H2VLR: Heterogeneous Hypergraph Vision-Language Reasoning for Few-Shot Anomaly Detection

论文地址:https://arxiv.org/html/2604.14507v1
项目页面:"论文接收后开源"
学术交流:922230617 或 CV_EDPJ
目录
[1. 引言](#1. 引言)
[3. H₂VLR](#3. H₂VLR)
[3.1 预备知识](#3.1 预备知识)
[3.2 方法概述](#3.2 方法概述)
[3.3 语义诱导与超图建模](#3.3 语义诱导与超图建模)
[3.4 异常的高阶推理](#3.4 异常的高阶推理)
[3.5 优化目标](#3.5 优化目标)
[4. 实验](#4. 实验)
[4.1 设置](#4.1 设置)
[4.2 性能比较](#4.2 性能比较)
[4.3 消融研究](#4.3 消融研究)
1. 引言
为缓解数据稀缺,近期 **少样本异常检测(few-shot anomaly detection,FSAD)**方法越来越多地利用视觉-语言模型(VLM),如 CLIP,其通过大规模预训练提供强大的视觉-语义对齐。
- 通过将视觉特征与正常或异常的文字描述进行匹配,这些方法将异常检测从任务特定训练转向跨模态对应。
- 如图 1(a) 所示,大多数现有方法采用基于提示或 patch 级的相似性匹配,对未见类别具有良好的泛化性。
然而,这些方法本质上依赖于视觉区域与语义概念之间的独立成对匹配。这种假设认为异常可通过局部相似性偏差(deviations)检测,忽略了跨区域的结构依赖和上下文一致性。因此,具有协调或结构偏差特征的细微异常常被忽视。
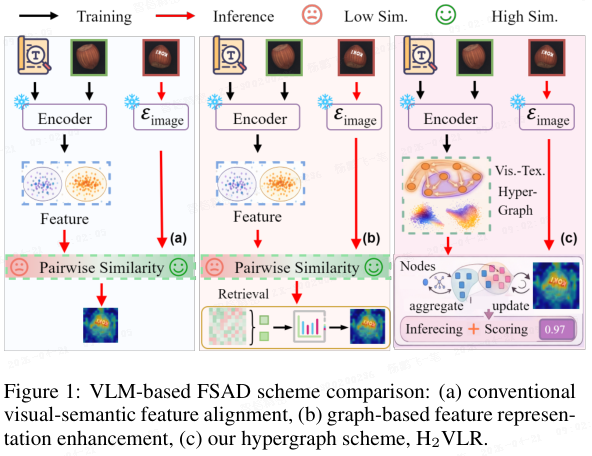
部分近期方法尝试通过基于图的聚合或记忆驱动精炼(refinement)来增强视觉表示,如图 1(b) 所示。
- 尽管这些策略丰富了特征表示,其推理阶段仍依赖独立成对匹配。因此,推理过程仍局限于局部,无法显式建模高阶空间-语义关系。
- 这一局限性使得现有方法在极端数据稀缺下无法充分捕捉全局结构一致性。
为克服这些局限,本文提出异构超图视觉语言推理(Heterogeneous Hypergraph Vision-Language Reasoning,H2VLR)。
- 这是一种基于超图的跨模态推理框架,将少样本异常检测重定义为高阶关系推理问题。
- H₂VLR 不再通过孤立相似度评估异常,而是将视觉区域和语义概念作为异构节点统一建模于超图中,实现跨模态结构的集体推理。
- 通过显式捕捉高阶依赖和全局上下文一致性,H₂VLR 在小样本场景下实现了鲁棒的异常检测与精确定位。
主要贡献如下:
- 超越传统成对匹配,提出 H₂VLR,一种用于小样本异常检测的异质超图视觉-语言推理框架。
- 设计了一组语义诱导与超图建模方案。
- 设计了基于视觉-语义特征超图的高阶关系推理策略,用于图像异常区域的有效检测与定位推理。
3. H₂VLR
3.1 预备知识
不同于局限于成对关系的标准图,本文构建跨模态超图 H=(N,E) 以捕捉统一视觉-语言空间中视觉区域间的高阶依赖。
定义异构节点集 N = N_v∪N_t,其中 N_v 表示 query 视觉 token,N_t 表示提示 embedding。
结构连通性由关联矩阵 H 表示,若节点 n 与超边 e 关联则 H_{n,e) = 1。
3.2 方法概述
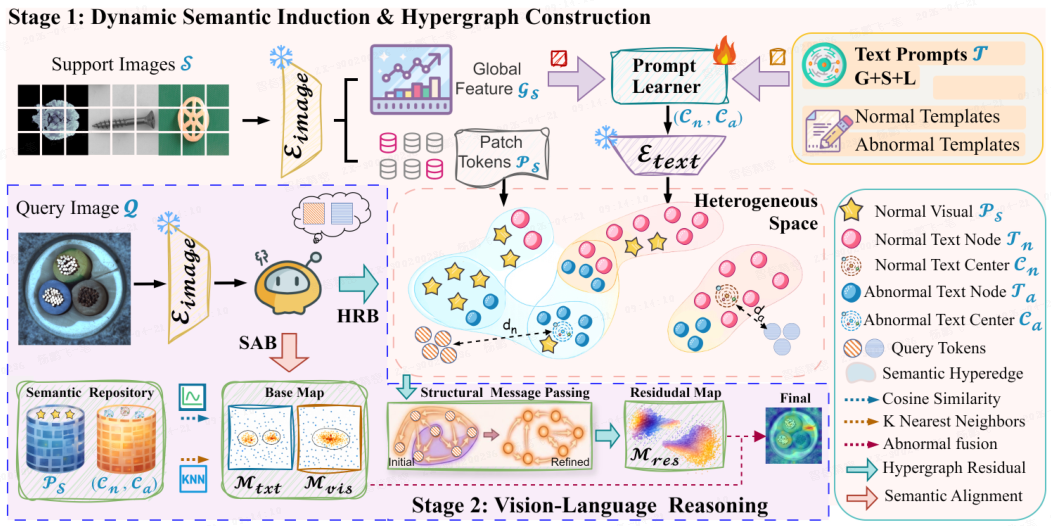
如上图所示,H₂VLR 不依赖独立的图像-文本相似度估计,而是显式建模自适应文本语义与多尺度视觉结构之间的高阶交互。
- 首先,构建异构语义引导超图,将视觉块和动态生成的文本提示 embedding 共享关系空间,超边编码跨模态与结构依赖。
- 然后应用超图消息传递机制进行语义约束的关系推理,使结构上有意义的偏差被增强,同时抑制不可靠响应。
- 最后,将精炼的关系特征融入异常推理,得到噪声鲁棒的图像级分数和像素级精确定位。
3.3 语义诱导与超图建模
小样本工业检测的主要挑战在于通用视觉-语言先验的表达能力有限,静态文本模板常无法捕捉类别特定的外观变化和异常模式。为此,本文提出动态语义诱导(Dynamic Semantic Induction,DSI),使文本语义以支持图像 S 的视觉统计为条件,产生任务自适应的文本表示。
如上图阶段 1 所示,用视觉编码器 E_image 提取支持集(support set)样本的视觉表示,包含全局特征 G_s 以及一组保留局部结构信息的 patch 级 token P_s。G_s 作为条件信号,使文本提示空间适应当前任务。
为桥接视觉与语言表示,一个可学习映射器将全局支持特征投影为支持感知的上下文 token 序列 C_S = Ψ_θ(G_s)。这些 token 通过逐元素乘法 ⊗ 注入预定义的**全局-特殊-局部(Global--Special--Local,G+S+L )**提示模板集
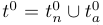
得到类别自适应的文本 embedding:
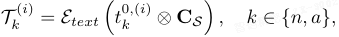
其中,n 表示正常(normal),a 表示异常(anomaly)。E_text 为文本编码器,i 表示同一语义类别内的提示模板编号。
这些诱导提示进一步聚合成正常与异常语义中心 C_k = Avg({T^(i)_k}),形成语义库 R={Tn,Ta,Cn,Ca}。
为规整诱导的语义空间,本文在语义诱导中施加基于间隔的对齐约束。令 sim(⋅,⋅) 为余弦相似度。对第 j 个 patch token p_{s,j} ∈ P_s,要求:
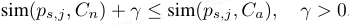
其中 γ 为间隔超参数,将正常视觉模式锚定到正常语义中心,强制其与异常流形分离。
【映射全局视觉特征为语义 token,并融入预定义的提示。通过简单平均找到正常/异常提示的语义中心,并通过约束分离正常/异常语义流形】
基于诱导的语义仓库 R,本文构建跨模态超图 H=(N,E) 以实现高阶关系推理。它在统一视觉-语言空间中对视觉区域的结构和语义依赖进行联合编码。
具体地,定义异构节点集 N。正常与异常语义中心 Cn,Ca 通过聚合相应提示 embedding 计算得到,作为全局语义参考。超图构建于异构节点之上,但超图推理仅在视觉节点上执行以聚合语义上下文证据。
超边集 E 通过双引导策略构建:
1)结构保持超边:每个视觉 patch p_{q,j} 与视觉特征空间中余弦相似度最高的 K 个最近邻相连,强制局部结构一致性。
2)语义引导超边:将视觉 patch 与提示 embedding 相关联。对每个提示节点 T^(i)_k,计算跨模态亲和度
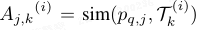
并将 T^(i)_k 与最相关的 K 个 patch 关联,形成高阶语义分组,连接局部视觉模式与支持条件化的语义。
【每个文本关联 K 个视觉 patch,每个视觉 patch 关联 K 个视觉近邻】
超图拓扑由关联矩阵 H ∈ {0,1} 表示,H_{n,e} = 1 表示节点 n 属于超边 e。
- 实现中,语义引导超边通过硬性 top-K 隶属规则实例化:对由 T^(i)_k 索引的语义超边,仅连接对应的 top-K 视觉patch。这产生了紧凑且稳定的关联结构,且不引入额外硬分配矩阵。
- 推理时,消息传递仅限制在 H 诱导的视觉子图中。
- 此外,提示embedding和语义中心仅通过超边构建影响超图推理。
3.4 异常的高阶推理
基于异构关联结构 H 和提示诱导的边权重 θ,设计高阶推理模块,将异常显式地推理为语义-结构一致性的违反,而非传统的 patch 级偏差。
在小样本场景中,局部外观变化常具模糊性,直接基于相似度的决策不可靠。超图推理通过跨语义对齐和结构连贯区域传播异常证据,实现上下文感知的异常推理。
令 X^(0) ∈ R^{|Nv|×d} 为堆叠的 query patch 特征,第 j 行对应视觉节点 p_{q,j}。给定关联矩阵 H,采用遵循节点-超边-节点聚合方案的超图卷积算子。节点度与超边度矩阵定义为:
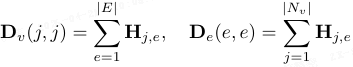
-
节点度 Dv:包含该节点的超边数量。
-
超边度 De:该超边包含的节点数量
第 ℓ 层的消息传递公式为:
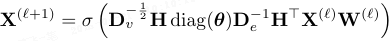
其中 θ 为语义引导超边构建时诱导的超边权重,W(ℓ) 为可学习投影矩阵,σ(⋅) 为非线形激活。
该操作从结构邻域和语义引导分组中聚合信息,使每个 patch 由其高阶关系上下文化。
- 通过堆叠多个超图推理层,局部 patch 表示逐步通过与语义一致和结构相关区域的交互得到精炼。
- 结果,异常区域将表现为无法被其超图邻域一致解释的区域,而不仅仅是与正常语义相似度低。
- 最终,精炼特征 X(L) 作为异常显著性估计和残差融合的基础。
给定 query 图像 Q,通过冻结的图像编码器 E_image 提取 patch token P_q,并通过**语义对齐分支(Semantic Alignment Branch,SAB)**计算初始异常估计 M_base。
- 通过 query patch 与诱导语义库 R 的余弦相似度获得文本驱动的异常图 M_txt;
- 同时,通过与支持特征库的 KNN 匹配计算视觉驱动图 M_vis。
- 两者结合得到基础异常图 M_base,该图提供了可靠的语义先验,同时保持对patch级模糊性的敏感性。
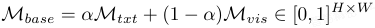
为融入超越局部 patch 证据的结构一致性,设计超图推理分支(Hypergraph Reasoning Branch,HRB):
- 把相同的 query patch 特征嵌入到语义引导的异质超图中,通过 L 层超图推理精炼,得到最终上下文化的(contextualized)视觉节点表示 X^(L)。
- 对 X^(L) 应用异常头得到节点级概率 s_q,重塑并插值到 M_base 的空间分辨率,得到结构感知的异常图 M_{hg}。
HRB 不是独立预测器,而是通过建模高阶结构偏差来精炼基础估计,产生超图残差:
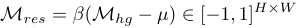
其中,μ 为对应决策边界的中心偏置,β 控制残差幅度。
然后,将超图残差作为像素级校正应用于基础异常估计。对每个空间位置 (i,j),将其校正响应投影到有效范围 0,1 以确保数值稳定:
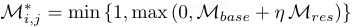
其中,M* 为最终像素级异常分数,η 控制超图推理的贡献。
【这里为什么使用的强制投影,而不是归一化?】
最终,异常图 M* 直接用于像素级定位。对于图像级检测,M* 进一步通过可学习的软直方图池化头汇总,然后输入轻量级 MLP 产生图像级 logits。
3.5 优化目标
本文使用复合目标函数端到端优化 H₂VLR:
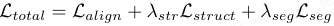
损失项 1:基础语义对齐:采用组合对齐损失
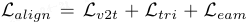
其中,L_v2t 和 L_tri 分别对齐视觉 token 与语义中心,并规整 embedding 空间;显式异常间隔(EAM)损失强制决策边界:
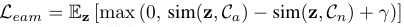
损失项2:超图结构正则化:采用结构约束在推断拓扑上传播稀疏监督。令 s_q 为节点级异常分数,该分支监督为:
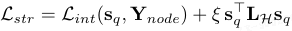
其中,L_int 结合 Focal 损失和 BCE 损失(对下采样真值 Y_node),L_H 为由关联结构导出的拉普拉斯矩阵。二次项(权重 ξ)通过惩罚结构相关 patch 间的分数差异来强制流形平滑性。
损失项3:语义引导分割:最终图 M* 由 Dice 损失和 Focal 损失监督。为抑制背景噪声,加入语义加权惩罚:
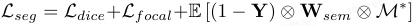
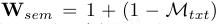
其中,W_sem 利用文本驱动的先验 M_txt 降低语义无关区域的假阳性权重。
4. 实验
4.1 设置
数据集:5 个工业基准(MVTec, VisA, BTAD, MPDD, 自建 BeltAD)和 3 个医学数据集(BrainMRI, LiverCT, BUSI)。
评估指标:图像级 AUC(I-AUC)和像素级 AUC(P-AUC)。
实现细节:
- PyTorch,冻结 OpenCLIP(ViT-B/16+)骨干,
- SGD 优化 100 轮(lr 2e-3,batch size 400),图像分辨率 240×240,
- λ_str = 0.02,λ_seg = 1.0,
- 超图(TopK)K=8,推理层 L=2,
- 单张 RTX 4090。
4.2 性能比较
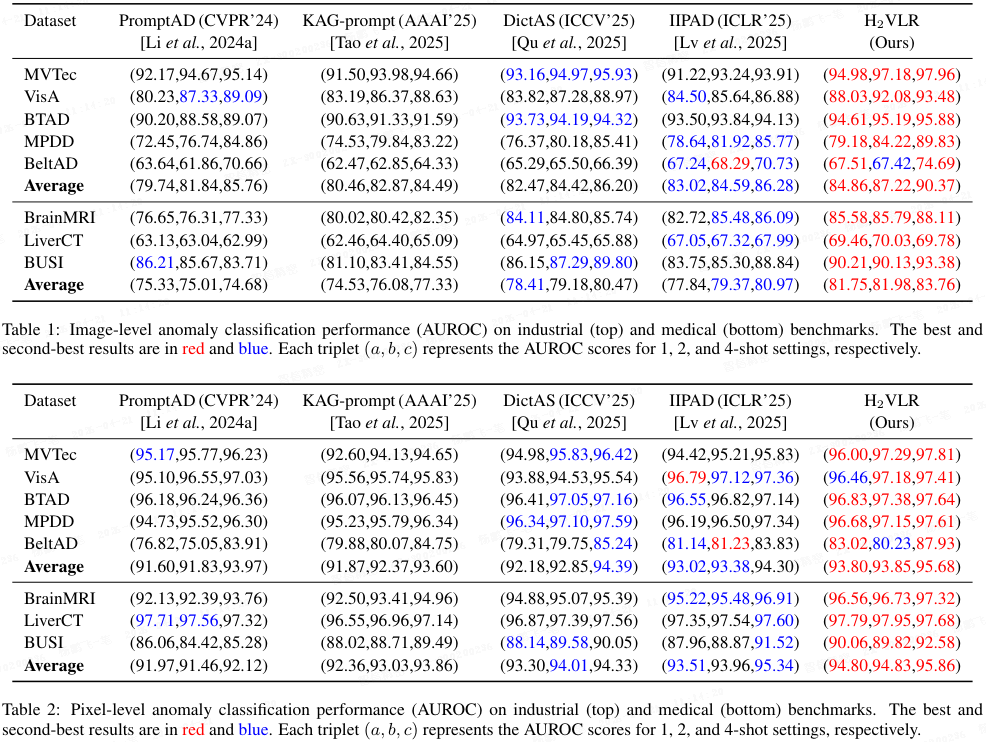
定量比较:对比 PromptAD、KAG-prompt、DictAS、IIPAD。在统一设置下重训。结果见表 1(图像级)和表 2(像素级)。
- H₂VLR 在多数情况下超越其他方法,例如 4-shot 下 MVTec I-AUC 97.96%,BUSI 93.38%;BrainMRI P-AUC 97.32%。
- 工业数据集上平均结果(84.86, 87.22, 90.37)优于医学数据集(81.75, 81.98, 83.76)。
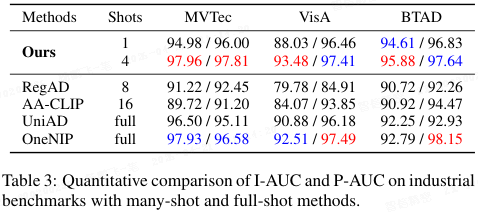
- 与更多样本及全样本方法对比见表 3,H₂VLR 的 1-shot 性能甚至超越 RegAD(8-shot)和 AA-CLIP(16-shot),4-shot 超越全样本的 OneNIP。
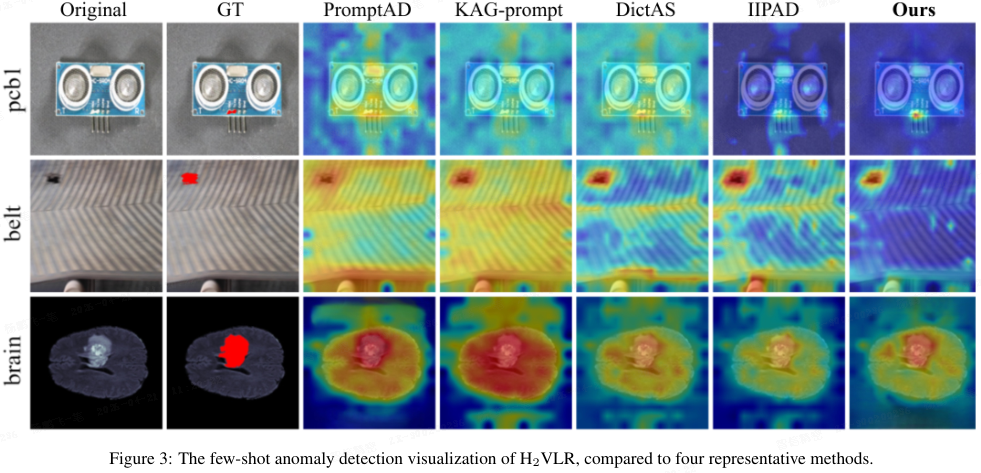
可视化比较:图 3 显示 H₂VLR 在多个数据集上取得更精确、更少噪声的异常检测与定位结果,与定量结果一致。
4.3 消融研究
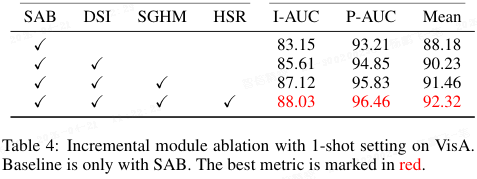
模块消融:表 4 验证了语义对齐分支(SAB)、动态语义诱导(DSI)、语义引导超图建模(SGHM)、高阶结构推理(HSR)的有效性。各模块逐步带来明显性能提升,例如 DSI 使 I-AUC 提升 2.46%。
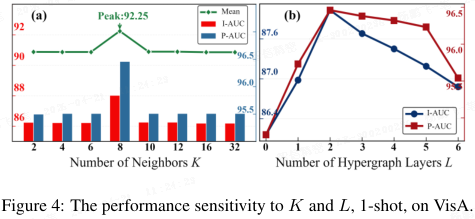
超图参数:图 4 显示 K=8 和 L=2 时性能最优。
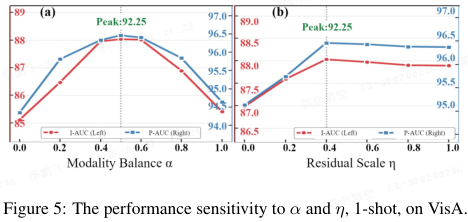
其他主要参数:图 5 显示 α=0.5 和 η=0.4 时性能最优。
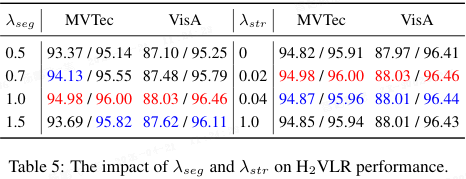
特殊损失参数:表 5 显示 λseg=1.0 和 λstr=0.02 时最优。
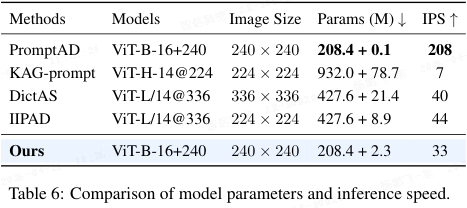
参数与推理速度:表 6 显示 H₂VLR 仅增加 2.3M 可学习参数(总计 210.7 M),推理速度 33 images/s,虽低于 PromptAD 但远高于 KAG-prompt,在检测性能上达 SOTA。