S05 Skills 技能
前面几章我们已经初步解决了任务太复杂,上下文太多导致的 AI 遗忘的问题,那么现在考虑一个新的问题,如果我们需要 AI 帮我们完成一个特定领域的问题呢?
比如某个任务流程正常情况下是 A-B-C-D ,AI 正常情况下就会按照这个流程工作,但是你自己却不想按照这个流程工作,你想让 AI 按照 A-D-C-B-E 的流程工作,那么这个时候你就可以写一个 skill 来仔细描述这个流程,然后发给 AI 做参考,让 AI 明白你的流程是特殊的,必须按照你的流程来。这样就可以了。
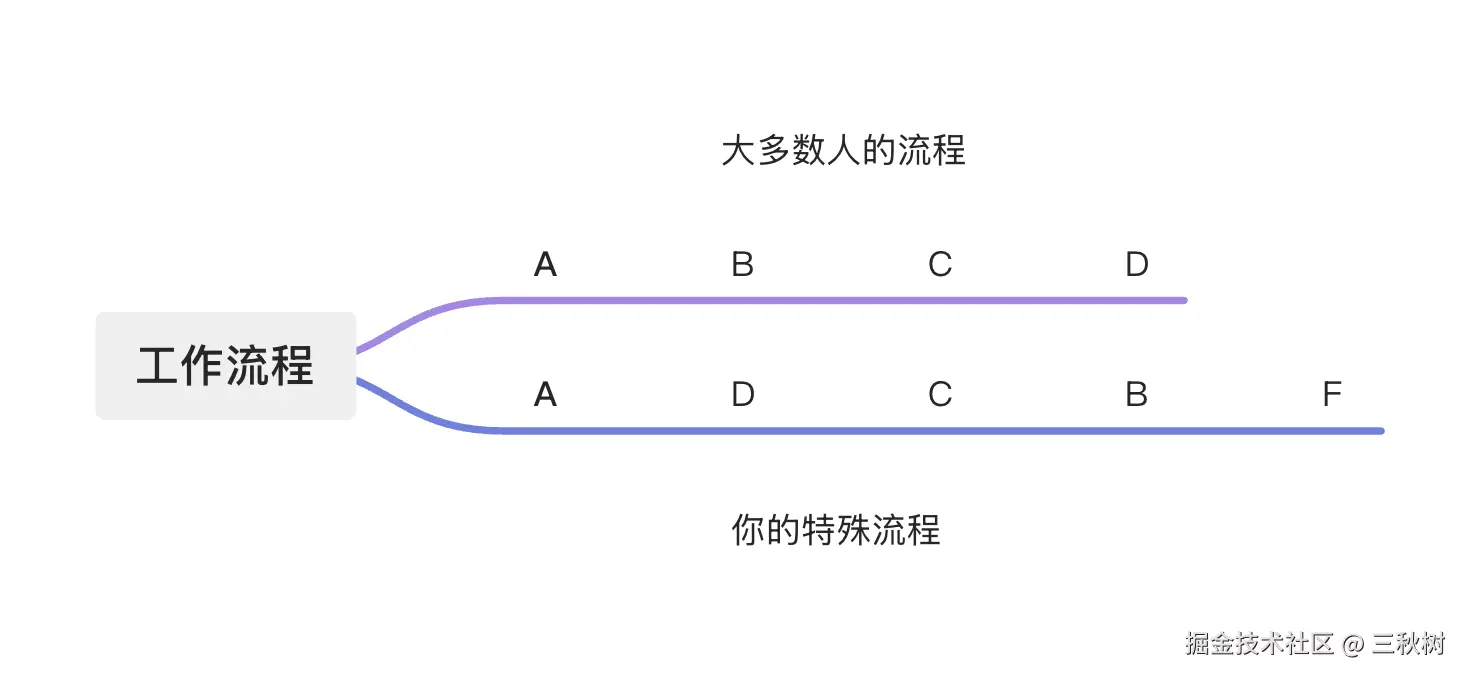
但是这个时候又有一个问题,如果你有 10 个 skill 呢。正常情况下一个 skill 可能有 2000 个 token。如果你有 10 个 skill 那就是 2万个 token。如果你把这些 skill 都放在 system 提示词里,每次跟 AI 沟通都发给 AI ,那么这是对 token 巨大的浪费,而且 AI 也不是每次都能用上这些 skill,可能一次也就用一个两个而已。
所以我们把每个技能总结一下,缩减成每个 skill 几十或者上百个 token 的简单描述。10 个 skill 加起来可能也就上千个 token,这样的话,每次沟通就比把 skill 全给 AI 节约了 20 倍的 token。如果对话轮数很多,那可能就会相差几百万 token 了。

等 AI 想要用那个 skill 了,在把 skill 的全文作为工具调用的结果发给 AI,又可以复用前面写的工具调用的逻辑,又可以节约 token。
这就是懒加载策略:只告诉 AI 我这里有某个技能,一句话总结技能大概的作用是什么,等 AI 说它需要这个技能的时候,我们才把这个技能的完整内容发给 AI。
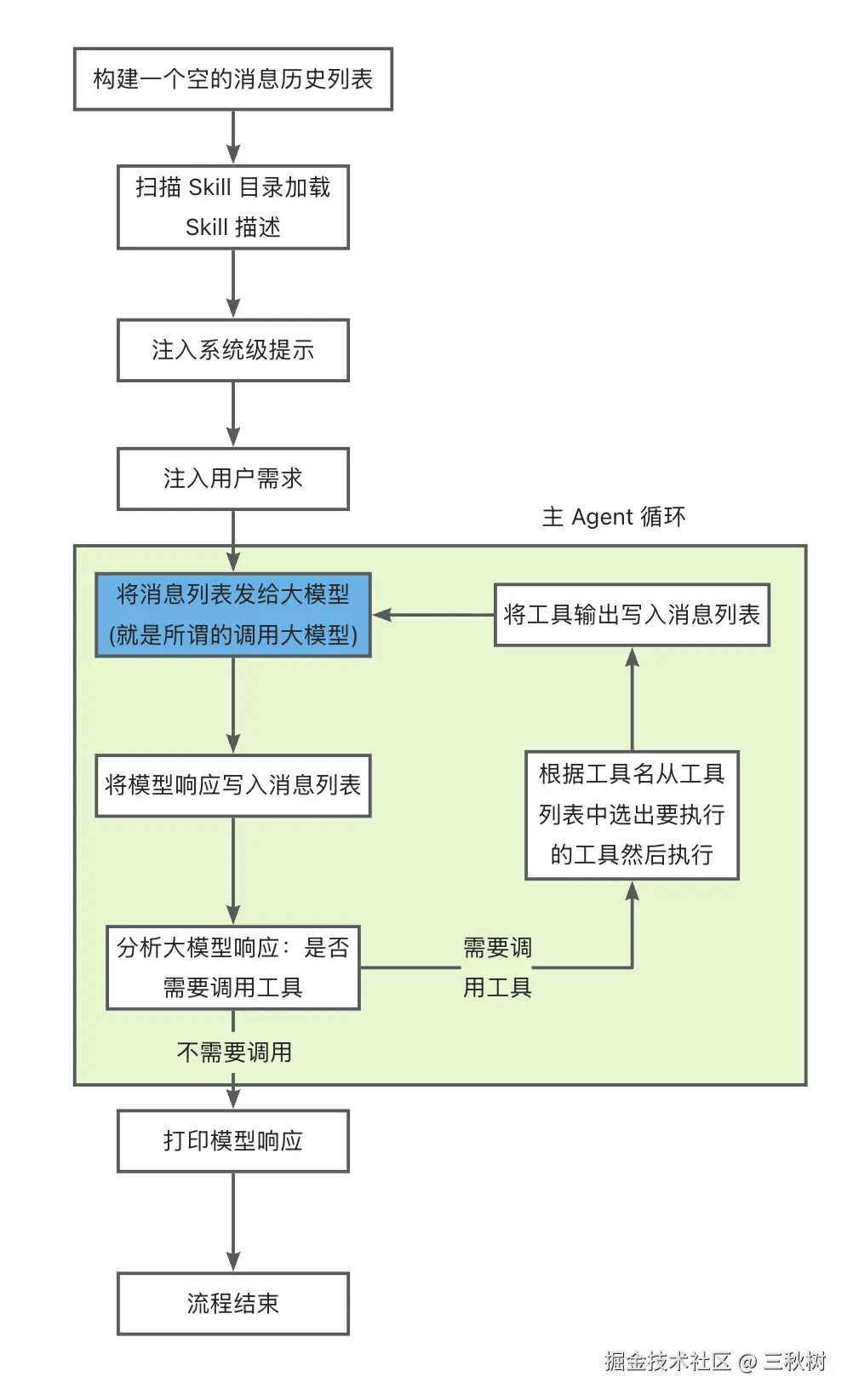
程序流程图
代码
完整的代码放在 gitee 了,请移步查看 gitee.com/sanqiushu/D...
首先看看新加的 SkillLoader 类,目的就是加载我们本地有哪些 Skills。
python
# Skills 目录
# Skills 目录
SKILLS_DIR = WORKDIR / "skills"
class SkillLoader:
def __init__(self, skills_dir: Path):
self.skills_dir = skills_dir
self.skills = {}
self._load_all()当我们新建一个 SkillLoader 类的实例时,只需要将 SKILLS_DIR 放在实例化函数里即可。
然后继续看 SkillLoader 类里面有哪些函数
python
def _load_all(self):
if not self.skills_dir.exists():
return
for f in sorted(self.skills_dir.rglob("SKILL.md")):
text = f.read_text()
meta, body = self._parse_frontmatter(text)
name = meta.get("name", f.parent.name)
self.skills[name] = {"meta": meta, "body": body, "path": str(f)}首先是 _load_all() 函数,这个函数是 init() 函数初始化的时候调用的。也算初始化函数的一部分了。 实际上就是读取 skills 目录,然后将里面所有的 SKILL.md 找出来,然后读取 SKILL.md 里面的内容。 基本上就是读取四个字段:名字 name、元数据 meta、主体 body、skill 的路径。
在继续讲后面的代码之前,有必要先讲讲 Skills 文件夹里的内容。首先是 skills 目录,其实这个目录可以叫任何名字,但是命名为 skills 目录言简意赅,一看就知道这个文件夹是干嘛的。
下面是一个 skills 目录中的基本结构。我这里举例 skills 文件夹中有三个子文件夹 git_skill、front_skill、other_skill 这三个名字即是文件夹的名字,也是对应 skill 的名字。
python
skills
|---git_skill
| |---SKILL.md
|---front_skill
| |---SKILL.md
|---other_skill
| |---SKILL.md然后是每个 SKILL.md 文件的名字。.md 结尾就意味着这是一个 markdown 文件,markdown 文件具体是什么大家问问 AI 即可,非常简单。
markdown
---
description: 这是一个 git skill
tags: git
---
请按照 XXXX 的格式进行 git XXXX
.... 这里写具体的 skill 的内容部分
我在网上找了一个前端设计的 SKILL.md ,具体内容我也放到 gitee 了,可以去下载一份。
OK,md 格式跟纯文本几乎差不多,很简单就能理解,看完 skills 目录和 SKILL.md 的格式,我们就继续看代码吧
前面的 _load_all() 函数中 调用了 _parse_frontmatter() 函数来读取 meta, body 。看看具体是如何读取的:
python
@staticmethod
def _parse_frontmatter(text: str) -> tuple:
"""Parse YAML frontmatter between --- delimiters."""
match = re.match(r"^---\n(.*?)\n---\n(.*)", text, re.DOTALL)
if not match:
return {}, text
meta = {}
for line in match.group(1).strip().splitlines():
if ":" in line:
key, val = line.split(":", 1)
meta[key.strip()] = val.strip()
return meta, match.group(2).strip()非常简单,就是读取 --- 和 --- 中间的文字作为 meta ,后面的作为 body 即可。
然后是两个暂时还没用到的函数,也比较好懂是干嘛的:
python
def get_descriptions(self) -> str:
"""Layer 1: short descriptions for the system prompt."""
if not self.skills:
return "(no skills available)"
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "No description")
tags = skill["meta"].get("tags", "")
line = f" - {name}: {desc}"
if tags:
line += f" [{tags}]"
lines.append(line)
return "\n".join(lines)就是把上面类初始化放到 self.skills 数组里的 skill 都变成 AI 可读的结构,类似于下面的结构,当然我这里写的比较简单,正常情况下这里肯定是具体描述一个真正的 skill 的描述的。
python
- git_skill: 这是一个 git skill [git]
- front_skill: 这是一个前端 skill
- other_skill: 这是一个其他的 skill然后是 get_content() 函数,就是加载 SKILL.md 里最后面的 body 部分的。
python
def get_content(self, name: str) -> str:
"""Layer 2: full skill body returned in tool_result."""
skill = self.skills.get(name)
if not skill:
return f"Error: Unknown skill '{name}'. Available: {', '.join(self.skills.keys())}"
return f"<skill name=\"{name}\">\n{skill['body']}\n</skill>"然后是系统提示词,我发现中文的系统提示词对 AI 来说好像不是很好用,AI 总是忽略我说的一些话,难道是听不懂吗?这里直接用别人文章里的英文版提示词了。
python
SKILL_LOADER = SkillLoader(SKILLS_DIR)
# 系统顶级指令
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Use load_skill to access specialized knowledge before tackling unfamiliar topics.
Skills available:
{SKILL_LOADER.get_descriptions()}"""这段提示词大概的意思就是:
python
SYSTEM = f"""你是工作在 {WORKDIR} 目录下的编程助手。
在处理不熟悉的主题前,请先使用 load_skill 工具来获取相关的专业知识。
可用技能列表:
{SKILL_LOADER.get_descriptions()}"""这是我调试运行中的示例系统提示词: 
下面是新加的 load_skill 工具的描述,BASE_TOOLS 还是以前的 4 个工具没有变化。
python
TOOL_HANDLERS = {
......
"load_skill": lambda **kw: SKILL_LOADER.get_content(kw["name"]),
}
BASE_TOOLS = [......]
TOOLS = BASE_TOOLS + [
{
"type": "function",
"function": {
"name": "load_skill",
"description": "Load specialized knowledge by name.",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Skill name to load"
}
},
"required": ["name"]
}
}
}
]四个基础工具的代码没有变化,然后是主 Agent 循环:
python
# Agent 循环的核心方法
def agent_loop(messages: list):
while True:
response = client.chat.completions.create(model=MODEL, messages=messages, tools=TOOLS, max_tokens=8000)
# 将大模型返回的消息添加到消息列表中
message = response.choices[0].message
messages.append(message.model_dump())
# 如果大模型没有调用工具,那么结束执行
if response.choices[0].finish_reason != "tool_calls":
# 打印 AI 的响应
print(f"\n\033[36mAI: {message.content}\033[0m\n")
return
# 打印 AI 的响应
print(f"\n\033[36mAI: \033[0m\033[36;9m思考: {message.content}\033[0m\n\033[36m回答:{message.reasoning_content} \033[0m\n")
# if message.tool_calls:
for tool_call in message.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
call_id = tool_call.id
# 3. 路由并执行本地函数
handler = TOOL_HANDLERS.get(func_name)
try:
output = handler(**func_args) if handler else f"不存在 {func_name} 工具"
except Exception as e:
output = f"Error: {e}"
print(f"\n\033[33mtools : \n{output}\033[0m\n") # 打印工具的输出
messages.append({"role": "tool", "content": output, "tool_call_id": call_id})也没有什么大变化。
下面直接运行程序看看效果,下面是需求提示词:
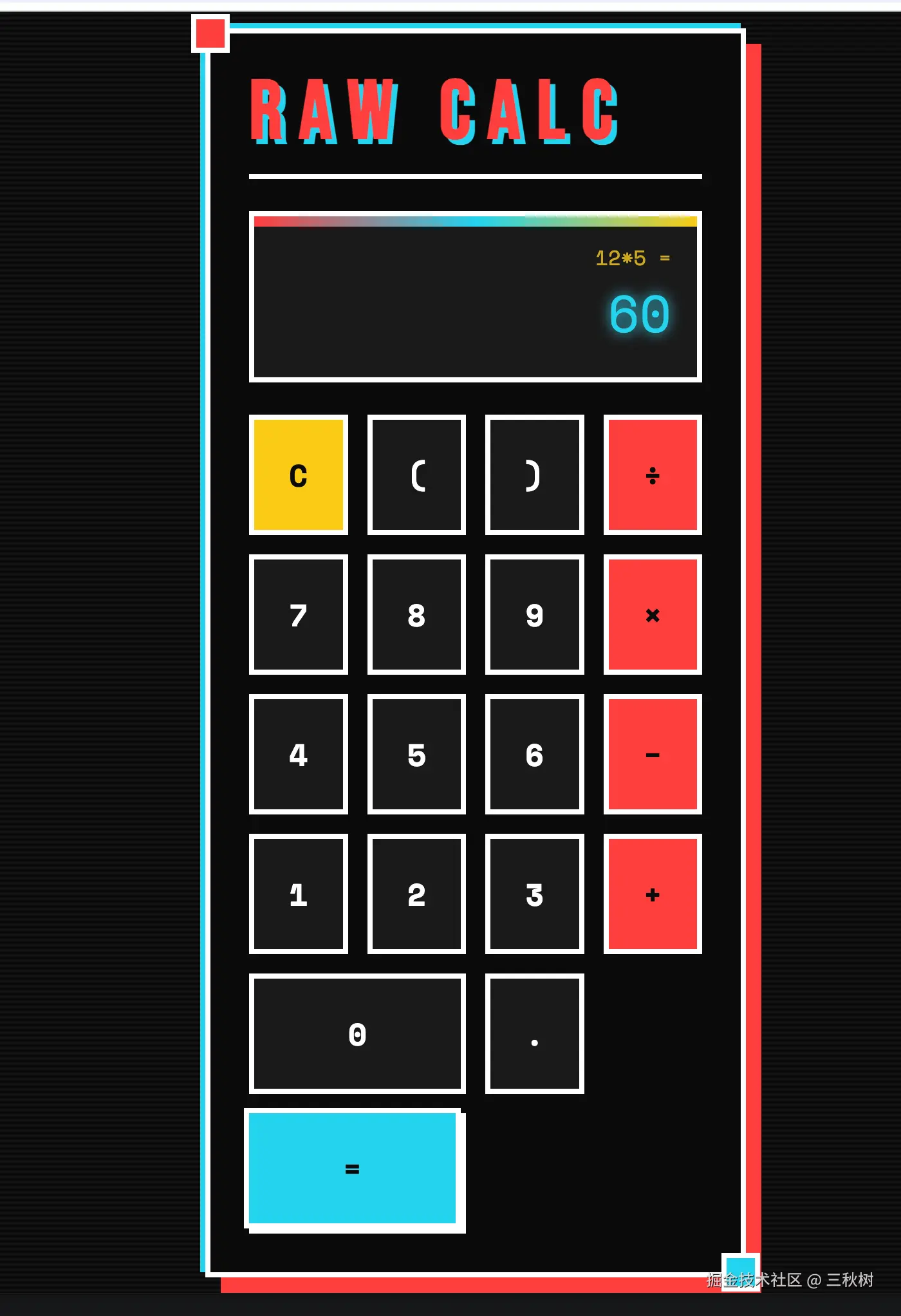
帮我写一个 html 版的计算器程序 calc.html,可以直接鼠标点击数字和加减符号,然后进行计算,并且前端页面设计需要满足 frontend-design 风格。
运行截图:
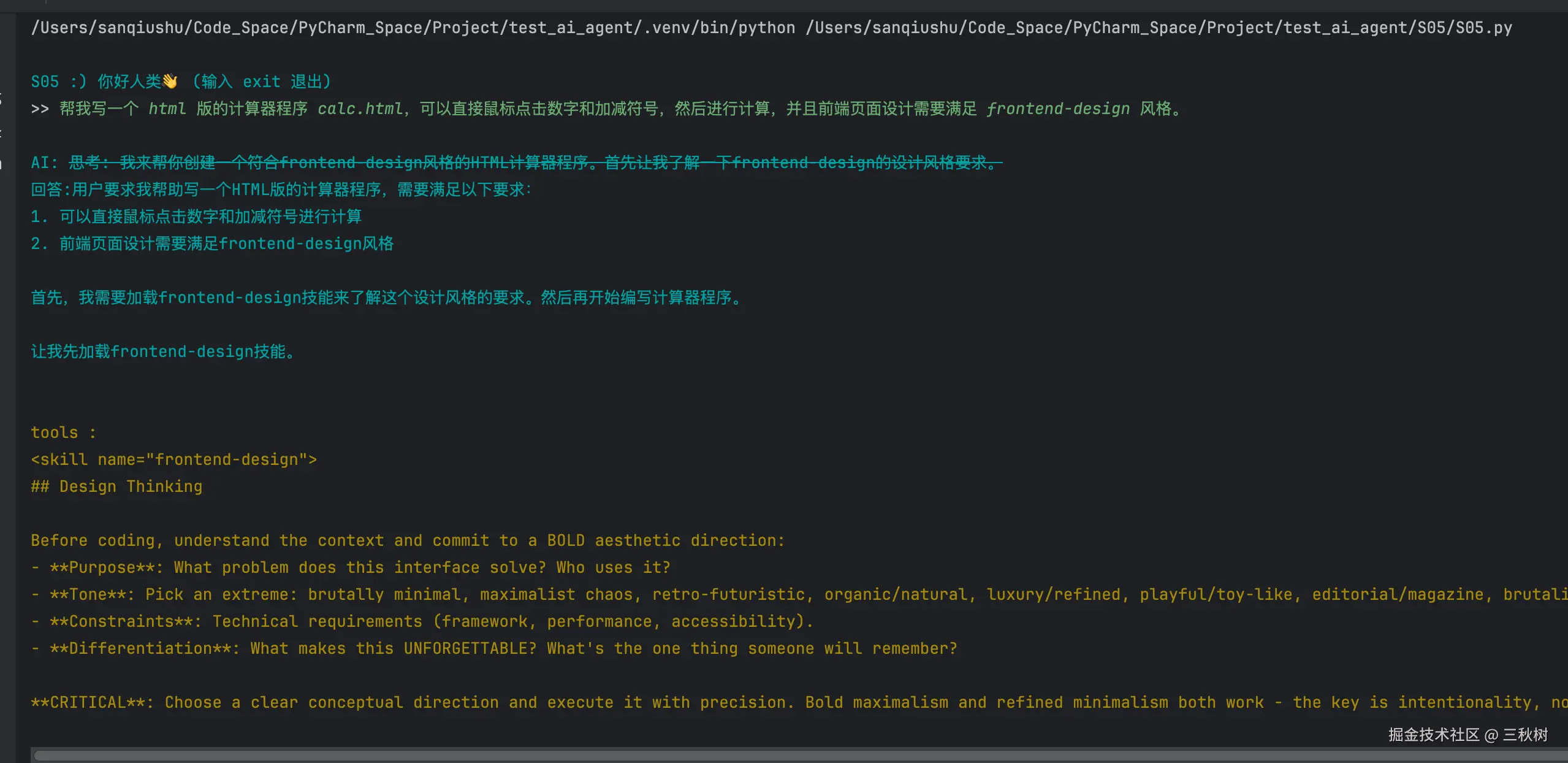
可以通过查看历史消息列表来看到 AI 确实会调用 load_skill 工具去调用 frontend-design 这个 skill 的,而且工具也返回了结果。 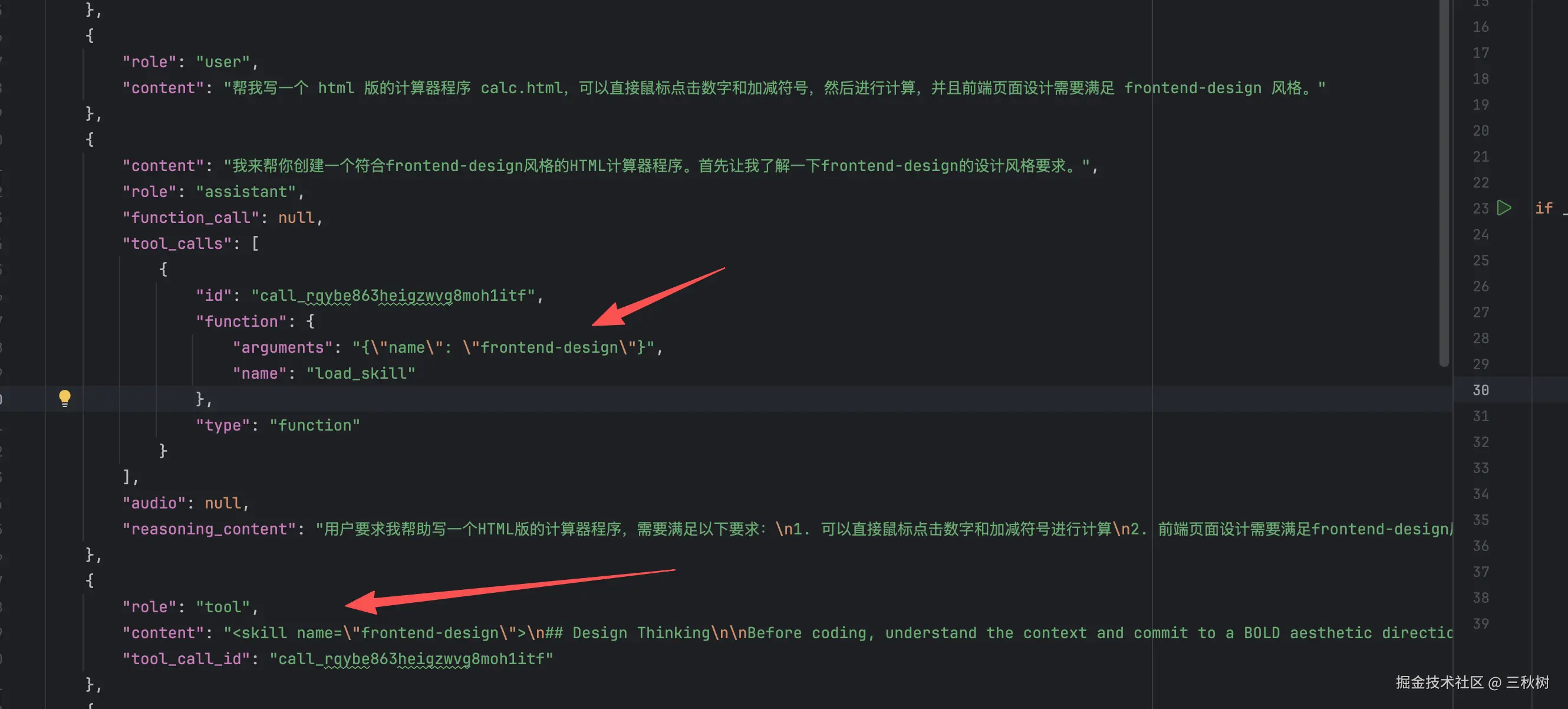
好吧,这个 AI 设计出来的计算器确实可以正常使用,并且界面确实"前卫"、"时尚",但不实用,哈哈哈,我找的这个 skill 还是有点太前卫了。