Pre-train
1.收集海量无标注文本数据
2.进行模型预训练,并在任务模型中使用
Fine-tune 传统方法
设置模型结构
收集/标注训练数据
使用标注数据进行模型训练
真实场景模型预测
传统方法: Fine-true
预训练方法: Pre-train + Fine-true
预训练方式
1.完形填空
依照一定概率,用mask掩盖文本中的某个字或词
2.句子关系预测


BERT的本质是一种文本特征
文本 -> 矩阵
文本 -> 向量
word2vec 也可以做到同样的事
但word2vec是静态的,而BERT是动态的 这里是因为,word2vec可以把语言弄成向量,但是无法做到语义上的理解,就好比苹果,是指苹果手机还是能吃的苹果,word2vec做不到
BERT可以做到,因为它经过线性层,就好比RNN,就能理解
BERT成功的原因一个是预训练,另一个则是提出大名鼎鼎的结构,transformer结构
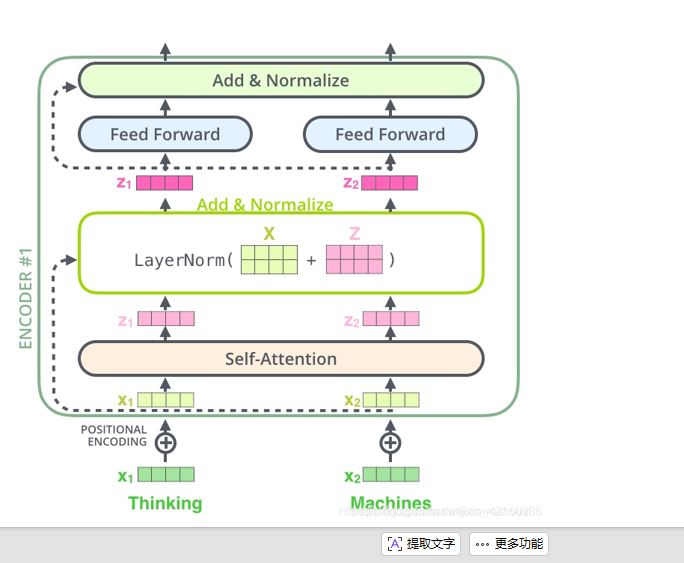
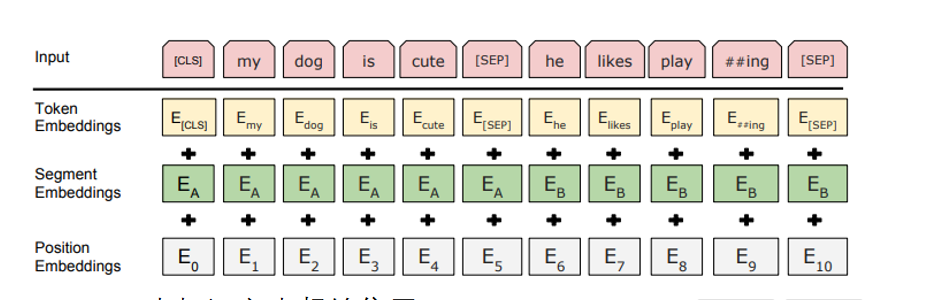
BERT结构 - Embedding
加入 CLS,SEP 来标记文本起始位置 BERT开源后V* h ,词表为2w多,h为768,
Segment embedding 判断来源语句 EA代表第一句 ,EB代表第二句,一共就准备两个embeding,第三句又会用上EA,第四句又会用上EB
Position embedding 带入语序信息
加和后会做 Layer Normalization
但是有个局限性,Position当时只准备了512个,无法适应超长的文本
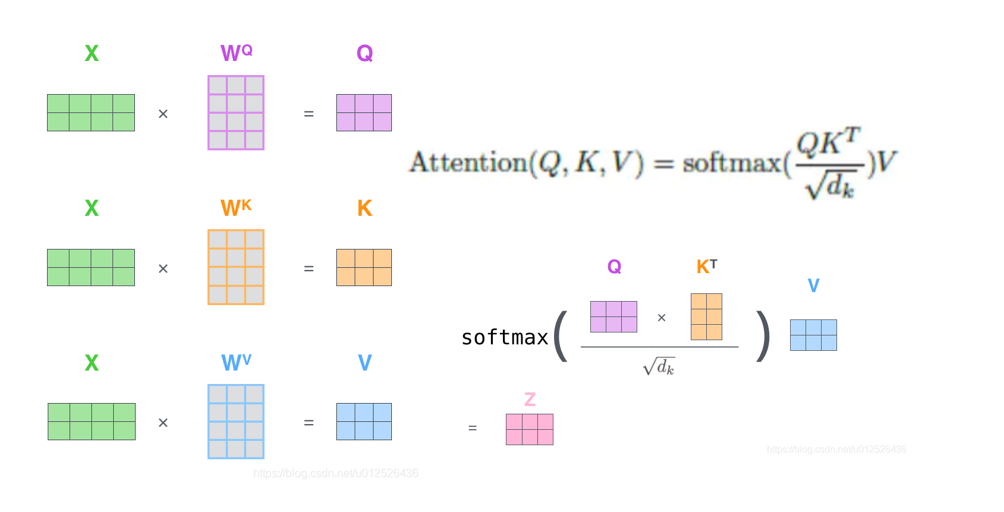
BERT结构 - self -attention
X为embedding层的输出,WQ,WK,WV都是 h*h,所以QKV是l*h
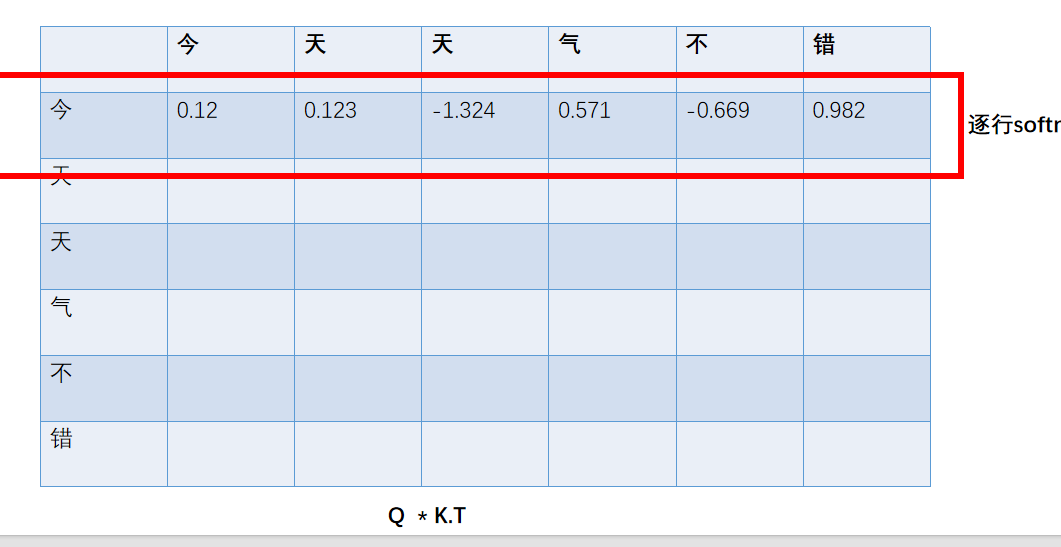
Q*K的转置 是L*L的矩阵,形成一个如下矩阵
这个矩阵很关键,它体现了自身到自身的注意力
接下来就是根号dk,多头机制
BERT结构 - Encoder
LayerNorm是干啥用的
因为,我们之间经历了很多神经网络层,为了防止"数据跑偏"和"梯度失控",强制把每一层数据拉回来
BERT的优势
1.通过预训练利用了海量无标注文本数据
2.想必词向量,BERT的文本表示结合了语境
3.Transformer模型结构由很强的拟合能力,词与词之间的距离不会造成关系计算上的损失
4.效果大幅提升