作者:来自 Elastic Pete Naylor

Elasticsearch Reindex 现在能够在节点关闭后继续执行任务,使用 Point in Time(PIT)实现更高效的源数据遍历,并提供专门的管理 API。在 Serverless 中,Reindex-from-remote 现已正式发布。
了解将数据摄取到 Elasticsearch 的不同方式,并通过实际示例深入体验和尝试新的功能。
Elasticsearch 持续推出新特性,帮助你为自己的使用场景构建最佳搜索解决方案。现在就开始免费的云试用,或者在本地机器上体验 Elastic。
Reindex 操作现在能够在 Elasticsearch 中跨越正常节点关闭(graceful node shutdown)继续运行,自动迁移到其他符合条件的节点,并从最后一个已完成的批次恢复执行,无需任何人工干预。
在支持的情况下,源数据遍历方式已经从 scroll 切换为 Point in Time(PIT):
-
不再需要为每个分片维护搜索上下文(search context)
-
任务进度状态可以在节点之间自由迁移
-
Reindex 任务迁移实现更加简洁
同时,一组全新的 Reindex 专用管理 API 已经推出,包括:
-
列出任务(list)
-
查看任务详情(inspect)
-
取消任务(cancel)
-
调整限流速率(rethrottle)
这些 API 取代了过去依赖通用 Task API 拼凑实现管理功能的方式。
此外,Elastic Cloud www.elastic.co/cloud/serve... 中的 Reindex-from-remote 现已正式可用,支持从任何 Hosted 部署或 Serverless 项目直接迁移数据。
如果你过去需要:
-
专门安排维护窗口执行 Reindex
-
为运行中的节点故障编写复杂的重试逻辑
-
处理任务中断后的恢复问题
那么现在大部分复杂性都已经由集群自动处理。
这些改进今天已经在 Elastic Cloud Serverless 中可用,而 Elastic Cloud Hosted(ECH)和 Elasticsearch 自托管环境的版本也即将发布。
接下来我们将详细介绍这些功能的实现方式、工程设计中的权衡,以及它们将如何改变你在生产环境中使用 Reindex 的方式。
Elasticsearch Reindex 如何在节点关闭后继续运行
一次 Reindex 操作可能持续数分钟甚至数小时,具体取决于数据量大小。
在这段时间内,集群并不会停止变化:节点会升级、基础设施会调整、运维人员会执行日常维护。如果正在执行 Reindex 的节点因为维护而关闭,那么过去该任务就会直接消失。
此时你会面对一个部分完成的 Reindex 任务,并不得不回答一个问题:
它到底执行到哪里了?
我们希望解决这个问题。
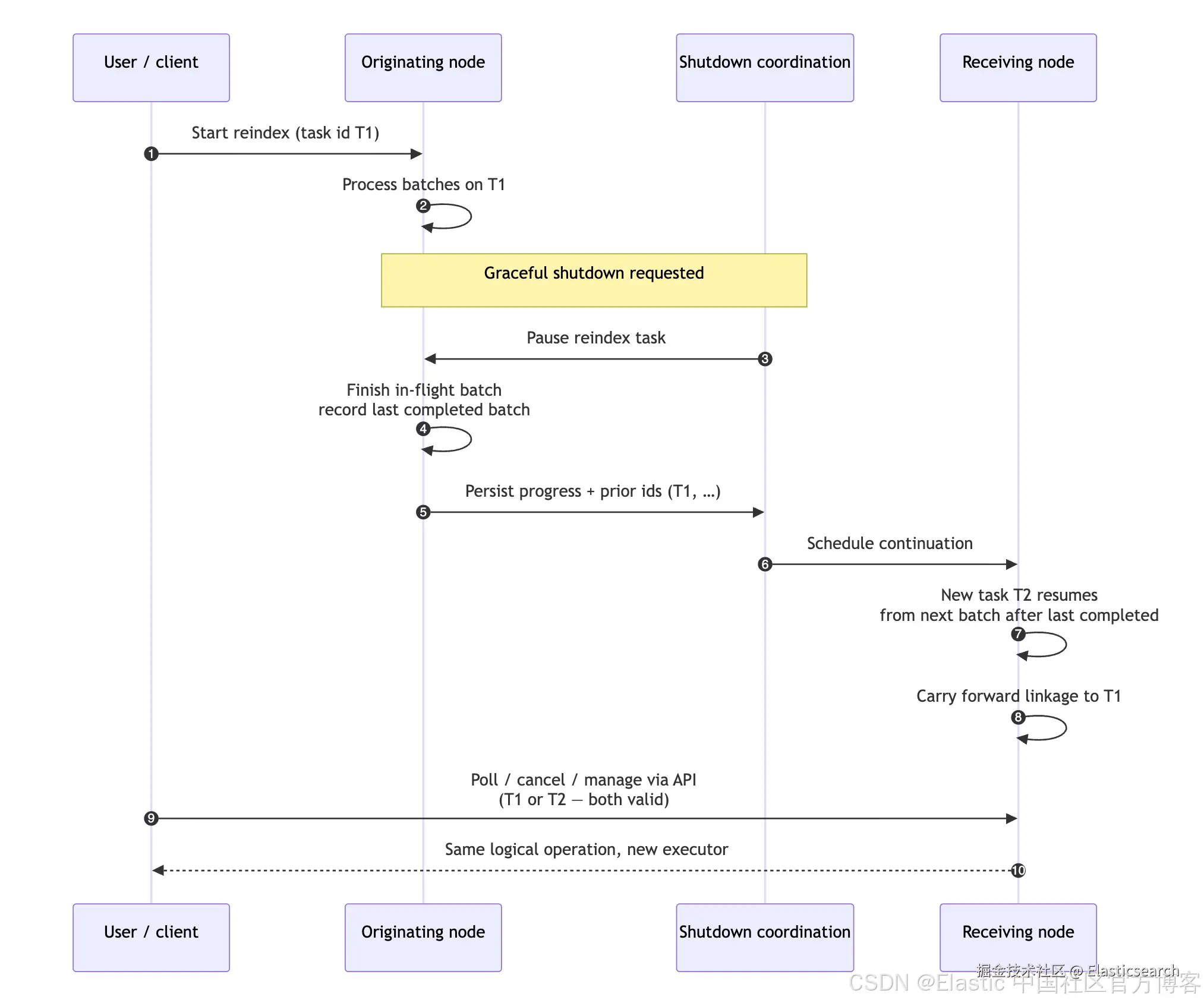
现在,Reindex 操作已经能够跨越正常节点关闭(graceful shutdown)继续运行。
Elasticsearch Reindex 任务迁移的工作原理
过去,Reindex 会作为一个任务运行在接收到请求的节点上,并且在整个执行周期内始终绑定在该节点。
现在,节点关闭协调层(shutdown coordination layer)已经具备了对 Reindex 任务的感知能力。
当节点执行正常关闭时:
-
节点会通知 Reindex 任务暂停执行。
-
系统会保存当前任务的进度状态。
-
剩余工作会被移交给集群中的另一台符合条件的节点。
接收任务的新节点会创建一个新的任务(拥有新的任务标识符),并从最后一个成功完成的批次继续处理数据。
同时,新任务还会记录此前所有任务标识符之间的关联关系。
因此,Reindex 管理 API 无论接收到原始任务 ID 还是迁移后的任务 ID,都能够正确地定位到当前运行中的任务。
从用户视角来看,整个处理过程无需任何人工干预,Reindex 会自动继续执行。
这项功能在托管环境中尤其重要,例如 Elastic Cloud。在这些环境中,基础设施运维通常是自动化完成的,以降低运维负担。
对于 Serverless 项目而言,扩缩容和拓扑变更都是日常操作。此时,长时间运行的 Reindex 任务最容易暴露出协调任务无法迁移的问题。
同样,这项功能对于 Elastic Cloud Hosted(ECH)部署以及自托管集群在执行版本升级或拓扑调整时也非常有价值。
自动 Reindex 任务迁移带来了什么
-
在执行 正常关闭 (graceful shutdown)流程时,任务迁移会自动发生,无需用户执行任何操作。
-
即使任务已经迁移到新的节点,你仍然可以继续使用原始任务 ID 调用管理 API;这些 API 在迁移后依然能够正常工作。
全新的 Reindex 专用任务管理 API
过去,Reindex 一直依赖 Elasticsearch 的 Task API 来实现状态查询和取消操作:
-
GET /_tasks/{node_id:task_id} -
POST /_tasks/{node_id:task_id}/_cancel
而调整限流速率(rethrottle)则使用:
POST /_reindex/{task_id}/_rethrottle
随着前面提到的任务迁移能力引入,这些接口也需要进行相应调整。
我们意识到,通用的 Task 管理 API 在直接管理 Reindex 操作时,并没有提供最佳的使用体验。
此外,其中一些 API 路径在 Serverless 环境中并不可用,从而导致管理能力存在缺口。
因此,我们引入了以 Reindex 为中心(reindex-first) 的 REST API。
通过这些新接口,你可以使用一个 Reindex 任务标识符(reindex task identifier)来:
-
列出任务(list)
-
查看任务详情(inspect)
-
调整执行速率(rethrottle)
-
取消任务(cancel)
而不再需要假设任务仍然运行在最初的节点上。
在底层实现中,集群仍然支持旧的 node_id:task_id 格式以保持兼容性。当系统检测到这种旧格式时,会自动回退到现有的 Task API 处理逻辑。
这些管理能力现在已经全部支持 Serverless。
Reindex 管理接口
下表列出了完整的 Reindex 专用管理 API 集合。
| 方法 | 路由 | 用途 |
|---|---|---|
| GET | /_reindex |
列出 Reindex 操作 |
| GET | /_reindex/{reindex_task_id} |
获取单个 Reindex 操作的状态(进度、指标等) |
| POST | /_reindex/{reindex_task_id}/_cancel |
取消 Reindex 操作 |
| POST | /_reindex/{reindex_task_id}/_rethrottle |
调整正在运行中的 Reindex 操作的限流速率 |
新的 Reindex 管理 API 在实际中解决了什么问题
响应内容更聚焦
返回结果会围绕 Reindex 操作本身进行组织,直接展示你所关心的 Reindex 详细信息,而不是通用任务信息。
更方便的任务列表查看
GET /_reindex
提供以 Reindex 为中心的任务视图,而不再需要从全局任务列表中筛选 reindex 相关条目。
覆盖所有部署模式
这些 API 路由将在所有 Elasticsearch 环境中提供一致的使用体验。
这一点对于 Serverless 尤为重要,因为过去通过通用 Task API 执行任务列表查询和任务取消操作并不可用。
Reindex API 权限:monitor_reindex 与 manage_reindex
这套设计还引入了更细粒度的集群权限,使用户能够遵循最小权限原则(least privilege),而无需授予完整的 manage 或 superuser 权限。
monitor_reindex
只读权限,包括:
-
查看 Reindex 任务列表
-
查看 Reindex 任务状态
manage_reindex
包含 monitor_reindex 的所有能力,并额外支持:
-
取消 Reindex 任务
-
调整 Reindex 任务限流速率(rethrottle)
Serverless 现已支持这些权限类型。
虽然 Serverless 内置的解决方案角色(solution roles)目前仍然比较粗粒度,但你可以创建自定义角色(custom roles),仅授予这些 Reindex 相关权限,从而实现更严格、更精细的访问控制。
Point in Time 替代 Scroll:更好的基础架构
Reindex 过去一直依赖 scroll 来遍历源文档。
相比 scroll,PIT(Point in Time)在任务迁移场景下具有更好的特性:
-
不需要为每个分片维护搜索上下文(per-shard search context)
-
状态可以跨节点迁移
-
不依赖特定节点(no node affinity)
而 scroll context 会持续占用特定节点上的资源,这恰恰会造成节点绑定(node affinity)问题,使任务迁移变得更加困难。
因此,现在 Reindex 在读取源数据时会优先使用 PIT 而不是 scroll。
对用户有什么影响:Elasticsearch Reindex 中的 PIT 与 Scroll
PIT 能够提供某一时刻数据的一致性快照,同时避免 scroll 所带来的每个分片资源开销。
对于大多数 Reindex 操作,你可以预期 PIT 相比基于 scroll 的方案在以下方面表现更好:
-
性能(performance)
-
资源利用效率(efficiency)
-
可靠性(reliability)
工程权衡:为什么 PIT 需要显式分页
现在 Reindex 使用 PIT 配合显式的 [search_after](https://www.elastic.co/docs/reference/elasticsearch/rest-apis/paginate-search-results#search-after "search_after") 分页机制,而不再使用 scroll 的隐式游标推进方式(implicit cursor advance)。
这意味着系统需要额外维护分页状态,但换来的好处是:
-
进度状态可序列化
-
进度状态可迁移
-
支持任务恢复
-
支持跨节点继续执行
换句话说,系统增加了一些状态管理开销,以换取可迁移、可恢复的执行能力。
这是一个工程实现与用户体验同时受益的改进:
-
从工程角度看,PIT 更适合作为迁移和恢复的基础设施。
-
从用户角度看,它更加稳定、可靠,并且资源消耗更低。
对于 Reindex from Remote 场景,如果远端(remote)集群版本低于 7.10.0 ,则仍然需要使用 scroll。
协调节点会根据远端集群的版本自动协商并选择正确的行为模式。
Reindex 为每个任务创建一个 PIT,而多个切片(slice)会通过 search slicing共享同一个 PIT。
当任务发生迁移时,以下状态会一起被序列化并迁移到新的节点:
-
PIT 状态
-
search_after排序续传值(sort continuation values)
当 Reindex 成功完成或失败时,实现层会主动关闭 PIT。
如果关闭 PIT 的请求失败,则仍会按照 PIT 配置的正常超时时间自动过期。
Serverless 中 Reindex-from-remote 现已正式可用
Reindex-from-remote,即从一个 Elasticsearch 集群向另一个集群重新索引数据的能力,现在已在 Serverless 中正式发布。
这一能力对正在整合 Elastic Cloud 资源的团队尤为重要。
现在,你可以:
-
从 ECH(Elastic Cloud Hosted)部署重新索引数据
-
或从另一个 Serverless 项目重新索引数据
-
跨区域(any region)直接写入目标 Serverless 项目
这为以下场景提供了非常直接的迁移路径:
-
从 ECH 迁移到 Serverless
-
在不同 Serverless 项目之间重组数据
Serverless 中 reindex-from-remote 的限制与设计
需要注意的是,在 Serverless 中,reindex-from-remote 仅允许连接:
-
ECH 部署
-
Serverless 项目
并且支持任意区域(any region)。
这里不需要 allowlist(白名单)配置,因为这些访问控制由平台统一管理。
从自管理集群迁移的方式
如果你需要从自管理(self-managed)集群导入数据到 Serverless,一个常见做法是:
-
在自管理集群创建 snapshot
-
将 snapshot 挂载为 searchable snapshots
-
在一个临时的 ECH 部署上使用这些数据
-
再通过 reindex-from-remote 从该 ECH 集群迁移到 Serverless
为什么在 Serverless 中实现 Reindex 是一条"困难但正确"的路径
Serverless 的设计目标是让用户不需要关心基础设施协调,但平台本身必须持续处理这些协调工作。
这对长期运行的 API 是一个压力测试。
Reindex 是一个典型的长任务:
-
持续数小时的读写协调
-
进度必须可恢复
-
必须跨节点迁移
如果任务绑定在单个节点,或者依赖在节点迁移后失效的 task ID,那么每一次扩缩容或 graceful shutdown 都可能变成一次"迁移事故"。
前面提到的这些能力,本质上都是 Serverless reindex-from-remote GA 的前置条件:
-
可迁移任务模型(non-relocatable → relocatable)
-
更完整的任务管理 API(Serverless 可用)
-
从 scroll 迁移到 PIT 的稳定数据访问方式
这些问题在静态集群中可能很少出现,但在自动化环境中会频繁暴露。
真正让 GA 成为可能的,是把以下系统行为统一起来:
-
任务迁移(relocation)
-
远程认证与访问控制
-
管理 API 一致性
-
PIT + bulk slicing 的稳定执行模型
这些问题通常只会在高负载 + 分布式协调 + 节点频繁变化的情况下暴露出来。
在 Serverless 中开始使用 reindex-from-remote
只需要将:
source.remote.host
指向:
-
ECH 部署 endpoint
-
或另一个 Serverless 项目 endpoint
Serverless 不需要配置 allowlist,所有 Elastic Cloud endpoint 默认允许访问。
然后执行 reindex 请求即可开始数据迁移流程。
bash
`
1. POST _reindex
2. {
3. "source": {
4. "remote": {
5. "host": "https://my-hosted-deployment.es.us-east-1.aws.found.io:443",
6. "api_key": "..."
7. },
8. "index": "source-index"
9. },
10. "dest": {
11. "index": "destination-index"
12. }
13. }
`AI写代码请参考 reindex-from-remote 文档 获取关于认证选项和配置的完整细节。
Elasticsearch Reindex:任务迁移、PIT 与新 API 如何协同工作
Elasticsearch Reindex 的三项改进(任务迁移、PIT 迭代以及新的管理 API)作为一个整体系统共同工作。
-
PIT(Point in Time) 让 Reindex 更轻量、更具可迁移性
-
任务迁移(task relocation) 利用这种可迁移性,使任务能够在节点关闭时继续运行
-
新的 Reindex 管理 API 提供对整个流程的可见性与控制能力
-
Serverless 中的 reindex-from-remote 则打开了此前需要各种 workaround 的迁移路径(现在任何 Elastic Cloud endpoint 都可以作为已认证的远程数据源)
如果你过去一直在使用:
-
自定义重试脚本
-
分批切分逻辑(batch splitting)
-
维护窗口调度(maintenance window scheduling)
那么现在可以考虑简化这些流程。
让集群承担更多的容错与恢复能力,并使用新的 API 来监控与管理你的操作。
虽然 Reindex 仍然可能失败(你仍然需要为此做规划),但在大多数情况下,你可以在无需精细时间规划的情况下获得成功。
我们希望这些新 API 能在所有 Elasticsearch 环境中提供更好的数据迁移体验。
如果未来你在后台进行索引复制、映射更新或跨集群数据迁移,希望这个过程变得"几乎无感",甚至"刻意无聊"(intentionally boring)。
Elasticsearch Reindex 与长任务的下一步演进
我们将持续投入,让 Elasticsearch 内部以及跨集群的数据迁移变得更加可预测、更加易管理。
目前已经建立的这些模式------
-
任务迁移(task relocation)
-
基于 PIT 的迭代模型
-
专用管理 API
未来也会扩展到其他长时间运行的操作中。
你可以在自己的集群中尝试这些更新后的 Reindex API,并向我们反馈使用体验:
常见问题(FAQ)
Elasticsearch Reindex 在节点关闭时会发生什么?
当节点进入正常关闭(graceful shutdown) (例如滚动升级期间),Elasticsearch 会自动将正在运行的异步 Reindex 任务(wait_for_completion=false)迁移到其他可用节点。
任务会从最后一个完成的批次继续执行,无需用户干预,也不会丢失进度。
但需要注意:
-
硬件故障
-
网络中断
-
kill -9
这些非优雅失败不在覆盖范围内,需要手动重新启动 Reindex。
Scroll 和 PIT 在 Reindex 中有什么区别?
-
Scroll
-
为每个 shard 保持 search context
-
资源消耗高
-
在大索引上容易造成 node affinity(节点绑定问题)
-
不利于任务迁移
-
-
Point in Time (PIT)
-
提供一致性数据快照
-
不依赖 per-shard search context
-
更轻量、更可迁移
-
更适合长任务与分布式执行
-
对于远程集群或早于 7.10.0 的系统,Reindex 会自动回退到 scroll。
如何取消或调整 Reindex 任务速率?
使用新的 Reindex 专用 API:
-
POST /_reindex/{reindex_task_id}/_cancel -
POST /_reindex/{reindex_task_id}/_rethrottle
这些接口具有迁移感知能力(relocation-aware),能够自动找到当前执行任务的节点。
在 Serverless 中,这些专用 API 是必需的,因为通用 _tasks API 不提供完整支持。
如何列出所有正在运行的 Reindex?
使用:
GET /_reindex
它提供的是Reindex 专用视图 ,而不是从 _tasks 过滤结果。
相比之下,它可以直接返回:
-
进度
-
吞吐量
-
slice 状态
-
错误计数
无需知道任务当前在哪个节点运行。
能否从自管理集群直接 reindex 到 Serverless?
不能直接支持。
Serverless 的 reindex-from-remote 仅支持:
-
Elastic Cloud Hosted(ECH)
-
Serverless 项目
解决方案:
-
从自管理集群做 snapshot
-
在 ECH 上挂载为 searchable snapshots
-
从 ECH reindex 到 Serverless
管理 Reindex 需要哪些权限?
新增两个细粒度权限:
-
monitor_reindex:只读(查看列表与状态) -
manage_reindex:包含取消与限速操作
相比 manage 或 superuser,权限更细粒度,更符合最小权限原则。
在 Serverless 中,建议使用自定义角色来精确授予这些权限。
原文:Elasticsearch reindex: Relocation, PIT, and Serverless GA - Elasticsearch Labs