语音识别
语音识别: 声音-> 文本
声音本质是一种波
将波按时间段切分很多帧,如25ms一段
之后进行声学特征提取,将每一帧转化成一个向量
以声学特征提取后的向量为输入,经过声学模型,预测得到音素
音素与拼音类似,但要考虑声调
音素序列对应多条文本序列,由语言模型挑选出成句概率最高的序列
使用beam search 或维特比的方式解码
手写识别
识别模型将图片中文字转化为候选汉字,再有语言模型挑选出成句概率最高的序列
输入法
输入即为拼音序列,每个拼音自然的有多个候选汉字,根据语言模型挑选高概率序列
输入法是一个细节繁多的任务,在语言模型这一基础算法上,需要考虑常见的打字手误,常见误读,拼音缩略,中英混杂,输出符号,用户习惯等能力
手写输入法,语音输入法同理
语言模型的分类
由简单到复杂
统计语言模型(SLM) ngram语言模型等
神经语言模型(NLM) rnn语言模型等
预训练模型(PLM) Bert,GPT等
大语言模型(LLM) ChatGPT等
N-gram语言模型
用S代表句子,w代表单个字或词
S=w1w2w3w4w5..wn
P(S)=P(w1,w2,w3,w4,w5,...wn)
成句概率 -> 词W1~Wn按顺序出现的概率
P(w1,w2,w3,..wn) = P(w1)P(w2|w1)P(w3|w1,w2)...P(wn|w1,...,wn-1)
N-gram语言模型怎么计算呢
以字为单位
P(今天天气不错) = P(今)*P(天|今)*P(天|今天)*P(气|今天天)*P(不|今天天气)*P(错|今天天气不)
以词为单位
P(今天 天气 不错) = P(今天)* P(天气|今天)*P(不错|今天 天气)
N-gram的困难
句子太多了
对任意一门语言,N-gram数量都非常庞大,无法穷举,需要简化
那么有没有缓解的办法:
有个不太好的解决办法,马尔科夫假设:
P(wn|w1,...,wn-1)≈ P(wn|wn-3,wn-2,wn-1) 一般常见的是3,4,5
假设第n个词出现的概率,仅受其前面有限个词影响
P(今天天气不错) = P(今)*P(天|今)*P(天|今天) * P(气|天天) * P(不|天气) * P(错|气不)
但是马尔科夫假设的缺陷也很明显:
1.影响第n个词的因素可能出现在前面很远的地方
例如: 我读过关于马尔科夫生平的书
2.影响第n个词的因素可能出现在其后面
3.影响第n个词的因素可能并不在文中
但是马尔科夫假设下依然可以得到非常有效的模型
但是有个问题就是 如何给出预料中没有出现过的词或ngram概率
就比如这个预料 ,P(今天 天气 糟糕) = P(今天)*(天气|今天)*P(糟糕|天气)
但是糟糕并没有出现过,那么概率是应该是0,那么问题来了,如果是0合适吗,模型的泛化性太低了,那么模型几乎不合格

那么有什么策略可以解决
平滑策略,这个问题也被称为平滑问题
理论上,任意的词组合成的句子,概率都不应当为零
如何给没见过的词或ngram分配概率即为平滑问题,也称折扣问题
平滑方法
1.回退(backoff)
当三元组a b c 不存在时,退而寻找b c 二元组的概率
P(c|a b) = P(c|b) * Bow(ab)
Bow(ab) 称为二元组a b 的回退概率
回退概率有很多计算方式,甚至可以设定为常数
回退可以迭代进行,如序列 a b c d
P(d|a b c) =P(d | b c) *Bow(abc)
P(d|bc) = P(d|c) * Bow(bc)
P(d|c) = P(d) * Bow(c)
平滑方法迭代的最后会回退到单字或词,但如果没存在怎么办
加1平滑 add - one smooth
对于1gram概率P(word) = Count(word) +1 / Count(totalword) +V
V为词表大小
对于高阶概率同意可以 PAdd-1(wi|wi-1) = C(wi-1,wi) +1 /C(wi-1)+V
还有另一种方法
将低频词替换为<UNK>
预测中遇到的未见过的词,也用<UNK>代替
P(<UNK>|一语成)
这是一种nlp处理为的登陆词(OOV)的常见方法
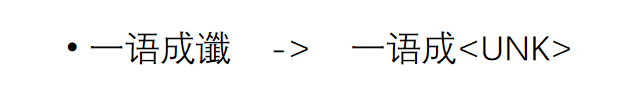
语言模型的评价指标
困惑度 perplexity


神经语言模型
与n-gram相比,神经网络语言模型优势
向量化表示语义信息优化字符统计,泛化性更好
例如: 猫和狗,两向量相似度极高,但是n-gram只是统计
输入长度不影响模型大小,长距离建模优势
例如 n-gram 计算 今天天气不错 ,P(wn) = P(wn| wn-3,wn-2,wn-1) 根据马尔科夫假设只考虑前 n-3个词,不能考虑太多
softmax带来的自带平滑
对下游任务的适配更加方便
两类语言模型的对比
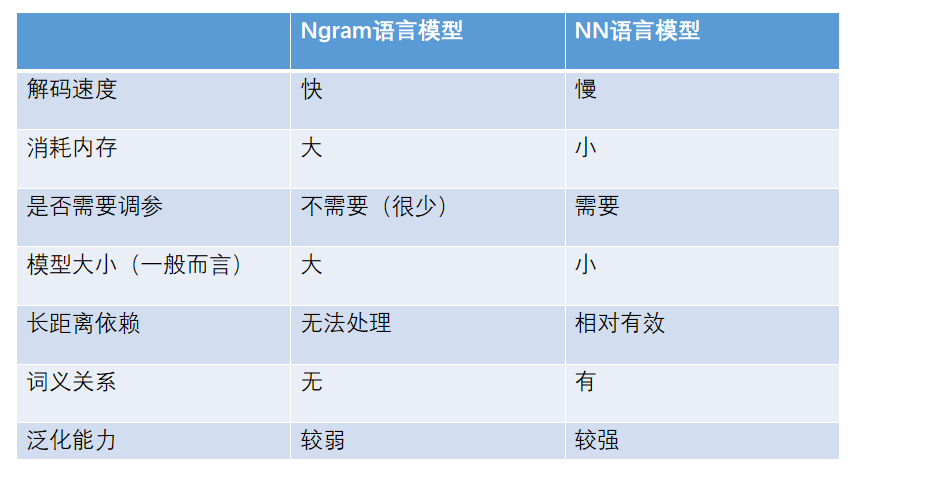
NN语言模型需要进行矩阵计算,NN语言模型慢
其他上面好像有