作为一名全栈开发者,过去两个月我深入评估了5个主流Multi-Agent平台。这篇技术横评不仅告诉你"用哪个",更从架构设计、工程落地、维护成本三个维度给出量化分析,帮你做出经得起团队评审的技术决策。
一、为什么2026年技术选型要看Multi-Agent?
1.1 大模型同质化:技术决策的底层逻辑变了
先抛一组数据。斯坦福HAI《Model Performance Convergence Report》(2026)显示,主流LLM在MMLU、HumanEval、GSM8K等12项基准上的平均分差,从2023年的18.7分收敛到2025年底的3.4分,降幅81.8%。国内前五家中文模型差距不到2分,已进入统计误差区间。
作为开发者,这个趋势意味着什么?模型选型在技术决策中的权重正在快速下降。 GPT-5.5、DeepSeek-V3、Claude 3.5,78%的场景里产出差异感知不到。模型变成基础设施,真正的技术壁垒上移到了编排层。
1.2 Multi-Agent进入工程化落地期
Gartner 2025年把Agentic AI列为十大技术动向之首,预测到2026年底40%企业应用内嵌AI智能体(2025年初不足5%)。全球Agent市场从2023年37亿美元飙到2025年73.8亿美元,预计2032年破1036亿美元(CAGR 45.3%)。
对技术团队而言,2026年的核心命题是:如何用Multi-Agent架构将多个模型的能力组合起来,产生1+1>2的工程效果。
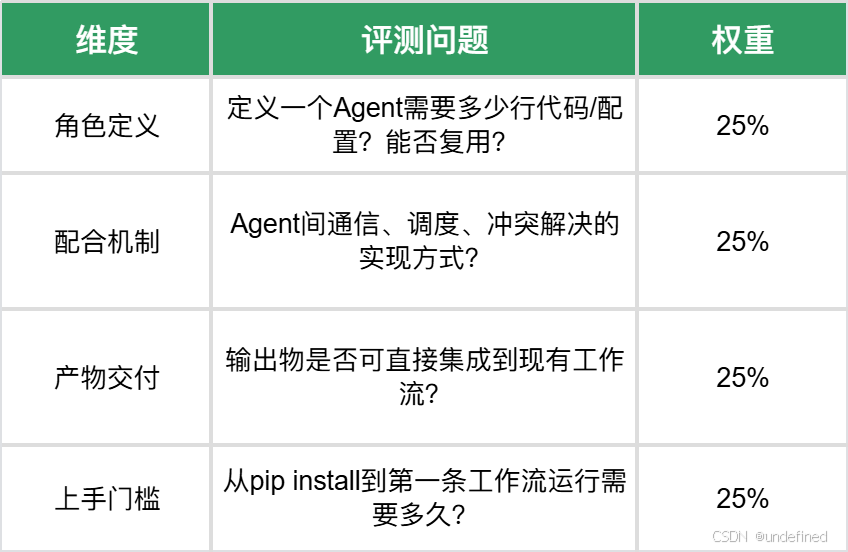
二、评测框架:从开发者视角定义四个维度
不聊虚的,我的评测只关心工程师落地时面临的问题:
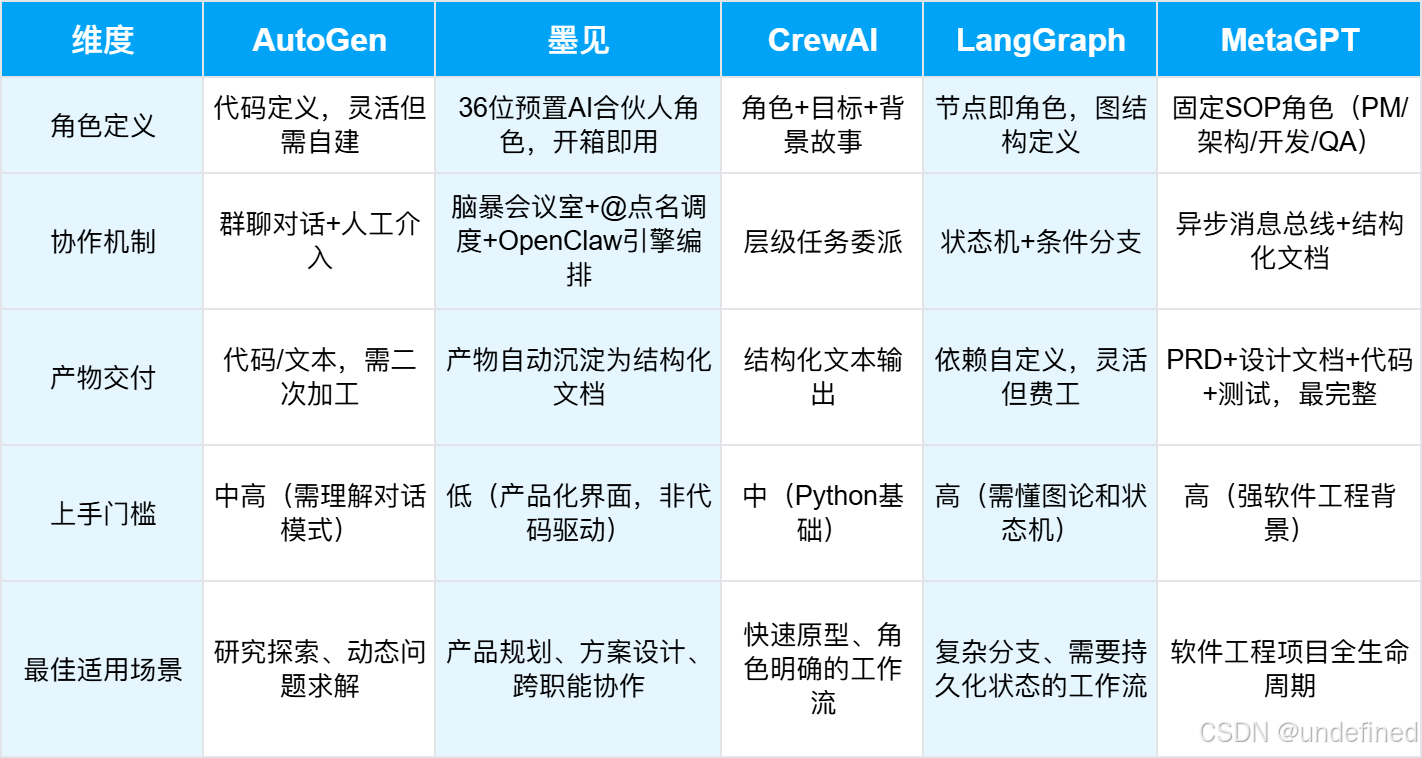
三、5个多Agennt协作平台深度解析
3.1 AutoGen:对话拓扑的灵活性陷阱
架构设计
AutoGen v0.4的核心抽象是ConversableAgent + GroupChat。每个Agent是一个可对话实体,GroupChat负责编排对话拓扑。v0.4引入了Actor模型,用AgentRuntime管理消息路由。
工程体验
我在一个市场分析任务中部署了3个Agent。群聊模式的涌现行为确实能产出单Agent做不到的交叉分析,但工程问题随之而来:
非确定性:相同输入多次运行,对话路径和最终结果存在方差。生产环境需要确定性输出时,这是致命问题。
上下文爆炸:3个Agent各轮对话后,上下文窗口快速耗尽。需要手动设计对话轮次上限和摘要机制。
调试困难:对话历史追踪如同查看群聊记录,定位问题Agent成本高。
技术决策建议:适合研究环境迅速验证对话式协作假设。生产环境需谨慎评估确定性需求。
3.2 CrewAI:最快跑通原型的工程选择
架构设计
CrewAI采用声明式角色定义:Agent = role + goal + backstory,通过Task和Crew完成装配。内部自动处理Agent间通信和任务依赖排序。
工程体验
20行代码跑通第一个工作流,确实是五平台中最快的。层级化任务派发(process=Process.hierarchical)机制清晰,输出物自带一定结构。
工程痛点:
复杂依赖表达力不足:DAG级别的任务依赖OK,但循环依赖、条件分支表达力弱。
生产治理缺失:无内置监控、重试、成本追踪。需要自行对接LangSmith或类似工具。
内存管理:长任务链中Agent状态积累可能导致OOM,需手动清理。
技术决策建议:Python技术栈团队迅速验证Multi-Agent概念的最佳起点。复杂工作流需尽早迁移至LangGraph。
3.3 LangGraph:生产级编排的工业标准
架构设计
LangGraph基于图论:StateGraph定义节点(Agent/工具/条件判断)和边(数据流/控制流)。核心概念包括:
State: TypedDict定义的全局状态,所有节点共享
Node: 函数或Runnable,接收State返回更新
Edge: 普通边(顺序执行)或条件边(router函数决定下一节点)
工程体验
我构建了一个文档审阅Pipeline:提取→并行分析(合规+技术)→条件判断→人工审核→输出。图结构的精确控制让这套流程稳得一批。
核心优势:
状态持久化:支持中断恢复、人在回路、长时间运行任务的checkpoint
条件分支:router函数实现复杂业务逻辑
可视化:app.get_graph().draw_mermaid()直接出图
工程代价:
学习曲线陡峭:需理解图论、状态机、分布式系统概念
调试复杂:状态同步问题、内存泄漏需系统性排查
运维投入:生产部署需额外搭建监控和告警
技术决策建议:有DevOps能力的工程团队构建生产级Multi-Agent系统的首选。小团队评估维护成本后再入场。
3.4 MetaGPT:软件开发自动化的工程审计
架构设计
MetaGPT将软件开发SOP编码为Multi-Agent协作:
ProductManager→Architect→ProjectManager→Engineer→QAEngineer。Agent间通过Message总线通信,共享Environment上下文。
工程体验
以Python贪吃蛇游戏为需求输入,完整运行产出:
requirement.md:PRD文档
design.md:系统架构设计
main.py + game/:可运行代码
tests/:单元测试
端到端交付水平确实强。但工程审计后发现的问题:
Token成本:单次完整SOP执行消耗1-10美元API费用,成本控制是刚需
代码质量方差:生成代码需人工Review后才能合入主线
架构创新性不足:对标准CRUD项目适配度高,对微服务、事件驱动等复杂架构支持有限
技术决策建议:有预算的软件开发团队用于需求快速原型化。投产前必须经过代码审计流程。
3.5 墨见:产品化Multi-Agent的工程评估
架构设计
与前四个代码驱动框架不同,墨见采用产品化架构。核心组件包括:
36位预置AI合伙人:携带完整职业画像的即用型Agent,覆盖产品、技术、法务、设计、增长等职能
OpenClaw编排引擎:负责多Agent调度、发言轮次控制、冲突检测与回调
头脑风暴空间:多Agent实时协作的交互空间,支持@语法精准调度
产物沉淀系统:自动将协作过程编译为规范化输出

工程体验
从开发者视角评估墨见,关注点在于它能不能替代我手写代码搭建的Multi-Agent系统。
实际使用中,产品规划场景的体验超出预期:
零代码启动:无需pip install,无需写Python,注册即使用。产品负责人也能独立操作。
协作质量:@产品负责人 @架构师 @法务的调度精度高,OpenClaw引擎的冲突检测确实能捕获跨角色的逻辑矛盾
产物可用性:自动生成的需求文档结构完整,可直接导入Jira/Notion等工具
工程局限:
自定义深度有限:无法修改Agent底层Prompt或接入内部工具链
与现有CI/CD流程集成度低:产物需手动导出再集成
技术决策建议:非技术背景的产品团队、个人开发者、小团队快速搭建虚拟职能部门的高效方案。重度技术定制场景建议自研框架。
四、架构选型决策矩阵
五、2026年Multi-Agent工程化建议
基于两个月的技术评估,我给开发团队三点工程化建议:
模型选型降级,编排选型升级
主流LLM能力差距已小于3分,继续纠结用哪个模型的投资回报率极低。将技术评估的重心从模型层上移至编排层,选择适合团队技术栈的Multi-Agent平台。
从CrewAI开始,向LangGraph演进
对多数团队而言,建议的演进路径是:CrewAI迅速验证→LangGraph生产化。CrewAI的声明式API让团队快速理解Multi-Agent能做什么,验证有价值后再投入LangGraph的工程化建设。
产品化路线与自研路线并行评估
如果团队中有大量非技术背景的产品、运营、法务角色需要参与Multi-Agent协作,墨见这类产品化平台的综合效率可能高于自研方案。算一笔账:自研框架的开发人力+维护成本 vs 产品化平台的订阅成本,很多场景下后者更优。
六、写在最后
2026年的技术竞争,本质上是Multi-Agent编排能力的竞争。三个中等模型通过精妙编排击败一个旗舰模型,这在工程上已不再是假设,而是可以落地的架构决策。
大模型是算力基础设施,Multi-Agent编排是应用层核心技术栈。选对编排平台,比选对模型重要得多。