从 DeepSeek、Qwen 到 GPT:一次企业级 AI 知识库项目的模型选型复盘
2025 年下半年,我们团队开始开发一个面向企业内部的智能知识库系统。
项目本身并不复杂,其核心目标是利用大语言模型提升企业文档检索效率。用户通过自然语言提问,系统能够自动从数万份内部文档中检索相关内容,并结合检索结果生成最终答案。
从架构上看,这是一个典型的 RAG(Retrieval-Augmented Generation)应用:
text
用户问题
↓
向量检索
↓
召回相关文档
↓
大模型生成答案
↓
返回结果然而在真正落地过程中,我们发现,系统性能的决定因素并不仅仅是检索效果,而是模型选型与基础设施架构。
下面就来讲讲,在这个项目启动到真正落地,我们的心路历程都是怎样的。
项目背景与技术需求
我们计划项目部署环境为私有云,知识库规模约:
- 5 万份企业文档
- 1200 万 Token 数据量
- 日均问答请求约 3 万次
- 峰值并发 150 QPS
在项目初期,我们制定了四项核心指标:
| 指标 | 要求 |
|---|---|
| 回答准确率 | ≥85% |
| 首 Token 延迟 | <2秒 |
| 平均响应时间 | <5秒 |
| 推理成本 | 可持续运营 |
其中,推理成本是最容易被忽视的问题。
很多团队在 PoC 阶段只关注模型效果,但当系统进入真实生产环境后,推理成本往往会迅速放大。
因此我们的模型评测从第一天开始就同时关注:
- 能力
- 性能
- 成本
于是我们开始了评测。
第一轮评测:模型能力对比
第一轮测试对象包括:
- DeepSeek-V3
- Qwen-Max
- GPT-4o
测试集包含:
- 企业制度问答
- 长文档总结
- 多轮追问
- 数据分析任务
共计 1000 条测试样本。
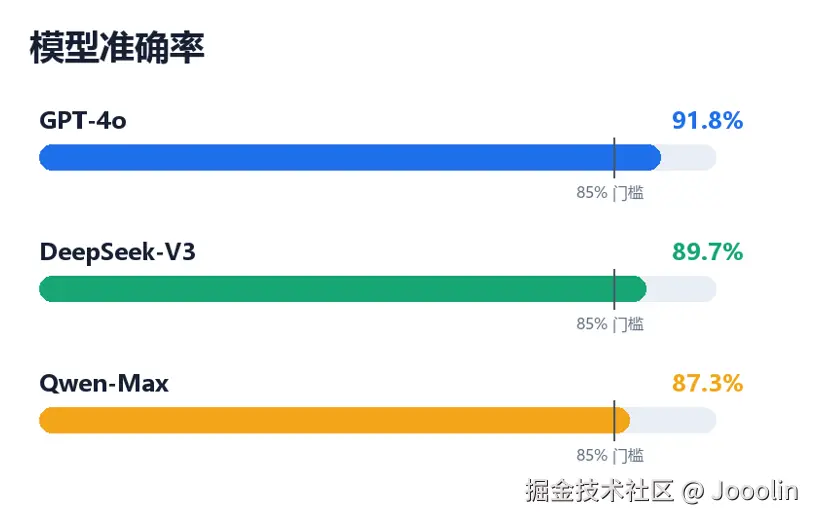
最终结果如下:
| 模型 | 准确率 |
|---|---|
| GPT-4o | 91.8% |
| DeepSeek-V3 | 89.7% |
| Qwen-Max | 87.3% |
从结果来看,GPT-4o 效果最佳。
但问题很快出现。
GPT-4o 的优势主要体现在复杂推理任务,而在企业知识库场景中,大部分请求属于文档理解与信息提取。
换句话说:用户并不需要最强模型,而是需要性价比最高的模型,因为本身答案的准确性并不是普通用户最追求的,他们更需要的是大量的回复量。
因此单纯比较准确率并不足以支撑最终决策。
第二轮评测:推理成本分析
我们开始引入成本指标,统计连续两周测试环境调用数据。
结果发现:模型成本与调用规模呈线性增长。
而企业知识库的特点恰恰是:
请求量大; 请求频繁; 单次价值有限。
这导致模型成本成为长期运营的重要变量。
此时团队内部出现两种声音:
第一种方案:
直接使用商业 API。
第二种方案:
部署开源模型。
为了验证可行性,我们开始尝试自建推理服务。
自建推理服务踩过的几个坑
最初我们采用:
- vLLM
- Kubernetes
- GPU 集群

搭建统一推理平台。理论上这套方案具有最高灵活性,但实际运行后暴露出不少问题------
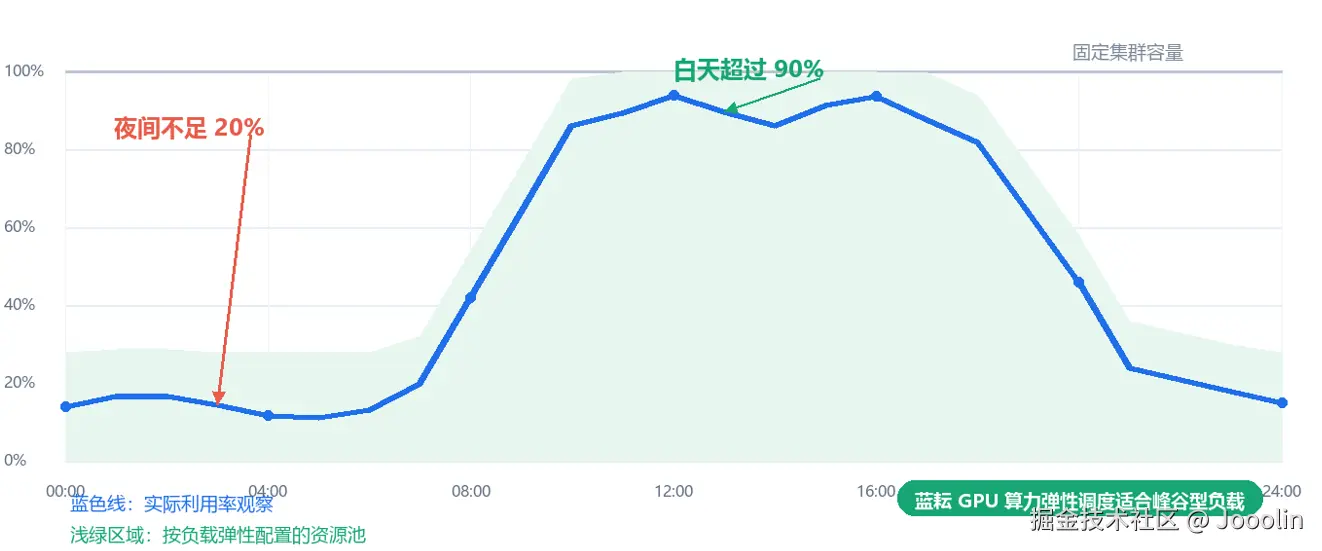
GPU 利用率波动严重
工作日白天:GPU 利用率超过 90%。
夜间:不足 20%。
资源利用率极不均衡!
模型升级成本高
每次模型版本更新都需要:
- 镜像重建
- 权重同步
- 灰度验证
- 服务切换
维护成本持续增加。
多模型管理复杂
随着业务扩展,我们开始同时维护DeepSeek、Qwen、Embedding 模型,接口规范逐渐碎片化,工程复杂度不断上升。
此时团队意识到:
问题已经不再是模型本身,而是模型服务层。
为什么最终选择蓝耘 MaaS
项目进入第三个月后,我们开始评估 MaaS(Model as a Service)方案。
我们的核心诉求其实很简单:
不要重复建设模型服务基础设施。
经过调研后,我们重点测试了蓝耘 MaaS 平台。
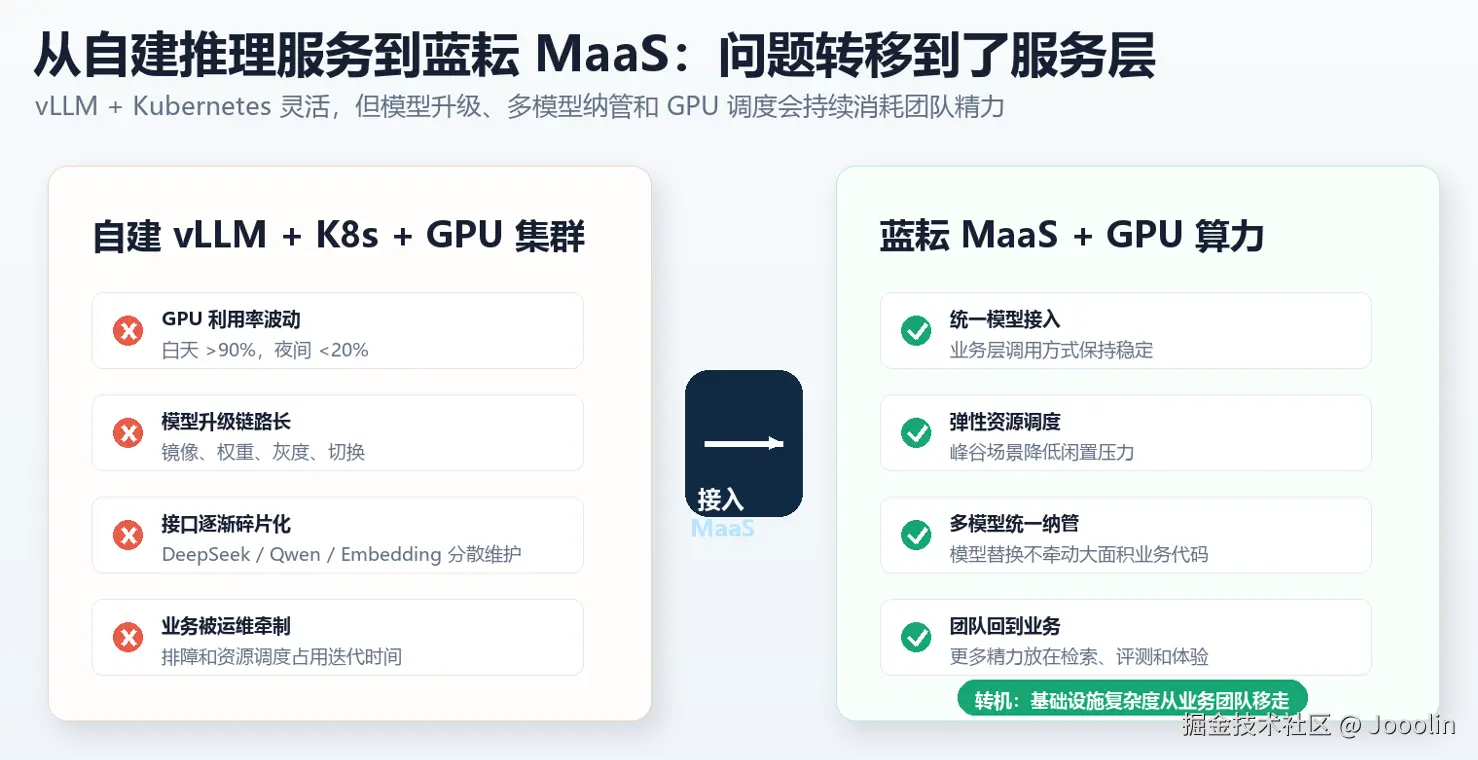
其吸引我们的原因主要有三个。
统一模型接入
过去不同模型需要维护不同 SDK。
而在 MaaS 架构下:
python
client.chat.completions.create()即可完成模型调用,业务层与模型层实现了解耦,未来替换模型几乎不需要修改业务代码。
GPU资源弹性调度
相比固定 GPU 集群,蓝耘 GPU 算力服务能够根据业务负载动态扩容。
对于峰谷明显的业务场景而言,这一点尤为重要。
运维成本下降
过去团队需要关注:
- 模型部署
- 权重更新
- 服务监控
- GPU调度
接入 MaaS 后,这些问题基本被平台屏蔽。
团队可以将精力重新集中到业务逻辑本身,反正我们团队用了蓝耘之后,效率确实提升了不少。

一个被低估的事实:AI 应用竞争正在从模型转向基础设施
过去两年,大模型行业的关注点始终围绕参数规模与排行榜展开。
但在实际项目中,我们越来越明显地感受到:模型能力提升正在趋缓。
而工程效率的重要性正在快速上升。
对于大多数企业而言:
决定项目成功与否的往往不是模型排行榜上的前 3 分差距。
而是:
- 是否能够快速迭代
- 是否能够控制成本
- 是否能够稳定运行
- 是否能够灵活切换模型
这些问题本质上都属于基础设施问题。
从这个角度看,MaaS 平台的价值并不是提供某一个模型,而是降低模型使用门槛。
还是总结一下吧
回顾整个项目,我们经历了三个阶段:
第一阶段关注模型能力;
第二阶段关注模型成本;
第三阶段关注基础设施效率。
而真正影响项目落地速度的,并不是模型本身,而是围绕模型构建的一整套服务体系。
对于正在开发 AI 应用的团队来说,模型选型固然重要,但如果把全部精力都投入到模型对比,而忽略基础设施建设,往往会陷入重复造轮子的困境...
当大模型逐渐成为标准化能力后,如何更高效地获取、管理和使用这些能力,或许才是下一阶段 AI 工程化竞争的核心,蓝耘还是不错的!