as e:
logger.error(f"❌ 知识库初始化失败: {e}")
raise
def _init_llm_client(self):
"""初始化vLLM API客户端"""
try:
from langchain_openai import ChatOpenAI
self.model = ChatOpenAI(
base_url=self.vllm_endpoint,
api_key="not-needed", # vLLM不需要API key
model="customer_service", # vLLM部署的服务名称
temperature=0.7,
max_tokens=512, # 降低至512,为输入prompt留出空间
timeout=30.0
)
# 测试连接
test_response = self.model.invoke("test")
logger.info(f"✅ vLLM连接成功: {self.vllm_endpoint}")
except ImportError:
logger.error("❌ 需要安装 langchain-openai: pip install langchain-openai")
raise
except Exception as e:
logger.error(f"❌ vLLM连接失败: {e}")
logger.info("💡 确保vLLM已启动: python -m vllm.entrypoints.openai.api_server --model ./Qwen/Qwen2.5-3B-Instruct --enable-lora --lora-modules customer_service=./lora/kf --port 8000")
raise
def _init_embedding_model(self):
"""初始化embedding模型(本地或远程)"""
self.embedder = None
if self.embedding_model_path and Path(self.embedding_model_path).exists():
# 使用本地模型
try:
from sentence_transformers import SentenceTransformer
self.embedder = SentenceTransformer(self.embedding_model_path)
logger.info(f"✅ 本地embedding模型: {self.embedding_model_path}")
except Exception as e:
logger.warning(f"⚠️ 本地embedding模型加载失败: {e}")
self.embedder = None
if self.embedder is None:
# 使用远程或自动下载
try:
from sentence_transformers import SentenceTransformer
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
self.embedder = SentenceTransformer("BAAI/bge-small-zh-v1.5")
logger.info("✅ 使用默认embedding模型: BAAI/bge-small-zh-v1.5")
except Exception as e:
logger.error(f"❌ embedding模型初始化失败: {e}")
raise
def _init_hybrid_retriever(self):
"""初始化混合检索器"""
self.retriever = HybridRetriever(chunks=self.chunks, embedder=self.embedder)
def _init_prompt_templates(self):
"""获取提示词文本"""
# 从core/prompts目录加载提示词
try:
with open(loader.get("rag_summize_prompt"), "r", encoding="utf-8") as f:
self.prompt_text = f.read()
logger.info("✅ 提示词模板加载成功")
except FileNotFoundError:
logger.error("❌ 提示词文件未找到")
raise
except Exception as e:
logger.error(f"❌ 提示词模板加载失败: {e}")
raise
def _init_chain(self):
chain = self.prompt_template | RunnableLambda(print_prompt) | self.model | StrOutputParser()
return chain
def retriever_docs(self, query: str, top_k: int = 8) -> List[Dict[str, Any]]:
"""检索相关知识"""
try:
results = self.retriever.hybrid_search(self.kb_client, query, self.collection_name, top_k=top_k)
logger.info(f"✅ 检索到 {len(results)} 条相关知识")
return results
except Exception as e:
logger.error(f"❌ 检索失败: {e}")
return []
def rag_summarize(self, query: str) -> str:
"""执行RAG总结"""
try:
docs = self.retriever_docs(query)
if not docs:
return "抱歉,我没有找到相关的知识来回答您的问题。"
context = ""
counter = 0
for doc in docs:
counter += 1
context += f"【知识{counter}】:参考资料: {doc['content']}\n来源: {doc['source_file']}\n重排序分数: {doc['rerank_score']}\n\n"
return self.chain.invoke({"input": query, "context": context})
except Exception as e:
logger.error(f"❌ RAG总结失败: {e}")
return "抱歉,处理您的请求时发生了错误。"
4.7 Agent
此环节包含两步:
-
将RAG的总结变为工具 tool
-
创建ReactAgent
封装为工具的代码较为简单:
python
# /core/agent_tools.py
from langchain_core.tools import tool
from core.rag_summize import RagSummarize
rag = RagSummarize()
@tool(description="基于rag的文本总结工具,输入为文本,输出为总结结果")
def rag_summarize_tool(query: str) -> str:
return rag.rag_summarize(query)智能体:
python
# /core/react_agent.py
import sys
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent.parent))
import json
import logging
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from agent_tools import rag_summarize_tool
from config.config_loader import loader
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def load_prompt():
"""加载系统提示词"""
try:
with open(loader.get("system_prompt"), "r", encoding="utf-8") as f:
prompt_text = f.read()
logger.info(f"✅ 提示词模板加载成功")
return prompt_text
except Exception as e:
logger.error(f"❌ 提示词模板加载失败: {e}")
raise
class ReactAgent:
def __init__(self):
# 创建 ChatOpenAI 实例
llm = ChatOpenAI(
base_url=loader.get("vllm_endpoint"),
api_key="not-needed",
model="customer_service",
temperature=0.7,
max_tokens=512,
timeout=30.0
)
self.agent = create_agent(
model=llm,
system_prompt=load_prompt(),
tools=[rag_summarize_tool],
# middleware=[]
)
def execute_stream(self, query :str):
input_dict = {
"messages":[
{
"role": "user",
"content": query
},
]
}
for chunk in self.agent.stream(input_dict, stream_mode="values"):
latest_msg = chunk["messages"][-1]
if latest_msg.content:
yield latest_msg.content.strip() + '\n'
if __name__ == '__main__':
agent = ReactAgent()
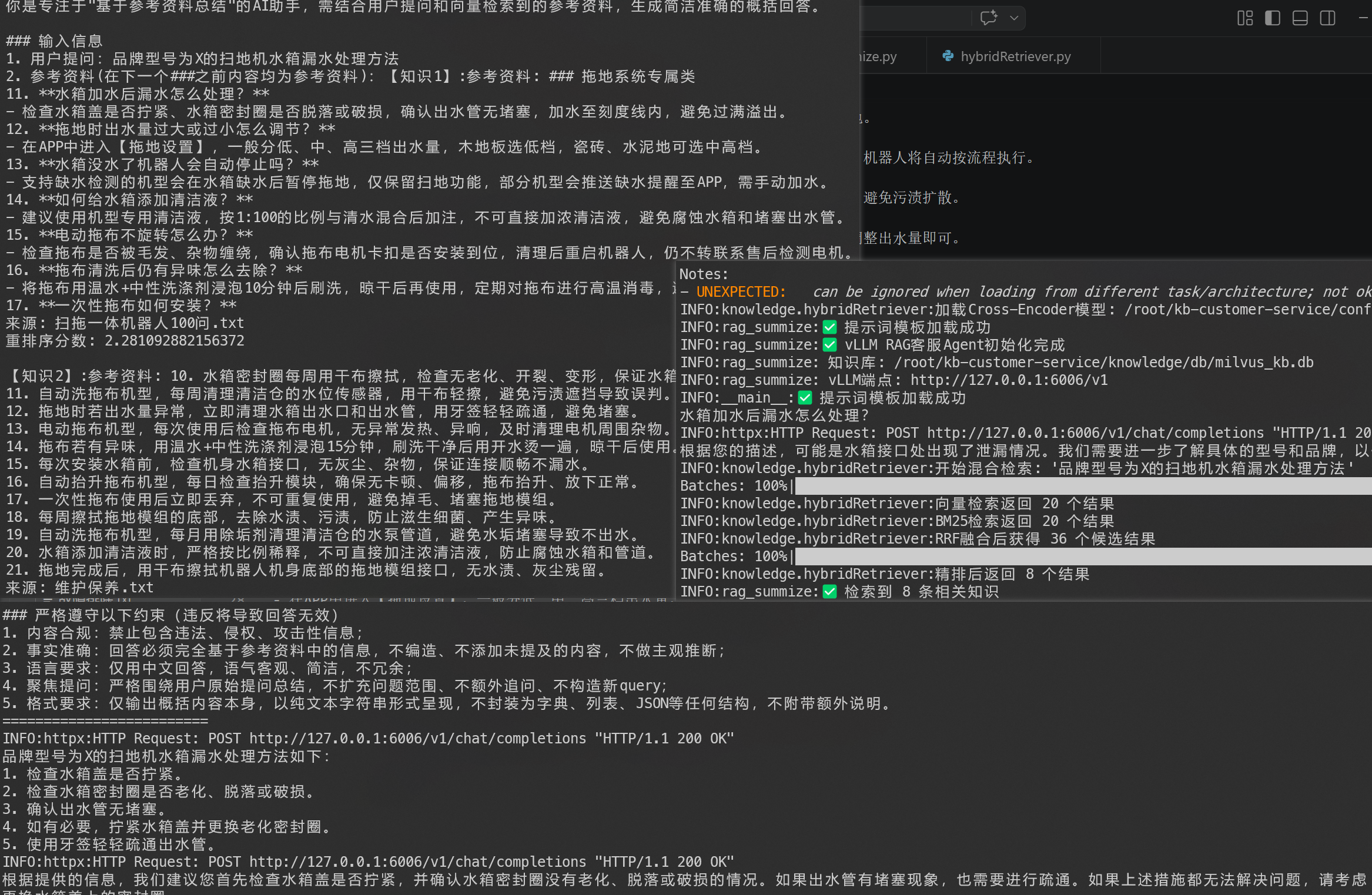
for chunk in agent.execute_stream("水箱加水后漏水怎么处理?"):
print(chunk, end='', flush=True)运行效果演示:
5. 评估系统
为了让评估更稳定,我还是建议重开一个conda环境,由于rag目录结构复杂,因为我将其放入evaluation目录
项目文件我会上传至 GitHub
5.1 RAGAS评估
评估的完整代码请看github仓库
python
# evaluation/ragas_evaluator.py
def main():
"""主函数"""
print("=" * 60)
print("🤖 RAG系统评估工具")
print("=" * 60)
try:
# 创建评估器
evaluator = RAGEvaluator()
# 运行完整评估
report = evaluator.run_full_evaluation()
# 打印摘要
print("\n📋 评估摘要:")
print(f" 总问题数: {report['summary']['total_questions']}")
print(f" 成功率: {report['summary']['success_rate']:.2%}")
if report['ragas_scores']:
print("\n📊 RAGAS指标:")
for metric, score in report['ragas_scores'].items():
print(f" {metric}: {score:.3f}")
print(f"\n📄 详细报告: {evaluator.reports_dir}/")
print("✅ 评估完成!")
except Exception as e:
print(f"❌ 评估失败: {e}")
import traceback
traceback.print_exc()5.2 评估指标
-
RAGAS标准指标:
- Faithfulness (忠实度)
- Answer Relevance (答案相关性)
- Context Relevance (上下文相关性)
- Context Recall (上下文召回率)
- Context Precision (上下文精确度)
- Answer Similarity (答案相似度)
- Answer Correctness (答案正确性)
-
自定义指标:
- 响应成功率
- 平均检索文档数
- 答案/上下文长度统计
6. 对话客服部署
思路是在服务器上运行Streamlit服务,然后用户就可以通过链接随时随地访问了
在项目根目录创建app.py文件
python
# /app.py
#!/usr/bin/env python3
"""
扫地机器人客服RAG系统 - 极简版
"""
import sys
from pathlib import Path
# 添加项目根目录到Python路径
project_root = Path(__file__).parent
sys.path.insert(0, str(project_root))
sys.path.insert(0, str(project_root / "core"))
import streamlit as st
from core.react_agent import ReactAgent
import warnings
warnings.filterwarnings("ignore")
# 页面配置
st.set_page_config(
page_title="扫地机器人客服",
page_icon="🤖",
layout="wide",
initial_sidebar_state="collapsed"
)
# 初始化Session State
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "你好!我是扫地机器人客服助手,有什么可以帮助你的吗?"
}
]
if "agent" not in st.session_state:
st.session_state.agent = ReactAgent()
# 主标题
st.title("🤖 扫地机器人客服系统")
st.markdown("---")
# 使用Streamlit原生聊天组件
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar="👤" if message["role"] == "user" else "🤖"):
st.markdown(message["content"])
# 用户输入
if prompt := st.chat_input("请输入你的问题..."):
# 添加用户消息
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user", avatar="👤"):
st.markdown(prompt)
# 生成助手回复
with st.chat_message("assistant", avatar="🤖"):
message_placeholder = st.empty()
full_response = ""
try:
for chunk in st.session_state.agent.execute_stream(prompt):
full_response += chunk
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
error_msg = f"抱歉,系统暂时无法处理您的请求:{str(e)}"
message_placeholder.markdown(f"⚠️ {error_msg}")
st.session_state.messages.append({"role": "assistant", "content": error_msg})
# # 侧边栏 - 快捷问题
# with st.sidebar:
# st.title("💡 快捷问题")
# st.markdown("---")
# quick_questions = [
# "扫地机器人怎么使用?",
# "故障代码E01是什么意思?",
# "如何更换边刷?",
# "机器人找不到充电座怎么办?"
# ]
# for q in quick_questions:
# if st.button(q, key=q, use_container_width=True):
# st.session_state.messages.append({"role": "user", "content": q})
# st.rerun()
# 页脚
st.markdown("---")
st.markdown(
"<div style='text-align: center; color: #666;'>"
"扫地机器人客服系统 | 基于RAG技术构建"
"</div>",
unsafe_allow_html=True
)同时也可以使用sh脚本,快速启动服务:
sh
# start_app.sh
echo "🚀 启动扫地机器人客服系统(AutoDL版)..."
echo "📊 端口: 6008"
echo "📍 绑定地址: 0.0.0.0"
echo ""
echo " 请在AutoDL控制台配置端口映射:外部端口 -> 6008"
echo ""
# 停止现有进程
pkill -f streamlit 2>/dev/null
sleep 2
# 创建Streamlit配置
mkdir -p .streamlit
cat > .streamlit/config.toml << 'EOF'
[server]
port = 6008
address = "0.0.0.0"
headless = true
enableCORS = false
enableXsrfProtection = false
maxUploadSize = 200
[client]
showErrorDetails = true
EOF
# 启动应用
streamlit run app.py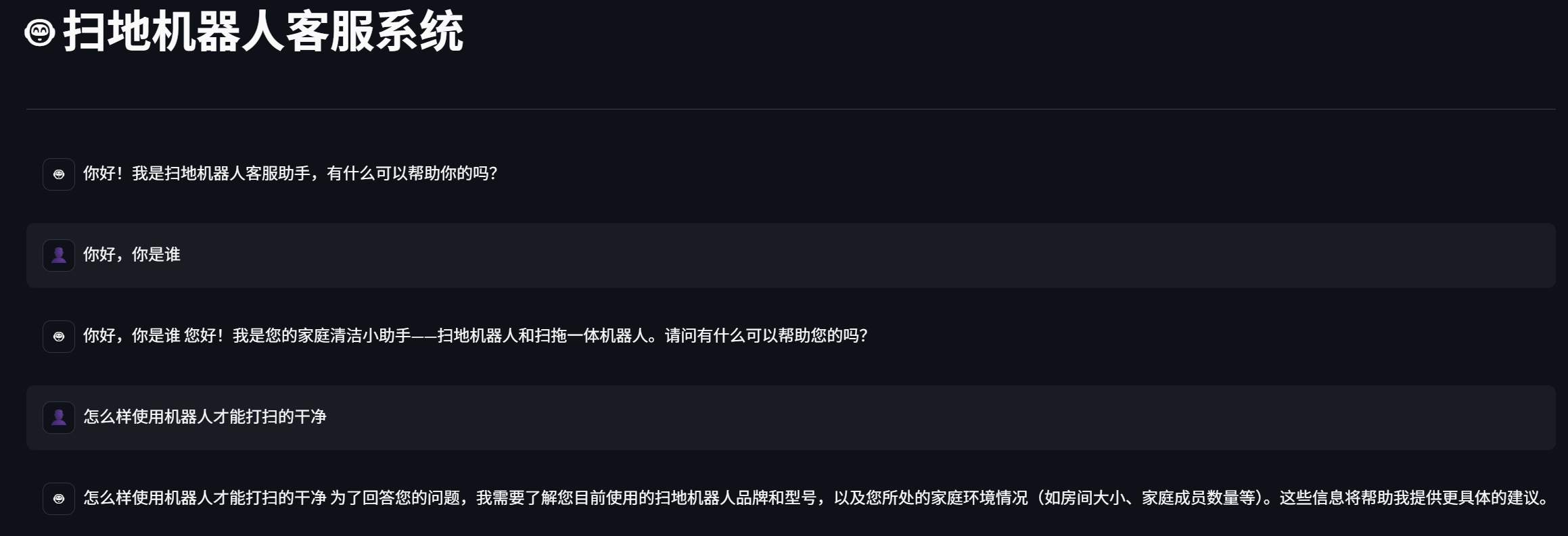
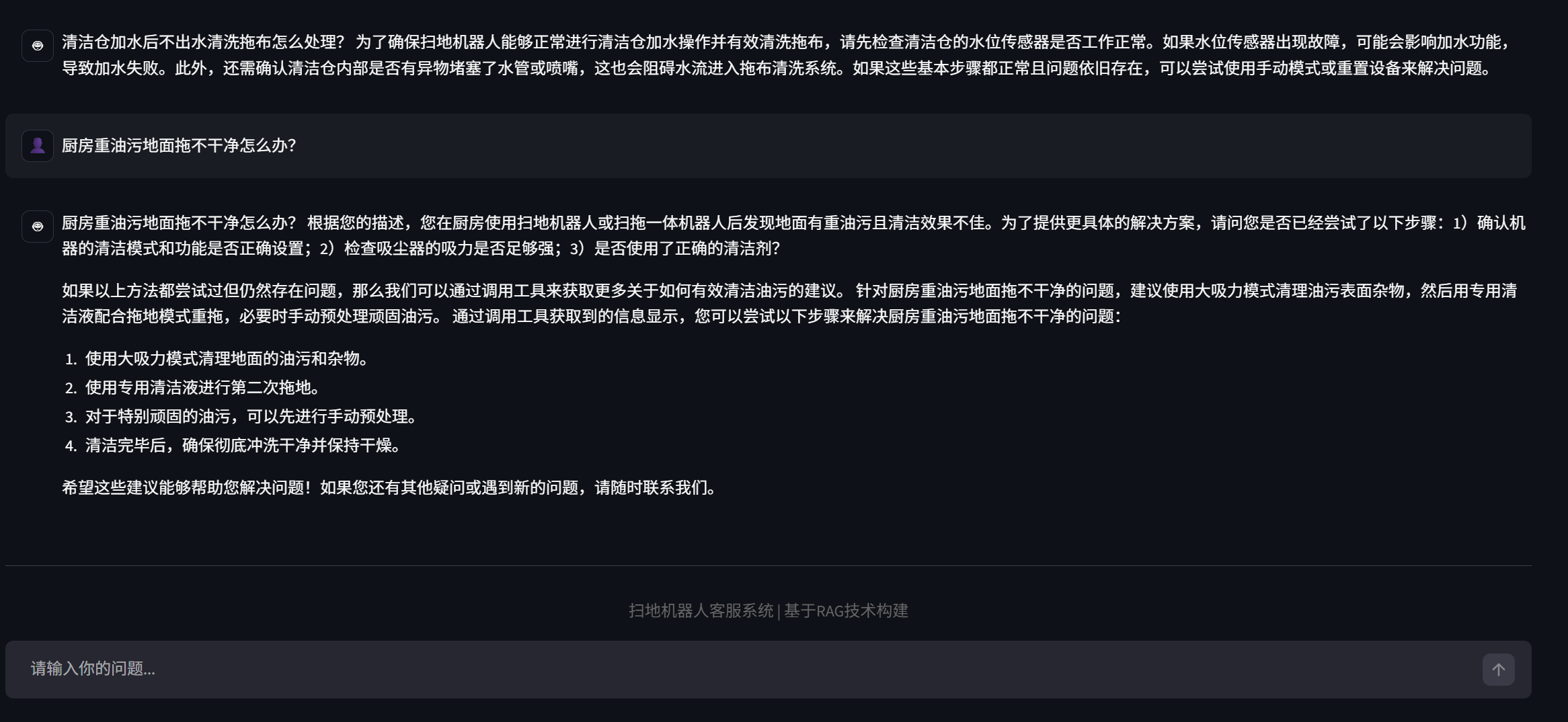
由于微调的模型部署在vLLM上,所以推理速度非常非常快,感兴趣的可以试试,完全可以实战!
项目文件 👉 代码与资料