动静态 decoder
- 感知基本以及收敛到bev技术上了
- decoder 把之前的BEV feature 解析成结果
- 主要可以解成 动态障碍物 静态道路结构 对于不规则物体的occ
动态障碍物感知
可以任何可以移动的 静态是地图相关的 occ是难以描述的
- 检测 跟踪

Sparse 4D 1-4
1️⃣ 多尺度
含义:系统能同时处理不同大小、不同距离的物体或场景特征。
作用:在复杂驾驶场景中,既看得清近处细节(如行人、交通标志),也能捕捉远处目标(如车辆、障碍物),提升感知的鲁棒性和适应性。2️⃣ 多视角
含义:利用多个摄像头(不同角度)的输入信息,进行联合分析与融合。
作用:模拟人眼的多角度观测,解决单一视角的遮挡、盲区问题,生成更完整、可靠的 3D 环境感知结果。3️⃣ 多时间
含义:引入时间维度,连续分析多帧图像或序列数据。
作用:捕捉目标的运动轨迹、速度变化与行为趋势,实现对动态场景的"记忆"与"预测",提升跟踪和平滑性。4️⃣ 多关键点
含义:聚焦于场景中多个重要的局部特征点(如角点、边缘、语义显著点),而非处理全部数据。
作用:在保证感知精度的同时,大幅降低计算量,符合"稀疏感知"的设计原则,尤其适合对实时性要求高的车载平台。- 问 sparse v1-4的概括
Sparse4D基本原理
Sparse4D采用稀疏感知范式,避免了传统BEV(鸟瞰图)方法中稠密特征转换带来的计算开销。其核心思想是:
Encoder-Decoder架构:采用编码器-解码器结构,编码器提取多视角多尺度特征图,解码器通过迭代方式精细化实例。
Instance定义:每个感知目标被定义为一个instance,包含两部分:
Instance feature:目标的高维语义特征
3D Anchor:目标的结构化状态信息(3D框的位置、尺寸、朝向、速度等)
Deformable 4D Aggregation模块:这是Sparse4D的核心创新,包括:
4D关键点生成:基于3D anchor生成固定关键点(anchor box各面中心点)和可学习关键点
稀疏采样:将4D关键点投影到多视角、多尺度、多时间戳的特征图上进行采样
层级化融合:融合多尺度/视角、多时间戳、多关键点的特征
深度重加权模块:解决3D到2D投影的深度歧义问题,通过深度置信度对实例特征进行重新加权
Sparse4D v1
v1是基础版本,主要改进包括:
重新引入Anchor的使用,将待感知目标定义为instance
提出Deformable 4D Aggregation模块,实现多视角、多尺度、多时间戳的特征融合
支持时序信息融合,通过特征队列缓存历史帧特征
Sparse4D v2
v2主要针对时序融合效率进行优化:
循环时序融合:将时序融合从O(T)复杂度降低到O(1),通过递归形式实现多帧特征采样
高效可变形聚合:对Deformable Aggregation模块进行底层优化,提升并行计算效率,降低显存占用
相机参数编码:将相机投影矩阵编码为高维特征,增强模型对相机内外参的泛化能力
密集深度监督:加入以点云为监督的多尺度密集深度估计作为辅助训练任务,加速模型收敛
Sparse4D v3
v3在检测性能和端到端跟踪方面有显著提升:
时间实例去噪:引入去噪任务作为辅助监督,提高模型收敛稳定性和检测性能
质量估计:增加centerness和yawness两个质量指标,让输出置信度排序更准确
解耦注意力:将instance self-attention和temporal instance cross-attention中的特征相加操作改为拼接,减少特征干扰
端到端多目标跟踪:无需修改训练流程,在推理阶段对instance进行ID分配,实现检测跟踪一体化
- 问 anchor 含义和作用
用一个具体的 BEV (鸟瞰图) 端到端规划 场景,拆解 Anchor 是如何将"神经网络输出的抽象数字"转化为"车辆物理轨迹"的。
场景设定:城市路口直行
假设你的车正以 30km/h 速度接近路口,前方有一辆慢车。端到端模型需要输出:"我车未来 3 秒的轨迹"。
步骤 1:在 BEV 空间"撒"Anchor(定义查询)
系统在车辆前方的 BEV 地图上,预设一组 Trajectory Anchor (轨迹锚点)。这些 Anchor 不是检测框,而是未来路径的"候选起点"。
| Anchor ID | 物理含义(相对车头) | 预设意图 |
|---|---|---|
| A1 | (10m, 0m) | 直行锚点 |
| A2 | (10m, -1.5m) | 轻微左偏锚点 |
| A3 | (10m, +1.5m) | 轻微右偏锚点 |
注:这些坐标是预设的"假设位置",模型的任务是判断哪个 Anchor 最合理,并微调它。
步骤 2:模型推理(匹配与回归)
模型(如 Transformer 解码器)以这些 Anchor 为 Query,与 BEV 特征进行交互:
- A1 (直行) :感知到前方有慢车,匹配代价高(不可行)。
- A2 (左偏) :感知到左侧车道空闲,匹配代价低(可行)。
- A3 (右偏) :感知到右侧有护栏,匹配代价极高(不可行)。
模型输出:
- 分类结果 :选择 A2 作为最优轨迹起点。
- 回归结果 :预测 A2 需要微调
Δx = +0.3m(更靠左一点),并生成未来 3 秒的位移序列[Δt1, Δt2, Δt3]。
步骤 3:物理解码(Anchor → 轨迹)
将 Anchor 的抽象坐标转化为物理世界的控制指令:
原始 Anchor 坐标 :(x=10m, y=-1.5m)
模型微调后 :(x=10.3m, y=-1.2m)
未来轨迹 :[ (12m, -1.0m), (14m, -0.8m), (16m, -0.5m) ]
最终输出:一条"向左微绕行,超越前车"的平滑轨迹。
为什么必须用 Anchor?(端到端视角)
如果没有 Anchor,模型需要从零回归绝对坐标:
- 输入:图像/BEV 特征。
- 输出 :
(x1, y1), (x2, y2), (x3, y3)。
问题 :输出空间无限大,模型极难收敛,且容易产生"跳跃"的不稳定轨迹。Anchor 将问题从**"预测绝对位置"降级为"预测相对偏移"**,极大地降低了学习难度。
与感知任务中 Anchor 的区别
-
感知 Anchor:预定义的 2D/3D 框,用于"框住"物体。
-
端到端 Anchor :预定义的状态/轨迹假设 ,用于"生成"未来路径。它是规划任务的结构化先验。
-
问 anchor 是随便给的吗
绝对不是随便给的。Anchor 是模型设计中最关键的**"经验先验"**(Prior Knowledge),它的设定直接决定了模型是"学得快且准"还是"根本学不会"。
在端到端自动驾驶中,Anchor 的设定遵循严格的物理规律 和任务导向,通常基于以下三个维度的强约束:
一、物理空间约束(不能撒在"天上")
Anchor 的初始位置必须符合车辆运动学 和道路结构,绝不是随机坐标。
- 纵向范围:通常覆盖 0~80 米(感知/预测范围),超出这个范围的目标对当前决策无意义。
- 横向范围 :通常限制在车道宽度内(-3.5m ~ +3.5m),不会在路沿外或对向车道预设 Anchor,因为车辆不可能瞬间跳过去。
- 尺度先验:如果是 3D 检测 Anchor,长宽高会预设为常见车辆尺寸(如 1.8m×4.5m×1.5m),而不是随便给一个 10m 的巨框。
二、任务导向约束(规划 vs 感知)
不同任务的 Anchor 定义逻辑完全不同,这是端到端模型的核心设计点:
| 任务类型 | Anchor 本质 | 设定逻辑 | 举例 |
|---|---|---|---|
| 感知 (Perception) | "是什么" | 空间+尺寸先验 | 预设"车"、"人"尺寸的框 |
| 预测 (Prediction) | "去哪里" | 运动学先验 | 预设"直行/左转/右转"的轨迹模版 |
| 规划 (Planning) | "怎么走" | 动力学+舒适度先验 | 预设"加速/减速/换道"的曲率曲线 |
在端到端规划中,Anchor 更像是**"候选策略"**(如"跟车锚点"、"超车锚点"),而不是简单的几何框。
三、数据驱动优化(可学习)
虽然初始 Anchor 是人工设计的,但现代端到端模型会通过数据统计 和训练过程对其进行优化:
- 统计聚类:训练前,对训练集所有真实轨迹进行聚类分析(如 K-Means),找出最常见的轨迹模式,将其作为 Anchor 的初始形状。
- 可学习参数:部分模型(如 DETR 的 Query)将 Anchor 初始化为可学习参数,让模型在训练中自己调整"什么样的初始点更容易匹配真实目标"。
四、如果"随便给"会发生什么?
如果 Anchor 设置不合理(如随机撒点、范围过大),会导致模型难以收敛 或性能崩塌:
- 召回率低:Anchor 离真实目标太远,模型永远学不会"匹配"。
- 计算爆炸:为了覆盖所有可能位置,需要撒海量 Anchor,推理速度骤降。
- 规划抖动:规划 Anchor 的曲率不连续,会导致输出的轨迹忽左忽右,乘坐体验极差。
总结 :Anchor 是**"带着镣铐的猜测"。它是工程师将 物理规则**(车不能瞬移)和驾驶常识(车通常在车道内)编码进模型的一种方式,绝不是随机数生成器。
总结
- 动态障碍物感知 detection 和 tracking
- 总结 query based 的内容

核心:query表示一类目标的聚类
这是最根本的思想。在传统目标检测中,模型需要在图像上预设大量锚点,或者用滑动窗口遍历,然后对这些"候选框"进行分类和微调。这种方法本质是"猜测-验证"。
而"基于Query"的方法完全不同:
- Query(查询向量) 可以理解为模型内部的一组"提问"或"任务说明书"。每个Query是一个可学习的向量(一组数字)。
- 它的目标是学习代表某一类目标的共同特征。例如,一个Query可能专门学习"汽车"应该长什么样(有轮子、有车窗等特征),另一个Query专门学习"行人"的特征。
- 在训练过程中,模型通过对比预测和真实目标,让这些Query自动"聚类",各自找到并代表图像中某类、某个特定目标的位置和特征。因此,查询向量的数量通常就对应了模型可检测目标的最大数量。
简单比喻:传统方法像"撒网捕鱼"(锚点遍布全图),而基于Query的方法像"派出了若干名带着明确目标描述(Query)的侦察兵",每个侦察兵(Query)负责在图中找到并描述一个符合其任务的目标。
代表方法:DETR, PETR, Sparse4D
这三种方法是这一范式的里程碑:
- DETR:开创者。首次提出了用Transformer的"编码器-解码器"结构做目标检测。解码器中的一组"对象查询"就是这里的Query。它直接输出一组目标预测,实现了真正的端到端检测(无需后处理的非极大值抑制NMS)。
- PETR :在DETR基础上,将3D空间信息(如深度、点云)编码成特征,与图像特征融合,使Query不仅能理解2D图像,还能感知3D空间位置,主要推动了3D目标检测。
- Sparse4D :更进一步,专门为自动驾驶等时序场景 设计。它的核心是让Query不仅在单帧图像中工作,而且能够关联和利用多帧连续图像的信息。Query随着时间演进,追踪同一个目标,从而利用历史信息来稳定当前帧的检测(如应对遮挡),甚至预测运动趋势。这正是您之前问的Sparse4D系列工作的核心。
应用场景:Sparse架构下,大多数目标检测
- Sparse(稀疏)架构 :指的是像上面这些方法一样,不 在图像所有位置进行密集计算,不生成成千上万的初始候选框。它只处理固定、少量(如100个)的Query,计算是高效且稀疏的。
- 大多数目标检测 :随着DETR及其衍生模型(如Deformable DETR, Conditional DETR等)的性能和训练效率被不断优化,这种"基于Query的稀疏范式"已经成为当前主流,在2D检测、3D检测、视频检测等任务中占据主导地位,逐渐取代了传统的"密集锚点"范式。
现代目标检测的核心思想,是让一组可学习的查询向量(Query) 各自学会代表某一类目标。以DETR 为起点,这种方法摆脱了传统锚点和复杂后处理。随后,PETR 等模型将其扩展到了3D感知领域。而Sparse4D 则进一步聚焦于时序建模 ,让Query能够跨帧工作,服务于自动驾驶等动态场景。最终,这种高效、优雅的"稀疏架构"已成为解决大多数目标检测问题的首选方案。
Sparse4D, 正是这个技术演进脉络中,在"时序+3D目标检测"这个重要方向上最前沿的代表之一。
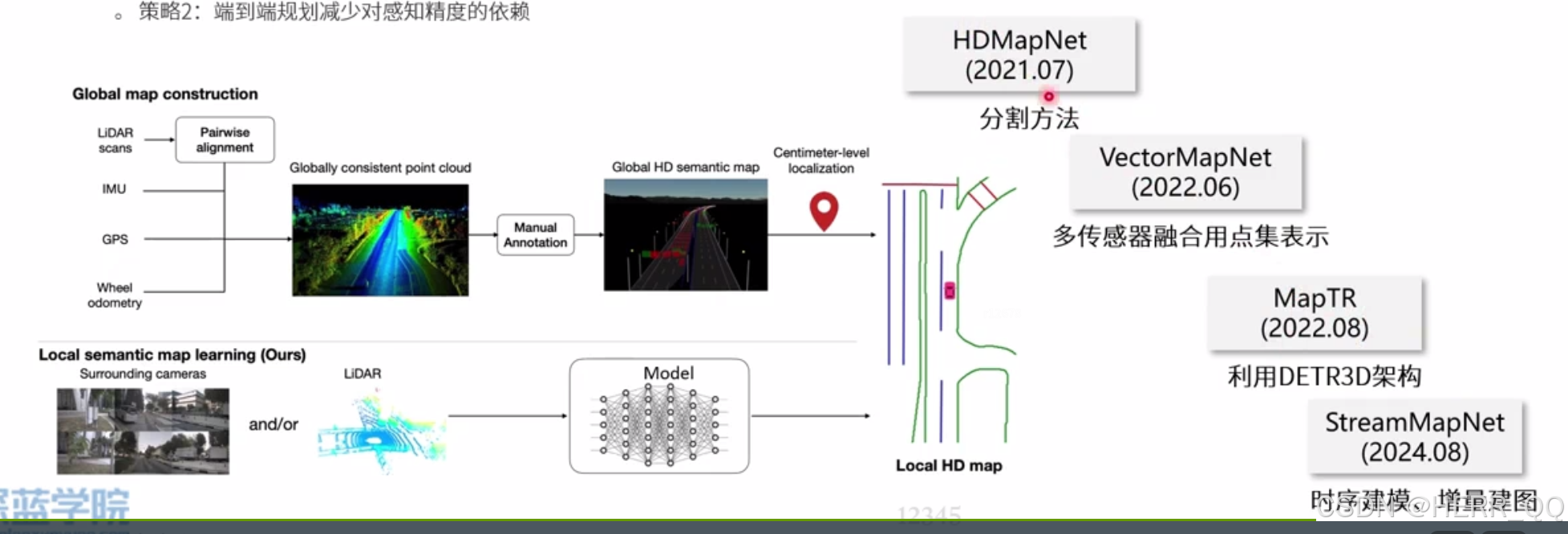
静态道路结构感知
- 几种不同的地图 激光点云 提供了基础的物体位置和定位信息 但体积太大 HD 地图 有地图各种元素信息 但是更新慢 导航地图 精度不够高 提供了一个总体路径信息
- 解决方案 静态感知加上导航地图
- 静态道路感知的挑战 怎么建模 静态元素怎么表达
vector net
MARTR
- 是当下的主流方法
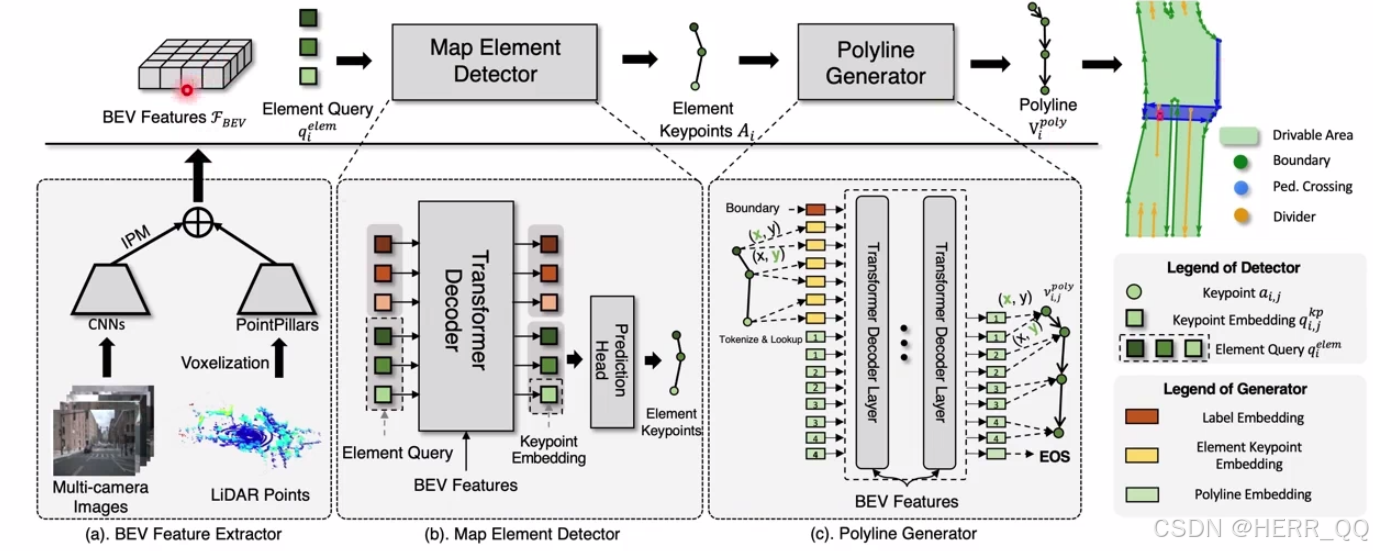
MapTR是一个基于DETR框架的、端到端的矢量高精地图构建模型。 它能够直接从车载摄像头等传感器数据中,实时、自动地感知并生成道路的矢量结构(如车道线、道路边界等),输出为精确的点坐标序列,而不是一张像素图片。
核心原理详解
MapTR要解决的核心问题是:如何让神经网络像人一样,用"笔画"(点连成的线、多边形)来理解和描述静态道路结构,而不是输出一团模糊的色块。
- 新的地图表达方式:用"点集"描述一切
这是MapTR最根本的创新。传统方法可能用分割图(像素级)或复杂的启发式规则来提取矢量,效果不佳。
- 核心思想 :将任何一个地图元素(如一条车道线、一个人行横道、一个路缘石区域)都统一表示为 "一个有序的点集" 。
- Polyline(折线) :用于描述线性元素,如车道线、道路边界。图中(a)显示,一条折线用一系列有序的点
[v0, v1, v2, v3]表示。 - Polygon(多边形) :用于描述面状区域,如人行横道、交通岛。图中(b)显示,一个多边形同样用一个首尾相连的点集
[v0, v1, v2, v3]表示。
- Polyline(折线) :用于描述线性元素,如车道线、道路边界。图中(a)显示,一条折线用一系列有序的点
- 方向灵活性:对于同一个几何形状,起点和方向可以不同(如顺时针或逆时针)。MapTR在训练时允许这种灵活性,只要预测的点集形状与真实形状一致即可,降低了学习难度。这就是"点集之间的方向只要满足Ground Truth Γ中任意一种即可"的含义。
- 基于DETR的端到端预测
MapTR采用了与DETR高度相似的框架:
- 编码器:处理图像或环视图像特征。
- 解码器 :拥有一组可学习的 "地图元素查询"。每个Query负责预测一个地图元素实例。
- 输出 :对于每个Query,模型直接输出:
- 类别:它是车道线、人行道还是停止线?
- 点集坐标 :构成这个元素的一系列点的
(x, y)坐标。
这种方法完全避免了传统流水线中复杂的后处理(如聚类、拟合、手工规则),实现了"输入图像,输出结构化矢量地图"的端到端过程。
- 层级化二分图匹配策略
这是训练MapTR的关键挑战和核心解决方案。如何将模型预测的几百个"地图元素假设"与真值进行一对一的匹配,以便计算损失、引导模型学习?
MapTR采用了图中表格所示的两层匹配策略:
-
第一层:实例级匹配
- 目标:决定预测的哪个实例(如"预测的车道线#3")对应到真值的哪个实例(如"真值的车道线#1")。
- 匹配代价 :计算两方面代价的综合:
- 分类代价:预测的类别是否正确(用Focal Loss衡量)。
- 位置代价:预测的实例与真值实例的整体位置是否接近。
- 这一步为每个真值实例找到了一个最匹配的预测实例。
-
第二层:点集匹配
- 目标 :在确定了实例对应关系后,进一步确定预测点集中的每个点
(v̂_j)对应到真值点集中哪个点(v_γ(j))。 - 关键 :由于点集的方向是灵活的(见原理1),这里会枚举真值点集所有可能的起点和方向(Γ),寻找一种点对点的排列 ,使得所有对应点之间的曼哈顿距离之和最小。这个最优排列
(γ)就是匹配结果。 - 匹配代价 :使用曼哈顿距离(
|Δx| + |Δy|)来衡量对应点之间的距离。
- 目标 :在确定了实例对应关系后,进一步确定预测点集中的每个点
训练过程:通过这种两步匹配,为每个预测找到了唯一对应的真值目标,然后就可以用损失函数(如分类损失、点坐标回归损失)来修正模型的预测,使其越来越准。
| 传统/直觉方法 | MapTR方法 | 优势 |
|---|---|---|
| 先分割,后矢量化(如像素聚类、曲线拟合) | 端到端直接预测矢量 | 结构更简单,避免了误差累积和后处理瓶颈 |
| 依赖手工设计的规则和特征 | 数据驱动,统一学习 | 泛化能力强,能适应不同场景 |
| 输出为像素或非结构化数据 | 输出为结构化点集 | 输出即高精地图格式,可直接用于自动驾驶规控 |
简单来说,MapTR就像是一个"会画地图的AI画家" 。它看着前方的画面,不是临摹涂抹,而是直接用一套可学习的"画图模板"(Query),在画布上标出关键点,然后用线条把这些点连起来,瞬间就生成了一张精确的矢量地图草图。其V1和V2版本的改进主要围绕提升训练效率、推理速度和输出精度展开,例如优化匹配策略、网络结构等,但其**"点集表达 + 层级匹配"** 的核心原理始终是基石。
OCC 暂时跳过
感知任务总结以及与planner的关系
重要的方法
- 动态sparse 4d
- 静态maptr
- occ 数据标注 coasres to fine 先做粗分割然后做细分割