系列文章目录
第一章 规则和传统NLP之NLP概述
第二章 规则和传统NLP之NLP任务范式
第三章 规则和传统NLP之困难和挑战
第四章 NLP常见语料库
第五章 NLP(正向,逆向,双向匹配法分词及代码实现)
词性标注
- 系列文章目录
- 一、词性标注
- 二、什么是词性标注
- 三、词性标注的原理
-
- [1. 基于规则的方法](#1. 基于规则的方法)
- [2. 基于统计模型的方法](#2. 基于统计模型的方法)
- 四、词性标注规范
- [五、 Jieba库词性标注](#五、 Jieba库词性标注)
- 六、【示例】Jieba库实现词性标注
一、词性标注
二、什么是词性标注
词性标注是自然语言处理中的一项重要任务,它旨在为文本中的每个词分配相应的词性标签(如名词、动词、形容词等)。准确的词性标注能够为后续的任务提供可靠的输入。
由于中文和其他语言在句子结构和词义上存在一定的复杂性,进行有效的词性标注对于理解句子的语法和语义至关重要。因此,词性标注被视为处理中文文本的重要步骤。
三、词性标注的原理
词性标注是NLP中的基础任务,尽管现代深度学习方法(如BERT、LSTM等)已经广泛应用,但在一些对精确度要求高的场景中(如法律、医学文本),基于规则的POS标注方法依然有效,尤其是在处理结构清晰、标准化的文本时。
1. 基于规则的方法
-
手工规则:通过专家定义的规则集,对词进行词性标注。这些规则通常基于语言学的知识,例如词形变化和上下文信息。
-
词典查找:利用词典中的词性信息进行标注。如果词在词典中有对应的词性,则直接使用。
2. 基于统计模型的方法
- 隐马尔可夫模型(HMM):HMM是一种常用的序列模型,能够通过训练数据学习词的转移概率和发射概率,从而进行词性标注。
四、词性标注规范
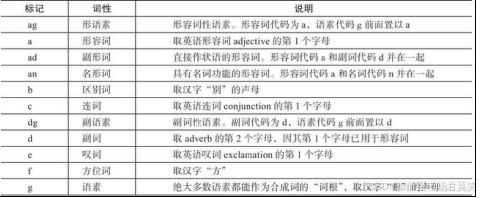
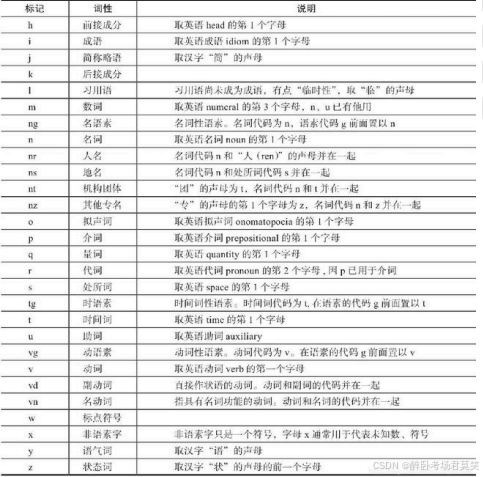
词性标注要有一定的标注规范,如将名词、形容词、动词表示为"n","adj","v"等。中文领域尚无统一的标注标准,较为主流的有北大词性标注集和宾州词性标注集。以下是北大词性标注集部分词性表示:
五、 Jieba库词性标注
Jieba库提供了词性标注功能,采用结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和HMM共同作用。词性标注流程如下:
- 第一步:根据正则表达式判断文本是否为汉字;
- 第二步:如果判断为汉字,构建HMM模型计算最大概率,在词典中查找分出的词性,若在词典中未找到,则标记为"未知";
- 第三步:若不如何上面的正则表达式,则继续通过正则表达式进行判断,分别赋予"未知"、"数词"或"英文"。
六、【示例】Jieba库实现词性标注
python
from jieba import posseg
def pos(text):
words = posseg.cut(text)
res = ''
for word , flag in words:
res+=f"{word}/{flag}"
return res
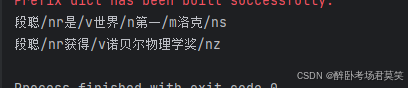
text = "段聪是世界第一洛克"
print(pos(text))
text = "段聪获得诺贝尔物理学奖"
print(pos(text))