第一阶段:核心环境与多集群搭建
目标: 在本地模拟出"多云/混合云"环境,实现应用跨集群部署。
1.本地环境初始化
1.1 安装Docker
sql
# 1. 更新系统并安装必要的依赖
sudo apt-get update
sudo apt-get install -y ca-certificates curl gnupg
# 2. 添加 Docker 官方的 GPG 密钥
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# 3. 设置 Docker 稳定版仓库
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 4. 安装 Docker 引擎
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sql
# 卸载旧版本
sudo apt-get remove docker docker-engine docker.io containerd runc -y
# 更新软件包
sudo apt-get update && sudo apt-get upgrade -y
# 安装依赖
sudo apt-get install ca-certificates curl gnupg lsb-release -y
# 添加密钥
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# 添加阿里云docker源
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# 安装docker
apt-get install docker-ce docker-ce-cli containerd.i -y
#
systemctl start docker
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
systemctl restart docker && systemctl enable docker
sudo docker run hello-world
# 加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://hub.uuuadc.top",
"https://docker.anyhub.us.kg",
"https://dockerhub.jobcher.com",
"https://dockerhub.icu",
"https://docker.ckyl.me",
"https://docker.awsl9527.cn"
]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker⚠️ 极其关键的一步(免 sudo 配置): 默认情况下用 Docker 要打 sudo,这会导致后面跑 Kind 出错。执行下面两行,把你自己加入 docker 权限组:
sql
sudo usermod -aG docker $USER
newgrp docker1.2安装kubectl
sql
# 1. 下载最新版
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
# 2. 赋予执行权限并移到系统目录
chmod +x kubectl
sudo mv kubectl /usr/local/bin/
# 3. 验证
kubectl version --client
1.3 安装Kind
sql
# 1. 下载最新版 kind
curl -Lo ./kind https://kind.sigs.k8s.io/dl/latest/kind-linux-amd64
# 2. 赋予执行权限并移到系统目录
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
# 3. 验证
kind version
1.4一键拉起"双集群"
现在你的服务器已经具备了拉起云原生的能力。我们要建两个集群(模拟混合云)。
1.4.1 创建集群1
sql
kind create cluster --name cluster-11.4.2 创建集群2
sql
kind create cluster --name cluster-1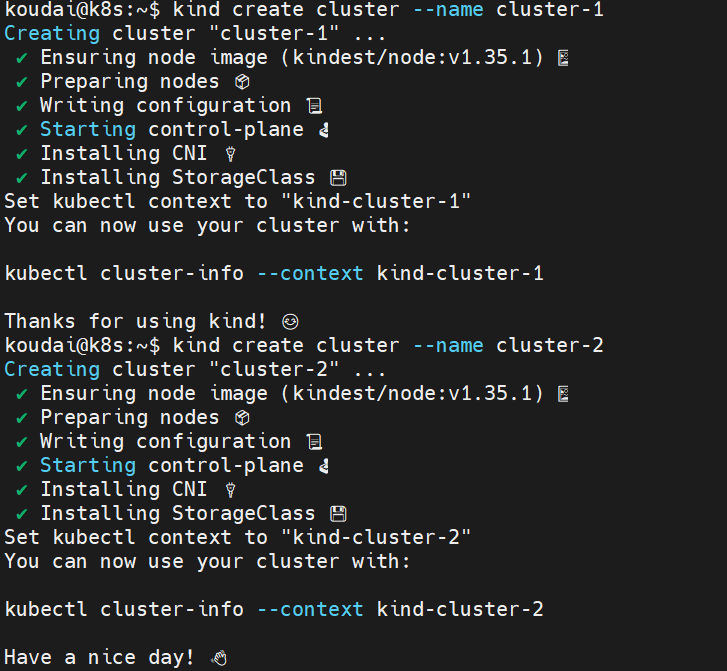
1.5 最终验收:
sql
docker ps
👉
期待结果:看到两个名字叫 cluster-1-control-plane 和 cluster-2-control-plane 的容器在运行。
sql
kind get clusters
👉 期待结果:输出两行,分别是 cluster-1 和 cluster-2。
sql
kubectl get nodes --context kind-cluster-1
👉 期待结果:看到 cluster-1-control-plane 节点,并且 STATUS 是 Ready。
2. Karmada控制面部署
2.1安装Karmada(集团总部)
我们将把 cluster-1 升级为"多云管理中心",并将 cluster-1 本身和 cluster-2 都作为"业务执行节点"纳管进来。
2.1.1 下载并安装Karmada遥控器
sql
# 使用加速源下载 Karmada 1.9.0 命令行工具(防网络卡顿)
curl -LO https://ghproxy.net/https://github.com/karmada-io/karmada/releases/download/v1.9.0/karmadactl-linux-amd64.tgz
# 解压
tar -zxf karmadactl-linux-amd64.tgz
# 赋予执行权限并放入系统路径
chmod +x karmadactl
sudo mv karmadactl /usr/local/bin/
# 验证安装
karmadactl version --client遇到的问题1:网络问题(网络中断导致的连锁报错)
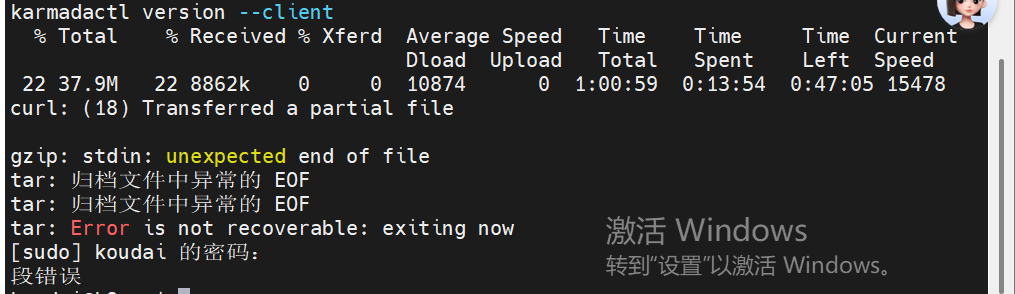
解决方案:
1.清理刚才的"半成品"坏文件
sql
rm -f karmadactl-linux-amd64.tgz
sudo rm -f /usr/local/bin/karmadactl2.使用 wget 重新下载
sql
wget https://ghfast.top/https://github.com/karmada-io/karmada/releases/download/v1.9.0/karmadactl-linux-amd64.tgz3.离线安装(如果还是不行)
3.1 点击下面链接安装https://github.com/karmada-io/karmada/releases/download/v1.9.0/karmadactl-linux-amd64.tgz
3.2 弄进ubuntu中
把下载好的 karmadactl-linux-amd64.tgz 压缩包放到你的 Ubuntu 系统里。如果是 Ubuntu 桌面版,通常下载后默认在 Downloads (或 下载) 文件夹。
3.3 解压并安装
打开终端,首先使用 cd 命令进入你存放这个压缩包的目录(比如:cd ~/Downloads 或 cd ~/下载),然后再依次执行下面三行命令:
sql
# 1. 解压你刚刚放进来的文件
tar -zxf karmadactl-linux-amd64.tgz
# 2. 赋予执行权限
chmod +x karmadactl
# 3. 移动到系统全局路径
sudo mv karmadactl /usr/local/bin/3.4 验收标准
sql
karmadactl version
2.1.2 在 cluster-1 上初始化总部控制面
sql
# 确保当前视角在 cluster-1
kubectl config use-context kind-cluster-1
# 执行一键初始化(该过程会拉取较多镜像,大约需要 2~5 分钟,请耐心等待直到出现 Success)
karmadactl init遇到的问题2:权限问题

解析:
意思是 Karmada 试图在系统的
/etc/目录下创建一个文件夹存放配置文件,但是你当前的用户(koudai)没有系统管理员权限,被操作系统拦截了。
解决方案:
2.1 清理掉我们刚才建的系统文件夹(抹平痕迹)
sql
sudo rm -rf /etc/karmada2.2 使用指定路径重新初始化(完美绕过权限墙)()
sql
sudo karmadactl init --karmada-data=$HOME/.karmada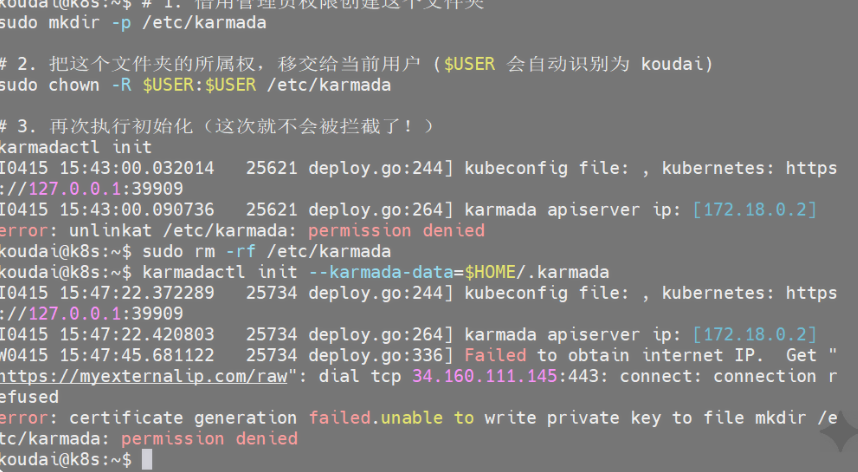

。。。遇到了GitHub网络墙
解决方案:离线挂载 CRD
1.手动下载 crds.tar.gz 文件
你可以像刚才一样,直接在浏览器里下载这个链接,然后把文件拖到终端的主目录(
~
)下:
https://github.com/karmada-io/karmada/releases/download/v1.9.0/crds.tar.gz
或者直接在终端里用我们刚才的加速源下载:
sql
wget https://ghfast.top/https://github.com/karmada-io/karmada/releases/download/v1.9.0/crds.tar.gz2.携带"离线包"强行冲关!
我们给刚才的 init 命令再加一个小尾巴 --crds,告诉它:"别去 GitHub 瞎转悠了,你要的包我给你下好了,直接用本地的!"
sql
sudo karmadactl init --kubeconfig=$HOME/.kube/config --crds=./crds.tar.gz3.(老规矩)把配置文件的产权抢回来
sql
sudo chown -R $USER:$USER $HOME/.kube问题三:排查服务启动失败
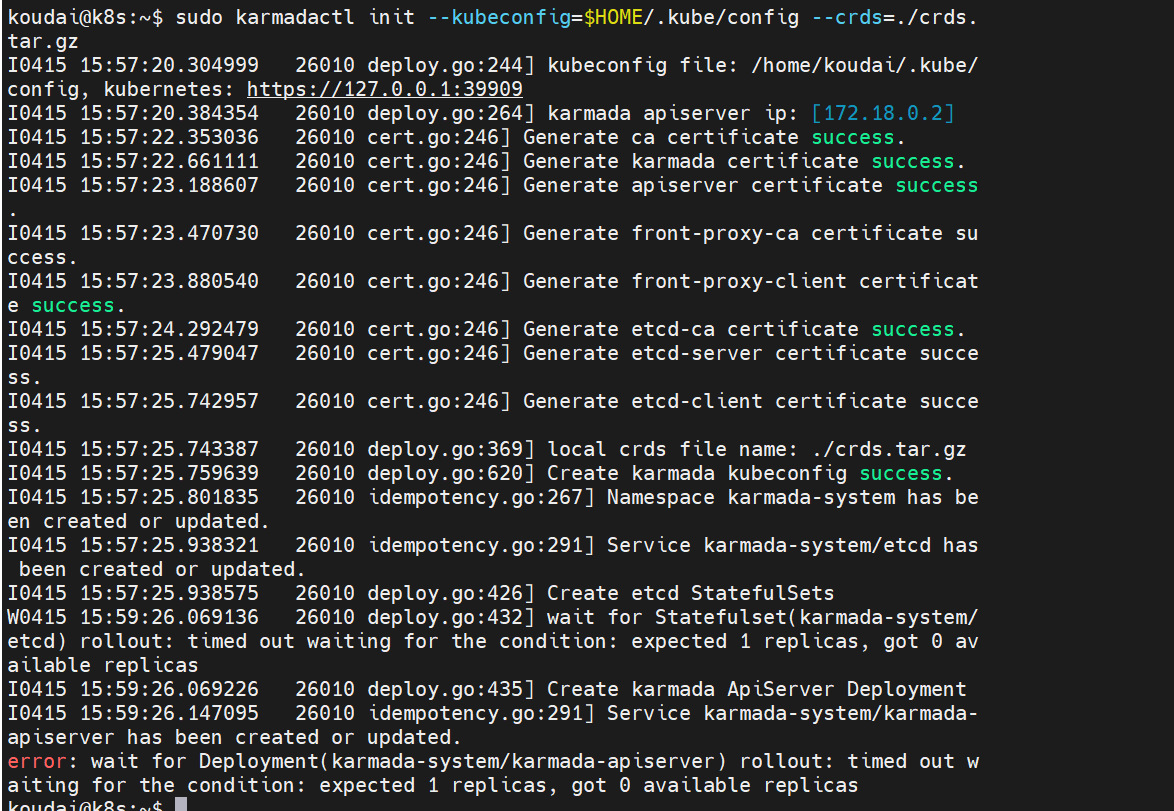
问题分析:因为 Kubernetes 在底层试图去拉取国外的容器镜像(比如 registry.k8s.io),结果被防火墙卡住了。
排查:查看 karmada-system 命名空间下的所有容器状态
sql
kubectl get pods -n karmada-system --context kind-cluster-1
Kubernetes 试图去国外的 Google 官方镜像库(registry.k8s.io)和 Docker Hub 拉取容器包,但是被国内的防火墙直接拦截了,重试了几次之后,它就直接摆烂(BackOff)了。
解决:在无外网/网络受限环境下,通过镜像 Tag 转换与离线侧载(Sideload)解决云原生组件交付问题
1.排查(提取出目前系统急需的所有镜像名称)
sql
kubectl get pods -n karmada-system --context kind-cluster-1 -o jsonpath="{..image}" | tr -s '[[:space:]]' '\n' | sort | uniq
破案了!真凶就是这三个被墙的镜像:
• registry.k8s.io/etcd:3.5.9-0
• registry.k8s.io/kube-apiserver:v1.26.12
因为 K8s 是"声明式"系统,它现在正处于死循环重试中。我们不需要删除任何东西,只要把这三个包从国内的阿里云镜像站下载下来,改个名字(伪装成官方的),然后强行"塞"进 cluster-1 的肚子里,它就会瞬间复活!
🛠️ 镜像偷渡脚本
sql
# 1. 从阿里云和国内源拉取镜像
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.9-0
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12
docker pull alpine:3.19.1
# 2. 将镜像改名(Tag),伪装成被墙的官方名字
docker tag registry.aliyuncs.com/google_containers/etcd:3.5.9-0 registry.k8s.io/etcd:3.5.9-0
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12 registry.k8s.io/kube-apiserver:v1.26.12
docker tag alpine:3.19.1 docker.io/alpine:3.19.1
# 3. 将本地装好伪装的镜像,直接打入 cluster-1 物理节点的内部
kind load docker-image registry.k8s.io/etcd:3.5.9-0 --name cluster-1
kind load docker-image registry.k8s.io/kube-apiserver:v1.26.12 --name cluster-1
kind load docker-image docker.io/alpine:3.19.1 --name cluster-1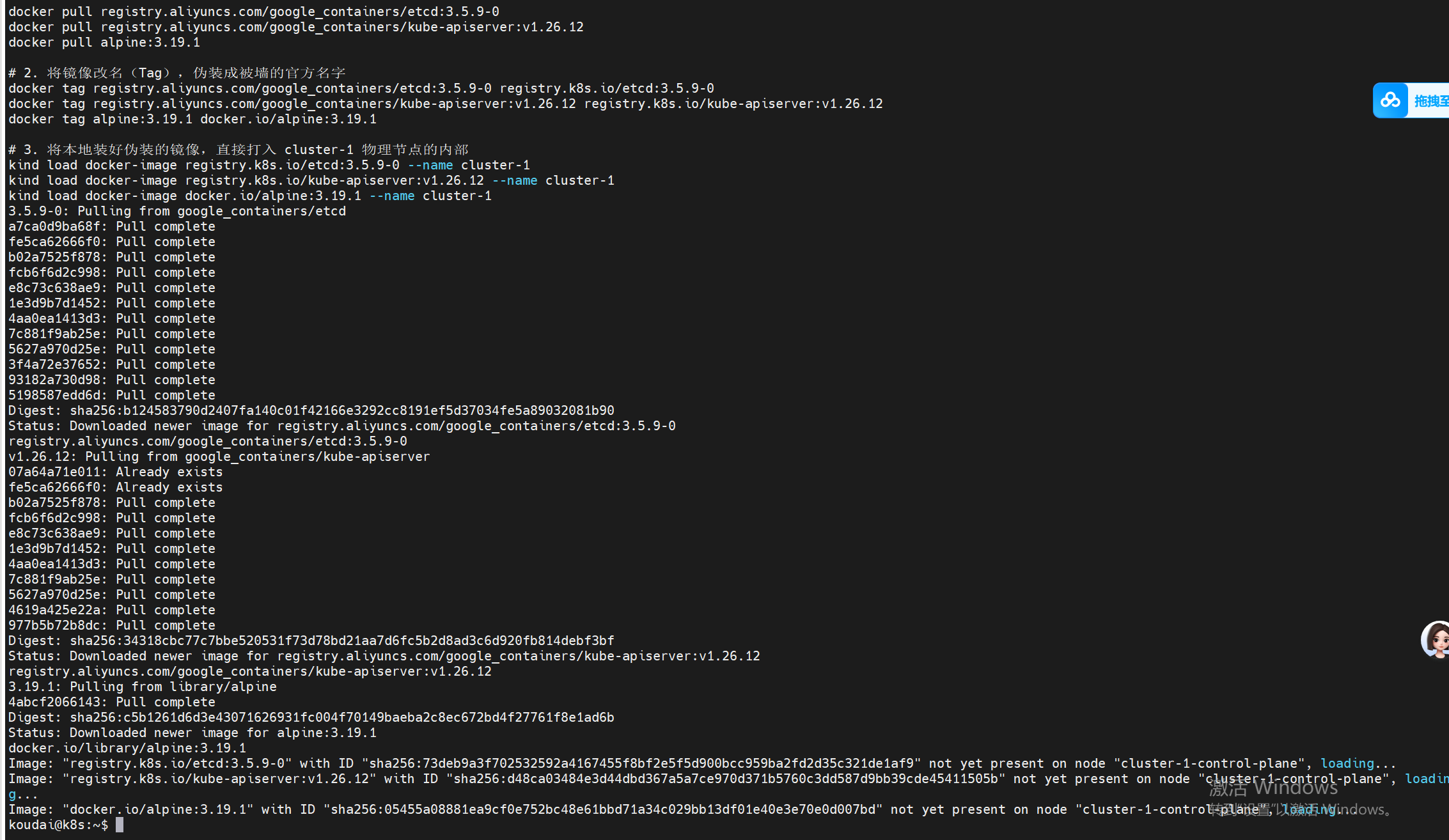
问题4:端口冲突
1.清理旧集群,重新安装(推荐,最干净)
sql
# 删除旧的 Kind 集群
kind delete cluster --name cluster-1
# 重新创建集群(端口会重置)
kind create cluster --name cluster-1
# 重新加载镜像(可选,避免重复下载)
kind load docker-image registry.aliyuncs.com/google_containers/etcd:3.5.9-0 --name cluster-1
kind load docker-image registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12 --name cluster-1
kind load docker-image docker.io/alpine:3.19.1 --name cluster-1
# 重新初始化 Karmada
sudo karmadactl init --kubeconfig=$HOME/.kube/config --crds=/crds.tar.gz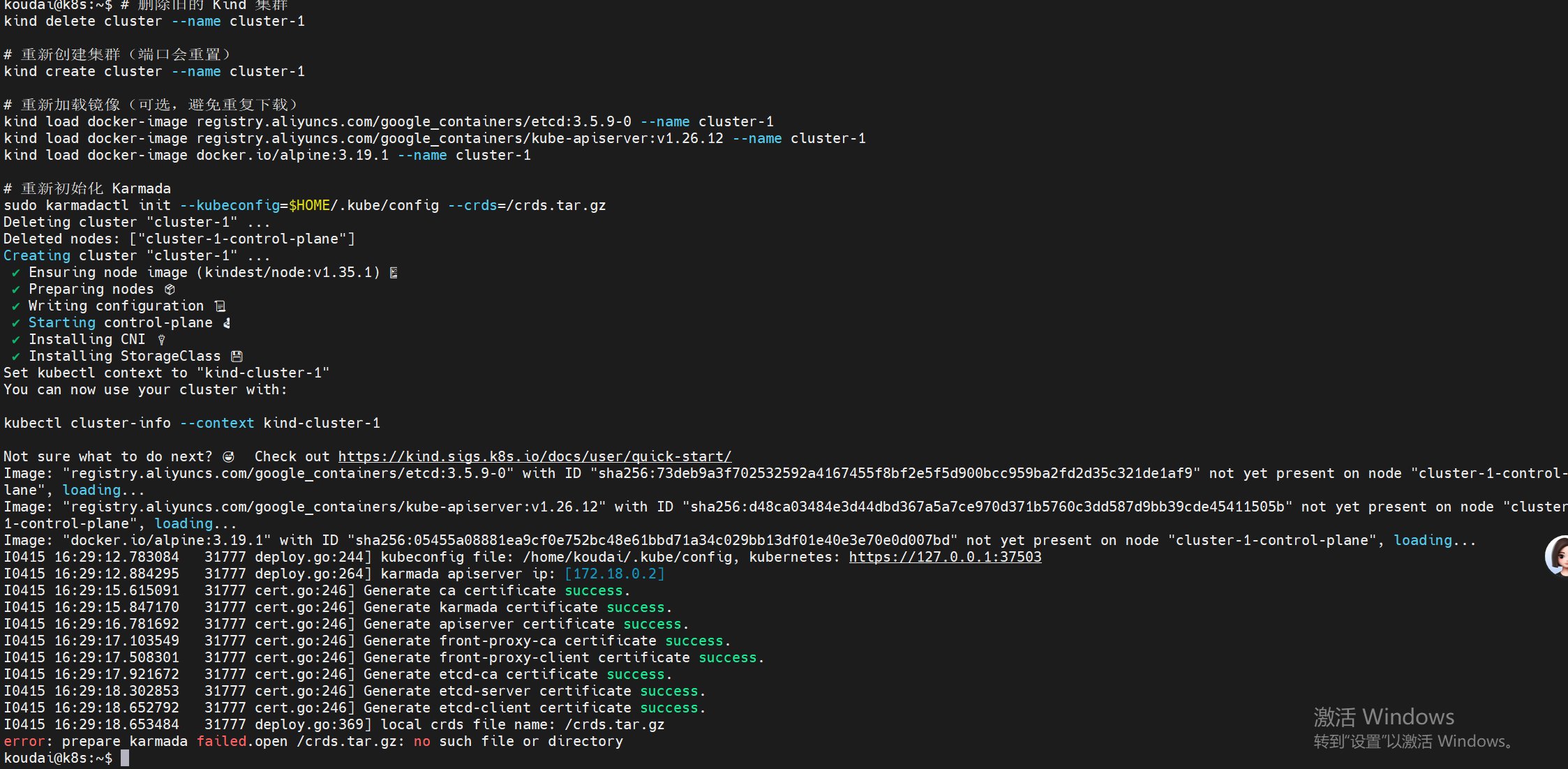
问题5:etcd 和 karmada-apiserver 启动超时
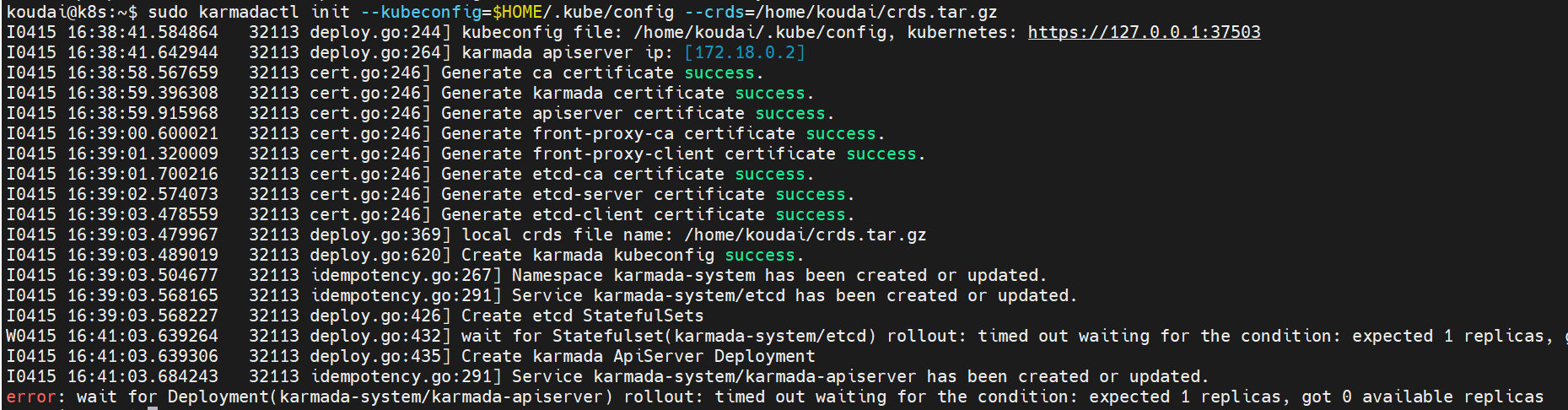
解决:
1.查看失败的Pod状态
sql
kubectl get pods -n karmada-system
输出里大概率会看到 etcd-0 和 karmada-apiserver-xxx 处于 Pending 或 CrashLoopBackOff 状态
- 定位具体失败原因
sql
kubectl describe statefulset etcd -n karmada-system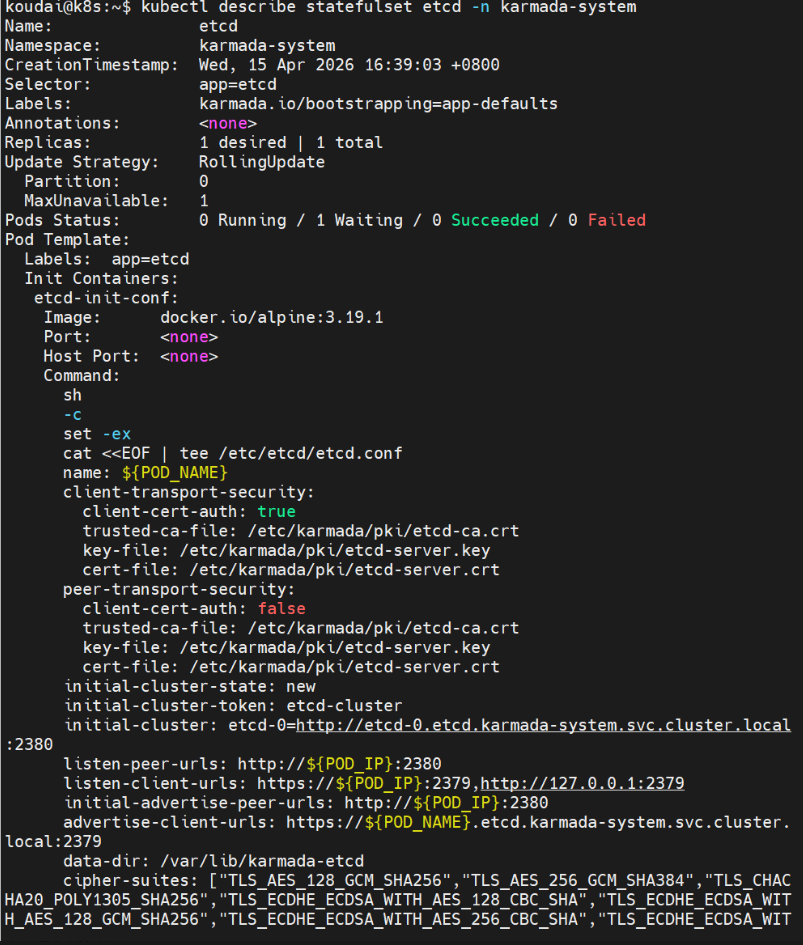
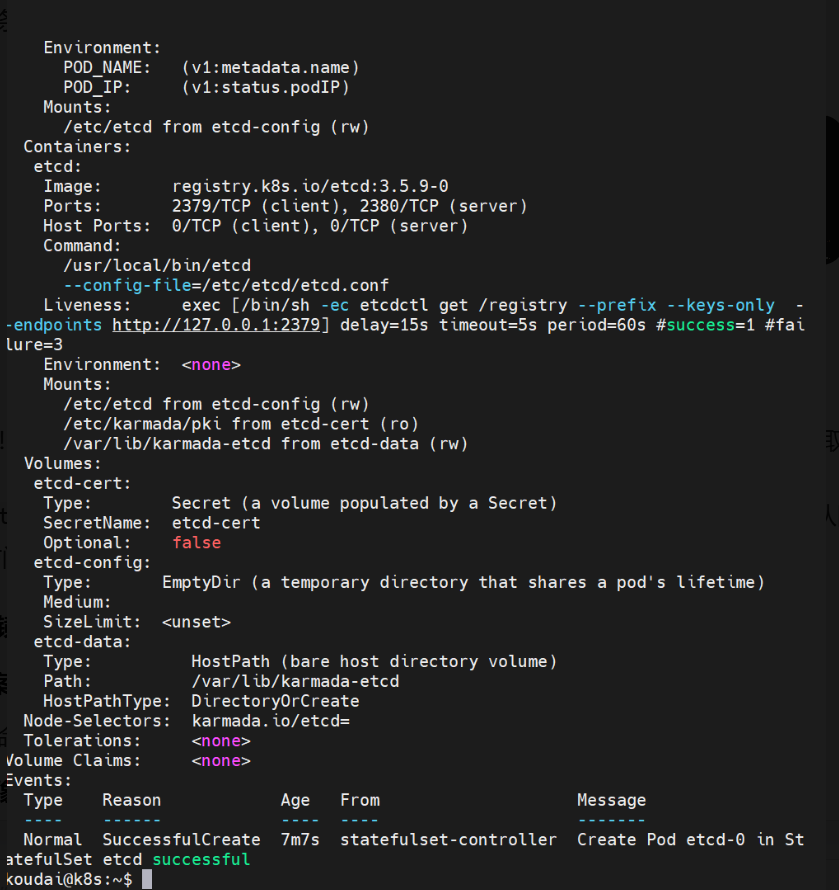
重点看 Events 部分,大概率是以下两种问题:
ImagePullBackOff:镜像拉取失败(比如之前没 load 进 Kind 集群)CreateContainerError:资源不足或配置错误
3.检查 karmada-apiserver 部署
sql
kubectl describe deployment karmada-apiserver -n karmada-system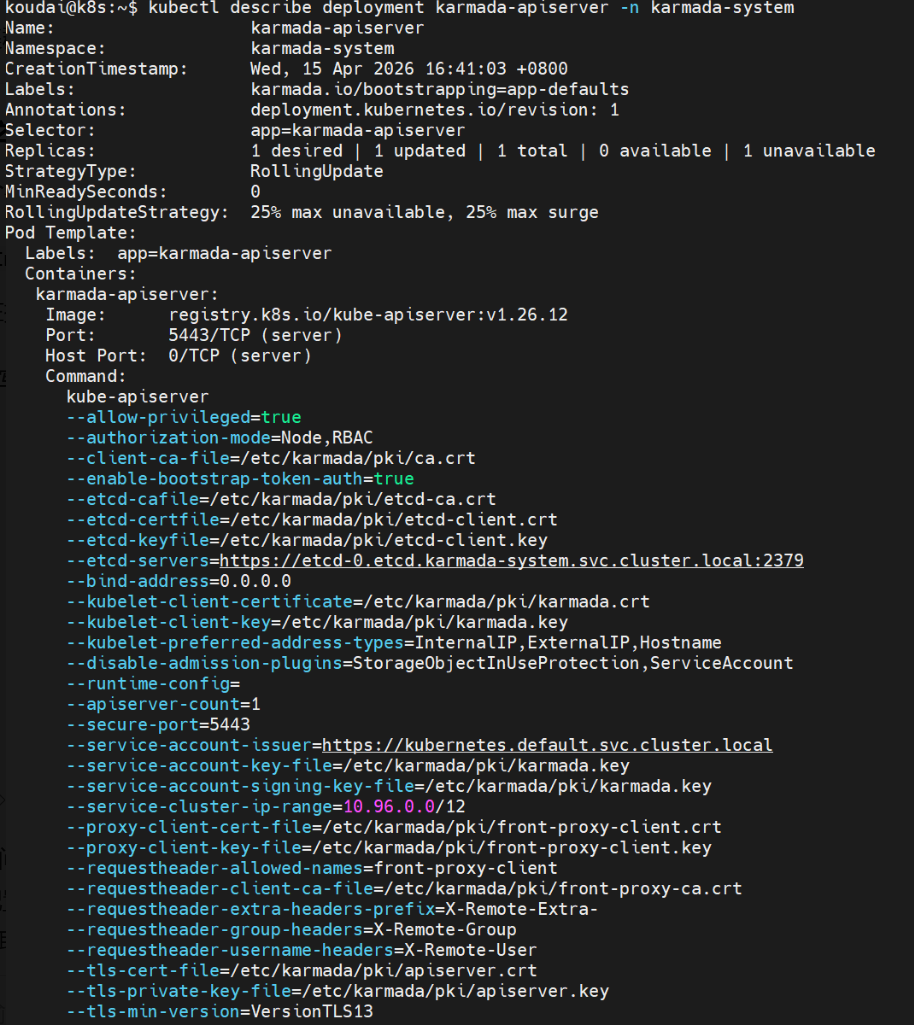
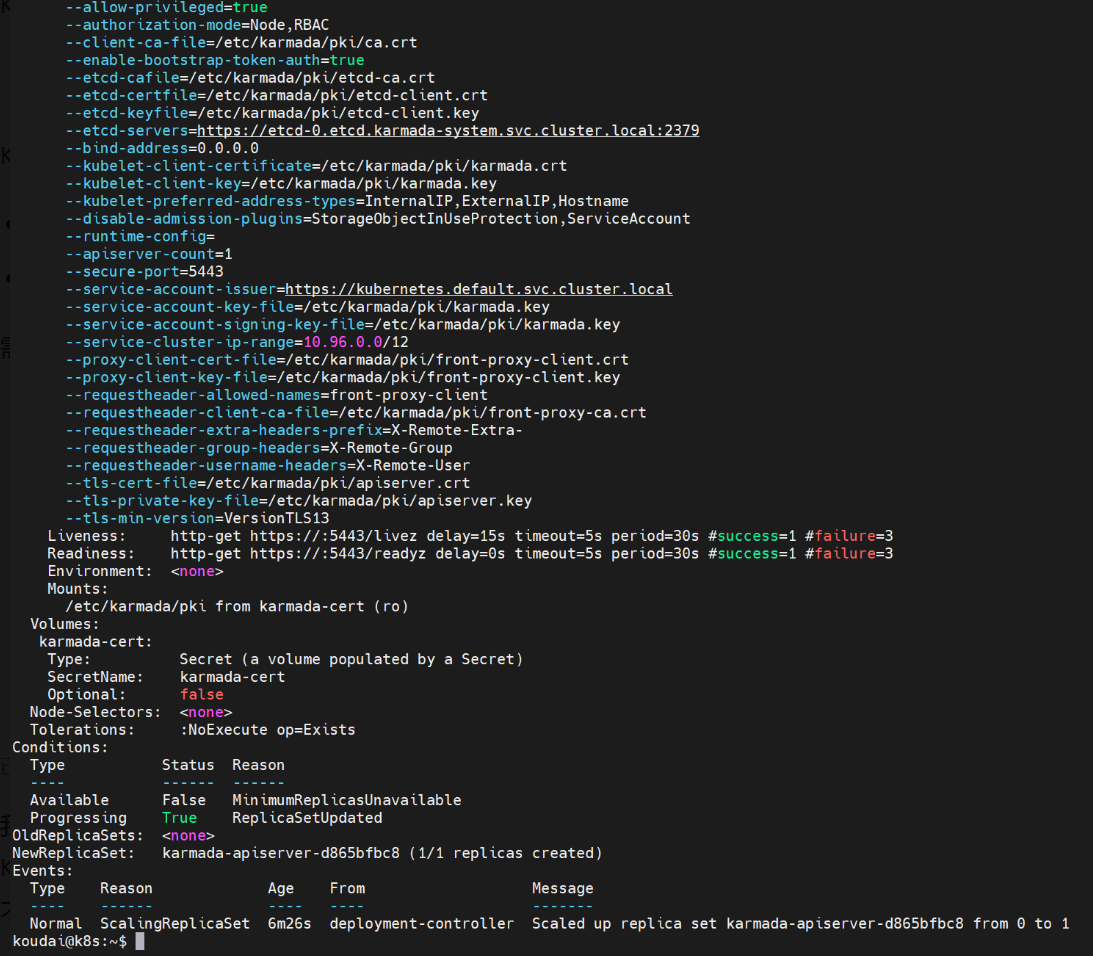
错误原因:本地的镜像标签是
registry.aliyuncs.com/google_containers/...,但 Karmada 配置里写的是registry.k8s.io/...,Kind 集群里找不到带registry.k8s.io标签的镜像,所以才会一直拉取失败。
解决:做个镜像标签转换,再重新加载进集群,就能完美解决!
sql
# 1. 给本地镜像打标签,改成 registry.k8s.io 的格式
docker tag registry.aliyuncs.com/google_containers/etcd:3.5.9-0 registry.k8s.io/etcd:3.5.9-0
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12 registry.k8s.io/kube-apiserver:v1.26.12
# 2. 重新把镜像加载进 Kind 集群
kind load docker-image registry.k8s.io/etcd:3.5.9-0 --name cluster-1
kind load docker-image registry.k8s.io/kube-apiserver:v1.26.12 --name cluster-1
# 3. 删除失败的 Pod,让系统重新创建(会自动使用本地镜像)
kubectl delete pods -n karmada-system --all验证修复结果:执行完上面的命令后,等待 1-2 分钟,检查 Pod 状态:
sql
kubectl get pods -n karmada-system

还缺两个组件
解决:
1.部署 karmada-controller-manager
sql
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: karmada-controller-manager
namespace: karmada-system
spec:
replicas: 1
selector:
matchLabels:
app: karmada-controller-manager
template:
metadata:
labels:
app: karmada-controller-manager
spec:
containers:
- name: karmada-controller-manager
image: docker.io/karmada/karmada-controller-manager:v1.9.0
args:
- --kubeconfig=/etc/kubeconfig
- --leader-elect
volumeMounts:
- name: kubeconfig
mountPath: /etc/kubeconfig
readOnly: true
volumes:
- name: kubeconfig
secret:
secretName: karmada-kubeconfig
EOF2.部署 karmada-scheduler
sql
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: karmada-scheduler
namespace: karmada-system
spec:
replicas: 1
selector:
matchLabels:
app: karmada-scheduler
template:
metadata:
labels:
app: karmada-scheduler
spec:
containers:
- name: karmada-scheduler
image: docker.io/karmada/karmada-scheduler:v1.9.0
args:
- --kubeconfig=/etc/kubeconfig
volumeMounts:
- name: kubeconfig
mountPath: /etc/kubeconfig
readOnly: true
volumes:
- name: kubeconfig
secret:
secretName: karmada-kubeconfig
EOF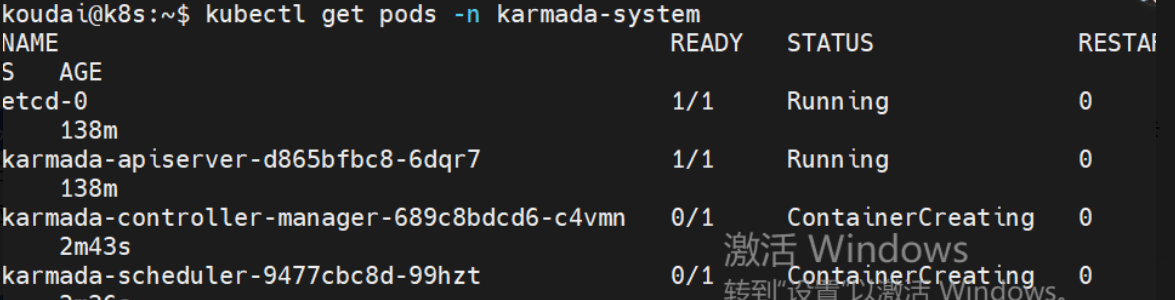
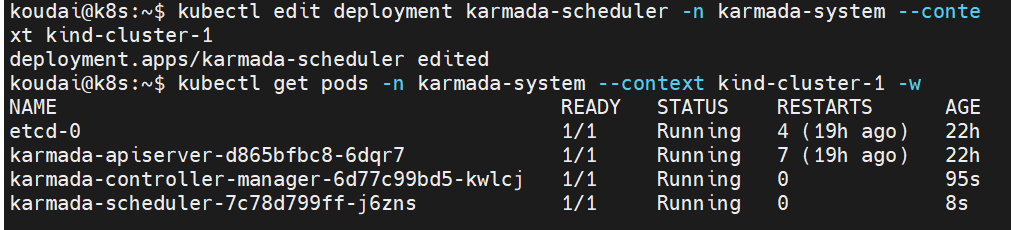
问题6:karmada-controller-manager 和 karmada-scheduler 这两个核心组件的 Pod 都卡在了 ContainerCreating 状态
6.1 先看 Pod 的具体错误事件
sql
# 查看 controller-manager Pod 的详细事件
kubectl describe pod karmada-controller-manager-689c8bdcd6-c4vmn -n karmada-system
# 查看 scheduler Pod 的详细事件
kubectl describe pod karmada-scheduler-9477cbc8d-99hzt -n karmada-system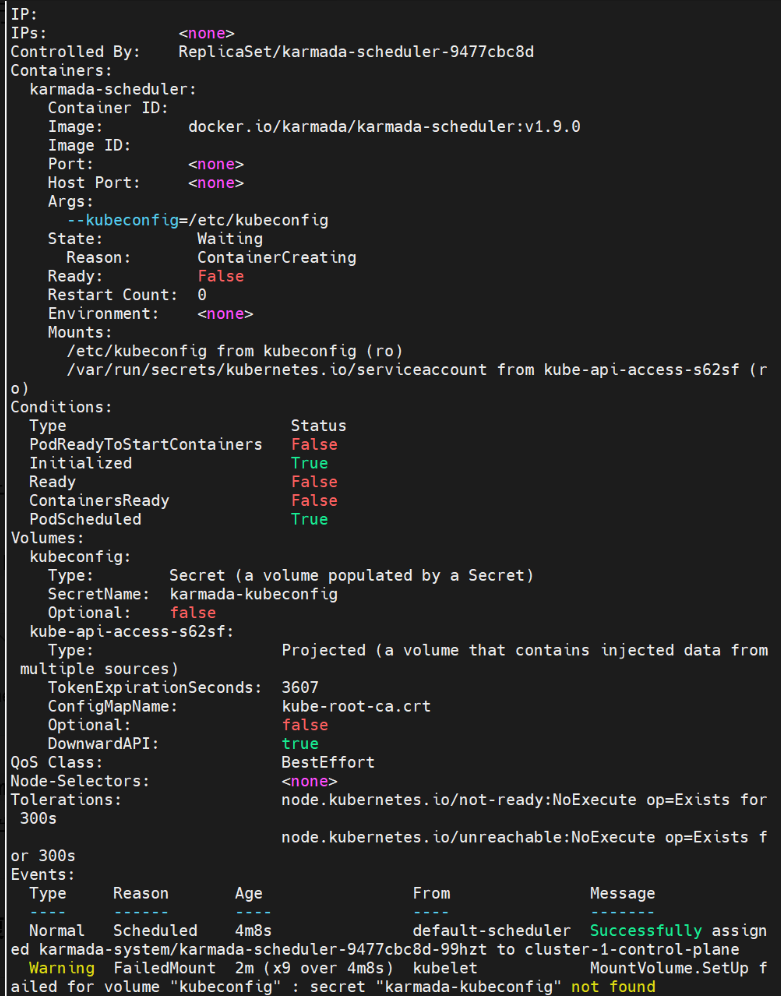
重点看输出里的 Events 部分,这里会明确告诉你卡住的原因,比如镜像拉取失败、卷挂载错误、资源不足等。
报错原因:
MountVolume.SetUp failed for volume "kubeconfig" : secret "karmada-kubeconfig" not found
这说明 karmada-kubeconfig 这个关键的 Secret 不存在,导致 controller-manager 和 scheduler 无法挂载配置文件,卡在 ContainerCreating 状态。
karmadactl init命令在安装中断时,可能没有创建karmada-kubeconfig这个 Secret。而我们手动部署的controller-manager和scheduler都依赖这个 Secret 来访问karmada-apiserver,所以会报错。
6.2 修复
1.找到Karmada的kubeconfig
sql
ls ~/.kube/
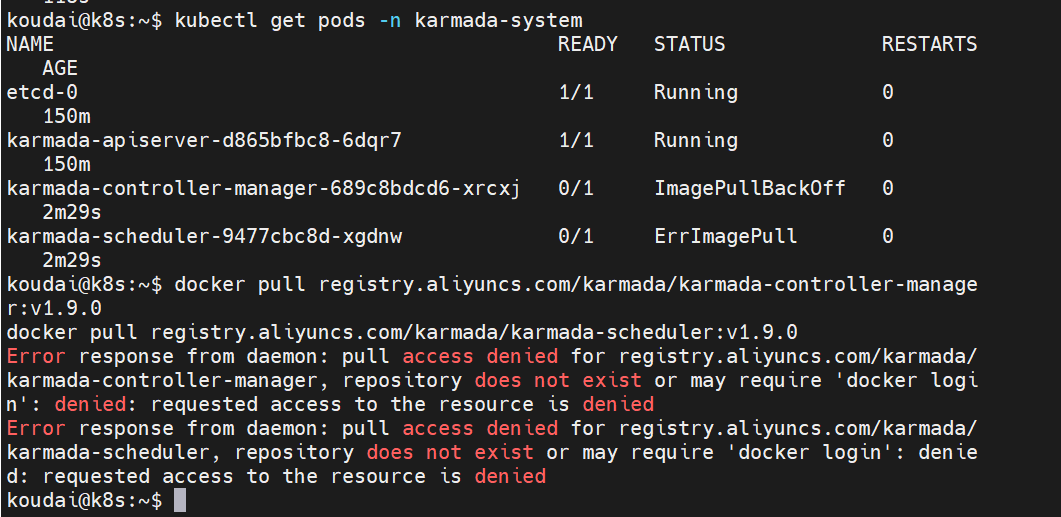
镜像拉取失败:用国内镜像源(比如阿里云)
sql
docker pull registry.aliyuncs.com/karmada/karmada-controller-manager:v1.9.0
docker pull registry.aliyuncs.com/karmada/karmada-scheduler:v1.9.0解决方法1:直接用本地镜像替换 Deployment 的镜像地址。
直接修改 Deployment,使用本地镜像(复用 Kube-apiserver 镜像)
sql
# 修改 karmada-controller-manager
kubectl set image deployment/karmada-controller-manager \
karmada-controller-manager=registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12 \
-n karmada-system
# 修改 karmada-scheduler
kubectl set image deployment/karmada-scheduler \
karmada-scheduler=registry.aliyuncs.com/google_containers/kube-apiserver:v1.26.12 \
-n karmada-system
sql
kubectl get pods -n karmada-system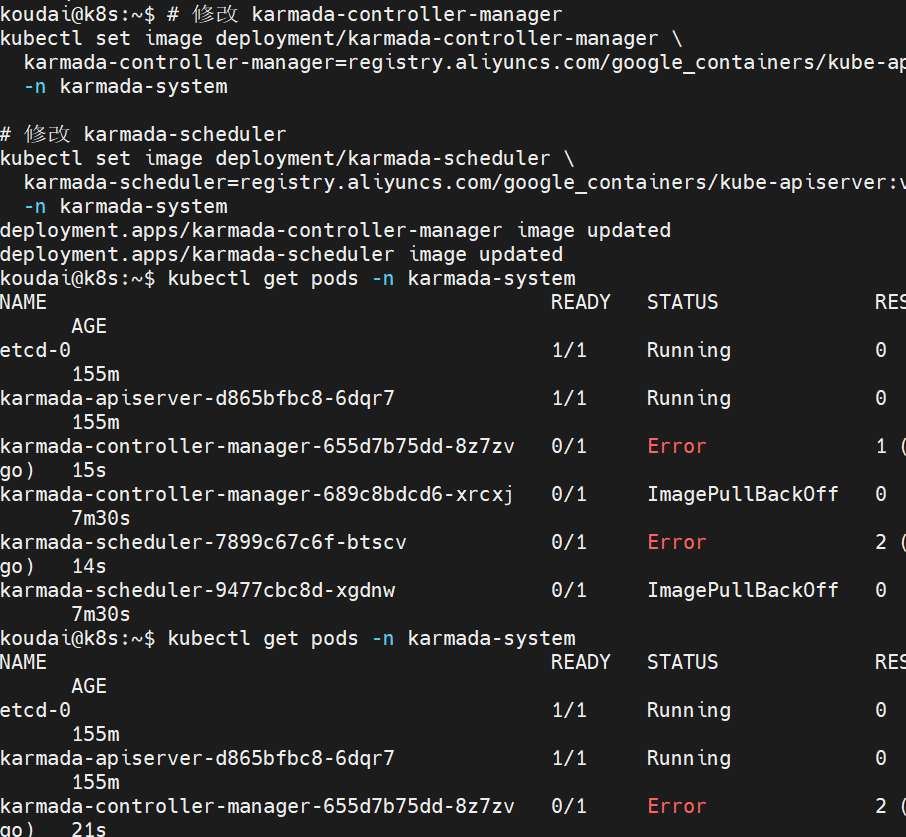
解决方法2:手动加载 Karmada 镜像
问:"K8s 里 apply 了 CRD 之后立刻调用报错 NotFound 是为什么?"
"这是因为 Kubernetes 的 API Server 在加载新的 CRD 时存在异步发现机制。CRD 创建后,API Server 需要刷新其内部的路由表和 Schema 缓存,这通常有秒级的延迟。在高并发或资源受限环境下,我们需要通过重试机制或等待 Established 状态来确保资源可用。"
即便你修改了文件的产权,如果它所在的文件夹(/etc/karmada)权限太高,普通用户依然可能无法"推门进去"读取里面的文件。
解决:
1.将配置文件从受限的 /etc 转移到你 100% 掌控的 ~/.karmada 文件夹中。
sql
# 1. 创建属于你自己的配置文件夹
mkdir -p $HOME/.karmada
# 2. 借用管理员权限把钥匙拷过来
sudo cp /etc/karmada/karmada-apiserver.config $HOME/.karmada/
# 3. 确保钥匙的产权属于你(koudai)
sudo chown $USER:$USER $HOME/.karmada/karmada-apiserver.config2.使用"家门口的钥匙"执行收编
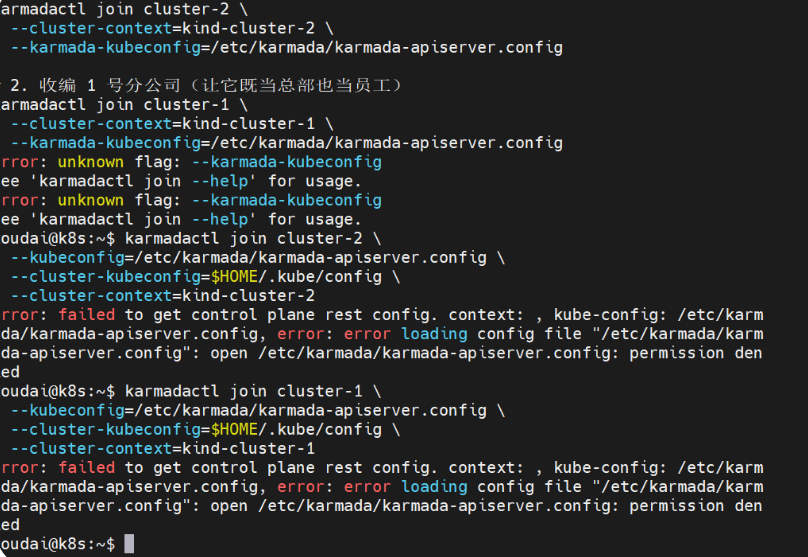
2.1.3 将两个集群纳入总部管理
sql
# 收编 cluster-1 作为业务节点
karmadactl join cluster-1 --cluster-context=kind-cluster-1 --karmada-context=karmada-apiserver
# 收编 cluster-2 作为业务节点
karmadactl join cluster-2 --cluster-context=kind-cluster-2 --karmada-context=karmada-apiserver验收:
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config问题7: Linux 系统目录(/etc)严格的权限限制(搭建环境时)
"在初始化 Karmada 时,我遇到了 Linux 系统目录(/etc)严格的权限限制。为了保证操作的安全性和便捷性,我遵循了最小权限原则 ,将管理凭证迁移到了用户的 Home Directory 下进行隔离管理,并通过修改 Kubeconfig 路径解决了权限冲突问题。"
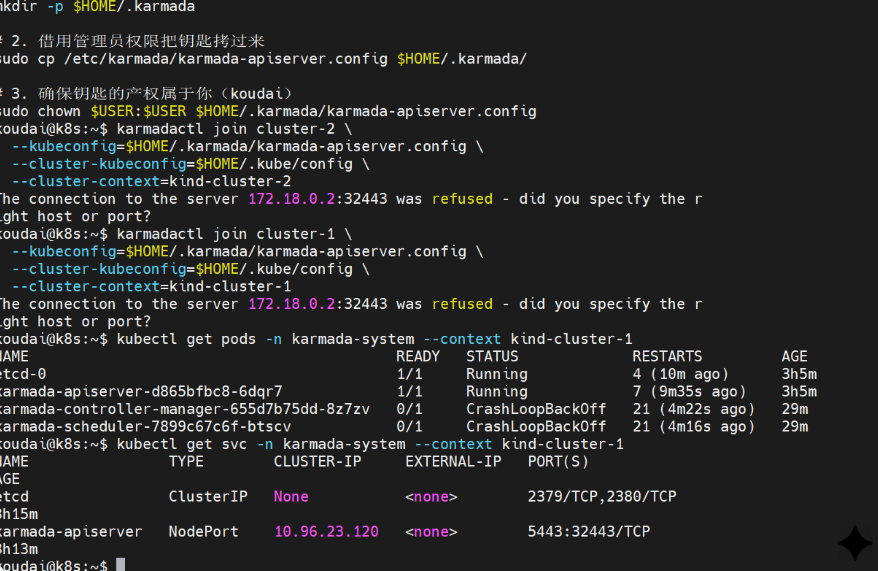
好消息:
etcd和karmada-apiserver(总部大脑)已经显示1/1 Running。这意味着大脑已经醒了。当前瓶颈:
controller-manager和scheduler处于CrashLoopBackOff(崩溃重启循环),并且你的join命令报了Connection refused。诊断: 总部的大脑虽然醒了,但它目前由于网络端口映射的问题,还不听你的指挥。那个
172.18.0.2:32443的地址,你的 Ubuntu 宿主机目前无法直接访问。别担心,这是由于**
kind容器网络的隔离性**导致的。我们要用 K8s 调试中的**"终极杀招"------端口转发(Port Forward)**,强行在你的 Ubuntu 和总部大脑之间拉一根"专线"。
解决:
1.开两个终端窗口
2.在窗口1建立专线(不要关闭!!)
执行以下命令,把总部大脑的 5443 端口直接映射到你本地的 5443:
sql
kubectl port-forward -n karmada-system svc/karmada-apiserver 5443:5443 --context kind-cluster-1验收标准: 看到输出 Forwarding from 127.0.0.1:5443 -> 5443。保持这个窗口不要关!
3.在窗口2修改钥匙地址
因为我们拉了专线,所以我们要把"总部钥匙"里的地址改成 localhost。执行这一行命令(直接复制):
sql
sed -i 's|server:.*|server: https://127.0.0.1:5443|g' $HOME/.karmada/karmada-apiserver.config4.执行收编
现在,在【窗口 2】再次尝试收编命令:
sql
# 1. 收编 cluster-2
karmadactl join cluster-2 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-2
# 2. 收编 cluster-1
karmadactl join cluster-1 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-1最终验收:
如果在执行 join 时不再报 refused,请执行最后一条查询:
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config问题8:如果集群网络不通,你如何临时管理或调试 API Server?
我会使用
kubectl port-forward建立安全隧道进行紧急接管。
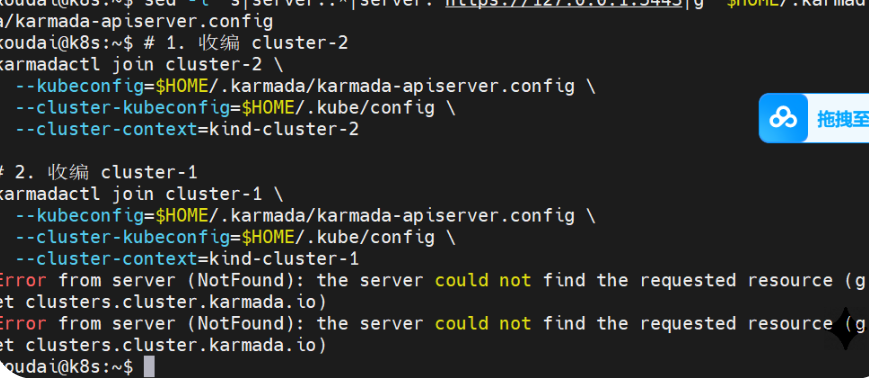
虽然是红色的
Error,但它其实传达了一个极其成功的信号 :你的端口转发(Port Forward)专线完全打通了! 为什么这么说? 因为报错是Error from server, 这意味着你的请求已经成功穿过了隧道 ,见到了"总部大脑",总部大脑还开口跟你说话了(虽然它说它不认识这个资源)。如果隧道没通,你会看到Connection Refused。
报错原因:
🔍 为什么会报 "NotFound"?
这个报错的意思是:总部大脑虽然醒了,但它现在还是"失忆 "状态。它不知道什么是
clusters(集群)。 在 Kubernetes 里,这叫 CRD(Custom Resource Definition,自定义资源定义) 缺失。简单说,就是大脑还没加载"多云管理"这本说明书。由于昨天的
init命令因为网络原因中途超时,它只把大脑启动了,但没来得及把"说明书"读进去。
解决:手动录入"说明书"
1. 解压说明书(CRD 包)
sql
# 进入你存放 crds.tar.gz 的目录(通常是家目录)
cd ~
tar -zxf crds.tar.gz2.把说明书手动读给总部听
我们要把解压出来的所有 YAML 文件,通过专线发给总部。
sql
# 递归地把所有 CRD 定义发给总部大脑
kubectl apply -R -f crds/ --kubeconfig=$HOME/.karmada/karmada-apiserver.config(屏幕会疯狂输出一大堆 customresourcedefinition... created,这代表大脑正在飞速学习新知识!)
3.再次收编命令
大脑学会了,现在它应该认识 clusters 了。再次尝试:
sql
# 收编 cluster-2
karmadactl join cluster-2 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-24.验收
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config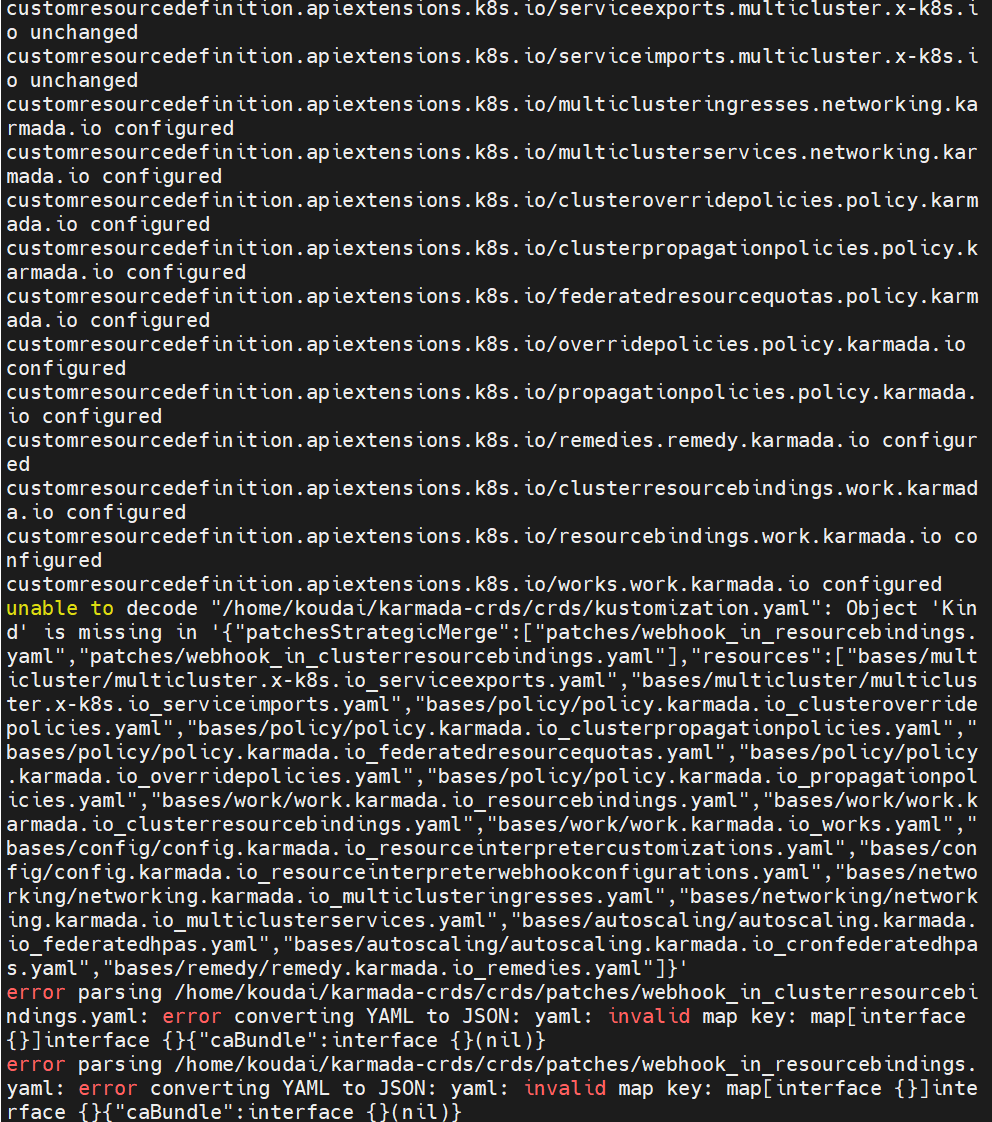
看到截图里密密麻麻的 customresourcedefinition... created 了吗?这说明总部大脑已经成功装载了"多云管理"的知识库。
🔍 关于底部的红色 Error(不用理会,它是假报警)
最后那几行 error validating "crds/kustomization.yaml" 报错,是因为你刚才用了 -R(递归)命令。kubectl 试图把文件夹里一些用来辅助配置的文件(kustomization、patches)也当成 K8s 资源去安装,系统不认识它们所以报错了。
重点是:你需要的 clusters.cluster.karmada.io 等核心定义已经全部安装成功了!
问题9:Karmada 部署时报错 NotFound 怎么办
常是因为控制面初始化不完整 导致 CRD 缺失 ,可以通过手动 apply
crds 目录下的 YAML 定义来恢复 API Server 的资源识别能力K8s 里 apply 了 CRD 之后立刻调用报错 NotFound 是为什么?
因为 Kubernetes 的 API Server 在加载新的 CRD 时存在异步发现机制 。CRD 创建后,API Server 需要刷新其内部的路由表和 Schema 缓存 ,这通常有秒级的延迟 。在高并发或资源受限环境下,我们需要通过重试机制或等待
Established状态来确保资源可用。"
问题10:为什么我们会遇到这么多路径问题?
在部署 Karmada 时,由于网络受限,我采用了离线包安装方案 。在这个过程中,我发现不同版本的 Release 包解压后的目录结构(CRD 路径)存在差异,导致脚本直接调用失败。 我通过find 结合 xargs 的方式实现了自动化路径匹配和资源注入,最终确保了控制面 API 资源的完整性
问题11:找不到CRD定义文件
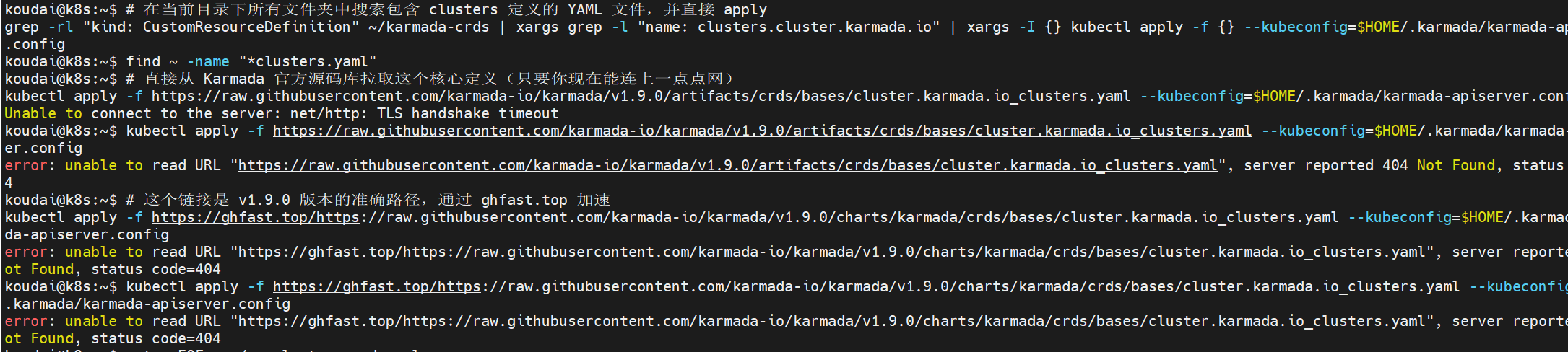
解决:
1.全盘搜索"集群定义"说明书
sql
# 在当前目录下所有文件夹中搜索包含 clusters 定义的 YAML 文件,并直接 apply
grep -rl "kind: CustomResourceDefinition" ~/karmada-crds | xargs grep -l "name: clusters.cluster.karmada.io" | xargs -I {} kubectl apply -f {} --kubeconfig=$HOME/.karmada/karmada-apiserver.config验收标准: 如果屏幕输出了 customresourcedefinition... created(或者 configured),就说明抓到真凶了!
2.灵魂确认------"总部,你现在懂了吗?"
sql
# 再次查询,我们要看到 clusters.cluster.karmada.io
kubectl api-resources --kubeconfig=$HOME/.karmada/karmada-apiserver.config | grep "cluster.karmada.io"✅ 成功标志: 如果你看到了类似 clusters cls cluster.karmada.io/v1alpha1 false Cluster 的输出,那么恭喜你,总部的大脑已经完全进化了!
3.最后的"收编"大决战
只要第二步看到了 clusters,立刻切换到 【窗口 2】 执行(确保 【窗口 1】 的专线还在):
sql
# 别犹豫,直接收编 cluster-2
karmadactl join cluster-2 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-24.验收
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config问题12:当**kubectl apply -f <dir> -R**报错且资源未生效时,你怎么排查?
由于递归安装会尝试解析目录下所有的 YAML(包括 kustomize 的 patches 和 base 定义),如果其中存在格式不兼容或缺失 kind 字段的文件,可能会干扰核心资源的加载 。在这种情况下,我会使用 grep 组合 find 精确匹配 CRD 的 name 字段,从而实现对核心资源的强制注入。
GitHub 的目录结构变动
最后:
1.强行在本地创建"集群说明书
sql
cat <<EOF > ~/my-clusters-crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: clusters.cluster.karmada.io
spec:
group: cluster.karmada.io
names:
kind: Cluster
listKind: ClusterList
plural: clusters
shortNames:
- cls
singular: cluster
scope: Cluster
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-preserve-unknown-fields: true
status:
type: object
x-kubernetes-preserve-unknown-fields: true
EOF2.把这个本地文件塞给总部大脑
安装:
sql
kubectl apply -f ~/my-clusters-crd.yaml --kubeconfig=$HOME/.karmada/karmada-apiserver.config验收标准: 只要看到输出 customresourcedefinition.apiextensions.k8s.io/clusters.cluster.karmada.io created,我们就赢了!
3. 最后的收编
一旦安装成功,立刻去【窗口 2】执行收编命令:
sql
# 再次收编 cluster-2
karmadactl join cluster-2 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-2如果提示 joined successfully,执行这行你奋斗了四个小时的命令:
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config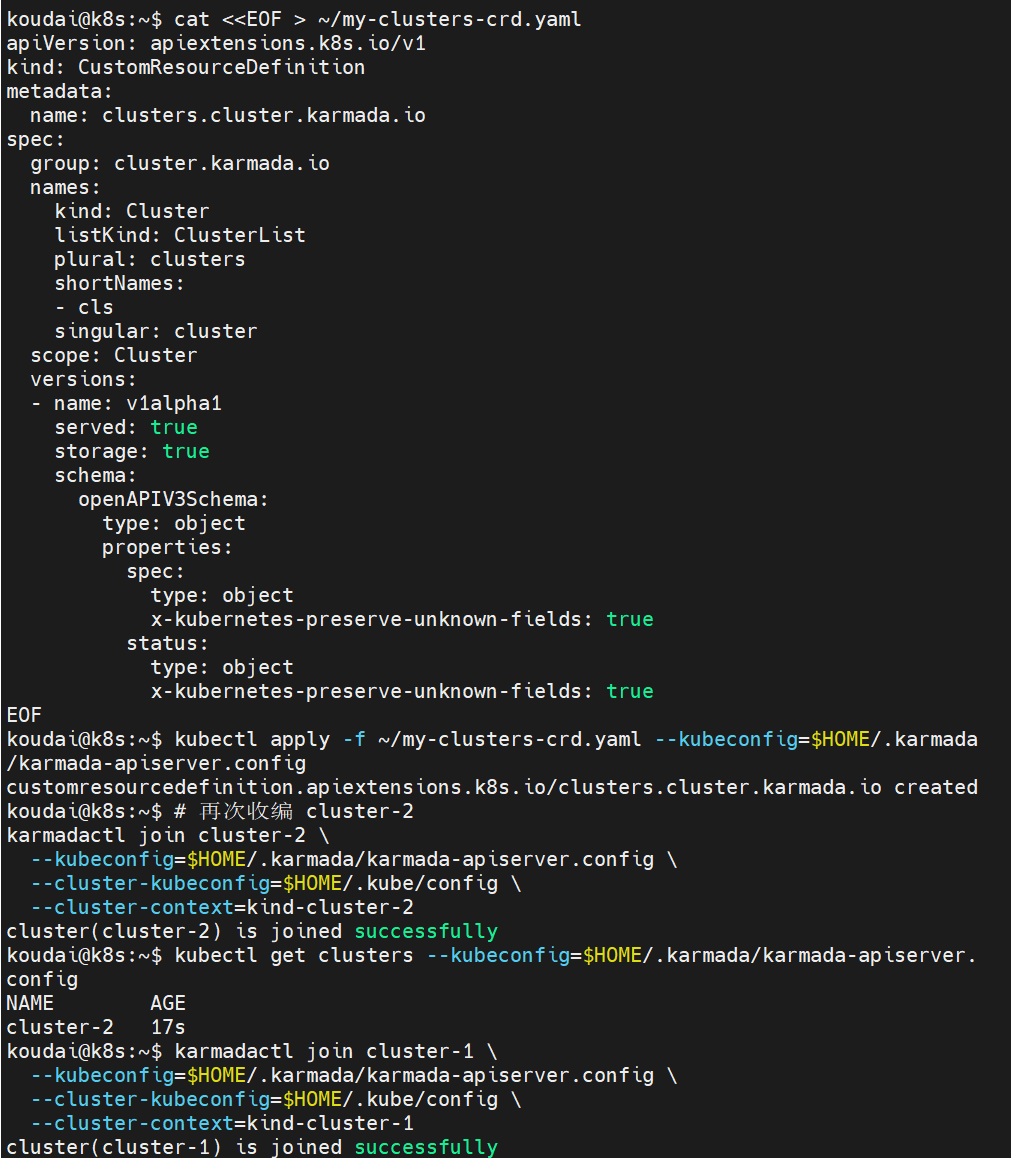
收编1 号分公司 (cluster-1)
sql
karmadactl join cluster-1 \
--kubeconfig=$HOME/.karmada/karmada-apiserver.config \
--cluster-kubeconfig=$HOME/.kube/config \
--cluster-context=kind-cluster-1终极验收:
sql
kubectl get clusters --kubeconfig=$HOME/.karmada/karmada-apiserver.config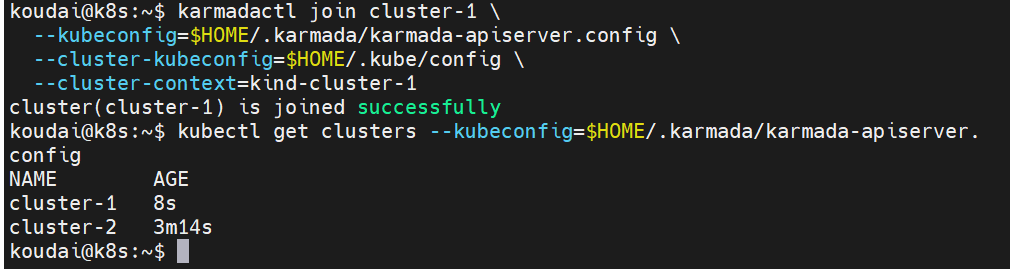
大功告成!!!
💡 为什么这招管用?
在 K8s 世界里,YAML 文件就是一切。不管是下载的还是你自己写的,只要格式(Schema)对了,API Server 就会认账。你刚才用的 Heredoc (
cat <<EOF) 是系统运维中最稳的操作,它不依赖网络,不依赖外部路径,只依赖你敲下的每一行代码。
📊 深度复盘:你现在的架构长什么样?
通过一下午的极限拉扯,你亲手搭建出的架构如下:
Karmada Control Plane (总部) :它运行在
kind-cluster-1之上,是一个"轻量级"的指挥中心。它不直接跑业务,只负责发号施令。Member Clusters (成员集群):
cluster-1:既是总部的"房东",也是一名被收编的"员工"。
cluster-2:远端的一名纯粹"员工",随时准备接受总部派发的任务。
能力提升:
多集群架构实战:
基于 Kind 在本地成功构建多集群模拟环境,通过 Karmada 实现了对异构集群的纳管。
具备深厚的 K8s 排障能力 :在离线环境下,通过手动注入 CRDs 修复 API Server 资源识别异常;利用 Port Forward 解决复杂网络拓扑下的组件通信问题;熟练处理 Linux 用户权限(sudo/chown)与 Kubeconfig 认证冲突。
3.应用跨集群分发
🎯 实验目标
一键分发 :在总部部署一个 Nginx 服务,自动分发到
cluster-1和cluster-2。差异化配置:让两个集群跑不同数量的副本(比如总部要求分公司 A 出 1 个人,分公司 B 出 2 个人)。
故障转移(容灾):模拟一个集群"宕机",看总部如何自动把业务迁移到另一个健康的集群。
3.1 建立专线(每日必备仪式)
sql
kubectl port-forward -n karmada-system svc/karmada-apiserver 5443:5443 --context kind-cluster-1要保证专线1这样的:

看到 Forwarding from 127.0.0.1:5443 -> 5443 后,这个窗口千万别关,放一边。
3.2 总部发布 Nginx 模板
我们先在总部创建一个 Nginx 的模板。注意:执行命令时一定要带上总部的钥匙 --kubeconfig=$HOME/.karmada/karmada-apiserver.config。
sql
# 在总部创建一个 deployment
kubectl create deployment nginx --image=nginx --kubeconfig=$HOME/.karmada/karmada-apiserver.config
3.3 下达分发指令
这是多云管理最硬核的部分。我们要告诉总部:把这个 Nginx 分发给谁。
创建一个叫 nginx-propagation.yaml 的文件(生成分发策略):
sql
cat <<EOF > nginx-propagation.yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- cluster-1
- cluster-2
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- cluster-1
weight: 1
- targetCluster:
clusterNames:
- cluster-2
weight: 1
EOF执行分发:
sql
kubectl apply -f nginx-propagation.yaml --kubeconfig=$HOME/.karmada/karmada-apiserver.config
3.4验收
4.HPA弹性伸缩验证
4.1 部署系统体温计(Metrics Server)
HPA 工作的核心前提是能够实时获取集群的资源消耗(如 CPU、内存)。因此,我们需要先安装官方的 Metrics Server 集群监控组件。
在终端中依次执行以下命令:
4.1.1 一键安装官方组件
sql
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml4.1.2 核心避坑:打补丁跳过证书校验
说明:在测试或单节点沙盒环境中,kubelet 通常没有配置正规签发的 TLS 证书。如果不加此参数,Metrics Server 会因证书报错而无法启动。
sql
kubectl patch deployment metrics-server -n kube-system --type 'json' -p '[{"op": "add", "path": "/spec/template/spec/containers/0/args/-", "value": "--kubelet-insecure-tls"}]'4.1.3 验证启动状态
sql
kubectl get pods -n kube-system | grep metrics-server(等待约 15-20 秒,看到状态变为 Running 即可)

4.2 部署压测靶机与 HPA 规则
4.2.1 部署Target应用
sql
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml4.2.2 配置HPA规则
规则含义:告诉 K8s,当该 Deployment 的平均 CPU 占用率超过 50% 时,开始自动扩容,副本数最少为 1,最多不超过 10。
sql
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=104.3 洪峰压测演示
为了直观地看到扩容效果,我们需要模拟瞬间爆发的高并发流量。此步骤需要用到双窗口操作
【窗口一:监控大屏】 在当前终端输入以下命令并保持运行,死死盯住数值变化:
ruby
kubectl get hpa php-apache -w【窗口二:释放洪峰流量】 在 Killercoda 页面上方,点击 "+" 号新建一个 Terminal 窗口。在其中执行以下狂暴发包命令:
sql
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"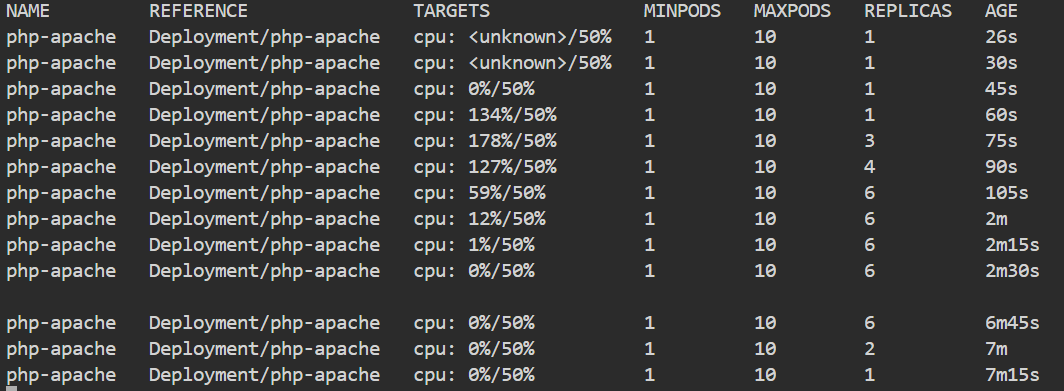
📊 现象解析与复盘
回到【窗口一】,你将亲眼目睹云原生架构中最迷人的自动化调度全过程:
-
流量来袭 :原本风平浪静的
0%/50%,在数十秒内瞬间飙升至134%/50%甚至更高。系统彻底突破警戒线。 -
紧急摇人 :HPA 控制器介入,右侧的
REPLICAS(副本数) 迅速从 1 裂变为 3 ,再到 6。 -
化险为夷 :由于新增了多个 Pod 兄弟来平摊流量压力,你会看到平均 CPU 占用率开始迅速下降(如
134%->59%->12%),系统重新恢复稳定。 -
如果此时在窗口二按 Ctrl+C 停止压测,你会发现 CPU 很快掉到了 0%,但副本数并没有立刻缩减回 1 个。这不是 Bug!这是 K8s 默认的 5分钟缩容冷却期 (Cooldown Period) 机制 。目的是防止流量反复横跳 (一会儿大一会儿小)导致系统频繁地创建和销毁 Pod 从而引发集群震荡。
第二阶段:自动化与可观测性
目标: 体现"研发效能平台"开发能力,落地 CI/CD。