作者:来自 Elastic Jesse Miller
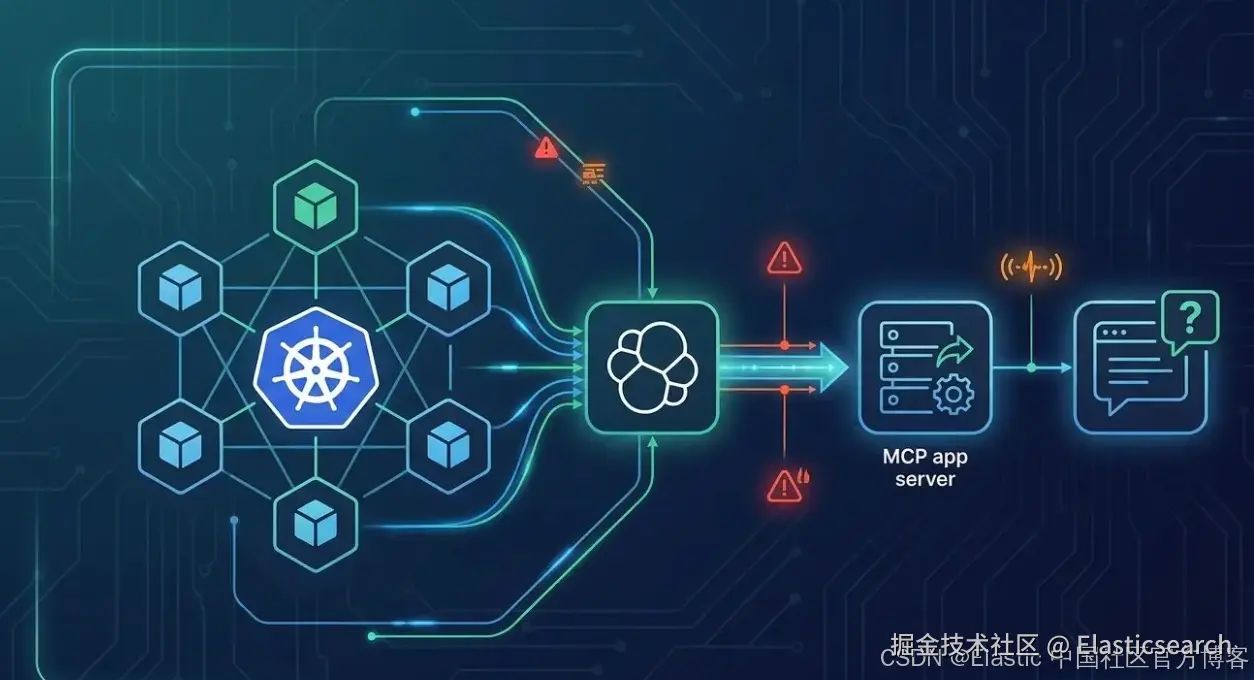
了解 Elastic 的 Agentic 驱动 Kubernetes 可观测性如何使用 MCP App 和 agent 技能,让 agent 调查集群、检测异常,并自动执行根因分析。
Agentic 驱动的 Kubernetes 可观测性现已在 Elastic Observability 中提供。无论你使用的是 Elastic Observability 的 UI,还是你自己的 agentic 工作流,Elastic 都提供了一组能力,用于帮助调查当前的 Kubernetes 问题。我们发布了一个 MCP( Model Context Protocol )应用,它允许像 Claude 和 Cursor 这样的 AI agents 查询 Elastic Observability,以理解 K8s 故障,并在不离开聊天界面的情况下展示 ML 异常。
在第一部分中,我们介绍了 Elastic 的 Kubernetes 集成如何通过 EDOT Collector 将遥测数据发送到 Elasticsearch。在这篇文章中,我们进一步介绍一个 MCP( Model Context Protocol )应用服务器,它将这些遥测数据以 AI 可调用工具的形式暴露出来,并支持在内联中渲染交互式 React UI。我们还将介绍如何通过 Elastic Workflows 进一步扩展:自动化 runbook,可以处理从告警到修复建议的完整根因分析闭环。
Observability MCP App 在你工作的地方直接渲染
Elastic Observability MCP App(技术预览)提供六个视图,每个对应一个 tool。每个视图在 tool 返回时都会以内联方式渲染,并且每个视图都会提供带有建议下一步操作的可点击按钮,这样你不需要去猜测下一步该做什么。MCP Apps 比独立的 agent 工作流更进一步------它们可以直接在你的 chat 或 IDE 中内联渲染实时交互视图,无需切换到 Kibana。
Cluster health 汇总
当你询问 "哪里坏了?" 或 "给我一个状态报告" 时,会得到一次性整体概览:整体健康状态标识、出现问题的服务及原因、top pod 内存消耗、异常严重程度分布以及 service 吞吐量 ------ 全部集中在一个内联视图中。
该视图会根据你的部署能力动态适配。如果有 APM,则会展示 service health;如果有 Kubernetes metrics,则会增加 pod 和 node 上下文;如果启用了 ML jobs,则会叠加异常检测。如果某个信号不存在,视图不会失败,而是明确告诉你缺少什么。我们将从 Kubernetes 集群的状态报告开始:
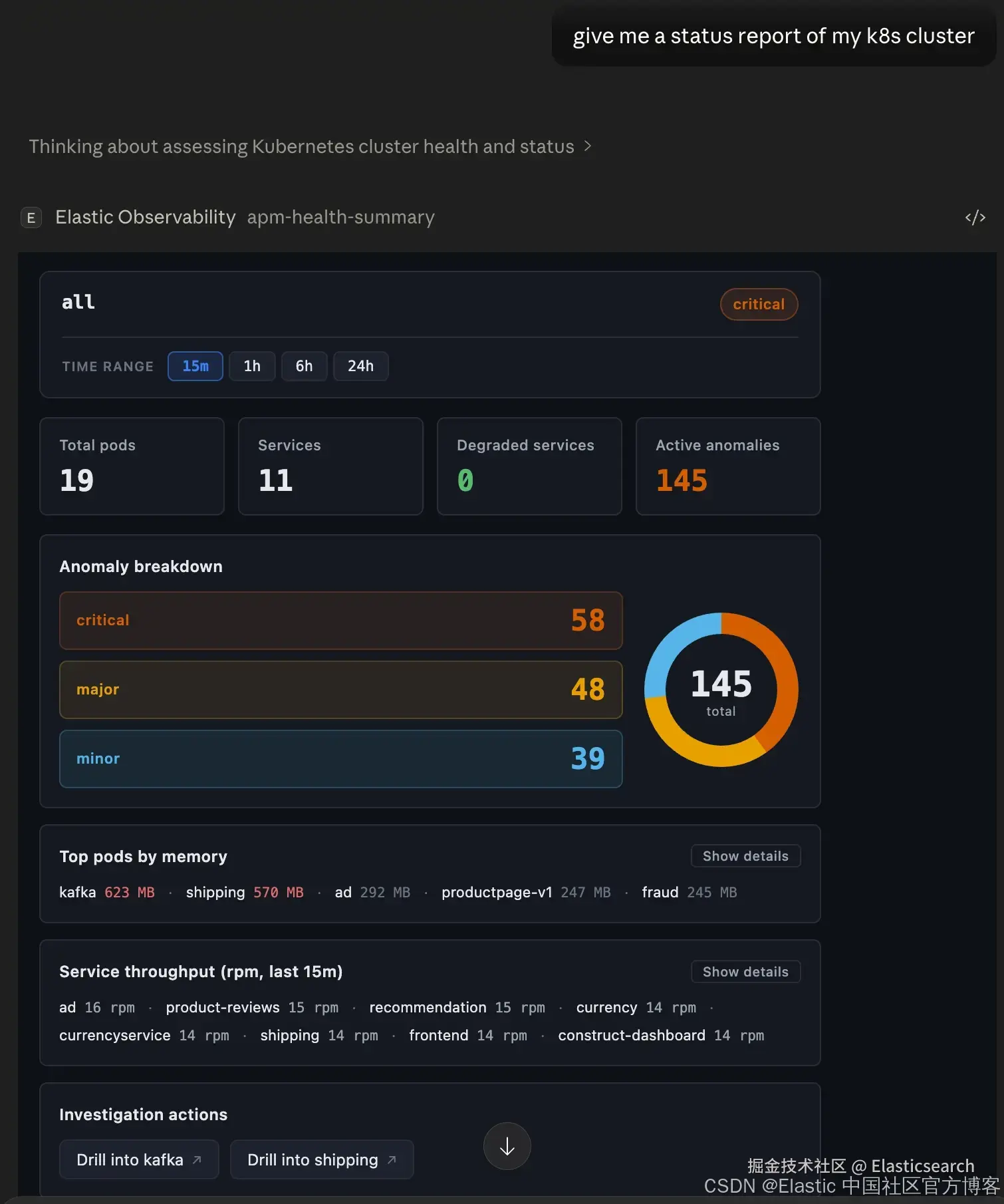
像健康汇总这样的复合报告具有压缩式数据展示和细节展开能力,让你可以自行选择一次查看的信息粒度。建议的调查操作不仅针对当前返回的具体信息提供指导,也帮助用户定位需要使用的其他工具。
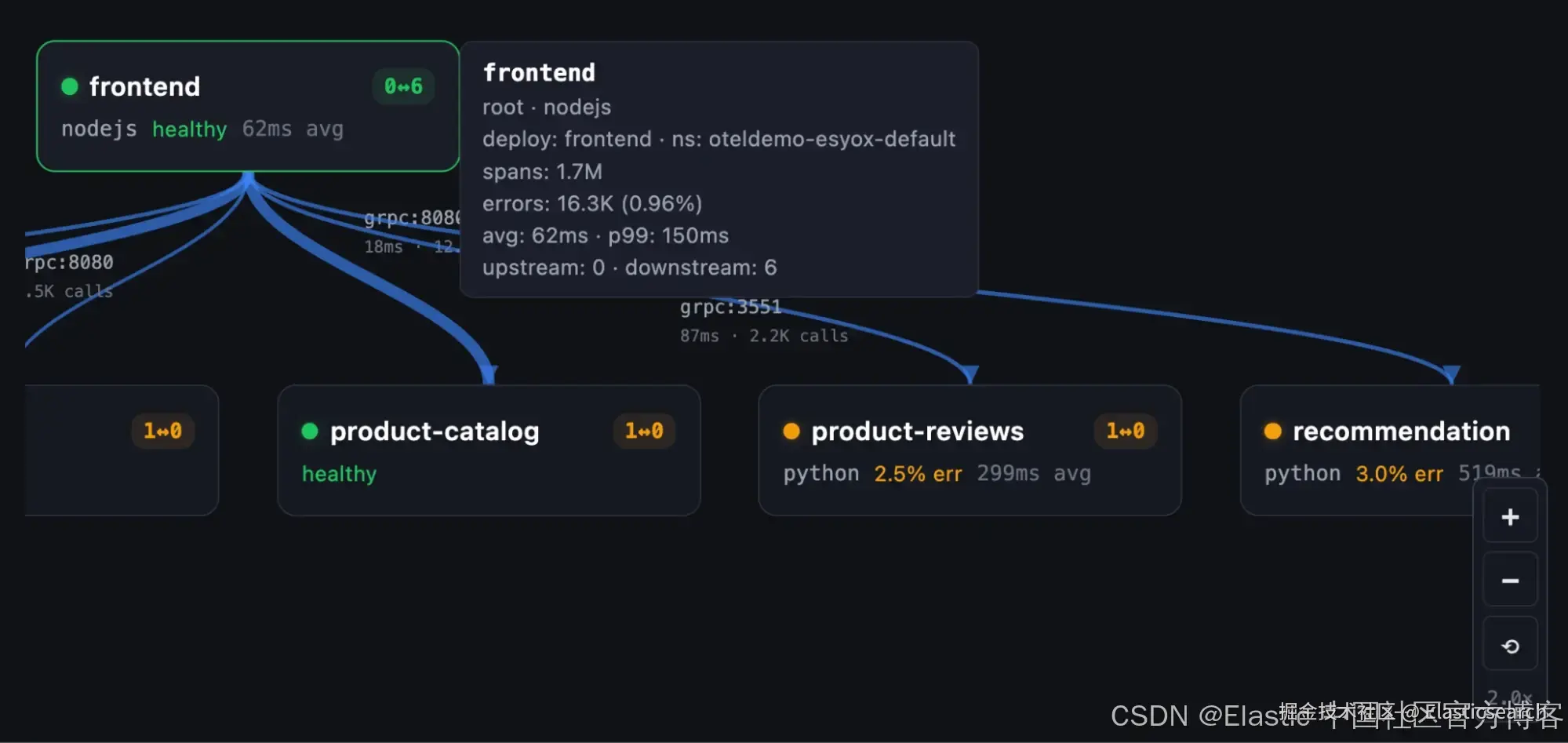
Service 依赖关系图
当你询问 "谁调用了 checkout?" 或 "展示拓扑结构" 时,会得到一个分层的依赖关系图 ------ 包括上游调用方、下游依赖、协议、调用量以及每条边的延迟。将鼠标悬停在某条边上时,可以高亮完整调用路径。让我们让 Claude 来"展示 frontend 的服务依赖关系":
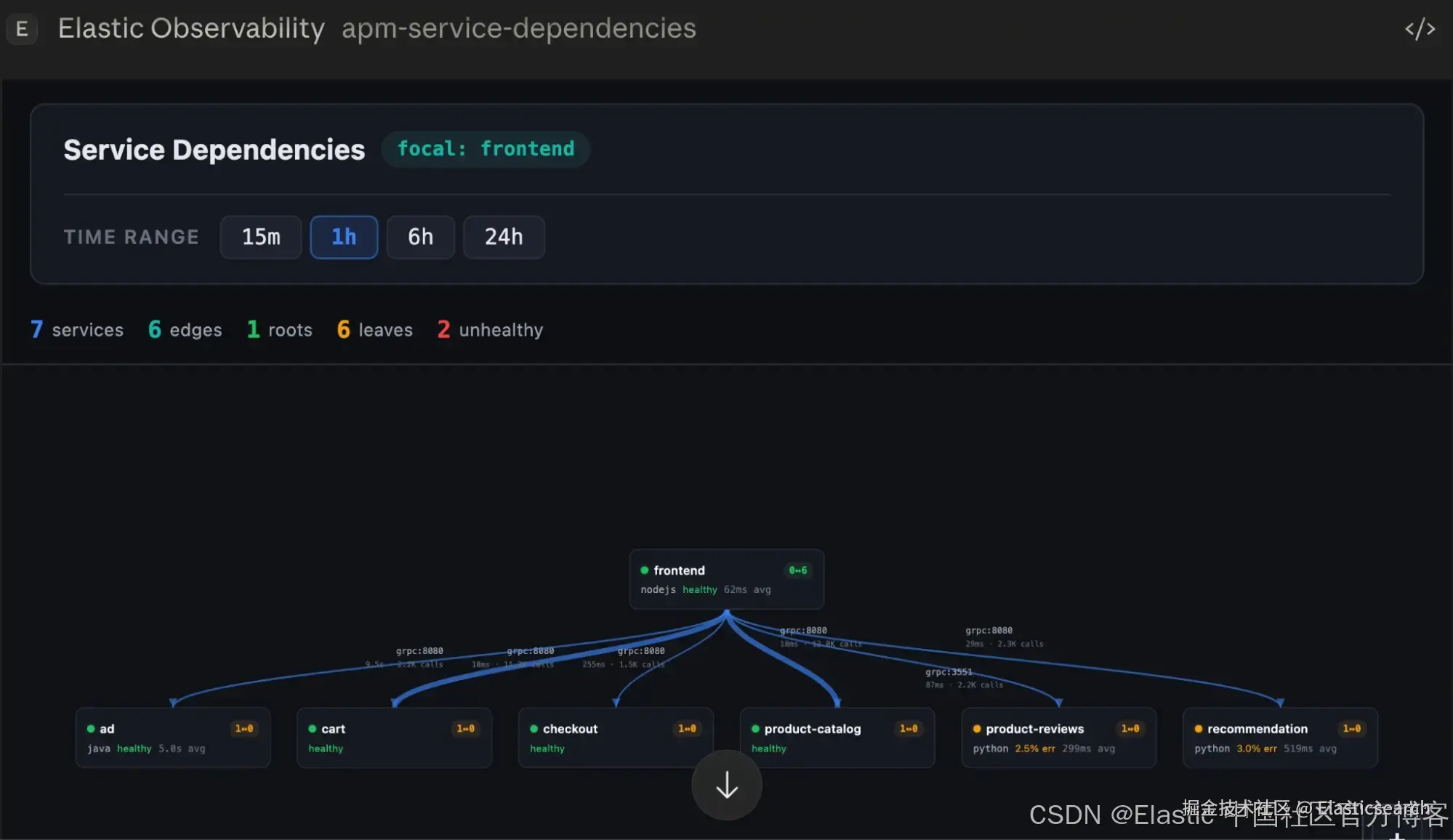
通过缩放、平移和悬停操作,你可以获取所有必要的细节,以理解复杂的服务关系:
异常详情
询问 "什么是异常?" 或 "在 checkout 中是否有任何异常?" 并自动获得两种视图之一。
如果有多个实体受到影响, overview mode 会显示严重程度计数、受影响实体以及按 job 的分解。
如果只有单个实体是关注重点, detail mode 会显示 score、actual vs. typical values 的对比(带 comparison bar)、deviation percentage,以及在可用情况下的 time-series。
让我们检查 frontend service:
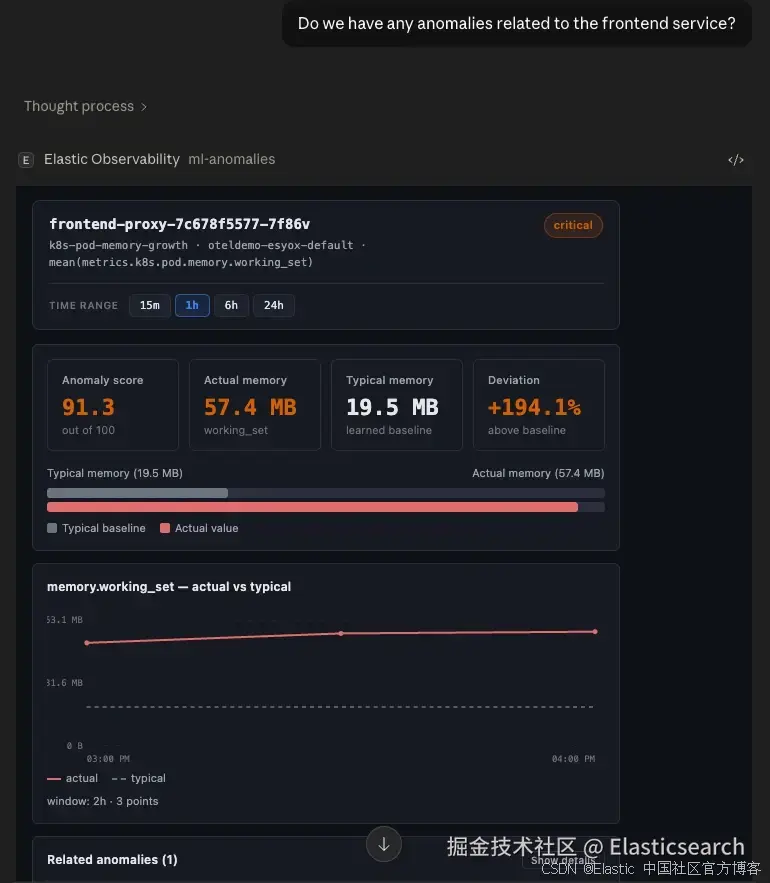
这不是一个 ESQL query --- 而是对先前定义的 anomaly detection job 结果的解释。正如本系列博客第一部分所讨论的,Kubernetes integration 随附了一些你可以启用的预置内容。这个 tool 将帮助你充分利用它们。
Observe
Observe 是 agent 访问 Elastic 的主要 primitive ------ 一个 tool,支持两种 mode,用于三种不同需求。说"我的 Kubernetes clusters 的 network throughput 是多少",可以得到结果的 table 或 chart。说"当 memory 低于 80MB 时告诉我"或"在接下来的 10 分钟内监控 frontend memory 是否异常",它会阻塞直到条件触发或时间窗口结束。
视图会根据 mode 自适应:一次性查询返回 results table,采样和 threshold 条件返回带当前值、峰值和 baseline stats 的实时趋势图,anomaly mode 则返回带 severity score 的 trigger card。我们将在这里使用它来识别最繁忙的 Kubernetes node:
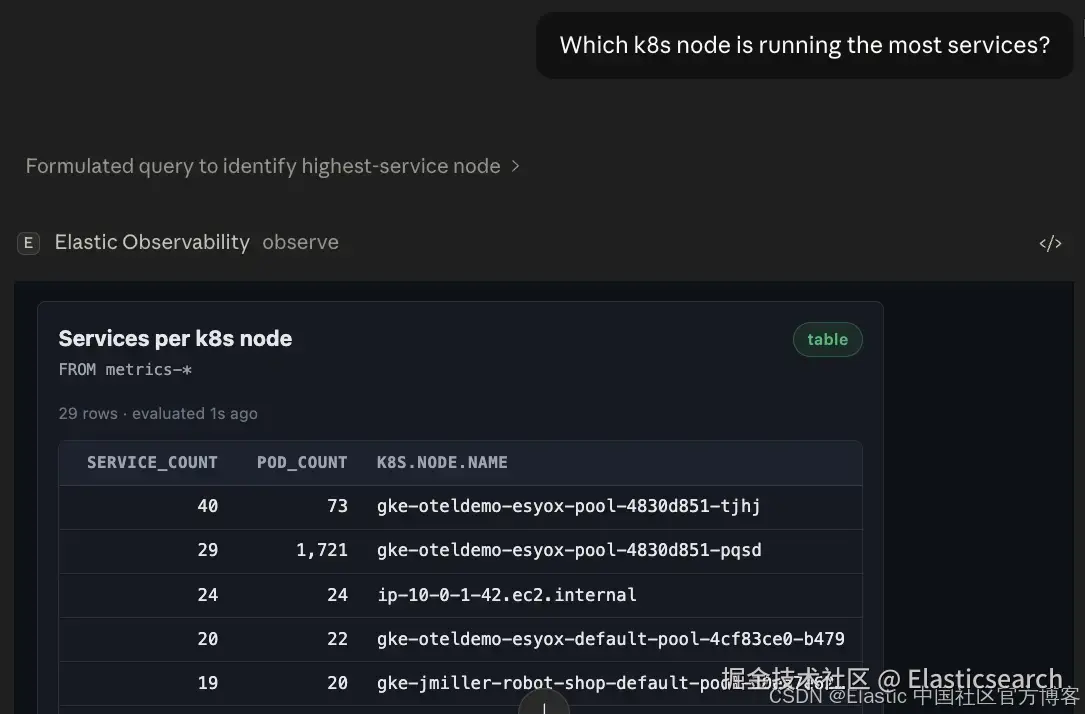
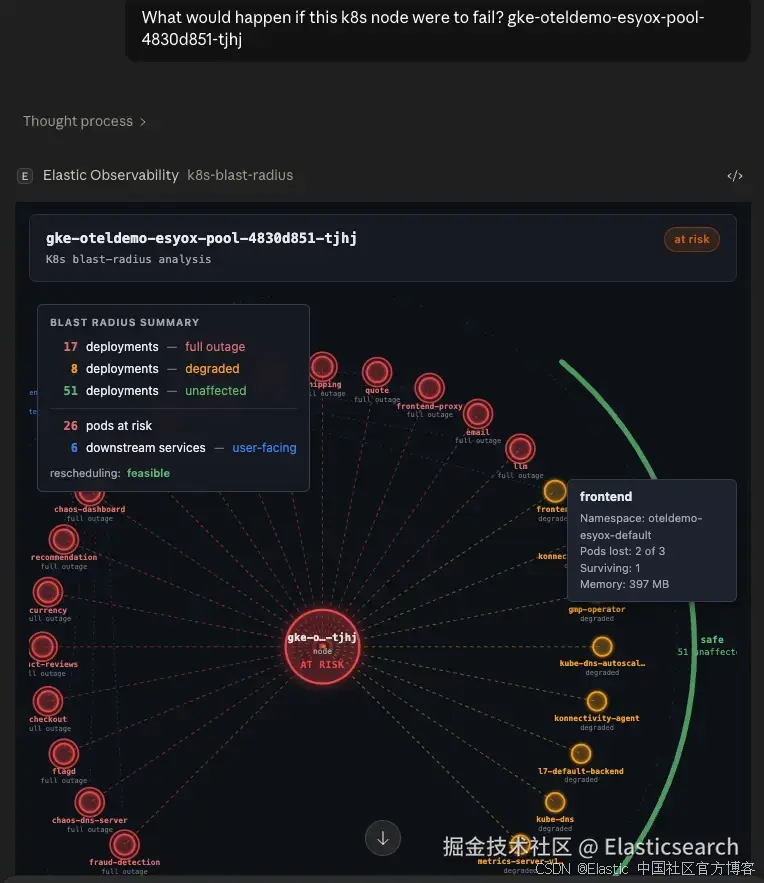
通过 blast radius 评估风险
当你询问 "如果这个 node 宕机会发生什么?" 时,会得到一个放射状影响图:目标 node 位于中心,完全中断的 deployments 用红色标记,性能下降的用琥珀色标记,未受影响的用灰色标记。
一个浮动的 summary card 会显示处于风险中的 pods,以及重新调度(rescheduling)的可行性。只有单副本(single-replica)的 deployments 会被标记为单点故障(single point of failure)。
如果我们的繁忙 node 发生故障,会发生如下情况:
警报管理
使用 Alert Management tool,你可以创建、列出、获取信息以及删除 alerts。我们接下来会创建一个 alert,但首先再使用 Observe 进行一次快速 baseline,以便我们确认这个 alert 是有意义的:
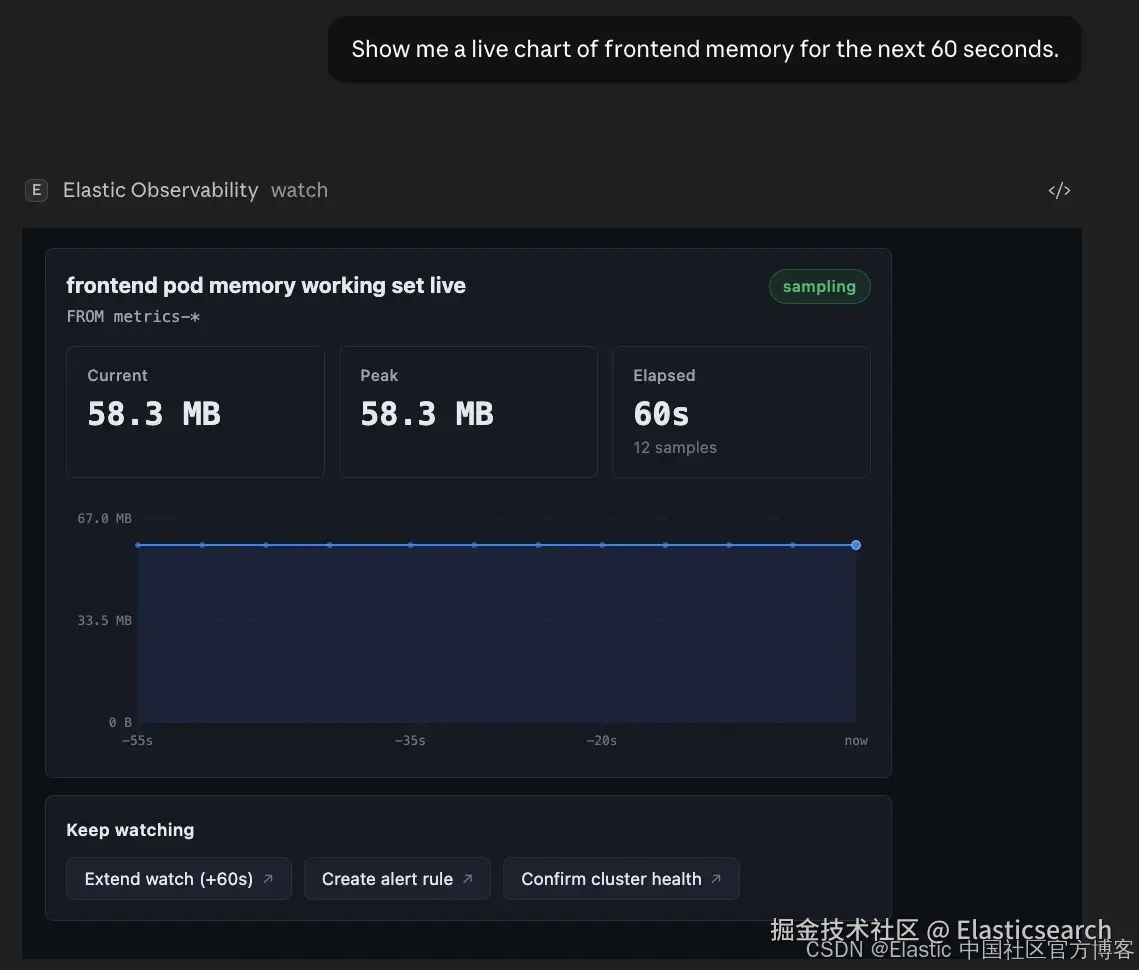
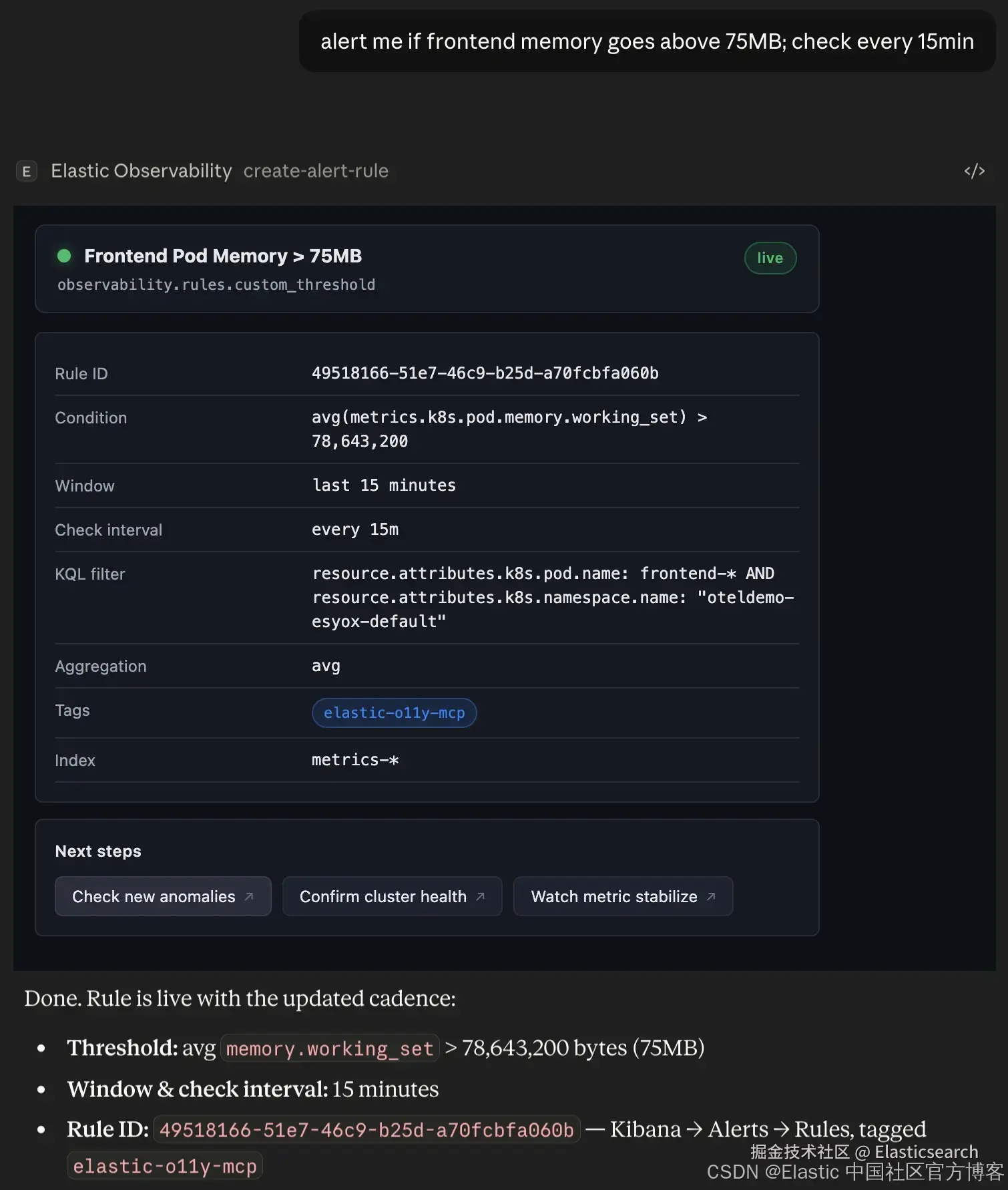
说 "如果 frontend 内存超过 75MB 就提醒我",agent 会创建一个持久化的 Kibana alerting rule ------ 一个在对话结束后仍会持续运行的 saved object。该视图会渲染一个实时 rule card:包含 rule name、condition、window、check interval、KQL filter 和 tags。
下一步按钮会提供操作选项:验证规则、观察指标是否稳定,或检查当前集群健康状况。
agent 会确认已创建的内容,以及在 Kibana 中的具体位置:
MCP App 架构
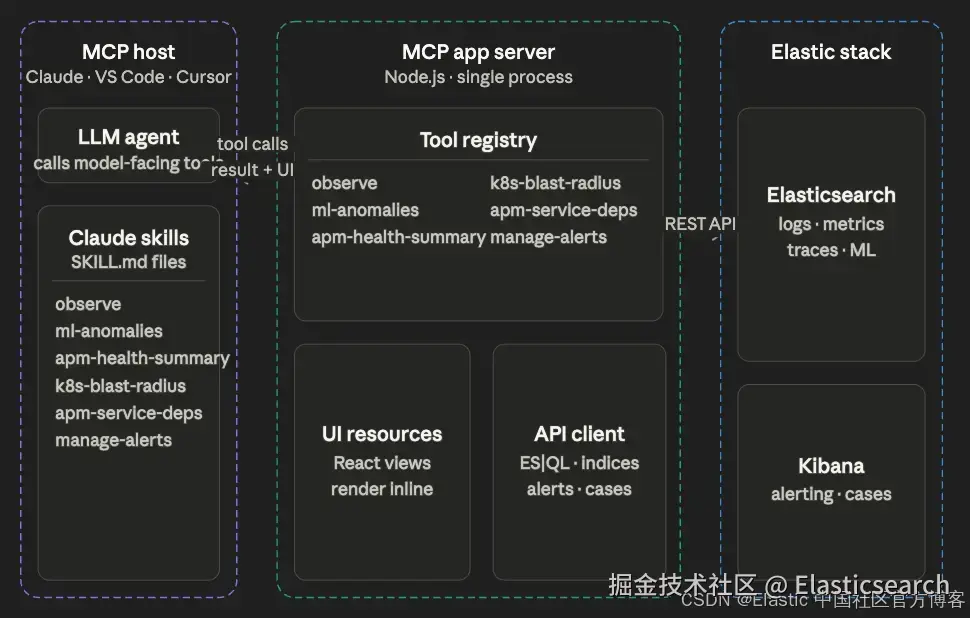
该应用由一个 Node.js server 构成,包含六个面向模型的 tools,这些 tools 分别绑定到六个单文件 view resources,同时还包括仅应用内部使用的 tools(用于重新查询),以及使用 vite-plugin-singlefile 的打包方式。
这些 tools 按部署后端进行分组(Universal、依赖 APM、依赖 K8s、依赖 ML),因此 agent 和用户在调用前就能清楚知道哪些 tools 可用,而不是在调用时才发现能力缺失。repo 还包含六个 Skills,以独立的 .zip 形式提供,用于指导 agent 何时以及如何调用每个 tool。
下面的图展示了该应用的三个组成部分:MCP host(如 Claude Desktop、VS Code 或类似环境),其中包含 LLM 以及教会它如何使用 tools 的 Claude skills;MCP app server,一个单一的 Node.js 进程,负责暴露 tool registry、打包 React UI views,并处理与 Elastic 的所有通信;以及 Elastic Stack,本身由 Elasticsearch 和 Kibana 组成,作为实时数据与 alerting 后端。
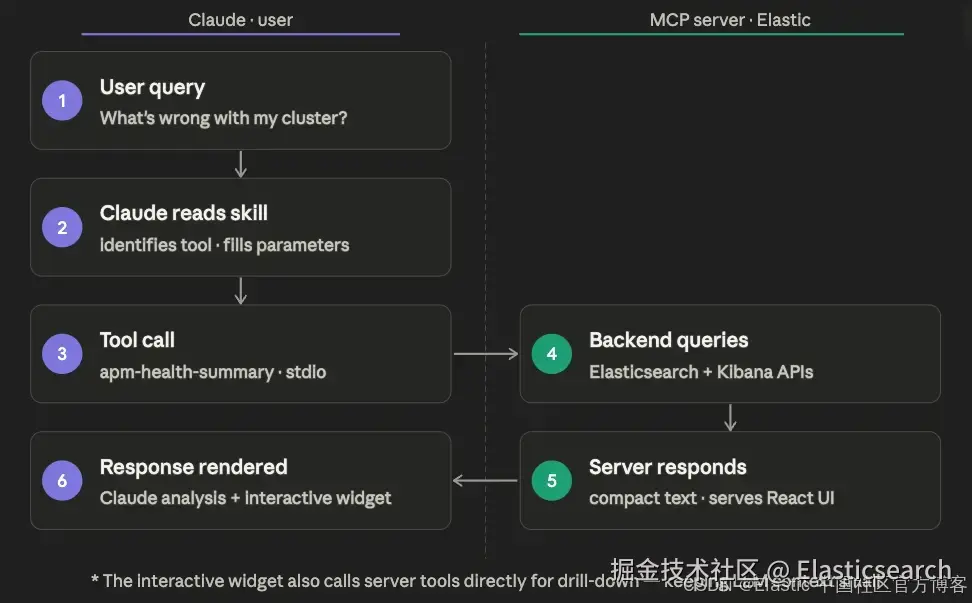
下图展示了用户请求的完整流程:Claude 读取相关的 skill 文件,以理解应该调用哪个 tool 以及如何填充其参数;随后调用该 tool,触发对 Elasticsearch 和 Kibana 的服务端查询;最后返回一个压缩的文本摘要,以及一个 React UI resource,该资源会以内联方式渲染为一个可交互 widget。
从 alert 到根因:Investigation Workflows
Alert rules 告诉你出了问题,ML modules 告诉你模式,而 Elastic Workflows 会自动执行诊断------在 alert 触发的瞬间就开始运行。
我们正在发布一个 Kubernetes Investigation Workflow(技术预览),它会在 Kubernetes alert 触发时启动,并在你打开任何 dashboard 之前返回一个结构化的根因分析摘要。被 paging 的 SRE 打开 alert 时,调查结果已经准备好了。
该 workflow 是一个有向图(directed graph)的步骤集合,它会查询多个数据源------主要通过 Elasticsearch Query Language( ES|QL ),并通过 Elasticsearch search 进行 ML anomaly lookup。如果步骤存在分支,则会基于查询结果决定下一步执行哪种验证,例如选择运行哪种相关性分析(ML memory anomaly 或 log classification),以及是否评估上游健康状态(仅在存在 APM dependencies 时)。
AI 步骤在三个关键点出现:在非 OOM 路径上对日志模式进行分类、对上游 degraded vs healthy 状态进行分类,以及最后通过 ai.summarize 将所有结构化证据整合为一段根因叙述。
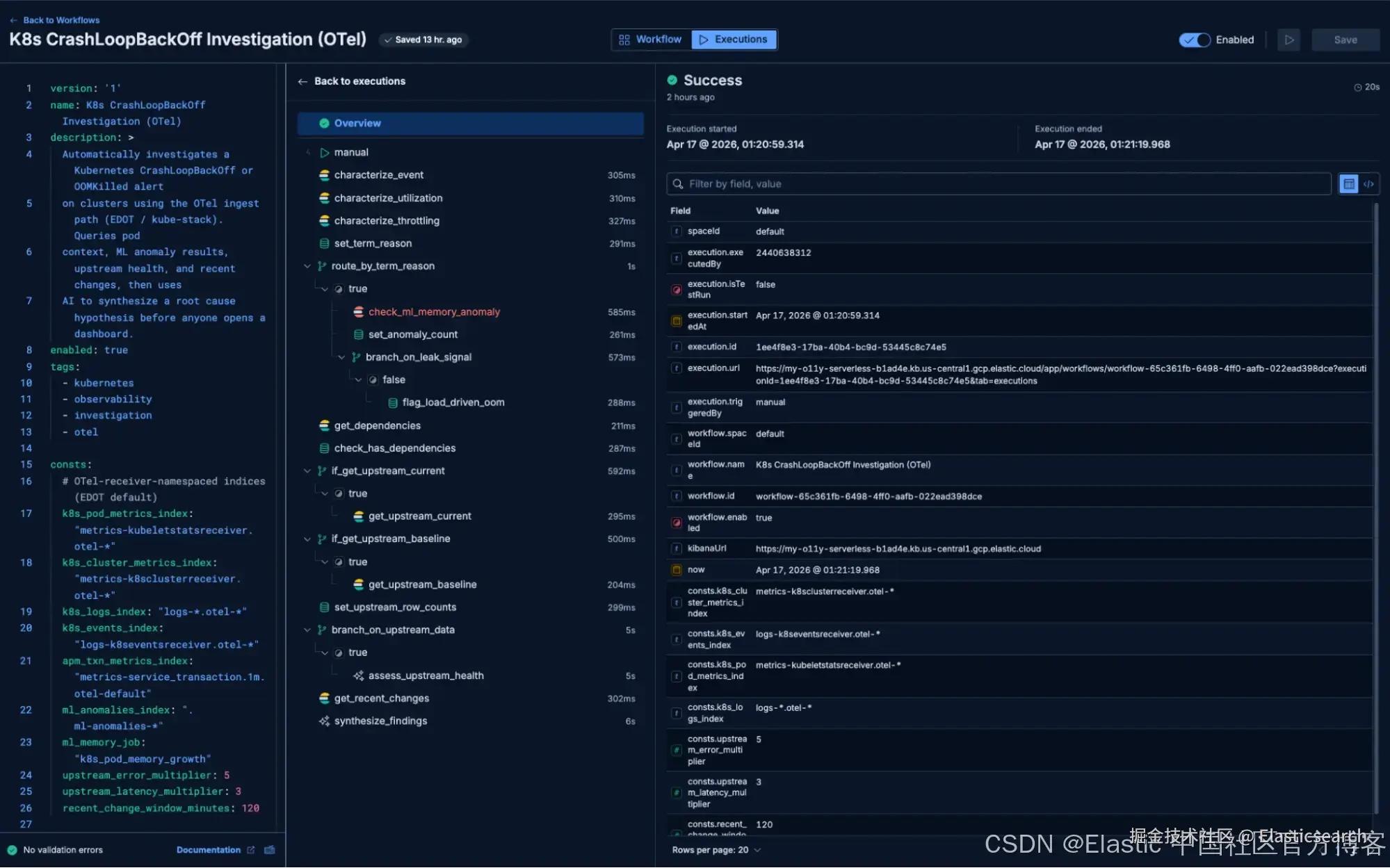
实际中的调查工作流长什么样
下面的示例执行基于运行在 Elastic 上的 OpenTelemetry Astronomy Shop ------ 包含 16 个服务、Kafka、PostgreSQL,并通过 OTLP 预先完成可观测性接入。除了 Shop 的真实遥测数据之外,我们还注入了一个合成的 OOMKill 连锁事件,该事件通过 EDOT 数据流写入同一个 namespace 中的合成 K8s 和 APM 信号。该 workflow 无法区分这些信号是真实还是模拟的------它只负责调查 alert 本身。
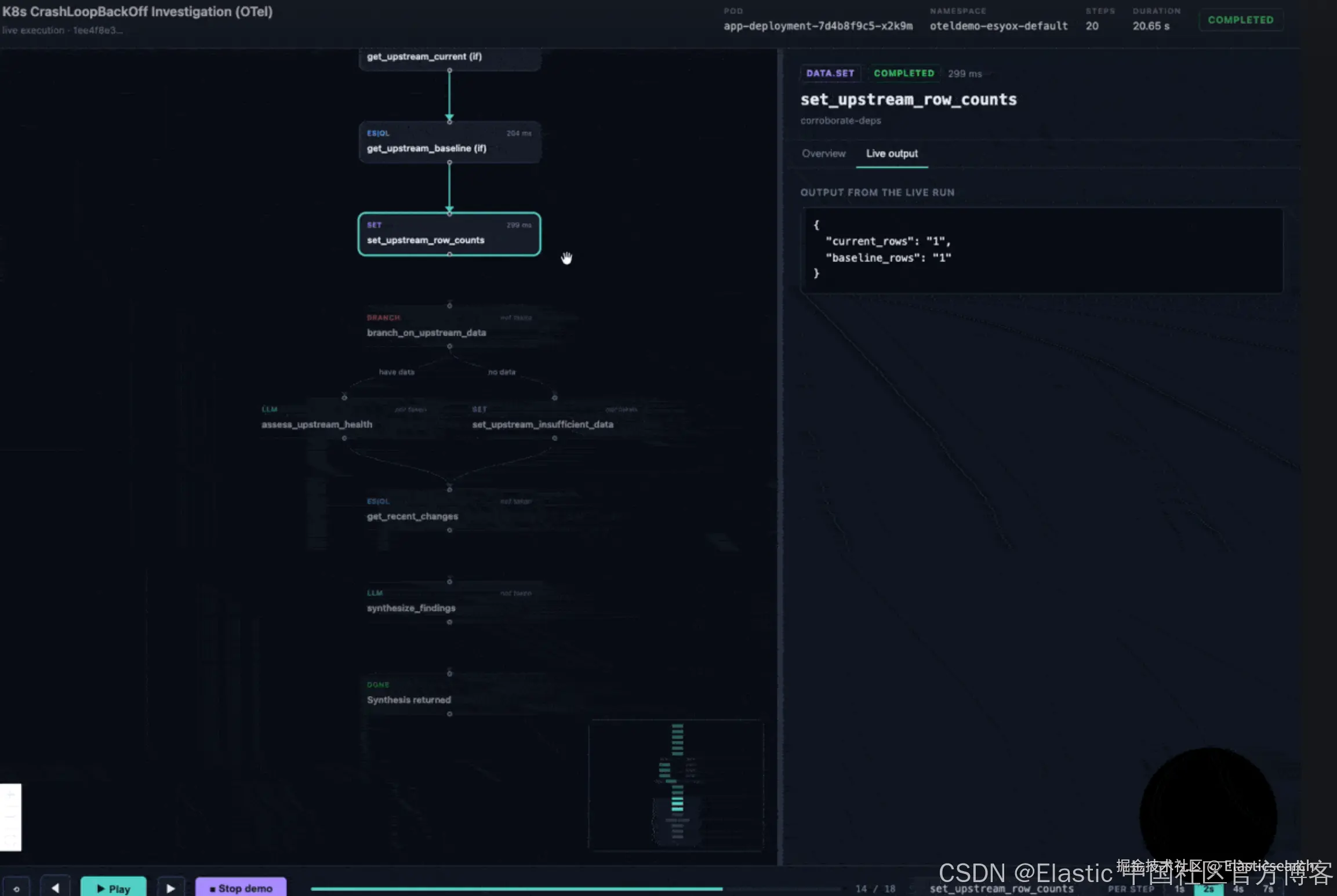
Alert 触发:CrashLoopBackOff ------ app-deployment 位于 oteldemo-esyox-default。重启次数:6。
Workflow 步骤 1 ------ 描述 Pod 与容器上下文
workflow 查询 K8s metrics,获取 restart count、last termination reason,以及相对于声明 limit 的资源利用率。
结果:最后终止原因是 OOMKilled,重启次数为 6。(注意:该 pod / 时间窗口的 kubeletstats utilization 不可用------workflow 仍然会优雅继续。)
workflow 分支:由于 termination reason 为 OOMKilled,因此进入 memory-investigation 路径,而不是 log-investigation 路径。
Workflow 步骤 2a ------ 查询 ML anomaly 结果
workflow 不再重新计算 memory trend,而是查询 ML anomaly index 中是否存在 k8s_pod_memory_growth 异常。
结果:没有 anomaly ------ 该 spike 被标记为 load-driven,而非 suspected leak。
Workflow 步骤 3 ------ 检查上游服务健康状况
workflow 基于 APM service_destination.1m 聚合枚举上游依赖,然后将当前 error rate 和 mean latency 与 7 天前同一时间进行对比。一个 AI 分类步骤判断上游退化是否发生在 alert 之前。
结果:只有一个上游 ------ api-gateway。当前 mean latency 15.13 ms,error rate 41.26%。基线(168 小时前):相同。分类结果:upstream_healthy ------ error / latency 均在 5× / 3× 阈值以内。排除上游因素。
Workflow 步骤 4 ------ 关联近期 K8s 变更
namespace 的 event log 显示一个紧密循环:Pulled → Created → Started → Killing → BackOff,大约每 60--90 秒重复一次。过去两小时内没有 deployment 或 scaling 事件。
Workflow 输出:
csharp
`
1. ROOT CAUSE HYPOTHESIS (confidence: high)
3. app-deployment is OOMKilling under memory pressure. The pod has restarted
4. 6 times with termination reason OOMKilled. ML flagged the memory spike as
5. load-driven (no leak). Upstream api-gateway is healthy at current vs 7-day
6. baseline. This is a resource-allocation issue --- the container's memory
7. limit is too low for its real working set.
9. Evidence:
10. - 6 restarts, last termination reason OOMKilled
11. - No ML memory-growth anomaly → leak_suspected=false (load-driven)
12. - Upstream api-gateway unchanged vs 7d baseline (15.13 ms, 41.26%) → healthy
13. - K8s events show tight Pulled/Created/Started/Killing/BackOff cycles;
14. no deployments in the last 2h
16. Likely cause: memory limit insufficient for actual working set under load.
18. Recommended next steps:
19. 1. Raise the app-deployment memory limit based on observed usage
20. 2. Review application code for memory-optimization opportunities
21. 3. Consider graceful degradation on high-load paths
23. Downstream impact: none identified from APM destination metrics.
`AI写代码上面的输出就是你打开 alert 时看到的内容------不是一堆日志或 dashboard 链接,而是一个答案。
同一个 workflow 也可以作为 MCP tool 在 Claude Desktop、VS Code 或任何兼容 MCP 的客户端中使用。当开发者在 IDE 中询问"为什么 checkout 出错?"时,agent 会调用该 workflow,并在编辑器内联返回相同的结构化输出------相同的证据、相同的根因分析,无需离开当前环境。
下面是该 workflow 执行过程的动画演示:
Kubernetes 调查的 Observability Skill
我们还发布了一个单一的、完整的调查 Skill(observability-k8s-investigation),它编码了 Kubernetes workload、node 和 control-plane 问题的完整诊断协议。这是一种带有明确观点的调查方法论,包含经验丰富的 SRE 会本能使用但很少写下来的推理方式。你可以通过保持 Kibana 更新获得这一能力,因为它已经内置在我们的 AI Agent skills 中。它从一些治理原则开始,用于防止最常见的误诊:
- 缺乏证据不等于没有问题。如果 log 查询返回 0 行,应报告 no_logs_available ------ 不要从空结果推断故障模式。
- OOMKilled 并不默认意味着内存泄漏。在断言泄漏之前,需要将当前使用情况与 7 天基线进行对比。可能只是 limit 设置过低。
- CPU 平均值会隐藏 throttling。一个 pod 在 40--60% 平均利用率下,可能在 p95 层面已经严重受限。应关注 max 和 p95,而不仅仅是平均值。
- 共现症状不等于因果关系。两个服务同时退化通常共享同一个上游原因。只有在一个服务退化明显先于另一个,并且差值显著时,才可以归因因果关系。
在此基础上,该 Skill 编码了一个失败模式分类体系,覆盖 16 种 Kubernetes 故障模式,横跨 workload、node、control-plane、autoscaling 和 networking 层------从 OOMKilled、CFS throttling,到 admission webhook blocking,再到 StatefulSet split-brain。每种模式都有一个关键识别信号(pivotal signal)以及用于验证的 corroboration checklist。
调查流程遵循结构化路径:
- orient(定位目标 pod、namespace、deployment)
- characterize(获取重启次数、终止原因、资源使用情况)
- classify(匹配故障分类体系)
- corroborate(拉取 events、logs、APM 与基线对比)
- synthesize(生成带校准置信度的根因假设:高 / 中 / 低,并给出证据与建议)
当两种故障模式同时符合证据时,Skill 会同时指出,并说明哪一个更可能是因果以及原因。当证据不明确时,它会明确说明不确定性。"竞争性假设是有效输出"是一个明确设计原则------制造虚假自信本身被视为一种调查失败模式。
开始使用
这些能力建立在第一部分介绍的 Kubernetes integration 之上。一旦你已经启用了 dashboards 和数据采集:
步骤 1 ------ 启用调查 workflows(技术预览)
在 Kibana 的 Workflows 页面导入 Kubernetes Crashloop Investigation Workflow,并可选择配置为在 alert rule 触发时自动执行。
步骤 2 ------ 在 MCP 兼容客户端安装 MCP App(技术预览)
Observability MCP App 仓库可在 GitHub 找到(下载请见 Releases 页面)。安装 app 时,不要忘记同时安装并启用内置 skills。从你喜欢的 agentic 客户端访问 Example MCP App 的 tools,具体说明在 GitHub 仓库 README 中。
步骤 3 ------ 使用 K8s Investigation Skill(技术预览)
如果你使用 Agent Builder,这一步是"开箱即用"的,因为它已经内置在 AI Agent Skills 中。该 Skill 会教会 agent 在对话中何时以及如何调用底层 tools 和 workflows,从而确保一致的诊断行为。
接下来
调查 workflows 解决的是"服务哪里坏了"。但下一个问题更难:那些你没有监控的服务怎么办?
我们正在探索 topology-aware coverage intelligence ------ 自动通过 Kubernetes API 发现集群中的所有 workload,并与 Elastic 中流动的 telemetry 进行交叉比对,从而找出监控盲区。"你有 47 个服务,其中 11 个没有分布式 traces。这是你最危险的盲点。"这一能力仍在评估中,可能会成为未来文章的主题。
同时,我们也在向 remediation 方向扩展 workflows ------ 不只是诊断,还包括行动:基于调查结果创建 case、提出(需人工确认的)回滚建议,或在根因解决前临时扩容以缓解影响。
如果你正在 Elastic 上运行 Kubernetes,请告诉我们哪些调查步骤你在每次 incident 中都会重复执行、哪些 remediation 你愿意信任 workflow 自动建议,以及我们下一步应该构建哪些 MCP tools。你可以在 Elastic Community Discussion 加入讨论。