一、Mem0 核心定位与技术本质
Mem0 是面向生产环境、可扩展的大语言模型(LLM)智能体长期记忆架构 ,旨在解决 LLM 固定上下文窗口导致的跨会话信息遗忘、对话一致性缺失、事实冲突等核心瓶颈。其技术本质为基于动态提取 - 整合 - 检索的结构化持久记忆机制 ,通过轻量化记忆管理突破上下文长度限制,同时兼顾推理性能与工程部署效率;体系内包含基础版 Mem0 与图增强版 Mem0ᵍ 两种互补架构,分别适配高效检索与复杂关系推理场景。
LOCOMO 是数据集?是对比6个基准模型?
论文在 LOCOMO 这套统一数据集上,横向对比了Mem0/Mem0ᵍ + 6 类主流记忆方案:
(i) 已成熟的 LOCOMO 基准模型(5 个Established LOCOMO Benchmarks):
- LoCoMo
- ReadAgent
- MemoryBank
- MemGPT
- A-Mem
(ii) 不同分块大小、不同检索 k 值的 RAG 方案(retrieval-augmented generation);
(iii) 载入完整全量对话历史的原生全上下文方法(Full-Context Processing);
(iv) 开源长期记忆解决方案(Open-Source Memory Solutions);
(v) 厂商闭源专有模型记忆系统(Proprietary Models);
(vi) 商用专用对话记忆管理平台(Memory Providers)
- 基准(Benchmark) = 统一的评测标准体系,它是评测用的 "考试规则 + 试卷 + 评分表"(规则层)
- 基线 (Baseline)= 用来对比的参照方法 / 模型,它是实验里的 "对照组 / 参照物"(对比层)
「xxx 作为基准」 = 把 xxx 设定为全行业统一、固定不变的评测标准 ,所有模型 / 方法都在这个标准上做实验、比分数,保证对比公平、可信、可复现。
「xxx 作为基线」= 把 xxx 当作对比参照的标准方法 / 模型
二、Mem0 整体架构、工作流程与记忆存储调用机制
(一)基础版 Mem0 架构与工作流程
基础版 Mem0 采用增量式两阶段流水线,实现记忆的全生命周期自动化管理:
step1:记忆提取阶段(Extraction Phase)
本阶段以时序连续对话消息对 (mt−1,mt) 作为原始触发输入。系统首先从底层持久化记忆数据库中拉取全量历史对话摘要与过往交互消息 ,交由摘要生成模块(Summary Generator),生成可完整封装整个对话历史全局语义的对话摘要S。随后大语言模型 LLM 拼接双维度结构化上下文构建推理提示:
- 覆盖全对话时序脉络的全局语义摘要S
- 由超参数m严格控制窗口长度的近期局部消息序列 {mt−m,mt−m+1,...,mt−2}叠加当前最新交互对话内容共同组成完整输入上下文,由 LLM 精准抽取对话核心事实、用户偏好、实体关键信息,过滤冗余噪声内容,输出标准化待校验候选新记忆(New extracted memories),传递至下游更新阶段。
step2:记忆更新阶段(Update Phase)
系统首先对上游候选记忆执行向量语义检索,从记忆数据库中匹配所有语义关联存量记忆,筛选排序后输出相似度 Top-s条历史相似记忆 。LLM 同时融合「新提取候选记忆」+「检索匹配的历史存量记忆」两组信息,通过原生 **工具调用(Tool Call)** 机制,自动化决策四类标准化记忆运维操作,实现记忆去重、时序冲突消解、全生命周期一致性维护:
- ADD(新增记忆):写入对话内全新、无逻辑冲突的有效长期事实记忆。
- UPDATE(更新记忆):迭代修正与旧信息矛盾、时序过期失效的存量记忆内容。
- DELETE(删除记忆):清理逻辑冲突、冗余重复、无效过期的历史记忆条目。
- NOOP(无操作):新旧记忆语义完全一致,不存在变更需求,不改动数据库内容。
最终经过规则校验的规范化新记忆,会回写更新至底层记忆数据库,完成提取 - 匹配 - 决策 - 持久化全流程闭环,持续支撑跨会话、长时序 AI 智能体长期记忆调用。
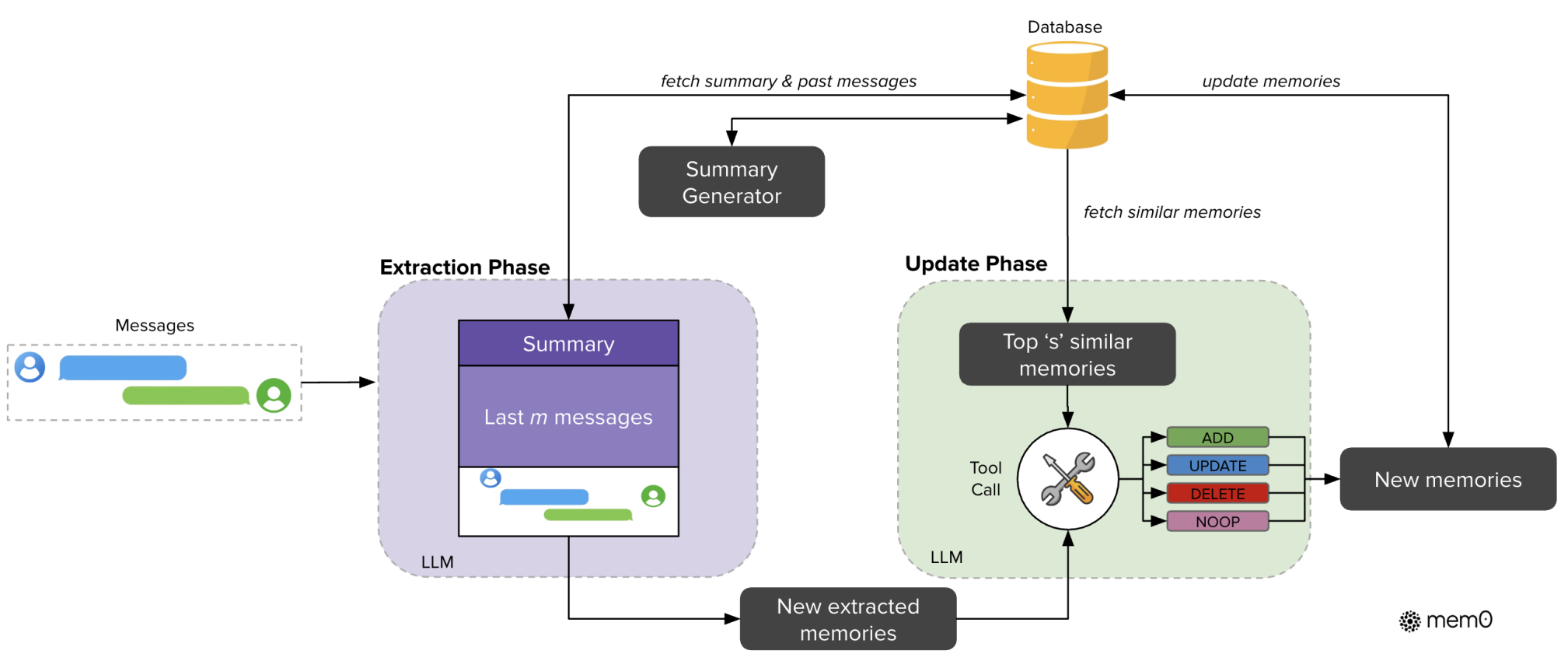
图:Mem0系统的架构概览,展示了提取和更新阶段。提取阶段 处理消息和历史上下文以生成新记忆。更新阶段将这些提取出的记忆与现有相似记忆进行比对,通过工具调用机制执行相应操作。数据库作为核心存储库,为记忆的处理和更新存储提供上下文支持。
(二)图增强版 Mem0ᵍ 架构与工作流程
Mem0ᵍ 是基础版 Mem0 的知识图谱增强长期记忆扩展架构 ,专门解决复杂实体关联、多跳逻辑推理、长时序事件演化场景下的记忆建模缺陷。其以有向带标签知识图谱 G=(V,E,L) 作为全流程核心存储结构:
- 节点集合 V:对应对话交互内所有语义实体(人物、地点、事件、用户偏好、物品等)
- 边集合 E:表征不同实体之间的语义关联关系(例如,居住于)
- 标签集合 L:为节点、关系绑定实体类型与时序属性标签(如人物、地点、事件时间戳)以此显式建模实体间依赖逻辑,原生支撑多跳关系推理、跨会话时序推演、开放域复杂事实关联计算。(例如,Alice - 人物,旧金山 - 城市)
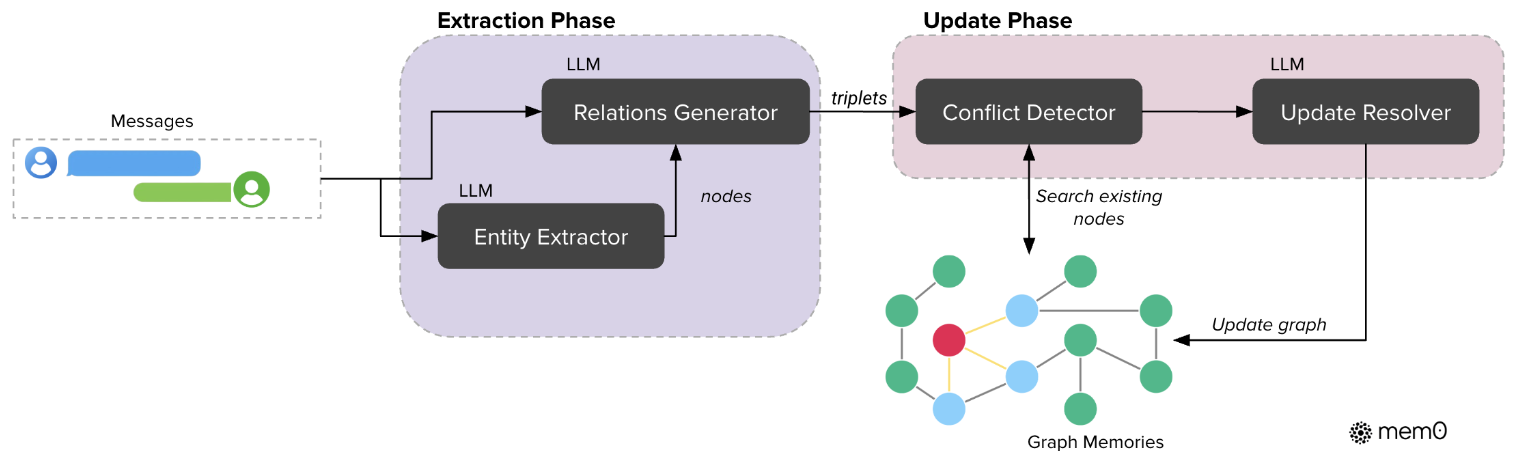
图:Mem0ᵍ 的基于图的内存架构,展示了实体提取和更新阶段。提取阶段 利用大语言模型将对话消息转换为实体和关系三元组。在将新信息整合到现有知识图谱中时,更新阶段采用冲突检测与解决机制。
step1:图谱记忆提取阶段(Extraction Phase)
以用户与模型的连续交互对话消息(Messages)作为非结构化原始输入,由 LLM 驱动**串行双模块结构化提取流水线,**提取流程采用了一个利用大语言模型的两阶段流水线,将非结构化文本转化为结构化的图表示形式:
- 实体提取模块(Entity Extractor)
LLM 对完整对话上下文执行高精度命名实体识别,抽取对话内全部关键语义单元,输出标准化图谱节点(nodes),完成自然语言文本到离散图谱实体单元的转换。 - 关系生成模块(Relations Generator)
以上一步输出的实体节点为输入约束,LLM 挖掘实体间语义关联逻辑(怎么挖掘的?) ,构建标准化**<源实体-关系-目标实体>** 知识三元组(triplets),将零散孤立实体拼接为结构化关联图谱片段,实现非结构化对话历史向结构化图记忆数据的完整转化。
该模块采用提示工程技术 ,引导大语言模型对对话中的显性表述和隐性信息 进行推理(怎么推理的?),最终生成的关系三元组将作为记忆图谱中的边,实现跨关联信息的复杂推理。
在整合新信息时,Mem0ᵍ 采用了一套精密的存储与更新策略。针对每一个新的关系三元组,我们都会为源实体和目标实体分别生成嵌入向量,随后在全局记忆图谱中检索语义相似度超过预设阈值t 的所有历史已有节点,完成同义指代、跨会话同名实体、相似实体的归一对齐,避免重复建点、图谱冗余碎片化。系统根据相似度匹配结果,自动选择对应存储方案:
- 头尾实体均无匹配历史节点:新建 2 个全新实体节点入库
- 仅单个实体匹配到存量节点:仅新建 1 个全新节点,直接复用已存在的历史实体
- 头尾实体均匹配到历史节点:完全复用现有节点,不重复创建新实体
节点确定后,为实体补充对话时间戳、实体类型、来源会话、时序属性等完整元数据,随后在对应实体节点之间建立有向关联边,完成整条关系记忆结构化入库。更新策略在下文介绍。
step2:图谱记忆更新阶段(Update Phase)
严格遵循「存量检索→冲突校验→规则解析→图谱回写」闭环流程:
- 冲突检测模块(Conflict Detector)
主动向下检索图记忆库中所有已存在的历史实体节点(Search existing nodes) ,将新生成实体三元组与存量图谱节点、历史关联关系做语义对齐、时序匹配与逻辑冲突校验,精准识别事实矛盾、实体冗余重复、新旧关系逻辑冲突等异常问题。 - 更新解析模块(Update Resolver)
针对冲突检测结果执行规范化图谱迭代操作,论文采用时序标记失效软删除机制:不对历史节点、关系做物理删除 ,仅对过期、冲突、失效关联打上时序废弃标签 ;同步完成新节点插入、关联边新增、旧关系迭代修正等操作,完整保留对话全周期时序脉络,保障长时序多跳推理不丢失历史上下文信息。 - 图谱持久化闭环
将冲突校验、规则解析完成后的合规变更,执行Update graph图谱更新操作,同步写入底层 Graph Memories 图数据库,完成整张记忆知识图谱的迭代更新。
三、图谱记忆检索与调用机制
Mem0ᵍ 采用双路径互补融合检索范式,双向匹配精准事实查询与泛化语义推理需求,全面适配 AI 智能体长时序、多跳复杂记忆调用场景:
- 实体中心精准检索 :
首先从用户查询语句中识别核心关键实体,依托实体语义嵌入向量,在全局知识图谱中通过语义相似度匹配定位对应图谱节点;随后系统性遍历该锚定节点全部入边、出边关联关系,延展构建完整关联子图,完整捕获目标实体相关全量上下文脉络信息。
该路径专门适配特定单实体精准问答、确定性事实查询场景,保障实体关联关系检索的完整性、唯一性与高精准度。。 - 语义三元组泛化检索 :
以全局整体视角解析用户查询,将整条问句完整编码为密集语义嵌入向量;随后将查询向量与知识图谱内所有历史关系三元组的文本编码做细粒度相似度匹配计算;系统自动筛选相似度超过可配置相关性阈值的有效结果,并按照匹配分数从高到低有序排序后输出。
该路径适配开放域宽泛概念查询、跨实体多层多跳逻辑推理、长时序事件关联推演场景,弥补单一实体检索无法覆盖模糊语义问题的短板。
两套检索机制并行互补、联动生效,让 Mem0ᵍ能够同等高效地处理精准实体类问题与宽泛概念类查询,同时兼顾实体链路推理严谨性、全局语义泛化匹配能力,在时序推理、开放域长对话复杂任务上,性能显著优于仅采用单一向量检索的基础版 Mem0 架构。
(三)记忆存储与调用机制
- 存储 :
Mem0 基于 向量数据库存储密集嵌入的自然语言记忆;
Mem0ᵍ 基于Neo4j 图数据库 存储实体 - 关系三元组 ,实体附加类型、嵌入向量、时间戳元数据。
Neo4j 是业界主流的生产级原生图数据库,以节点 - 关系 - 属性结构存储知识图谱,为 Mem0ᵍ 提供生产级、高效率的结构化记忆存储与关系推理底座。 - 调用 :检索相关记忆 / 子图作为 LLM 上下文,替代全量对话历史,实现低 token、低延迟的长期记忆调用。省 90%+token、降 91% 延迟,还能跨会话长期记忆。
三、与传统大模型记忆方案的对比:创新点与核心优势
(一)传统记忆方案的核心缺陷
- 全上下文处理:token 消耗随对话长度指数增长,延迟极高,无法规模化部署。
- 标准 RAG:固定分块导致信息冗余,检索精度低,无法建模实体关系与时序逻辑。
- 传统记忆系统(MemGPT、A-Mem、Zep):token 冗余度高、后台异步处理延迟大、推理效率不足。
- 厂商内置记忆(OpenAI 记忆):时序推理能力弱,无开放 API 支撑自定义部署。
(二)Mem0 核心创新点
- 闭环式记忆管理:提取 - 更新一体化,自动完成记忆增删改,无需人工干预。
- 双架构互补设计:基础版保障高效检索,图增强版支撑复杂关系与时序推理。
- 生产级工程优化:实时记忆构建,无后台异步延迟,适配低延迟交互场景。
- LLM 原生操作:以工具调用直接决策记忆操作,无需额外分类模型,简化架构。
(三)核心优势
- 性能优势:在 LOCOMO 基准上实现单跳、多跳任务 SOTA,Mem0ᵍ 时序、开放域任务最优。
- 效率优势:较全上下文方案 p95 延迟降低 91%,token 成本节省 90% 以上。
- 部署优势:记忆轻量化、实时可用,兼容工业级生产环境。
四、Mem0 在智能体场景中的应用价值
- 通用 AI 智能体:持久化存储用户偏好与对话历史,维持一致人设,跨会话保持决策连贯性。
- 长上下文对话:突破 LLM 上下文窗口限制,支撑跨天、跨月的长期连贯对话。
- 多轮交互系统:避免重复提问、事实矛盾,提升交互可靠性与用户信任度。
- 高价值行业场景:医疗问诊、教育辅导、企业客服等需长期记忆的领域,保障信息连续性与服务专业性。
五、实验结果、性能总结与现存不足
- 单跳 :只查一条记忆、单轮对话,直接拿答案;
- 多跳 :要把多轮 / 多会话的多条记忆拼起来推理,才能得出答案。
(一)实验设置与核心结果
- 实验基准:采用 LOCOMO 长对话记忆数据集,覆盖单跳、多跳、时序、开放域四类任务。
- 评估指标:性能指标(F1、BLEU-1、LLM-as-a-Judge);部署指标(延迟、token 消耗)。
- 核心性能
- Mem0:单跳、多跳任务 SOTA,LLM-as-a-Judge 较 OpenAI 记忆相对提升 26%。
- Mem0ᵍ:时序、开放域任务最优,整体得分较 Mem0 提升约 2%。
- 效率表现
- Mem0 搜索延迟 p50=0.148s、p95=0.200s,总响应 p95=1.44s。
- 单对话平均 token:Mem0≈7k,Mem0ᵍ≈14k,远低于 Zep(600k+)。
(二)优点总结
- 性能全面超越现有记忆系统,兼顾精度与推理能力。
- 双架构适配不同任务场景,灵活性强。
- 工程化程度高,低延迟、低 token、实时可用,满足生产要求。
- 记忆自动维护,一致性与时序性保障完善。
(三)现存不足
- Mem0ᵍ 图结构操作引入小幅延迟,效率略低于基础版。
- 开放域任务性能略逊于 Zep(差距 < 1%)。
- 仅支持文本对话记忆,未覆盖多模态场景。
- 记忆冲突检测完全依赖 LLM,存在少量误判风险。
- 未融合分层记忆机制,复杂推理场景仍有优化空间。
六、科研视角:未来研究方向、改进思路与学术借鉴意义
(一)论文提出的未来研究方向
- 优化 Mem0ᵍ 图操作逻辑,降低延迟开销。
- 融合分层记忆架构,平衡检索效率与关系表达能力。
- 拓展至多模态记忆、过程式推理场景。
(二)研究生可落地的改进思路
- 引入轻量化图神经网络(GNN)加速 Mem0ᵍ 实体 - 关系推理。
- 借鉴人类认知记忆机制,构建短时 - 长时 - 工作记忆分层体系。
- 结合模型蒸馏与记忆压缩,进一步降低 token 消耗。
- 设计多模态记忆统一表征框架,支持文本、图像、音频联合记忆。
- 提出自适应记忆更新策略,动态调整提取与更新频率。
(三)学术借鉴意义
- 构建学术创新 - 工程落地一体化的记忆架构范式,填补长对话记忆研究与生产应用的鸿沟。
- 验证结构化持久记忆对提升 LLM 长期对话一致性的核心价值。
- 双架构模块化设计为后续记忆系统研究提供可复用框架。
- 建立性能 + 效率双维度评估体系,为长记忆领域提供标准化实验基准。