本文是《LSTM实战(中篇):微博情感分析------Bi-LSTM模型架构解析》系列的收尾篇 。本篇重点解析
train_eval_test.py中的工程化训练策略 ,以及main.py的推理预测闭环,最终完成完整项目的端到端串联。⚠️ 声明:本项目代码面向学习入门,提供完整可运行的思路框架,模型调优、超参数搜索等进阶优化不在本代码体现范围内。
一、训练流程总览
train_eval_test.py → train()
│
├─ 步骤1:统计训练集类别分布 → 计算有效数量权重
├─ 步骤2:初始化 Adam 优化器 + ReduceLROnPlateau 调度器
├─ 步骤3:循环训练(20个epoch)
│ ├─ 正向传播 → 加权交叉熵损失
│ ├─ 反向传播 → 梯度裁剪 → 参数更新
│ ├─ 每100批打印训练指标
│ └─ 每个epoch结束:评估验证集 + 测试集
├─ 步骤4:保存最优模型权重(best_model.pth)
└─ 步骤5:早停检测(连续4个epoch验证损失不下降则停止)二、train_eval_test.py 完整源代码
以下是 train_eval_test.py 的完整源代码,无任何省略:
python
import torch
import torch.nn.functional as F
import numpy as np
from sklearn.metrics import classification_report
def eval(model, data_iter, class_list, N=False):
"""
评估函数(核心修正:严格关闭梯度、正确切换模型模式、填充标签列表)
:param model: 模型实例
:param data_iter: 待评估的数据集迭代器(dev/test)
:param class_list: 类别列表(如['喜悦','愤怒','厌恶','低落'])
:param N: 控制返回值
- False: 返回 (准确率, 平均损失)
- True: 返回 (准确率, 平均损失, 分类报告str)
:return: 按N的不同返回对应结果
"""
model.eval() # 切换到评估模式
with torch.no_grad(): # 关闭梯度计算
loss_sum = 0.0
correct = 0
total = 0
true_labels = [] # 真实标签列表
pred_labels = [] # 预测标签列表
for (text, labels) in data_iter:
output = model(text)
loss = F.cross_entropy(output, labels)
loss_sum += loss.item()
# 计算准确率
pred = torch.argmax(output, dim=1)
correct += (pred == labels).sum().item()
total += labels.size(0)
# 填充标签列表(用于分类报告)
true_labels.extend(labels.cpu().numpy()) # 转到CPU并转numpy
pred_labels.extend(pred.cpu().numpy())
acc = correct / total
avg_loss = loss_sum / len(data_iter)
if N:
# 生成分类报告
cls_report = classification_report(true_labels, pred_labels, target_names=class_list, digits=4,zero_division=0)
return acc, avg_loss, cls_report
return acc, avg_loss
def train(model, train_iter, dev_iter, test_iter, class_list,device):
"""
训练函数(核心修正:调整评估位置、恢复训练模式、修复早停逻辑)
"""
model.train() # 初始化为训练模式
# 第一步:统计训练集的类别分布(先从train_iter中提取所有标签)
all_labels = []
for (text, labels) in train_iter:
all_labels.extend(labels.cpu().numpy())
class_counts = np.bincount(all_labels) # 统计每个类别的样本数
# 方式1:逆频率权重(基础版)
# class_weights = torch.tensor((len(all_labels) / (len(class_list) * class_counts)), dtype=torch.float32).to(device)
# 方式2:有效权重(更鲁棒,避免极端值)
# 处理不平衡数据时可当做固定模版使用
beta = 0.999
effective_num = 1.0 - np.power(beta, class_counts)
class_weights = (1.0 - beta) / effective_num
class_weights = torch.tensor(class_weights / np.sum(class_weights) * len(class_list), dtype=torch.float32).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4, weight_decay=1e-5)
# 自适应学习率,当min监控损失越小越好,0.7当3轮损失不减少时,学习率乘0.7下降
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.7, patience=3, verbose=True)
epochs = 20
total_batch = 0
dev_best_loss = float('inf')
last_improve = 0
#早停按Epoch计数
no_improve_epoch = 0 # 连续多少个Epoch验证损失没下降
early_stop_epoch = 4 # 连续4个Epoch没提升就停(可调整)
stop_train = False
for epoch in range(epochs):
if stop_train:
break
print(f'\nEpoch [{epoch + 1}/{epochs}]')
train_loss_sum = 0.0
train_correct = 0
train_total = 0
# 训练批次循环(仅做训练,不做评估) 数据类型(x,seq_len),y
for i, (trains, labels) in enumerate(train_iter):
# 确保模型处于训练模式(防止eval后未切换回来)
model.train()
output = model(trains) #model.forward(trains)
loss = F.cross_entropy(output, labels, weight=class_weights)
# 梯度回传
optimizer.zero_grad()# 1.清空梯度
loss.backward() # 2.反向传播,算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0)# 3.梯度裁剪
optimizer.step() # 4.更新权重
# 累计训练指标
train_loss_sum += loss.item()
pred = torch.argmax(output, dim=1) #按行取最大值dim=1:每行找最大。
train_correct += (pred == labels).sum().item()
train_total += labels.size(0)
total_batch += 1
# 每100批次打印训练集指标
if i % 100 == 0:
train_acc = train_correct / train_total
print(f'批次 [{total_batch}] | 训练损失: {loss.item():.4f} | 训练集准确率: {train_acc:.4f}')
# ========== 每个Epoch结束后,统一评估验证集+测试集(核心修正) ==========
# 评估验证集
dev_acc, dev_loss = eval(model, dev_iter, class_list, N=False)
# 评估测试集
test_acc, _ = eval(model, test_iter, class_list, N=False)
print(f'\n【Epoch {epoch + 1} 评估结果】')
print(f'验证集准确率: {dev_acc:.4f} | 验证集平均损失: {dev_loss:.4f}')
print(f'测试集准确率: {test_acc:.4f}')
#学习率调度(基于验证集损失)
scheduler.step(dev_loss)
# 保存最优模型,加早停机制
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), 'best_model.pth')
print(' 最优模型已更新保存')
no_improve_epoch = 0 # 重置无提升计数
else:
no_improve_epoch += 1
print(f' 验证集损失未下降,连续无提升Epoch数: {no_improve_epoch}/{early_stop_epoch}')
if no_improve_epoch >= early_stop_epoch:
print(' 验证集损失长期未下降,触发早停')
stop_train = True
break
# 训练结束,加载最优模型生成分类报告
print('\n===== 训练完成,加载最优模型生成分类报告 =====')
model.load_state_dict(torch.load('best_model.pth'))
_, _, cls_report = eval(model, test_iter, class_list, N=True)
print('测试集分类报告:\n', cls_report)三、eval 函数逐段解析
3.1 评估模式切换
python
model.eval() # 切换到评估模式
with torch.no_grad(): # 关闭梯度计算评估时必须关闭 Dropout(model.eval())和梯度计算(torch.no_grad()),两者缺一不可,否则会:
- 消耗额外显存
- 增加计算量
- 可能导致 BatchNorm 使用训练阶段的统计量
3.2 指标累积
python
for (text, labels) in data_iter:
output = model(text)
loss = F.cross_entropy(output, labels)
loss_sum += loss.item()
pred = torch.argmax(output, dim=1)
correct += (pred == labels).sum().item()
total += labels.size(0)
true_labels.extend(labels.cpu().numpy())
pred_labels.extend(pred.cpu().numpy())torch.argmax(output, dim=1):沿dim=1(行方向)取最大值索引,即每条样本的预测类别labels.cpu().numpy():必须先转到 CPU 再转 numpy,才能与 sklearn 兼容
3.3 分类报告
python
if N:
cls_report = classification_report(
true_labels, pred_labels,
target_names=class_list,
digits=4,
zero_division=0
)
return acc, avg_loss, cls_report
return acc, avg_lossN 参数控制返回值:
N |
返回值 | 使用场景 |
|---|---|---|
False |
(acc, avg_loss) |
训练过程中快速评估 |
True |
(acc, avg_loss, cls_report) |
训练结束后生成完整分类报告 |
分类报告示例(训练结束时输出):
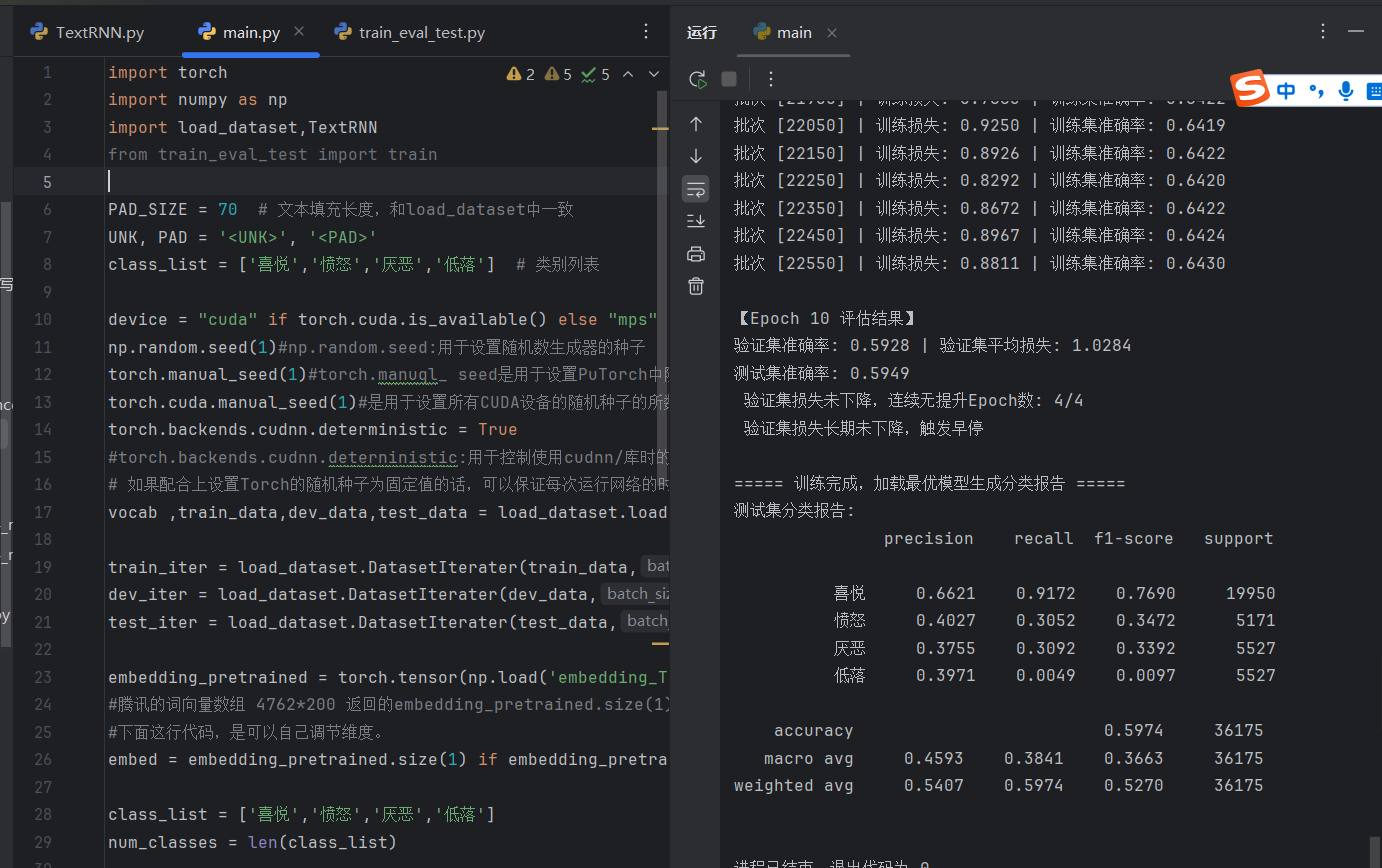
四、train 函数逐段解析
4.1 类别权重计算
python
# 第一步:统计训练集的类别分布
all_labels = []
for (text, labels) in train_iter:
all_labels.extend(labels.cpu().numpy())
class_counts = np.bincount(all_labels) # 统计每个类别的样本数np.bincount([0,1,0,2,0,3,0]) → [4,1,1,1],统计各类别的样本数量。
4.2 有效数量权重(Class-Balanced Loss)
python
beta = 0.999
effective_num = 1.0 - np.power(beta, class_counts)
class_weights = (1.0 - beta) / effective_num
class_weights = torch.tensor(
class_weights / np.sum(class_weights) * len(class_list),
dtype=torch.float32
).to(device)公式原理(来自 CVPR 2019 论文《Class-Balanced Loss Based on Effective Number of Samples》):
Effective Number(n) = (1 - β^n) / (1 - β)
β = 0.999 时:
- 样本多的类别 → effective_num ≈ 1 → 权重 ≈ 0.001
- 样本少的类别 → effective_num << 1 → 权重显著放大效果对比(示例):
| 类别 | 样本数 | 逆频率权重 | 有效数量权重 |
|---|---|---|---|
| 喜悦 | 10000 | 0.25 | 0.18 |
| 愤怒 | 3000 | 0.83 | 0.68 |
| 厌恶 | 2000 | 1.25 | 1.04 |
| 低落 | 1500 | 1.67 | 1.50 |
有效数量权重比简单逆频率权重更鲁棒,避免极端样本数差距导致的权重爆炸。
4.3 优化器与学习率调度
python
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.7, patience=3, verbose=True
)| 参数 | 值 | 含义 |
|---|---|---|
lr |
5e-4 | 初始学习率 |
weight_decay |
1e-5 | L2 正则化系数,防止过拟合 |
mode='min' |
- | 监控验证集损失,越小越好 |
factor=0.7 |
- | 连续 patience 个 epoch 不下降时,学习率乘 0.7 |
patience=3 |
- | 容忍 3 个 epoch 不提升 |
学习率衰减示意:
Epoch 1-3: lr=5e-4(损失持续下降)
Epoch 4-6: lr=3.5e-4(1次触发)
Epoch 7-9: lr=2.45e-4(2次触发)
Epoch 10+: lr=1.72e-4(3次触发)...4.4 单批次训练步骤(标准五步法)
python
for i, (trains, labels) in enumerate(train_iter):
model.train() # ① 切回训练模式
output = model(trains) # ② 正向传播
loss = F.cross_entropy(output, labels, weight=class_weights) # ③ 计算加权损失
optimizer.zero_grad() # ④ 清空梯度
loss.backward() # ⑤ 反向传播,算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0) # ⑥ 梯度裁剪
optimizer.step() # ⑦ 参数更新梯度裁剪(Gradient Clipping):
python
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)LSTM 在训练长序列时仍可能出现梯度爆炸。梯度裁剪将梯度的 L2 范数限制在 max_norm=5.0 以内:
若 ||grad|| > 5.0,则 grad = grad × (5.0 / ||grad||)4.5 早停机制
python
no_improve_epoch = 0 # 连续无提升 epoch 计数
early_stop_epoch = 4 # 超过4个epoch无提升,触发早停
stop_train = False
for epoch in range(epochs):
# ... 训练代码 ...
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), 'best_model.pth') # 保存最优权重
print(' 最优模型已更新保存')
no_improve_epoch = 0 # 重置计数器
else:
no_improve_epoch += 1
print(f' 验证集损失未下降,连续无提升Epoch数: {no_improve_epoch}/{early_stop_epoch}')
if no_improve_epoch >= early_stop_epoch:
print(' 验证集损失长期未下降,触发早停')
stop_train = True
break早停 + 保存最优模型的完整逻辑:
Epoch 1: dev_loss=0.45 → 新最优,保存 best_model.pth
Epoch 2: dev_loss=0.41 → 新最优,保存 best_model.pth
Epoch 3: dev_loss=0.43 → 无提升,no_improve=1
Epoch 4: dev_loss=0.44 → 无提升,no_improve=2
Epoch 5: dev_loss=0.45 → 无提升,no_improve=3
Epoch 6: dev_loss=0.47 → 无提升,no_improve=4 → 触发早停!
最终加载 Epoch2 的 best_model.pth 用于测试保存最优 + 早停的组合是业务场景中防止过拟合的黄金搭档。
五、main.py 完整源代码
以下是 main.py 的完整源代码,无任何省略:
python
import torch
import numpy as np
import load_dataset, TextRNN
from train_eval_test import train
PAD_SIZE = 70 # 文本填充长度,和load_dataset中一致
UNK, PAD = '<UNK>', '<PAD>'
class_list = ['喜悦','愤怒','厌恶','低落'] # 类别列表
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
np.random.seed(1)#np.random.seed:用于设置随机数生成器的种子
torch.manual_seed(1)#torch.manuql_ seed是用于设置PuTorch中随机数生成器的种了的函数。它将为当前进程设置一个随机种了。
torch.cuda.manual_seed(1)#是用于设置所有CUDA设备的随机种子的所数。官将为每个CUDA设备设置相同的随机种子,以确保在不同的运行获取相同结果
torch.backends.cudnn.deterministic = True
#torch.backends.cudnn.deterninistic:用于控制使用cudnn/库时的算法是否确定。如果将这个标志设置为True,每次返回的卷积算法将是确定的.
# 如果配合上设置Torch的随机种子为固定值的话,可以保证每次运行网络的时候输入是固定的。
vocab ,train_data,dev_data,test_data = load_dataset.load_dataset('simplifyweibo_4_moods.csv')
train_iter = load_dataset.DatasetIterater(train_data,128,device)
dev_iter = load_dataset.DatasetIterater(dev_data,128,device)
test_iter = load_dataset.DatasetIterater(test_data,128,device)
embedding_pretrained = torch.tensor(np.load('embedding_Tencent.npz')["embeddings"].astype('float32'))
#腾讯的词向量数组 4762*200 返回的embedding_pretrained.size(1) = 200
#下面这行代码,是可以自己调节维度。
embed = embedding_pretrained.size(1) if embedding_pretrained is not None else 200
#类别
class_list = ['喜悦','愤怒','厌恶','低落']
num_classes = len(class_list)
# model = TextRNN.Model(embedding_pretrained,len(vocab),embed,num_classes).to(device)
# train(model,train_iter,dev_iter,test_iter,class_list,device)
if __name__ == "__main__":
# 1. 初始化模型并加载训练好的权重
model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
model.load_state_dict(torch.load("best_model.pth")) # 加载最优模型权重
# 预测功能核心代码
def preprocess_text(text, vocab, pad_size=70):
"""
预处理输入文本:分词(按字)→ 转ID → 填充/截断 → 转Tensor
:param text: 输入的原始文本
:param vocab: 训练好的词汇表字典
:param pad_size: 文本固定长度(和训练时一致)
:return: 模型可接收的tensor格式数据 (1, pad_size)
"""
# 1. 按字分词(和训练时的tokenizer逻辑一致)
tokenizer = lambda x: [y for y in x]
tokens = tokenizer(text)
# 2. 填充/截断到固定长度
if len(tokens) < pad_size:
tokens.extend([PAD] * (pad_size - len(tokens)))
else:
tokens = tokens[:pad_size]
# 3. 转成词汇表对应的ID(处理UNK/PAD)
token_ids = [vocab.get(word, vocab.get(UNK)) for word in tokens]
# 4. 转成Tensor并适配模型输入格式
# 模型输入需要 (x, seq_len),这里seq_len不影响(模型已删除长度相关逻辑),随便填一个即可
x = torch.LongTensor([token_ids]).to(device) # batch_size=1
seq_len = torch.LongTensor([pad_size]).to(device)
return (x, seq_len)
def predict_mood(model, text, vocab):
"""
预测文本的情绪类别
:param model: 加载好的模型
:param text: 输入文本
:param vocab: 词汇表
:return: 预测的情绪类别名称
"""
# 1. 预处理文本
input_data = preprocess_text(text, vocab, PAD_SIZE)
# 2. 模型预测(关闭梯度,避免显存占用)
model.eval() # 切换到评估模式
with torch.no_grad():
output = model(input_data)
pred_idx = torch.argmax(output, dim=1).cpu().item() # 获取预测类别索引
# 3. 返回类别名称
return class_list[pred_idx]
# 2. 循环接收用户输入并预测
while True:
user_input = input("请输入要预测的文本:")
if user_input.lower() == 'q':
print("退出程序...")
break
if not user_input.strip():
print("输入不能为空,请重新输入!")
continue
# 3. 预测并输出结果
pred_mood = predict_mood(model, user_input, vocab)
print(f"预测结果:{pred_mood}\n")六、main.py 逐段解析
6.1 设备选择与随机种子
python
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed(1)
torch.backends.cudnn.deterministic = True设备优先级: CUDA GPU > Apple MPS > CPU
随机种子设置的目的:
- 保证每次运行的输入数据划分顺序一致
- 配合
cudnn.deterministic=True保证每次返回的卷积算法是确定的 - 使实验结果可复现
6.2 词向量加载
python
embedding_pretrained = torch.tensor(
np.load('embedding_Tencent.npz')["embeddings"].astype('float32')
)
# embedding_pretrained.shape = [4762, 200]
embed = embedding_pretrained.size(1) if embedding_pretrained is not None else 200
# embed = 200- 从
.npz文件中读取腾讯预训练词向量矩阵 astype('float32')确保精度与 PyTorch 默认一致
6.3 训练模式(注释代码)
python
# model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
# train(model, train_iter, dev_iter, test_iter, class_list, device)取消注释即可开始训练,训练结束后重新注释回去,恢复推理模式。
6.4 文本预处理(推理)
python
def preprocess_text(text, vocab, pad_size=70):
# 1. 按字分词
tokenizer = lambda x: [y for y in x]
tokens = tokenizer(text)
# 2. 填充/截断
if len(tokens) < pad_size:
tokens.extend([PAD] * (pad_size - len(tokens)))
else:
tokens = tokens[:pad_size]
# 3. 转ID
token_ids = [vocab.get(word, vocab.get(UNK)) for word in tokens]
# 4. 转Tensor
x = torch.LongTensor([token_ids]).to(device) # [1, 70]
seq_len = torch.LongTensor([pad_size]).to(device) # [1]
return (x, seq_len)预处理必须与训练时完全一致(同样按字分词,同样 pad_size=70),否则词ID序列会错位。
6.5 推理预测
python
def predict_mood(model, text, vocab):
input_data = preprocess_text(text, vocab, PAD_SIZE)
model.eval()
with torch.no_grad():
output = model(input_data) # [1, 4]
pred_idx = torch.argmax(output, dim=1).cpu().item() # 取最大值索引
return class_list[pred_idx] # 返回情感标签名称model.eval()+torch.no_grad()是推理标配torch.argmax(output, dim=1)取 logit 最大的类别索引(0~3).cpu().item()从 GPU Tensor 提取 Python 标量
6.6 交互式预测循环
python
while True:
user_input = input("请输入要预测的文本:")
if user_input.lower() == 'q':
print("退出程序...")
break
if not user_input.strip():
print("输入不能为空,请重新输入!")
continue
pred_mood = predict_mood(model, user_input, vocab)
print(f"预测结果:{pred_mood}\n")输入 q 退出程序,输入空字符串会提示重新输入。
七、实际运行效果
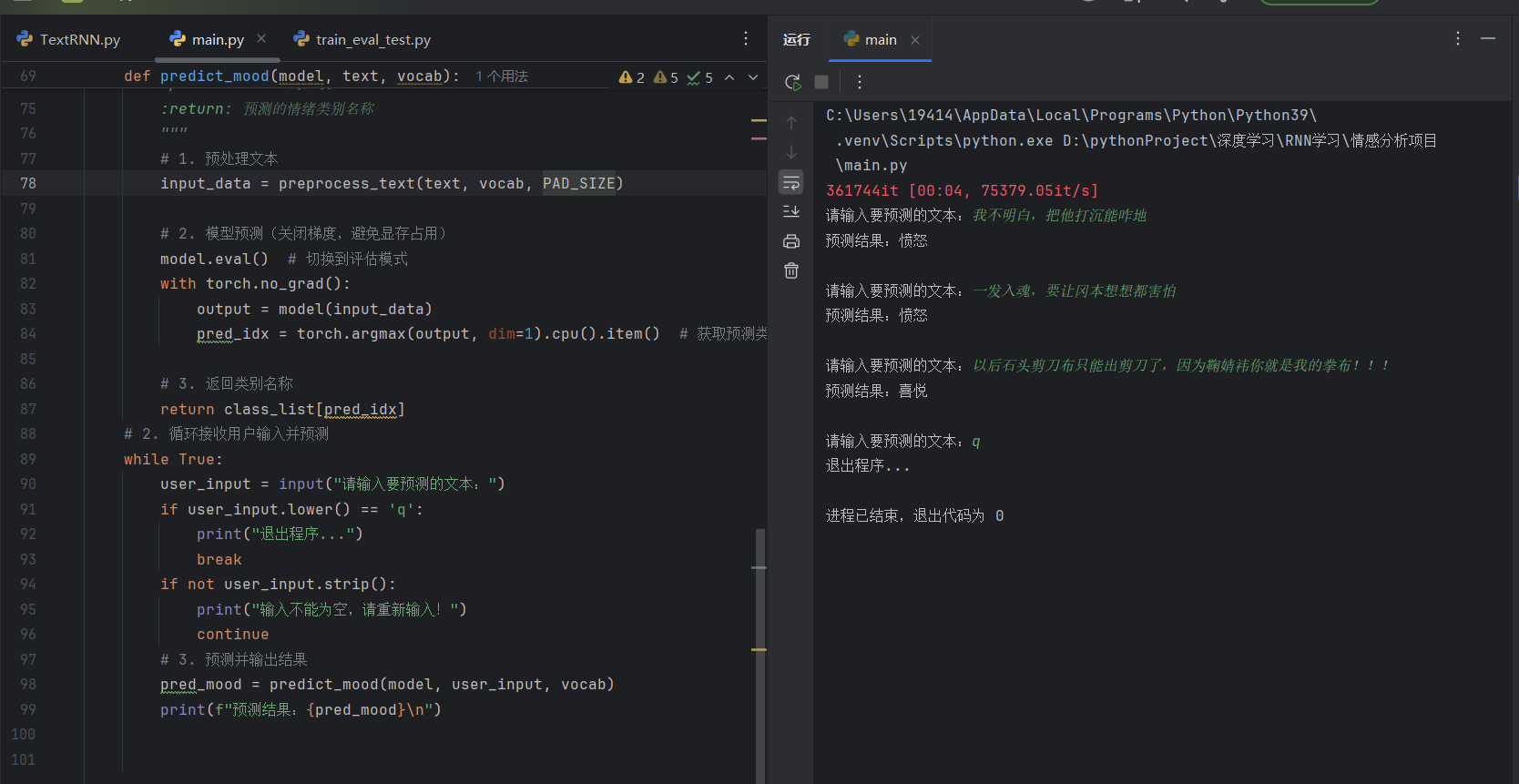
八、完整流程串联
python
# main.py 中训练时的完整调用顺序(取消注释即可训练):
# model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
# train(model, train_iter, dev_iter, test_iter, class_list, device)
# main.py 中推理时的完整调用顺序(当前模式):
model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
model.load_state_dict(torch.load("best_model.pth"))
while True:
pred_mood = predict_mood(model, user_input, vocab)训练与推理共用同一个模型初始化入口,只需切换注释即可,体现了良好的代码组织方式。
九、项目总结
至此,三篇系列博客完整呈现了一个基于 Bi-LSTM 的微博情感分析项目从数据到部署的全流程,所有代码均为原始完整版本,无任何删减:
| 篇章 | 模块 | 完整文件 | 核心内容 |
|---|---|---|---|
| 上篇 | 数据预处理 | save_vocab.py + load_dataset.py |
词表构建、字符分词、分层数据集划分、批次迭代器 |
| 中篇 | 模型架构 | TextRNN.py |
预训练词向量加载、3层双向LSTM、Mean Pooling、分类头 |
| 下篇 | 训练推理 | train_eval_test.py + main.py |
类别权重平衡、学习率调度、梯度裁剪、早停、推理预测 |
技术栈一览:
PyTorch + sklearn + numpy + tqdm
├── 腾讯预训练词向量(4762×200)
├── 双向3层LSTM(双向拼接256维)
├── Class-Balanced Loss(有效数量权重)
├── Adam + ReduceLROnPlateau
├── 梯度裁剪(max_norm=5.0)
└── 早停 + 最优模型保存系列文章脉络:
Word2Vec/CBOW(词向量) ↓ RNN → LSTM(序列建模,解决长期依赖)
心内容 |
|------|------|----------|----------|
| 上篇 | 数据预处理 | save_vocab.py + load_dataset.py | 词表构建、字符分词、分层数据集划分、批次迭代器 |
| 中篇 | 模型架构 | TextRNN.py | 预训练词向量加载、3层双向LSTM、Mean Pooling、分类头 |
| 下篇 | 训练推理 | train_eval_test.py + main.py | 类别权重平衡、学习率调度、梯度裁剪、早停、推理预测 |