作者 :唐启宏¹*, 刘昌翰¹*, 张少峰², 李文斌¹, 范奇¹✉, 高阳¹
单位 :¹南京大学,²中国科学技术大学
*共同第一作者,✉通讯作者:范奇 <fanqi@nju.edu.cn>
摘要
在各种计算机视觉应用中,识别潜在物体对于物体识别和分析至关重要。现有方法通常依赖于示例图像、预定义类别或文本描述来定位潜在物体。然而,它们对图像和文本提示的依赖往往限制了灵活性,制约了在真实场景中的适应性。本文提出了一种新颖的无需提示的通用区域提议网络 (Prompt-Free Universal Region Proposal Network, PF-RPN),无需依赖外部提示即可识别潜在物体。首先,稀疏图像感知适配器 (Sparse Image-Aware Adapter, SIA)模块使用可学习的查询嵌入(通过视觉特征动态更新)对潜在物体进行初步定位。其次,级联自提示 (Cascade Self-Prompt, CSP)模块通过自提示的可学习嵌入,以级联方式自主聚合信息性视觉特征,识别剩余的潜在物体。最后,中心性引导的查询选择 (Centerness-Guided Query Selection, CG-QS)模块利用中心性评分网络促进高质量查询嵌入的选择。我们的方法可以使用有限数据(例如 5%5\%5% 的 MS COCO 数据)进行优化,并可直接应用于各种物体检测应用领域以识别潜在物体而无需微调,例如水下物体检测、工业缺陷检测和遥感图像物体检测。在 191919 个数据集上的实验结果验证了我们方法的有效性。代码地址:https://github.com/tangqh03/PF-RPN

1. 引言
近年来,基于区域提议网络(Region Proposal Network, RPN)12, 49 的物体检测方法在各种计算机视觉应用中取得了显著进展。区域提议网络(RPN)为潜在物体生成稀疏的提议框集合,这是物体检测的关键组件。然而,现有的 RPN 方法 34, 39, 64 往往无法从未见域中识别出目标物体。这一限制严重阻碍了物体检测在开放世界场景中的应用。
开放词汇物体检测(Open-Vocabulary Object Detection, OVD)模型 6, 8, 11, 13, 17, 32, 42 通过利用类别名称或示例图像作为提示,在定位未见域物体方面展现了令人印象深刻的能力。尽管 OVD 方法因其强大的泛化能力而适合作为 RPN 检测器,但它们对预定义类别和示例图像的依赖限制了实际场景中的灵活性。例如,在工业缺陷检测和水下物体检测场景中,目标类别和示例图像通常不可用,这大大限制了这些模型的应用。尽管一些无需提示的 OVD 模型 22, 29, 45, 52 探索使用生成式视觉-语言模型(VLMs)来消除手动提供提示的需求,但它们往往会引入显著的内存和延迟成本。因此,有必要提出一种高效的区域提议网络,能够在无需外部提示的情况下跨各种领域泛化。
在本文中,我们提出了一种新颖的无需提示的通用区域提议网络(PF-RPN),用于定位潜在物体,该方法可应用于不同的未见域,无需示例图像或文本描述。我们的模型使用有限数据进行优化,可直接应用于下游任务而无需额外微调。
PF-RPN 基于强大的 OVD 模型构建,通过可学习的视觉嵌入聚合信息性视觉特征,消除了手动提供提示的需求,同时保留了其强大的泛化能力。具体而言,可学习的查询嵌入由我们提出的稀疏图像感知适配器(SIA)模块初始化和更新,该模块通过选择性聚合多级视觉特征动态调整嵌入。该适配器使模型能够捕获不同空间分辨率下的显著视觉细节,增强复杂视觉场景中潜在物体的定位能力。
经 SIA 调整的可学习查询嵌入使模型能够识别具有显著视觉外观的物体。然而,该嵌入可能仍难以捕获视觉特征不清晰的挑战性物体,例如小物体或被遮挡物体。为缓解这一问题,我们提出级联自提示(CSP)模块,通过自提示机制迭代优化查询嵌入,以识别剩余的挑战性物体。查询嵌入通过聚合多尺度、信息丰富的视觉上下文逐步更新,使模型能够更有效地处理与小物体或被遮挡物体相关的歧义性。
此外,我们观察到靠近物体中心的查询嵌入往往比物体边缘的查询嵌入生成更准确的提议。这一观察促使我们设计中心性引导的查询选择(CG-QS)模块,该模块基于预测的中心性评分选择查询,在查询嵌入选择过程中强调物体的中心区域。聚焦于最中心区域有助于减少误报并提高模型生成提议的质量。
与传统和基于 OVD 的 RPN 方法相比,我们的 PF-RPN 在无需针对未见域重新训练或外部提示的情况下,显著提高了提议质量。使用有限数据训练的 PF-RPN 展现出强大的零样本泛化能力,在跨越不同领域和应用场景的 191919 个数据集上实现了一致的性能提升。
具体而言,在使用 100/300/900100/300/900100/300/900 个候选框时,PF-RPN 在 CD-FSOD 基准上分别实现了 6.0/7.5/6.66.0/7.5/6.66.0/7.5/6.6 的 AR 提升,在 ODinW13 基准上分别实现了 4.4/5.2/5.84.4/5.2/5.84.4/5.2/5.8 的 AR 提升,大幅超越了最先进(SOTA)模型。总之,我们的优势如下:
- 我们提出了一种新颖的无需提示的通用区域提议网络(PF-RPN),这是一种前沿模型,能够在实际开放世界场景中无需任何外部提示即可准确识别潜在物体。
- 我们提出了稀疏图像感知适配器、级联自提示和中心性引导查询选择,使我们的模型能够仅使用视觉特征有效检索潜在物体。
- 我们的 PF-RPN 使用有限数据(例如 5%5\%5% 的 COCO 数据)实现了强大的泛化性能,可直接应用于下游任务而无需额外微调。在 191919 个跨域数据集上的实验结果证明了我们模型的有效性。
2. 相关工作
开放词汇物体检测(Open-Vocabulary Object Detection)
近期在开放词汇和接地视觉-语言建模 6, 8, 13, 18, 21, 27, 40, 46, 51, 55, 59, 61 方面的进展极大地提升了检测器的泛化能力。GLIP 21 统一了检测与接地以进行语言感知预训练,Grounding DINO 27 通过视觉-语言融合增强了开放集检测能力。DetCLIPv2 51 进一步加强了词-区域对齐,而 YOLO-World 6 和 YOLOE 40 为准确、实时的 OVD 提供了高效的视觉-语言融合。然而,大多数方法仍依赖于文本提示或示例图像进行定位,当外部输入不可用时限制了灵活性。尽管 YOLOE 支持无需提示的检测,但其零样本泛化能力受限于静态文本代理。相比之下,我们的 PF-RPN 学习视觉嵌入并通过自提示进行优化,消除了对文本提示的需求,同时保持了强大的泛化能力。
无需提示的物体检测(Prompt-free Object Detection)
近期工作 22, 29, 45, 52 探索了无需提示的范式,直接生成物体描述。GenerateU 22 将检测公式化为将视觉区域映射到自由形式名称的生成过程,而 CapDet 29 通过预测类别标签或区域描述来桥接检测与图像描述。DetCLIPv3 52 将描述头集成到开放集检测器中,并利用自动标注数据进行预训练。然而,此类模型依赖于大型描述生成器,计算成本高且往往存在偏差。我们的 PF-RPN 使用可学习嵌入作为文本代理,以低延迟和内存成本实现无偏检测。
多模态大语言模型(Multimodal Large Language Models)
多模态大语言模型(MLLMs)将视觉感知和推理能力扩展到大语言模型。早期研究 9, 19, 37, 48, 50 专注于视觉-语言对齐以执行图像描述和视觉问答等任务,而后续工作 1, 2, 5, 30, 41, 43, 47, 53, 54, 62(如 Qwen3-VL、DeepSeek-VL2)则针对接地和 OCR 等任务的细粒度理解。尽管 MLLMs 具有强大的推理能力,但它们需要大量计算资源,且在跨域检测任务上的迁移能力有限。我们的 PF-RPN 在无需文本输入或大规模训练的情况下实现了可比的零样本泛化能力,提供了更低的延迟和部署成本。
3. 方法
3.1 方法概述
与现有的无需提示的开放词汇物体检测(PFOVD)方法 22, 45, 52 和 OVD 方法 6, 21, 27, 40 不同(这些方法依赖计算昂贵的描述生成器为图像 III 生成物体名称,或需要用户手动输入类别名称或示例图像),我们的 PF-RPN 无需任何文本或视觉提示即可直接跨不同领域提议潜在物体。
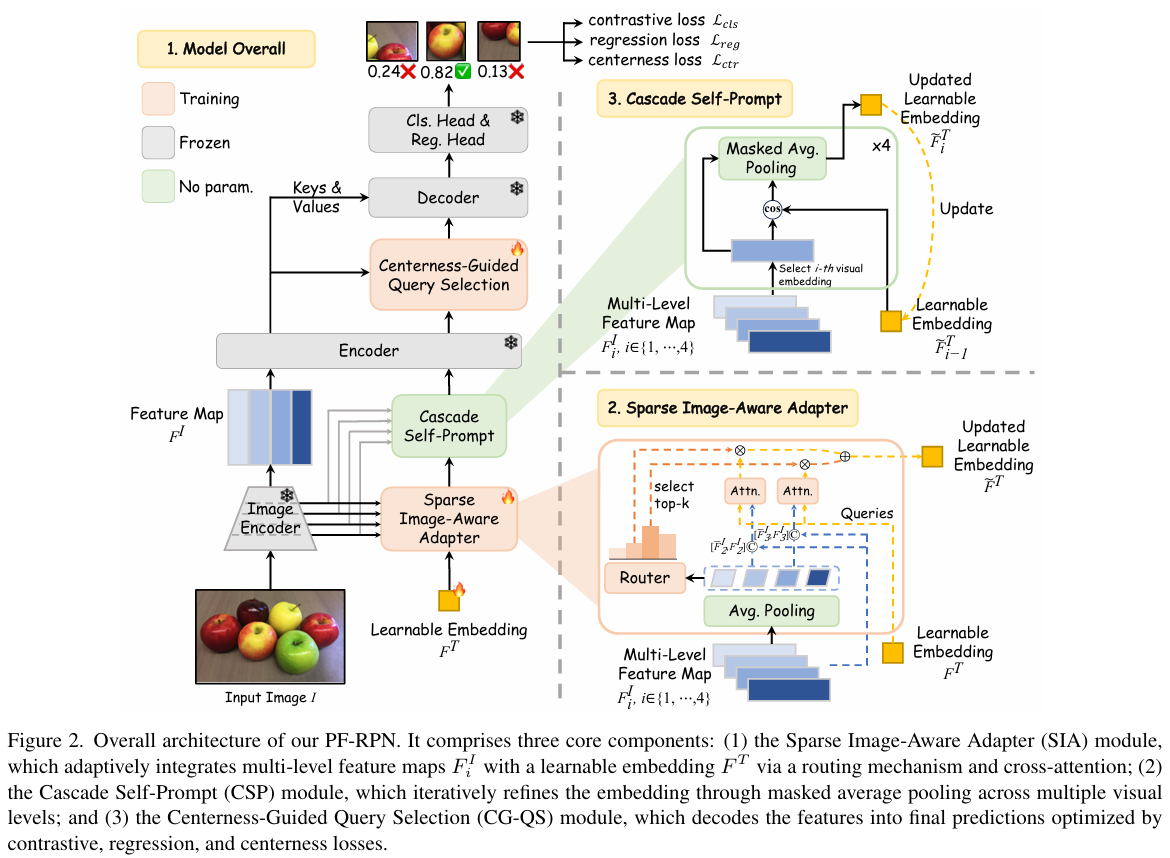
图 2 展示了 PF-RPN 的整体架构。首先,图像编码器(如 ResNet 14 或 Swin Transformer 28)提取多级特征图 FIi∈RHi×Wi×C,i∈{1,...,4}F_I^i \in \mathbb{R}^{H_i \times W_i \times C}, i \in \{1, \dots, 4\}FIi∈RHi×Wi×C,i∈{1,...,4},其中 Hi×WiH_i \times W_iHi×Wi 表示第 iii 个特征图的空间分辨率,CCC 为通道维度。然后,稀疏图像感知适配器 (SIA)通过路由机制和交叉注意力自适应地将 kkk 个最信息丰富的特征与可学习嵌入 FT∈R1×CF_T \in \mathbb{R}^{1 \times C}FT∈R1×C 集成。随后,级联自提示 (CSP)模块使用从深层到浅层的特征图逐步优化 FTF_TFT。最后,多级特征 FIiF_I^iFIi 被展平为 FI∈RH×W×CF_I \in \mathbb{R}^{H \times W \times C}FI∈RH×W×C 并用作记忆,遵循 DETR 类框架 4, 27, 57, 63。我们将 Grounding DINO 27 中的语言引导查询选择替换为我们的中心性引导的查询选择(CG-QS)模块以解码物体提议。整个框架在带有伪边界框的分类数据集和物体检测数据集上联合训练。
3.2 稀疏图像感知适配器(Sparse Image-Aware Adapter, SIA)
现有 OVD 方法 6, 21, 27, 40 主要关注对齐图像和文本特征以对检测框进行评分,但往往忽略了图像编码器中丰富的多级视觉线索。早期工作 25, 26 表明,不同层级的特征贡献不同------浅层特征有利于小物体,而深层特征捕获大物体------这表明在所有层级上进行朴素融合会引入冗余和噪声。为解决这一问题,我们提出稀疏图像感知适配器 (SIA),这是一个混合专家(Mixture-of-Experts, MoE)模块,自适应地选择并融合最信息丰富的特征层级与可学习嵌入 FTF_TFT。受基于视觉特征的提示调优 60 启发,SIA 用图像衍生表示替换预训练 OVD(如 Grounding DINO 27)中的文本嵌入,弥合了模态差距。
给定多级特征图 FIiF_I^iFIi,全局平均池化层提取紧凑特征 FˉIi∈RC\bar{F}_I^i \in \mathbb{R}^CFˉIi∈RC。MoE 路由器预测其重要性 wi=Router(FˉIi)w_i = \text{Router}(\bar{F}_I^i)wi=Router(FˉIi),其中 Router\text{Router}Router 是一个轻量级 MLP。然后我们选择 top-k\text{top-}ktop-k(k≤4k \le 4k≤4)特征层级并通过 softmax 归一化其权重。最后,FTF_TFT 作为查询,拼接特征 FˉIσ(j),FIσ(j)\\bar{F}_{I}\^{\\sigma(j)}, F_{I}\^{\\sigma(j)}FˉIσ(j),FIσ(j) 作为键-值对用于交叉注意力 33, 38 以生成更新后的嵌入:
F~T=∑j=1kw~σ(j)⋅Attn(FT,FˉIσ(j),FIσ(j))(1)\tilde{F}T = \sum{j=1}^{k} \tilde{w}_{\sigma(j)} \cdot \text{Attn}(F_T, \\bar{F}_{I}\^{\\sigma(j)}, F_{I}\^{\\sigma(j)}) \quad (1)F~T=j=1∑kw~σ(j)⋅Attn(FT,FˉIσ(j),FIσ(j))(1)
其中 σ(j),1≤j≤k\sigma(j), 1 \le j \le kσ(j),1≤j≤k 表示选定的特征层级。
提出的 SIA 模块稀疏地将多级视觉特征适配到可学习嵌入,同时保持物体尺度与特征层级之间的一致性。此外,通过同时利用全局特征 FˉIσ(j)\bar{F}{I}^{\sigma(j)}FˉIσ(j) 和局部特征 FIσ(j)F{I}^{\sigma(j)}FIσ(j),可学习嵌入被丰富了粗粒度和细粒度的视觉线索。如图 4 所示,通过强调语义相关的物体区域并抑制背景噪声,SIA 显著增强了可学习嵌入的定位能力。然而,仍观察到背景激活,这表明单步适配是不够的。为进一步优化嵌入并实现更精确的定位,我们在下一节引入 CSP 模块。

3.3 级联自提示(Cascade Self-Prompt, CSP)
虽然 SIA 模块用尺度相关线索丰富了可学习嵌入 F~T\tilde{F}_TF~T 并增强了其定位能力,但我们观察到如图 4 所示,某些背景区域可能仍被部分激活。这表明单步适配仍不足以完全抑制噪声响应。为进一步净化嵌入,我们设计了一种利用嵌入自身视觉激活的优化机制。
经验表明,物体内部特征比可学习嵌入本身具有更强的定位能力,这一发现我们在补充材料中进行了证明。这促使我们采用迭代优化方案,其中激活的视觉特征逐步引导 F~T\tilde{F}_TF~T 朝向更具判别性的表示。
此外,由于深层编码高级语义而浅层捕获细粒度结构细节 24, 56,我们以从深到浅的级联方式执行优化------首先聚合语义,然后整合结构。
基于这些见解,我们提出级联自提示 (CSP)模块,使用多级特征 FIiF_I^iFIi 迭代优化 F~T\tilde{F}TF~T。从 F~T0=F~T\tilde{F}{T_0} = \tilde{F}_TF~T0=F~T 开始,我们在每个层级生成相似性掩码:
Mi=1(cos(F~Ti−1,FIi)>δ)(2)M^i = \mathbb{1}(\cos(\tilde{F}{T{i-1}}, F_I^i) > \delta) \quad (2)Mi=1(cos(F~Ti−1,FIi)>δ)(2)
其中 δ\deltaδ 是手动设置的阈值(设为 0.30.30.3),cos\coscos 表示余弦相似度,1\mathbb{1}1 是指示函数。然后通过掩码平均池化更新嵌入:
F~Ti=F~Ti−1+MAP(Mi,FIi)(3)\tilde{F}{T_i} = \tilde{F}{T_{i-1}} + \text{MAP}(M^i, F_I^i) \quad (3)F~Ti=F~Ti−1+MAP(Mi,FIi)(3)
其中 MAP\text{MAP}MAP 表示掩码平均池化。通过从深层到浅层层级级联此过程,CSP 逐步扩展物体一致的激活同时抑制背景噪声。在 SIA 的强先验引导下,优化联合优化视觉一致性和评分可靠性,产生更精确和鲁棒的定位。图 3 说明了此迭代过程的有效性。为在准确性和效率之间实现最佳平衡,我们将迭代次数设为 333。
3.4 中心性引导的查询选择(Centerness-Guided Query Selection, CG-QS)
在 CSP 模块之后,我们可以定位潜在物体区域并获得其对应的查询。然而,每个查询的重要性很大程度上取决于其空间位置。如图 7 所示,靠近物体中心的查询往往比靠近物体边界的查询产生更准确的提议。因此,我们提出中心性引导的查询选择(CG-QS)模块来估计每个查询靠近物体中心的可能性。
具体而言,采用轻量级 MLP 作为中心评分网络为每个查询 fif_ifi 生成中心评分 gig_igi。同时,我们计算查询到对应真实框左、右、上、下边缘的距离以推导中心监督 cic_ici:
ci=min(l,r)max(l,r)×min(t,b)max(t,b)(4)c_i = \sqrt{\frac{\min(l, r)}{\max(l, r)} \times \frac{\min(t, b)}{\max(t, b)}} \quad (4)ci=max(l,r)min(l,r)×max(t,b)min(t,b) (4)
当查询更靠近真实框中心时,对应的监督 cic_ici 趋近于 111,网络被训练使预测评分 gig_igi 匹配 cic_ici。中心性损失然后定义为预测中心评分 gig_igi 与其监督 cic_ici 之间的 L1 距离,Lctr=∑i=1N∥gi−ci∥1L_{\text{ctr}} = \sum_{i=1}^{N} \|g_i - c_i\|_1Lctr=∑i=1N∥gi−ci∥1,其中 NNN 表示查询总数,∥⋅∥1\|\cdot\|_1∥⋅∥1 表示 L1 损失。
提出的 CG-QS 模块有效优先考虑靠近物体中心的视觉嵌入。在训练和推理过程中,给定通过可学习嵌入与查询的点积计算的分类评分,我们将评分网络生成的中心评分与这些分类评分结合用于查询选择,然后使用得到的评分确定最终候选查询集。
3.5 目标损失函数(Objective Loss)
先前的工作 10 表明,检测器的微调阶段会向图像编码器引入偏差,因为检测模型在检测数据集上微调,而图像编码器在分类数据集(如 ImageNet 7)上预训练。为缓解这一偏差,我们在 5%5\%5% 的带有伪边界框的 ImageNet 数据和 COCO 23 数据上联合微调我们的 PF-RPN,从而减少分类和检测数据之间的分布差距。
遵循 DETR 类框架 4, 21, 27, 57, 63,我们采用 L1 损失和 GIoU 损失 35 作为回归损失 LregL_{\text{reg}}Lreg,并使用查询与可学习嵌入 F~T4\tilde{F}_{T_4}F~T4 之间的对比损失进行分类评分。
为防止少数专家被过度激活而其他专家很少使用(导致负载不平衡),我们在专家权重 wi,i∈{1,...,4}w_i, i \in \{1, \dots, 4\}wi,i∈{1,...,4} 上引入辅助损失 Lrt=std(wi)L_{\text{rt}} = \text{std}(w_i)Lrt=std(wi) 以平衡专家间的负载并充分利用多级特征图,其中 std\text{std}std 表示经验标准差。最小化 LrtL_{\text{rt}}Lrt 鼓励路由器产生的专家权重 wiw_iwi 更均匀分布,改善负载平衡。最终,整体目标函数公式化为:
L=Lreg+Lcls+Lrt+λLctr(5)L = L_{\text{reg}} + L_{\text{cls}} + L_{\text{rt}} + \lambda L_{\text{ctr}} \quad (5)L=Lreg+Lcls+Lrt+λLctr(5)
其中 LregL_{\text{reg}}Lreg 和 LclsL_{\text{cls}}Lcls 遵循与 Grounding DINO 27 相同的配置。
4. 实验
我们采用带有 Swin-B 骨干网络的 Grounding DINO 27 作为基线。我们的模型在 5%5\%5% 的 COCO 23 数据集(808080 类)和 5%5\%5% 的 ImageNet 7 数据集(100010001000 类)上训练,可直接应用于下游任务而无需任何进一步微调。遵循先前工作 21,我们在 ODinW13 基准上评估我们的模型,该基准包含来自不同领域的数据集,如野生动物摄影、家居物品和航空影像。为进一步评估我们模型的泛化能力,我们还在 CD-FSOD 基准上评估我们的模型,该基准由六个具有明显域偏移的跨域数据集组成:ArTaxOr 31(昆虫图像)、Clipart1k 16(手绘卡通图像)、DIOR 20(遥感图像)、DeepFish 36(水下鱼类图像)、NEU-DET 15(工业缺陷图像)和 UODD 44(海洋生物图像)。在我们的实验中,我们使用平均召回率(Average Recall, AR)作为评估指标来评估我们的 PF-RPN 提议潜在物体的能力。所有实验在四块 NVIDIA RTX 4090 GPU 上进行。
4.1 定量结果
与 OVD 模型、RPN 和 MLLM 的比较 。如表 1 所示,我们将我们的 PF-RPN 与典型的开放词汇物体检测(OVD)模型进行比较。对于 OVD 模型,我们将对应数据集的类别名称输入模型以获得作为提议的检测框。同时,为进一步研究文本提示对模型性能的影响,我们还通过将类别名称替换为 "object" 作为模型文本输入,在无需提示的设置下评估其性能。我们的 PF-RPN 优于基线模型 Grounding DINO,在 CD-FSOD 基准上使用 100/300/900100/300/900100/300/900 个候选框时分别实现了 7.8/11.8/13.57.8/11.8/13.57.8/11.8/13.5 的 AR 提升。在 ODinW13 基准上,我们的 PF-RPN 在使用 100/300/900100/300/900100/300/900 个候选框时进一步超越 Grounding DINO 4.4/5.2/5.84.4/5.2/5.84.4/5.2/5.8 的 AR。与 OVD 模型 YOLOE 40 相比,我们的 PF-RPN 实现了 16.3/19.1/21.116.3/19.1/21.116.3/19.1/21.1 的 AR 性能提升。为进一步评估我们 PF-RPN 的泛化能力,我们还将其与 MLLM 进行比较。具体而言,与 Qwen2.5-VL-7B 2 相比,我们的 PF-RPN 在使用 100/300/900100/300/900100/300/900 个候选框时获得了 40.6/45.2/48.140.6/45.2/48.140.6/45.2/48.1 的 AR 提升。此外,与 Cascade RPN 39 相比,我们的 PF-RPN 在 ODinW13 基准上提升了 15.6/13.1/9.615.6/13.1/9.615.6/13.1/9.6 的 AR。
模块消融研究 。为评估每个模块的贡献,我们在 CD-FSOD 基准上进行模块消融研究。如表 2 所示,添加 SIA 模块将平均性能提升至 57.857.857.8 AR100_{100}100,优于基线,表明视觉特征在定位潜在物体方面比文本更有效。在此基础上,同时添加 SIA 和 CSP 模块进一步将性能提升至 60.260.260.2 AR100_{100}100,表明级联自提示策略通过迭代更新可学习嵌入以检索更多潜在物体,有效减少了漏检。添加 SIA 模块和 CG-QS 模块将性能提升至 59.659.659.6 AR100_{100}100,表明中心评分网络可以准确评估提议质量并帮助模型选择高质量提议。当组合所有模块时,我们的方法实现了 60.760.760.7 AR100_{100}100 的最佳性能,证实了这些模块之间的互补性。
数据消融研究 。为研究训练数据规模对我们模型的影响,我们在 CD-FSOD 基准上进行数据消融实验。如表 3 所示,增加来自 COCO 的检测数据比例会带来平均召回率(AR)的一致提升。值得注意的是,使用 1%1\%1% 到 5%5\%5% 的 COCO 带来的性能提升明显大于从 5%5\%5% 到 10%10\%10% 的提升,表明在进一步扩大数据规模时收益递减。因此,我们采用 5%5\%5% 的 COCO 作为性能和效率之间的权衡。此外,引入分类数据(ImageNet)带来了 AR 的额外提升,证明了其在缓解仅检测训练引起的图像编码器偏差方面的有效性。这证实了少量分类数据有助于增强跨模态对齐并提高我们模型的泛化能力。
与不同骨干网络的比较 。如表 4 所示,实验结果表明我们的模型在不同骨干网络上均实现了强大的性能。具体而言,当将我们的模型与 ResNet-50 骨干网络 14 集成时,性能提升了 5.25.25.2 AR100_{100}100,而使用 Swin-B 骨干网络 28 则带来了 7.87.87.8 AR100_{100}100 的提升。
SIA 中 MoE 模块的消融研究。为验证 MoE 模块的有效性,我们进行了如表 5 所示的消融实验。移除 MoE 导致性能一致下降,进一步验证了其重要性。实验结果表明,虽然注意力机制可以抑制无关信息,但它仅在单个特征层级内操作,无法跨层级选择。相比之下,MoE 模块在注意力阶段之前过滤掉无关的特征层级。由于不同尺度的物体在不同特征层级上表示最佳,仅依赖注意力将不可避免地引入来自非信息层级的噪声。
集成到训练良好的检测器中 。为评估我们模型的可扩展性,我们将我们的模型集成到现有的训练良好的基于 RPN 的检测器中。如表 6 所示,当我们将 DE-ViT 49 中的原始 RPN 替换为我们提出的模块时,检测器在 COCO 数据集上实现了 3.73.73.7 AP 的提升。此外,为评估我们模型在跨域场景中的泛化能力,我们将我们的模型集成到跨域检测器 CD-ViTO 12 中,并按照原始设置在 CD-FSOD 基准上评估其性能。实验结果表明,集成我们的模型在 CD-FSOD 基准上带来了 5.55.55.5 AP 的提升。
4.2 定性可视化
级联自提示模块 。在级联自提示(CSP)模块中,我们的核心思想是使用某些物体的视觉特征迭代检索剩余的潜在物体。为验证这一范式的有效性,我们可视化了不同迭代次数下选择的图像区域。如图 3 所示,在第一次迭代中,模型只能选择部分物体区域。在用选定的特征更新可学习嵌入后,它扩展到覆盖更多潜在物体区域。通过多次迭代,模型能够提议大多数潜在物体区域。

稀疏图像感知适配器 。在稀疏图像感知适配器(SIA)中,我们使用视觉特征动态适配可学习嵌入,使其能够提议未见类别的物体。为评估该模块的有效性,我们可视化了 SIA 更新前后可学习嵌入选择的区域。如图 4 所示,在更新之前,可学习嵌入对背景区域分配高注意力。如果将这些区域输入 CSP 模块,模型倾向于提议更多背景区域。相比之下,在用视觉特征更新后,可学习嵌入聚焦于物体区域并抑制背景干扰,强调了 SIA 的必要性。

中心性引导的查询选择。CG-QS 的核心思想是,靠近物体中心的图像查询往往比靠近物体边界的查询生成更准确的提议。如图 7 所示,当模型选择中心区域查询(红色星号)时,它产生精确的边界框。相比之下,当模块从边界区域选择查询时,通常会导致显著的定位误差。基于这一观察,我们引入中心损失以鼓励模型优先考虑更靠近物体中心的查询。为评估 CG-QS 策略的有效性,我们可视化了选定的图像查询,如图 5 所示。添加 CG-QS 模块后,我们的模型更倾向于选择中心位置的查询,证实了 CG-QS 策略的有效性。
5. 结论
在本文中,我们提出了无需提示的通用区域提议网络(PF-RPN),旨在解决计算机视觉中的一个关键限制:提议任意潜在物体的任务通常依赖于外部提示(如文本描述或视觉线索)。为缓解这一限制,PF-RPN 引入可学习嵌入作为文本嵌入的代理,实现无需提示的任意物体提议。我们提出了稀疏图像感知适配器和级联自提示模块,由于视觉嵌入之间的相似度通常大于可学习嵌入与视觉嵌入之间的相似度,这些模块增强了模型的定位能力。我们进一步提出了中心性引导的查询选择模块,该模块结合中心性和分类评分以选择更适合后续阶段的查询。大量实验证明了我们的 PF-RPN 在零样本跨域物体提议方面的优越性,为未来研究提供了宝贵见解。
补充材料
1. 关于 kkk 的消融研究
在第 3.2 节中,我们引入稀疏性以自适应地选择 top-k\text{top-}ktop-k 个信息丰富的特征图来更新可学习嵌入。在本节中,我们在 CD-FSOD 基准上对稀疏图像感知适配器模块中的 kkk 值进行消融,以检验稀疏性的影响。
如表 7 所示,当 k=2k=2k=2 时 PF-RPN 实现了最佳整体性能,因此我们在框架中选择 k=2k=2k=2 作为默认设置。增加 kkk 会引入更多冗余特征图并略微降低性能,而 kkk 过小会限制可用的上下文信息。这表明适度的稀疏性提供了最佳权衡。
表 7 . 稀疏图像感知适配器模块中参数 kkk 在 CD-FSOD 基准上的消融研究。最佳结果以粗体突出显示。
| kkk | AR100_{100}100 | AR300_{300}300 | AR900_{900}900 | ARs_ss | ARm_mm | ARl_ll |
|---|---|---|---|---|---|---|
| 111 | 60.360.360.3 | 64.764.764.7 | 67.467.467.4 | 44.244.244.2 | 60.060.060.0 | 78.878.878.8 |
| 2\mathbf{2}2 | 60.7\mathbf{60.7}60.7 | 65.3\mathbf{65.3}65.3 | 68.2\mathbf{68.2}68.2 | 38.5\mathbf{38.5}38.5 | 61.9\mathbf{61.9}61.9 | 80.3\mathbf{80.3}80.3 |
| 333 | 59.959.959.9 | 64.464.464.4 | 67.367.367.3 | 41.541.541.5 | 59.059.059.0 | 79.679.679.6 |
| 444 | 59.759.759.7 | 64.464.464.4 | 67.367.367.3 | 41.541.541.5 | 59.059.059.0 | 79.679.679.6 |
2. 关于目标损失函数的消融研究
在我们的目标损失函数中,我们引入超参数 λ\lambdaλ 来控制中心性损失对整体损失的贡献。为确定合适的设置,我们对 λ\lambdaλ 进行消融研究。如表 8 所示,当 λ\lambdaλ 过小时,模型无法学习选择位于中心区域的查询。相比之下,当 λ\lambdaλ 过大时,中心性损失主导优化并对回归性能产生负面影响。当 λ=5\lambda=5λ=5 时实现最佳性能。
表 8 . 目标损失中参数 λ\lambdaλ 在 CD-FSOD 基准上的消融研究。最佳结果以粗体突出显示。
| λ\lambdaλ | AR100_{100}100 | AR300_{300}300 | AR900_{900}900 | ARs_ss | ARm_mm | ARl_ll |
|---|---|---|---|---|---|---|
| 111 | 60.560.560.5 | 65.165.165.1 | 68.168.168.1 | 39.639.639.6 | 59.859.859.8 | 79.479.479.4 |
| 333 | 60.660.660.6 | 65.165.165.1 | 68.168.168.1 | 39.639.639.6 | 60.360.360.3 | 79.579.579.5 |
| 5\mathbf{5}5 | 60.7\mathbf{60.7}60.7 | 65.3\mathbf{65.3}65.3 | 68.2\mathbf{68.2}68.2 | 38.5\mathbf{38.5}38.5 | 61.9\mathbf{61.9}61.9 | 80.3\mathbf{80.3}80.3 |
| 777 | 58.558.558.5 | 63.163.163.1 | 66.366.366.3 | 37.137.137.1 | 58.358.358.3 | 79.279.279.2 |
| 999 | 59.659.659.6 | 64.364.364.3 | 67.467.467.4 | 39.739.739.7 | 59.659.659.6 | 78.978.978.9 |
3. 自提示的有效性
如图 8 所示,图 8a 中的物体内部特征以高语义一致性聚焦于物体区域,而图 8b 中的可学习嵌入产生更分散的响应。

这些观察表明,物体内部特征比可学习嵌入具有更强的定位能力。因此,在第 3.3 节中,我们利用多级特征图更新可学习嵌入,进一步增强其基于内部视觉线索定位物体的能力。
4. 延迟与效率分析
提出的迭代级联自提示(CSP)策略引入的可忽略延迟开销。如表 9 所示,将 CSP 迭代次数从 111 增加到 333 带来了一致的性能提升,同时推理时间仅略有增加(约 4.64.64.6 毫秒)。
表 9. CD-FSOD 基准上不同 CSP 迭代次数的延迟与性能分析。
| 迭代次数 | AR100_{100}100 | AR300_{300}300 | AR900_{900}900 | ARs_ss | ARm_mm | ARl_ll | ms/img |
|---|---|---|---|---|---|---|---|
| Iter 1 | 59.659.659.6 | 63.163.163.1 | 65.465.465.4 | 35.735.735.7 | 57.857.857.8 | 77.777.777.7 | 214.3214.3214.3 |
| Iter 2 | 59.959.959.9 | 63.763.763.7 | 65.965.965.9 | 36.736.736.7 | 57.957.957.9 | 78.278.278.2 | 216.7216.7216.7 |
| Iter 3 | 60.760.760.7 | 65.365.365.3 | 68.268.268.2 | 38.538.538.5 | 61.961.961.9 | 80.380.380.3 | 218.9218.9218.9 |
此外,提出的方法具有高灵活性,可与轻量级检测器无缝集成以作为实时、高性能的区域提议网络(RPN 34)运行。如表 10 所示,将提出的方法与 YOLO-World 6 集成在保持与传统 RPN 相当推理速度的同时实现了有竞争力的性能。
表 10. PF-RPN 与不同检测器集成的效率比较。
| 指标 | GLIP 27 | CasRPN 39 | RPN 34 | PF-RPN (GDINO) | PF-RPN (YWorld) |
|---|---|---|---|---|---|
| AR100_{100}100 | 47.647.647.6 | 45.845.845.8 | 32.032.032.0 | 60.760.760.7 | 52.352.352.3 |
| FPS | 5.55.55.5 | 24.824.824.8 | 27.827.827.8 | 4.64.64.6 | 25.125.125.1 |
5. 误报分析
RPN 旨在检测所有潜在物体,这一过程不可避免地会提议与任务无关的区域,从而产生误报(FP)。与现有 RPN 相比,提出的 PF-RPN 为真正的阳性物体候选分配更高的置信度评分,同时有效抑制无关区域。如表 11 所示,与 300300300 个提议设置相比,当限制为 100100100 个提议时,提出的方法在 AP 方面实现了更显著的提升,且误报数量更低。这一结果证明了所提出方法优先考虑高质量候选并减少冗余误报的能力。
表 11. 不同基线在不同顶部提议设置下的误报分析。
| 指标 | DeViT 49 Top 100 | DeViT 49 Top 300 | DeViT+Ours Top 100 | DeViT+Ours Top 300 | CD-ViTO 12 Top 100 | CD-ViTO 12 Top 300 | CD-ViTO+Ours Top 100 | CD-ViTO+Ours Top 300 |
|---|---|---|---|---|---|---|---|---|
| FP (↓) | 18.218.218.2 | 21.721.721.7 | 17.117.117.1 | 18.318.318.3 | 15.315.315.3 | 20.220.220.2 | 14.614.614.6 | 17.917.917.9 |
| AP (↑) | 32.332.332.3 | 33.433.433.4 | 37.3(+5.0)37.3 (+5.0)37.3(+5.0) | 37.1(+3.7)37.1 (+3.7)37.1(+3.7) | 26.826.826.8 | 29.029.029.0 | 34.2(+7.4)34.2 (+7.4)34.2(+7.4) | 35.1(+6.1)35.1 (+6.1)35.1(+6.1) |
6. 对基础检测器的依赖性
提出的方法表现出强大的可扩展性,可有效集成到各种基础检测器中。如表 12 所示,提出的方法直接从更强大的基础检测器中获益,随着基础模型容量的增加展现出稳定的性能提升。
表 12. 将 PF-RPN 与更强基础模型(MMGrounding DINO 58)集成的性能比较。
| 方法 | AR100_{100}100 | AR300_{300}300 | AR900_{900}900 | ARs_ss | ARm_mm | ARl_ll |
|---|---|---|---|---|---|---|
| MMGDINO-B | 72.472.472.4 | 73.573.573.5 | 73.973.973.9 | 46.446.446.4 | 66.766.766.7 | 78.778.778.7 |
| + Ours | 76.376.376.3 | 78.978.978.9 | 79.879.879.8 | 45.745.745.7 | 75.275.275.2 | 86.386.386.3 |
| MMGDINO-L | 73.673.673.6 | 74.274.274.2 | 74.574.574.5 | 48.348.348.3 | 69.869.869.8 | 79.479.479.4 |
| + Ours | 77.477.477.4 | 79.179.179.1 | 80.180.180.1 | 48.548.548.5 | 78.478.478.4 | 86.586.586.5 |
7. 与先前无需提示方法的比较
我们将 PF-RPN 与代表性的开源无需提示方法 GenerateU 22 和 Open-Det 3 进行比较。由于官方代码不可用,我们未包含 CapDet 29 和 DetCLIPv3 52。如表 13 所示,在 CD-FSOD 上 PF-RPN 超越 GenerateU +13.0+13.0+13.0 AR100_{100}100,同时将 VRAM 使用量减少 95%95\%95% 并将推理速度提升近 20×20\times20×。值得注意的是,由于移除了计算昂贵的文本编码器,PF-RPN 甚至比基线 GDINO 27 更快。
表 13. 与开源无需提示方法在性能和效率方面的比较。
| 基准 | 方法 | AR100_{100}100 | AR300_{300}300 | AR900_{900}900 | S | M | L | FPS | VRAM |
|---|---|---|---|---|---|---|---|---|---|
| CD-FSOD | GDINO 27 | 54.754.754.7 | 57.857.857.8 | 61.661.661.6 | 34.134.134.1 | 49.349.349.3 | 67.067.067.0 | 3.33.33.3 | 0.90.90.9G |
| GenerateU 22 | 47.747.747.7 | 54.154.154.1 | 55.755.755.7 | 28.128.128.1 | 48.348.348.3 | 69.469.469.4 | 0.220.220.22 | 12.212.212.2G | |
| Open-Det 3 | 36.636.636.6 | 46.346.346.3 | 54.354.354.3 | 28.228.228.2 | 45.345.345.3 | 67.767.767.7 | 0.150.150.15 | 30.730.730.7G | |
| PF-RPN(Ours) | 60.7\mathbf{60.7}60.7 | 65.3\mathbf{65.3}65.3 | 68.2\mathbf{68.2}68.2 | 38.5\mathbf{38.5}38.5 | 61.9\mathbf{61.9}61.9 | 80.3\mathbf{80.3}80.3 | 4.6\mathbf{4.6}4.6 | 0.5\mathbf{0.5}0.5G | |
| ODinW13 | GDINO 27 | 69.169.169.1 | 70.970.970.9 | 72.472.472.4 | 40.840.840.8 | 64.664.664.6 | 78.478.478.4 | 3.33.33.3 | 0.90.90.9G |
| GenerateU 22 | 67.367.367.3 | 71.571.571.5 | 72.272.272.2 | 32.832.832.8 | 63.163.163.1 | 80.080.080.0 | 0.220.220.22 | 12.212.212.2G | |
| Open-Det 3 | 53.953.953.9 | 62.962.962.9 | 69.169.169.1 | 27.727.727.7 | 59.859.859.8 | 76.676.676.6 | 0.150.150.15 | 30.730.730.7G | |
| PF-RPN(Ours) | 76.5\mathbf{76.5}76.5 | 78.6\mathbf{78.6}78.6 | 79.8\mathbf{79.8}79.8 | 45.4\mathbf{45.4}45.4 | 71.9\mathbf{71.9}71.9 | 85.8\mathbf{85.8}85.8 | 4.6\mathbf{4.6}4.6 | 0.5\mathbf{0.5}0.5G |
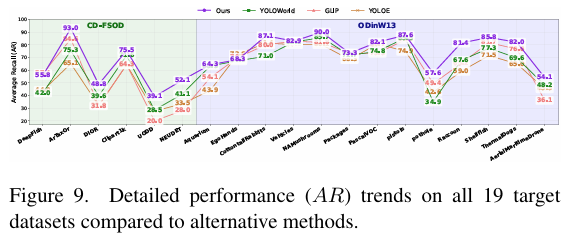
8. 所有 19 个数据集的详细实验结果
在 CD-FSOD 基准和 ODinW13 基准的各个数据集上报告了所提出方法的综合性能指标。此外,图 9 以折线图形式直观比较了这些结果与现有基线方法的结果。
致谢
本工作部分得到国家自然科学基金(621927836219278362192783, 622761286227612862276128, 624061406240614062406140)、中国科协青年人才托举工程(2023QNRC0012023\text{QNRC001}2023QNRC001)、江苏省重点研发计划(BE2023019\text{BE2023019}BE2023019)和江苏省自然科学基金(BK20221441\text{BK20221441}BK20221441, BK20241200\text{BK20241200}BK20241200)的支持。作者感谢华为昇腾云生态发展项目对昇腾 910 处理器的支持。
参考文献
1 Jinze Bai, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023.
2 Shuai Bai, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
3 Guiping Cao, et al. Open-det: An efficient learning framework for open-ended detection. In ICML, 2025.
4 Nicolas Carion, et al. End-to-end object detection with transformers. In ECCV, 2020.
5 Zhe Chen, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, 2024.
6 Tianheng Cheng, et al. Yolo-world: Real-time open-vocabulary object detection. In CVPR, 2024.
7 Jia Deng, et al. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
8 Yu Du, et al. Learning to prompt for open-vocabulary object detection with vision-language model. In CVPR, 2022.
9 Zhengxiao Du, et al. Glm: General language model pretraining with autoregressive blank infilling. In ACL, 2022.
10 Qi Fan, et al. Few-shot object detection with model calibration. In ECCV, 2022.
11 Shenghao Fu, et al. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. In CVPR, 2025.
12 Yuqian Fu, et al. Cross-domain few-shot object detection via enhanced open-set object detector. In ECCV, 2024.
13 Xiuye Gu, et al. Open-vocabulary object detection via vision and language knowledge distillation. In ICLR, 2022.
14 Kaiming He, et al. Deep residual learning for image recognition. In CVPR, 2016.
15 Yibin Huang, et al. Surface defect saliency of magnetic tile. The Visual Computer, 2020.
16 Naoto Inoue, et al. Cross-domain weakly-supervised object detection through progressive domain adaptation. In CVPR, 2018.
17 Prannay Kaul, et al. Multi-modal classifiers for open-vocabulary object detection. In ICML, 2023.
18 Weicheng Kuo, et al. F-vlm: Open-vocabulary object detection upon frozen vision and language models. In ICLR, 2022.
19 Junnan Li, et al. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023.
20 Ke Li, et al. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS journal of photogrammetry and remote sensing, 2020.
21 Liunian Harold Li*, et al. Grounded language-image pre-training. In CVPR, 2022.
22 Chuang Lin, et al. Generative region-language pretraining for open-ended object detection. In CVPR, 2024.
23 Tsung-Yi Lin, et al. Microsoft coco: Common objects in context. In ECCV, 2014.
24 Tsung-Yi Lin, et al. Feature pyramid networks for object detection. In CVPR, 2017.
25 Tsung-Yi Lin, et al. Feature pyramid networks for object detection. In CVPR, 2017.
26 Shu Liu, et al. Path aggregation network for instance segmentation. In CVPR, 2018.
27 Shilong Liu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In ECCV, 2024.
28 Ze Liu, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021.
29 Yanxin Long, et al. Capdet: Unifying dense captioning and open-world detection pretraining. In CVPR, 2023.
30 Haoyu Lu, et al. Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525, 2024.
31 Fatma MA Mazen. Arthropod taxonomy orders object detection in artaxor dataset using yolox. Journal of Engineering and Applied Science, 2023.
32 Matthias Minderer, et al. Scaling open-vocabulary object detection. In NIPS, 2023.
33 Yongming Rao, et al. Denseclip: Language-guided dense prediction with context-aware prompting. In CVPR, 2022.
34 Shaoqing Ren, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. TPAMI, 2016.
35 Hamid Rezatofighi, et al. Generalized intersection over union: A metric and a loss for bounding box regression. In CVPR, 2019.
36 Alzayat Saleh, et al. A realistic fish-habitat dataset to evaluate algorithms for underwater visual analysis. Scientific reports, 2020.
37 Peter Tong, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. In NIPS, 2024.
38 Ashish Vaswani, et al. Attention is all you need. In NIPS, 2017.
39 Thang Vu, et al. Cascade rpn: Delving into high-quality region proposal network with adaptive convolution. NeurIPS, 2019.
40 Ao Wang, et al. Yoloe: Real-time seeing anything. In ICCV, 2025.
41 Peng Wang, et al. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024.
42 Tao Wang. Learning to detect and segment for open vocabulary object detection. In CVPR, 2023.
43 Weiyun Wang, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025.
44 Yu Wei, et al. Underwater detection: A brief survey and a new multitask dataset. International Journal of Network Dynamics and Intelligence, 2024.
45 Jialian Wu, et al. Grit: A generative region-to-text transformer for object understanding. In ECCV, 2024.
46 Size Wu, et al. Aligning bag of regions for open-vocabulary object detection. In CVPR, 2023.
47 Zhiyu Wu, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302, 2024.
48 Chunyu Xie, et al. Ccmb: A large-scale chinese cross-modal benchmark. In ACMMM, 2023.
49 Guanyu Xu, et al. Devit: Decomposing vision transformers for collaborative inference in edge devices. CoRL, 2024.
50 Guowei Xu, et al. Llava-cot: Let vision language models reason step-by-step. In ICCV, 2025.
51 Lewei Yao, et al. Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment. In CVPR, 2023.
52 Lewei Yao, et al. Detclipv3: Towards versatile generative open-vocabulary object detection. In CVPR, 2024.
53 Yuan Yao, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024.
54 Tianyu Yu, et al. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe. arXiv preprint arXiv:2509.18154, 2025.
55 Alireza Zareian, et al. Open-vocabulary object detection using captions. In CVPR, 2021.
56 Matthew D Zeiler, Rob Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014.
57 Hao Zhang, et al. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In ICLR, 2023.
58 Xiangyu Zhao, et al. An open and comprehensive pipeline for unified object grounding and detection. arXiv preprint arXiv:2401.02361, 2024.
59 Yiwu Zhong, et al. Regionclip: Region-based language-image pretraining. In CVPR, 2022.
60 Kaiyang Zhou, et al. Conditional prompt learning for vision-language models. In CVPR, 2022.
61 Xingyi Zhou, et al. Detecting twenty-thousand classes using image-level supervision. In ECCV, 2022.
62 Jinguo Zhu, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025.
63 Xizhou Zhu, et al. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2021.
64 Wenbin Zou, et al. Sc-rpn: A strong correlation learning framework for region proposal. TIP, 2021.