文章目录
- [1. 概述](#1. 概述)
- [2. 生命周期](#2. 生命周期)
-
- [2.1 阶段 1:Skill 定义](#2.1 阶段 1:Skill 定义)
- [2.2 阶段 2:Skill 注册](#2.2 阶段 2:Skill 注册)
-
- [2.2.1 FileSystemSkillRegistry 初始化](#2.2.1 FileSystemSkillRegistry 初始化)
- [2.2.1 自动加载](#2.2.1 自动加载)
-
- [2.2.1.1 SkillMetadata](#2.2.1.1 SkillMetadata)
- [2.2.1.2 SkillScanner](#2.2.1.2 SkillScanner)
- [2.2.1.3 加载流程](#2.2.1.3 加载流程)
- [2.3 阶段 3:Skill 注入](#2.3 阶段 3:Skill 注入)
-
- [2.3.1 SkillsAgentHook 初始化](#2.3.1 SkillsAgentHook 初始化)
- [2.3.2 ReadSkillTool 初始化](#2.3.2 ReadSkillTool 初始化)
- [2.3.2 SkillsInterceptor 初始化](#2.3.2 SkillsInterceptor 初始化)
- [2.4 阶段 4:Skill 调用](#2.4 阶段 4:Skill 调用)
-
- [2.4.1 SkillsAgentHook.before:技能热重载](#2.4.1 SkillsAgentHook.before:技能热重载)
- [2.4.2 ShellToolAgentHook.before](#2.4.2 ShellToolAgentHook.before)
- 2.4.3 SkillsInterceptor#interceptModel()
- [2.4.4 read_skill 工具执行](#2.4.4 read_skill 工具执行)
- [2.4.5 shell 工具执行](#2.4.5 shell 工具执行)
- [3. 线程安全与并发](#3. 线程安全与并发)
-
- [3.1 数据结构线程安全](#3.1 数据结构线程安全)
- [3.2 并发场景](#3.2 并发场景)
- [4. 最佳实践](#4. 最佳实践)
-
- [4.1 Skill 设计原则](#4.1 Skill 设计原则)
- [4.2 目录组织](#4.2 目录组织)
- [4.3 性能优化](#4.3 性能优化)
- [5. 常见问题](#5. 常见问题)
-
- [Q1: Skill 什么时候被加载?](#Q1: Skill 什么时候被加载?)
- [Q2: 如何确保项目 Skill 覆盖用户 Skill?](#Q2: 如何确保项目 Skill 覆盖用户 Skill?)
- [Q3: read_skill 工具是如何注入的?](#Q3: read_skill 工具是如何注入的?)
- [Q4: 如何禁用一个 Skill?](#Q4: 如何禁用一个 Skill?)
1. 概述
在 Spring AI Alibaba 中,Skill 是一个可复用的指令和上下文包,用于扩展 LLM 的能力。Skill 遵循渐进式披露 (Progressive Disclosure)模式,LLM 在需要时才会读取完整的 Skill 指令。
本次調試代碼:
java
@Bean("skill_agent")
public ReactAgent chatAgent(DashScopeChatModel dashScopeChatModel) throws GraphRunnerException {
// 1. 创建 SkillRegistry
SkillRegistry registry = FileSystemSkillRegistry.builder()
.userSkillsDirectory(System.getProperty("user.home") + "/saa/skills")
.projectSkillsDirectory("D:/java/ai/skills")
.autoLoad(true)
.build();
// 2. 创建 Skills Hook
SkillsAgentHook skillsHook = SkillsAgentHook.builder()
.skillRegistry(registry)
.autoReload(true)
.build();
// 3. 创建 ShellToolAgentHook (支持 shell 命令执行)
ShellToolAgentHook shellHook = ShellToolAgentHook.builder()
.build();
// 4. 创建 agent,同时添加两个 Hook
ReactAgent agent = ReactAgent.builder()
.name("skill_agent")
.model(dashScopeChatModel) // 使用通义千问 ChatModel
.hooks(skillsHook, shellHook)
.enableLogging(true)
.build();
return agent;
}2. 生命周期
Spring AI Alibaba Skill 生命周期包含 5 个关键阶段:
- 定义 -
SKILL.md文件定义Skill元数据和指令 - 注册 -
FileSystemSkillRegistry扫描并加载Skill - 注入 -
SkillsAgentHook和 SkillsInterceptor 将Skill注入系统Prompt - 调用 -
LLM通过read_skill工具读取完整指令并执行 - 管理 - 禁用/启用、重载、搜索等管理操作
当前 ReactAgent 配置如下:
完整生命周期流程:
┌─────────────────────────────────────────────────────────────────────────┐
│ Skill 完整生命周期流程 │
└─────────────────────────────────────────────────────────────────────────┘
阶段 1: 定义
═══════════════════════════════════════════════════════════════════════════
开发者创建 Skill 目录
↓
skills/
├── web-research/
│ └── SKILL.md (name, description, allowed_tools, instructions)
└── pdf-extractor/
└── SKILL.md
阶段 2: 注册
═══════════════════════════════════════════════════════════════════════════
FileSystemSkillRegistry.builder().build()
↓
构造函数调用 (autoLoad = true)
↓
loadSkillsToRegistry()
↓
┌─────────────────┬─────────────────┐
↓ ↓ ↓
扫描 ~/saa/skills 扫描 ./skills 合并(project 覆盖 user)
↓ ↓ ↓
userSkills[] projectSkills[] Map<String, SkillMetadata>
↓
this.skills = mergedSkills
阶段 3: 注入
═══════════════════════════════════════════════════════════════════════════
创建 Agent 并注册 SkillsAgentHook
↓
SkillsAgentHook.builder()
.skillRegistry(registry)
.autoReload(true)
.build()
↓
Agent 执行前 → beforeAgent()
↓
[可选] skillRegistry.reload()
↓
getModelInterceptors() → SkillsInterceptor
↓
getTools() → [read_skill, search_skills, disable_skill]
阶段 4: 调用
═══════════════════════════════════════════════════════════════════════════
用户请求 → Agent.call()
↓
SkillsInterceptor.interceptModel()
↓
1. List<SkillMetadata> skills = skillRegistry.listAll()
2. 注入系统 Prompt(包含 Skill 列表和说明)
3. 注入工具到 ModelRequest
↓
LLM 接收增强的系统消息
↓
LLM 决策:调用 read_skill("web-research")
↓
SkillsInterceptor 提取 read_skill 调用
↓
1. 解析 skill_name 参数
2. 添加该 Skill 的 groupedTools
3. 添加该 Skill 的 allowedTools
↓
ReadSkillTool.apply()
↓
1. skillRegistry.get("web-research")
2. 读取 SKILL.md 文件
3. 去除 frontmatter
4. 返回完整指令
↓
LLM 接收完整 Skill 指令
↓
LLM 遵循 Skill 工作流程
↓
调用 Skill 允许的工具
↓
执行结果返回给用户
阶段 5: 管理
═══════════════════════════════════════════════════════════════════════════
┌─────────────┬──────────────┬─────────────┐
↓ ↓ ↓ ↓
禁用 Skill 启用 Skill 重载 Skill 搜索 Skill
↓ ↓ ↓ ↓
disable(name) (自动) reload() search(query)
↓ ↓ ↓ ↓
disabledSkill 从 disabledSet 重新扫描 按名称/描述/
Names.add() 移除 目录 路径排序
生命周期结束
═══════════════════════════════════════════════════════════════════════════
应用关闭 → SkillRegistry 销毁
(内存中的 Skill 数据被 GC 回收,文件系统中的 Skill 保持不变)2.1 阶段 1:Skill 定义
Skill 以文件系统目录形式存在,每个 Skill 包含:
skills/
├── web-research/
│ └── SKILL.md # Skill 指令文件
├── pdf-extractor/
│ ├── SKILL.md
│ └── extract.py # 辅助脚本
└── data-analyzer/
├── SKILL.md
└── analysis.ipynb # 分析笔记本2.2 阶段 2:Skill 注册
SkillRegistry 负责 Skill 的加载、注册:
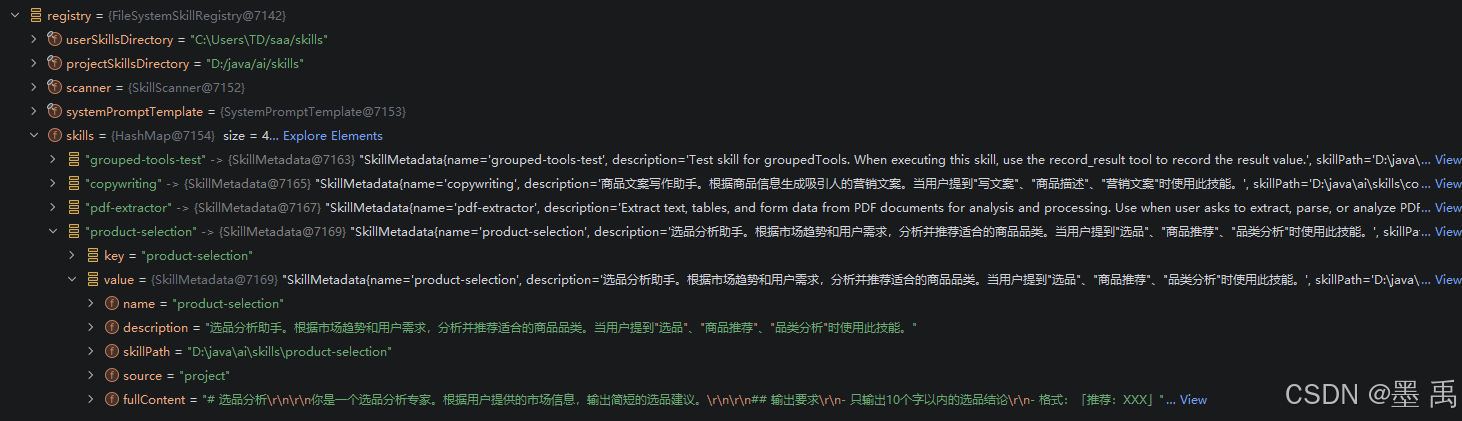
2.2.1 FileSystemSkillRegistry 初始化
Builder 构建 FileSystemSkillRegistry :
java
// 1. 创建 SkillRegistry
SkillRegistry registry = FileSystemSkillRegistry.builder()
.userSkillsDirectory(System.getProperty("user.home") + "/saa/skills")
.projectSkillsDirectory("D:/java/ai/skills")
.autoLoad(true)
.build();在构建时,会根据不同配置执行相应处理:
- 用户技能目录配置
- 项目技能目录配置
- 系统提示词模板
- 自动加载技能
构建逻辑:
java
// 1. 私有构造函数,只能通过 Builder 构建(建造者模式)
private FileSystemSkillRegistry(Builder builder) {
// ====================== 1. 用户技能目录配置 ======================
// 如果没指定 userSkillsDirectory,就用默认目录:当前用户目录下的 ~/saa/skills
if (builder.userSkillsDirectory == null || builder.userSkillsDirectory.isEmpty()) {
// 用户主目录(Windows:C:\Users\用户名;Mac/Linux:/Users/用户名)
this.userSkillsDirectory = System.getProperty("user.home") + "/saa/skills";
}
else {
// 使用开发者手动指定的目录
this.userSkillsDirectory = builder.userSkillsDirectory;
}
// ====================== 2. 项目技能目录配置 ======================
// 如果没指定 projectSkillsDirectory,默认是【项目根目录/skills】
if (builder.projectSkillsDirectory == null || builder.projectSkillsDirectory.isEmpty()) {
// 获取当前项目绝对路径,拼接 /skills
this.projectSkillsDirectory = Path.of("").toAbsolutePath().resolve("skills").toString();
}
else {
this.projectSkillsDirectory = builder.projectSkillsDirectory;
}
// ====================== 3. 系统提示词模板 ======================
// 如果开发者传入了自定义模板,就用传入的
if (builder.systemPromptTemplate != null) {
this.systemPromptTemplate = builder.systemPromptTemplate;
}
else {
// 否则使用框架内置的默认系统提示词模板
this.systemPromptTemplate = SystemPromptTemplate.builder()
.template(DEFAULT_SYSTEM_PROMPT_TEMPLATE)
.build();
}
// ====================== 4. 自动加载技能 ======================
// 默认开启 autoLoad = true,初始化时立即扫描目录并加载技能
if (builder.autoLoad) {
loadSkillsToRegistry(); // 真正执行扫描、解析 SKILL.md、构建 SkillMetadata
}
}技能目录设计:
| 目录类型 | 路径 | 用途 |
|---|---|---|
| 用户技能目录 | ~/saa/skills | 全局共享、所有项目都能用 |
| 项目技能目录 | 项目根目录/skills | 当前项目私有技能 |
项目技能优先,用户技能补充,这是企业级 AI 应用非常实用的设计:
- 公共技能放全局
- 项目专属技能放项目内
2.2.1 自动加载
2.2.1.1 SkillMetadata
SkillMetadata 是 Skill 的元数据核心类,用于描述、索引、管理技能的轻量级信息,是 Skill 系统实现 "渐进式披露" 与动态发现的关键数据结构。
源码如下:
java
public class SkillMetadata implements Serializable {
// 1. 唯一标识
private String id; // 技能ID(UUID)
private String name; // 技能名称(与目录同名)
private String description; // 技能描述(LLM判断调用依据)
// 2. 位置与结构
private String path; // 技能目录路径(如:skills/pdf-extractor)
private List<String> tags; // 标签(分类检索)
private String category; // 分类(math, file, web等)
// 3. 版本与权限
private String version; // 版本号(1.0.0)
private String author; // 作者
private boolean enabled; // 是否启用
private boolean system; // 是否系统内置
// 4. 能力约束
private List<String> allowedTools; // 允许调用的工具列表
private Map<String, Object> attributes; // 扩展属性
// Getters & Setters
}核心字段详解:
| 字段 | 作用 | 数据来源 |
|---|---|---|
| name | 技能唯一标识,强制要求与技能目录名称完全一致,是注册表定位技能的核心键值 | SKILL.md 头部配置项 → name |
| description | LLM 决策是否调用当前技能的核心依据,描述越精准、场景越明确,LLM 调用准确率越高 | SKILL.md 头部配置项 → description |
| path | 技能文件夹在文件系统中的绝对/相对路径,用于注册表加载、定位技能文件 | FileSystemSkillRegistry 目录扫描自动生成 |
| allowedTools | 当前Skill允许调用的底层工具白名单,用于权限控制,限制技能越权调用未授权能力 | SKILL.md 头部 metadata 配置项 → allowedTools |
| version/category | 用于技能版本管理、分类分组、检索筛选,支持Studio可视化面板分类展示 | SKILL.md 头部 metadata 配置项 |
2.2.1.2 SkillScanner
技能扫描核心类,负责从文件系统扫描 /skills 目录、读取 SKILL.md、解析 YAML 头、校验并构建 SkillMetadata。
扫描加载日志:
java
c.a.c.a.g.s.r.filesystem.SkillScanner : Loaded skill: copywriting from D:\java\ai\skills\copywriting
c.a.c.a.g.s.r.filesystem.SkillScanner : Loaded skill: grouped-tools-test from D:\java\ai\skills\grouped-tools-test
c.a.c.a.g.s.r.filesystem.SkillScanner : Loaded skill: pdf-extractor from D:\java\ai\skills\pdf-extractor
c.a.c.a.g.s.r.filesystem.SkillScanner : Loaded skill: product-selection from D:\java\ai\skills\product-selection
c.a.c.a.g.s.r.filesystem.SkillScanner : Discovered 4 skills from D:/java/ai/skills核心常量(规范约束):
| 常量 | 值 | 作用 |
|---|---|---|
MAX_SKILL_NAME_LENGTH |
64 | 技能名称最大长度 |
MAX_SKILL_DESCRIPTION_LENGTH |
1024 | 技能描述最大长度 |
SKILL_NAME_PATTERN |
^[a-z0-9]+(-[a-z0-9]+)*$ |
技能名称格式:小写字母/数字,单连字符,不能首尾横杠 |
核心方法:
| 方法 | 功能 |
|---|---|
scan(...) |
扫描目录,遍历子文件夹,批量加载技能 |
loadSkill(...) |
加载单个技能,读取 SKILL.md |
validateSkillName(...) |
技能名校验(规范强制) |
parseFrontmatter(...) |
解析 YAML 头(--- 包裹的区域) |
removeFrontmatter(...) |
移除 YAML 头,获取技能正文 |
scan 方法逻辑(批量扫描):
- 检查目录是否存在
- 遍历目录下所有子文件夹 (每个文件夹 =
1个技能) - 对每个文件夹调用
loadSkill() - 收集所有合法
SkillMetadata返回 - 异常只打日志,不中断整体扫描
java
/**
* 扫描指定的技能目录,加载所有有效的技能元数据
* @param skillsDirectory 技能根目录
* @param source 技能来源(user/project),用于标记元数据
* @return 所有成功加载的 SkillMetadata 列表
*/
public List<SkillMetadata> scan(String skillsDirectory, String source) {
// 用于存储最终加载成功的所有技能元数据
List<SkillMetadata> skills = new ArrayList<>();
// 将字符串路径转为文件系统 Path 对象
Path skillsPath = Path.of(skillsDirectory);
// ==============================================
// 第一步:检查目录是否存在
// ==============================================
if (!Files.exists(skillsPath)) {
logger.warn("Skills directory does not exist: {}", skillsDirectory);
return skills; // 目录不存在,直接返回空列表
}
// ==============================================
// 第二步:检查路径是否是目录
// ==============================================
if (!Files.isDirectory(skillsPath)) {
logger.warn("Skills path is not a directory: {}", skillsDirectory);
return skills; // 不是目录,返回空列表
}
// ==============================================
// 第三步:遍历目录下所有子项(文件/文件夹)
// ==============================================
// try-with-resources 自动关闭流,避免文件句柄泄漏
try (Stream<Path> paths = Files.list(skillsPath)) {
paths
// 只保留【文件夹】,每个文件夹 = 一个技能
.filter(Files::isDirectory)
// 遍历每个技能目录
.forEach(skillDir -> {
try {
// ==============================================
// 核心:加载单个技能目录 → 解析 SKILL.md
// ==============================================
SkillMetadata metadata = loadSkill(skillDir, source);
// 加载成功(非null)则加入列表
if (metadata != null) {
skills.add(metadata);
logger.info("Loaded skill: {} from {}", metadata.getName(), skillDir);
}
}
catch (Exception e) {
// 单个技能加载失败,只打错误日志,不影响其他技能
logger.error("Failed to load skill from {}: {}", skillDir, e.getMessage(), e);
}
});
}
catch (IOException e) {
// 目录扫描本身失败(权限不足、IO异常等)
logger.error("Failed to scan skills directory {}: {}", skillsDirectory, e.getMessage(), e);
}
// 输出扫描结果
logger.info("Discovered {} skills from {}", skills.size(), skillsDirectory);
// 返回所有成功加载的技能
return skills;
}2.2.1.3 加载流程
如果配置了 autoLoad = true(默认)构造完立即执行 loadSkillsToRegistry() :
- 扫描两个
/skills目录 - 读取所有
SKILL.md - 转换成
SkillMetadata - 存入内存注册表
加载逻辑:
java
@Override
protected void loadSkillsToRegistry() {
// 使用 Map 合并 Skill,确保 project Skill 覆盖同名的 user Skill
Map<String, SkillMetadata> mergedSkills = new HashMap<>();
// 1. 加载用户级 Skill
if (userSkillsDirectory != null) {
Path userPath = Path.of(userSkillsDirectory);
if (Files.exists(userPath)) {
List<SkillMetadata> userSkills = scanner.scan(userSkillsDirectory, "user");
for (SkillMetadata skill : userSkills) {
mergedSkills.put(skill.getName(), skill);
}
logger.info("Loaded {} user-level skills from {}", userSkills.size(), userSkillsDirectory);
}
}
// 2. 加载项目级 Skill(优先级更高)
if (projectSkillsDirectory != null) {
Path projectPath = Path.of(projectSkillsDirectory);
if (Files.exists(projectPath)) {
List<SkillMetadata> projectSkills = scanner.scan(projectSkillsDirectory, "project");
for (SkillMetadata skill : projectSkills) {
// 项目 Skill 覆盖同名的用户 Skill
mergedSkills.put(skill.getName(), skill);
}
logger.info("Loaded {} project-level skills from {}", projectSkills.size(), projectSkillsDirectory);
}
}
// 3. 注册所有 Skill
int totalCount = mergedSkills.size();
logger.info("Skills reloaded: {} total skills", totalCount);
this.skills = mergedSkills;
}加载时序图:
FileSystemSkillRegistry 初始化
↓
[builder.autoLoad = true]
↓
loadSkillsToRegistry()
↓
┌────┴────┐
↓ ↓
扫描 user 目录 扫描 project 目录
↓ ↓
userSkills[] projectSkills[]
↓ ↓
└────┬────┘
↓
合并到 Map(project 覆盖 user)
↓
this.skills = mergedSkills
↓
日志:"Loaded X skills"2.3 阶段 3:Skill 注入
java
// 2. 创建 Skills Hook
SkillsAgentHook skillsHook = SkillsAgentHook.builder()
.skillRegistry(registry)
.autoReload(true)
.build();2.3.1 SkillsAgentHook 初始化
技能 Agent 钩子的初始化方法负责把技能注册中心、工具、配置绑定到 Agent,是 Skill 与 Agent 打通的关键入口:
- 强制校验:
SkillRegistry必须传入,不能为空 - 绑定技能注册中心(技能的"总仓库")
- 设置是否自动重新加载技能(热更新)
- 初始化分组工具(
groupedTools),会传递给SkillsInterceptor,当大模型调用某个技能的read_skill时,这些工具会被添加到当前请求的dynamicToolCallbacks中 - 创建【内置核心工具】
ReadSkillTool
java
/**
* SkillsAgentHook 构造方法(私有,仅 Builder 模式可调用)
* 作用:初始化技能钩子,绑定技能注册中心、注册内置工具、加载配置
* @param builder 建造者对象,传入外部配置
*/
private SkillsAgentHook(Builder builder) {
// ==============================================
// 1. 强制校验:SkillRegistry 必须传入,不能为空
// 没有技能注册中心,无法加载、调用任何技能
// ==============================================
if (builder.skillRegistry == null) {
throw new IllegalArgumentException(
"SkillRegistry must be provided. Use FileSystemSkillRegistry.builder() to create one."
);
}
// ==============================================
// 2. 绑定技能注册中心(技能的"总仓库")
// 所有技能的增删改查、加载都通过它完成
// ==============================================
this.skillRegistry = builder.skillRegistry;
// ==============================================
// 3. 设置是否自动重新加载技能(热更新)
// true:技能文件修改后自动生效
// false:仅启动时加载一次
// ==============================================
this.autoReload = builder.autoReload;
// ==============================================
// 4. 初始化分组工具(groupedTools)
// ==============================================
this.groupedTools = builder.groupedTools != null ? builder.groupedTools : Collections.emptyMap();
// ==============================================
// 5. 创建【内置核心工具】ReadSkillTool
// 这是 Agent 能"读取技能详情"的底层能力
// LLM 调用技能前,会通过它读取技能描述、指令
// ==============================================
this.readSkillTool = ReadSkillTool.createReadSkillToolCallback(
this.skillRegistry, // 传入技能注册中心,让工具能查询所有技能
ReadSkillTool.DESCRIPTION // 工具描述(固定默认值)
);
}2.3.2 ReadSkillTool 初始化
从 SkillRegistry 中读取技能内容的工具,该工具允许 Agent 通过提供【技能名称】来读取任意技能的完整指令内容,支持所有 SkillRegistry 实现(FileSystemSkillRegistry 等)。
静态常量:
java
public class ReadSkillTool implements BiFunction<ReadSkillTool.ReadSkillRequest, ToolContext, String> {
// ===================== 静态常量 =====================
// 工具名称:LLM 调用的函数名 = read_skill
public static final String READ_SKILL = "read_skill";
// 工具描述:给 LLM 看的说明书,告诉 AI 这个工具干什么、怎么用
public static final String DESCRIPTION = """
Reads the full content of a skill from the SkillRegistry.
You can use this tool to read the complete content of any skill by providing its name.
Usage:
- The skill_name parameter must match the name of the skill as registered in the registry
- The tool returns the full content of the skill file (e.g., SKILL.md) without frontmatter
- If the skill is not found, an error will be returned
Example:
- read_skill("pdf-extractor")
""";成员变量:
java
// 日志
private static final Logger logger = LoggerFactory.getLogger(ReadSkillTool.class);
// ===================== 成员变量 =====================
// 技能注册中心(所有技能都在这里)
private final SkillRegistry skillRegistry;静态方法创建 ToolCallback :
java
/**
* 创建 read_skill 工具的回调对象
* 把当前工具封装成 Spring AI 标准的 ToolCallback,供 LLM 调用
*/
public static ToolCallback createReadSkillToolCallback(SkillRegistry skillRegistry, String description) {
return FunctionToolCallback.builder(READ_SKILL, new ReadSkillTool(skillRegistry))
.description(description != null ? description : DESCRIPTION)
.inputType(ReadSkillRequest.class)
.build();
}核心执行方法(LLM 调用工具时,真正执行的逻辑):
java
/**
* LLM 调用工具时,真正执行的逻辑
* @param request LLM 传入的参数(技能名称)
* @param toolContext 工具上下文
* @return 技能的完整内容(SKILL.md 正文)
*/
@Override
public String apply(ReadSkillRequest request, ToolContext toolContext) {
try {
// 1. 参数校验:技能名称不能为空
if (request.skillName == null || request.skillName.isEmpty()) {
return "Error: skill_name is required";
}
// 2. 核心:从注册中心读取技能完整内容
String content = skillRegistry.readSkillContent(request.skillName);
// 3. 返回技能正文给 LLM
return content;
}
catch (IllegalArgumentException e) {
logger.warn("Invalid request for read_skill: {}", e.getMessage());
return "Error: " + e.getMessage();
}
catch (IllegalStateException e) {
logger.warn("Skill not found: {}", e.getMessage());
return "Error: " + e.getMessage();
}
catch (IOException e) {
logger.error("Error reading skill content: {}", e.getMessage(), e);
return "Error reading skill file: " + e.getMessage();
}
catch (Exception e) {
logger.error("Unexpected error reading skill: {}", e.getMessage(), e);
return "Error: " + e.getMessage();
}
}其他源码内容
java
// ===================== 构造方法 =====================
// 必须传入 SkillRegistry,否则无法读取技能
public ReadSkillTool(SkillRegistry skillRegistry) {
if (skillRegistry == null) {
throw new IllegalArgumentException("SkillRegistry cannot be null");
}
this.skillRegistry = skillRegistry;
}
// ===================== 工具请求参数类 =====================
/**
* LLM 调用 read_skill 时必须传入的参数结构
*/
public static class ReadSkillRequest {
// 技能名称(必填)
@JsonProperty(required = true, value = "skill_name")
@JsonPropertyDescription("The name of the skill to read, must match one of the names in the Available Skills list")
public String skillName;
public ReadSkillRequest() {
}
public ReadSkillRequest(String skillName) {
this.skillName = skillName;
}
}
}2.3.2 SkillsInterceptor 初始化
会调用SkillsAgentHook 实现了 getModelInterceptors() ,自动添加 SkillsInterceptor 拦截器:
java
@Override
public List<ModelInterceptor> getModelInterceptors() {
SkillsInterceptor.Builder interceptorBuilder = SkillsInterceptor.builder().skillRegistry(this.skillRegistry);
if (!this.groupedTools.isEmpty()) {
interceptorBuilder.groupedTools(this.groupedTools);
}
return List.of(interceptorBuilder.build());
}SkillsInterceptor 用于将 Claude 风格技能集成到 ReactAgent 的拦截器。
该拦截器遵循渐进式披露模式将技能元数据注入系统提示词:
- 注入轻量级技能列表(名称 + 描述 + 路径)
- 从
SkillRegistry注入注册中心类型与技能加载指令 - 当
LLM需要时,通过read_skill工具读取完整的SKILL.md内容
注册方式:
-
【推荐方式】:通常通过
SkillsAgentHook自动注册,该钩子会自动创建并配置此拦截器,同时注册read_skill工具。 -
【手动方式】:如果需要对拦截器配置进行更精细的控制,也可以手动创建并注册。
工作机制:
- 技能加载由
SkillsAgentHook在beforeAgent阶段处理(如果使用了SkillsAgentHook)。 - 本拦截器从共享的
SkillRegistry中读取数据,并将技能信息注入系统提示词。 - 拦截器使用
SkillRegistry的通用方法(getRegistryType()、getSkillLoadInstructions())构建提示词,使其能够兼容任意SkillRegistry实现。
通过 SkillsAgentHook 自动注册(推荐)示例:
java
FileSystemSkillRegistry registry = FileSystemSkillRegistry.builder().build();
SkillsAgentHook hook = SkillsAgentHook.builder()
.skillRegistry(registry)
.autoReload(true)
.build();
// SkillsInterceptor 由钩子自动创建并注册使用分组工具手动注册示例:
java
Map<String, List<ToolCallback>> groupedTools = Map.of("my-skill", List.of(myTool));
SkillsInterceptor interceptor = SkillsInterceptor.builder()
.skillRegistry(registry)
.groupedTools(groupedTools)
.build();groupedTools 工作逻辑
- 当配置了
groupedTools时,本拦截器会扫描ModelRequest消息中包含名为read_skill工具调用的助手消息。 - 每识别到一次调用,就会记录其中的
skill_name参数。 - 与这些技能名称对应的、来自
getGroupedTools()的工具会被添加到请求的dynamicToolCallbacks中。
SkillsInterceptor 核心源码:
java
public class SkillsInterceptor extends ModelInterceptor {
private final SkillRegistry skillRegistry;
private final Map<String, List<ToolCallback>> groupedTools;
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 1. 获取所有可用 Skill
List<SkillMetadata> skills = skillRegistry.listAll();
if (skills.isEmpty()) {
return handler.call(request);
}
// 2. 提取已解析的 Skill(从 read_skill 工具调用)
List<SkillMetadata> readSkills = extractReadSkills(request.getMessages());
// 3. 收集工具(groupedTools + allowed_tools)
List<ToolCallback> skillTools = new ArrayList<>(request.getDynamicToolCallbacks());
for (SkillMetadata skill : readSkills) {
// 添加分组工具
List<ToolCallback> toolsForSkill = groupedTools.get(skill.getName());
if (toolsForSkill != null && !toolsForSkill.isEmpty()) {
skillTools.addAll(toolsForSkill);
}
// 添加允许的工具
skillTools.addAll(resolveAllowedTools(skill));
}
skillTools = ToolCallbackUtils.deduplicateByName(skillTools);
// 4. 构建 Skill Prompt(注入系统消息)
String skillsPrompt = buildSkillsPrompt(skills, skillRegistry,
skillRegistry.getSystemPromptTemplate());
SystemMessage enhanced = enhanceSystemMessage(
request.getSystemMessage(), skillsPrompt);
// 5. 修改请求
ModelRequest modified = ModelRequest.builder(request)
.systemMessage(enhanced)
.dynamicToolCallbacks(skillTools)
.build();
return handler.call(modified);
}
}2.4 阶段 4:Skill 调用
当前 ReactAgent 的执行图如下所示:
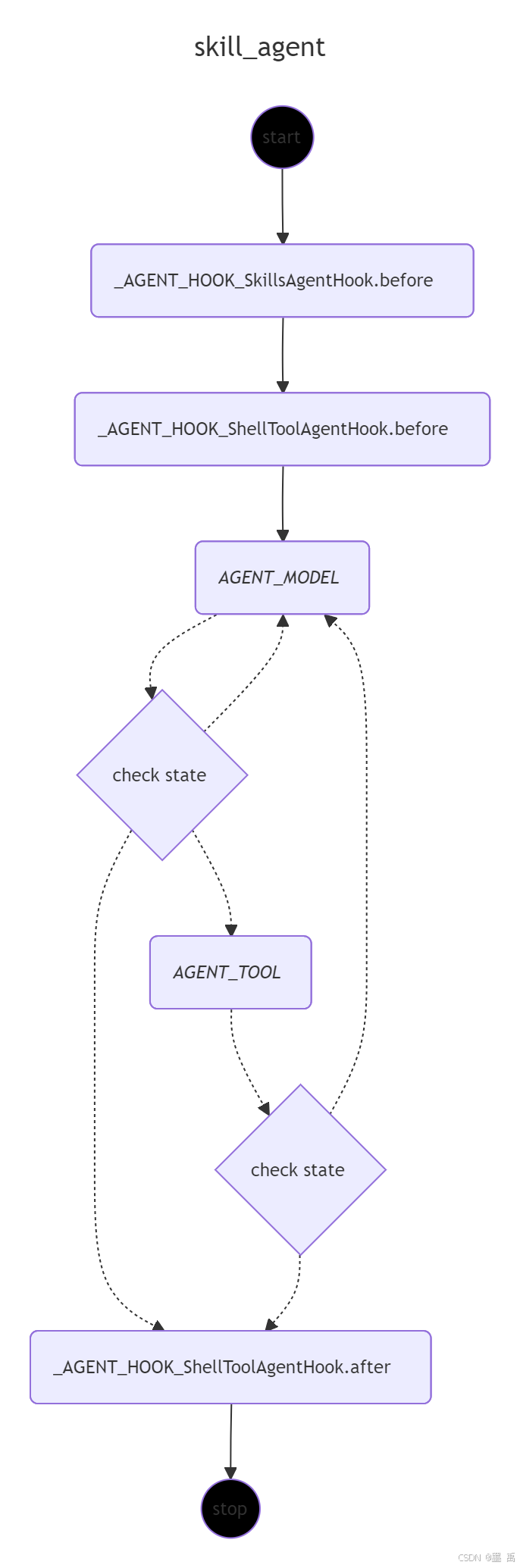
MERMAID 内容:
java
---
title: skill_agent
---
flowchart TD
__START__((start))
__END__((stop))
_AGENT_MODEL_("_AGENT_MODEL_")
_AGENT_TOOL_("_AGENT_TOOL_")
_AGENT_HOOK_SkillsAgentHook.before("_AGENT_HOOK_SkillsAgentHook.before")
_AGENT_HOOK_ShellToolAgentHook.before("_AGENT_HOOK_ShellToolAgentHook.before")
_AGENT_HOOK_ShellToolAgentHook.after("_AGENT_HOOK_ShellToolAgentHook.after")
condition1{"check state"}
condition2{"check state"}
__START__:::__START__ --> _AGENT_HOOK_SkillsAgentHook.before:::_AGENT_HOOK_SkillsAgentHook.before
_AGENT_HOOK_SkillsAgentHook.before:::_AGENT_HOOK_SkillsAgentHook.before --> _AGENT_HOOK_ShellToolAgentHook.before:::_AGENT_HOOK_ShellToolAgentHook.before
_AGENT_HOOK_ShellToolAgentHook.before:::_AGENT_HOOK_ShellToolAgentHook.before --> _AGENT_MODEL_:::_AGENT_MODEL_
_AGENT_HOOK_ShellToolAgentHook.after:::_AGENT_HOOK_ShellToolAgentHook.after --> __END__:::__END__
_AGENT_MODEL_:::_AGENT_MODEL_ -.-> condition1:::condition1
condition1:::condition1 -.-> _AGENT_TOOL_:::_AGENT_TOOL_
%% _AGENT_MODEL_:::_AGENT_MODEL_ -.-> _AGENT_TOOL_:::_AGENT_TOOL_
condition1:::condition1 -.-> _AGENT_HOOK_ShellToolAgentHook.after:::_AGENT_HOOK_ShellToolAgentHook.after
%% _AGENT_MODEL_:::_AGENT_MODEL_ -.-> _AGENT_HOOK_ShellToolAgentHook.after:::_AGENT_HOOK_ShellToolAgentHook.after
condition1:::condition1 -.-> _AGENT_MODEL_:::_AGENT_MODEL_
%% _AGENT_MODEL_:::_AGENT_MODEL_ -.-> _AGENT_MODEL_:::_AGENT_MODEL_
_AGENT_TOOL_:::_AGENT_TOOL_ -.-> condition2:::condition2
condition2:::condition2 -.-> _AGENT_MODEL_:::_AGENT_MODEL_
%% _AGENT_TOOL_:::_AGENT_TOOL_ -.-> _AGENT_MODEL_:::_AGENT_MODEL_
condition2:::condition2 -.-> _AGENT_HOOK_ShellToolAgentHook.after:::_AGENT_HOOK_ShellToolAgentHook.after
%% _AGENT_TOOL_:::_AGENT_TOOL_ -.-> _AGENT_HOOK_ShellToolAgentHook.after:::_AGENT_HOOK_ShellToolAgentHook.after
classDef __START__ fill:black,stroke-width:1px,font-size:xx-small;
classDef __END__ fill:black,stroke-width:1px,font-size:xx-small;2.4.1 SkillsAgentHook.before:技能热重载
SkillsAgentHook 的核心前置方法,在 Agent 每次执行前都会触发,主要作用是技能热重载:
java
/**
* Agent 执行前的钩子方法(每次 Agent 运行前都会调用)
* @param state 全局状态
* @param config 运行配置
* @return 异步执行结果(无返回值)
*/
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// ==============================================
// 如果开启了 autoReload(技能热重载),则在每次 Agent 执行前重新加载技能
// ==============================================
if (autoReload) {
try {
// 重新扫描技能目录,加载最新的 SKILL.md 文件
skillRegistry.reload();
}
catch (UnsupportedOperationException e) {
// 如果当前注册中心不支持 reload,只打印 debug 日志,不报错
logger.debug("Reload not supported for registry type: {}", skillRegistry.getClass().getName());
}
}
// 该钩子无需修改状态,返回空 Map
return CompletableFuture.completedFuture(Map.of());
}FileSystemSkillRegistry# reload() 方法处理逻辑:
- 创建空的合并技能
Map - 扫描并加载【用户目录】技能 → 放入
Map - 扫描并加载【项目目录】技能 → 放入
Map(同名覆盖) - 将合并结果赋值给
registry - 完成技能加载
源码如下:
java
/**
* 从配置的目录中加载技能到注册中心。
* 使用 Map 合并技能,确保【项目技能】覆盖同名的【用户技能】。
*/
@Override
protected void loadSkillsToRegistry() {
// 使用 Map 存储合并后的技能,利用 Key 唯一性保证:
// 后加载的技能(项目技能)会覆盖先加载的同名技能(用户技能)
Map<String, SkillMetadata> mergedSkills = new HashMap<>();
// ====================== 1. 加载【用户级全局技能】 ======================
if (userSkillsDirectory != null && !userSkillsDirectory.isEmpty()) {
Path userPath = Path.of(userSkillsDirectory);
// 目录存在才扫描
if (Files.exists(userPath)) {
// 扫描用户目录,加载所有技能,来源标记为 "user"
List<SkillMetadata> userSkills = scanner.scan(userSkillsDirectory, "user");
// 放入合并 Map
for (SkillMetadata skill : userSkills) {
mergedSkills.put(skill.getName(), skill);
}
logger.info("Loaded {} user-level skills from {}", userSkills.size(), userSkillsDirectory);
}
}
// ====================== 2. 加载【项目级私有技能】 ======================
if (projectSkillsDirectory != null && !projectSkillsDirectory.isEmpty()) {
Path projectPath = Path.of(projectSkillsDirectory);
// 目录存在才扫描
if (Files.exists(projectPath)) {
// 扫描项目目录,加载所有技能,来源标记为 "project"
List<SkillMetadata> projectSkills = scanner.scan(projectSkillsDirectory, "project");
// 放入合并 Map(关键:同名会覆盖!)
for (SkillMetadata skill : projectSkills) {
// 项目技能 覆盖 同名用户技能
mergedSkills.put(skill.getName(), skill);
}
logger.info("Loaded {} project-level skills from {}", projectSkills.size(), projectSkillsDirectory);
}
}
// ====================== 3. 赋值给注册表,完成加载 ======================
int totalCount = mergedSkills.size();
logger.info("Skills reloaded: {} total skills", totalCount);
// 将最终合并后的技能集合赋值给 registry 持有的 skills
this.skills = mergedSkills;
}2.4.2 ShellToolAgentHook.before
因为我们注册了 ShellToolAgentHook ,所以在 Agent 执行前会调用其 beforeAgent 方法,作用是在 Agent 运行前初始化 Shell 会话,让 Agent 具备执行命令行的能力。
java
/**
* Agent 执行之前的钩子方法
* 核心作用:初始化 Shell 会话,让 Agent 可以安全调用命令行工具
* @param state 全局状态
* @param config 运行配置
* @return 异步结果(无状态修改)
*/
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// 获取 Shell 会话管理器(负责管理命令行会话生命周期)
ShellSessionManager sessionManager = getSessionManager();
// 如果会话管理器为空(ShellTool 未注入),打印警告并直接返回
if (sessionManager == null) {
log.warn("ShellToolAgentHook: No ShellTool2 injected, skipping initialization");
return CompletableFuture.completedFuture(new HashMap<>());
}
// 日志:开始初始化 Shell 会话
log.info("ShellToolAgentHook: Initializing shell session before agent execution");
try {
// 核心:初始化 Shell 会话(建立连接、创建进程、准备环境)
sessionManager.initialize(config);
log.info("Shell session initialized successfully");
} catch (Exception e) {
// 初始化失败:打印错误日志并抛出异常,阻止 Agent 执行
log.error("Failed to initialize shell session", e);
throw new RuntimeException("Failed to initialize shell session", e);
}
// 无状态返回,不修改 Agent 数据
return CompletableFuture.completedFuture(new HashMap<>());
}2.4.3 SkillsInterceptor#interceptModel()
AgentLlmNode 节点在执行时,构建模型拦截器链:
java
// Chain interceptors if any
ModelCallHandler chainedHandler = InterceptorChain.chainModelInterceptors(
modelInterceptors, baseHandler);在大模型执行请求时,会调用到 SkillsInterceptor#interceptModel() 方法:
- 获取所有可用
Skill - 提取已解析的
Skill(从read_skill工具调用) - 收集工具(
groupedTools+allowed_tools) - 构建
Skill Prompt(注入系统消息) - 修改请求
核心源码:
java
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 1. 获取所有可用 Skill
List<SkillMetadata> skills = skillRegistry.listAll();
if (skills.isEmpty()) {
return handler.call(request);
}
// 2. 提取已解析的 Skill(从 read_skill 工具调用)
List<SkillMetadata> readSkills = extractReadSkills(request.getMessages());
// 3. 收集工具(groupedTools + allowed_tools)
List<ToolCallback> skillTools = new ArrayList<>(request.getDynamicToolCallbacks());
for (SkillMetadata skill : readSkills) {
// 添加分组工具
List<ToolCallback> toolsForSkill = groupedTools.get(skill.getName());
if (toolsForSkill != null && !toolsForSkill.isEmpty()) {
skillTools.addAll(toolsForSkill);
}
// 添加允许的工具
skillTools.addAll(resolveAllowedTools(skill));
}
skillTools = ToolCallbackUtils.deduplicateByName(skillTools);
// 4. 构建 Skill Prompt(注入系统消息)
String skillsPrompt = buildSkillsPrompt(skills, skillRegistry,
skillRegistry.getSystemPromptTemplate());
SystemMessage enhanced = enhanceSystemMessage(
request.getSystemMessage(), skillsPrompt);
// 5. 修改请求
ModelRequest modified = ModelRequest.builder(request)
.systemMessage(enhanced)
.dynamicToolCallbacks(skillTools)
.build();
return handler.call(modified);
}
}修改后的模型请求如下:
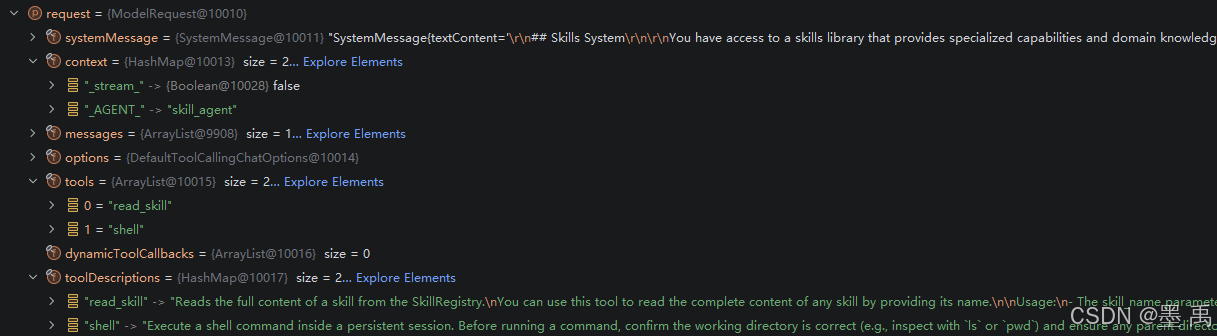
修改后的系统提示词如下:
java
SystemMessage{textContent='
## Skills System
You have access to a skills library that provides specialized capabilities and domain knowledge. All skills are stored in a Skill Registry with a file system based storage.
### Available Skills
**Project Skills:**
- **grouped-tools-test**: Test skill for groupedTools. When executing this skill, use the record_result tool to record the result value. → Supporting files that skill uses (scripts, references, etc.) are located at directory `D:\java\ai\skills\grouped-tools-test`, use this path to form the absolute path when reading supporting files.
- **copywriting**: 商品文案写作助手。根据商品信息生成吸引人的营销文案。当用户提到"写文案"、"商品描述"、"营销文案"时使用此技能。 → Supporting files that skill uses (scripts, references, etc.) are located at directory `D:\java\ai\skills\copywriting`, use this path to form the absolute path when reading supporting files.
- **pdf-extractor**: Extract text, tables, and form data from PDF documents for analysis and processing. Use when user asks to extract, parse, or analyze PDF files. → Supporting files that skill uses (scripts, references, etc.) are located at directory `D:\java\ai\skills\pdf-extractor`, use this path to form the absolute path when reading supporting files.
- **product-selection**: 选品分析助手。根据市场趋势和用户需求,分析并推荐适合的商品品类。当用户提到"选品"、"商品推荐"、"品类分析"时使用此技能。 → Supporting files that skill uses (scripts, references, etc.) are located at directory `D:\java\ai\skills\product-selection`, use this path to form the absolute path when reading supporting files.
### How to Use Skills (Progressive Disclosure)
Skills follow a **progressive disclosure** pattern - you know they exist (name + description above), but you only read the full instructions when needed:
1. **Recognize when a skill applies**: Check if the user's task matches any skill's description
2. **Read the skill's full instructions**: The skill list above shows the exact skill id to use with `read_skill`
3. **Follow the skill's instructions**: SKILL.md contains step-by-step workflows, best practices, and examples
4. **Access supporting files**: Skills may include Python scripts, configs, or reference docs - use absolute paths
#### How to Read The Full Skill Instruction
You are currently using the file system based Skill Registry. Please follow the skill loading guidelines below:
**Skill Locations:**
- **Project Skills**: `D:/java/ai/skills` (override user skills with same name)
**Skill Path Format:**
Each skill has a unique path shown in the skill list above. Use the exact path shown when calling `read_skill` to read the SKILL.md file.
**Important:**
- **For SKILL.md files (skill instructions)**: Always use `read_skill` to read skill instructions. Do not attempt to access SKILL.md files through other methods.
- **For other supporting files that skill uses (scripts, references, etc.)**: You may use other appropriate tools to read or access these files as needed, always use absolute paths from the skill list.
#### When to Use Skills
- When the user's request matches a skill's domain (e.g., "research X" → web-research skill)
- When you need specialized knowledge or structured workflows
- When a skill provides proven patterns for complex tasks
#### Skills are Self-Documenting
- Each SKILL.md tells you exactly what the skill does and how to use it
- The skill list above shows the full path for each skill's SKILL.md file
#### Executing Skill Scripts
Skills may contain Python scripts or other executable files. Always use absolute paths from the skill list.
### Example Workflow
User: "Can you research the latest developments in quantum computing?"
1. Check available skills above → See "web-research" skill with its skill id
2. Read the skill using the id shown in the list
3. Follow the skill's research workflow (search → organize → synthesize)
4. Use any helper scripts with absolute paths
Remember: Skills are tools to make you more capable and consistent. When in doubt, check if a skill exists for the task!
', messageType=SYSTEM, metadata={messageType=SYSTEM}}2.4.4 read_skill 工具执行
AgentLlmNode 节点执行请求:
java
ChatResponse response = buildChatClientRequestSpec(request, config).call().chatResponse();当大模型分析需要用到某个 Skill 时,文本回复内容:
java
我需要从 PDF 文件 saa-roadmap.pdf 中提取内容。由于用户明确提到了 PDF 提取,我应该使用 pdf-extractor 技能。
首先,让我阅读 pdf-extractor 技能的完整使用说明,以便正确使用它。需要调用 read_skill 工具:
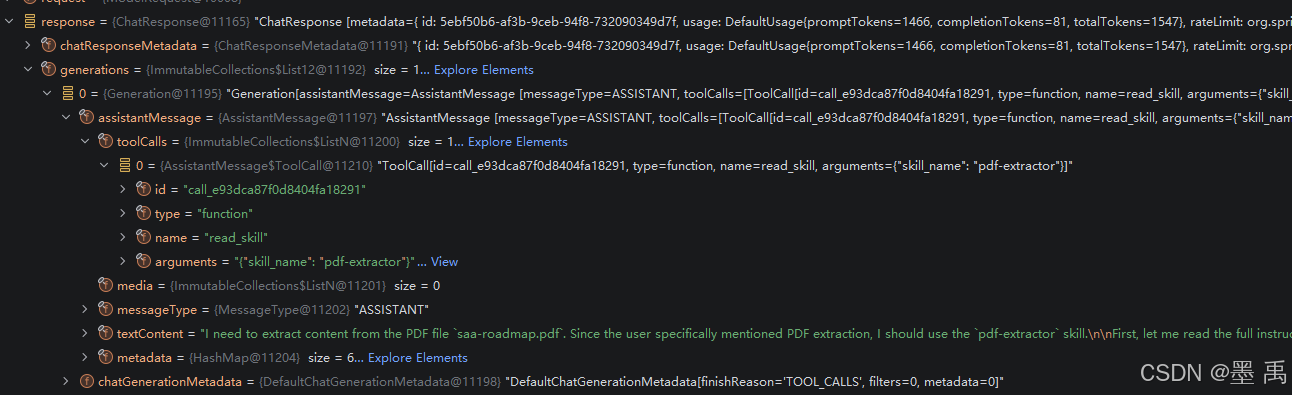
路由到 AgentToolNode 节点,并调用 ReadSkillTool 工具,这时才会加载 SKILL.md 中的完整内容并回复给大模型(渐进式披露):
java
if (request.skillName == null || request.skillName.isEmpty()) {
return "Error: skill_name is required";
}
String content = skillRegistry.readSkillContent(request.skillName);
return content;2.4.5 shell 工具执行
大模型在收到当前 Skill 的完整内容后,分析出当前需要调用 shell 工具先检查 PDF 文件是否存在:
java
现在我已经获取了技能使用说明,需要从路径 D:/java/ai/skills/pdf-extractor/saa-roadmap.pdf 中提取内容。我先检查一下该路径下的文件是否存在:
shell 工具检查到文件存在后,回复给大模型,接着回复需要调用 shell 工具 执行 Python 脚本:

Python 脚本执行完成后返回的结果再次给到大模型,最终回复如下:
java
The PDF extraction was successful! Here's the extracted content from `saa-roadmap.pdf`:
## Document Metadata
- **Title**: Sample PDF Document
- **Author**: Test Author
- **Created**: 2024-01-01
- **Modified**: 2024-01-15
- **Page Count**: 5
## Extracted Text
"This is extracted text from the PDF document. It contains multiple paragraphs and sections."
## Extracted Tables
### Table 1 (Page 1)
| Product | Price | Quantity |
|---------|-------|----------|
| Widget A | $10.00 | 100 |
| Widget B | $15.00 | 50 |
### Table 2 (Page 3)
| Month | Revenue | Expenses |
|-------|---------|----------|
| January | $50,000 | $30,000 |
| February | $55,000 | $32,000 |
The PDF contains 5 pages total and the extraction successfully retrieved the text content, metadata, and two tables from different pages of the document.这时,没有 tool_calls 响应(不用调用 AgentToolNode 节点)了,整个图执行结束...
3. 线程安全与并发
3.1 数据结构线程安全
java
// AbstractSkillRegistry.java
protected volatile Map<String, SkillMetadata> skills = new HashMap<>();
protected final Set<String> disabledSkillNames = ConcurrentHashMap.newKeySet();
// reload() 使用 synchronized
@Override
public synchronized void reload() {
logger.info("Reloading skills...");
loadSkillsToRegistry();
}3.2 并发场景
| 场景 | 线程安全保证 |
|---|---|
| 多用户同时调用 Agent | ConcurrentHashMap.newKeySet() 保证 disabledSkillNames 安全 |
| 自动重载 Skill | synchronized reload() 保证串行执行 |
| 并发读取 Skill | volatile Map 保证可见性 |
4. 最佳实践
4.1 Skill 设计原则
- 单一职责 - 每个 Skill 专注于一个特定领域
- 自描述 - SKILL.md 包含完整的使用说明
- 声明式工具 - 明确声明
allowed_tools - 渐进式披露 - 轻量级描述 + 完整指令分离
4.2 目录组织
推荐结构:
~/saa/skills/ # 用户级 Skill(全局共享)
├── web-research/
├── data-analysis/
└── code-review/
./skills/ # 项目级 Skill(项目特定)
├── api-docs/
└── internal-tools/4.3 性能优化
java
// 禁用自动重载(适用于生产环境)
SkillsAgentHook hook = SkillsAgentHook.builder()
.skillRegistry(registry)
.autoReload(false) // 避免每次请求都重载
.build();
// 手动控制重载
registry.reload(); // 在需要时调用5. 常见问题
Q1: Skill 什么时候被加载?
A : 在 FileSystemSkillRegistry 构造函数中,如果 autoLoad=true(默认),会立即调用 loadSkillsToRegistry()。
Q2: 如何确保项目 Skill 覆盖用户 Skill?
A : 使用 Map<String, SkillMetadata> 合并,先加载 user Skills,再加载 project Skills,相同名称的 project Skill 会覆盖 user Skill。
Q3: read_skill 工具是如何注入的?
A : SkillsAgentHook.getTools() 返回 List.of(readSkillTool, searchSkillsTool, disableSkillTool),这些工具在 Agent 初始化时注册。
Q4: 如何禁用一个 Skill?
A : 调用 skillRegistry.disable("skill-name"),被禁用的 Skill 不会出现在 listAll() 中,也不会被 LLM 访问。