本文适合谁:了解 Java Bean Validation(@NotNull、@Valid)的工程师,想理解 pydantic 如何在 AI 项目中工作的开发者。读完本篇,你能用 pydantic 处理 LLM 的结构化输出,不再被 KeyError 和 TypeError 困扰。
LLM 的 JSON 输出存在一个固有问题:字段名可能变化(result 变成 results,或者套了一层 data.result),数值类型可能以字符串形式返回("42" 而不是 42)。用 response["result"] 直接访问,一旦字段不存在就抛 KeyError(键错误,访问字典中不存在的键时报出的错误),数值以字符串返回就引发 TypeError(类型错误,对错误类型的值进行操作时报出的错误)。
在数据进入系统时做校验和类型转换,把不符合预期的数据拦在外面,是正确的处理方式。pydantic 就是干这个的。
1.1 BaseModel:从一个对比开始
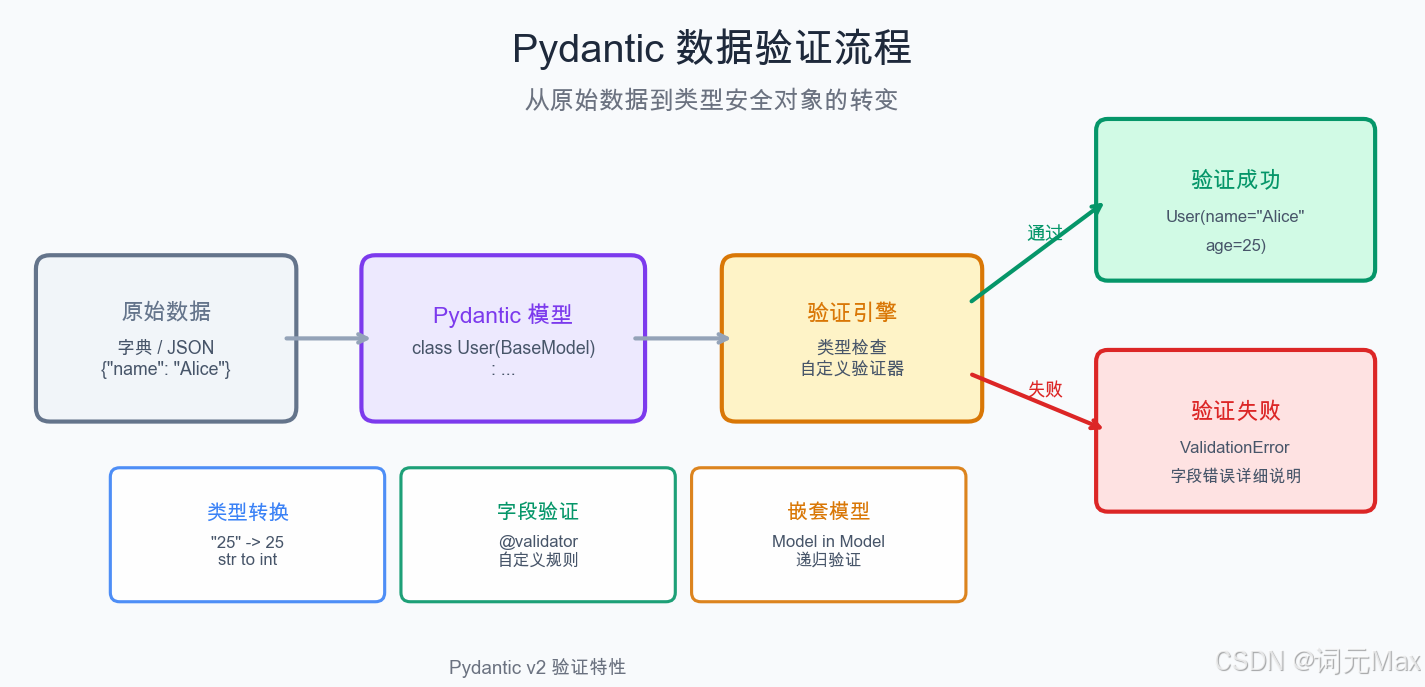
Pydantic 从原始数据到验证对象的完整处理流程
Java 里定义一个数据对象,通常是这样:
java
@Data
public class UserProfile {
@NotNull
private String name;
@Min(0) @Max(150)
private int age;
private String email;
}pydantic 的等价写法:
python
from pydantic import BaseModel, Field
from typing import Optional
class UserProfile(BaseModel):
name: str
age: int = Field(ge=0, le=150)
email: Optional[str] = None两者都做了类型声明和约束,但 pydantic 多做了一件 Java Bean Validation 做不到的事:自动类型转换。
python
# 传入字符串 "25",pydantic 自动转成 int 25
profile = UserProfile(name="张三", age="25")
print(profile.age) # 25,是int,不是字符串
print(type(profile.age)) # <class 'int'>这个特性在处理 LLM 输出时极其有价值,因为 LLM 的 JSON 里数字经常以字符串形式出现。
1.2 数据校验和错误提示
创建对象时如果数据不合法,pydantic 会抛出 ValidationError(校验错误,包含所有不合格字段的详细说明),错误信息清晰:
python
from pydantic import ValidationError
try:
profile = UserProfile(name="张三", age=200) # age超出范围
except ValidationError as e:
print(e)
# 输出:
# 1 validation error for UserProfile
# age
# Input should be less than or equal to 150 [type=less_than_equal, ...]这个错误信息可以直接返回给调用方,不需要额外包装。
1.3 Field:精细控制字段行为
Field 是 pydantic 里最常用的工具,控制字段的方方面面:
python
from pydantic import BaseModel, Field
from typing import Optional
class ProductAnalysis(BaseModel):
product_name: str = Field(description="商品名称")
sentiment_score: float = Field(
ge=0.0,
le=1.0,
description="情感得分,0到1之间,越高越正面"
)
category: str = Field(
default="未知",
description="商品类别"
)
keywords: list[str] = Field(
default_factory=list,
description="关键词列表,最多5个"
)
confidence: Optional[float] = Field(
default=None,
ge=0.0,
le=1.0,
description="置信度"
)几个关键点:
ge/le:大于等于/小于等于(gt/lt是严格大于/小于)default_factory:对于可变默认值(list、dict)必须用这个,不能用default=[]description:这个字段在 AI 开发里有特殊意义,后面详解
1.4 嵌套模型
LLM 经常返回嵌套结构的 JSON,pydantic 处理嵌套非常自然:
python
class Address(BaseModel):
city: str
district: str
street: Optional[str] = None
class Store(BaseModel):
name: str
address: Address
rating: float = Field(ge=0, le=5)
tags: list[str] = Field(default_factory=list)
# pydantic 自动处理嵌套的dict转换
data = {
"name": "好吃的饭馆",
"address": {
"city": "北京",
"district": "朝阳区"
},
"rating": 4.5,
"tags": ["川菜", "性价比高"]
}
store = Store(**data)
print(store.address.city) # "北京"
print(store.address.district) # "朝阳区"不需要手动 data["address"]["city"],pydantic 帮你把整个嵌套结构都转换好了。
1.5 model_validator:自定义业务逻辑校验
有些校验规则不是单个字段的约束,而是字段之间的关系。model_validator 处理这种情况:
python
from pydantic import BaseModel, Field, model_validator
from typing import Optional
class DateRange(BaseModel):
start_date: str
end_date: str
max_days: Optional[int] = None
@model_validator(mode="after")
def validate_date_range(self) -> "DateRange":
if self.start_date >= self.end_date:
raise ValueError(f"start_date ({self.start_date}) 必须早于 end_date ({self.end_date})")
# 如果设置了最大天数,检查范围
if self.max_days is not None:
from datetime import datetime
start = datetime.strptime(self.start_date, "%Y-%m-%d")
end = datetime.strptime(self.end_date, "%Y-%m-%d")
days = (end - start).days
if days > self.max_days:
raise ValueError(f"日期范围 {days} 天超过最大限制 {self.max_days} 天")
return selfmode="after" 表示所有字段校验完成后再执行这个验证器,此时 self 的所有字段已经是转换后的类型,可以直接用。
1.6 在 LLM 结构化输出里的应用
这是 pydantic 在 AI 开发里最核心的用法,也是它和普通数据校验库最大的区别。
OpenAI 的 GPT-4 和 LangChain 都支持让 LLM 直接输出符合 pydantic 模型的结构化数据。LangChain 里用 with_structured_output:
python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Optional
class MovieReview(BaseModel):
"""电影评价的结构化分析结果"""
title: str = Field(description="电影名称")
rating: int = Field(ge=1, le=10, description="评分,1到10分")
pros: list[str] = Field(description="优点列表,最多3条")
cons: list[str] = Field(description="缺点列表,最多3条")
recommendation: bool = Field(description="是否推荐观看")
target_audience: Optional[str] = Field(
default=None,
description="适合的观众群体,例如:科幻爱好者、家庭观众"
)
llm = ChatOpenAI(model="gpt-4o")
structured_llm = llm.with_structured_output(MovieReview)
review = structured_llm.invoke(
"分析这部电影:《流浪地球2》是一部中国科幻大片,特效震撼,剧情感人,但节奏偏慢,时长偏长。"
)
# review 直接就是 MovieReview 对象,不是dict,不会KeyError
print(review.title) # "流浪地球2"
print(review.rating) # 8(int类型,不是字符串)
print(review.recommendation) # True
for pro in review.pros: # 直接遍历,类型安全
print(f"- {pro}")注意这里几个细节:
MovieReview的类文档字符串("""电影评价的结构化分析结果""")会被传给 LLM,帮助它理解这个模型的用途- 每个字段的
description会被传给 LLM,作为填写这个字段的指引 ge=1, le=10这类约束也会被传给 LLM,告诉它数值范围- 返回的
review是真正的 Python 对象,不是 dict,IDE 有类型提示,不会写错字段名
这就是为什么 pydantic 是 AI 工程化的基础设施:它不只是校验数据,它是 LLM 和结构化代码之间的桥梁。
OpenAI 原生 SDK 也支持这个模式,叫 parse:
python
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
completion = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "user", "content": "下周二下午三点,我和Alice、Bob有个产品评审会议"}
],
response_format=CalendarEvent,
)
event = completion.choices[0].message.parsed
print(event.name) # "产品评审会议"
print(event.date) # "下周二下午三点"(或标准化的日期格式)
print(event.participants) # ["Alice", "Bob"]1.7 pydantic v1 vs v2:不要被旧文档坑了
2023 年 pydantic 发布了 v2 版本,性能大幅提升(底层用 Rust 重写),但语法有变化。网上很多教程还是 v1 写法,混用会出问题。
主要变化:
验证器装饰器
python
# v1 写法(老)
from pydantic import validator
class MyModel(BaseModel):
name: str
@validator("name")
def name_must_not_be_empty(cls, v):
if not v.strip():
raise ValueError("name不能为空")
return v
# v2 写法(新)
from pydantic import field_validator
class MyModel(BaseModel):
name: str
@field_validator("name")
@classmethod
def name_must_not_be_empty(cls, v: str) -> str:
if not v.strip():
raise ValueError("name不能为空")
return vdict() 改成 model_dump()(序列化,即把 pydantic 对象转换成普通字典,便于传输或存储)
python
# v1
data = my_model.dict()
# v2
data = my_model.model_dump()json() 改成 model_dump_json()
python
# v1
json_str = my_model.json()
# v2
json_str = my_model.model_dump_json()判断当前使用的版本:
python
import pydantic
print(pydantic.VERSION) # "2.x.x" 是v2,"1.x.x" 是v1新项目直接用 v2,LangChain 0.1 之后也全面切换到 pydantic v2。遇到旧代码报奇怪的错,先看版本。
1.8 总结
LLM 的输出天然不稳定。同样的 prompt,不同的温度参数、不同的模型版本、不同的上下文,输出格式可能不一样。没有结构化约束,代码迟早崩在某个边缘情况上,而且崩的方式是 KeyError 或 TypeError 这种难以追踪的运行时错误。
用了 pydantic 之后,数据在进入系统时就被验证,不合格的在入口拦截,合格的已经是类型安全的对象。加上 with_structured_output 这类工具,LLM 的输出和代码之间有了清晰的契约。
pydantic 是 AI 工程化的基础设施,是第一个要装的依赖包。
1.9 pydantic 在 LangChain 和 FastAPI 中无处不在
理解 pydantic 不只是为了做数据校验,更重要的是理解它是整个 Python AI 生态的基础设施。
LangChain 中的 pydantic
LangChain 几乎所有组件都是 pydantic BaseModel 的子类:
python
from langchain_core.tools import BaseTool
from pydantic import BaseModel, Field
# 方式一:用 @tool 装饰器(内部也是用 pydantic 处理参数)
from langchain_core.tools import tool
@tool
def search(query: str) -> str:
"""搜索网页。"""
...
# 方式二:继承 BaseTool(完全控制,BaseTool 是 BaseModel 的子类)
class CustomSearchTool(BaseTool):
name: str = "custom_search"
description: str = "自定义搜索工具"
# pydantic 字段可以定义工具的配置
max_results: int = Field(default=5, description="最大结果数")
def _run(self, query: str) -> str:
return f"搜索结果: {query}"
# LangChain 的结构化输出:LLM 直接输出 pydantic 对象
from langchain_openai import ChatOpenAI
class AnalysisResult(BaseModel):
"""分析结果的结构"""
summary: str = Field(description="摘要,不超过100字")
sentiment: str = Field(description="情感:正面/负面/中性")
confidence: float = Field(ge=0.0, le=1.0, description="置信度")
llm = ChatOpenAI(model="gpt-4o")
structured_llm = llm.with_structured_output(AnalysisResult)
# 直接返回 pydantic 对象,不是 dict,不会有 KeyError
result = structured_llm.invoke("分析:今天天气真好,心情很愉快。")
print(result.summary) # str,有类型
print(result.sentiment) # str,有类型
print(result.confidence) # float,有类型FastAPI 中的 pydantic
FastAPI 的整个请求/响应系统都建立在 pydantic 上:
python
from fastapi import FastAPI
from pydantic import BaseModel, Field
from typing import Literal
app = FastAPI()
# 请求体:FastAPI 自动验证 JSON 是否符合 pydantic 模型
class ChatRequest(BaseModel):
message: str = Field(min_length=1, max_length=4000, description="用户消息")
model: Literal["gpt-4o", "gpt-4o-mini"] = "gpt-4o-mini"
temperature: float = Field(default=0.7, ge=0.0, le=2.0)
session_id: str | None = None # 可选字段
# 响应体:FastAPI 自动序列化 pydantic 对象为 JSON
class ChatResponse(BaseModel):
reply: str
model_used: str
tokens: int
session_id: str | None = None
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest) -> ChatResponse:
# request.message 已经通过了 pydantic 验证
# 如果客户端发来的 message 为空或超长,FastAPI 在这里之前就返回 422 错误
reply = await call_llm(request.message, model=request.model)
return ChatResponse(
reply=reply,
model_used=request.model,
tokens=len(reply), # 简化计算
session_id=request.session_id,
)1.10 与 Java Bean Validation 的完整对比
pydantic 和 Java Bean Validation(JSR 380,即 javax.validation / jakarta.validation)在目标上相同,但能力差异显著:
| 特性 | Java Bean Validation | pydantic v2 |
|---|---|---|
| 基本约束 | @NotNull, @Size, @Min, @Max |
Field(min_length=1), ge=0, le=100 |
| 自定义约束 | @Constraint + ConstraintValidator |
@field_validator 或 @model_validator |
| 类型转换 | 不转换,传错类型直接报错 | 自动转换("42" -> 42) |
| 嵌套验证 | @Valid 注解触发 |
自动递归验证 |
| 错误收集 | ConstraintViolation 集合 |
ValidationError(含所有错误) |
| 序列化 | 需要 Jackson/Gson,独立配置 | 内置 model_dump(), model_dump_json() |
| LLM 集成 | 无 | 原生支持(with_structured_output) |
| 性能 | 中等 | 快(v2 底层用 Rust) |
代码等价对比:
java
// Java Bean Validation
@Data
public class ProductAnalysis {
@NotBlank
private String productName;
@DecimalMin("0.0") @DecimalMax("1.0")
private Double sentimentScore;
@Size(max = 5)
private List<String> keywords;
}
python
# pydantic(更简洁,且支持自动类型转换)
class ProductAnalysis(BaseModel):
product_name: str = Field(min_length=1)
sentiment_score: float = Field(ge=0.0, le=1.0)
keywords: list[str] = Field(default_factory=list, max_length=5)
# pydantic 额外优势:可以接受 {"product_name": "iPhone", "sentiment_score": "0.9"}
# 自动把 "0.9"(字符串)转换成 0.9(float),Java Bean Validation 做不到这个1.11 小结
| 使用场景 | pydantic 的作用 | 对应 Java 概念 |
|---|---|---|
| 定义 LLM 结构化输出格式 | 字段描述传给 LLM,结果自动校验 | 无直接对应 |
| FastAPI 请求/响应校验 | 自动验证,422 错误自动返回 | @Valid + Spring MVC |
| LangChain 工具参数定义 | 生成 JSON Schema 给 LLM | 无直接对应 |
| 配置管理(pydantic-settings) | 类型安全读取环境变量 | @Value + @ConfigurationProperties |
| 处理外部数据(API/文件) | 类型转换 + 校验,统一入口 | DTO + @Valid |
LLM 的输出天然不稳定。同样的 prompt,不同的温度参数、不同的模型版本、不同的上下文,输出格式可能不一样。没有结构化约束,代码迟早崩在某个边缘情况上,而且崩的方式是 KeyError 或 TypeError 这种难以追踪的运行时错误。
用了 pydantic 之后,数据在进入系统时就被验证,不合格的在入口拦截,合格的已经是类型安全的对象。加上 with_structured_output 这类工具,LLM 的输出和代码之间有了清晰的契约。