本部分收集若干 2025-2026 年的时间序列预测与情感分析结合的文章。目前市面上对于情感分析的研究仅局限于找到一个合适的情感数据集,这对于我们将时间序列预测应用于实践的道路还很遥远。收集市面上的科研论文在这方面的做法,对于我们更深刻的理解市场有重要意义。本模块聚焦于收集情感分析的做法,分析其局限性以及可以改进的方向。
情感分析,是我们时间序列预测方向上的一组高位特征,如何收集特征和如何建模特征是两个重要问题。特征建模则是我们非常熟悉的一个环节,即使用深度学习模型或者模块进行建模。除此之外,那么对于情感分析来说,最重要的就是特征收集了,也就是情感分析数据集如何获取的问题。
情感分析数据集获取
YaHoo API
https://eodhd.com/financial-apis/stock-market-financial-news-api#Sentiment_Data_API
GET https://eodhd.com/api/news
API 描述:
金融新闻API返回给定股票代码或主题标记的最新金融新闻标题和完整文章。您必须提供"s"(代码)或"t"(标记)---至少需要一个。该API支持按日期筛选、分页和以JSON格式返回结果。
请求 URL 例子:
https://eodhd.com/api/news?s=AAPL.US&offset=0&limit=10&api_token=your_api_token&fmt=json参数:
| Parameter | Required | Type | Description |
|---|---|---|---|
| s | Yes (if t not set) | string | 检索新闻的股票代码,例如: AAPL.US |
| t | Yes (if s not set) | string | 检索新闻的主题标签,例如:科技 |
| from | No | string (YYYY-MM-DD) | 开始日期 |
| to | No | string (YYYY-MM-DD) | 结束日期 |
| limit | No | integer | 返回的结果数(默认:50,最小:1,最大:1000) |
| offset | No | integer | 返回的结果数(默认:50,最小:1,最大:1000) |
| fmt | No | string | 返回格式, json 或 xml (default: json) |
| api_token | Yes | string | API token |
输出格式 (JSON):
Each article includes:
| Field | Type | Description |
|---|---|---|
| date | string (ISO 8601) | The publication date and time of the article |
| title | string | The headline of the news article |
| content | string | Full article body |
| link | string | Direct URL to the article |
| symbols | array | List of ticker symbols mentioned in the article |
| tags | array | Article topic tags (may be empty) |
| sentiment | object | Contains sentiment scores: polarity, neg, neu, pos |
http responds 格式案例:
jsx
**"date": "2025-08-18T08:48:00+00:00",
"title": "Kenya Healthcare Statistics Databook 2025: Navigate Healthcare Planning with Over 300 KPIs Spanning Patient to Pharmacist Statistics",
"content": "Dublin, Aug. 18, 2025 (GLOBE NEWSWIRE) -- The \"Kenya Healthcare Statistics Databook Q2 2025: 300+ KPIs Covering Detailed Statistics on Patients, Healthcare Facilities, Public and Private Spending, Medical Staff\" report has been added to ResearchAndMarkets.com's offering.This comprehensive report on Kenya's healthcare sector offers a range of statistics covering the entire value chain an in-depth data-centric analysis of the entire healthcare ecosystem, covering a range of modules from demographic data to healthcare .....",
"link": "https://www.globenewswire.com/news-release/2025/08/18/3134815/28124/en/Kenya-Healthcare-Statistics-Databook-2025-Navigate-Healthcare-Planning-with-Over-300-KPIs-Spanning-Patient-to-Pharmacist-Statistics.html",
"symbols": [
"AAPL.US"
],
"tags": [
"DEMOGRAPHICS",
"GLOBAL",
"GROSS DOMESTIC PRODUCT",
"HEALTH PROFESSIONAL",
"HEALTHCARE ANALYTICS",
"HEALTHCARE INFRASTRUCTURE",
"HEALTHCARE LANDSCAPE",
"HEALTHCARE RESOURCES",
"HEALTHCARE SECTOR",
"HEALTHCARE SPENDING",
"HEALTHCARE STATISTICS",
"KENYA",
"MARKET OPPORTUNITIES",
"MARKET RESEARCH REPORTS",
"MEDICAL STAFF",
"MEDICAL STAFFING",
"PHARMACEUTICAL DISTRIBUTION",
"PHARMACIES",
"POPULATION TRENDS"
],
"sentiment": {
"polarity": 0.959,
"neg": 0.008,
"neu": 0.948,
"pos": 0.044
}
.......**在此过程中,我们会得到一个情感分析的数据集,此处为
| date | polarity | neg | neu | pos |
|---|---|---|---|---|
| 2025-08-18 | 0.959 | 0.008 | 0.948 | 0.044 |
| ... | ... | ... | ... | ... |
论文中仅使用了极性值这单一特征。文中的说法是将当天的极性分数求平均。即对于单一公司,其得到的特征维度为 1 × W 1 \times W 1×W,对于 N N N 个公司,则维度为 N × W N \times W N×W, W W W 为时间维度。在与传统时间序列特征合并之前,需要进行建模,该建模过程使用 Transformer,将其维度转换为 d m o d e l × W d_{model} \times W dmodel×W。最后使用向量直接相加的方式进行融合。
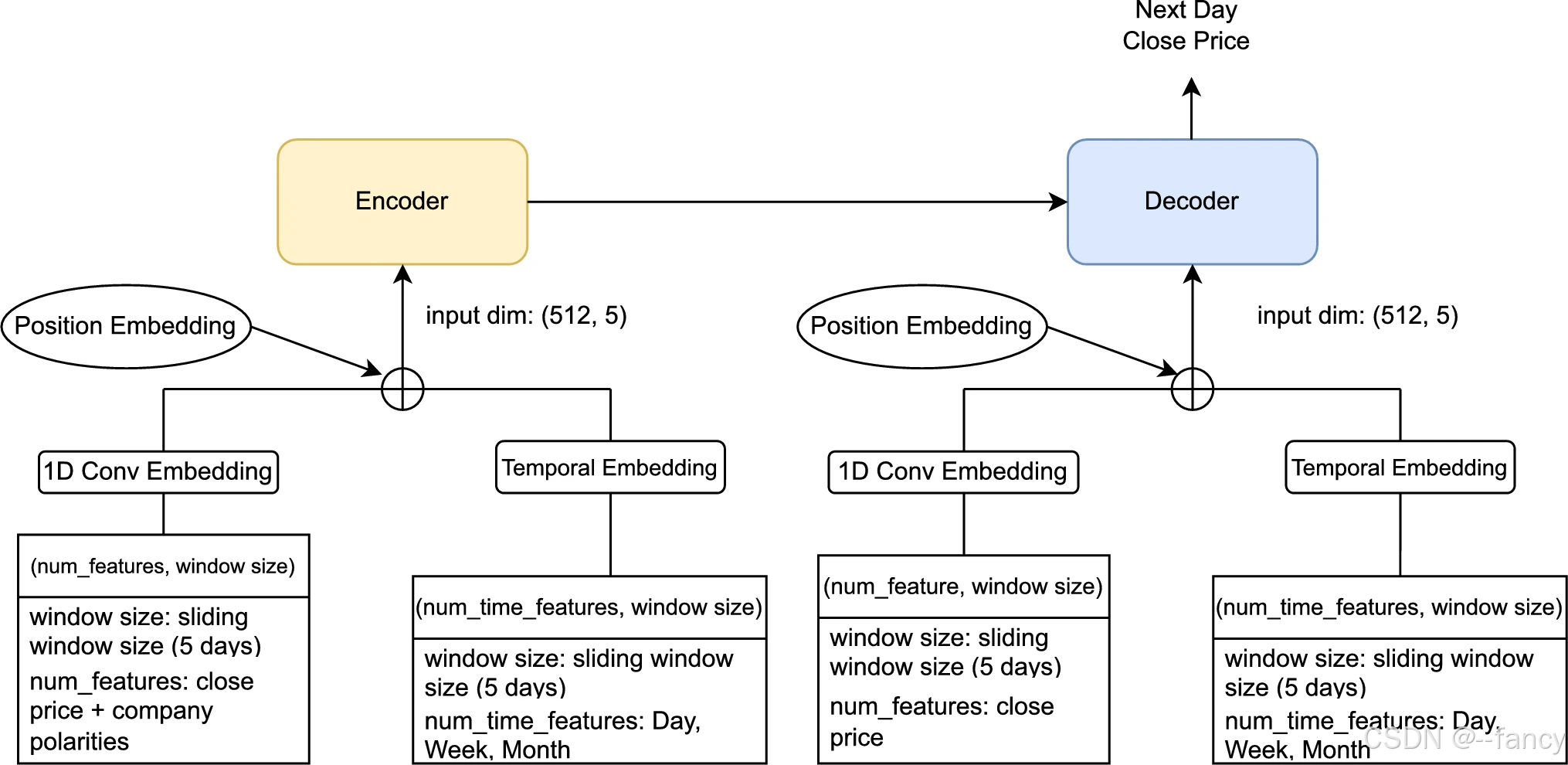
参考文献
A novel sentiment correlation-based method with dual transformer model for stock price prediction
中国研究数据服务平台(CNRDS)数据库
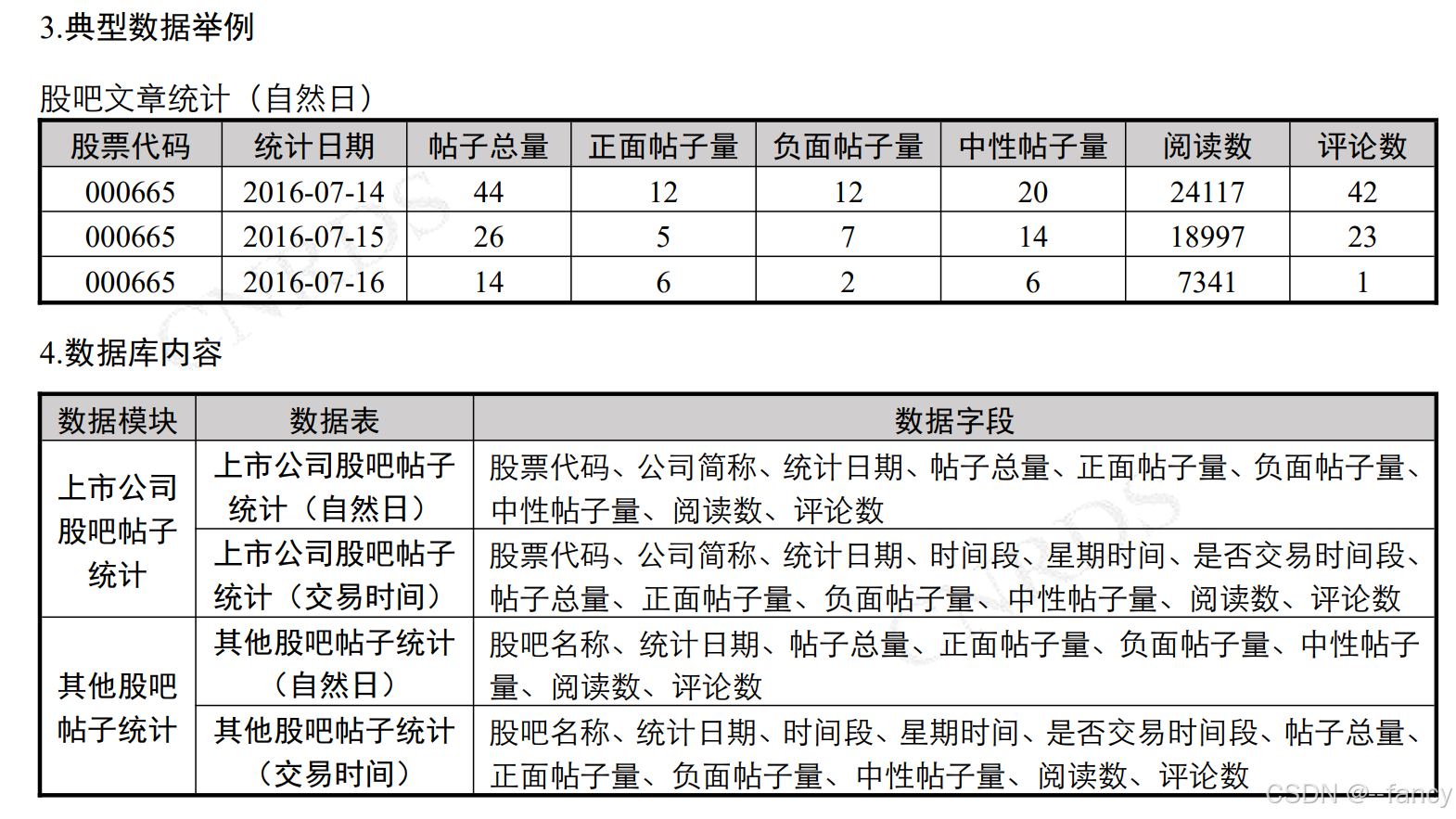
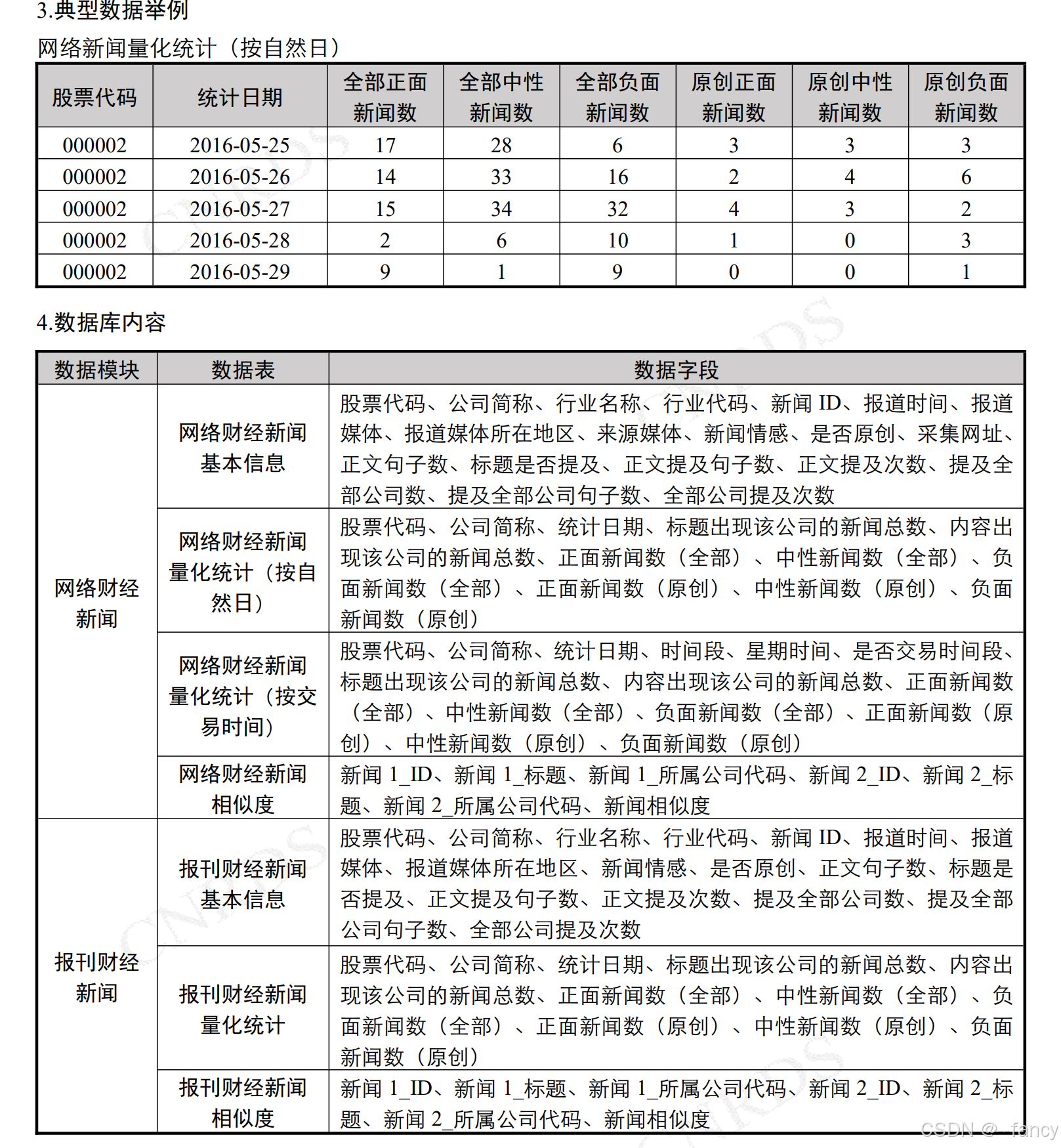
投资者情绪数据来源于中国研究数据服务平台(CNRDS)数据库,这是一个面向中国经济学、金融学和商业研究的开放性、综合性数据平台。在本研究中,2018 年至 2022 年的中国上市公司财务新闻数据库(CFND)和中国上市公司股票评论数据库(GUBA)被用于 CNRDS 数据库。作为中国首个采用先进人工智能技术聚合、总结和分析上市公司财务新闻的综合性大数据平台,CFND 主要涵盖两个核心模块:网络财经新闻和报纸财经新闻。在网络财经新闻模块中,汇集了来自 400 多家主流网络媒体的新闻报道。此外,该平台还整合了 400 多家其他重要的大型网站、行业门户和地方新闻网站。报纸财经新闻模块汇集了 500 多家知名报纸和媒体的新闻数据,被广泛用作国内经济、管理和商业研究的重要数据资源。同时,该模块还包括中央报纸、地方晨报、日报、晚报和各种财经类报纸。GUBA 专注于中国最具影响力的证券交易所论坛------东方财富网,网友们在这里发布了大量关于上市公司的帖子。
论文中介绍了这个数据库,并且使用了 CFND 和 GUBA,这两个具体的数据库就是该论文情感分析中使用的数据集。
首先来看 GUBA
其次是 CFND
以上两个数据库构建了三类情绪指标,分别为社媒情绪指标 S t S S_t^S StS 、互联网情绪指标 S t I S_t^I StI 和报刊情绪指标 S t N S_t^N StN,(Liang 等人,2020)情绪指标的计算由以下公式表示:
S t = ln 1 + p o s t 1 + n e g t S_t = \ln\frac{1 + pos_t}{1 + neg_t} St=ln1+negt1+post
其中, p o s t pos_t post 是第 t t t 天的正面评论或新闻数量,而 n e g t neg_t negt 是第 t t t 天的负面评论或新闻数量。
此外,论文还构建了另外一种情感指标,一个是均值指标,另一个是机器学习指标。
首先,使用等组合来设计基于社媒情绪指标 S t S S_t^S StS 、互联网情绪指标 S t I S_t^I StI 和报刊情绪指标 S t N S_t^N StN的等情感指标 S t E S_t^E StE ,其计算简单且避免了主观权重偏差,但也忽略了媒体影响差异。具体公式参考:
S t E = 1 3 S t S + 1 3 S t N + 1 3 S t I S_t^E = \frac{1}{3}S_t^S + \frac{1}{3}S_t^N + \frac{1}{3}S^{I}_t StE=31StS+31StN+31StI
另一个情绪指标公式使用主成分分析来给予权重,具体公式参考:
S t P C A = a S S t S + a N S t N + a I S t I S_t^{PCA} = a_SS_t^S + a_N S_t^N + a_IS^{I}_t StPCA=aSStS+aNStN+aIStI
其中, a S a_S aS、 a N a_N aN 、 a I a_I aI 分别代表对应情感指标的贡献率,取值范围为-1, 1。
最后我们看一下实验结果,这里只放部分了,挑选了三个行业。
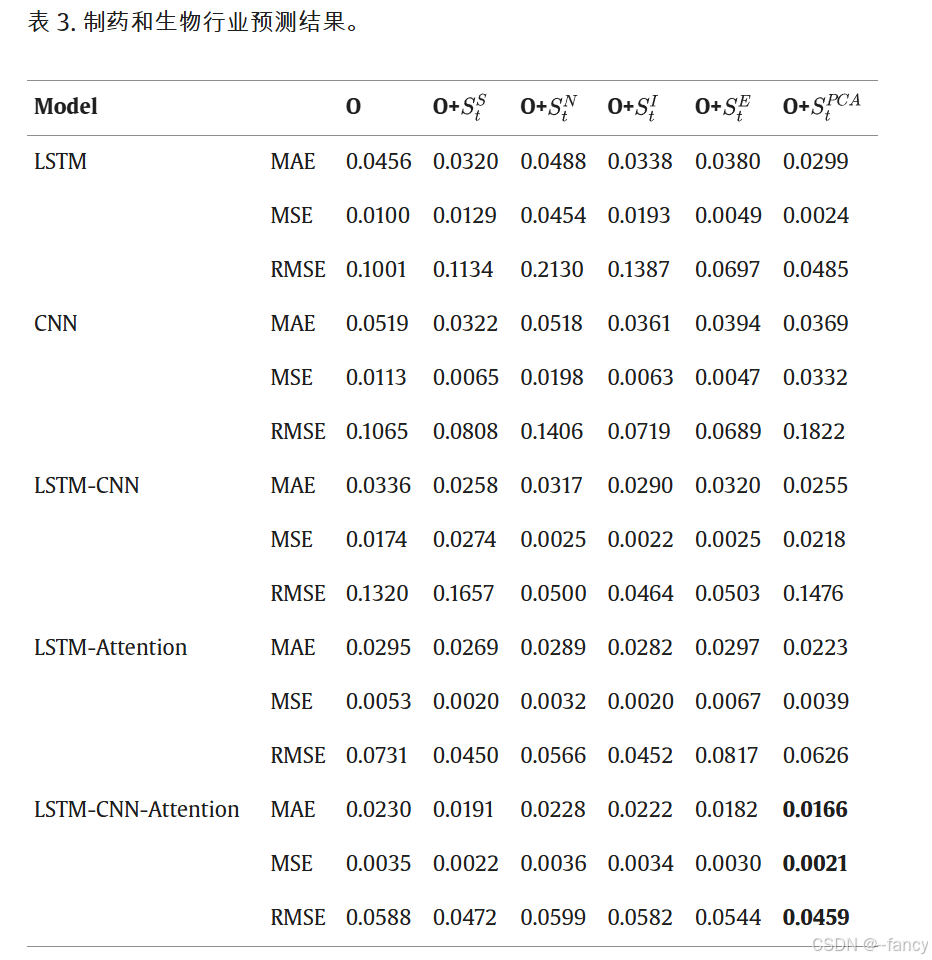
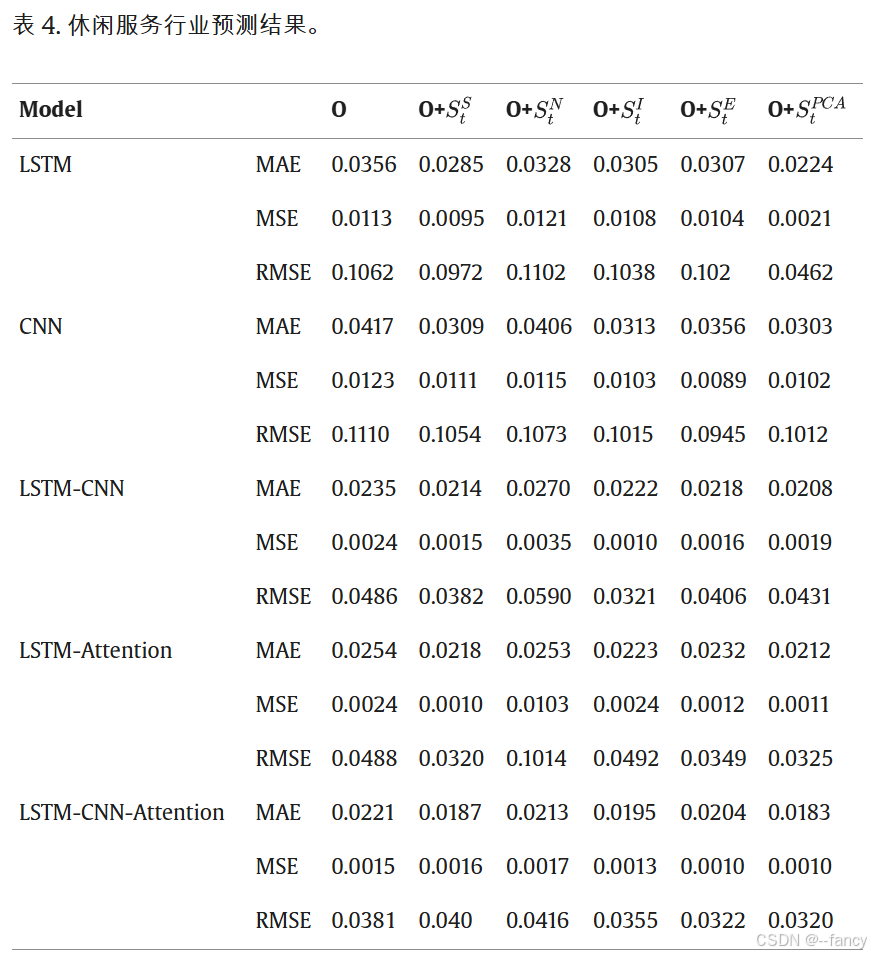
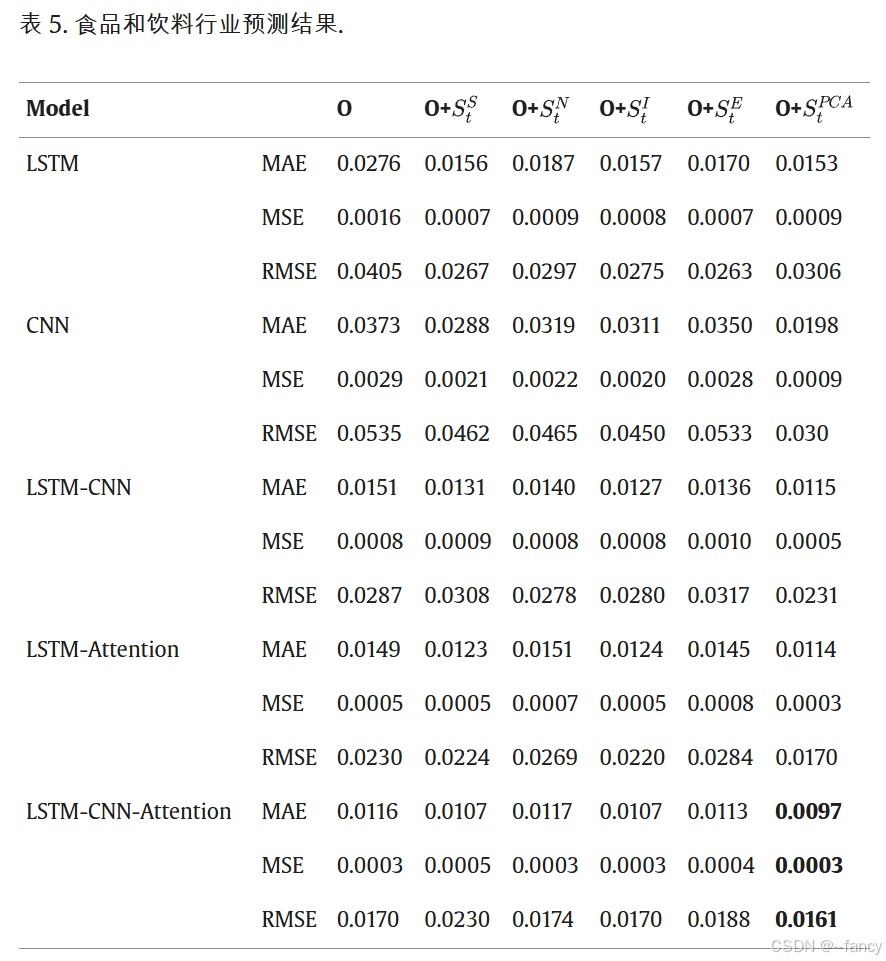
最后放一下消融实验
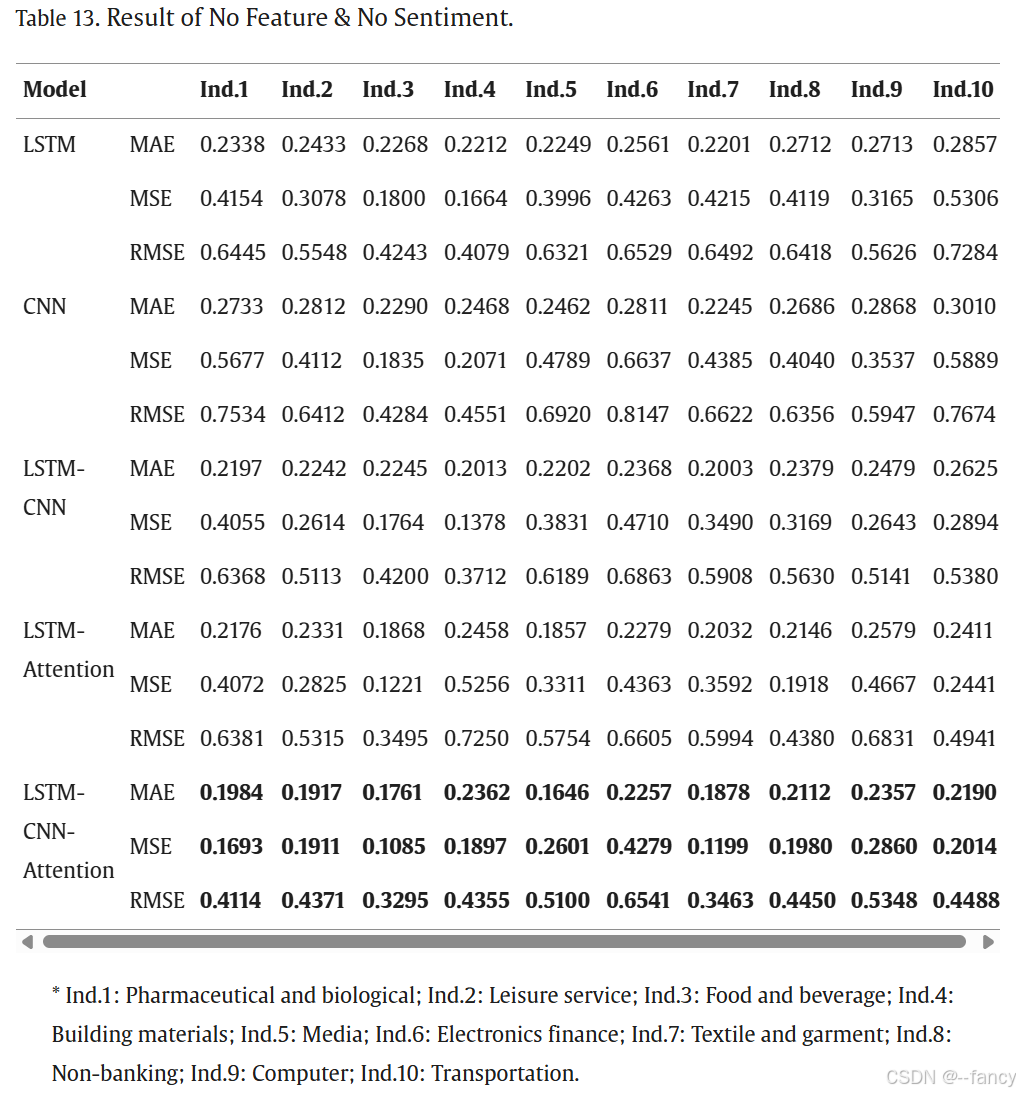
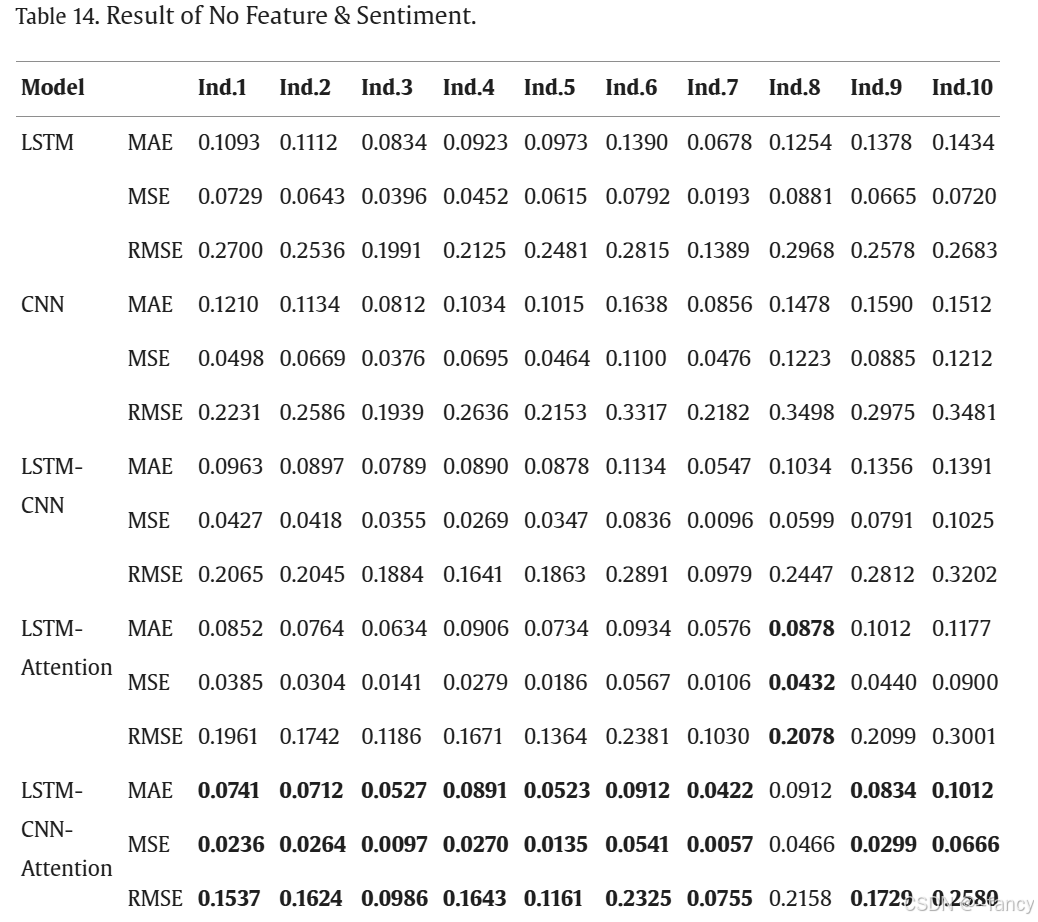
这里的结论是 特征选择 > 情感指标。
参考文献
A multi-feature selection fused with investor sentiment for stock price prediction
Which sentiment index is more informative to forecast stock market volatility? Evidence from China
情感分析建模
机器学习建模
- 主成分分析
- 聚类
- ...
传统深度学习建模
模型设计综述
基于大语言模型的情感分析建模 ------ FinBert
FinBert 是一个金融大于语言模型,可以用与金融的情感分析,获取情感分析向量,这个向量可以直接作为时间序列预测的特征向量,值得我们学习与参考。
// 未完待续...
参考文献
FinBERT2: A Specialized Bidirectional Encoder for Bridging the Gap in Finance-Specific Deployment of Large Language Models。除此之外,那么对于情感分析来说,最重要的就是特征收集了,也就是情感分析数据集如何获取的问题。